В первом посте об аналитической системе Sports.ru и Tribuna.com мы рассказали о том, как используем нашу инфраструктуру в повседневной жизни: наполняем контентом рекомендательную систему, наблюдаем за бизнес-метриками, ищем среди пользовательского контента бриллианты, находим ответы на вопросы “Как работает лучше?” и “Почему?”, нарезаем пользователей для почтовых рассылок и строим красивые отчеты о деятельности компании. Всю техническую часть повествования мы скромно спрятали за этой схемой:
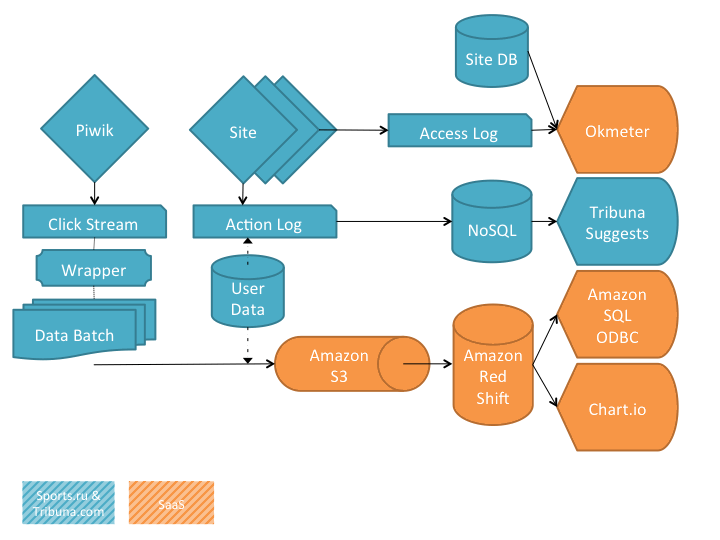
Читатели законно потребовали продолжить повествование со смешными котиками, а olegbunin пригласил рассказать о всем, что было скрыто, на РИТ++. Что ж, изложим некоторые технические детали – в продолжении веселого поста.
По мере того как Sports.ru эволюционировал из новостного сайта в полноценную социальную сеть, к привычным аналитическим инструментам типа Google Analytics и Яндекс.Метрика добавлялись новые сервисы для анализа данных (similarweb, appanie, flurry и пр.). Чтобы не разрываться между десятком разных приложений и иметь общую систему координат для измерения метрик, мы решили собрать в одном хранилище все данные о трафике всех наших сайтов, мобильных приложений и социальных потоков.
Нам нужно было получить единый сервис для работы с разными данными, который позволял бы журналистам следить за популярностью текстов и авторов, сотрудникам социальной редакции – быстро реагировать на возникающие тренды, менеджерам продукта – оценивать вовлеченность пользователей в наши сервисы, получать результаты экспериментов при запуске нового функционала и т.д. Мы решили хранить собираемые данные так, чтобы с ними можно было легко работать, представлять в виде, удобном для самых разных пользователей: и для журналистов, и для сисадминов.
Что нам нужно было считать? Посещаемость сайтов и мобильных приложений, активность зарегистрированных пользователей (комментарии, рейтинги, посты, подписки, регистрации и т.д.), количество подписчиков на наши потоки в соцсетях, число установок мобильных приложений. Так как месячный объем трафика приближался к 250 миллионам хитов и продолжал расти, мы решили не использовать обычные реляционные СУБД, а выбрать технологию, которая могла бы легко масштабироваться с ростом объема данных. Нам хотелось иметь максимально простой и удобный доступ к данным, например, в виде SQL-запросов. В итоге мы остановились на SaaS-хранилище Redshift, которое был запущено в экосистеме Amazon Web Services в начале 2013 года.

Redshift – это распределенная колоночная СУБД с некоторыми особенностями, вроде отсутствия ограничений целостности типа внешних ключей или уникальности значений поля. Колоночные СУБД хранят записи таким образом, чтобы запросы с группировками и расчетом агрегатов по большому числу строк работали максимально быстро. При этом выборка всех полей одной записи по ключу (select * from table where id=N), а также операции изменения или добавления по одной записи могут работать дольше, чем в обычных базах данных. Подробнее про устройство колоночных СУБД можно почитать в этом посте.
Redshift подкупил нас простотой доступа к данным (с ним можно работать как с обычным PostgreSQL), легкостью масштабирования (с ростом объема данных новые сервера добавляются в пару кликов, все данные перераспределяются автоматически) и низкой стоимостью внедрения (по сравнению, например, со связкой Apache Hadoop + Hive). В самом начале, к слову, мы думали о своем Hadoop-кластере, но отказались от этой идеи, чем ограничили себя и потеряли возможность создания на нашем хранилище персонализированных Realtime-рекомендаций, использование Apache Mahout и вообще запуск каких-то распределенных алгоритмов, которые нельзя описать в SQL.Не очень-то и хотелось.
