
Некоторое время назад я начал рассказывать на Хабре про Elliptics — наше отказоустойчивое распределенное key-value хранилище (к слову, свободное и распространяемое под GPL-лицензией). Тогда я в общем описал устройство Elliptics: про архитектуру и основные принципы работы, за счет чего достигается надежность системы, как систему можно расширять, и как она ведет себя при сбоях.
Начиная с этой статьи попробуем погрузиться в Elliptics глубже: я хочу рассказать вам про внутреннюю архитектуру и различные поддерживаемые фичи.
Сегодня — про сетевую и программную архитектуру Elliptics и некоторые из его особенностей. Также я подробно расскажу про кэш и нашу низкоуровневую библиотеку для локального хранения данных — Eblob.
Для начала введем небольшой набор понятий, для лучшего понимания друг друга:
Как уже говорилось в прошлой статье, в Elliptics каждая нода отвечает за какой-то диапазон ключей в своей группе. Но при этом каждой ноде известно о том, за какой диапазон отвечают все из них. В Elliptics эти знания называются таблицей маршрутизации запросов. Именно благодаря ей и peer-to-peer технологии, в которой все ноды соединяются со всеми, можно совершать любой запрос за O(1) сетевых операций.
Elliptics изначально создавался в качестве по-настоящему надежной системы хранения данных, которая архитектурно не будет бояться отключения машин, дата-центров или целых стран. Поэтому было важно построить систему без использования master-нод, достаточно простую и легко реагирующую на любое изменения конфигурации сети.
Таблица маршрутизации Elliptics поддерживается в актуальном состоянии весьма простым способом: каждая нода раз в определенное количество времени просит первую ноду из каждой группы вернуть ее таблицу маршрутизации. Это позволяет своевременно реагировать на любые изменения в сети, узнавать о появлении новых или выпадении имеющихся машин.
В случае же если таблица маршрутизации клиента отстала от реального положения дел, то на сервер может прийти запрос на идентификатор, за который он не отвечает. В таком случае запрос будет переотправлен сервером на ту ноду, которая, по его мнению, отвечает за этот диапазон.
Для связи между узлами в Elliptics используется свой расширяемый асинхронный бинарный протокол с поддержкой мультиплексирования. В каждом пакете есть заголовок и, возможно, тело запроса или ответа.
В заголовке указаны:
Всего заголовок занимает 96 байт, тело же запроса и ответа специфично для команды и, с точки зрения сетевого движка, представляет собой просто набор байт. Данный протокол позволяет абстрагировать собственно сетевое взаимодействие между узлами от логики работы сервера — хранения данных. За счет этого можно сказать, что Elliptics — это уже давно не просто система хранения данных, а распределенная система выполнения команд.
В больших сетях возникают проблемы, связанные с приоритезацией сетевых потоков, существуют несколько способов для ее решения.
Во-первых, можно «красить» трафик, используя в ip-пакете поле TOS (Type of Service). В таком случае можно выставлять приоритеты запросам от клиента к серверу и между серверами. Для этого в Elliptics используются опции server_net_prio и client_net_prio.
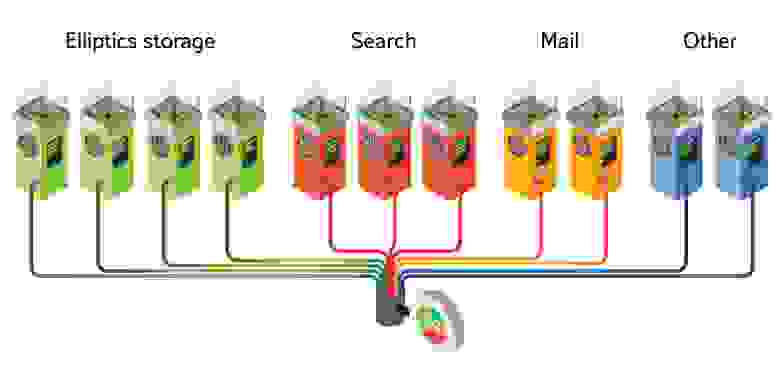
Во-вторых, можно пускать разный трафик по разным сетям, для этого в Elliptics есть поддержка нескольких интерфейсов. При этом каждому интерфейсу нужно указать класс (номер, идентификатор) сети, таким образом, у нас для каждой сети будет поддерживаться своя таблица маршрутизации, это позволяет части клиентов ходить по более скоростной, но, например, менее надежной сети, а другим клиентам — по более медленной, но надежной. За счет этого можно запускать процедуру восстановления на более скоростной сети никак не влияя на выполняющиеся сейчас запросы из внешнего мира.
