
Когда-то мы уже рассказывали о том, как появился и развивался машинный перевод. С тех пор произошло ещё одно историческое событие – его наконец-то покорили нейронные сети и глубокое обучение. Среди задач обработки естественного языка (Natural Language Processing, NLP) машинный перевод одним из первых получил строгое статистическое основание — еще в начале 1990-х. Но в сфере глубокого обучения он оказался относительно запоздавшим участником. В этом посте мы — команда Яндекса по машинному переводу — обсуждаем, почему это заняло так много времени и какие новые возможности открыл машинный перевод на основе нейросетей.
Мы также будем рады ответить на вопросы на встрече «Яндекс изнутри: от алгоритмов до измерений — в Переводчике, Алисе и Поиске» 1 марта (можно зарегистрироваться или задать вопрос в чате трансляции).
Всего три года назад почти все серьезные промышленные и исследовательские системы машинного перевода были построены с использованием конвейера статистических моделей («фразовый машинный перевод», ФМП), в котором нейронные сети не участвовали. Фразовый машинный перевод впервые сделал машинный перевод доступным для массового пользователя в начале 2000-х годов. При наличии достаточного количества данных и достаточных вычислительных ресурсов ФМП позволял разработчикам создавать системы перевода, которые в основном давали представление о смысле текста, но изобиловали грамматическими, а иногда и семантическими ошибками.
Конвейер статистических моделей, который использовался для построения систем ФМП, на самом деле довольно замысловат. На основании выровненных обучающих предложений — например, переводов русской новостной статьи на английский — система строит статистическую модель, которая пытается «объяснить» каждое из слов целевого языка словами исходного языка, используя «скрытые» переменные, известные как «выравнивания по словам» (word alignments). Идея интуитивно понятна, а математика (максимизация ожидания, EM-алгоритм) довольно хороша.
Итеративный ЕМ-алгоритм — когда на каждом шаге мы строим наилучшее предположение о том, какие исходные слова соответствуют каким целевым словам, а затем эти «догадки» используются в качестве обучающих данных для следующей итерации — вполне похож на подход, который мы могли бы применить для расшифровки меню на иностранном языке. Проблема в том, что он основан на отдельных словах, а пословный перевод зачастую невозможен.
Модели выравнивания слов вводят различные предположения о независимости, чтобы упростить задачу слишком большой вычислительной сложности (принятие решения о том, какие из 2^{JI} возможных способов выровнять слова в исходном предложении длины I со словами в целевом предложении длины J) до более приемлемых размеров. Например, может быть разработана скрытая марковская модель для решения этой задачи со сложностью O(I^2J).
Модели на основе слов никогда не показывали особенно хороших результатов. И все выглядело довольно печально, пока не был предложен метод построения модели перевода на уровне фразы, поверх выравнивания слов. После этого машинный перевод стал применяться в интернете — для перевода веб-сайтов на иностранных языках или просто в качестве неисчерпаемого источника вдохновения для мемов.
ФМП использует матрицы выравнивания слов, чтобы определить, какие пары фраз в паре предложений могут служить переводами друг для друга. Полученная таблица фраз становится главным фактором в линейной модели, которая вместе с такими компонентами, как языковая модель, используется для генерации и отбора потенциальных переводов.

ФМП очень хорошо запоминает фразы из параллельного корпуса текстов. Теоретически ему достаточно одного единственного примера, чтобы выучить фразовый перевод, если только слова в этом примере относительно хорошо выровнены. Хотя это может производить впечатление беглого владения языком, на самом деле система не очень понимает, что она делает.
Пространство параметров системы ФМП огромно, но сами параметры чрезвычайно просты — «какова вероятность увидеть эту целевую фразу как перевод этой исходной фразы?» Во время применения модели для перевода каждое исходное предложение разбивается на фразы, которые система видела раньше, и эти фразы переводятся независимо друг от друга. К сожалению, когда эти фразы сшиваются вместе, нестыковки между ними оказываются чересчур заметными.

Исследователи, занимавшиеся распознаванием речи или изображений, уже давно задумывались о том, как кодировать данные, ведь непрерывный сигнал трудно представить в дискретном мире компьютеров. А вот работающие над обработкой естественного языка об этом не особенно беспокоились. Это казалось довольно простым — можно заменить слова целочисленными идентификаторами и индексировать параметры модели этими числами. Именно так поступают N-граммные языковые модели и системы ФМП.
К сожалению, в такой унитарной кодировке все слова в некотором смысле одинаково похожи (или в равной степени отличаются друг от друга). Это не соответствует тому, как люди воспринимают язык, когда слова определяются тем, как они используются, как соотносятся с другими словами и чем отличаются от них. Это принципиальный недостаток до-нейронных моделей в обработке естественного языка.
С такими дискретными категориальными данными нейронным сетям справиться нелегко, и для автоматической обработки языка пришлось придумать новый способ представления входных данных. Важно, что при этом модель сама обучается нужному для конкретной задачи представлению данных.
Векторное представление слов (word embedding), применяемое в нейронном машинном переводе, как правило, сопоставляет каждому слову во входных данных вектор длиной в несколько сотен вещественных чисел. Когда слова представлены в таком векторном пространстве, сеть может научиться моделировать отношения между ними так, как это было бы невозможно сделать, если эти же слова представлены как произвольные дискретные символы, как в системах ФМП.
Например, модель может распознать, что, поскольку «чай» и «кофе» часто появляются в сходных контекстах, оба эти слова должны быть возможны в контексте нового слова «разлив», с которым, допустим, в обучающих данных встретилось лишь одно из них.
Однако процесс обучения векторным представлениям явно более статистически требователен, чем механическое запоминание примеров, используемое ФМП. Кроме того, непонятно, что делать с теми редкими входными словами, которые недостаточно часто встречались, чтобы сеть могла построить для них приемлемое векторное представление.
Переход от дискретных к непрерывным представлениям позволяет нам гораздо более гибко моделировать зависимости. Это в буквальном смысле видно в переводах, которые производит система машинного перевода на основе нейросетей, построенная нами в Яндексе (НМП).
Система, основанная на переводе фраз, неявно предполагает, что каждая исходная фраза может быть переведена независимо от остальной части предложения. Звучит, как рецепт катастрофы, но в дискретной статистической модели это неизбежно, ведь добавка в модель всего лишь одного бита информации о контексте удвоила бы количество параметров. Это известное в нашем деле «проклятие размерности».
Единственная причина, по которой фразовый MП вообще работает, заключается в том, что для сшивания независимо переведенных фраз используется языковая модель. Эта модель обучена на больших объемах одноязычных данных и делает ортогональные предположения о независимости, которые часто могут компенсировать предположения о независимости на уровне фраз.
В системе ФМП приходилось на каждом шаге принимать решения, какие исходные слова мы «в данный момент» переводим (но на самом деле зачастую довольно сложно построить такое выравнивание между исходными и целевыми словами). В декодере НМП мы просто применяем преобразования к вектору скрытых состояний, пошагово генерируя целевые слова, пока сеть не решит остановиться (или пока мы её не остановим).
