
В этой лекции на примере Яндекса будут рассмотрены базовые компоненты, необходимые для организации интернет-поисковика. Мы поговорим о том, как эти компоненты взаимодействуют и какими особенностями обладают. Вы узнаете также, что такое ранжирование документов и как измеряется качество поиска.
Лекция рассчитана на старшеклассников – студентов Малого ШАДа, но и взрослые могут узнать из нее много нового об устройстве поисковых машин.
Первый компонент нашей поисковой машины – это Паук. Он ходит по интернету и пытается выкачать как можно больше информации. Робот обрабатывает документы таким образом, чтобы по ним было проще искать. По простым html-файлам искать не очень удобно. Они очень большие, там много лишнего. Робот отсекает все лишнее и делает так, чтобы по документам было удобно искать. Ну и непосредственно поиск, который получает запросы и выдает ответы.
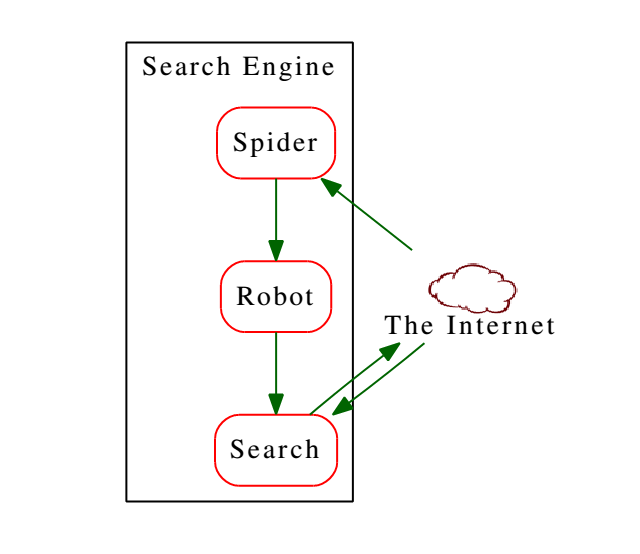
Как понять, насколько хорошо работает Паук? Первая метрика – какой процент сайтов мы увидели. Вторая метрика – насколько быстро мы умеем замечать изменения.
Рунет:
Все вместе:
Если весь Паук всеми своими серверами начнет скачивать один сайт, получится достаточно мощная DDoS-атака. Для предотвращения таких ситуаций предусмотрен компонент Zora. Он координирует закачки, знает, какие сайты были закэшированы недавно, а на какие стоит сходить в ближайшее время.
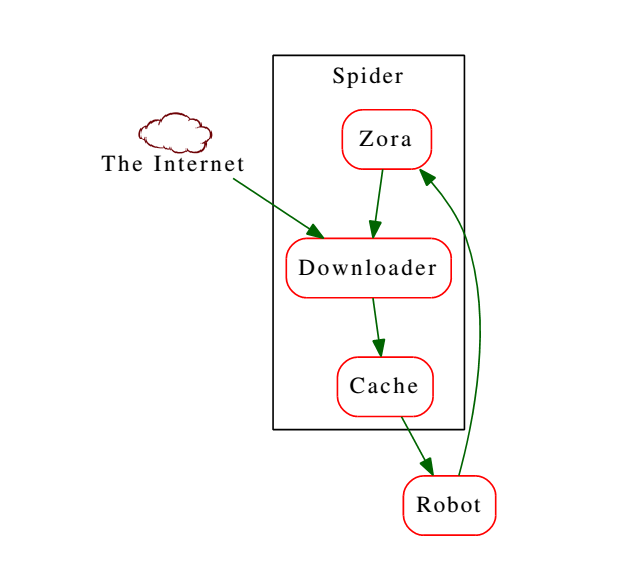
Паук должен иметь возможность посмотреть на страницу из разных точек, чтобы убедиться, что, например, из России и из США страницы выглядят одинаково. Если же для разных регионов выдаются разные страницы, он должен учесть и обработать эту информацию.
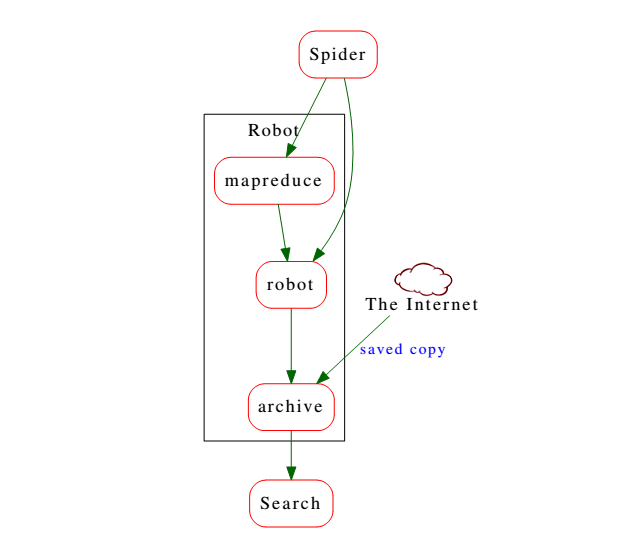
Скачанные Пауком страницы переходят к роботу, который обрабатывает их и делает пригодными для поиска. В первую очередь удаляется вся html-разметка, определяются важные участки.
