До недавнего времени все СУБД, работающие со структурированными данными (и не только их), можно было разделить на 2 категории: хранящие записи в построчном формате и хранящие записи в поколоночном формате. Это фундаментальное отличие, влияющее на то, как строки таблиц выглядят на уровне внутренних механизмов хранения СУБД. Долгое время СУБД Teradata относилась к первой группе, но с выходом 14-й версии представилась возможность определять, как хранить данные конкретной таблицы – в виде колонок или строк. Таким образом, появилось гибридное хранение. В этой статье мы хотим рассказать о том, зачем это нужно, как это реализовано и какие преимущества дает.
Прежде чем говорить о формате хранения по колонкам, скажем пару слов о том, как мы обычно храним данные по строкам. Возьмем реляционную таблицу, в которой есть колонки и строки:
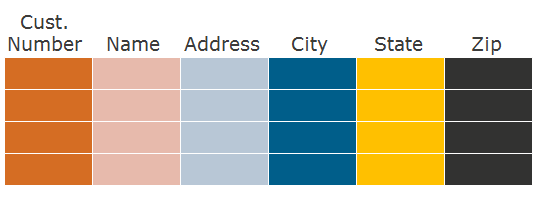
Как мы пишем на диск данные этой таблицы в случае ее строчного формата? Сначала пишем первую строку, затем вторую, третью и так далее:
Как минимизировать нагрузку на дисковую систему при чтении этой таблицы? Можно использовать разные методы доступа к ней:
То есть минимизация нагрузки на дисковую систему основана на том, что нам требуется прочитать не всю таблицу, а только отдельные ее строки.
А как насчет колонок? Если SQL-запрос использует не все колонки таблицы, а только некоторые из них? При чтении строк мы читаем с диска каждую строку полностью. Если в таблице 100 колонок, а конкретному SQL-запросу нужны лишь 5 из них, то мы вынуждены прочитать с диска 95 колонок, которые SQL-запрос не использует.
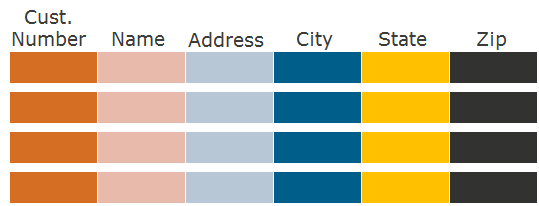
Вот здесь-то на ум и приходит идея хранить данные не по строкам, а по колонкам. В случае формата хранения по колонкам – columnar – подход такой: сначала запишем на диск первую колонку, затем вторую, третью и так далее:
Такое разбиение таблицы на колонки создает партиции по колонкам. Если запросу нужны только отдельные колонки, то мы читаем с диска только нужные партиции по колонкам, существенно сокращая количество операций ввода-вывода при чтении данных, которые нужны SQL-запросу.
Интересная особенность такого подхода состоит в том, что партиции по строкам и партиции по колонкам можно использовать одновременно в одной и той же таблице, иными словами – партиции внутри партиций. Сначала заходим в нужные партиции по колонкам, затем внутри них читаем только нужные партиции по строкам.
Суммируя вышесказанное, Teradata Columnar – это метод хранения данных в СУБД Teradata, который позволяет таблицам одновременно использовать два метода партиционирования:
Преимущества следующие:
Оба эти пункта ведут к сокращению нагрузки на дисковую систему. В первом случае мы читаем меньшее количество данных, поэтому совершаем меньшее количество операций ввода-вывода. Во втором случае таблица занимает меньше места на диске, и, как следствие, чтобы ее прочитать, требуется меньшее количество операций ввода-вывода.
Снижение нагрузки на дисковую систему уменьшает время отклика в приложениях, поскольку запросы выполняются быстрее. А также увеличивается производительность работы системы Teradata в целом – отдельные запросы потребляют меньший процент от емкости системы по операциям ввода-вывода, поэтому система может выполнять большее количество таких запросов.
Хранение данных по колонкам существенно меняет механику чтения данных из такой таблицы. Фактически нам нужно “собирать” данные из отдельных партиций колонок, чтобы получить те строки, которые должен вернуть SQL-запрос.
Выглядит это следующим образом. Если в запросе есть условие WHERE для какой-то колонки, то сначала сканируем эту колонку. Отфильтровываем данные, и для тех строк, которые удовлетворяют условию WHERE, переходим на соседние партиции по колонкам и считываем значения остальных колонок для этих строк.