Вектор скрытых состояний, который обновляется на каждом шаге, может хранить информацию из любой части исходного предложения и любой части уже выполненного к этому моменту перевода. Это отсутствие «явных» предположений о независимости — пожалуй, самое важное различие между системами нейронного и фразового машинного перевода. Именно этим, скорее всего, и объясняется ощущение, что переводы нейронных систем более точно передают общую структуру и значение исходного предложения.
Впрочем, наивно утверждать, что модели НМП не делают никаких предположений о независимости просто потому, что они не исключают явным образом контекст, как это происходит в ФМП. Наиболее важные разработки в архитектурах НМП за последние несколько лет показывают, что ключ к улучшению качества — способность модели эффективно передавать информацию между различными частями предложения. Самый подходящий механизм для динамического и выборочного распространения информации из сгенерированных энкодером представлений для разных частей исходного предложения называется «внимание».
Научившись «обращать внимание» на различные части исходного и целевого предложений в процессе перевода, сеть пытается решить одну из фундаментальных проблем обработки естественного языка: как превратить линейную последовательность слов во что-то более структурированное, например, дерево.
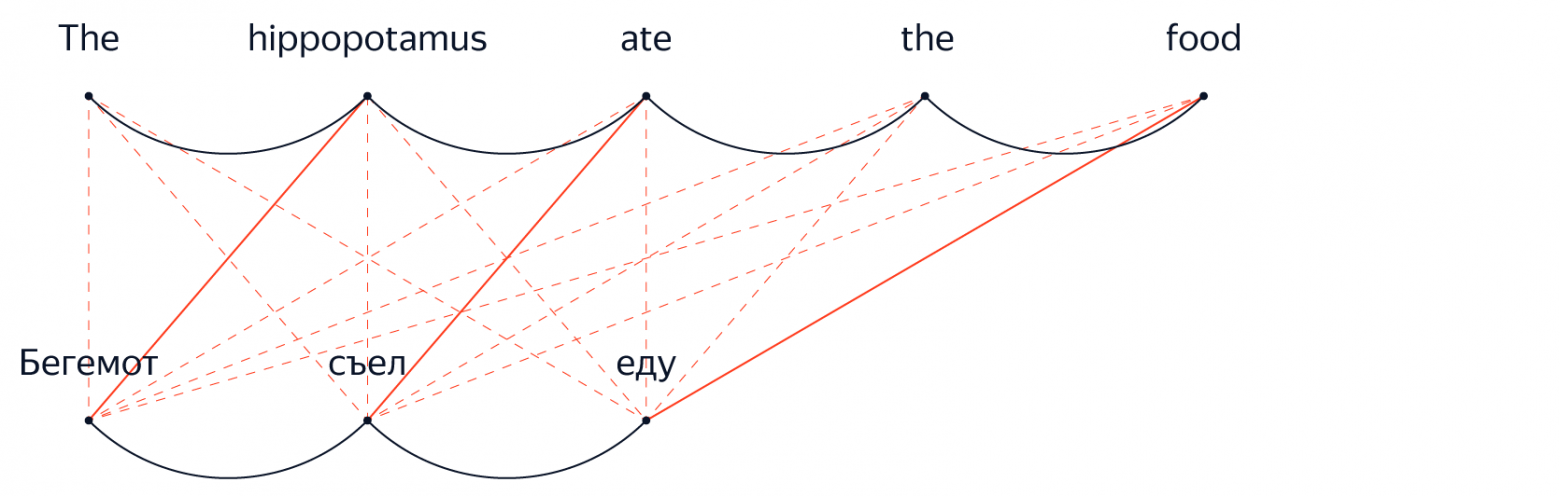
Нейронные и фразовые системы машинного перевода — совсем непохожие создания. В Яндекс.Переводчике многолетний опыт разработки системы ФМП. В прошлом году мы начали изучать возможности интеграции в наш сервис нейронного машинного перевода.
Будучи, помимо прочего, поисковиком, мы не испытывали нехватки обучающих данных для обеих систем. Судя по оценочным исследованиям, мы создали самую надежную в мире фразовую систему машинного перевода для пары английский—русский.
Очевидно, что последние архитектуры НМП могли дать результаты не хуже и даже лучше, чем наша фразовая система. Однако вдруг появились тревожные сигналы в поведении нашей нейронной системы — особенно при переводе пользовательских запросов.
Стоит отметить, что Яндекс.Переводчик стремится быть способным перевести всё, что могут предложить пользователи. И некоторые из них предлагают довольно странные вещи. В результате получается, мягко говоря, некоторое несоответствие обучающих и пользовательских данных.
Напомним, что наша система обучена на переводах, извлеченных из интернета. Это в основном высококачественные переводы, как правило, без проблем с орфографией, пунктуацией и прочими «мелочами», о которых пользователь, спешащий получить свой перевод, может не очень-то заботиться. По тематике, содержанию и стилю тексты, которые нужно переводить нашим пользователям, зачастую сильно отличаются от документов, попадающих в наш обучающий корпус.
В то время как среднее качество переводов системы ФМП ниже, чем у НМП, дисперсия воспринимаемого качества переводов НМП может быть намного выше.
Похоже, этому есть два объяснения:
ФМП просто заучивает фразы из корпуса, поэтому, когда дело доходит до низкочастотных входных данных, он имеет явное преимущество над НМП. С другой стороны, НМП должен увидеть слово несколько раз, чтобы построить приемлемое векторное представление. Он также очень старается моделировать зависимости в данных, поэтому, если сталкивается с мусором во входных данных, легко может производить в десять раз больше мусора в выходных.
Это не совсем то, что мы хотели видеть, когда готовились рассказать, насколько лучше стали наши переводы благодаря нейронным сетям.
Требуется много времени, чтобы заработать доверие пользователя к продукту, но потерять это доверие можно в считанные секунды. Переводы вроде показанных выше, вероятно, хороший способ добиться именно потери доверия.
Хуже того, не все пользователи нашего сервиса смогут оценить адекватность переводов, ведь не все знают исходный или целевой язык. Наш долг перед ними — избегать таких наихудших переводов.
Две наши системы машинного перевода — фразовая и нейронная — вели себя совершенно по-разному на одних и тех же входных данных. Каждая из них при этом демонстрировала довольно высокое качество перевода. Поэтому мы вспомнили, чему нас учили на первом курсе анализа данных и построили ансамблевую систему. Несходство систем часто служит ключом к успешному ансамблю.
Вместо того чтобы комбинировать две системы во время декодирования каким-нибудь сложным способом, мы избрали более простой подход: выбирать результат одной из двух систем. Для этого мы обучили классификаторы с использованием CatBoost.