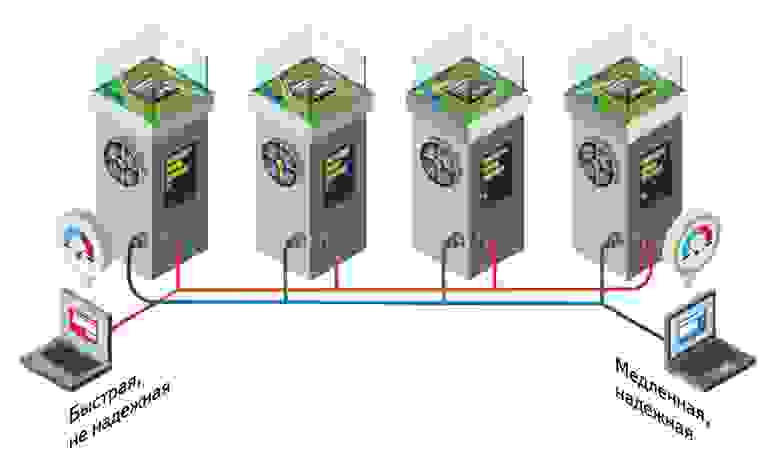
В Elliptics есть поддержка региональности, данные всегда будут стараться отдавать от той машины в сети, которая находится ближе к клиенту. Это позволяет иметь кеширующие копии данных в дата-центрах по всему миру без необходимости слать каждый запрос в Москву. Например для Яндекс.Музыки можно в дата-центрах определенного региона хранить наиболее популярные композиции.
За счет того как Elliptics хранит данные на диске (о чем будет рассказано ниже), можно осуществлять стримминг данных непосредственно с серверов, без промежуточного проксирования. Для этого клиент узнает, где находятся ближайшие к нему данные, и перенаправляет пользовательский HTTP-запрос прямо на сервер, где данные расположены физически. При этом в запросе уже содержится информация о файле, в котором лежит нужный блок данных, а также размер и координаты этого блока по отношению к началу файла. Это позволяет использовать одно из лучших решений на сегодня для отдачи статики по HTTP — nginx. Для защиты от доступа к «чужим» данным, такие запросы содержат несложную аутентификацию с приватным ключом.
Не секрет, что время от времени данные теряются по независящим от нас причинам — сыпятся диски, сгорают сервера, ураганы оставляют дата-центры без электричества, по политическим причинам в стране отключают интернет. В этом случае важно, чтобы данные продолжали храниться в нужном количестве копий. Поэтому в Elliptics работает процедура под названием read recovery. Если во время чтения обнаруживается, что файл есть не на всех нужных группах, то по получении данных клиент на этих группах его восстанавливает. Это позволяет даже без длительного запуска глобальных процедур восстановления данных поддерживать систему в рабочем состоянии.
В дополнение к read recovery у нас также есть системы для восстановления данных как внутри дата-центра, так и между ними. Первый способ хорошо подходит, если мы добавили в группы новые машины — при этом добавленные машины сразу же начинают отвечать на все запросы. Запись будет произведена успешно, а вот отдать данные новые узлы не смогут, ведь они все еще находятся на «старых» серверах, хотя соответствующие диапазоны уже обслуживают «новые». Merge-восстановление перевозит данные с одних серверов в группе на другие. Междатацентровое восстановление нужно в случае аварий или плановых учений, когда мы теряем часть данных на одной или нескольких группах. Недостающие (или более новые) данные будут скопированы из других реплик.