Для хранения данных о просмотрах и событиях на страницах мы используем клиентскую часть опенсорсного счетчика Piwik, состоящего из javascript-трекера и бекендовой части на PHP/MySQL, которую мы выкинули за ненадобностью. Счетчик асинхронно шлет запросы на сервера с Nginx, где они пишутся в стандартные логи. Код счетчика выглядит примерно так:
Запросы от счетчика содержат все необходимые данные вроде адреса страницы, User-Agent, Referer, источника перехода, даты предыдущего визита, уникального ID посетителя из Cookie и так далее. К каждому запросу добавляется идентификатор пользователя (если известно), по которому мы можем совмещать данные о просмотрах с данными об активности пользователя, которые накапливаются в БД сайта (комментарии, посты, плюсы-минусы). Кроме того, nginx дописывает в логи информацию о географическом положении посетителя (maxmind + ngx_http_geoip_module).
Для записи в Amazon Redshift данные приводятся к CSV-подобному виду, отправляются в Amazon S3, а при желании, разбиваются на несколько частей для быстроты загрузки. Парсинг лога делается простым скриптом, который за один проход выбирает нужные данные (см. выше) и делает простые преобразования вроде перевода User-Agent в пару Browser/OS.
Так как каждый запрос от счетчика содержит в себе уникальный ID посетителя и время последнего посещения сайта, на этапе подготовки данных нет необходимости вычислять пользовательские сессии. Более того, данные о просмотрах страниц из одной и той же сессии могут быть записаны на разных серверах счетчика, поэтому хиты в сессии склеиваются уже внутри Redshift. Таким образом мы собираем в нашем хранилище базовые метрики вроде объема показов (инвентарь) или количество уникальных пользователей (аудитория) по любым срезам: раздел сайта, источник, браузер и т.д.
В большинстве случаев при анализе трафика нет необходимости узнавать что-то про конкретного посетителя или про одну из его сессий, а требуются суммарные или усредненные значения вроде количества уникальных посетителей за определенный период или среднего количества просмотров на сессию. Поэтому нет смысла проводить анализ непосредственно сырого кликстрима, который занимает очень много места, а запросы к нему выполняются не очень быстро.
Мы упаковываем собираемые данные в агрегаты, удобные для последующего анализа, например, всю пользовательскую сессию, состоящую обычно из нескольких хитов, мы компонуем в одну запись, в которой отражается основная информация об этом посещении: длительность и число просмотров в сессии, источник перехода и другие данные визита:
Из этих данных можно собирать агрегаторы следующего уровня:
Работа с конечными агрегатами происходит намного быстрее, чем с сырыми данными: для получения информации об инвентаре нужно всего лишь взять суммарное число просмотров всех сессий, а для оценки аудитории потребуется посчитать количество уникальных ID посетителей из сжатого в 20 раз (по сравнению с сырым кликстримом) массива данных. Для измерения охвата в каком-то конкретном разделе сайта мы создаем отдельный профиль (если говорить в терминологии GA) в виде таблицы и предвычисляем в этот профиль только те данные о сессиях, которые соответствуют условиям выборки:
Группировка хитов кликстрима в сессии производится SQL-запросом раз в сутки и занимает несколько секунд. Кроме агрегации данных по визитам, мы также считаем информацию об активности пользователей по дням, неделям и месяцам, чтобы такие данные были мгновенно доступны для соответствующих отчетов. Мы храним в Redshift кликстрим за последний месяц, чтобы можно было делать произвольные запросы по любым срезам, а также иметь свежие данные за последний час.
Мы не сэмплируем исходные данные: собираем информацию о каждом показе страниц, поэтому у нас всегда есть возможность посчитать статистику по любой странице в любом измерении, даже если такая страница собрала всего 10 хитов за месяц. Старые данные кликстрима (старше месяца) мы храним в бэкап-файлах и можем импортировать их в Redshift в любой момент.
Чтобы иметь возможность работать одновременно с данными о просмотрах страниц и о действиях пользователей (плюсы к постам блогов, комментарии, управление командам в фэнтези-турнирах и т.д.) мы импортируем из БД сайта в Redshift часть пользовательских данных. При этом в Redshift не переносятся полные тексты постов или новостей, а также персональные данные (email, имена, логины, пароли).