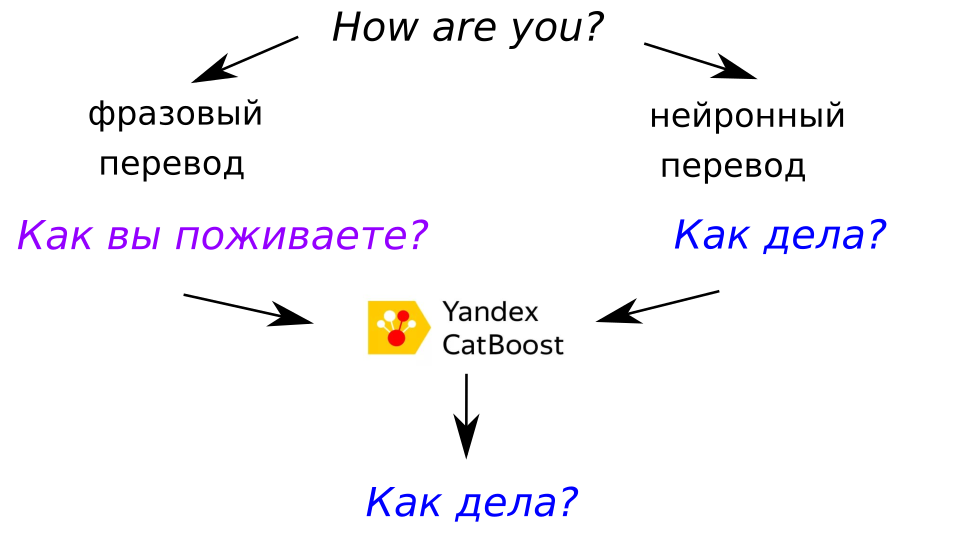
Первый классификатор, обученный на небольшом, размеченном вручную наборе стьюпидов, выявил особенно катастрофические сбои в модели НМП. Второй, обученный предсказывать разницу в баллах BLEU между выходными данными двух систем на большем наборе пар параллельных предложений, использовался, чтобы выловить менее очевидные ошибки. Такие, например, как недоперевод, когда нейронная сеть просто отказывается сотрудничать и оставляет часть исходного предложения непереведенной.
Пользователи Яндекса ежедневно отправляют миллионы запросов на перевод, при этом многократно приходится переводить множество одинаковых запросов. Как правило, эти запросы очень короткие, следовательно, в них не хватает контекста. К сожалению, нейронной системе довольно трудно переводить такие короткие запросы, так как очень немногие из примеров, на которых система обучена, состоят из отдельных слов или фраз. Несмотря на ансамбль и CatBoost, мы понимали, что иногда всей мощности глубокого обучения может быть недостаточно, чтобы дать нашим пользователям лучший результат.

Яндекс.Переводчик гордится словарными статьями, которые он предлагает пользователям. Словари Яндекса создаются автоматически с помощью хорошо настроенного конвейера машинного обучения, оптимизированного с использованием обратной связи от пользователей и краудсорсинговой платформы Яндекса — Толоки.
Мы решили, что включив лучшие переводы из этих словарных статей в нашу систему в качестве ограничений, сможем значительно повысить качество машинного перевода для наиболее частотных запросов.
Последняя тема сегодняшнего поста — если машинный перевод достиг новых высот благодаря гибридному НМП, то откуда нам ожидать дальнейших улучшений?
Одна из малоисследованных областей в машинном переводе — использование контекста в максимально широком смысле. Контекст может включать предыдущее предложение в документе, некоторую информацию о лицах или сущностях, упомянутых в тексте, или просто информацию о том, из какого места на веб-странице взят текст, который мы в данный момент переводим.
По аналогии с восприятием контекста сегодняшними системами НМП на уровне предложения (что было не под силу предыдущему поколению ФМП), мы экспериментируем с включением все более разнообразных типов контекста в нашу систему перевода, чтобы лучше переводить текст в конкретных ситуациях и для различных задач.
Идея эта не слишком радикальна. Большинство переводчиков скажут, что чем больше контекста или справочной информации о переводимом тексте и его аудитории, тем проще будет их работа. В этом смысле системы машинного перевода не должны отличатся от людей. И у нас уже есть положительные результаты, показывающие, что работа в этом направлении стоит вложенных усилий.
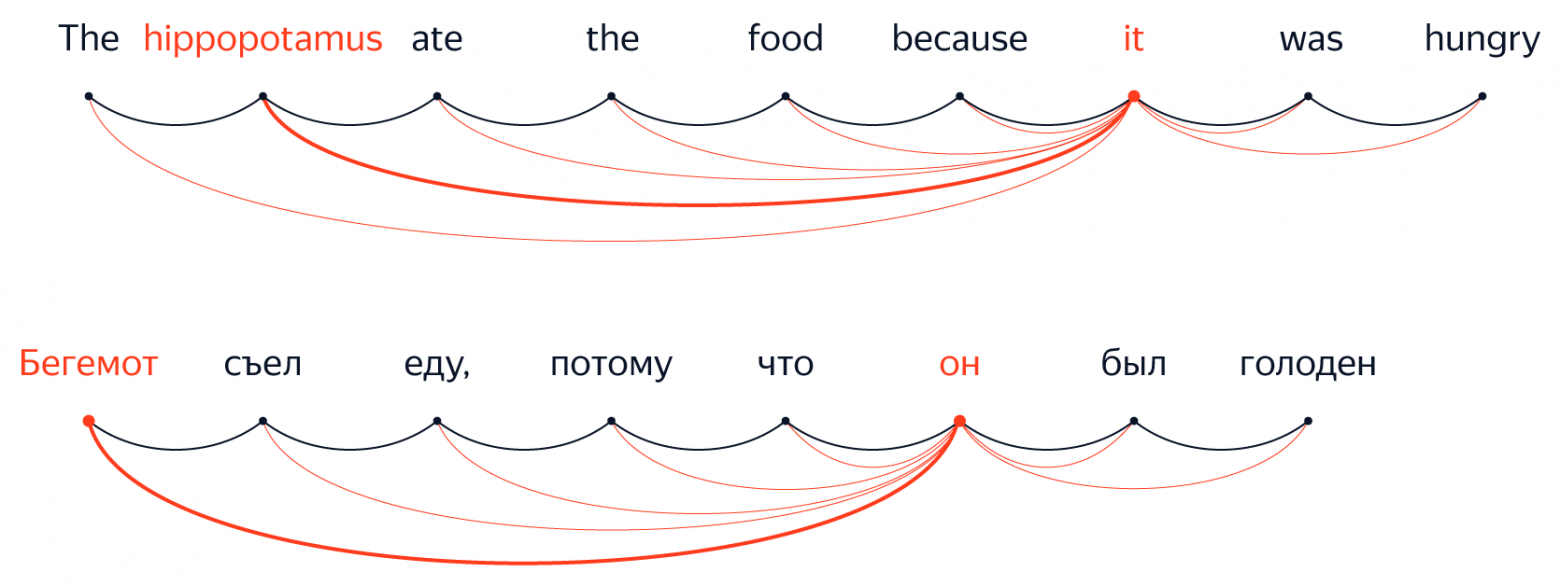
Например, экспериментальная система, которая при переводе использует предыдущее исходное предложение наряду с текущим. Кажется, сеть вполне способна научиться понимать, когда нужно «обратить внимание» на слова из предыдущего предложения. Это естественным образом срабатывает для местоимений, у которых есть антецеденты, что позволяет избежать неприятностей подобного рода:

Другой пример — система, которую мы планируем в ближайшее время запустить на Яндекс.Браузере.