Состоит Робот их трех компонентов. Во-первых, это система распределенных вычислений MapReduce, которая позволяет посчитать свойства для каждого выкачанного Пауком документа. Второй компонент – это кластер серверов, занятых сборкой поискового индекса. Ну и третий компонент – это архив, содержащий несколько версий поисковой базы.
Мы упомянули свойства документа. Что мы подразумеваем под этим понятием? Допустим, мы скачали html-файл, и нам нужно собрать как можно больше данных о его содержании. MapReduce проводит вычисления и навешивает на документ ярлыки, которые позже будут использоваться в качестве факторов ранжирования: язык документа, тематика, коммерческая направленность и т.п.
Факторы бывают двух типов: быстрые и медленные. Медленные факторы считаются однократно и присваиваются исключительно документу. Быстрые вычисляются для документа вместе с поисковым запросом.
Даже если не брать в расчет сервера MapReduce (они могут использоваться и для других задач), Робот представляет собой более двух тысяч серверов.
Российская база:
Мировая база:
В базе хранится около 25 миллиардов документов (214 ТБ), два раза в неделю она полностью пересчитывается.
Устройство поискового индекса
Допустим, у нас есть три очень простых документа, содержащих которыкие тексты:
Просматривать все эти документы каждый раз, когда приходит запрос, в поисках содержащихся в нем слов неэффективно. Поэтому создается инвертированный индекс: мы выписываем все слова из трех документов (без учета словоформ) и указываем, где они встречаются.
Мама (1, 3)
Мыть (1)
Рама (1, 2)
Москва (2, 3)
Купить (2)
В (2)
Для (3)
Теперь если нам придет поисковый запрос [мама], у нас уже будет готовый ответ. Нам будет достаточно один раз заглянуть в таблицу, чтобы узнать, в каких документах встречается это слово. Если в запросе больше одного слова (например, [мама Москва]), в той же таблице Робот сможет найти документы, в которых встречаются оба этих слова. В нашем случае это третий документ.
Как мы уже говорили, размер нашего реального поискового индекса – 214 ТБ. Чтобы Поиск работал с достаточной скоростью и эффективностью, все эти данные должны храниться в оперативной памяти. Сейчас у нас стоят сервера, в которых установлено от 24 до 128 ГБ памяти. Для оптимизации мы делим поисковую базу на тиры (от англ. Tier – уровень). С их помощью мы разделяем документы по языкам и другим признакам. Поэтому когда нам приходит запрос на русском языке, мы имеем возможность проводить поиск только по соответствующим документам. Всего таких тиров у нас более десятка. Тиры делятся на шарды по 32 гигабайта: объем данных, который можно разместить в памяти физической машины. Сейчас у нас около 6700 шардов.
Поток поисковых запросов к Яндексу может достигать 36 000 обращений в секунду. Только получить такой трафик – серьезная задача. Для ее решения предусмотрено несколько уровней балансировки. В качестве первого уровня применяется DNS. За распределение пакетов отвечает L3 balancer, а за обработку их содержимого – http balancer. Первым делом отсекаются запросы от роботов. Затем исправляются опечатки и проводится анализ запроса. В результате получается «дерево запроса», содержащее возможные написания запроса и вероятные смыслы. После всей этой обработки запрос передается на фронтэнд, и начинается непосредственно поиск. Помимо основного поиска во всем документам, содержащимся в базе, происходит еще множество маленьких поисков с определенными параметрами. Например, по картинкам, видео, афише и т.д. Если эти поиски дадут релевантные результаты, они будут подмешаны в основную поисковую выдачу.

Лекция рассчитана на старшеклассников – студентов Малого ШАДа, но и взрослые могут узнать из нее много нового об устройстве поисковых машин.
Первый компонент нашей поисковой машины – это Паук. Он ходит по интернету и пытается выкачать как можно больше информации. Робот обрабатывает документы таким образом, чтобы по ним было проще искать. По простым html-файлам искать не очень удобно. Они очень большие, там много лишнего. Робот отсекает все лишнее и делает так, чтобы по документам было удобно искать. Ну и непосредственно поиск, который получает запросы и выдает ответы.

Паук
Как понять, насколько хорошо работает Паук? Первая метрика – какой процент сайтов мы увидели. Вторая метрика – насколько быстро мы умеем замечать изменения.
Рунет:
- Качающие сервера: 300;
- Нагрузка: 20 000 документов в секунду;
- Трафик: 400 МБайт/с (3200 Мбит/с).