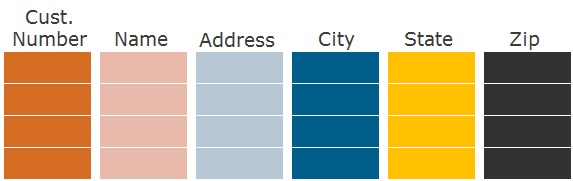
Пример: Какие клиенты живут в Сочи?
В формате строк (для сравнения) считываются значения всех колонок при фильтрации по колонке City (условие WHERE City=’Сочи’).

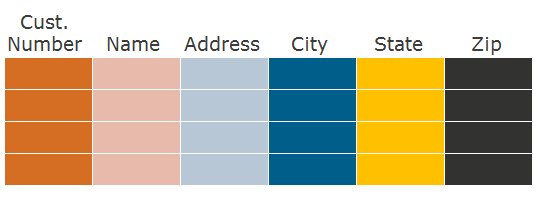
В формате колонок считываются только данные колонок City и Cust. Number – сначала фильтр по колонке City, затем поиск соответствующих значений Cust. Number.

Если колонок в условии WHERE несколько, то сначала выбирается наиболее селективная из них, фильтр по которой приведет к наибольшему отсечению строк, затем следующая колонка WHERE и т.д. И далее все остальные колонки, участвующие в запросе.
Что касается механики перехода между партициями колонок для “сборки” одной строки из отдельных колонок, то такой переход осуществляется “позиционно”. При чтении конкретной строки мы знаем, что в каждой колоночной партиции значение нужной нам строки находится на N-ой позиции относительно начала таблицы. Для поиска строки используется специальная структура адреса строки rowid, – в которой содержится номер партиции и номер строки. Это позволяет переходить между партициями колонок, заменяя номер партиции внутри rowid для того же номера строки. Таким образом, мы собираем значения колонок для отдельной строки воедино.
А если колонок в таблице очень много? Тогда понадобится больше накладных расходов, чтобы собирать строки из отдельных колонок. Этого эффекта можно избежать, создавая отдельные партиции не для каждой колонки, а для групп колонок. Если мы знаем, что какие-то колонки часто используются вместе и редко по отдельности, то помещаем эти колонки в одну партицию. Тогда внутри такой партиции данные этих колонок могут храниться по строкам, как если бы это была подтаблица. Такой метод хранения называется гибридным: часть данных таблицы хранится по колонкам, а часть данных этой же таблицы – по строкам.
Пример (другая таблица, чем раньше):

Единственно давайте оговоримся, что термин «гибридное хранение данных» может использоваться не только для указанного выше способа хранения данных, но и для хранения блоков данных на дисках разной скорости, о чем у нас на Хабрахабре была отдельная статья.
Про исключение партиций мы рассказали чуть подробнее, чем про сжатие данных. Давайте и ему уделим должное внимание.
Партиции по колонкам означают, что значения отдельной колонки находятся рядом друг с другом. Это очень удобно для компрессии данных. Например, если в колонке немного различных значений, то можно составить «словарь» часто используемых значений колонки и с его помощью сжимать данные. Причем для одной колонки таких словарей может быть несколько – отдельно для различных «контейнеров», на которые разбивается колонка при ее хранении на диске (по аналогии с блоками данных при хранении по строкам).
Что удобно – Teradata подбирает словари автоматически на основе тех данных, которые загружаются в таблицу, и если данные со временем меняются, то меняются и словари для сжатия данных.
Кроме словарей есть и другие методы сжатия данных, такие как кодирование run length encoding, отсечение Trim, компрессия значений Null, хранение дельты, UNICODE в UTF8. В детали каждого из них вдаваться не будем – скажем лишь, что они могут применяться как по отдельности, так и в сочетании друг с другом для одних и тех же данных. Teradata может динамически сменить механизм компрессии для колонки, если это принесет лучший результат.
Цель компрессии – уменьшение объема данных (в гигабайтах), который таблица занимает на диске. Это позволяет хранить больше данных (в терминах количества строк таблицы) на том же оборудовании, а также больше данных на быстрых SSD-дисках, если они есть.
Teradata Columnar – это отличная функциональность, которая позволяет увеличивать производительность запросов и сжимать данные. Однако не следует рассматривать ее как идеальное решение. Выигрыш будет получен лишь для соответствующих данных и SQL-запросов с определенными характеристиками. В других случаях эффект может быть даже негативным – например, когда все запросы используют все колонки таблицы и данные не очень хорошо сжимаются.