Сам сервер по своему устройству напоминает слоеный пирог. На самой вершине находится сетевой слой, который отвечает только за поддержание соединений между нодами, а также за считывание и отправку пакетов по сети. На этом же уровне происходит поддержание таблицы маршрутизации в актуальном состоянии.
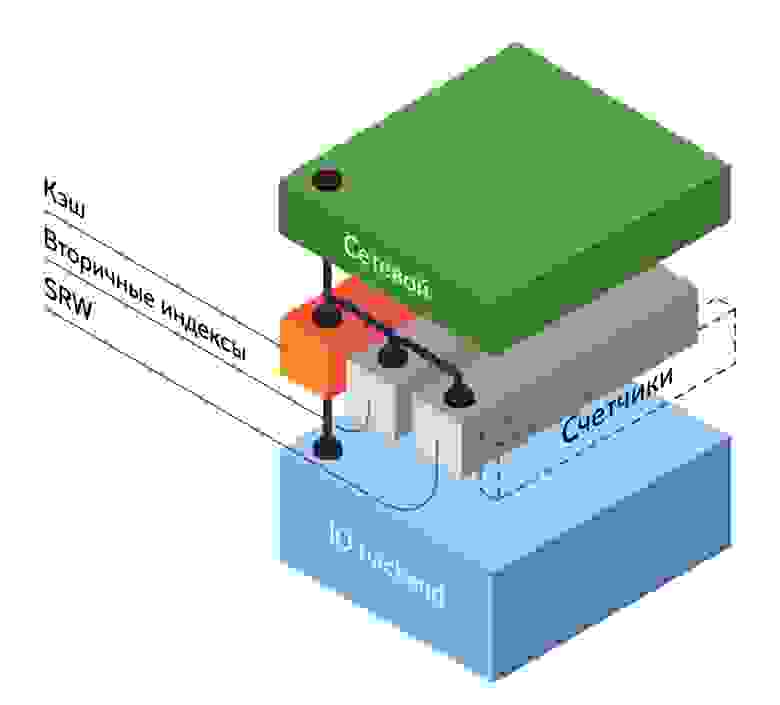
Ниже находится слой для обработки команд. Все приходящие запросы распределяются по соответствующим обработчикам: кэш, вторичные индексы, счетчики, srw, backend, служебные команды.
I/O-операции с соответствующими флагами попадают в кэш. В backend они попадут только в том случае, если у кэша недостаточно данных для обработки запроса, или по таймауту (по умолчанию синхронизация данных из кэша на диск происходит раз в 30 секунд). Так, например, все запросы на append будут аккумулироваться в кэше, чтобы минимизировать количество операций с диском. Исключение составляет итерирование и range-запросы, они сразу отправляются в backend. Можно вообще запретить работать с диском (включается специальным флагом в команде) — в этом случае все операции будут выполняться только с памятью кэша.
Вторичные индексы работают поверх уже существующей инфраструктуры Elliptics. Для их реализации достаточно было добавить несколько новых команд, а также уметь вызывать уже существующие методы для записи и чтения файлов, которые в свою очередь будут проходить через кэш. Вторичные индексы в Elliptics позволяют помечать любые файлы метками, а также впоследствии находить нужные файлы по ним.
Кроме того, в Elliptics есть система для обработки данных — srw (к сожалению, уже никто не помнит, как это расшифровывается и что вообще значит). Srw позволяет выполнять на серверах Elliptics’а различные задачи. Для запуска приложений и контроля за потреблением их ресурсов используется наша облачная платформа Cocaine. В целом принцип работы следующий:
Данные будут получены именно той «копией» приложения, которая запущена непосредственно на машине, отвечающей за хранение обрабатываемого ключа — таким образом, реализована высокая локальность данных и обработчиков.
