
С 16 по 17 ноября в Москве проходила международная конференция по информационной безопасности ZeroNights 2017. В этом году Яндекс, как обычно, выступил её соорганизатором и представил ряд докладов в ходе Defensive Track'а – секции, посвященной защите сервисов и инфраструктуры. В частности, мы поделились нашим опытом внедрения Secure Development Lifecycle (SDL) для такого крупного и комплексного проекта, как Яндекс.Браузер.

Если кратко, то SDL – это набор различных контролей безопасности на всех этапах жизненного цикла продукта. Сама по себе данная методология существует уже довольно давно, изначально её анонсировала компания Microsoft, и про канонический подход вы можете почитать на их сайте, на Хабре, а также на просторах интернета. SDL позволяет снизить вероятность возникновения уязвимостей, максимально усложнить их эксплуатацию и ускорить исправление. Всё это позволяет сделать продукт более безопасным.
Однако в настоящее время в индустрии до сих пор существует весьма распространенное мнение, что для проектов, которые разрабатываются в рамках процессов на базе Agile’a, внедрение SDL – очень сложная и почти нерешаемая задача, т.к. множество проверок создают бутылочное горлышко и мешают разработчикам укладываться в сроки. С первым тезисом мы спорить точно не будем, а второму готовы бросить вызов и поделиться историей о том, какие контроли мы встроили в процесс разработки Браузера и какие трудности встретились на этом пути. Если вы пропустили наш доклад или хотите узнать дополнительные подробности – просим заглянуть под кат.
Входные данные
Чтобы было понятнее, обозначим входные данные для решаемой нами задачи. SDL для Браузера встраивался уже в существующий процесс разработки довольно масштабного проекта. Яндекс.Браузер построен на одной из самых продвинутых и безопасных платформ – Chromium. Для всех версий браузера, в т.ч. для мобильного браузера, используется единый репозиторий, кодовая база имеет размер примерно 10 гигабайт и включает в себя различные компоненты, написанные на C++, JavaScript, Java и Objective C. В качестве системы сборки используется TeamCity c нашими собственными доработками. В ходе разработки продукта команда решает несколько типов задач: продуктовые (создание новой функциональности), технологические (улучшения и доработки, с которыми пользователь обычно не взаимодействует, например оптимизация производительности или замена кодека) и инфраструктурные (задачи по доработке инфраструктуры сборки браузера).
Важно также отметить, что на самом начальном этапе внедрения SDL у продукта уже существовал свой устоявшийся релизный цикл (новый релиз Браузера выходит в среднем каждые три недели), поэтому первоочередная задача заключалась в том, чтобы не сломать существующие процессы и не сильно усложнить жизнь разработчикам. Именно поэтому первое, что было сделано – это декомпозиция существующего жизненного цикла разработки на этапы и выделение наиболее оптимальных с точки зрения внедрения контролей безопасности. Ниже на схеме можно увидеть, что из этого получилось. Оптимальные, на наш взгляд, этапы выделены желтым цветом: feature freeze – этап, когда уже понятен перечень новых разработок и фич, которые поедут в релиз, и code freeze – этап, когда разработчики не вливают в релиз новый код без особых на то причин.

Еще одной особенностью цикла разработки Браузера является то, что в процессе решение продуктовых задач команда оформляет два обязательных документа (у нас это просто страницы во внутренней wiki):
продуктовое описание (ПО) – в нем содержится описание того, какую задачу должна решать функциональность, а также каким образом она должна взаимодействовать с пользователем, т.е. где именно и какого размера должна быть кнопка или поле ввода, какой диалог должен показывать браузер и т.п.
- техническое задание (ТЗ) – тут уже с дополнительными техническими подробностями описывается как именно должна решаться задача: какие должны быть реализованы компоненты, как они должны работать "под капотом" и т.п.
Детализация этих документов как правило зависит от сложности разработки. С точки зрения безопасности, наиболее интересным обычно оказывается именно ТЗ.