Удачными кандидатами для колоночного хранения являются таблицы, в которых много колонок, однако каждый SQL-запрос использует относительно небольшое их количество. При этом различные запросы могут использовать различные колонки, главное, чтобы каждый отдельный запрос использовал лишь небольшое количество колонок. В этих случаях происходит существенное сокращение количества операций ввода-вывода и улучшение производительности по I/O.
Разнесение данных строки на отдельные колонки при вставке данных (insert) и последующий «сбор» значений колонок обратно в строки при выборке данных (select) – эти операции потребляют больше CPU для колоночных таблиц, чем для обычных. Поэтому следует учитывать, что если в системе есть значительная нехватка ресурсов CPU (так называемые CPU-bound-системы), то для них Teradata Columnar также следует применять с аккуратностью, поскольку это может уменьшить общую производительность системы из-за нехватки ресурсов CPU.
Одно из требований для колоночных таблиц состоит в том, чтобы данные загружались в таблицу большими порциями INSERT-SELECT. Причина – в следующем: если вставлять данные «построчно», то для колоночных таблиц это очень неудобно, т.к. надо вместо одной записи строки (одна операция ввода-вывода), как это было бы для обычной таблицы, здесь нужно записать значения колонок в разные колонки отдельно – резко увеличивая количество операций ввода-вывода. Впрочем, это характерно для вставки именно одной строки. Если же вставляется сразу много строк, то запись большого набора строк сравнима по трудоемкости с тем, чтобы разбить тот же объем данных на колонки и записать эти колонки в нужные партиции по колонкам.
По этой же причине в колоночных таблицах операции UPDATE и DELETE являются трудоемкими, ведь нужно зайти в различные партиции колонок, чтобы выполнить эти операции. Впрочем, трудоемкими – это не значит невозможными. Если объем таких изменений относительно небольшой, то Teradata Columnar вполне подойдет для таких задач.
Еще одной особенностью колоночных таблиц является отсутствие первичного индекса – колонки, которая обеспечивает распределение строк по AMPам в системе Teradata. Доступ по первичному индексу – наиболее быстрый способ получения строк в Teradata. Для колоночных таблиц такого индекса нет, вместо него используется механизм No-Primary Index (No-PI) – когда данные равномерно распределяются самой Teradata, но без возможности обращения к этим данным по первичному индексу. Это означает, что колоночные таблицы не следует использовать для таблиц, специфика использования которых подразумевает наличие первичного индекса.
Эти правила не являются однозначными. Каждую ситуацию следует анализировать отдельно. Например, можно создавать дополнительные индексы для смягчения эффекта отсутствия первичного индекса. Или другой пример: можно создать таблицу в формате по строкам, а поверх нее – join-индекс в формате по колонкам (join-индекс – это материализованное представление в Teradata, его тоже можно хранить в формате колонок). Тогда запросы, в которых используется много колонок, будут обращаться к самой таблице, а запросы, в которых мало колонок, будут использовать материализованное представление.
Что удобно – вовсе не обязательно объявлять все таблицы колоночными. Можно лишь часть таблиц создать в формате колонок, а остальные таблицы – в формате строк.
Суммируя вышесказанное – Teradata Columnar применяется для таблиц, которые обладают следующими свойствами:
Если присмотреться внимательнее, многие очень большие таблицы, которые растут с течением времени, как раз обладают этими свойствами. Хотите, чтобы они занимали меньше места на дисках и запросы к ним выполнялись быстрее? Тогда функциональность Teradata Columnar стоит того, чтобы обратить на нее внимание.
Чтобы помочь тем, кто выполняет физическое моделирование, определить, какие таблицы следует или не следует создавать в формате колонок, имеется специальный инструмент – Columnar Analysis Tool. Этот инструмент анализирует использование той или иной таблицы SQL-запросами и выдает рекомендации по применимости формата хранения по колонкам. Также много полезной информации есть, разумеется, и в документации по Teradata 14.
Что такое Teradata Columnar?