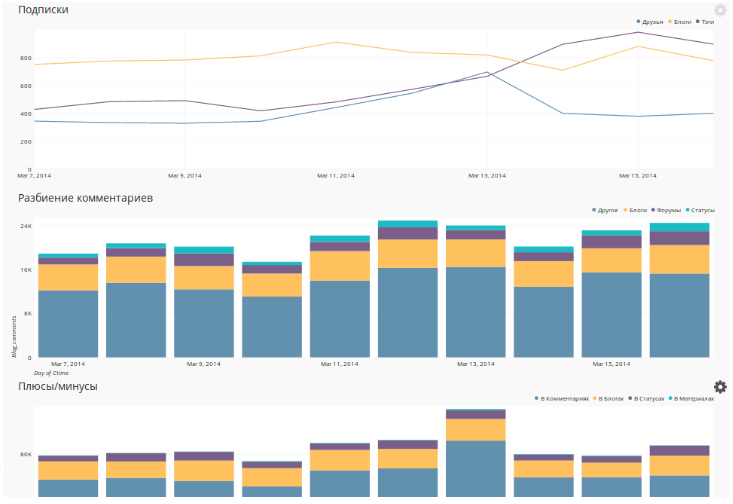
Данные об активности пользователей агрегируются по дням, неделям и месяцам, чтобы можно было быстро строить отчеты по вовлеченности. Например, так можно следить за количеством новых активных пользователей (которые плюсовали, комментировали, заводили команды в фэнтези-турнирах или совершали любые другие действия на сайте) по дням:
Чтобы получить для email-рассылки список активных болельщиков сборной Лесото из Саратова, которые заходили к нам не меньше двух раз за последнюю неделю и при этом посещали сайт больше трех недель подряд, можно выполнить такой запрос:
В итоге мы имеем возможность наблюдать за активностью пользователей в разных измерениях:
Мы собираем данные о наших подписчиках в Facebook, Twitter и Вконтакте раз в сутки и, как всю прочую статистику, складываем их в Redshift. Для получения данных о числе подписчиков в группах Facebook используется Graph API:
API ВКонтакте также позволяет получать данные о группах при помощи метода groups.getById:
Твиттер же после обновления своего API стал запрашивать авторизацию и ужесточил лимиты на частоту запросов, поэтому данные по нашим пятистам аккаунтам стали собираться слишком долго, поэтому для получения статистики по нашим потокам в Твиттере мы используем несколько аккаунтов и access token keys. Для работы с API Твиттера мы используем tweepy.
Проведя все импорты и преобразования, мы получаем в Redshift таблицу с динамикой изменения числа подписчиков по дням:
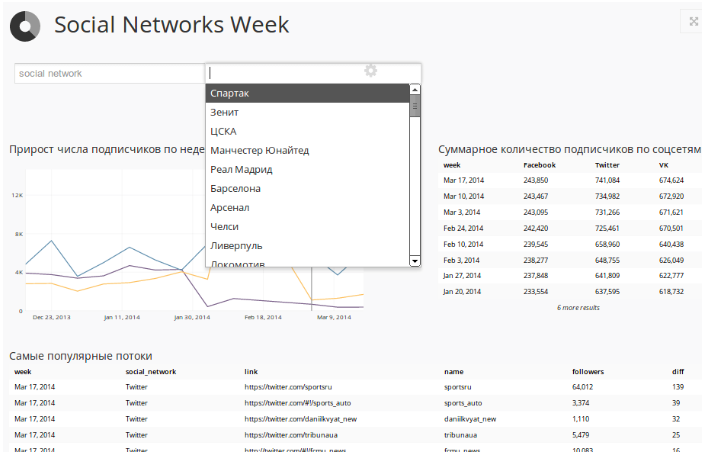
Над этими данными построена интерактивная панель в Chart.io, которая позволяет наблюдать за всеми нашими потоками в соцсетях:
Чтобы не тратить время на разработку графического интерфейса, мы решили использовать сторонний сервис для рисования графиков и таблиц Chart.io. Он имеет готовые коннекторы к Redshift, Google Analytics и другим источникам данных, поддерживает кеширование результатов запросов на своей стороне. Данные для графика могут запрашиваться SQL-запросом или при помощи удобного интерфейса, где можно выбрать метрики, измерения и фильтры.
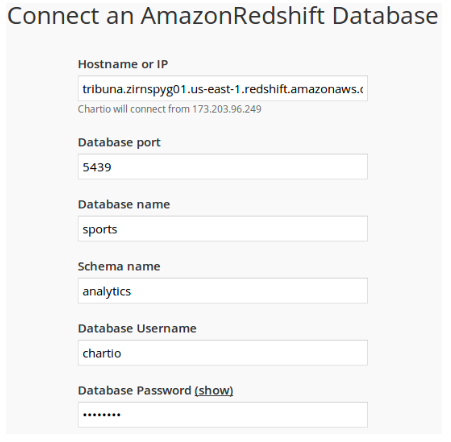
Для того, чтобы подключить Chartio к базе данных достаточно просто указать хост, порт и логин с паролем для подключения к Redshift, а в настройках Amazon Web Services нужно разрешить доступ к данным с серверов Chart.io:
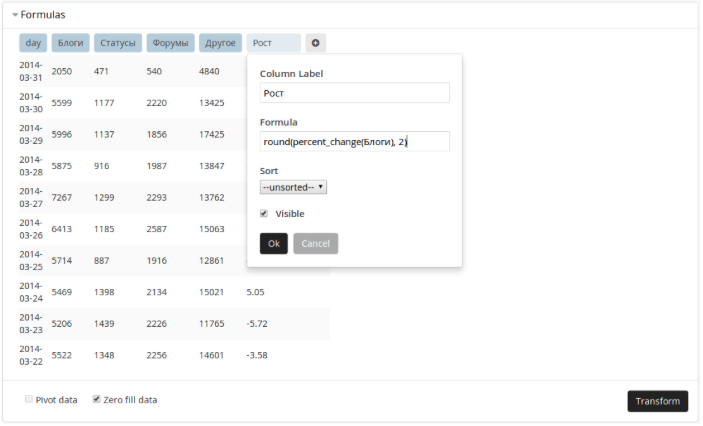
Для того чтобы построить график с разбиением числа комментариев по типам комментируемого контента и динамикой по дням достаточно указать поля, по которым будет производиться группировка данных, и условия выборки:

К выбранным данным можно применять простые математические функции:
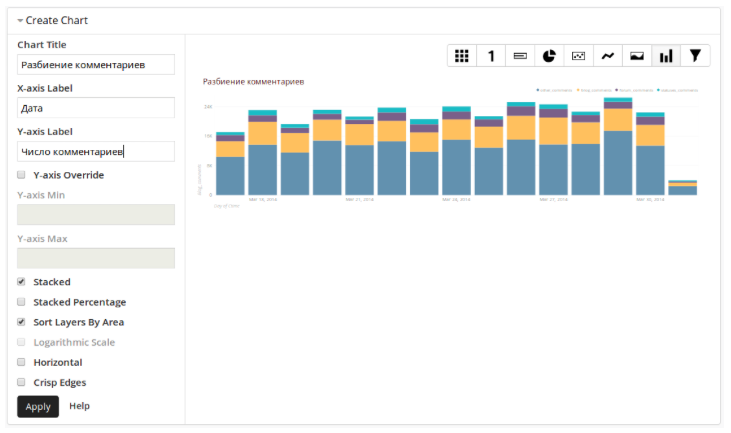
После этого нужно выбрать тип графика:
И интерактивная панель готова к использованию. Собственно, таким образом мы обложились всевозможными графиками и таблицами по большому спектру аналитических данных. Потратив меньше 3 месяцев на разработку, мы получили возможность делать произвольные запросы к данным из всех нужных источников, не ограничиваясь стандартными дашбордами Google Analytics.