Каждый день миллионы пользователей переводят страницы благодаря нашей интеграции в Яндекс.Браузере. Поскольку структура HTML-страницы позволяет легко определить, где находится текст — в навигационном компоненте, заголовке или блоке с контентом, мы решили использовать эту информацию для улучшения наших переводов.
Понятно, что во многих случаях наилучшим переводом слова «Home», вероятно, будет «Домой». Однако на навигационной панели веб-сайта оно наверняка должно быть переведено как «Главная». Точно так же «Back», вероятно, лучше всего перевести в таком контексте как «Назад», а не «Спина».

Автоматически разметив обучающую выборку извлеченных из интернета параллельных текстов метками «навигация», «заголовок», «содержание», а затем настроив нашу систему так, чтобы она предсказывала эти метки в процессе перевода, мы значительно повысили качество в конкретных видах перевода.
Конечно, мы могли бы добиться всего лишь переобучения системы на этом довольно специфическом распределении. Поэтому, чтобы избежать снижения производительности в более стандартных областях, мы включили в расчет функции потерь при обучении расстояние Ку́льбака—Ле́йблера между предсказаниями нашей адаптированной модели и предсказаниями нашей общей системы. Фактически это штрафование модели за чрезмерное изменение предсказаний.
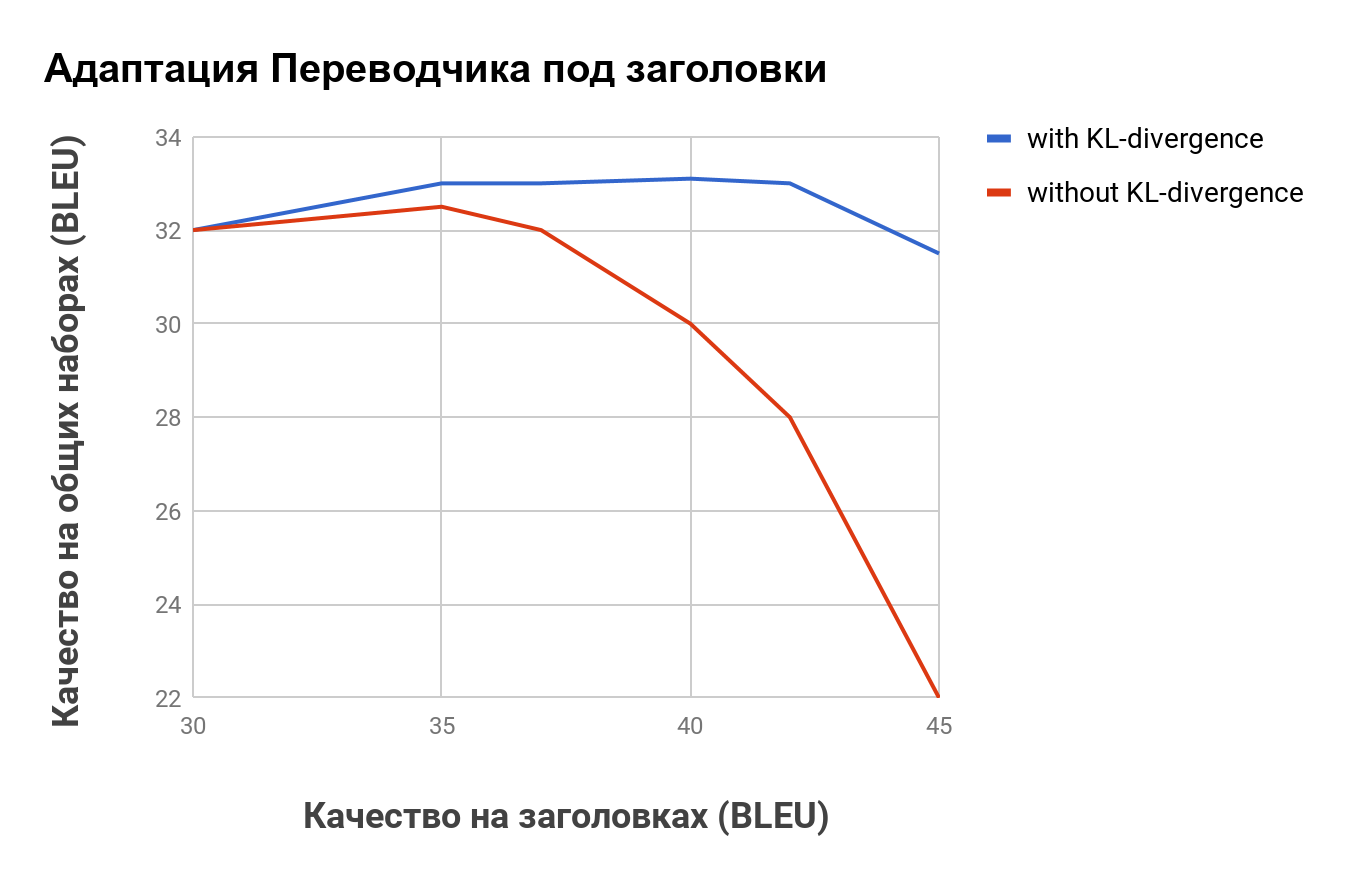
Как видно из графиков, качество для данных в домене значительно возрастает, и как только наша функция потерь дополняется учетом расстояния Кульбака—Лейблера, рост качества больше не приводит к ухудшению перевода для документов вне домена.
Очень скоро мы запустим эту систему на Яндекс.Браузере. Надеемся, это только первое из целого ряда улучшений, которые мы сделаем на основе лучшего понимания пользовательского контекста и «неоправданной эффективности [рекуррентных] нейронных сетей».
Мы также будем рады ответить на вопросы на встрече «Яндекс изнутри: от алгоритмов до измерений — в Переводчике, Алисе и Поиске» 1 марта (можно зарегистрироваться или задать вопрос в чате трансляции).