Прежде чем говорить о формате хранения по колонкам, скажем пару слов о том, как мы обычно храним данные по строкам. Возьмем реляционную таблицу, в которой есть колонки и строки:
Как мы пишем на диск данные этой таблицы в случае ее строчного формата? Сначала пишем первую строку, затем вторую, третью и так далее:
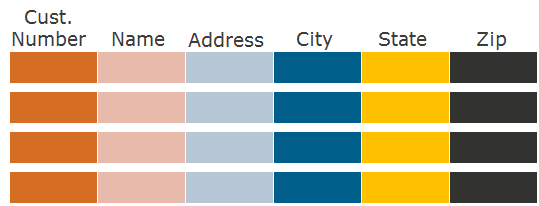
Как минимизировать нагрузку на дисковую систему при чтении этой таблицы? Можно использовать разные методы доступа к ней:
- Доступ по индексу – если нужно прочитать лишь несколько строк.
- Доступ к отдельным ее партициям (секциям) – если таблица очень большая (например, приведены транзакции за несколько лет, но нужно прочитать данные только за последние несколько недель). Это партиции по строкам.
- Полное чтение таблицы – если нужно прочитать большой процент от числа ее строк.
То есть минимизация нагрузки на дисковую систему основана на том, что нам требуется прочитать не всю таблицу, а только отдельные ее строки.
А как насчет колонок? Если SQL-запрос использует не все колонки таблицы, а только некоторые из них? При чтении строк мы читаем с диска каждую строку полностью. Если в таблице 100 колонок, а конкретному SQL-запросу нужны лишь 5 из них, то мы вынуждены прочитать с диска 95 колонок, которые SQL-запрос не использует.
Вот здесь-то на ум и приходит идея хранить данные не по строкам, а по колонкам. В случае формата хранения по колонкам – columnar – подход такой: сначала запишем на диск первую колонку, затем вторую, третью и так далее:
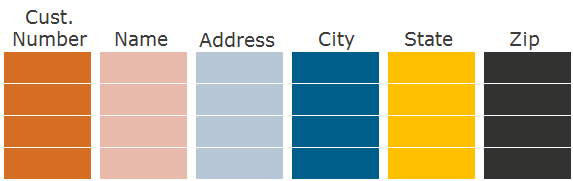
Такое разбиение таблицы на колонки создает партиции по колонкам. Если запросу нужны только отдельные колонки, то мы читаем с диска только нужные партиции по колонкам, существенно сокращая количество операций ввода-вывода при чтении данных, которые нужны SQL-запросу.
Интересная особенность такого подхода состоит в том, что партиции по строкам и партиции по колонкам можно использовать одновременно в одной и той же таблице, иными словами – партиции внутри партиций. Сначала заходим в нужные партиции по колонкам, затем внутри них читаем только нужные партиции по строкам.
Суммируя вышесказанное, Teradata Columnar – это метод хранения данных в СУБД Teradata, который позволяет таблицам одновременно использовать два метода партиционирования:
- Горизонтальные партиции – по строкам
- Вертикальные партиции – по колонкам
Преимущества Teradata Columnar
Преимущества следующие:
- Увеличение производительности запросов – за счет чтения только отдельных партиций по колонкам, исключая необходимость считывать все данные в строках таблицы. Это как раз то, с чего мы начали нашу статью.
- Эффективное автоматическое сжатие данных с использованием механизма автоматической компрессии. А вот это дополнительная приятная возможность, которая открывается при хранении данных по колонкам: в этом случае данные намного удобнее сжимать. Некоторые даже ставят это преимущество на первое место, и вполне обоснованно.
Оба эти пункта ведут к сокращению нагрузки на дисковую систему. В первом случае мы читаем меньшее количество данных, поэтому совершаем меньшее количество операций ввода-вывода. Во втором случае таблица занимает меньше места на диске, и, как следствие, чтобы ее прочитать, требуется меньшее количество операций ввода-вывода.
Снижение нагрузки на дисковую систему уменьшает время отклика в приложениях, поскольку запросы выполняются быстрее. А также увеличивается производительность работы системы Teradata в целом – отдельные запросы потребляют меньший процент от емкости системы по операциям ввода-вывода, поэтому система может выполнять большее количество таких запросов.
Чтение данных из таблицы, хранящейся по колонкам
Хранение данных по колонкам существенно меняет механику чтения данных из такой таблицы. Фактически нам нужно “собирать” данные из отдельных партиций колонок, чтобы получить те строки, которые должен вернуть SQL-запрос.
Выглядит это следующим образом. Если в запросе есть условие WHERE для какой-то колонки, то сначала сканируем эту колонку. Отфильтровываем данные, и для тех строк, которые удовлетворяют условию WHERE, переходим на соседние партиции по колонкам и считываем значения остальных колонок для этих строк.
Пример: Какие клиенты живут в Сочи?