Можно грубо представить серверсайд-код как триггер на операцию в базе данных. Поверх данной системы построен Grape — наша Open Source система для обработки потока данных в реальном времени.
Кэш в Elliptics появился в августе 2012 года для уменьшения нагрузки на диск. Изначально это был LRU-кэш, который при специальных флагах сохранял в кэш копию считываемых или записываемых данных, чтобы в следующий раз уже не идти на диск. На самом деле, всего в каждой ноде ро умолчанию 16 кэшей (конечно же их количество можно изменить), каждый из которых отвечает за свой диапазон ключей. Таким образом, достигается лучшая поддержка многоядерных систем.
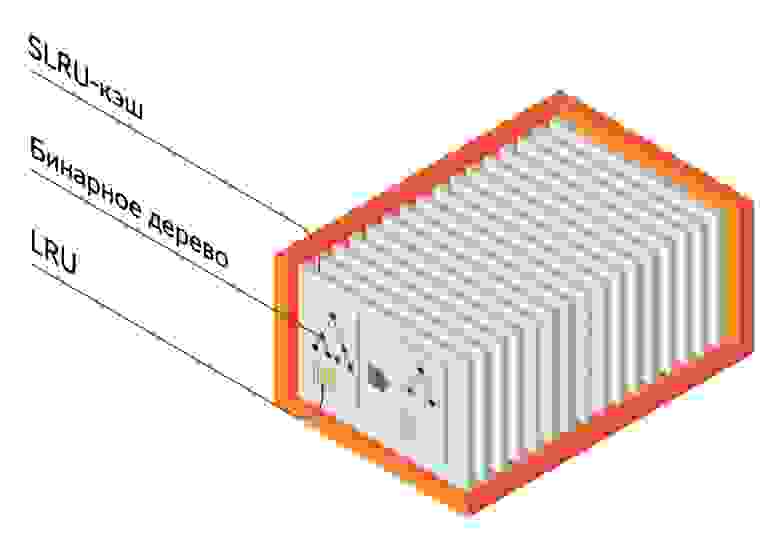
Впоследствии в него была добавлена поддержка timeout’ов, по истечении которых данные удаляются из кэша. Так же была добавлена отложенная запись на диск, это позволяет «склеивать» несколько I/O-операций по ключу в одну — это очень хорошо заметно, если делается много append-записей в конец файлов, например в случае хранения логов.
Совсем недавно LRU-кэш был заменен на Segmented LRU-кэш, он гораздо лучше ведет себя при наличии «горячих» данных. К этой идее мы пришли после изучения опыта Facebook. Segmented LRU хранит горячие данные в отдельном списке, поэтому они не вытесняются из кэша ключами, к которым обратились единожды.
Всего для кэша нужно поддерживать 4 структуры данных — LRU-списки (по списку на страницу в SLRU), бинарное дерево поиска по ключам, очередь с приоритетами для timeout’ов и очередь с приоритетами для синка на диск. Однако последние 3 структуры вполне неплохо кладутся поверх декартова дерева — бинарное дерево над ключами и куча над «событиями», где «событие» — это время синка или протухания ключа. Но при этом вопреки стандартной практике, когда балансировка достигается за счет случайных весов в куче, у нас дерево получается сбалансированным за счет «случайных» ключей. А ключи у нас можно считать случайными по причине того, что они являются результатом криптографического хеширования функцией sha512.
В заключение расскажу кратко про наш основной backend — Eblob. За всю историю Elliptics было опробовано немало разных библиотек, например Google LevelDB, Tokyo/Kyoto Cabinet, Oracle BerkeleyDB, файловая система. Для наших задач Eblob оказался лучшей локальной системой для хранения средних (более одного килобайта) и больших (десятки гигабайт) объемов данных.
Итак, Eblob — это наша низкоуровневая Open Source append-only библиотека для хранения данных в блобах.
