
В рамках проекта интеграции GridGain и хранилища на базе Hadoop (HDFS + HBASE) мы столкнулись с задачей получения и обработки существенного объема данных, примерно до 80 Тб в день. Это необходимо для построения витрин и для восстановления удаленных в GridGain данных после их выгрузки в наше долговременное хранилище. В общем виде, можно сказать, что мы передаём данные между двумя распределёнными системами обработки данных при помощи распределённой системы передачи данных. Соответственно, мы хотим рассказать о тех проблемах, с которыми столкнулась наша команда при реализации данной задачи и как они были решены.
Так как инструментом интеграции является кафка (весьма подробно о ней описано в статье Михаила Голованова), естественным и легким решением тут выглядит использование SparkStreaming. Легким, потому что не нужно особо беспокоиться о падениях, переподключениях, коммитах и т.д. Spark известен, как быстрая альтернатива классическому MapReduce, благодаря многочисленным оптимизациям. Нужно лишь настроиться на топик, обработать батч и сохранить в файл, что и было реализовано. Однако в ходе разработки и тестирования была замечена нестабильность работы модуля приема данных. Для того чтобы исключить влияние потенциальных ошибок в коде, был произведен следующий эксперимент. Был выпилен весь функционал обработки сообщений и оставлено только прямое сохранение сразу в avro:
JavaRDD<AvroWrapper<GenericRecord>> map = rdd.map(messageTuple ->
{
SeekableByteArrayInput sin = new SeekableByteArrayInput(messageTuple.value());
DataFileReader dataFileReader = new DataFileReader<>(sin, new GenericDatumReader<>());
GenericRecord record = (GenericRecord) dataFileReader.next();
return new AvroWrapper<>(record);
});
Timestamp ts = new Timestamp(System.currentTimeMillis());
map.mapToPair(recordAvroWrapper ->
new Tuple2<AvroWrapper<GenericRecord>, NullWritable>(recordAvroWrapper, NullWritable.get()))
.saveAsHadoopFile("/tmp/SSTest/" + ts.getTime(),
AvroWrapper.class, NullWritable.class,
AvroOutputFormat.class, jobConf);
Все тесты проходили на таком стенде:

Как выяснилось, на свободном от чужих задач кластере все работает прекрасно, можно получать довольно хорошую скорость. Однако оказалось, что при работе одновременно с другими приложениями наблюдаются весьма большие задержки. Причем, проблемы возникают даже при смешных скоростях, около 150 МБ/сек. Иногда спарк выходит из депрессии и нагоняет упущенное, однако иногда бывает вот так:
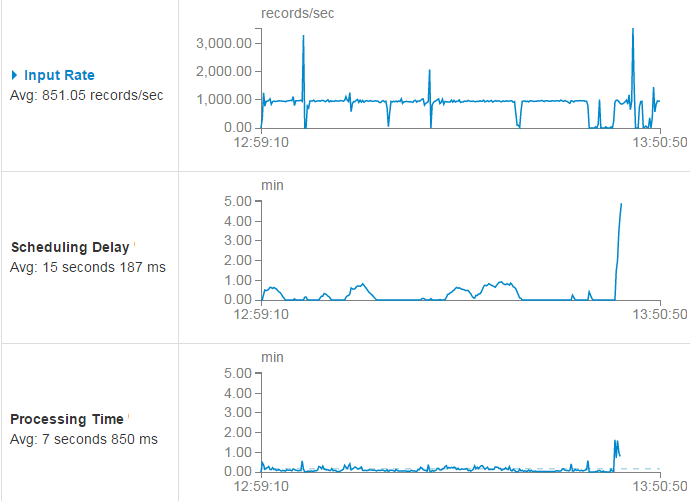
Тут видно, что при скорости приема порядка 1000 сообщений в секунду (input rate), после нескольких просадок задержка начала обработки батча (scheduling delay) все-таки возвращалась к норме (средняя часть графика). Однако в какой-то момент время обработки (processing time) вышло из допустимых пределов и душа спарка не выдержав земных испытаний и устремилась в небо.