В дополнение к базовым аналитическим инструментам сотрудников компании мы начали строить data-сервисы для наших пользователей. Например, мы с определенной точностью вычисляем интерес посетителя к тому или иному клубу, спортсмену, турниру и используем эти знания для формирования персонализированного меню сайта и ссылок на часто посещаемые страницы. Мы используем информацию о тегах материалов, которые читает посетитель, иногда обогащаем эти знания другими сигналами (переходы с фан-сайта клуба или из тематического объявления контекстной рекламы).

Рассказывать о нашей инфраструктуре обработки данных можно бесконечно. Мы продолжим обстоятельный разговор в рамках нашей секции на РИТ++, где мы подробнее расскажем об архитектуре, стоимости внедрения и владения, обсудим кампейнинг пользователей для почтовых рассылок, realtime-рекомендации контента, мониторинг бизнес-метрик, а также про поиск ботов среди пользователей и формирование клиентских профилей.
Читатели законно потребовали продолжить повествование со смешными котиками, а olegbunin пригласил рассказать о всем, что было скрыто, на РИТ++. Что ж, изложим некоторые технические детали – в продолжении веселого поста.
Хранилище
По мере того как Sports.ru эволюционировал из новостного сайта в полноценную социальную сеть, к привычным аналитическим инструментам типа Google Analytics и Яндекс.Метрика добавлялись новые сервисы для анализа данных (similarweb, appanie, flurry и пр.). Чтобы не разрываться между десятком разных приложений и иметь общую систему координат для измерения метрик, мы решили собрать в одном хранилище все данные о трафике всех наших сайтов, мобильных приложений и социальных потоков.
Нам нужно было получить единый сервис для работы с разными данными, который позволял бы журналистам следить за популярностью текстов и авторов, сотрудникам социальной редакции – быстро реагировать на возникающие тренды, менеджерам продукта – оценивать вовлеченность пользователей в наши сервисы, получать результаты экспериментов при запуске нового функционала и т.д. Мы решили хранить собираемые данные так, чтобы с ними можно было легко работать, представлять в виде, удобном для самых разных пользователей: и для журналистов, и для сисадминов.
Что нам нужно было считать? Посещаемость сайтов и мобильных приложений, активность зарегистрированных пользователей (комментарии, рейтинги, посты, подписки, регистрации и т.д.), количество подписчиков на наши потоки в соцсетях, число установок мобильных приложений. Так как месячный объем трафика приближался к 250 миллионам хитов и продолжал расти, мы решили не использовать обычные реляционные СУБД, а выбрать технологию, которая могла бы легко масштабироваться с ростом объема данных. Нам хотелось иметь максимально простой и удобный доступ к данным, например, в виде SQL-запросов. В итоге мы остановились на SaaS-хранилище Redshift, которое был запущено в экосистеме Amazon Web Services в начале 2013 года.

Управлять своим кластером Redshift можно через веб-интерфейс. Проще некуда
Redshift – это распределенная колоночная СУБД с некоторыми особенностями, вроде отсутствия ограничений целостности типа внешних ключей или уникальности значений поля. Колоночные СУБД хранят записи таким образом, чтобы запросы с группировками и расчетом агрегатов по большому числу строк работали максимально быстро. При этом выборка всех полей одной записи по ключу (select * from table where id=N), а также операции изменения или добавления по одной записи могут работать дольше, чем в обычных базах данных. Подробнее про устройство колоночных СУБД можно почитать в этом посте.