Цикл безопасной разработки
Далее мы стали проектировать сам процесс. Канонический SDL от Microsoft показался нам несколько избыточным, поэтому в итоге мы сформировали цикл из 5 этапов:
- обучение и тренинги;
- дизайн-ревью по безопасности (security design review);
- анализ реализации (implementation analysis);
- финальное ревью по безопасности (final security review / security audit);
- поддержка (response / bug bounty).
Часть из этих контролей привязаны к жизненному циклу, в частности дизайн-ревью, анализ реализации и финальное ревью. Часть – нет. Например, обучение проходит независимо от релизов, а поддержка осуществляется вообще непрерывно. Дизайн-ревью и финальное ревью по безопасности проводится именно в отношение новых фичей продукта, а вот анализ реализации применяется в целом к релизу. На полную схему можно посмотреть ниже.
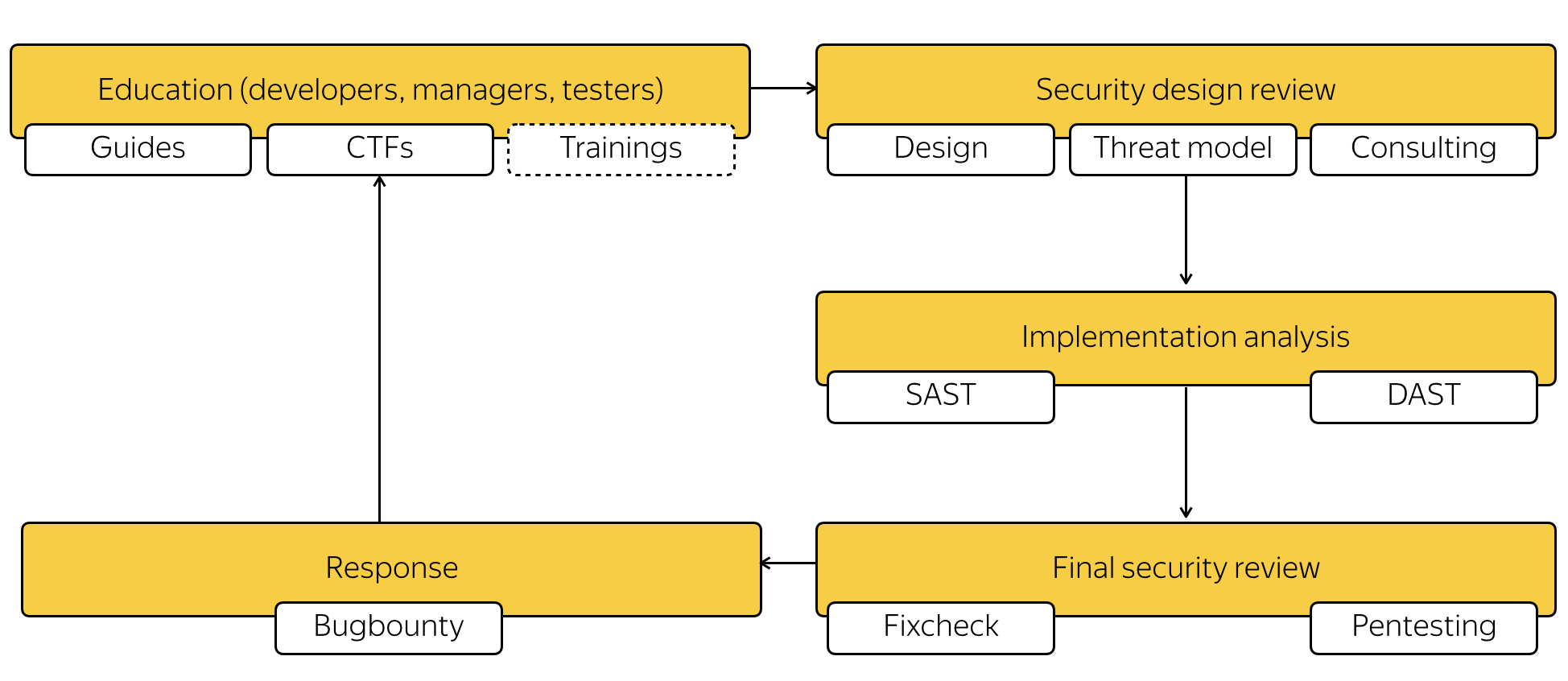
Покрыть весь продукт SDL полностью почти нереально, поэтому мы начали с малого, постепенно расширяя покрытие проверок, сейчас наш перечень уже приоритизирован и выглядит примерно так:
- Фичи и разработки, которые связаны с безопасностью напрямую (например, защита wi-fi или новый менеджер паролей).