Все вместе:
- Качающие сервера: 700;
- Нагрузка: 35 000 документов в секунду;
- Трафик: 700 МБайт/с (5600 Мбит/с).
Если весь Паук всеми своими серверами начнет скачивать один сайт, получится достаточно мощная DDoS-атака. Для предотвращения таких ситуаций предусмотрен компонент Zora. Он координирует закачки, знает, какие сайты были закэшированы недавно, а на какие стоит сходить в ближайшее время.

Паук должен иметь возможность посмотреть на страницу из разных точек, чтобы убедиться, что, например, из России и из США страницы выглядят одинаково. Если же для разных регионов выдаются разные страницы, он должен учесть и обработать эту информацию.
Робот
Скачанные Пауком страницы переходят к роботу, который обрабатывает их и делает пригодными для поиска. В первую очередь удаляется вся html-разметка, определяются важные участки.
Состоит Робот их трех компонентов. Во-первых, это система распределенных вычислений MapReduce, которая позволяет посчитать свойства для каждого выкачанного Пауком документа. Второй компонент – это кластер серверов, занятых сборкой поискового индекса. Ну и третий компонент – это архив, содержащий несколько версий поисковой базы.

Мы упомянули свойства документа. Что мы подразумеваем под этим понятием? Допустим, мы скачали html-файл, и нам нужно собрать как можно больше данных о его содержании. MapReduce проводит вычисления и навешивает на документ ярлыки, которые позже будут использоваться в качестве факторов ранжирования: язык документа, тематика, коммерческая направленность и т.п.
Факторы бывают двух типов: быстрые и медленные. Медленные факторы считаются однократно и присваиваются исключительно документу. Быстрые вычисляются для документа вместе с поисковым запросом.
Даже если не брать в расчет сервера MapReduce (они могут использоваться и для других задач), Робот представляет собой более двух тысяч серверов.
Российская база:
- Кластер вычисления факторов: 650;
- Варка поисковой базы: 169;
- Тестовые сервера: 878;
- Архив: 172.
Мировая база:
- Кластер вычисления факторов: 301;
- Варка поисковой базы: 120;
- Тестовые сервера: ???;
- Архив: 60.
В базе хранится около 25 миллиардов документов (214 ТБ), два раза в неделю она полностью пересчитывается.
Устройство поискового индекса
Допустим, у нас есть три очень простых документа, содержащих которыкие тексты:
- Мама мыла раму
- Рамы в Москве купить
- Москва для мам
Просматривать все эти документы каждый раз, когда приходит запрос, в поисках содержащихся в нем слов неэффективно. Поэтому создается инвертированный индекс: мы выписываем все слова из трех документов (без учета словоформ) и указываем, где они встречаются.
Мама (1, 3)
Мыть (1)
Рама (1, 2)
Москва (2, 3)
Купить (2)
В (2)
Для (3)
Теперь если нам придет поисковый запрос [мама], у нас уже будет готовый ответ. Нам будет достаточно один раз заглянуть в таблицу, чтобы узнать, в каких документах встречается это слово. Если в запросе больше одного слова (например, [мама Москва]), в той же таблице Робот сможет найти документы, в которых встречаются оба этих слова. В нашем случае это третий документ.
Как мы уже говорили, размер нашего реального поискового индекса – 214 ТБ. Чтобы Поиск работал с достаточной скоростью и эффективностью, все эти данные должны храниться в оперативной памяти. Сейчас у нас стоят сервера, в которых установлено от 24 до 128 ГБ памяти. Для оптимизации мы делим поисковую базу на тиры (от англ. Tier – уровень). С их помощью мы разделяем документы по языкам и другим признакам. Поэтому когда нам приходит запрос на русском языке, мы имеем возможность проводить поиск только по соответствующим документам. Всего таких тиров у нас более десятка. Тиры делятся на шарды по 32 гигабайта: объем данных, который можно разместить в памяти физической машины. Сейчас у нас около 6700 шардов.
Работа с запросом
Поток поисковых запросов к Яндексу может достигать 36 000 обращений в секунду. Только получить такой трафик – серьезная задача. Для ее решения предусмотрено несколько уровней балансировки. В качестве первого уровня применяется DNS. За распределение пакетов отвечает L3 balancer, а за обработку их содержимого – http balancer. Первым делом отсекаются запросы от роботов. Затем исправляются опечатки и проводится анализ запроса. В результате получается «дерево запроса», содержащее возможные написания запроса и вероятные смыслы. После всей этой обработки запрос передается на фронтэнд, и начинается непосредственно поиск. Помимо основного поиска во всем документам, содержащимся в базе, происходит еще множество маленьких поисков с определенными параметрами. Например, по картинкам, видео, афише и т.д. Если эти поиски дадут релевантные результаты, они будут подмешаны в основную поисковую выдачу.