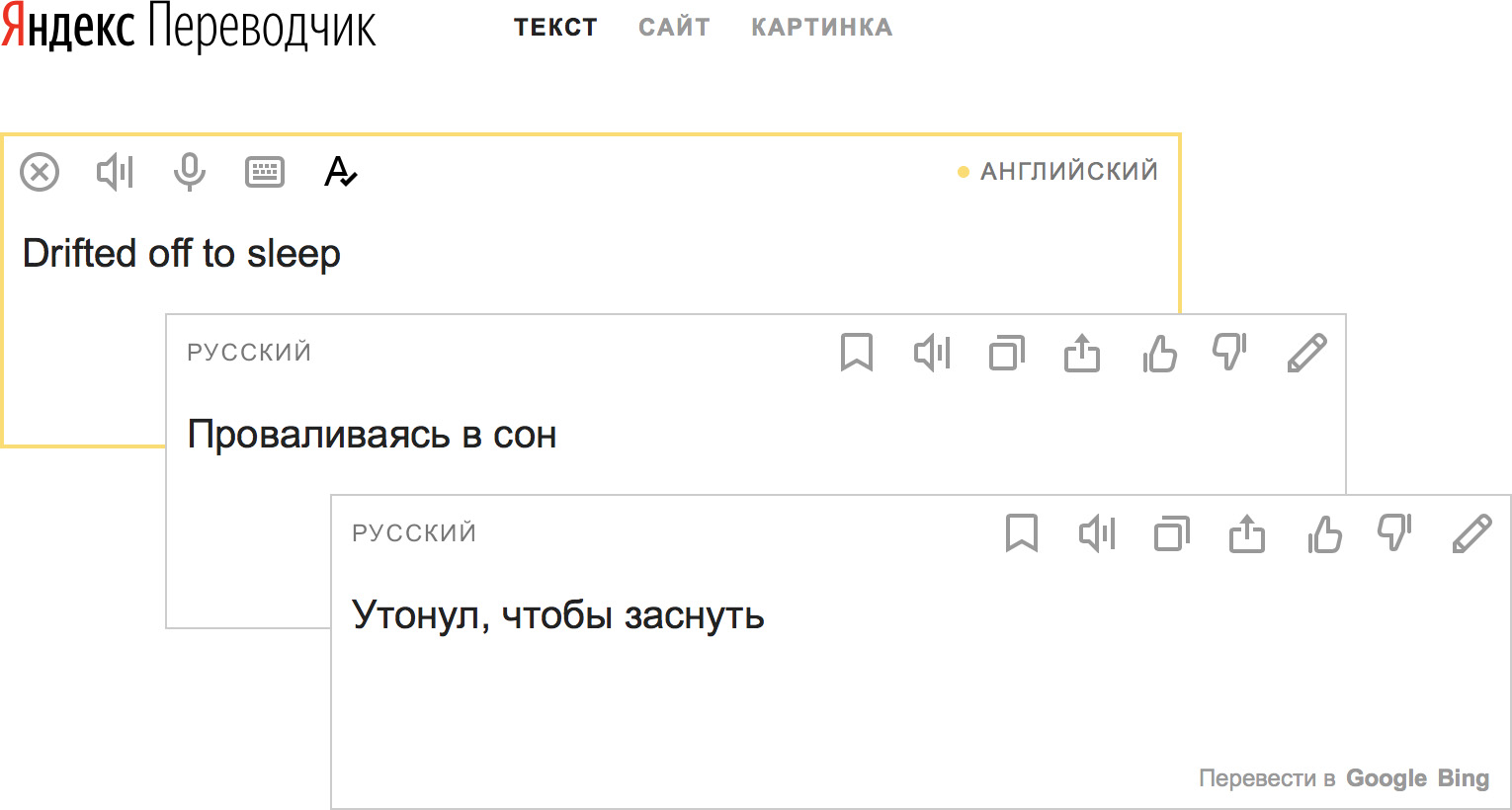
Фразовый машинный перевод
Всего три года назад почти все серьезные промышленные и исследовательские системы машинного перевода были построены с использованием конвейера статистических моделей («фразовый машинный перевод», ФМП), в котором нейронные сети не участвовали. Фразовый машинный перевод впервые сделал машинный перевод доступным для массового пользователя в начале 2000-х годов. При наличии достаточного количества данных и достаточных вычислительных ресурсов ФМП позволял разработчикам создавать системы перевода, которые в основном давали представление о смысле текста, но изобиловали грамматическими, а иногда и семантическими ошибками.
Конвейер статистических моделей, который использовался для построения систем ФМП, на самом деле довольно замысловат. На основании выровненных обучающих предложений — например, переводов русской новостной статьи на английский — система строит статистическую модель, которая пытается «объяснить» каждое из слов целевого языка словами исходного языка, используя «скрытые» переменные, известные как «выравнивания по словам» (word alignments). Идея интуитивно понятна, а математика (максимизация ожидания, EM-алгоритм) довольно хороша.
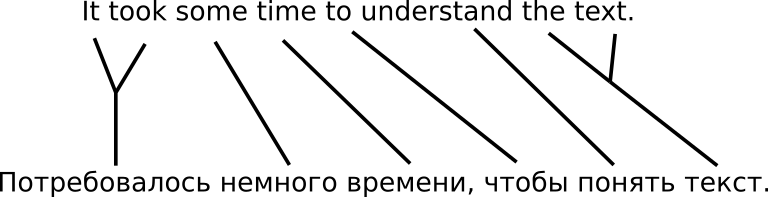
Итеративный ЕМ-алгоритм — когда на каждом шаге мы строим наилучшее предположение о том, какие исходные слова соответствуют каким целевым словам, а затем эти «догадки» используются в качестве обучающих данных для следующей итерации — вполне похож на подход, который мы могли бы применить для расшифровки меню на иностранном языке. Проблема в том, что он основан на отдельных словах, а пословный перевод зачастую невозможен.
Модели выравнивания слов вводят различные предположения о независимости, чтобы упростить задачу слишком большой вычислительной сложности (принятие решения о том, какие из 2^{JI} возможных способов выровнять слова в исходном предложении длины I со словами в целевом предложении длины J) до более приемлемых размеров. Например, может быть разработана скрытая марковская модель для решения этой задачи со сложностью O(I^2J).
Модели на основе слов никогда не показывали особенно хороших результатов. И все выглядело довольно печально, пока не был предложен метод построения модели перевода на уровне фразы, поверх выравнивания слов. После этого машинный перевод стал применяться в интернете — для перевода веб-сайтов на иностранных языках или просто в качестве неисчерпаемого источника вдохновения для мемов.
ФМП использует матрицы выравнивания слов, чтобы определить, какие пары фраз в паре предложений могут служить переводами друг для друга. Полученная таблица фраз становится главным фактором в линейной модели, которая вместе с такими компонентами, как языковая модель, используется для генерации и отбора потенциальных переводов.

ФМП очень хорошо запоминает фразы из параллельного корпуса текстов. Теоретически ему достаточно одного единственного примера, чтобы выучить фразовый перевод, если только слова в этом примере относительно хорошо выровнены. Хотя это может производить впечатление беглого владения языком, на самом деле система не очень понимает, что она делает.
Пространство параметров системы ФМП огромно, но сами параметры чрезвычайно просты — «какова вероятность увидеть эту целевую фразу как перевод этой исходной фразы?» Во время применения модели для перевода каждое исходное предложение разбивается на фразы, которые система видела раньше, и эти фразы переводятся независимо друг от друга. К сожалению, когда эти фразы сшиваются вместе, нестыковки между ними оказываются чересчур заметными.