В каждом блобе могут лежат миллионы файлов и его размер может достигать сотен гигабайт, все эти параметры могут настраиваться. В каждый момент времени запись идет только в последний, «открытый» блоб. Как только в блобе достигается ограничение по размеру или по количеству файлов — он «закрывается» и открывается новый. После этого в «закрытых» блобах файлы никогда не будут изменяться, максимум что может произойти — это пометка файла как удаленного, если его удалили или записали новую версию в новый блоб.
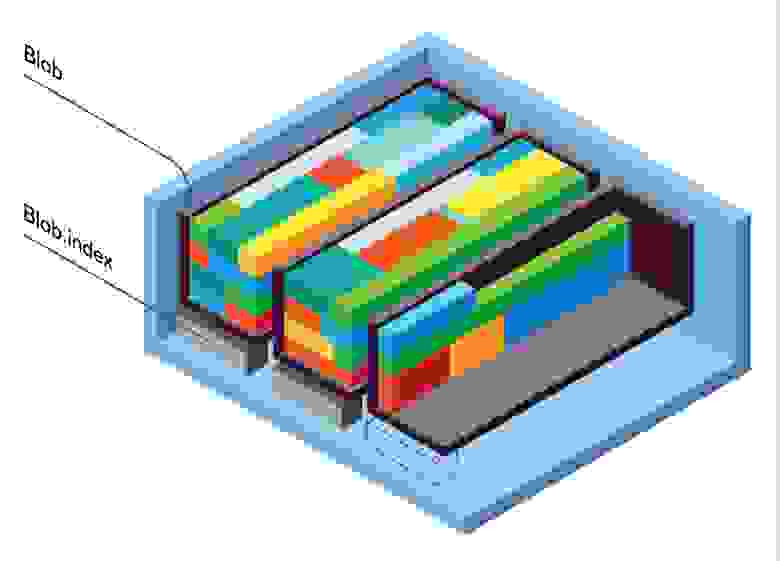
Через некоторое время после закрытия блоба, или как только из него будет удалено ключей больше порогового значения, запускается процедура сортировки (она же — дефрагментация). Это можно сделать либо вручную внешней утилитой, либо по таймауту или диапазону, указанному в конфиге еблоба. В ходе сортировки/дефрагментации из блоба будет удалены все пустые места, и будет сформирован индексный файл, в котором содержатся только заголовки данных (ключ, внутренние eblob’овские флаги, размер и отступ от начала данных в «большом» блобе). В связи с необходимостью сглаживания нагрузки на диск операцию дефрагментации можно отложить на будущее, чтобы выполнить ее во время наименьшей нагрузки на систему.
Для поиска блоба, в котором лежит ключ, применяется несколько приемов:
В следующих статьях мы расскажем про то, как поднять Elliptics в домашних условиях и примеры его использования, подробнее про устройство Eblob’а (поверьте, нам есть что о нем интересного рассказать), стриминг данных, вторичные индексы и многое другое.
Начиная с этой статьи попробуем погрузиться в Elliptics глубже: я хочу рассказать вам про внутреннюю архитектуру и различные поддерживаемые фичи.
Сегодня — про сетевую и программную архитектуру Elliptics и некоторые из его особенностей. Также я подробно расскажу про кэш и нашу низкоуровневую библиотеку для локального хранения данных — Eblob.
Словарь
Для начала введем небольшой набор понятий, для лучшего понимания друг друга:
- нода — один из узлов в сети Elliptics;
- группа — одно из DHT-колец, каждая нода принадлежит какой-то одной из групп;
- id — уникальный ключ элемента в Elliptics;
- сервер — серверная нода;
- клиент — клиентская нода.
Сетевая архитектура
Как уже говорилось в прошлой статье, в Elliptics каждая нода отвечает за какой-то диапазон ключей в своей группе. Но при этом каждой ноде известно о том, за какой диапазон отвечают все из них. В Elliptics эти знания называются таблицей маршрутизации запросов. Именно благодаря ей и peer-to-peer технологии, в которой все ноды соединяются со всеми, можно совершать любой запрос за O(1) сетевых операций.