Redshift подкупил нас простотой доступа к данным (с ним можно работать как с обычным PostgreSQL), легкостью масштабирования (с ростом объема данных новые сервера добавляются в пару кликов, все данные перераспределяются автоматически) и низкой стоимостью внедрения (по сравнению, например, со связкой Apache Hadoop + Hive). В самом начале, к слову, мы думали о своем Hadoop-кластере, но отказались от этой идеи, чем ограничили себя и потеряли возможность создания на нашем хранилище персонализированных Realtime-рекомендаций, использование Apache Mahout и вообще запуск каких-то распределенных алгоритмов, которые нельзя описать в SQL.
Любые реляционные данные из канонической СУБД легко перекладываются в структуры Redshift
Сбор данных о трафике
Для хранения данных о просмотрах и событиях на страницах мы используем клиентскую часть опенсорсного счетчика Piwik, состоящего из javascript-трекера и бекендовой части на PHP/MySQL, которую мы выкинули за ненадобностью. Счетчик асинхронно шлет запросы на сервера с Nginx, где они пишутся в стандартные логи. Код счетчика выглядит примерно так:
<script type="text/javascript">
var _paq = _paq || [];
_paq.push(["enableLinkTracking"]);
_paq.push(["setTrackerUrl", "http://stat.sports.ru/p"]);
_paq.push(["setSiteId", "1"]);
_paq.push(["trackPageView"]);
(function(w,d,s,u,e,p){
e=d.createElement(s);
e.src=u;e.async=1;
p=d.getElementsByTagName(s)[0];
p.parentNode.insertBefore(e,p);})(window,document,'script', 'http://stat.sports.ru/piwik.js');
</script>
Очень похоже на код счетчика GA, не правда ли?
Запросы от счетчика содержат все необходимые данные вроде адреса страницы, User-Agent, Referer, источника перехода, даты предыдущего визита, уникального ID посетителя из Cookie и так далее. К каждому запросу добавляется идентификатор пользователя (если известно), по которому мы можем совмещать данные о просмотрах с данными об активности пользователя, которые накапливаются в БД сайта (комментарии, посты, плюсы-минусы). Кроме того, nginx дописывает в логи информацию о географическом положении посетителя (maxmind + ngx_http_geoip_module).
77.0.155.47 - - [31/Mar/2014:13:00:02 +0400] "GET /p?action_name=12 способов сделать Sports.ru удобнее лично для вас - Административный блог - Блоги - Sports.ru&idsite=1&rec=1&r=878036&h=13&m=1&s=54&url=http%3A%2F%2Fwww.sports.ru%2Ffootball%2F&_id=4cfacf46947ecc9a&_idts=1396089767&_idvc=7&_idn=0&_refts=0&_viewts=1396218890&suid=4582d0d1-0b34-4208-b154-413de9cd40ee&suida=JcHxFVM2AIp2Rdr1C6q0Ag&tsl=1396256514&pdf=1&qt=0&realp=0&wma=0&dir=0&fla=1&java=1&gears=0&ag=1&cookie=1&res=1920x1080>_ms=1072 HTTP/1.1" 200 35 "http://www.sports.ru/football/" "Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.154 Safari/537.36" "-" "RU" "Grozny"
188.232.174.186 - - [31/Mar/2014:13:00:02 +0400] "GET /p?action_name=_event&idsite=1&rec=1&r=109951&h=13&m=1&s=53&url=http://www.sports.ru/football/4283301.html&_id=45af8e84654389f1&_idts=1392628066&_idvc=2&_idn=0&_refts=1396256513&_viewts=1392628066&_ref=http://www.sports.ru/&suida=JcHxFVMB0V0b91OfKBpEAg&tsl=1396256513&cvar=%7B%221%22%3A%5B%22Authors-News%22%2C%22%D0%AE%D1%80%D0%B8%D0%B9%20%D0%91%D0%BE%D0%B3%D0%B4%D0%B0%D0%BD%D0%BE%D0%B2%22%5D%7D&pdf=0&qt=0&realp=0&wma=0&dir=0&fla=0&java=0&gears=0&ag=0&cookie=1&res=1280x800>_ms=117 HTTP/1.1" 200 35 "http://www.sports.ru/football/159071418.html?ext=yandex" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:27.0) Gecko/20100101 Firefox/27.0" "-" "RU" "Zhukovskiy"
От счетчика на бекенде остаются только записи в access-логе nginx
Для записи в Amazon Redshift данные приводятся к CSV-подобному виду, отправляются в Amazon S3, а при желании, разбиваются на несколько частей для быстроты загрузки. Парсинг лога делается простым скриптом, который за один проход выбирает нужные данные (см. выше) и делает простые преобразования вроде перевода User-Agent в пару Browser/OS.