Что же нам дают нейросети?
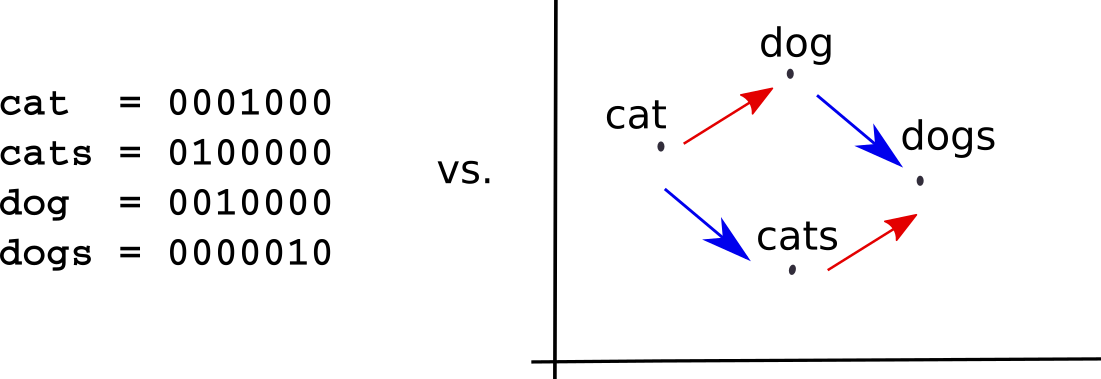
Исследователи, занимавшиеся распознаванием речи или изображений, уже давно задумывались о том, как кодировать данные, ведь непрерывный сигнал трудно представить в дискретном мире компьютеров. А вот работающие над обработкой естественного языка об этом не особенно беспокоились. Это казалось довольно простым — можно заменить слова целочисленными идентификаторами и индексировать параметры модели этими числами. Именно так поступают N-граммные языковые модели и системы ФМП.
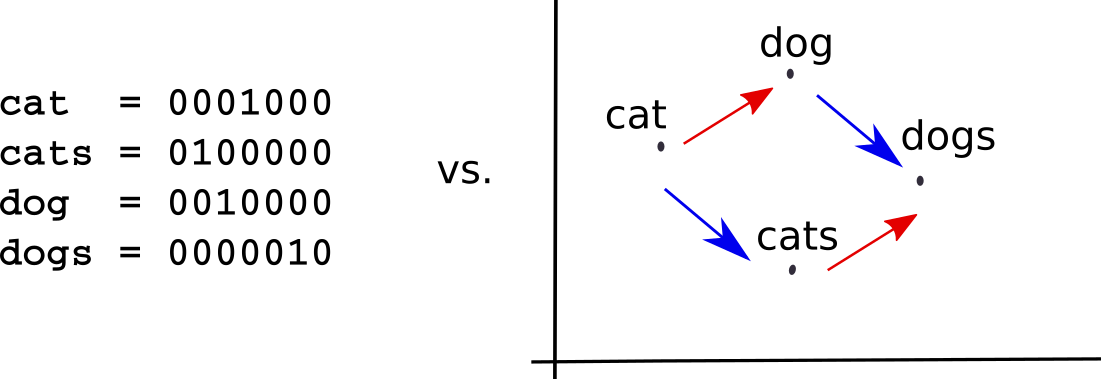
К сожалению, в такой унитарной кодировке все слова в некотором смысле одинаково похожи (или в равной степени отличаются друг от друга). Это не соответствует тому, как люди воспринимают язык, когда слова определяются тем, как они используются, как соотносятся с другими словами и чем отличаются от них. Это принципиальный недостаток до-нейронных моделей в обработке естественного языка.
С такими дискретными категориальными данными нейронным сетям справиться нелегко, и для автоматической обработки языка пришлось придумать новый способ представления входных данных. Важно, что при этом модель сама обучается нужному для конкретной задачи представлению данных.
Векторное представление слов (word embedding), применяемое в нейронном машинном переводе, как правило, сопоставляет каждому слову во входных данных вектор длиной в несколько сотен вещественных чисел. Когда слова представлены в таком векторном пространстве, сеть может научиться моделировать отношения между ними так, как это было бы невозможно сделать, если эти же слова представлены как произвольные дискретные символы, как в системах ФМП.
Например, модель может распознать, что, поскольку «чай» и «кофе» часто появляются в сходных контекстах, оба эти слова должны быть возможны в контексте нового слова «разлив», с которым, допустим, в обучающих данных встретилось лишь одно из них.
Однако процесс обучения векторным представлениям явно более статистически требователен, чем механическое запоминание примеров, используемое ФМП. Кроме того, непонятно, что делать с теми редкими входными словами, которые недостаточно часто встречались, чтобы сеть могла построить для них приемлемое векторное представление.
Нет предположений о независимости
Переход от дискретных к непрерывным представлениям позволяет нам гораздо более гибко моделировать зависимости. Это в буквальном смысле видно в переводах, которые производит система машинного перевода на основе нейросетей, построенная нами в Яндексе (НМП).
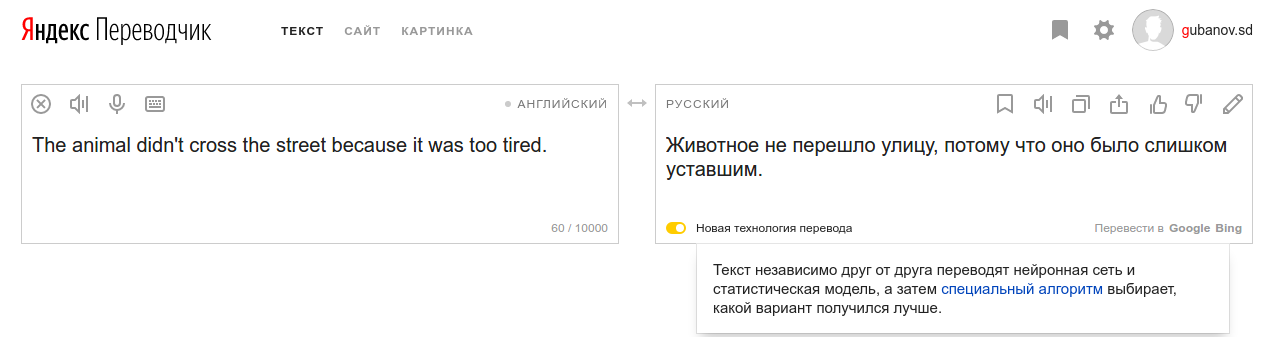
Система, основанная на переводе фраз, неявно предполагает, что каждая исходная фраза может быть переведена независимо от остальной части предложения. Звучит, как рецепт катастрофы, но в дискретной статистической модели это неизбежно, ведь добавка в модель всего лишь одного бита информации о контексте удвоила бы количество параметров. Это известное в нашем деле «проклятие размерности».
Единственная причина, по которой фразовый MП вообще работает, заключается в том, что для сшивания независимо переведенных фраз используется языковая модель. Эта модель обучена на больших объемах одноязычных данных и делает ортогональные предположения о независимости, которые часто могут компенсировать предположения о независимости на уровне фраз.