Elliptics изначально создавался в качестве по-настоящему надежной системы хранения данных, которая архитектурно не будет бояться отключения машин, дата-центров или целых стран. Поэтому было важно построить систему без использования master-нод, достаточно простую и легко реагирующую на любое изменения конфигурации сети.
Таблица маршрутизации Elliptics поддерживается в актуальном состоянии весьма простым способом: каждая нода раз в определенное количество времени просит первую ноду из каждой группы вернуть ее таблицу маршрутизации. Это позволяет своевременно реагировать на любые изменения в сети, узнавать о появлении новых или выпадении имеющихся машин.
В случае же если таблица маршрутизации клиента отстала от реального положения дел, то на сервер может прийти запрос на идентификатор, за который он не отвечает. В таком случае запрос будет переотправлен сервером на ту ноду, которая, по его мнению, отвечает за этот диапазон.
Для связи между узлами в Elliptics используется свой расширяемый асинхронный бинарный протокол с поддержкой мультиплексирования. В каждом пакете есть заголовок и, возможно, тело запроса или ответа.
В заголовке указаны:
- ключ, по которому совершен запрос;
- статус команды (представляет из себя errno);
- номер транзакции;
- номер (идентификатор) команды;
- набор общих для всех команд флагов;
- размер тела запроса/ответа.
Всего заголовок занимает 96 байт, тело же запроса и ответа специфично для команды и, с точки зрения сетевого движка, представляет собой просто набор байт. Данный протокол позволяет абстрагировать собственно сетевое взаимодействие между узлами от логики работы сервера — хранения данных. За счет этого можно сказать, что Elliptics — это уже давно не просто система хранения данных, а распределенная система выполнения команд.
Что отличает Elliptics
В больших сетях возникают проблемы, связанные с приоритезацией сетевых потоков, существуют несколько способов для ее решения.
Во-первых, можно «красить» трафик, используя в ip-пакете поле TOS (Type of Service). В таком случае можно выставлять приоритеты запросам от клиента к серверу и между серверами. Для этого в Elliptics используются опции server_net_prio и client_net_prio.

Во-вторых, можно пускать разный трафик по разным сетям, для этого в Elliptics есть поддержка нескольких интерфейсов. При этом каждому интерфейсу нужно указать класс (номер, идентификатор) сети, таким образом, у нас для каждой сети будет поддерживаться своя таблица маршрутизации, это позволяет части клиентов ходить по более скоростной, но, например, менее надежной сети, а другим клиентам — по более медленной, но надежной. За счет этого можно запускать процедуру восстановления на более скоростной сети никак не влияя на выполняющиеся сейчас запросы из внешнего мира.

В Elliptics есть поддержка региональности, данные всегда будут стараться отдавать от той машины в сети, которая находится ближе к клиенту. Это позволяет иметь кеширующие копии данных в дата-центрах по всему миру без необходимости слать каждый запрос в Москву. Например для Яндекс.Музыки можно в дата-центрах определенного региона хранить наиболее популярные композиции.
За счет того как Elliptics хранит данные на диске (о чем будет рассказано ниже), можно осуществлять стримминг данных непосредственно с серверов, без промежуточного проксирования. Для этого клиент узнает, где находятся ближайшие к нему данные, и перенаправляет пользовательский HTTP-запрос прямо на сервер, где данные расположены физически. При этом в запросе уже содержится информация о файле, в котором лежит нужный блок данных, а также размер и координаты этого блока по отношению к началу файла. Это позволяет использовать одно из лучших решений на сегодня для отдачи статики по HTTP — nginx. Для защиты от доступа к «чужим» данным, такие запросы содержат несложную аутентификацию с приватным ключом.
Не секрет, что время от времени данные теряются по независящим от нас причинам — сыпятся диски, сгорают сервера, ураганы оставляют дата-центры без электричества, по политическим причинам в стране отключают интернет. В этом случае важно, чтобы данные продолжали храниться в нужном количестве копий. Поэтому в Elliptics работает процедура под названием read recovery. Если во время чтения обнаруживается, что файл есть не на всех нужных группах, то по получении данных клиент на этих группах его восстанавливает. Это позволяет даже без длительного запуска глобальных процедур восстановления данных поддерживать систему в рабочем состоянии.