77.0.155.47|2014-03-31 13:00:02|1|Футбол России и мира, новости футбола, онлайн трансляции, видео голов, трансферы, результаты, статистика, таблицы - Sports.ru|9cfacf46947ecc9a|8582d0d1-0b34-4208-b154-413de9cd40ee|JdHxFVM2AIp2Rdr1C6q0Ag|2014-03-29 14:42:47|7|0|||1970-01-01 04:00:00|2014-03-31 02:32:58|1970-01-01 04:00:00|||||13|1|54|0|0|RU|Grozny|Chrome|33.0.1750|Windows||Other|/football/|/football/
233.91.249.44|2014-03-31 13:00:02|1|Нина Мозер: «Расцениваю серебро Климова и Столбовой как успех» - Фигурное катание - Sports.ru|a3e990633872eb74||JcHxFVKB2Z0nhRhOJHMEAg|2014-03-17 07:55:17|12|0|||2014-03-31 13:01:22|2014-03-31 11:08:01|1970-01-01 04:00:00|hideme.ru/||||13|1|52|2|159076870|RO|Bucharest|Firefox|27|Windows XP||Other|/others/figure-skating/159076870.html|/others/figure-skating/159076870.html|http://alu5.ojf6lnoa.owl.e/others/
Подготовленные для загрузки в Redshift данные выглядят примерно так
Так как каждый запрос от счетчика содержит в себе уникальный ID посетителя и время последнего посещения сайта, на этапе подготовки данных нет необходимости вычислять пользовательские сессии. Более того, данные о просмотрах страниц из одной и той же сессии могут быть записаны на разных серверах счетчика, поэтому хиты в сессии склеиваются уже внутри Redshift. Таким образом мы собираем в нашем хранилище базовые метрики вроде объема показов (инвентарь) или количество уникальных пользователей (аудитория) по любым срезам: раздел сайта, источник, браузер и т.д.
| timestamp | uid | url | visits_count | new_visitor | last_visit_ts |
|---|---|---|---|---|---|
| 3/25/2014 17:42:00 | 108e36856acb1384 | / | 0 | 1 | NULL |
| 3/25/2014 17:43:00 | 108e36856acb1385 | /football/ | 0 | 1 | NULL |
| 3/25/2014 23:42:00 | 108e36856acb1384 | /cska/ | 1 | 0 | 3/25/2014 17:42:00 |
Сырые данные (кликстрим) складываются в Redshift в подобные структуры
В большинстве случаев при анализе трафика нет необходимости узнавать что-то про конкретного посетителя или про одну из его сессий, а требуются суммарные или усредненные значения вроде количества уникальных посетителей за определенный период или среднего количества просмотров на сессию. Поэтому нет смысла проводить анализ непосредственно сырого кликстрима, который занимает очень много места, а запросы к нему выполняются не очень быстро.
Мы упаковываем собираемые данные в агрегаты, удобные для последующего анализа, например, всю пользовательскую сессию, состоящую обычно из нескольких хитов, мы компонуем в одну запись, в которой отражается основная информация об этом посещении: длительность и число просмотров в сессии, источник перехода и другие данные визита:
| start | end | uid | last_visit_ts | pageviews |
|---|---|---|---|---|
| 3/25/2014 17:42:00 |
3/25/2014 17:43:00 |
108e36856acb1384 | NULL | 2 |
| 3/25/2014 23:42:00 |
3/25/2014 23:53:00 |
108e36856acb1385 | 3/25/2014 17:42:00 |
4 |
| 3/26/2014 0:42:00 |
3/25/2014 0:43:00 |
108e36856acb1385 | 3/25/2014 23:42:00 |
2 |
В таком виде представляются агрегированные данные по сессиям
Из этих данных можно собирать агрегаторы следующего уровня:
| date | uid | pageviews | sessions |
|---|---|---|---|
| 3/25/2014 | 108e36856acb1384 | 6 | 2 |
| 3/25/2014 | 108e36856acb1385 | 2 | 1 |
| 3/25/2014 | a3e990633872eb74 | 12 | 3 |
Агрегированные данные по посетителям
Работа с конечными агрегатами происходит намного быстрее, чем с сырыми данными: для получения информации об инвентаре нужно всего лишь взять суммарное число просмотров всех сессий, а для оценки аудитории потребуется посчитать количество уникальных ID посетителей из сжатого в 20 раз (по сравнению с сырым кликстримом) массива данных. Для измерения охвата в каком-то конкретном разделе сайта мы создаем отдельный профиль (если говорить в терминологии GA) в виде таблицы и предвычисляем в этот профиль только те данные о сессиях, которые соответствуют условиям выборки:
INSERT INTO sessions (uid,last_visit_ts, start, end, pageviews)
SELECT uid, last_visit_ts, min(ts), max(ts), count(uid)
FROM clickstream
WHERE timestamp > date_trunc('hour', NOW()) - interval '24 hours'
GROUP BY uid, last_visit_ts
Группировка хитов кликстрима в сессии производится SQL-запросом раз в сутки и занимает несколько секунд. Кроме агрегации данных по визитам, мы также считаем информацию об активности пользователей по дням, неделям и месяцам, чтобы такие данные были мгновенно доступны для соответствующих отчетов. Мы храним в Redshift кликстрим за последний месяц, чтобы можно было делать произвольные запросы по любым срезам, а также иметь свежие данные за последний час.
Мы не сэмплируем исходные данные: собираем информацию о каждом показе страниц, поэтому у нас всегда есть возможность посчитать статистику по любой странице в любом измерении, даже если такая страница собрала всего 10 хитов за месяц. Старые данные кликстрима (старше месяца) мы храним в бэкап-файлах и можем импортировать их в Redshift в любой момент.