- Новые и сложные с точки зрения реализации механизмы (облачный просмотр документов, Турбо).
- Доработки и новые механизмы в web-api браузера.
- Все, что потенциально влияет на безопасность или приватность пользователей.
Теперь рассмотрим детальнее сами контроли. На фазе обучения команда продуктовой безопасности Яндекса работает с менеджерами, разработчиками и тестировщиками. Цель этой работы – описать всем участникам процесса базовые модели угроз для продукта и научить команду бороться с причинами их реализации – уязвимостями. Это один из самых важных этапов, т.к. код пишут люди и от его качества безопасность зависит напрямую, и мы об этом заботимся, к примеру, для разработчиков у нас существует отдельное внутреннее руководство. В нем описаны базовые принципы безопасной разработки, перечень возможных уязвимостей для разного типа приложений, показаны типичные примеры уязвимого кода и исправлений. Также там есть информация о том, как использовать различные техники и технологии снижения вероятности эксплуатации уязвимости (так называемые mitigations). Подробнее о нашей документации и процессах, которые существуют вокруг неё мы уже рассказывали в этом году на OWASP Poland Day. Для тестировщиков есть похожее руководство, в нем перечислены некоторые "маркеры" – свойства продуктов и сервисов, а также данные о том, как подключить к продукту наши внутренние инструменты для анализа безопасности. Стоит заметить, что данный набор руководств существует не только для Браузера, он общий для всей компании.

Дизайн-ревью уже привязано к релизному циклу таким образом, что оно должно завершиться до того, как какая-то фича попадет в тот или иной релиз и произойдет feature freeze.
Заключается данный контроль в том, что участник команды разработки (менеджер, отвечающий за фичу) связывается любым удобным для него образом с командой продуктовой безопасности и передает на анализ документы по разработке: продуктовое описание и техническое задание. Если безопасники видят с точки зрения архитектуры той или иной фичи потенциальные проблемы в её работе, они дают свои комментарии, и их пожелания попадают в ТЗ. Также, если фича имеет отношение к безопасности или просто несёт в себе новые угрозы безопасности, команда безопасности разрабатывает отдельную модель угроз для фичи, которая потом будет использоваться на других этапах. В ряде случаев угрозы попадают и в основную модель угроз.
Анализ реализации – этап, в рамках которого отрабатывают автоматизированные контроли по безопасности. Их задача – выявить уязвимости, и применяются они уже не к отдельным фичам, а целиком к сборкам Браузера. Его задача – покрывать общую модель угроз продукта. У нас реализовано 2 вида контролей: статический анализ (SAST) и динамический анализ (DAST).
Процесс статического анализа делится на 2 подпроцесса: анализ кода различными статическими анализаторами и поиск уязвимых third-party компонентов по базе данных с уязвимостями. Для решения второй задачи у нас создан собственный сервис. А для решения первой мы используем известные статические анализаторы Coverity и Сlang static analyzer, а также собственные механизмы для анализа частных случаев: например, для оценки безопасности регулярных выражений, поиска секретов в репозиториях или для обнаружения небезопасных вызовов внутреннего API. Кроме того, мы отслеживаем ситуацию с безопасностью платформы Chromium и (несмотря на то, что наша версия Chromium'а обычно отстает от релиза всего на 3 недели) стараемся вливать в наш код какие-то отдельные патчи безопасности, если в Chromium'e найдены критичные уязвимости.
Динамический анализ безопасности также применяется к сборке и включает в себя дополнительные этапы:
- Прогон unit-тестов, собранных с различными sanitizer'ами (Asan, Msan, Ubsan и т.п.) – мы называем этот этап sanity-тестированием;
- Прогон fuzzy-тестов (для этого у нас разработчики пишут специальные fuzzy-тесты на базе libfuzzer'а).