В формате строк (для сравнения) считываются значения всех колонок при фильтрации по колонке City (условие WHERE City=’Сочи’).
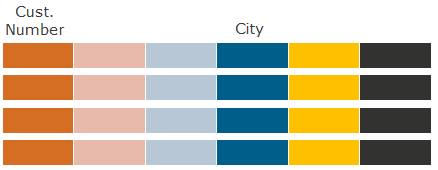
В формате колонок считываются только данные колонок City и Cust. Number – сначала фильтр по колонке City, затем поиск соответствующих значений Cust. Number.

Если колонок в условии WHERE несколько, то сначала выбирается наиболее селективная из них, фильтр по которой приведет к наибольшему отсечению строк, затем следующая колонка WHERE и т.д. И далее все остальные колонки, участвующие в запросе.
Что касается механики перехода между партициями колонок для “сборки” одной строки из отдельных колонок, то такой переход осуществляется “позиционно”. При чтении конкретной строки мы знаем, что в каждой колоночной партиции значение нужной нам строки находится на N-ой позиции относительно начала таблицы. Для поиска строки используется специальная структура адреса строки rowid, – в которой содержится номер партиции и номер строки. Это позволяет переходить между партициями колонок, заменяя номер партиции внутри rowid для того же номера строки. Таким образом, мы собираем значения колонок для отдельной строки воедино.
Гибридное хранение данных в одной таблице
А если колонок в таблице очень много? Тогда понадобится больше накладных расходов, чтобы собирать строки из отдельных колонок. Этого эффекта можно избежать, создавая отдельные партиции не для каждой колонки, а для групп колонок. Если мы знаем, что какие-то колонки часто используются вместе и редко по отдельности, то помещаем эти колонки в одну партицию. Тогда внутри такой партиции данные этих колонок могут храниться по строкам, как если бы это была подтаблица. Такой метод хранения называется гибридным: часть данных таблицы хранится по колонкам, а часть данных этой же таблицы – по строкам.
Пример (другая таблица, чем раньше):
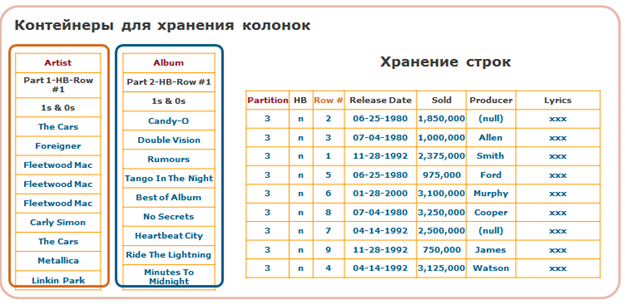
Единственно давайте оговоримся, что термин «гибридное хранение данных» может использоваться не только для указанного выше способа хранения данных, но и для хранения блоков данных на дисках разной скорости, о чем у нас на Хабрахабре была отдельная статья.
Экономия дискового пространства
Про исключение партиций мы рассказали чуть подробнее, чем про сжатие данных. Давайте и ему уделим должное внимание.
Партиции по колонкам означают, что значения отдельной колонки находятся рядом друг с другом. Это очень удобно для компрессии данных. Например, если в колонке немного различных значений, то можно составить «словарь» часто используемых значений колонки и с его помощью сжимать данные. Причем для одной колонки таких словарей может быть несколько – отдельно для различных «контейнеров», на которые разбивается колонка при ее хранении на диске (по аналогии с блоками данных при хранении по строкам).
Что удобно – Teradata подбирает словари автоматически на основе тех данных, которые загружаются в таблицу, и если данные со временем меняются, то меняются и словари для сжатия данных.
Кроме словарей есть и другие методы сжатия данных, такие как кодирование run length encoding, отсечение Trim, компрессия значений Null, хранение дельты, UNICODE в UTF8. В детали каждого из них вдаваться не будем – скажем лишь, что они могут применяться как по отдельности, так и в сочетании друг с другом для одних и тех же данных. Teradata может динамически сменить механизм компрессии для колонки, если это принесет лучший результат.
Цель компрессии – уменьшение объема данных (в гигабайтах), который таблица занимает на диске. Это позволяет хранить больше данных (в терминах количества строк таблицы) на том же оборудовании, а также больше данных на быстрых SSD-дисках, если они есть.
Когда использовать Columnar?
