
С 10 по 22 сентября пройдет конкурс Яндекс.Блиц по мобильной разработке. Регистрация открыта. Блиц — это короткий путь в Яндекс: участникам топ-5 будет достаточно успешно пройти одну секцию собеседования вместо стандартных четырех, чтобы получить предложение по работе.
По случаю конкурса мы поговорили с коллегами об интересных задачах, относящихся сразу и к мобильным платформам, и к алгоритмам. Сегодня мы поделимся их историями с читателями Хабра.
Есть мнение, что разработка мобильных приложений — нечто особенное, далекое от программирования в общем смысле, и специалисты, которые пишут под Android и iOS, никогда не сталкиваются с решением алгоритмоемких задач, ограничиваясь подключением готовых библиотек, версткой экранов, написанием простейшей бизнес-логики и исследованием багов конкретной платформы. Но не всё так просто.
Создание софта для мобильных устройств всегда сопряжено с ограничениями. Даже в топовых девайсах не такие мощные CPU и GPU и не так много памяти, как в современном компьютере. При этом основную часть рынка составляют бюджетные смартфоны с еще более слабым железом. Их владельцы особенно сильно страдают от нехватки ресурсов.
Разработка сложного конкурентоспособного проекта невозможна без использования решений, которые справляются с задачами быстрее, чем за квадратичное время. Пользователи могут уйти к конкуренту, если им не понравится скорость работы или то, как ваше приложение расходует заряд аккумулятора.
Исторически Блиц — это конкурс на знание алгоритмов и умение воплотить идею решения в коде. Блиц, который пройдет в сентябре, не станет исключением. Мы постарались отобрать задачи с алгоритмами, похожими на те, которые приходилось применять мобильным разработчикам Яндекса в реальных проектах для Android и iOS.
Михаил Ефимов, ведущий разработчик:
Сергей Кузнецов, ведущий разработчик:
Александр Яшкин, руководитель группы бэкенда портала:
Олег Максименко, ведущий разработчик:
По случаю конкурса мы поговорили с коллегами об интересных задачах, относящихся сразу и к мобильным платформам, и к алгоритмам. Сегодня мы поделимся их историями с читателями Хабра.

Есть мнение, что разработка мобильных приложений — нечто особенное, далекое от программирования в общем смысле, и специалисты, которые пишут под Android и iOS, никогда не сталкиваются с решением алгоритмоемких задач, ограничиваясь подключением готовых библиотек, версткой экранов, написанием простейшей бизнес-логики и исследованием багов конкретной платформы. Но не всё так просто.
Создание софта для мобильных устройств всегда сопряжено с ограничениями. Даже в топовых девайсах не такие мощные CPU и GPU и не так много памяти, как в современном компьютере. При этом основную часть рынка составляют бюджетные смартфоны с еще более слабым железом. Их владельцы особенно сильно страдают от нехватки ресурсов.
Разработка сложного конкурентоспособного проекта невозможна без использования решений, которые справляются с задачами быстрее, чем за квадратичное время. Пользователи могут уйти к конкуренту, если им не понравится скорость работы или то, как ваше приложение расходует заряд аккумулятора.
Исторически Блиц — это конкурс на знание алгоритмов и умение воплотить идею решения в коде. Блиц, который пройдет в сентябре, не станет исключением. Мы постарались отобрать задачи с алгоритмами, похожими на те, которые приходилось применять мобильным разработчикам Яндекса в реальных проектах для Android и iOS.
Ускорение работы саджеста Браузера
Михаил Ефимов, ведущий разработчик:
— Я занимался омнибоксом — поисковой строкой Браузера. В ней работает автозаполнение — достаточно ввести начало слова, и мы предложим слово целиком. Исходная задача может быть упрощена до следующей: получив на вход некоторую строку, найти все слова из заранее заданного множества, в которых введенная строка встречается в виде подстроки. Чтобы это сделать, мы берем все суффиксы слова — все подстроки, которыми оно заканчивается. Например, для слова «стол» это будет «cтол» и «тол». Суффиксы из одного и двух символов — здесь у нас были бы «ол» и «л» — не учитываем, потому что по ним в саджест попадает мусор.
