Привет! Меня зовут Сергей, я работаю главным инженером в Сбертехе. В ИТ-сфере я примерно 10 лет, из которых 6 занимаюсь базами данных, ETL-процессами, DWH и всем, что связано с данными. В этом материале я расскажу о Vertica — аналитической и по-настоящему колоночной СУБД, которая эффективно сжимает, хранит, быстро отдает данные и отлично подходит в качестве big data решения.

С 2000-х годов начали развиваться большие данные и потребовались движки, которые способны все это переварить. В ответ на это появился ряд предназначенных для этого колоночных СУБД — в том числе и Vertica.
Vertica не просто хранит свои данные в колонках, она делает это рационально, с высокой степенью сжатия, а также эффективно планирует запросы и быстро отдает данные. Информация, которая в классической строчной СУБД занимает около 1 ТБ дискового пространства, на Vertica займет порядка 200-300 Гб, тем самым мы получаем хорошую экономию на дисках.
Vertica изначально проектировалась именно как колоночная СУБД. Другие базы в основном только стараются имитировать различные колоночные механизмы, но у них это не всегда хорошо получается, поскольку движок все равно создан чтобы обрабатывать строки. Как правило, подражатели просто транспонируют таблицу и далее обрабатывают привычным строчным механизмом.
Vertica отказоустойчива, в ней нет управляющей ноды — все ноды равны. Если с одним из серверов в кластере возникают проблемы, то данные мы все равно получим. Очень часто получить данные вовремя бывает критично для бизнес-заказчиков, особенно в период, когда закрывается отчетность и нужно предоставлять информацию в финансовые органы.
Vertica — это в первую очередь аналитическое хранилище данных. В нее не стоит писать мелкими транзакциями, не стоит прикручивать ее к какому-то сайту и т.п. Vertica следует рассматривать как некий batch-слой, куда стоит погружать данные большими пачками. При необходимости Vertica очень быстро готова эти данные отдать — запросы на миллионы строк выполняются за секунды.
Где это может быть полезно? Возьмем для примера телекоммуникационную компанию. Vertica может использоваться в ней для геоаналитики, развития сети, управления качеством, целевого маркетинга, изучения информации с контактных центров, управления оттоком клиентов и антифрод/антиспам-решений.