Всё, что касается анализа реализации, отрабатывается в TeamCity как на master-ветке, так и на RC/Beta-сборках, чтобы отслеживать появление уязвимостей. За результатом работы следят как сами разработчики, так и группа продуктовой безопасности. Очень важно, чтобы все эти процессы были завершены к следующему и последнему этапу, который привязан к циклу разработки.
Этим этапом является финальное ревью по безопасности – контроль, который применяется опять же именно к фиче и позволяет подтвердить, что функциональность разрабатывалась при участии команды продуктовой безопасности, прошла через SAST и DAST, и все основные проблемы с безопасностью уже решены. Если фича сложная, и понятно, что она может повлиять на безопасность пользователя, то на этом этапе делается дополнительное ручное или автоматизированное тестирование (пентест). Обычно в ходе такого пентеста оценивается вероятность реализации угроз, которые были обозначены в модели угрозы для фичи.
Проблемы при внедрении контролей и их решение
Давайте перейдем к самому интересному – к описанию проблем, с которыми мы столкнулись. Одним из самых проблемных этапов для нас оказался этап анализа реализации, в частности на этапе статического анализа кода. Данный этап является весьма спорным с точки зрения сравнения результатов DAST'а и SAST'а (т.к. DAST находит воспроизводимые проблема, а SAST – часто лишь потенциальные), однако мы всё равно решили его реализовать, т.к. основной платформой для нашего браузера является Windows, а реализовать эффективный DAST под Windows весьма проблематично. Кроме того, DAST как правило требует дополнительной разработки fuzzy-тестов, а также инфраструктуры для прогона этих тестов, а SAST можно относительно просто запустить в CI-системе. Независимо от производителя на нашей кодовой базе в 10 гигабайт все анализаторы из коробки имели соотношение "сигнал/шум" 20/80. Т.е. только 20% срабатываний анализаторов отражали реальные или хотя бы потенциальные проблемы с безопасностью, а 80% срабатываний были ложными. Также мы встретились с проблемой покрытия кода, т.к. Браузер собирается с помощью Ninja, и у нас есть собственный набор компиляторов на агенте сборки, которые не всегда перехватывались статическим анализатором. Для решения последней проблемы мы прибегли к созданию шагов дополнительного конфигурирования билд-агента в TeamCity, а вот с первой проблемой пришлось биться гораздо дольше.
Решением проблемы излишнего шума стала настройка правил срабатывания у статических анализаторов и отображение команде браузера наиболее вероятных проблем. Мы изначально сделали 2 дэшборда с результатами анализа SAST'а: один для разработчиков, один для команды безопасности. Группа продуктовой безопасности разбирала результаты SAST'а, выбирала правила срабатывания (или отдельные компоненты-модули проверки) и для каждого правила классифицировала срабатывания: TP (True Positive, истинно положительные срабатывания), FP (False Positive, ложно положительные срабатывания). В итоге для каждого правила / модуля проверки высчитывалась метрика точности P (Precision). Правила, которые преодолели порог по точности 0.7, попадали на дэшборд разработчиков. Те, что показывали плохую точность, отключались с отправкой дополнительной информации разработчикам SAST'а.
Ниже находится схема, которая иллюстрирует этот процесс.

Таким образом нам удалось выделить наиболее эффективные виды правил для SAST'а, для нашего набора средств это:
- unitialized variables;
- integer overflow;
- null pointer dereference;
- deadcode.
А вот наиболее проблемными оказались наиболее интересные для нас:
- use after free;
- out of bounds.
Их точность, к сожалению, на нашей кодовой базе составляет примерно 30-50%, зачастую из-за того, что статические анализаторы путаются в ходе анализа семантики weak/shared pointer (а код Chromium активно их использует), также возникали проблемы в раскрутке макросов CHECK/DCHECK, которые также характерны для Chromium.
Действуя итеративно, мы постепенно улучшили как общую точность обнаружения SAST'а, так и покрытие кода.

