
Успех в проектах по машинному обучению обычно связан не только с умением применять разные библиотеки, но и с пониманием той области, откуда взяты данные. Отличной иллюстрацией этого тезиса стало решение, предложенное командой Алексея Каюченко, Сергея Белова, Александра Дроботова и Алексея Смирнова в конкурсе PIK Digital Day. Они заняли второе место, а спустя пару недель рассказали о своём участии и построенных моделях на очередной ML-тренировке Яндекса.
Алексей Каюченко:
— Добрый день! Мы расскажем о соревновании PIK Digital Day, в котором мы участвовали. Немного о команде. Нас было четыре человека. Все с абсолютно разным бэкграундом, из разных областей. На самом деле, мы на финале познакомились. Команда сформировалась буквально за день до финала. Я расскажу про ход конкурса, организацию работы. Потом выйдет Сережа, он расскажет про данные, а Саша расскажет уже про сабмишен, про финальный ход работы и про то, как мы двигались по лидерборду.

Вкратце о конкурсе. Задачка была очень прикладная. ПИК организовал этот конкурс, предоставив данные по продажам квартир. В качестве обучающего дата-сета была история с атрибутами за 2 с половиной года по Москве и Московской области. Конкурс состоял из двух этапов. Это был онлайн-этап, где каждый из участников индивидуально пытался сделать свою модель, и офлайн-этап, не такой долгий, всего один день с утра до вечера. В него попали лидеры онлайн-этапа.

Наши места по итогам онлайн-конкурса были даже не в топ-10, и даже не в топ-20. Мы там были на местах 50+. На самом финале, то есть офлайн-этапе, было 43 команды. Было очень много команд, состоящих из одного человека, хотя можно было объединяться. Около трети команд были больше одного человека. На финале было два конкурса. Первый конкурс — модель без ограничений. Можно было использовать любые алгоритмы: deep learning, machine learning. Параллельно проходил конкурс на лучшее решение линейной регрессии. Организатор посчитал, что линейная регрессия тоже достаточно прикладная, поскольку сам конкурс в целом был очень прикладной. То есть ставилась прикладная задачка — нужно было спрогнозировать объем продаж квартир, имея исторические данные за предыдущие 2,5 года с атрибутами.
Наша команда заняла второе место в конкурсе на лучшую модель без ограничений и первое место в конкурсе на лучшую регрессию. Двойной приз.

Про общий ход организации могу сказать, что финал был очень напряженный, достаточно стрессовый. Например, наше победное решение было загружено буквально за две минуты до стоп-игры. Предыдущее решение нас ставило, по-моему, на четвертое или пятое место. То есть мы работали до конца, не расслабляясь. ПИК очень хорошо все организовал. Там были такие столы, была даже верандочка, чтобы можно было посидеть на улице, подышать свежим воздухом. Еда, кофе, все было предоставлено. На картинке видно, что все сидели по своим группкам, работали.
Сергей расскажет больше про данные.
Сергей Белов:
— Спасибо. ПИК предоставил нам несколько файлов с данными. Два основных — train.csv и test.csv, в которых было примерно 50 фич, сгенеренных самим ПИК. Train состоял примерно из 10 тысяч строк, test — из 2 тысяч.
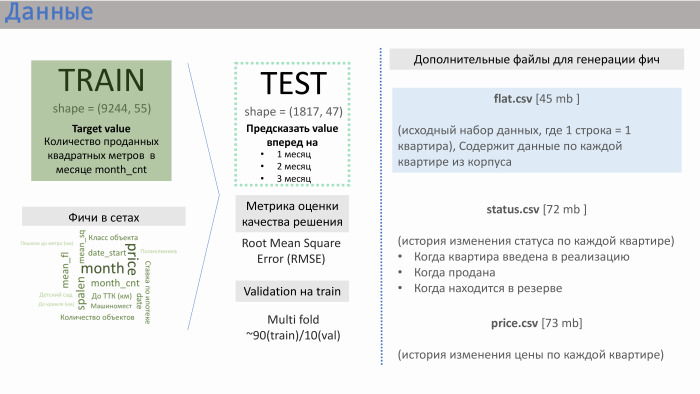
Что предоставляла из себя строка? Она содержала данные по продажам. То есть в качестве value (в данном случае — target) у нас были продажи по квадратным метрам для квартир, усредненных по конкретному корпусу. Было примерно 10 тысяч таких строк. Фичи в сетах, которые нагенерил сам ПИК, приведены на слайде с примерной значимостью, которую мы получили.
Мне тут помог опыт работы в девелоперских компаниях. Такие фичи, как расстояние квартиры до Кремля или до Транспортного кольца, количество машиномест, — они не очень сильно влияют на продажи. Влияние оказывают класс объекта, спальность, и, что особенно важно, количество квартир в реализации в данный момент. ПИК не сгенерил эту фичу, но они предоставили нам три дополнительных файла: flat.csv, status.csv и price.csv. И мы решили взглянуть на flat.csv, поскольку там как раз были данные по количеству квартир, по их статусу.
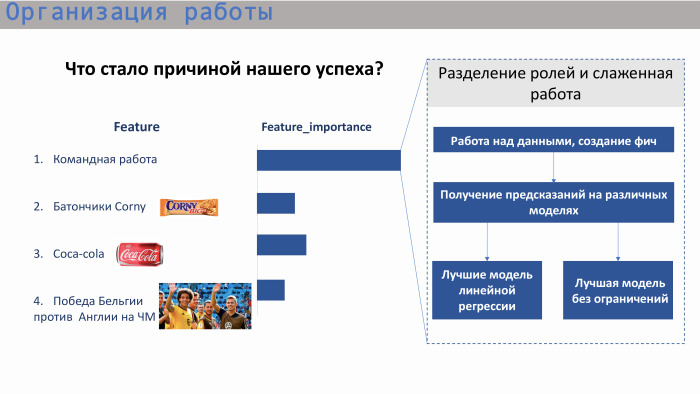
И если задаваться вопросом, что послужило успехом нашего решения, то это определенная командная работа. Мы с самого начала этого соревнования работали очень слаженно. Мы сразу обсудили где-то минут за 20, чем мы будем заниматься. Пришли к общему выводу, что первым делом надо работать с данными, потому что любой data scientist понимает: в данных очень много заложено и часто победа получается из-за какой-то фичи, которую команда сгенерила. После работы с данными мы, в первую очередь, использовали различные модели. Мы решили посмотреть, какой результат дают наши фичи в каждой из этих моделей, и дальше сделали акцент на модели без ограничений и модели линейной регрессии.
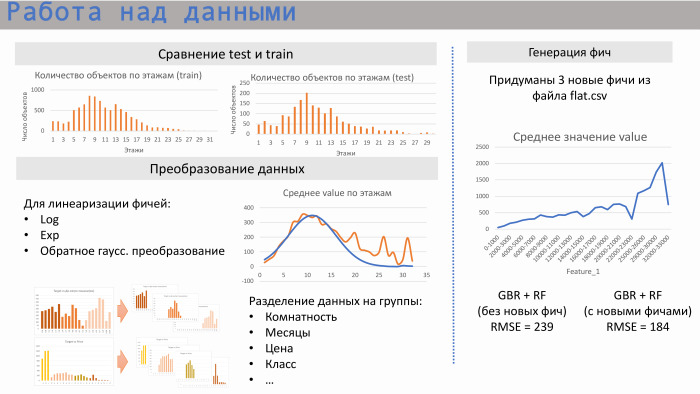
Мы начали работать с данными. Первым делом мы посмотрели, как между собой соотносятся тесты train set, то есть пересекаются ли области этих данных. Да, они пересекаются: и по количеству квартир, и по спальности, и по некой средней этажности.
Дальше для линейной регрессии мы начали выполнять некие преобразования. Это как стандартные логарифмы экспоненты. Например, в случае со средним этажом это было обратное гауссовское преобразование для линеаризации. Также мы заметили, что иногда лучше разделить данные по группам. Если мы берем, например, расстояние от квартиры до метро или ее комнатность, то там немножко другие рынки, и лучше разделить, делать различные модели для каждой такой группы.
Из файла flat.csv мы сгенерили три фичи. Одна из них представлена здесь. Видно, что она имеет достаточно хорошую линейную зависимость, кроме этого проседания. Что это была за фича? Она соответствовала количеству квартир, которые находятся в реализации на данный момент. И эта фича очень хорошо работает при низких значениях. То есть не может быть больше проданных квартир, чем то количество, которое находится в реализации. Но в этих файлах, на самом деле, был заложен некий человеческий фактор, потому что они часто составляются человеком. Мы прямо видели там точки, которые выбиваются из этого района, потому что они были забиты немножко неправильно.
Пример из scikit-learn. Модель из GBR и Random Forest без фич давала RMSE 239, а с тремя этими фичами — 184.
Саша расскажет про модели, которые мы использовали.
Александр Дроботов:
— Пару слов про наш подход. Как ребята уже сказали, мы все разные, пришли из разных сфер, разное образование. И подходы были у нас разные. На финальном этапе Леша больше использовал XGBoost от Яндекса (скорее всего, имеется в виду CatBoost — прим. ред.), Сережа — библиотеку scikit-learn, я — LightGBM и линейную регрессию.

Модели XGBoost, линейная регрессия и Prophet — три варианта, которые показали у нас самый лучший score. Для линейной регрессии у нас был блендинг из двух моделей, а для общего конкурса — XGBoost, и мы добавили немножко линейной регрессии.

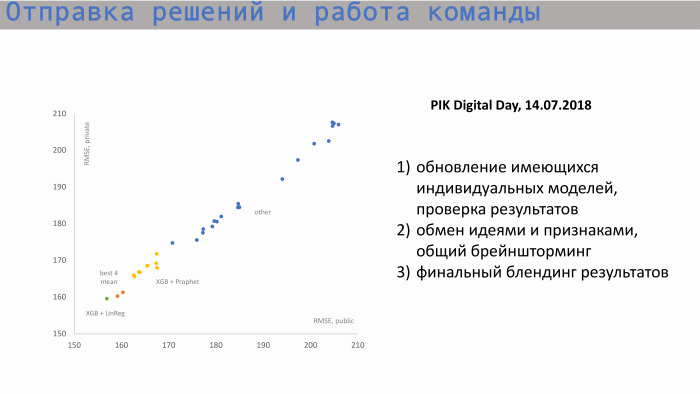
Вот процесс отправки решений и работы команды. На графике слева по оси X — public RMSE, значение метрики, а по оси Y — значение private score, RMSE. Мы начинали примерно с этих позиций. Здесь индивидуальные модели каждого из участников. Затем, после обмена идеями и создания новых фич, мы начали приближаться к нашему самому лучшему score. Наши значения по индивидуальным моделям были примерно такими. Самая лучшая индивидуальная модель — XGBoost и Prophet. Prophet создавал прогноз для накопленных продаж. Там был такой признак, как start square. То есть мы знали, какое количество квартир у нас total, понимали, какое значение историческое, и incremental-значение стремилось к total-значению. Prophet строил прогноз на будущее, выдавал значения в следующих периодах и подавал их в XGBoost.
Блендинг наших лучших индивидуальных score находится где-то здесь, вот эти две оранжевые точки. Но этого score нам не хватало, чтобы попасть в топ.
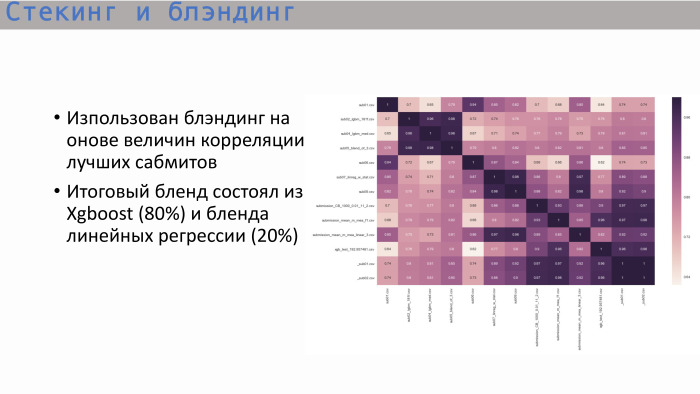
Изучив обычную матрицу корреляции самых лучших сабмитов, мы увидели следующее: деревья — и это логично — показывали корреляцию, близкую к единице, а самое лучшее дерево давал XGBoost. Он показывает не такую высокую корреляцию с линейной регрессией. Мы решили заблендить эти два варианта в пропорции 8 к 2. Именно так мы и получили самое лучшее финальное решение.
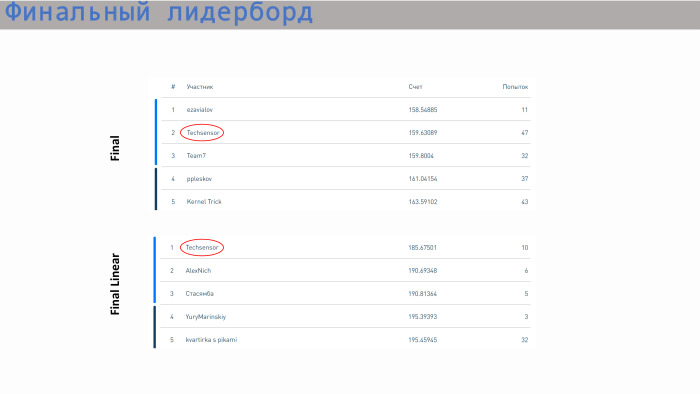
Это лидерборд с результатами. Наша команда заняла второе место по моделям без ограничений и первое место по линейным моделям. Что касается score — здесь все значения довольно близкие. Разница не очень большая. По линейной регрессии уже идет шаг в районе 5. У нас все, спасибо!
Алексей Каюченко:
— Добрый день! Мы расскажем о соревновании PIK Digital Day, в котором мы участвовали. Немного о команде. Нас было четыре человека. Все с абсолютно разным бэкграундом, из разных областей. На самом деле, мы на финале познакомились. Команда сформировалась буквально за день до финала. Я расскажу про ход конкурса, организацию работы. Потом выйдет Сережа, он расскажет про данные, а Саша расскажет уже про сабмишен, про финальный ход работы и про то, как мы двигались по лидерборду.