В других отраслях бизнеса все примерно так же — для получения прибыли важна своевременная и достоверная аналитика. В торговле, например, все пытаются как-то персонализировать клиентов, распространяют для этого дисконтные карты, собирают данные о том, где что и когда человек покупал и т.п. Анализируя массивы информации со всех этих каналов, мы можем ее сопоставлять, строить модели и принимать решения, ведущие к росту прибыли.
Сегодня любой работодатель требует, чтобы аналитик представлял, что такое SQL. Если вы знаете ANSI SQL, то вас можно назвать уверенным пользователем Vertica. Если вы можете строить модели на Python и R, то вы просто «массажист» данных. Если освоили Linux и имеете базовые знания по администрированию Vertica, то можете работать администратором. В целом, входной порог в Vertica невысокий, но, разумеется, все нюансы можно узнать, только набивая руку в процессе эксплуатации.
Рассмотрим Vertica на уровне кластера. Эта СУБД обеспечивает массивно-параллельную обработку данных (МРР) в распределенной вычислительной архитектуре — «shared-nothing» — где, в принципе, любая нода готова подхватить функции любой другой ноды. Основные свойства:
Кластер без проблем линейно масштабируется. Мы просто ставим сервера в полку и подключаем их через графический интерфейс. Помимо серийных серверов, возможно развертывание на виртуальные машины. Что можно добиться с помощью расширения?
Но нужно кое-что учесть. Периодически ноды нужно вынимать из кластера для обслуживания. Еще довольно распространенный кейс в крупных организация — сервера сходят с гарантии и переходят из продуктивной в какую-нибудь тестовую среду. На их место встают новые, которые находятся на гарантии производителя. По итогам всех этих операций нужно выполнять ребалансировку. Это процесс, когда данные перераспределяются между нодами — соответственно перераспределяется рабочая нагрузка. Это требовательный к ресурсам процесс, и на кластерах с большим объемом данных он может сильно снизить производительность. Чтобы этого избежать, нужно выбрать сервисное окно — время, когда нагрузка минимальна, и в этом случае пользователи этого не заметят.
Для понимания, как хранятся данные в Vertica, требуется разобраться с одним из основных понятий — проекцией.
Логические единицы хранения информации — это схемы, таблицы и представления. Физические единицы — это проекции. Проекции бывают нескольких типов:
При создании любой таблицы автоматически создается суперпроекция, которая содержит все колонки нашей таблицы. Если нужно ускорить какой-то из регулярных процессов, мы можем создать специальную запрос-ориентированную проекцию, которая будет содержать, допустим, 3 столбца из 10.
Для ускорения предназначен и третий тип — агрегированные проекции. Не буду вдаваться в их подклассы — это не очень интересно. Сразу хочу предупредить, что постоянно решать свои проблемы с выполнением запросов через создание новых проекций не стоит. В конечном итоге кластер начнет тормозить.
Создавая проекции, нужно оценивать, хватает ли нашим запросам суперпроекций. Если мы все-таки хотим поэкспериментировать, добавляем строго по одной новой проекции. При возникновении проблем так будет проще найти первопричину. Для больших таблиц следует создавать сегментированную проекцию. Она разбивается на сегменты, которые распределяются по нескольким нодам, что повышает отказоустойчивость и минимизирует нагрузки на одну ноду. Если таблички маленькие, то лучше делать несегментированные проекции. Они полностью копируются на каждую ноду, и производительность таким образом увеличивается. Оговорюсь: в терминах Vertica «маленькая» таблица — это примерно 1 млн строк.
Отказоустойчивость в Vertica реализована при помощи механизма K-Safety. Он довольно простой с точки зрения описания, но сложный с точки зрения работы на уровне движка. Им можно управлять с помощью параметра K-Safety — он может иметь значение 0, 1 или 2. Этот параметр задает количество копий сегментированных проекционных данных.
Копии проекций называются buddy projections. Я попытался перевести это словосочетание через Яндекс-переводчик и получилось что-то вроде «проекции-кореша». Гугл предлагал варианты и интересней. Обычно данные проекции называют партнерскими или соседними, по их функциональному назначению. Это проекции, которые просто хранятся на соседних нодах и таким образом резервируются. У несегментированных проекций нет buddy projections — они копируются полностью.
Как это работает? Рассмотрим кластер из пяти машин. Пусть K-safety у нас равен 1.
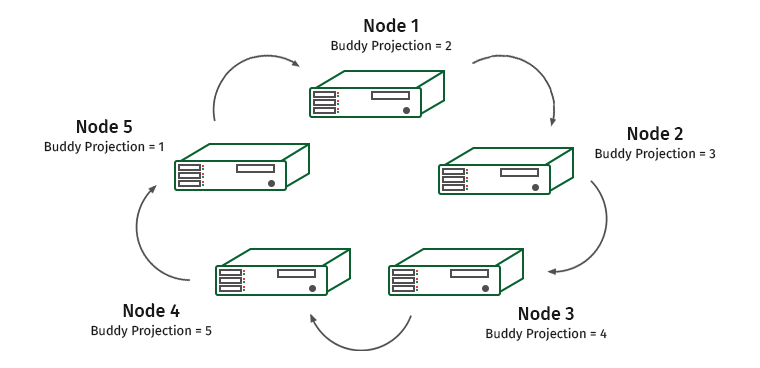
Ноды пронумерованы, а под ними написаны партнерские проекции, которые хранятся на них. Предположим, у нас отключилась одна нода. Что будет?

Нода 1 содержит дружественную проекцию ноды 2. Поэтому на ноде 1 подрастет нагрузка, но работать кластер не перестанет. А теперь такая ситуация:
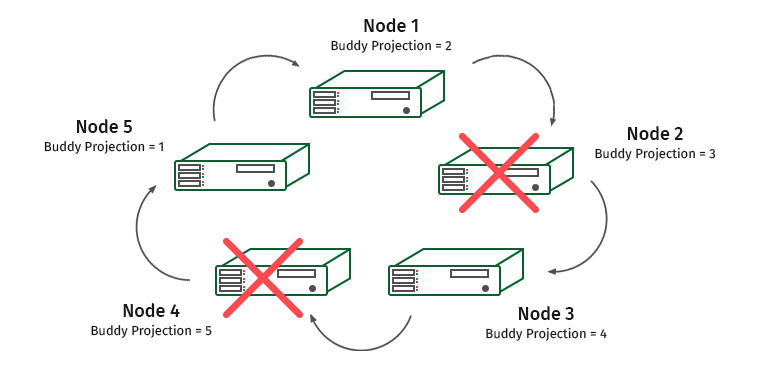
Нода 3 содержит проекцию ноды 4, и ноды 1 и 3 будут перегружены.
Усложняем задачу. K-Safety = 2, отключим две соседние ноды.