Понятно, что для индийского гуру это норм, но наш ПРОМ стоит не в ашраме, так что это не особо приемлемо. Для того чтобы убедиться, что проблема не в функции сохранения данных, можно воспользоваться оберткой Dataset — вроде как он хорошо оптимизирован. Поэтому пробуем такой код:
JavaRDD<Row> rows = rdd.map(messageTuple -> {
try (SeekableByteArrayInput sin = new SeekableByteArrayInput(messageTuple.value());
DataFileReader dataFileReader = new DataFileReader<>(sin, new GenericDatumReader<>())) {
GenericRecord record = (GenericRecord) dataFileReader.next();
Object[] values = new Object[]{
record.get("field_1"),
…
record.get("field_N")};
return new GenericRowWithSchema(values, getSparkSchema(ReflectData.get().getSchema(SnapshotContainer.class)));
}
});
StructType st = (StructType) SchemaConverters.toSqlType(schm).dataType();
Dataset<Row> batchDs = spark.createDataFrame(rows, st);
Timestamp ts = new Timestamp(System.currentTimeMillis());
batchDs
.write()
.mode(SaveMode.Overwrite)
.format("com.databricks.spark.avro")
.save("/tmp/SSTestDF/" + ts.getTime());И получаем точно такие же проблемы. Причем если запустить одновременно две версии, на разных кластерах, то проблемы возникали только у той, которая работает на более загруженном. Это означало, что проблема не в кафке и не в специфике функции сохранения данных. Также тестирование показало, что если одновременно читать тот же самый топик с которым работал SS, при помощи flume на этом же кластере, то было получено такое же замедление извлечения данных:
Topic1, Cluster1, SparkSreaming – замедления
Topic2, Cluster1, Flume – замедления
Topic2, Cluster2, SparkSreaming – без замедлений
Иными словами, проблема заключалась именно в фоновой нагрузке на кластер. Таким образом, задача заключалась в том, чтобы написать приложение, которое будет надежно работать в высоконагруженной среде, и все это осложнялось тем, что тесты выше не содержат в себе вообще никакой логики обработки данных. Тогда как реальный процесс выглядит примерно так:
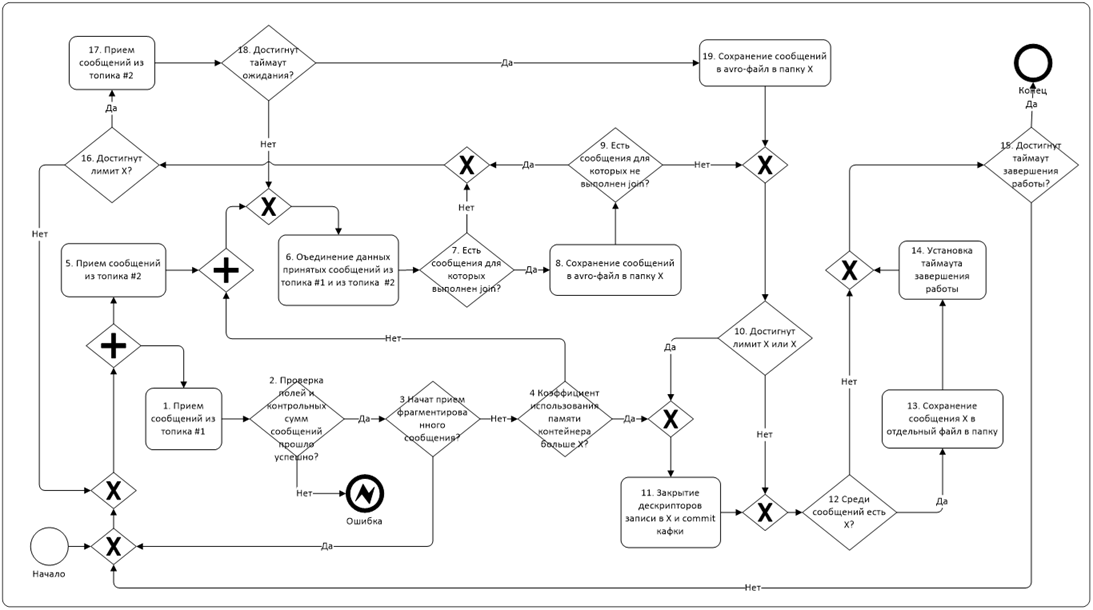
Основную трудность тут представляет задача сбора данных одновременно из двух топиков (из одного маленький поток данных, а из второго большой) и их join на лету. Также была необходимость писать данные из одного батча в разные файлы одновременно. В спарке это реализовали, используя сериализуемый класс и вызывая его методы из мапы приёма сообщений. Иногда спарк падал, пытаясь прочитать протухшие сообщения из топика, и мы начали хранить оффсеты в hbase. В какой-то момент мы начали взирать на получающегося монстра с какой-то тоской и душеными муками.
Поэтому мы решили обратиться к светлой стороне силы – теплой, ламповой java. Благо у нас аджайл, и совсем не обязательно

Однако для этого нужно решить проблему распределенного приема сообщений сразу с нескольких нод. Для этого был выбран фреймворк Spring for Apache Hadoop, который позволяет запустить необходимое количество контейнеров Yarn и выполнять свой код внутри каждого.
Общая логика работы у него следующая. Запускается AppMaster, который является координатором работы контейнеров YARN. Т.е., он запускает их, передавая необходимые параметры им на вход, и отслеживает статус выполнения. В случае падения контейнера (например по причине OutOfMemory) он может перезапустить его или завершить работу.
Непосредственно в контейнере и реализована логика работы с кафкой и обработки данных. Так как YARN запускает контейнеры распределяя по нодам кластера примерно равномерно, не возникает узких мест для сетевого трафика или доступа к дискам. Каждый контейнер цепляется к выделенной партиции и работает только с ней, это помогает избежать ребалансировки консюмеров.
Ниже дано сильно упрощенное описание логики работы модуля, более детальное описание того, что происходит под капотом спринга, коллеги планируют сделать в отдельной статье. Оригинальный пример можно скачать тут.