Teradata Columnar – это отличная функциональность, которая позволяет увеличивать производительность запросов и сжимать данные. Однако не следует рассматривать ее как идеальное решение. Выигрыш будет получен лишь для соответствующих данных и SQL-запросов с определенными характеристиками. В других случаях эффект может быть даже негативным – например, когда все запросы используют все колонки таблицы и данные не очень хорошо сжимаются.
Удачными кандидатами для колоночного хранения являются таблицы, в которых много колонок, однако каждый SQL-запрос использует относительно небольшое их количество. При этом различные запросы могут использовать различные колонки, главное, чтобы каждый отдельный запрос использовал лишь небольшое количество колонок. В этих случаях происходит существенное сокращение количества операций ввода-вывода и улучшение производительности по I/O.
Разнесение данных строки на отдельные колонки при вставке данных (insert) и последующий «сбор» значений колонок обратно в строки при выборке данных (select) – эти операции потребляют больше CPU для колоночных таблиц, чем для обычных. Поэтому следует учитывать, что если в системе есть значительная нехватка ресурсов CPU (так называемые CPU-bound-системы), то для них Teradata Columnar также следует применять с аккуратностью, поскольку это может уменьшить общую производительность системы из-за нехватки ресурсов CPU.
Одно из требований для колоночных таблиц состоит в том, чтобы данные загружались в таблицу большими порциями INSERT-SELECT. Причина – в следующем: если вставлять данные «построчно», то для колоночных таблиц это очень неудобно, т.к. надо вместо одной записи строки (одна операция ввода-вывода), как это было бы для обычной таблицы, здесь нужно записать значения колонок в разные колонки отдельно – резко увеличивая количество операций ввода-вывода. Впрочем, это характерно для вставки именно одной строки. Если же вставляется сразу много строк, то запись большого набора строк сравнима по трудоемкости с тем, чтобы разбить тот же объем данных на колонки и записать эти колонки в нужные партиции по колонкам.
По этой же причине в колоночных таблицах операции UPDATE и DELETE являются трудоемкими, ведь нужно зайти в различные партиции колонок, чтобы выполнить эти операции. Впрочем, трудоемкими – это не значит невозможными. Если объем таких изменений относительно небольшой, то Teradata Columnar вполне подойдет для таких задач.
Еще одной особенностью колоночных таблиц является отсутствие первичного индекса – колонки, которая обеспечивает распределение строк по AMPам в системе Teradata. Доступ по первичному индексу – наиболее быстрый способ получения строк в Teradata. Для колоночных таблиц такого индекса нет, вместо него используется механизм No-Primary Index (No-PI) – когда данные равномерно распределяются самой Teradata, но без возможности обращения к этим данным по первичному индексу. Это означает, что колоночные таблицы не следует использовать для таблиц, специфика использования которых подразумевает наличие первичного индекса.
Эти правила не являются однозначными. Каждую ситуацию следует анализировать отдельно. Например, можно создавать дополнительные индексы для смягчения эффекта отсутствия первичного индекса. Или другой пример: можно создать таблицу в формате по строкам, а поверх нее – join-индекс в формате по колонкам (join-индекс – это материализованное представление в Teradata, его тоже можно хранить в формате колонок). Тогда запросы, в которых используется много колонок, будут обращаться к самой таблице, а запросы, в которых мало колонок, будут использовать материализованное представление.
Что удобно – вовсе не обязательно объявлять все таблицы колоночными. Можно лишь часть таблиц создать в формате колонок, а остальные таблицы – в формате строк.
Суммируя вышесказанное – Teradata Columnar применяется для таблиц, которые обладают следующими свойствами:
- SQL-запросы выполняются к отдельным наборам колонок таблицы
ИЛИ
SQL-Запросы выполняются к отдельному поднабору строк таблицы
> Лучший результат – когда и то и другое - Данные могут загружаться большими INSERT-SELECT’ами
- Нет или немного операций update/delete
Если присмотреться внимательнее, многие очень большие таблицы, которые растут с течением времени, как раз обладают этими свойствами. Хотите, чтобы они занимали меньше места на дисках и запросы к ним выполнялись быстрее? Тогда функциональность Teradata Columnar стоит того, чтобы обратить на нее внимание.
Чтобы помочь тем, кто выполняет физическое моделирование, определить, какие таблицы следует или не следует создавать в формате колонок, имеется специальный инструмент – Columnar Analysis Tool. Этот инструмент анализирует использование той или иной таблицы SQL-запросами и выдает рекомендации по применимости формата хранения по колонкам. Также много полезной информации есть, разумеется, и в документации по Teradata 14.