Здесь будут перегружены ноды 1 и 4 (нода 2 содержит проекцию ноды 1, а нода 3 содержит проекцию ноды 4).
В таких ситуациях движок системы распознает, что одна из нод не отвечает, и нагрузка перекладывается на соседнюю ноду. Она будет использоваться, пока нода снова не восстановится. Как только это происходит, нагрузка и данные перераспределяются обратно. Как только мы теряем больше половины кластера или ноды, содержащие все копии каких-то данных, кластер встает.
В Vertica есть области хранения данных, оптимизированные для записи, области, оптимизированные для чтения, и механизм Tuple Mover, который обеспечивает перетекание данных из первой области во вторую.
При использовании операции COPY, INSERT, UPDATE мы автоматически попадаем в WOS (Write Optimized Store) — область, где данные не оптимизированы для чтения и сортируются только при запросе, хранятся без сжатия или индексирования. Если объемы данных слишком велики для области WOS, то с помощью дополнительной инструкции DIRECT их стоит писать сразу в ROS. Иначе WOS будет переполнен, и у нас случится сбой.
По истечении заданного в настройках времени данные из WOS перетекают в ROS (Read Optimized Store) — оптимизированную, ориентированную на чтение структуру дискового хранилища. В ROS хранится основная часть данных, здесь она сортируется и сжимается. Данные в ROS разделены на контейнеры хранения. Контейнер представляет собой набор строк, созданных операторами трансляции (COPY DIRECT), и хранится в определенной группе файлов.
Вне зависимости от того, куда записаны данные — в WOS или в ROS — они доступны сразу. Но из WOS чтение идет медленнее, потому что данные там не сгруппированы.

Tuple Mover — это инструмент-уборщик, который выполняет две операции:
Если мы читаем строки, то, например, для выполнения команды
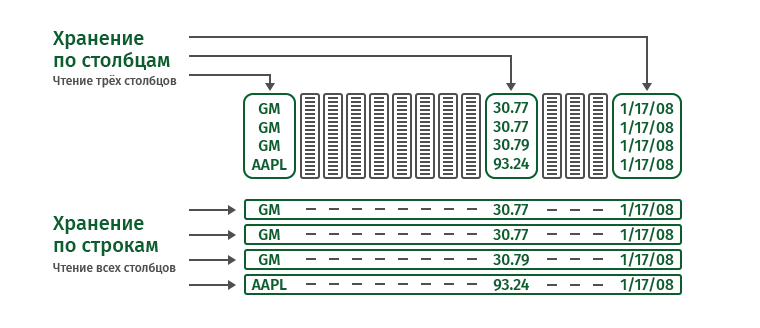
нам придется читать всю таблицу. Это огромный объем информации. В данном случае колоночный подход выгоднее. Он позволяет считать только три нужных нам столбца, экономя память и время.
Чтобы в работе не возникало проблем, пользователя нужно немного ограничивать. Всегда есть вероятность, что пользователь напишет тяжелый запрос, который сожрет все ресурсы. По умолчанию в Vertica значительную часть занимает область General, и помимо этого выделяются отдельные области под Tuple Mover, WOS и системные процессы (восстановление и прочее).

Попробуем поделить эти ресурсы. Создаем области для писателей, для читателей и для медленных запросов с низким приоритетом.
Если посмотреть системные таблицы, в которых хранятся наши ресурсы — ресурсные пулы — то мы увидим множество параметров, с помощью которых можно все отрегулировать более тонко. На старте не стоит в это углубляться, лучше просто ограничиться отсеканием памяти под определенные задачи. Когда наберетесь опыта и будете на 100% уверены, что делаете все правильно, можно будет поэкспериментировать.
К тонким настройкам можно отнести приоритет выполнения, конкурентные сессии, объем выделяемой памяти. И даже с процессорами мы можем кое-что поправить.Для работы с этими настройками нужна полная уверенность в правильности своих действий, так что лучше заручиться поддержкой бизнеса и иметь право на ошибку.
Ниже пример запроса, с помощью которого можно увидеть настройки пула General:
Vertica, как и все текущие инструменты, серьезно интегрирована с другими системами. Умеет хорошо работать с HDFS (Hadoop). В ранних версиях Vertica могла только загружать данные с HDFS определенных форматов, а сейчас умеет вообще все, работает со всеми форматами, например, ORC и Parquet. Умеет даже подключать файлы как внешние таблицы (external tables) и хранить свои данные в ROS контейнерах прямо на HDFS. В восьмой версии Vertica была проведена значительная оптимизация скорости работы с HDFS, каталога метаданных и парсинга этих форматов. Можно строить кластер Vertica прямо на Hadoop-кластере.
Начиная с версии 7.2 Vertica умеет работать с Apache Kafka — если кому-то нужен message broker.
В Vertica 8 появилась полная поддержка Spark. Есть возможность копировать данные из Spark в Vertica и обратно.
Vertica — хороший вариант для работы с большими данными, не требующий больших знаний на входе. Эта СУБД имеет широкие аналитические возможности. Из минусов — это решение не open source, но можно попробовать развернуть бесплатно с ограничением в 1 ТБ и три ноды — этого вполне хватит, чтобы понять, нужна вам Vertica или нет.

Общая информация
С 2000-х годов начали развиваться большие данные и потребовались движки, которые способны все это переварить. В ответ на это появился ряд предназначенных для этого колоночных СУБД — в том числе и Vertica.
Vertica не просто хранит свои данные в колонках, она делает это рационально, с высокой степенью сжатия, а также эффективно планирует запросы и быстро отдает данные. Информация, которая в классической строчной СУБД занимает около 1 ТБ дискового пространства, на Vertica займет порядка 200-300 Гб, тем самым мы получаем хорошую экономию на дисках.
Vertica изначально проектировалась именно как колоночная СУБД. Другие базы в основном только стараются имитировать различные колоночные механизмы, но у них это не всегда хорошо получается, поскольку движок все равно создан чтобы обрабатывать строки. Как правило, подражатели просто транспонируют таблицу и далее обрабатывают привычным строчным механизмом.
Vertica отказоустойчива, в ней нет управляющей ноды — все ноды равны. Если с одним из серверов в кластере возникают проблемы, то данные мы все равно получим. Очень часто получить данные вовремя бывает критично для бизнес-заказчиков, особенно в период, когда закрывается отчетность и нужно предоставлять информацию в финансовые органы.
Области применения
Vertica — это в первую очередь аналитическое хранилище данных. В нее не стоит писать мелкими транзакциями, не стоит прикручивать ее к какому-то сайту и т.п. Vertica следует рассматривать как некий batch-слой, куда стоит погружать данные большими пачками. При необходимости Vertica очень быстро готова эти данные отдать — запросы на миллионы строк выполняются за секунды.
Где это может быть полезно? Возьмем для примера телекоммуникационную компанию. Vertica может использоваться в ней для геоаналитики, развития сети, управления качеством, целевого маркетинга, изучения информации с контактных центров, управления оттоком клиентов и антифрод/антиспам-решений.

В других отраслях бизнеса все примерно так же — для получения прибыли важна своевременная и достоверная аналитика. В торговле, например, все пытаются как-то персонализировать клиентов, распространяют для этого дисконтные карты, собирают данные о том, где что и когда человек покупал и т.п. Анализируя массивы информации со всех этих каналов, мы можем ее сопоставлять, строить модели и принимать решения, ведущие к росту прибыли.
Входной порог
Сегодня любой работодатель требует, чтобы аналитик представлял, что такое SQL. Если вы знаете ANSI SQL, то вас можно назвать уверенным пользователем Vertica. Если вы можете строить модели на Python и R, то вы просто «массажист» данных. Если освоили Linux и имеете базовые знания по администрированию Vertica, то можете работать администратором. В целом, входной порог в Vertica невысокий, но, разумеется, все нюансы можно узнать, только набивая руку в процессе эксплуатации.
Аппаратная архитектура
Рассмотрим Vertica на уровне кластера. Эта СУБД обеспечивает массивно-параллельную обработку данных (МРР) в распределенной вычислительной архитектуре — «shared-nothing» — где, в принципе, любая нода готова подхватить функции любой другой ноды. Основные свойства:
- отсутствует единая точка отказа,
- каждый узел независим и самостоятелен,
- отсутствует единая для всей системы точка подключения,
- узлы инфраструктуры дублируются,
- данные на узлах кластера автоматически копируются.
Кластер без проблем линейно масштабируется. Мы просто ставим сервера в полку и подключаем их через графический интерфейс. Помимо серийных серверов, возможно развертывание на виртуальные машины. Что можно добиться с помощью расширения?
- Увеличения объема для новых данных
- Увеличение максимальной рабочей нагрузки
- Повышение отказоустойчивости. Чем больше нод в кластере, тем меньше вероятность выхода кластера из строя из-за отказа, а следовательно, тем ближе мы к обеспечению доступности 24/7.
Но нужно кое-что учесть. Периодически ноды нужно вынимать из кластера для обслуживания. Еще довольно распространенный кейс в крупных организация — сервера сходят с гарантии и переходят из продуктивной в какую-нибудь тестовую среду. На их место встают новые, которые находятся на гарантии производителя. По итогам всех этих операций нужно выполнять ребалансировку. Это процесс, когда данные перераспределяются между нодами — соответственно перераспределяется рабочая нагрузка. Это требовательный к ресурсам процесс, и на кластерах с большим объемом данных он может сильно снизить производительность. Чтобы этого избежать, нужно выбрать сервисное окно — время, когда нагрузка минимальна, и в этом случае пользователи этого не заметят.
Проекции
Для понимания, как хранятся данные в Vertica, требуется разобраться с одним из основных понятий — проекцией.
Логические единицы хранения информации — это схемы, таблицы и представления. Физические единицы — это проекции. Проекции бывают нескольких типов:
- суперпроекции (Superprojection),
- запрос-ориентированные проекции (Query-Specific Projections),
- агрегированные проекции (Aggregate Projections).
При создании любой таблицы автоматически создается суперпроекция, которая содержит все колонки нашей таблицы. Если нужно ускорить какой-то из регулярных процессов, мы можем создать специальную запрос-ориентированную проекцию, которая будет содержать, допустим, 3 столбца из 10.
Для ускорения предназначен и третий тип — агрегированные проекции. Не буду вдаваться в их подклассы — это не очень интересно. Сразу хочу предупредить, что постоянно решать свои проблемы с выполнением запросов через создание новых проекций не стоит. В конечном итоге кластер начнет тормозить.
Создавая проекции, нужно оценивать, хватает ли нашим запросам суперпроекций. Если мы все-таки хотим поэкспериментировать, добавляем строго по одной новой проекции. При возникновении проблем так будет проще найти первопричину. Для больших таблиц следует создавать сегментированную проекцию. Она разбивается на сегменты, которые распределяются по нескольким нодам, что повышает отказоустойчивость и минимизирует нагрузки на одну ноду. Если таблички маленькие, то лучше делать несегментированные проекции. Они полностью копируются на каждую ноду, и производительность таким образом увеличивается. Оговорюсь: в терминах Vertica «маленькая» таблица — это примерно 1 млн строк.
Отказоустойчивость
Отказоустойчивость в Vertica реализована при помощи механизма K-Safety. Он довольно простой с точки зрения описания, но сложный с точки зрения работы на уровне движка. Им можно управлять с помощью параметра K-Safety — он может иметь значение 0, 1 или 2. Этот параметр задает количество копий сегментированных проекционных данных.
Копии проекций называются buddy projections. Я попытался перевести это словосочетание через Яндекс-переводчик и получилось что-то вроде «проекции-кореша». Гугл предлагал варианты и интересней. Обычно данные проекции называют партнерскими или соседними, по их функциональному назначению. Это проекции, которые просто хранятся на соседних нодах и таким образом резервируются. У несегментированных проекций нет buddy projections — они копируются полностью.
Как это работает? Рассмотрим кластер из пяти машин. Пусть K-safety у нас равен 1.

Ноды пронумерованы, а под ними написаны партнерские проекции, которые хранятся на них. Предположим, у нас отключилась одна нода. Что будет?

Нода 1 содержит дружественную проекцию ноды 2. Поэтому на ноде 1 подрастет нагрузка, но работать кластер не перестанет. А теперь такая ситуация:
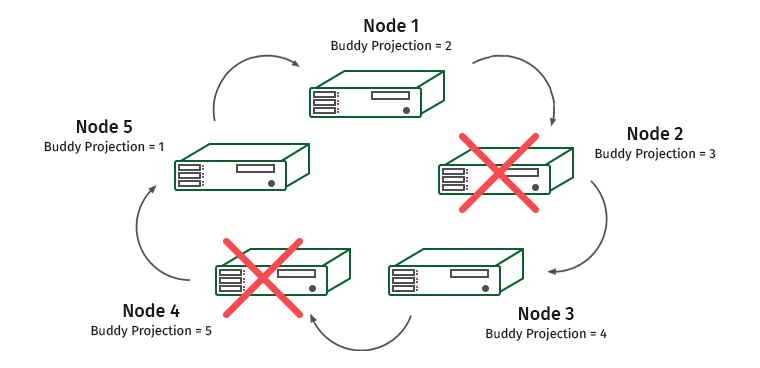
Нода 3 содержит проекцию ноды 4, и ноды 1 и 3 будут перегружены.
Усложняем задачу. K-Safety = 2, отключим две соседние ноды.
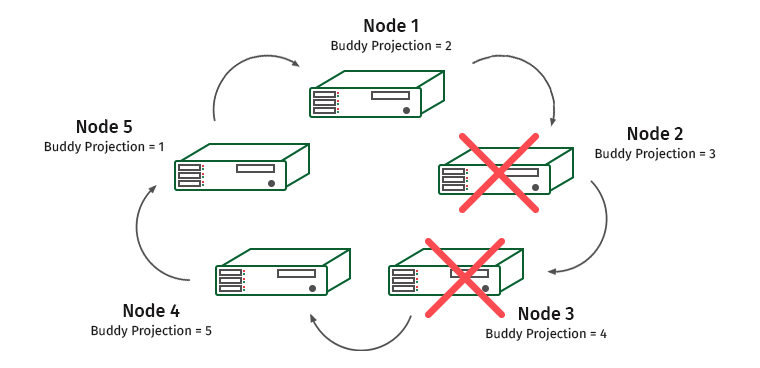
Здесь будут перегружены ноды 1 и 4 (нода 2 содержит проекцию ноды 1, а нода 3 содержит проекцию ноды 4).
В таких ситуациях движок системы распознает, что одна из нод не отвечает, и нагрузка перекладывается на соседнюю ноду. Она будет использоваться, пока нода снова не восстановится. Как только это происходит, нагрузка и данные перераспределяются обратно. Как только мы теряем больше половины кластера или ноды, содержащие все копии каких-то данных, кластер встает.
Логическое хранение данных
В Vertica есть области хранения данных, оптимизированные для записи, области, оптимизированные для чтения, и механизм Tuple Mover, который обеспечивает перетекание данных из первой области во вторую.
При использовании операции COPY, INSERT, UPDATE мы автоматически попадаем в WOS (Write Optimized Store) — область, где данные не оптимизированы для чтения и сортируются только при запросе, хранятся без сжатия или индексирования. Если объемы данных слишком велики для области WOS, то с помощью дополнительной инструкции DIRECT их стоит писать сразу в ROS. Иначе WOS будет переполнен, и у нас случится сбой.
По истечении заданного в настройках времени данные из WOS перетекают в ROS (Read Optimized Store) — оптимизированную, ориентированную на чтение структуру дискового хранилища. В ROS хранится основная часть данных, здесь она сортируется и сжимается. Данные в ROS разделены на контейнеры хранения. Контейнер представляет собой набор строк, созданных операторами трансляции (COPY DIRECT), и хранится в определенной группе файлов.
Вне зависимости от того, куда записаны данные — в WOS или в ROS — они доступны сразу. Но из WOS чтение идет медленнее, потому что данные там не сгруппированы.

Tuple Mover — это инструмент-уборщик, который выполняет две операции:
- Moveout — сжимает и сортирует данные в WOS, перемещает их в ROS и создает для них в ROS новые контейнеры.
- Mergeout — подметает за нами, когда мы используем DIRECT. Мы не всегда способны грузить столько информации, чтобы получались большие ROS-контейнеры. Поэтому он периодически объединяет небольшие контейнеры ROS в более крупные, очищает данные с пометкой на удаление, работая при этом в фоновом режиме (по времени, заданному в конфигурации).
В чем выгода колоночного хранения?
Если мы читаем строки, то, например, для выполнения команды
SELECT 1,11,15 from table1
нам придется читать всю таблицу. Это огромный объем информации. В данном случае колоночный подход выгоднее. Он позволяет считать только три нужных нам столбца, экономя память и время.