Сбор данных об активности пользователей
Чтобы иметь возможность работать одновременно с данными о просмотрах страниц и о действиях пользователей (плюсы к постам блогов, комментарии, управление командам в фэнтези-турнирах и т.д.) мы импортируем из БД сайта в Redshift часть пользовательских данных. При этом в Redshift не переносятся полные тексты постов или новостей, а также персональные данные (email, имена, логины, пароли).
Данные об активности пользователей агрегируются по дням, неделям и месяцам, чтобы можно было быстро строить отчеты по вовлеченности. Например, так можно следить за количеством новых активных пользователей (которые плюсовали, комментировали, заводили команды в фэнтези-турнирах или совершали любые другие действия на сайте) по дням:
SELECT day, new_users, new_active_users
FROM user_activities_day
ORDER BY day
LIMIT 7
day new_users new_active_users
2014-02-15 2051 508
2014-02-16 1608 366
2014-02-17 1052 419
2014-02-18 2131 603
2014-02-19 2374 547
2014-02-20 1340 508
2014-02-21 966 340
Чтобы получить для email-рассылки список активных болельщиков сборной Лесото из Саратова, которые заходили к нам не меньше двух раз за последнюю неделю и при этом посещали сайт больше трех недель подряд, можно выполнить такой запрос:
SELECT ul.user_id
FROM user_log ul
INNER JOIN user_tags ut ON ut.user_id = ul.user_id
WHERE ul.last_week_sessions > 2 -- кол-во сессий за последние 7 дней
AND ul.weeks > 3 -- кол-во недель подряд на сайте
AND ul.city = 'Саратов'
AND ut.tag = 'сборная Лесото'
В итоге мы имеем возможность наблюдать за активностью пользователей в разных измерениях:
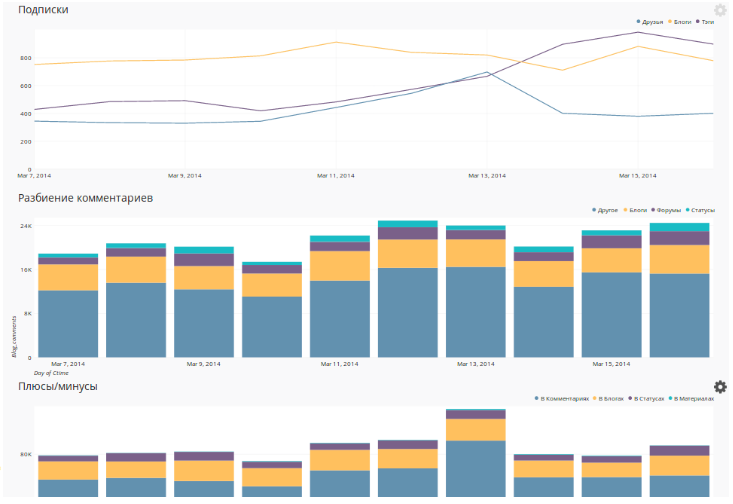
Интеграция с API социальных сетей
Мы собираем данные о наших подписчиках в Facebook, Twitter и Вконтакте раз в сутки и, как всю прочую статистику, складываем их в Redshift. Для получения данных о числе подписчиков в группах Facebook используется Graph API:
$ curl http://graph.facebook.com/sportsru?fields=likes
{
"likes": 238845,
"id": "110179310119"
}
API ВКонтакте также позволяет получать данные о группах при помощи метода groups.getById:
$ curl https://api.vk.com/method/groups.getById?gid=sportsru&fields=members_count
{
"response": [
{
...
"screen_name": "sportsru",
"members_count": 280548,
...
}
]
}
Твиттер же после обновления своего API стал запрашивать авторизацию и ужесточил лимиты на частоту запросов, поэтому данные по нашим пятистам аккаунтам стали собираться слишком долго, поэтому для получения статистики по нашим потокам в Твиттере мы используем несколько аккаунтов и access token keys. Для работы с API Твиттера мы используем tweepy.
Проведя все импорты и преобразования, мы получаем в Redshift таблицу с динамикой изменения числа подписчиков по дням:
| date | social network id | tag | followers |
|---|---|---|---|
| 2014-03-26 |
ЦСКА | 10315 | |
| 2014-03-26 |
VK | Премьер-лига (Англия) | 133427 |
Над этими данными построена интерактивная панель в Chart.io, которая позволяет наблюдать за всеми нашими потоками в соцсетях:
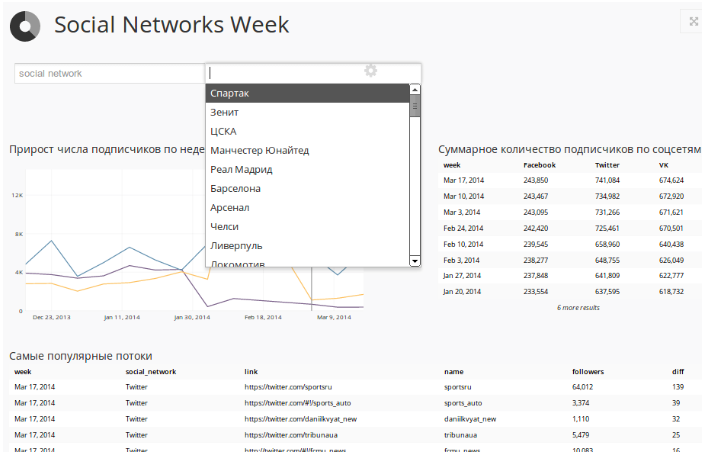
Визуализация данных
Чтобы не тратить время на разработку графического интерфейса, мы решили использовать сторонний сервис для рисования графиков и таблиц Chart.io. Он имеет готовые коннекторы к Redshift, Google Analytics и другим источникам данных, поддерживает кеширование результатов запросов на своей стороне. Данные для графика могут запрашиваться SQL-запросом или при помощи удобного интерфейса, где можно выбрать метрики, измерения и фильтры.