Таким образом, вместо одного слова мы получаем два. Если бы оно состояло из пяти букв — получили бы три, и т. д. Дальше из них, например, можно построить хорошо известную структуру данных trie, которая позволяет по ним искать. Но у этой структуры есть недостаток — она может занимать очень много места в памяти.
Мы, в свою очередь, хранили отсортированный список суффиксов — suffix array. Элементом в массиве является не суффикс целиком — тогда бы структура занимала слишком много памяти, квадратичное количество, — а просто пара указателей. Первый из них указывает на слово или фразу, которую нужно использовать, второй — на символ в слове или фразе, с которого начинается суффикс. Такой подход отлично экономит память. У нас только два указателя, два восьмибайтовых числа вместо очень длинных слов.
Дальше возникает вопрос, как хранить уже отсортированный список. Можно хранить как простой массив — но в него тогда будут очень долго вставляться новые вхождения. Поэтому я выбрал для хранения «дополненное» двоичное дерево поиска — augmented binary search tree. В качестве ключа каждый узел дерева содержит определенный суффикс определенного слова, а в качестве «дополнения» в узлах хранится информация по приоритетам. Все, что нужно сделать, — найти узел дерева, соответствующий введенному префиксу. Дальше можно анализировать этот и соседние узлы, чтобы понять, какие из слов можно использовать для выдачи.
Среди них выбираются те, у которых выше приоритет. На приоритет влияет длина отступа суффикса от начала слова. У слов с нулевым отступом приоритет выше — скажем, если пользователь ввел «ст», то слово «стол» окажется гораздо выше по приоритету, чем слово «мост». Но в принципе можно ввести такую последовательность символов, что Браузер в ответ посоветует слово, где эта последовательность встречается в середине или конце. Например — если нет слова, которое начинается с этой последовательности.
Отображение камер видеонаблюдения на мобильных Яндекс.Картах
Сергей Кузнецов, ведущий разработчик:
— У нас был алгоритм, который отображал камеры на карте. Он работал за квадратичное время, не очень быстро. Возникла мысль, что можно его улучшить, причем не прибегая к каким-то изыскам.
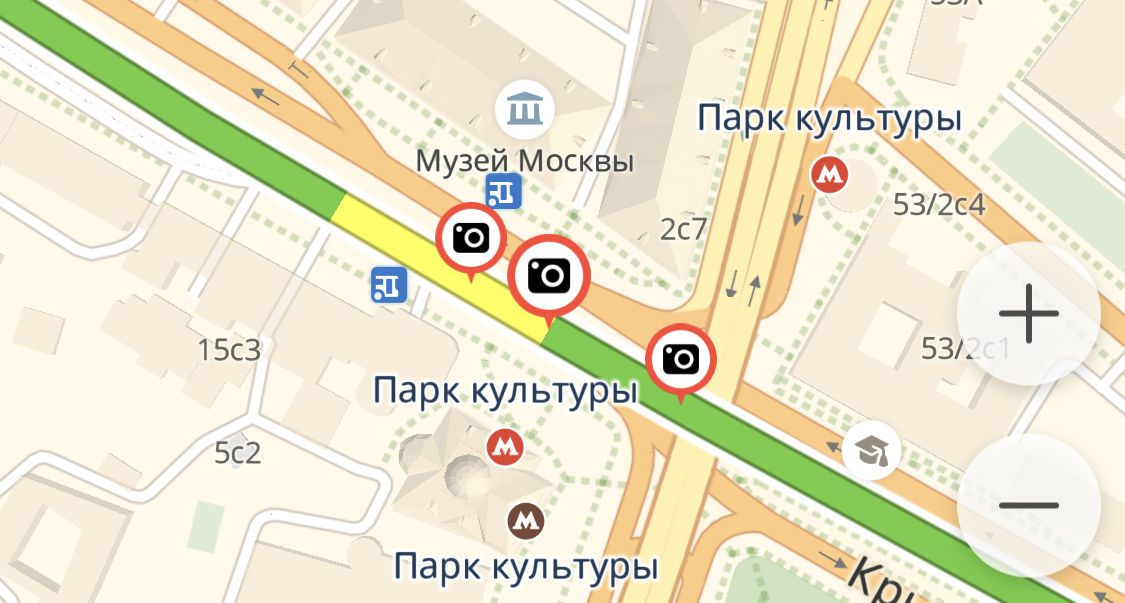
Если говорить про постановку задачи, то у нас было множество камер, которые нужно отображать. На высоких масштабах карты они могли друг с другом пересекаться, и это было некрасиво — требовалось отображать одну камеру вместо множества пересекающихся.