Итак, для запуска мастера используется модуль клиент:
@EnableAutoConfiguration
public class ClientApplication {
public static void main(String[] args) {
ConfigurableApplicationContext applicationContext = SpringApplication.run(ClientApplication.class, args);
YarnClient yarnClient = applicationContext.getBean(YarnClient.class);
yarnClient.submitApplication();
}
}После того как выполнен submit мастера клиент завершает работу. Далее работает класс CustomAppMaster прописанный в application.yml
spring:
hadoop:
fsUri: hdfs://namespace:port/
resourceManagerHost: hostname
resources:
- "file:/path/hdfs-site.xml"
yarn:
appName: some-name
applicationDir: /path/to/app/
appmaster:
resource:
memory: 10240
virtualCores: 1
appmaster-class: enter.appmaster.CustomAppMaster
containerCount: 10
launchcontext:
archiveFile: container.jar
container:
container-class: enter.appmaster.FailingContextContainer
В нем наиболее интересна функция preLaunch. Тут мы управляем контейнерами и параметрами передаваемыми на вход:
@Override
public ContainerLaunchContext preLaunch(Container container, ContainerLaunchContext context) {
Integer attempt = 1; // Счетчик попыток запуска
ContainerId containerId = container.getId();
ContainerId failedContainerId = failed.poll();
if (failedContainerId == null) {
// Логика подготовки к запуску контейнера
}
else {
// Логика обработки случая падения контейнера (перезапуск и т.д.)
}
Object assignedData = (failedContainerId != null ? getContainerAssign().getAssignedData(failedContainerId) : null);
if (assignedData != null) {
attempt = (Integer) assignedData;
attempt += 1;
}
getContainerAssign().assign(containerId, attempt);
Map<String, String> env = new HashMap<String, String>(context.getEnvironment());
env.put("some.param", "param1");
context.setEnvironment(env);
return context;
}
И обработчик падений:
@Override
protected boolean onContainerFailed(ContainerStatus status) {
ContainerId containerId = status.getContainerId();
if (status.getExitStatus() > 0) {
failed.add(containerId);
getAllocator().allocateContainers(1);
}
return true;
}В классе контейнера ContainerApplication.java подключаются необходимые бины, например:
@Bean
public WorkClass workClass() {
return new WorkClass();
}В рабочем классе используем аннотацию @OnContainerStart для указания метода который будет вызван автоматически при старте контейнера:
@OnContainerStart
public void doWorkOnStart() throws Exception {
// Получаем текущий контейнер и выясняем текуший containerId
DefaultYarnContainer yarnContainer = (DefaultYarnContainer) containerConfiguration.yarnContainer();
Map<String, String> environment = yarnContainer.getEnvironment();
ContainerId containerId = getContainerId(environment);
// Получаем параметр на вход
String param = environment.get("some.param");
SimpleConsumer<Serializable, Serializable> simpleConsumer = new SimpleConsumer<>();
// Начинаем работать
simpleConsumer.kafkaConsumer(param);
}
В реальности логика реализации, конечно, гораздо сложнее. В частности, идет обмен сообщениями между контейнером и AppMaster через REST, позволяющий координировать процесс приема данных и т.д.
В итоге мы получили приложение, которое необходимо протестировать в условиях нагруженного кластера. Для этого днем, во время высокой фоновой нагрузки, запустили урезанную версию на SparkStreaming, которая ничего не делает кроме сохранения в файл, и одновременно версию «полный фарш» на java. Ресурсов им было выделено одинаково, каждому 30 контейнеров по 2 ядра.

Теперь интересно провести эксперимент в чистых условиях, чтобы понять предел производительности решения на java. Для этого была запущена загрузка 1.2 ТБ данных, 65 контейнеров по 1 ядру и она выполнилась за 10 минут:

Т.е. скорость составила 2 ГБ/сек. Более высокие значения на картинке выше объясняются тем, что фактор репликации данных на HDFS равен 3. CPU серверов кластера приема данных E5-2680v4 @ 2.40GHz. Остальные параметры нет большого смысла приводить, потому что все равно утилизация ресурсов существенно ниже 50%. Текущее решение позволяет легко масштабироваться и дальше, но это не имеет смысла, т.к. на данный момент узким местом является сама кафка (точнее её сетевые интерфейсы, там всего три брокера и при этом тройная репликация для надежности).
На самом деле, не должно показаться, что мы что-то имеем против спарка в принципе. Это весьма хороший инструмент в определенных условиях и мы его также используем для дальнейшей обработки. Однако высокий уровень абстракции, который позволяет быстро и легко работать с любыми данными, имеет свою цену. Всегда бывает когда что-то идет не так. Мы имели и опыт патчинга Hbase и ковыряния в коде Hive, однако, это не самое воодушевляющее занятие, на самом деле. В случае со спарком конечно тоже возможно найти какое-то приемлемое решение, однако ценой достаточно больших усилий. А в своем приложении мы всегда можем быстро найти причину проблем и исправить, а так же реализовать весьма сложную логику и это будет работать быстро. В общем как гласит старая латинская поговорка:

