
На хабре уже есть множество статей, посвященных распознаванию образов методами обучения машин, таких как нейронные сети, машины опорных векторов, случайные деревья. Все они требуют значительного количества примеров для обучения и настройки параметров. Создание обучающей и тестовой баз изображений адекватного объема для них — весьма нетривиальная задача. Причем речь идет не о технических трудностях сбора и хранения миллиона изображений, а об извечной ситуации, когда на первом этапе разработки системы у вас есть полторы картинки. Кроме того, следует понимать, что состав обучающей базы может влиять на качество получающейся системы распознавания больше, чем все остальные факторы. Несмотря на это, в большинстве статей этот немаловажный этап разработки полностью опущен.
Если вам интересно узнать про все это — добро пожаловать под кат.
Перед созданием базы примеров изображений и обучением нейронной сети необходимо конкретизировать техническую задачу. Понятно, что распознавание рукописного текста, эмоций человеческого лица или определение местоположения по фотографии — совершенно различные задачи. Также ясно, что на архитектуру используемой нейронной сети повлияет выбор платформы: в “облаке”, на ПК, на мобильном устройстве — доступные вычислительные ресурсы различаются на порядки.
Дальше становится интереснее. Распознавание изображений, полученных с фотокамер высокого разрешения, или размытых изображений с веб камеры без автофокуса потребуют совершенно различных данных для обучения, тестирования и валидации. Об этом нам намекают “теоремы об отсутствии бесплатных данных”. Именно поэтому свободно распространяемые обучающие базы изображений (например, [1, 2, 3]), отлично подходят для академических исследований, но почти всегда неприменимы в реальных задачах вследствие своей «обобщенности».
Чем точнее обучающая выборка аппроксимирует генеральную совокупность изображений, которые будут поступать на вход вашей системе, тем выше будет предельно достижимое качество результата. Получается, что правильно составленная обучающая выборка — это и есть предельно конкретизированное техническое задание! Например, если мы хотим распознавать печатные символы на фотографии, сделанной мобильным устройством, то база примеров должна содержать фотографии документов из разных источников с различным освещением, сделанные с разных моделей телефонов и камер. Все это усложняет сбор необходимого числа примеров для обучения распознавателя.
Рассмотрим теперь несколько возможных способов подготовки выборки изображений для создания системы распознавания.
Создание обучающих примеров из естественных изображений.
Примеры для обучения из естественных изображений создаются на основе реальных данных. Их создание состоит из следующих этапов:
- Сбор графических данных (фотографирование интересующих объектов, снятие видеопотока с камеры, выделение части изображения на интернет странице).
- Фильтрация — проверка изображений на ряд требований: достаточный уровень освещенности объектов на них, наличие необходимого объекта и т. д.
- Подготовка инструментария для разметки (написание собственного или оптимизация готового).
- Разметка (выделение четырехугольников, необходимых знакомест, интересующих областей изображения).
- Присвоение каждому изображению метки (буква или название объекта на изображении).
Эти операции требуют значительных затрат рабочего времени, и, соответственно, подобный способ создания обучающий базы весьма дорог. К тому же собирать данные необходимо в различных условиях — освещение, модели телефонов, камер, с которых происходит съемка, различные источники документов (типографии), и т. д.
Все это усложняет сбор необходимого числа примеров для обучения распознавателя. С другой стороны, по результатам обучения системы на таких данных можно судить об её эффективности в реальных условиях.
Создание обучающих примеров из искусственных изображений.
Другой подход к созданию обучающих данных — их искусственная генерация. Можно взять несколько шаблонов / «идеальных» примеров (например, наборов шрифтов) и с помощью различных искажений создать необходимое число примеров для обучения. Можно использовать следующие искажения:
- Геометрические (афинные, проективные, ...).
- Яркостные/цветовые.
- Замена фона.
- Искажения, характерные для решаемой задачи: блики, шумы, размытие и т. д.
Примеры искажений изображений для задачи распознавания символов:
Сдвиги:
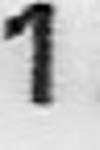
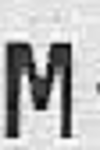
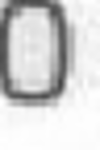

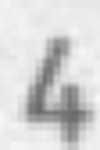

Повороты:





Дополнительные линии на изображениях:






Блики:








Дефокус:






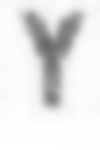
Сжатия и растяжения вдоль осей:



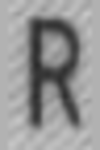
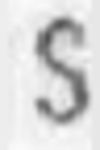
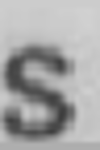
Генерировать искажения можно с помощью библиотек для работы с изображениями [1, 2, 3] или специальных программ, которые позволяют создавать целые искусственные документы или объекты.
Такой подход не требует большого количества человеческих ресурсов и сравнительно дешев, поскольку не требует разметки и сбора данных — весь процесс создания базы изображений определяется выбором алгоритма и параметров.
Главным минусом подобного метода является слабая связь качества работы системы на сгенерированных данных с качеством работы в реальных условиях. Кроме того, метод требует больших вычислительных мощностей для создания необходимого числа примеров. Выбор искажений, используемых при создания базы для конкретной задачи, также составляет определенную сложность.
Ниже приведен пример создания полностью искусственной базы.
Первоначальный набор изображений символов шрифта:
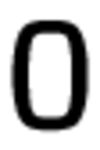

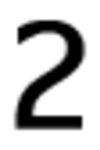
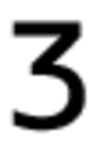
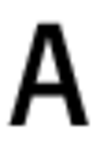
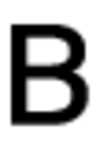

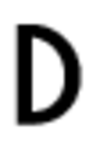
Примеры фонов:




Примеры изображений без искажений:





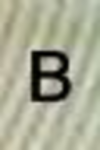

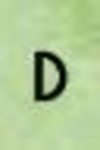
Добавление небольших искажений:

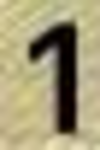

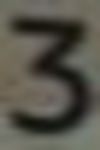



Создание искусственных обучающих примеров, сгенерированных на основе естественных изображений.
Логичным продолжением предыдущего метода является генерация искусственных примеров с использованием реальных данных вместо шаблонов и первоначальных «идеальных» примеров. Добавляя искажения, можно добиться существенного улучшения работы системы распознавания. Для того чтобы понять, какие именно искажения следует применять, часть реальных данных стоит использовать для валидации. По ним можно оценивать наиболее часто встречающиеся типы ошибок и добавлять изображения с соответствующими искажениями в обучающую базу.
Такой способ создания обучающих примеров содержит в себе преимущества обоих вышеизложенных подходов: он не требует высоких материальных затрат и позволяет создать большое число примеров, необходимых для обучения распознавателя.
Сложности может вызвать аккуратный подбор параметров «раздутия» обучающей выборки из первоначальных примеров. С одной стороны число примеров должно быть достаточным для того, чтобы нейронная сеть научилась распознавать даже зашумленные примеры, с другой стороны — необходимо, чтобы при этом не падало качество на других типах сложных изображений
Сравнение качества обучения нейронной сети на примерах из естественных изображений, полностью искусственных и сгенерированных с использованием естественных.
Попробуем создать нейронную сеть на изображениях символов MRZ. Машинно-читаемой зоной (MRZ — Machine-Readable Zone) называют часть документа, удостоверяющего личность, выполненную согласно международным рекомендациям, закрепленным в документе Doc 9303 — Machine Readable Travel Documents Международной Организации Гражданской Авиации. Подробнее про проблемы распознавания MRZ можно прочитать в другой нашей статье.
Пример MRZ:

MRZ содержит 88 символов. Будем использовать 2 характеристики качества работы системы:
- процент ошибочно распознанных символов.
- процент полностью правильно распознанных зон (MRZ считается полностью правильно распознанной, если все символы в ней распознаны правильно).
В дальнейшем нейронную сеть предполагается использовать на мобильных устройствах, где вычислительные мощности ограничены, поэтому используемые сетки будут иметь относительно небольшое число слоев и весов.
Для экспериментов было собрано 800'000 примеров символов, которые были разбиты на 3 группы: 200'000 примеров на обучение, 300'000 примеров на валидацию и 300'000 примеров на тестирование. Подобное разбиение неестественно, поскольку большая часть примеров “пропадает впустую” (валидация и тестирование), но позволяет наилучшим образом показать преимущества и недостатки различных методов.
Для тестовой выборки распределение примеров различных классов близко к реальному и выглядит следующим образом:
Название класса (символ): число примеров
0: 22416 1: 17602 2: 13746 3: 8115 4: 8587 5: 9383 6: 8697 7: 8082 8: 9734 9: 8847
<: 110438 A: 12022 B: 1834 C: 3891 D: 2952 E: 7349 F: 3282 G: 2169 H: 3309 I: 6737
J: 934 K: 2702 L: 4989 M: 6244 N: 7897 O: 4515 P: 4944 Q: 109 R: 7717 S: 5499 T: 3730
U: 4224 V: 3117 W: 744 X: 331 Y: 1834 Z: 1246
При обучении только на естественных примерах средняя посимвольная величина ошибки по 25 экспериментам составила 0,25%, т.е. общее число неправильно распознанных символов составило 750 изображений из 300000. Для практического применения подобное качество неприемлемо, поскольку число правильно распознанных зон в таком случае составляет 80%.
Рассмотрим наиболее частые типы ошибок, которые совершает нейронная сеть.
Примеры неправильно распознанных изображений:



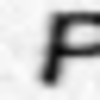
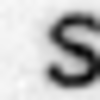