Если эту задачу формализовать, то она сводилась к следующей: на плоскости есть n одинаковых квадратов со сторонами, параллельными осям координат, и нужно из них выбрать такое множество квадратов, чтобы внутри него они не пересекались, а все остальные квадраты пересекались хотя бы с одним из квадратов исходного множества. Простейший алгоритм решения — когда мы выбирали какой-нибудь квадрат и пересекали его со всеми остальными — работал за n2. Но задачу можно решить и за n*log(n), используя некий класс алгоритмов, который в литературе называется «сканирующая прямая». Если не знать о таком подходе, то такую задачу, конечно, можно решить, но если знать — она решается гораздо проще. Сразу знаешь, в каком направлении думать.

Камеры на мобильных Картах. Если уменьшить масштаб, остается только один значок
Получение данных от одного из источников саджеста Браузера
Александр Яшкин, руководитель группы бэкенда портала:
— Существует несколько «тяжелых» источников подсказок, которые выводятся при наборе текста в омнибоксе Браузера. Один из таких источников — локальная история пользователя. Подсказки из истории выгружает исторический провайдер — компонент приехал к нам из Chromium. В чем особенность омнибокса? Он должен быть очень быстр, подсказывать сразу же, по мере набора текста, поэтому источники в основном синхронные. При старте браузера провайдер строит быстрый индекс подсказок по истории за последнюю неделю. В Chromium индекс истории для омнибокса использовал ассоциативные контейнеры std::set и std::map из стандартной библиотеки C++. Для хранения данных внутри таких контейнеров обычно применяется красно-черное дерево.
У нас была задача ускорить поиск по истории в омнибоксе. По гистограммам от пользователей мы видели, что исторический поиск занимает больше всего времени, и на медленных компьютерах люди действительно страдают. У некоторых ожидание составляло одну десятую секунды — когда ты быстро набираешь символы в омнибоксе, это слишком долго, а бывает еще хуже.
Я сделал несколько подходов, оптимизаций, апстримов в Chromium. Параллельно вносил изменения в наш код. Затем задача перешла к нашему разработчику Денису Ярошевскому. Он достаточно увлеченный разработчик — интересуется C++, STL, алгоритмами. Покопавшись, он предложил поступить кардинально: заменить std::set на flat_set, а std::map на flat_map. То есть просто поменять базовые структуры. std::set и std::map хранят свои элементы в узлах дерева, а flat_set и flat_map, по сути, являются обертками над сортированным вектором. Flat-контейнеры — одни из самых популярных контейнеров, не входящих в стандартную библиотеку C++. Возможно, в следующем стандарте они все-таки в нее попадут.
Вначале было некоторое недоверие: предлагаемый путь казался слишком простым, лежал на поверхности. Чтобы доказать эффективность, мы сделали perf test: взяли профиль одного из наших коллег, построили из него индекс истории и прогнали на нем популярные запросы. Выбрали штук 10 запросов и посчитали времена. Денис показал мне результат, улучшения были очевидны, и я в его идею тоже поверил.
Найденная проблема не была специфичной для Яндекс.Браузера. Она сказывалась в любом Chromium-based-браузере, поэтому сначала мы, как участники проекта Chromium, решили сделать апстрим. Но в Chromium много кто коммитит, и часть предлагаемых идей — дикие. У разработчиков Chromium достаточно настороженное отношение ко всем, кто снаружи предлагает что-то поменять, тем более кардинально. Наш патч сначала не хотели брать. Предложили перед этим доказать эффективность и написать мини-design-doc, чтобы они могли понять идею, выгоду и покритиковать предложение.