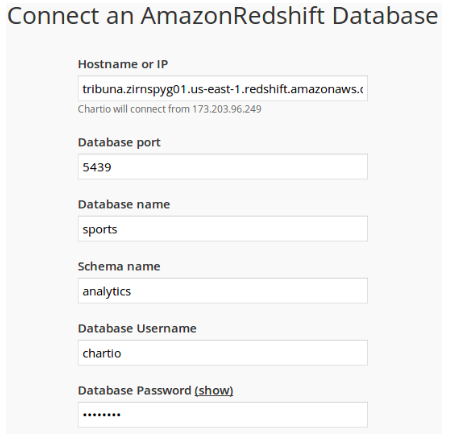
Для того, чтобы подключить Chartio к базе данных достаточно просто указать хост, порт и логин с паролем для подключения к Redshift, а в настройках Amazon Web Services нужно разрешить доступ к данным с серверов Chart.io:
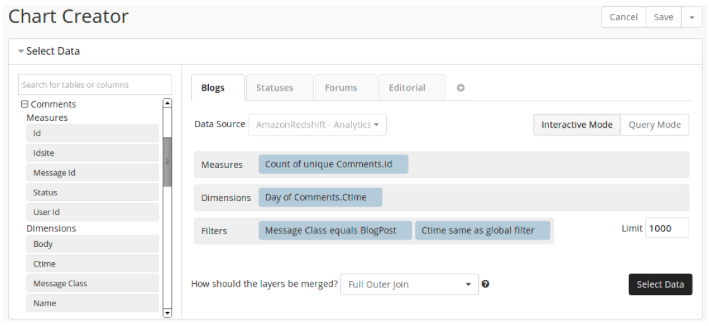
Для того чтобы построить график с разбиением числа комментариев по типам комментируемого контента и динамикой по дням достаточно указать поля, по которым будет производиться группировка данных, и условия выборки:
К выбранным данным можно применять простые математические функции:

После этого нужно выбрать тип графика:
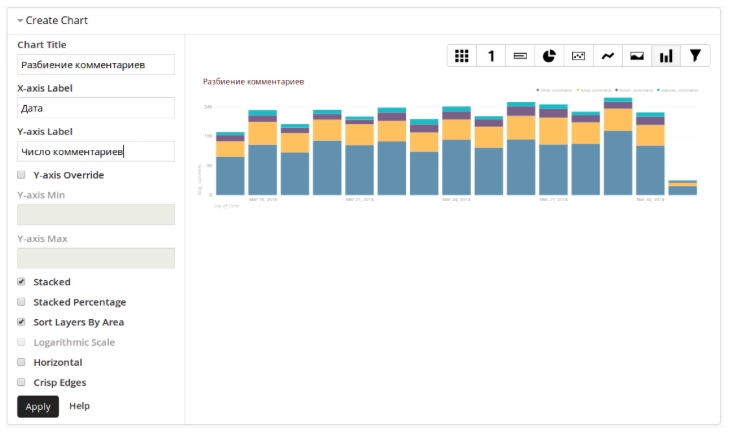
И интерактивная панель готова к использованию. Собственно, таким образом мы обложились всевозможными графиками и таблицами по большому спектру аналитических данных. Потратив меньше 3 месяцев на разработку, мы получили возможность делать произвольные запросы к данным из всех нужных источников, не ограничиваясь стандартными дашбордами Google Analytics.
Что еще?
В дополнение к базовым аналитическим инструментам сотрудников компании мы начали строить data-сервисы для наших пользователей. Например, мы с определенной точностью вычисляем интерес посетителя к тому или иному клубу, спортсмену, турниру и используем эти знания для формирования персонализированного меню сайта и ссылок на часто посещаемые страницы. Мы используем информацию о тегах материалов, которые читает посетитель, иногда обогащаем эти знания другими сигналами (переходы с фан-сайта клуба или из тематического объявления контекстной рекламы).

Рассказывать о нашей инфраструктуре обработки данных можно бесконечно. Мы продолжим обстоятельный разговор в рамках нашей секции на РИТ++, где мы подробнее расскажем об архитектуре, стоимости внедрения и владения, обсудим кампейнинг пользователей для почтовых рассылок, realtime-рекомендации контента, мониторинг бизнес-метрик, а также про поиск ботов среди пользователей и формирование клиентских профилей.