Состояния декодера и скрытые состояния
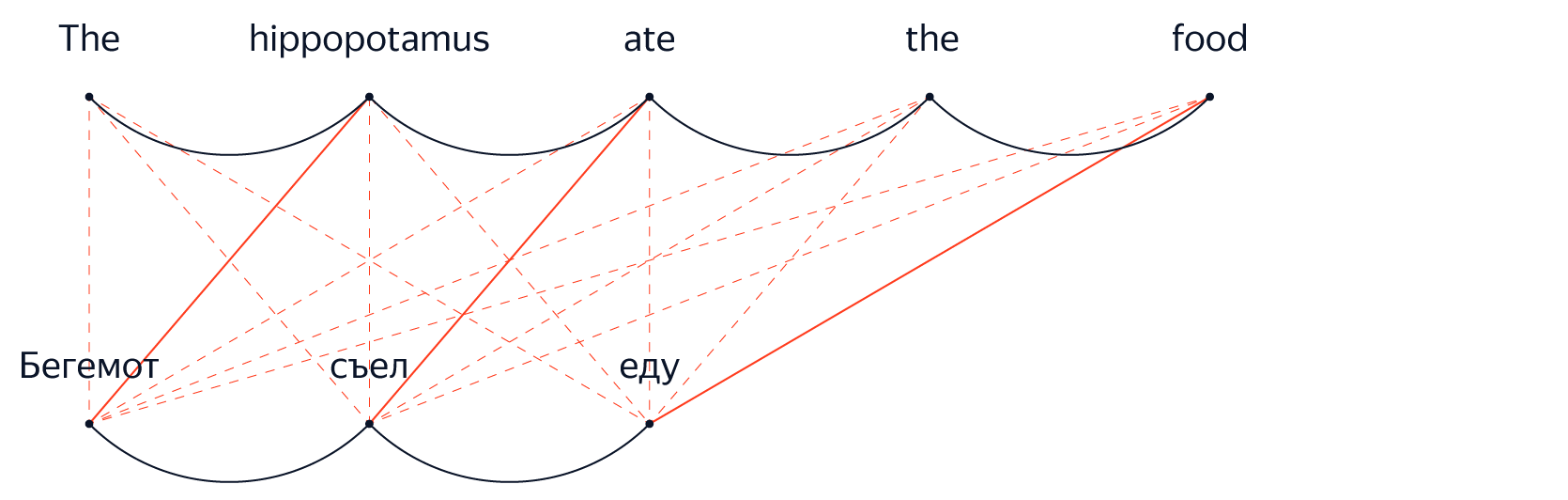
В системе ФМП приходилось на каждом шаге принимать решения, какие исходные слова мы «в данный момент» переводим (но на самом деле зачастую довольно сложно построить такое выравнивание между исходными и целевыми словами). В декодере НМП мы просто применяем преобразования к вектору скрытых состояний, пошагово генерируя целевые слова, пока сеть не решит остановиться (или пока мы её не остановим).
Вектор скрытых состояний, который обновляется на каждом шаге, может хранить информацию из любой части исходного предложения и любой части уже выполненного к этому моменту перевода. Это отсутствие «явных» предположений о независимости — пожалуй, самое важное различие между системами нейронного и фразового машинного перевода. Именно этим, скорее всего, и объясняется ощущение, что переводы нейронных систем более точно передают общую структуру и значение исходного предложения.
Вычисление динамических зависимостей
Впрочем, наивно утверждать, что модели НМП не делают никаких предположений о независимости просто потому, что они не исключают явным образом контекст, как это происходит в ФМП. Наиболее важные разработки в архитектурах НМП за последние несколько лет показывают, что ключ к улучшению качества — способность модели эффективно передавать информацию между различными частями предложения. Самый подходящий механизм для динамического и выборочного распространения информации из сгенерированных энкодером представлений для разных частей исходного предложения называется «внимание».
Научившись «обращать внимание» на различные части исходного и целевого предложений в процессе перевода, сеть пытается решить одну из фундаментальных проблем обработки естественного языка: как превратить линейную последовательность слов во что-то более структурированное, например, дерево.

Собираем все вместе
Нейронные и фразовые системы машинного перевода — совсем непохожие создания. В Яндекс.Переводчике многолетний опыт разработки системы ФМП. В прошлом году мы начали изучать возможности интеграции в наш сервис нейронного машинного перевода.
Будучи, помимо прочего, поисковиком, мы не испытывали нехватки обучающих данных для обеих систем. Судя по оценочным исследованиям, мы создали самую надежную в мире фразовую систему машинного перевода для пары английский—русский.
Очевидно, что последние архитектуры НМП могли дать результаты не хуже и даже лучше, чем наша фразовая система. Однако вдруг появились тревожные сигналы в поведении нашей нейронной системы — особенно при переводе пользовательских запросов.
Стоит отметить, что Яндекс.Переводчик стремится быть способным перевести всё, что могут предложить пользователи. И некоторые из них предлагают довольно странные вещи. В результате получается, мягко говоря, некоторое несоответствие обучающих и пользовательских данных.
Напомним, что наша система обучена на переводах, извлеченных из интернета. Это в основном высококачественные переводы, как правило, без проблем с орфографией, пунктуацией и прочими «мелочами», о которых пользователь, спешащий получить свой перевод, может не очень-то заботиться. По тематике, содержанию и стилю тексты, которые нужно переводить нашим пользователям, зачастую сильно отличаются от документов, попадающих в наш обучающий корпус.
В то время как среднее качество переводов системы ФМП ниже, чем у НМП, дисперсия воспринимаемого качества переводов НМП может быть намного выше.
Похоже, этому есть два объяснения:
- ФМП лучше запоминает редкие слова и фразы, поэтому у нее меньше «пробелов» в знании языка.
- НМП обращает намного больше внимания на контекст, поэтому некоторый шум во входном сигнале может повлиять на весь перевод.
ФМП просто заучивает фразы из корпуса, поэтому, когда дело доходит до низкочастотных входных данных, он имеет явное преимущество над НМП. С другой стороны, НМП должен увидеть слово несколько раз, чтобы построить приемлемое векторное представление. Он также очень старается моделировать зависимости в данных, поэтому, если сталкивается с мусором во входных данных, легко может производить в десять раз больше мусора в выходных.