Кроме того, они сказали: раз вам нужно, напишите и добавьте отдельные реализации flat-контейнеров. Не добавляйте к нам в проект никаких новых библиотек — реализации уже существуют в boost, eastl. Flat-контейнеры предстояло добавить в base-компоненты Chromium. Это аналог стандартной библиотеки, и хромиумцы очень переживают, чтобы в нее не попало ничего лишнего.
Денис Ярошевский всем этим занялся, потратил время на написание design-документа, написал на C++-шаблонах реализацию flat_set, применил массу шаблонной магии, написал тесты, покрывающие функциональность контейнеров, создал еще один синтетический perf test — мы же не могли отправлять perf test с настоящим профилем коллеги. Денис спорил с владельцами кода base и омнибокса, существенно переработал код по результатам ревью — и наконец поборол их и заапстримил код в Chromium.
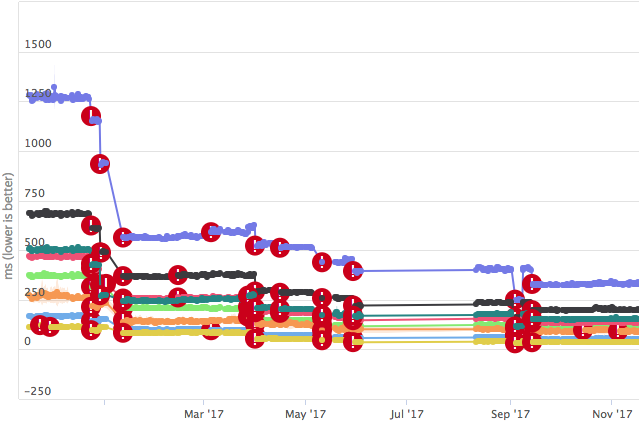
Вся эта эпопея длилась месяцев шесть. Хромиумцы затем написали: «Да, мы действительно увидели 10–20% улучшения на всех гистограммах. Классно, спасибо!». От них это уже через даунстрим пришло к нам в браузер, и потом хэппи-энд. Действительно, исторический индекс значительно ускорился на всех конфигурациях, на всех платформах. В этом индексе преимущества flat-контейнеров проявились гораздо лучше, чем недостатки.
После апстрима flat_set и flat_map стали использовать гораздо чаще — сейчас в коде можно встретить несколько сотен мест, где они задействованы. Мораль — терпение и труд все перетрут, и внимательно выбирайте для своего кода не только алгоритмы, но и подходящие структуры данных.

См. левую часть графика. Резкое снижение времени загрузки результатов омнибокса в начале 2017 года связано именно с переходом на flat_set и flat_map
Ускорение работы одного из HashMap в Chromium
Олег Максименко, ведущий разработчик:
— Задача была ускорить сохранение обычных HTML-страниц в одном из наших подпроектов. Я воспользовался стандартными средствами профилирования кода — посмотрел, какие куски кода «горячие» в процессе сохранения. Наткнулся на неожиданное место. То есть это не основная логика, а просто поиск по контейнеру HashMap, который должен занимать какой-то небольшой процент от общего времени работы. Вместо этого там наблюдались действительно сильные затраты.
Я решил заменить имеющуюся реализацию. Это был внутренний HashMap, из Chromium. Я его заменил и получил выигрыш в несколько раз. Затем я пошел немножко дальше и убедился, что это не ошибка ребят из Google, что дело не в реализации всего HashMap, а в хэш-функции. Это внешняя вещь. И получилось, что у них в коде, который мы использовали, был тривиальный хеш, в качестве хеша использовался адрес в памяти. Возможно, из-за каких-то особенностей, например небольшого объема, такое решение их устраивало. Может быть, у них HashMap и не был горячим местом, а у нас стал, когда мы применили эту структуру. Простой заменой наивной и тривиальной хеш-функции на std::hash мы получили прирост скорости в 3–10 раз. В результате это обращение к хеш-памяти пропало из списка горячих мест, стало занимать уже какой-то небольшой процент, как и ожидалось сначала. Все стало хорошо и красиво.