Распределение ресурсов
Чтобы в работе не возникало проблем, пользователя нужно немного ограничивать. Всегда есть вероятность, что пользователь напишет тяжелый запрос, который сожрет все ресурсы. По умолчанию в Vertica значительную часть занимает область General, и помимо этого выделяются отдельные области под Tuple Mover, WOS и системные процессы (восстановление и прочее).
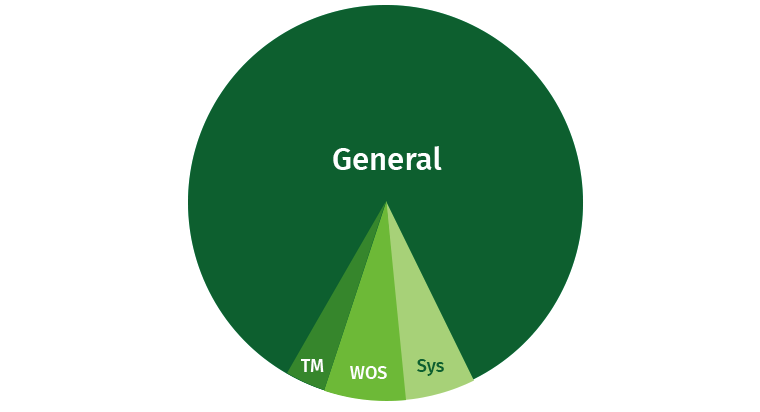
Попробуем поделить эти ресурсы. Создаем области для писателей, для читателей и для медленных запросов с низким приоритетом.

Если посмотреть системные таблицы, в которых хранятся наши ресурсы — ресурсные пулы — то мы увидим множество параметров, с помощью которых можно все отрегулировать более тонко. На старте не стоит в это углубляться, лучше просто ограничиться отсеканием памяти под определенные задачи. Когда наберетесь опыта и будете на 100% уверены, что делаете все правильно, можно будет поэкспериментировать.
К тонким настройкам можно отнести приоритет выполнения, конкурентные сессии, объем выделяемой памяти. И даже с процессорами мы можем кое-что поправить.Для работы с этими настройками нужна полная уверенность в правильности своих действий, так что лучше заручиться поддержкой бизнеса и иметь право на ошибку.
Ниже пример запроса, с помощью которого можно увидеть настройки пула General:
dbadmin => select * FROM resource_pools WHERE NAME = 'general';
-[ RECORD 1 ]------------+---------------
pool_id | 45035996273721212
name | general
is_internal | t
memorysize |
maxmemorysize | 30G
executionparallelism | AUTO
priority | 0
runtimepriority | MEDIUM
runtimeprioritythreshold | 2
queuetimeout | 0:05
plannedconcurrency | 10
maxconcurrency | 20
runtimecap |
singleinitiator | f
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto | ANSI SQL и другие фичи
- Vertica позволяет писать на SQL-99 — поддерживается весь функционал.
- Verica имеет большие аналитические возможности — в поставку входят даже инструменты машинного обучения
- Vertica умеет индексировать тексты
- Vertica обрабатывает полуструктурированные данные
Интеграция
Vertica, как и все текущие инструменты, серьезно интегрирована с другими системами. Умеет хорошо работать с HDFS (Hadoop). В ранних версиях Vertica могла только загружать данные с HDFS определенных форматов, а сейчас умеет вообще все, работает со всеми форматами, например, ORC и Parquet. Умеет даже подключать файлы как внешние таблицы (external tables) и хранить свои данные в ROS контейнерах прямо на HDFS. В восьмой версии Vertica была проведена значительная оптимизация скорости работы с HDFS, каталога метаданных и парсинга этих форматов. Можно строить кластер Vertica прямо на Hadoop-кластере.
Начиная с версии 7.2 Vertica умеет работать с Apache Kafka — если кому-то нужен message broker.
В Vertica 8 появилась полная поддержка Spark. Есть возможность копировать данные из Spark в Vertica и обратно.
Вывод
Vertica — хороший вариант для работы с большими данными, не требующий больших знаний на входе. Эта СУБД имеет широкие аналитические возможности. Из минусов — это решение не open source, но можно попробовать развернуть бесплатно с ограничением в 1 ТБ и три ноды — этого вполне хватит, чтобы понять, нужна вам Vertica или нет.