В дополнение к read recovery у нас также есть системы для восстановления данных как внутри дата-центра, так и между ними. Первый способ хорошо подходит, если мы добавили в группы новые машины — при этом добавленные машины сразу же начинают отвечать на все запросы. Запись будет произведена успешно, а вот отдать данные новые узлы не смогут, ведь они все еще находятся на «старых» серверах, хотя соответствующие диапазоны уже обслуживают «новые». Merge-восстановление перевозит данные с одних серверов в группе на другие. Междатацентровое восстановление нужно в случае аварий или плановых учений, когда мы теряем часть данных на одной или нескольких группах. Недостающие (или более новые) данные будут скопированы из других реплик.
Архитектура сервера
Сам сервер по своему устройству напоминает слоеный пирог. На самой вершине находится сетевой слой, который отвечает только за поддержание соединений между нодами, а также за считывание и отправку пакетов по сети. На этом же уровне происходит поддержание таблицы маршрутизации в актуальном состоянии.

Ниже находится слой для обработки команд. Все приходящие запросы распределяются по соответствующим обработчикам: кэш, вторичные индексы, счетчики, srw, backend, служебные команды.
I/O-операции с соответствующими флагами попадают в кэш. В backend они попадут только в том случае, если у кэша недостаточно данных для обработки запроса, или по таймауту (по умолчанию синхронизация данных из кэша на диск происходит раз в 30 секунд). Так, например, все запросы на append будут аккумулироваться в кэше, чтобы минимизировать количество операций с диском. Исключение составляет итерирование и range-запросы, они сразу отправляются в backend. Можно вообще запретить работать с диском (включается специальным флагом в команде) — в этом случае все операции будут выполняться только с памятью кэша.
Вторичные индексы работают поверх уже существующей инфраструктуры Elliptics. Для их реализации достаточно было добавить несколько новых команд, а также уметь вызывать уже существующие методы для записи и чтения файлов, которые в свою очередь будут проходить через кэш. Вторичные индексы в Elliptics позволяют помечать любые файлы метками, а также впоследствии находить нужные файлы по ним.
Кроме того, в Elliptics есть система для обработки данных — srw (к сожалению, уже никто не помнит, как это расшифровывается и что вообще значит). Srw позволяет выполнять на серверах Elliptics’а различные задачи. Для запуска приложений и контроля за потреблением их ресурсов используется наша облачная платформа Cocaine. В целом принцип работы следующий:
- Клиент отсылает на сервер запрос на выполнение задачи, в запросе указано имя приложения, имя события и бинарные данные — аргументы события;
- Сервер через Cocaine отсылает запрос нужному приложению;
- Cocaine при необходимости запускает новый экземпляр приложения, следит за временем их жизни и за нагрузкой;
- Приложение обрабатывает запрос, при необходимости посылает сообщения дальше на обработку другим приложениям (которые могут быть и на других машинах). Каждое из приложений может отослать клиенту какие-то данные.
- Последнее приложение сообщает клиенту о завершение выполнения задачи.
Данные будут получены именно той «копией» приложения, которая запущена непосредственно на машине, отвечающей за хранение обрабатываемого ключа — таким образом, реализована высокая локальность данных и обработчиков.
Можно грубо представить серверсайд-код как триггер на операцию в базе данных. Поверх данной системы построен Grape — наша Open Source система для обработки потока данных в реальном времени.
Кэш
Кэш в Elliptics появился в августе 2012 года для уменьшения нагрузки на диск. Изначально это был LRU-кэш, который при специальных флагах сохранял в кэш копию считываемых или записываемых данных, чтобы в следующий раз уже не идти на диск. На самом деле, всего в каждой ноде ро умолчанию 16 кэшей (конечно же их количество можно изменить), каждый из которых отвечает за свой диапазон ключей. Таким образом, достигается лучшая поддержка многоядерных систем.