С DAST'ом тоже были свои сложности. Инфраструктура, на которой запускались браузерные unit-тесты, уже существовала. Первым делом был запущен прогон unit-тестов, собранных с различными sanitizer'ами. Это сразу позволило начать находить проблемы с продуктом. Вторым этапом было написание fuzz-тестов для libfuzer'а, и этот этап потребовал значительных вложений со стороны команды разработки. Особое внимание стоит уделить параметрам фаззинга, мы активно используем словари libfuzzer'a, а также настраиваем maxlen для мутационных данных индивидуально, исходя из размера оригинальных данных. Помимо написания самых fuzz-тестов и их запуска необходимо ещё и отслеживать эффективность их работы. В промышленных масштабах неудобно одновременно выполнять мутацию входных данных libfuzzer'а и поиск крешей процесса (который работает до первого креша), поэтому мы разделили фаззинг на 2 шага:
- Сборка новых входных данных, сгенерированных фаззером на основе существующих;
- Прогон на сборке с санитайзером уже всех полученных входных данных с целью поиска крешей.
Второй важный вопрос, который стоит решить в ходе фаззинга – когда его стоит остановить. У нас используется 2 основных условия: остановка по времени и остановка по покрытию. Покрытие для Браузера измеряется с помощью llvm-cov.
Но анализ реализации не единственное проблемное место. Еще одно потенциальное бутылочное горлышко – это процесс финального ревью, которые у нас называется аудитом безопасности. У нас в Яндексе этот этап SDL существует уже давно и не только для Яндекс.Браузера, он максимально автоматизирован, подробнее об этом можно почитать тут. Для Браузера этот процесс мы сделали неблокирующим для функциональности, которая явным образом не связана с безопасностью. Для большинства фич – это скорее чек-лист на предмет того, что фича прошла все наши контроли. Но если фича связана с безопасностью, либо на предыдущих этапах были найдены уязвимости, то команда продуктовой безопасности проверяет, что уязвимости были исправлены. В ряде случаев делается даже экспресс-пентест, проверяющий модель угроз, созданную специально для фичи.
Выводы и результаты
В данной публикации мы описали не просто абстрактные меры безопасности. С помощью наших мер за последний год мы обнаружили более 50 проблем с безопасностью (не считая тех, что были присланы нам в "Охоту за ошибками" или в рамках сотрудничества с сообществом CVE). Наш опыт показывает, что запустить SDL для большого продукта реально, но в ходе решения такой сложной задачи сталкиваешься с набором проблем, которые лучше решать постепенно. С точки зрения процессов, мы рекомендуем всем, кто попробует повторить наш опыт, обратить внимание на несколько важных вещей:
- при внедрении SDL в первую очередь сфокусируйтесь на критичной, с точки зрения безопасности, функциональности;
- работайте со своими разработчиками, менеджерами, тестировщиками, ваш продукт создают люди, от их навыков и знаний зависит качество итогового продукта, а также объем работы продуктовых безопасников в рамках процессов SDL;
- актуализируйте свою модель угроз, обращайте внимания как на базовые проблемы, описанные в популярных руководствах, так и на нестандартные проблемы.
Cо стороны автоматизированных средств мы хотели бы тоже поделиться набором советов:
- статические анализаторы кода из коробки работают не так хорошо, как нам бы хотелось – внедряйте SAST, если понимаете, что внедрить DAST будет ещё сложнее;
- чтобы получить точность для SAST'а на уровне хотя бы 70%, необходимо заниматься настройкой правил / исправлением самих плагинов для проверки кода;
- с комплексными семантиками современных стандартов C++ SAST также работает не очень хорошо, например weak/shared pointer'ы стали для нас головной болью;
- если хотите внедрять DAST – начните с прогона юнит-тестов с помощью sanitizer'ов, как только кол-во найденных проблем снизится – можно переходить к fuzzing'у;
- показывайте своим разработчикам результаты только проверенных анализиторов / правил, действуйте постепенно, это упростит внедрение SDL.
Построение SDL для Яндекс.Браузера заняло около года. Какие-то контроли безопасности у нас уже полностью отлажены (например, статический анализ кода), другие находятся на стадии пилотного проекта и экспериментов (в первую очередь фаззинг). Мы планируем увеличивать их количество, улучшать качество и делиться своим опытом и дальше. Оставайтесь на связи!