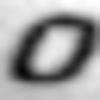
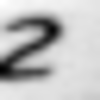
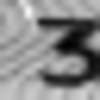




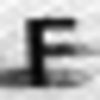

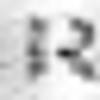
Можно выделить следующие типы ошибок:
- Ошибки на нецентрированных изображениях.
- Ошибки на повернутых изображениях.
- Ошибки на изображениях с линиями.
- Ошибки на изображениях с бликами.
- Ошибки в сложных случаях.
Таблица наиболее частых ошибок:
(формат Оригинальный символ, число ошибок, с какими символами сеть чаще всего путает данный символ и сколько раз)
Оригинальный символ: ’0’, число ошибок: 437
’O’: 419, ’U’: 5, ’J’: 4, ’2’: 2, ’1’: 1
Оригинальный символ: ’<’, число ошибок: 71
’2’: 29, ’K’: 6, ’P’: 6, ’4’: 4, ’6’: 4
Оригинальный символ: ’8’, число ошибок: 35
’B’: 10, ’6’: 10, ’D’: 4, ’E’: 2, ’M’: 2
Оригинальный символ: ’O’, число ошибок: 20
’0’: 19, ’Q’: 1
Оригинальный символ: ’4’, число ошибок: 19
’6’: 5, ’N’: 3, ’¡’: 2, ’A’: 1, ’D’: 1
Оригинальный символ: ’6’, число ошибок: 18
’G’: 4, ’S’: 4, ’D’: 3, ’O’: 2, ’4’: 2
Оригинальный символ: ’1’, число ошибок: 17
’T’: 6, ’Y’: 5, ’7’: 2, ’3’: 1, ’6’: 1
Оригинальный символ: ’L’, число ошибок: 14
’I’: 9, ’4’: 4, ’C’: 1
Оригинальный символ: ’M’, число ошибок: 14
’H’: 7, ’P’: 5, ’3’: 1, ’N’: 1
Оригинальный символ: ’E’, число ошибок: 14
’C’: 5, ’I’: 3, ’B’: 2, ’F’: 2, ’A’: 1
Будем постепенно добавлять различные виды искажений, соответствующие наиболее распространенным типам ошибок, в обучающую выборку. Число добавленных «искаженных» изображений необходимо варьировать и подбирать, основываясь на обратном отклике валидационной выборки.
Действуем по следующей схеме:
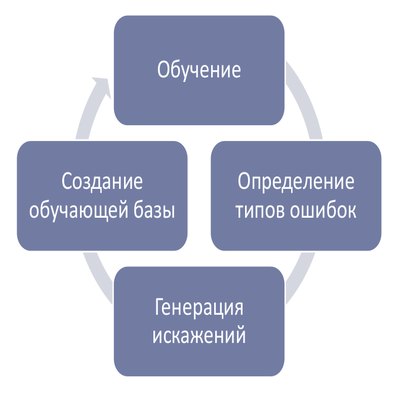
Например, для данной задачи было сделано следующее:
- Добавление искажения типа “сдвиг”, соответствующего ошибке на “нецентрированных” изображения.
- Проведение серии экспериментов: обучение нескольких нейронных сетей.
- Оценка качества на тестовой выборке. Качество распознавания MRZ увеличилось на 9%.
- Анализ наиболее частых ошибок распознавания на валидационной выборке.
- Добавление изображений с дополнительными линиями в обучающую базу.
- Снова проведение серии экспериментов.
- Тестирование. Качество распознавания MRZ на тестовой выборке возросло на 3.5%.
Подобные “итерации” можно проводить многократно — до достижения необходимого качества или до тех пор, пока качество не перестает расти.
Таким способом, было получено качество распознавания в 94,5% правильно распознанных зон. Используя постобработку (марковские модели, конечные автоматы, N-граммные и словарные методы и т.д.), можно получить дальнейшее увеличения качества.
При использовании обучения только на искусственных данных в рассматриваемой задаче удалось достичь только качества в 81,72% правильно распознанных зон, при этом основная проблема — сложность подбора параметров искажений.
| Тип данных для обучения | Процент правильно распознанных MRZ | Посимвольная ошибка |
|---|---|---|
| Естественные изображения | 80,78% | 0,253% |
| Естественные изображения + изображения со сдвигами | 89,68% | 0.13% |
| +изображения с дополнительными линиями | 93,19% | 0.1% |
| +повернутые изображения | 95,50% | 0.055% |
| Искусственные изображения | 78,53% | 0.29% |
Заключение.
В заключение хотелось бы отметить, что в каждом конкретном случае необходимо выбирать свой алгоритм получения обучающих данных. Если исходные данные совсем отсутствуют — придется генерировать выборку искусственно. Если реальные данные легко получить — можно использовать обучающую выборку, созданную только из них. А если реальных данных не очень много, или присутствуют редко встречающиеся ошибки, оптимальный способ — раздутие набора естественных изображений. На нашем опыте этот последний случай встречается наиболее часто.