Впоследствии в него была добавлена поддержка timeout’ов, по истечении которых данные удаляются из кэша. Так же была добавлена отложенная запись на диск, это позволяет «склеивать» несколько I/O-операций по ключу в одну — это очень хорошо заметно, если делается много append-записей в конец файлов, например в случае хранения логов.
Совсем недавно LRU-кэш был заменен на Segmented LRU-кэш, он гораздо лучше ведет себя при наличии «горячих» данных. К этой идее мы пришли после изучения опыта Facebook. Segmented LRU хранит горячие данные в отдельном списке, поэтому они не вытесняются из кэша ключами, к которым обратились единожды.
Всего для кэша нужно поддерживать 4 структуры данных — LRU-списки (по списку на страницу в SLRU), бинарное дерево поиска по ключам, очередь с приоритетами для timeout’ов и очередь с приоритетами для синка на диск. Однако последние 3 структуры вполне неплохо кладутся поверх декартова дерева — бинарное дерево над ключами и куча над «событиями», где «событие» — это время синка или протухания ключа. Но при этом вопреки стандартной практике, когда балансировка достигается за счет случайных весов в куче, у нас дерево получается сбалансированным за счет «случайных» ключей. А ключи у нас можно считать случайными по причине того, что они являются результатом криптографического хеширования функцией sha512.
Бэкэнд
В заключение расскажу кратко про наш основной backend — Eblob. За всю историю Elliptics было опробовано немало разных библиотек, например Google LevelDB, Tokyo/Kyoto Cabinet, Oracle BerkeleyDB, файловая система. Для наших задач Eblob оказался лучшей локальной системой для хранения средних (более одного килобайта) и больших (десятки гигабайт) объемов данных.
Итак, Eblob — это наша низкоуровневая Open Source append-only библиотека для хранения данных в блобах.
В каждом блобе могут лежат миллионы файлов и его размер может достигать сотен гигабайт, все эти параметры могут настраиваться. В каждый момент времени запись идет только в последний, «открытый» блоб. Как только в блобе достигается ограничение по размеру или по количеству файлов — он «закрывается» и открывается новый. После этого в «закрытых» блобах файлы никогда не будут изменяться, максимум что может произойти — это пометка файла как удаленного, если его удалили или записали новую версию в новый блоб.

Через некоторое время после закрытия блоба, или как только из него будет удалено ключей больше порогового значения, запускается процедура сортировки (она же — дефрагментация). Это можно сделать либо вручную внешней утилитой, либо по таймауту или диапазону, указанному в конфиге еблоба. В ходе сортировки/дефрагментации из блоба будет удалены все пустые места, и будет сформирован индексный файл, в котором содержатся только заголовки данных (ключ, внутренние eblob’овские флаги, размер и отступ от начала данных в «большом» блобе). В связи с необходимостью сглаживания нагрузки на диск операцию дефрагментации можно отложить на будущее, чтобы выполнить ее во время наименьшей нагрузки на систему.
Для поиска блоба, в котором лежит ключ, применяется несколько приемов:
- Все индексы еще не отсортированных блобов находятся в памяти;
- По отсортированным блобам строится по Bloom Filter на каждый блоб, а также строится дерево из диапазонов на каждые 40 (по умолчанию) ключей в блобе.
- Если Bloom Filter говорит, что ключ, возможно, есть на диске, то в бинарном дереве ищется диапазон, в котором должен быть запрашиваемый ключ.
- Соответствующий найденному диапазону кусок индексного файла вычитывается с диска, затем по нему делается бинарный поиск.
- Если ключ нашелся в индексном файле, то уже делается запрос в большой блоб по точным координатам.
Заключение
В следующих статьях мы расскажем про то, как поднять Elliptics в домашних условиях и примеры его использования, подробнее про устройство Eblob’а (поверьте, нам есть что о нем интересного рассказать), стриминг данных, вторичные индексы и многое другое.