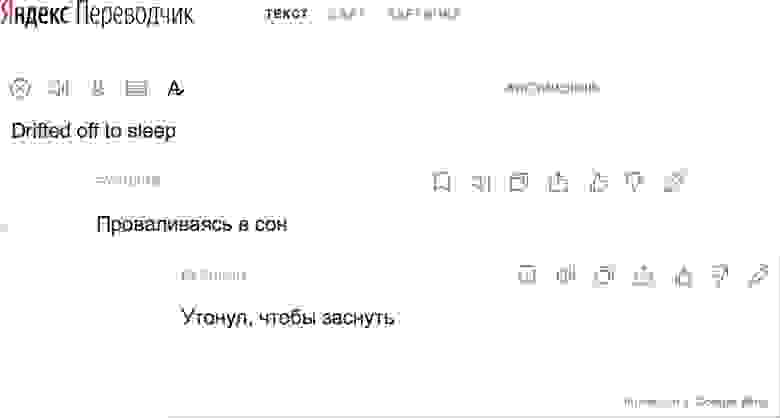
Примеры стьюпидов
Это не совсем то, что мы хотели видеть, когда готовились рассказать, насколько лучше стали наши переводы благодаря нейронным сетям.
Требуется много времени, чтобы заработать доверие пользователя к продукту, но потерять это доверие можно в считанные секунды. Переводы вроде показанных выше, вероятно, хороший способ добиться именно потери доверия.
Хуже того, не все пользователи нашего сервиса смогут оценить адекватность переводов, ведь не все знают исходный или целевой язык. Наш долг перед ними — избегать таких наихудших переводов.
Лучшее из двух миров
Две наши системы машинного перевода — фразовая и нейронная — вели себя совершенно по-разному на одних и тех же входных данных. Каждая из них при этом демонстрировала довольно высокое качество перевода. Поэтому мы вспомнили, чему нас учили на первом курсе анализа данных и построили ансамблевую систему. Несходство систем часто служит ключом к успешному ансамблю.
Вместо того чтобы комбинировать две системы во время декодирования каким-нибудь сложным способом, мы избрали более простой подход: выбирать результат одной из двух систем. Для этого мы обучили классификаторы с использованием CatBoost.

Первый классификатор, обученный на небольшом, размеченном вручную наборе стьюпидов, выявил особенно катастрофические сбои в модели НМП. Второй, обученный предсказывать разницу в баллах BLEU между выходными данными двух систем на большем наборе пар параллельных предложений, использовался, чтобы выловить менее очевидные ошибки. Такие, например, как недоперевод, когда нейронная сеть просто отказывается сотрудничать и оставляет часть исходного предложения непереведенной.
Как справиться с несоответствием доменов
Вишенка на торте
Пользователи Яндекса ежедневно отправляют миллионы запросов на перевод, при этом многократно приходится переводить множество одинаковых запросов. Как правило, эти запросы очень короткие, следовательно, в них не хватает контекста. К сожалению, нейронной системе довольно трудно переводить такие короткие запросы, так как очень немногие из примеров, на которых система обучена, состоят из отдельных слов или фраз. Несмотря на ансамбль и CatBoost, мы понимали, что иногда всей мощности глубокого обучения может быть недостаточно, чтобы дать нашим пользователям лучший результат.

Яндекс.Переводчик гордится словарными статьями, которые он предлагает пользователям. Словари Яндекса создаются автоматически с помощью хорошо настроенного конвейера машинного обучения, оптимизированного с использованием обратной связи от пользователей и краудсорсинговой платформы Яндекса — Толоки.
Мы решили, что включив лучшие переводы из этих словарных статей в нашу систему в качестве ограничений, сможем значительно повысить качество машинного перевода для наиболее частотных запросов.
Адаптация к контексту
Последняя тема сегодняшнего поста — если машинный перевод достиг новых высот благодаря гибридному НМП, то откуда нам ожидать дальнейших улучшений?
Одна из малоисследованных областей в машинном переводе — использование контекста в максимально широком смысле. Контекст может включать предыдущее предложение в документе, некоторую информацию о лицах или сущностях, упомянутых в тексте, или просто информацию о том, из какого места на веб-странице взят текст, который мы в данный момент переводим.
По аналогии с восприятием контекста сегодняшними системами НМП на уровне предложения (что было не под силу предыдущему поколению ФМП), мы экспериментируем с включением все более разнообразных типов контекста в нашу систему перевода, чтобы лучше переводить текст в конкретных ситуациях и для различных задач.
Идея эта не слишком радикальна. Большинство переводчиков скажут, что чем больше контекста или справочной информации о переводимом тексте и его аудитории, тем проще будет их работа. В этом смысле системы машинного перевода не должны отличатся от людей. И у нас уже есть положительные результаты, показывающие, что работа в этом направлении стоит вложенных усилий.
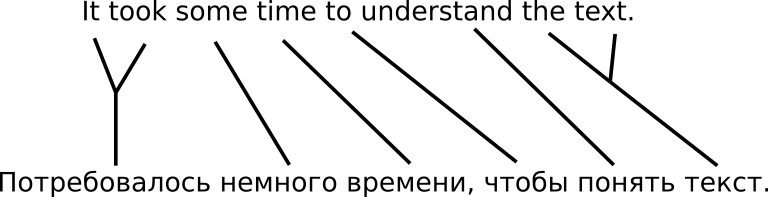
Например, экспериментальная система, которая при переводе использует предыдущее исходное предложение наряду с текущим. Кажется, сеть вполне способна научиться понимать, когда нужно «обратить внимание» на слова из предыдущего предложения. Это естественным образом срабатывает для местоимений, у которых есть антецеденты, что позволяет избежать неприятностей подобного рода:

Другой пример — система, которую мы планируем в ближайшее время запустить на Яндекс.Браузере.
Каждый день миллионы пользователей переводят страницы благодаря нашей интеграции в Яндекс.Браузере. Поскольку структура HTML-страницы позволяет легко определить, где находится текст — в навигационном компоненте, заголовке или блоке с контентом, мы решили использовать эту информацию для улучшения наших переводов.
Понятно, что во многих случаях наилучшим переводом слова «Home», вероятно, будет «Домой». Однако на навигационной панели веб-сайта оно наверняка должно быть переведено как «Главная». Точно так же «Back», вероятно, лучше всего перевести в таком контексте как «Назад», а не «Спина».

Автоматически разметив обучающую выборку извлеченных из интернета параллельных текстов метками «навигация», «заголовок», «содержание», а затем настроив нашу систему так, чтобы она предсказывала эти метки в процессе перевода, мы значительно повысили качество в конкретных видах перевода.
Конечно, мы могли бы добиться всего лишь переобучения системы на этом довольно специфическом распределении. Поэтому, чтобы избежать снижения производительности в более стандартных областях, мы включили в расчет функции потерь при обучении расстояние Ку́льбака—Ле́йблера между предсказаниями нашей адаптированной модели и предсказаниями нашей общей системы. Фактически это штрафование модели за чрезмерное изменение предсказаний.

Как видно из графиков, качество для данных в домене значительно возрастает, и как только наша функция потерь дополняется учетом расстояния Кульбака—Лейблера, рост качества больше не приводит к ухудшению перевода для документов вне домена.
Очень скоро мы запустим эту систему на Яндекс.Браузере. Надеемся, это только первое из целого ряда улучшений, которые мы сделаем на основе лучшего понимания пользовательского контекста и «неоправданной эффективности [рекуррентных] нейронных сетей».

{kind=link}