Вкратце о конкурсе. Задачка была очень прикладная. ПИК организовал этот конкурс, предоставив данные по продажам квартир. В качестве обучающего дата-сета была история с атрибутами за 2 с половиной года по Москве и Московской области. Конкурс состоял из двух этапов. Это был онлайн-этап, где каждый из участников индивидуально пытался сделать свою модель, и офлайн-этап, не такой долгий, всего один день с утра до вечера. В него попали лидеры онлайн-этапа.
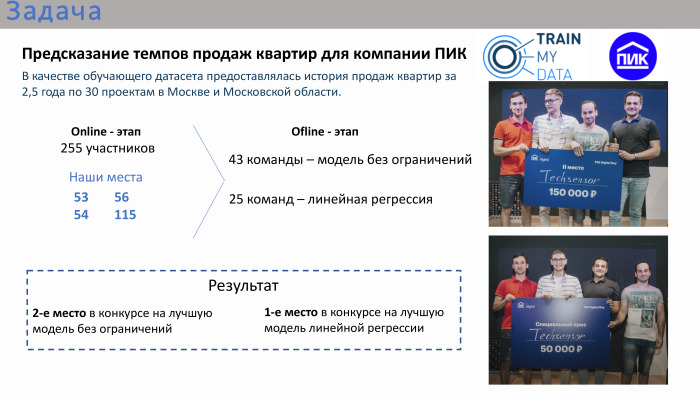
Наши места по итогам онлайн-конкурса были даже не в топ-10, и даже не в топ-20. Мы там были на местах 50+. На самом финале, то есть офлайн-этапе, было 43 команды. Было очень много команд, состоящих из одного человека, хотя можно было объединяться. Около трети команд были больше одного человека. На финале было два конкурса. Первый конкурс — модель без ограничений. Можно было использовать любые алгоритмы: deep learning, machine learning. Параллельно проходил конкурс на лучшее решение линейной регрессии. Организатор посчитал, что линейная регрессия тоже достаточно прикладная, поскольку сам конкурс в целом был очень прикладной. То есть ставилась прикладная задачка — нужно было спрогнозировать объем продаж квартир, имея исторические данные за предыдущие 2,5 года с атрибутами.
Наша команда заняла второе место в конкурсе на лучшую модель без ограничений и первое место в конкурсе на лучшую регрессию. Двойной приз.

Про общий ход организации могу сказать, что финал был очень напряженный, достаточно стрессовый. Например, наше победное решение было загружено буквально за две минуты до стоп-игры. Предыдущее решение нас ставило, по-моему, на четвертое или пятое место. То есть мы работали до конца, не расслабляясь. ПИК очень хорошо все организовал. Там были такие столы, была даже верандочка, чтобы можно было посидеть на улице, подышать свежим воздухом. Еда, кофе, все было предоставлено. На картинке видно, что все сидели по своим группкам, работали.
Сергей расскажет больше про данные.
Сергей Белов:
— Спасибо. ПИК предоставил нам несколько файлов с данными. Два основных — train.csv и test.csv, в которых было примерно 50 фич, сгенеренных самим ПИК. Train состоял примерно из 10 тысяч строк, test — из 2 тысяч.
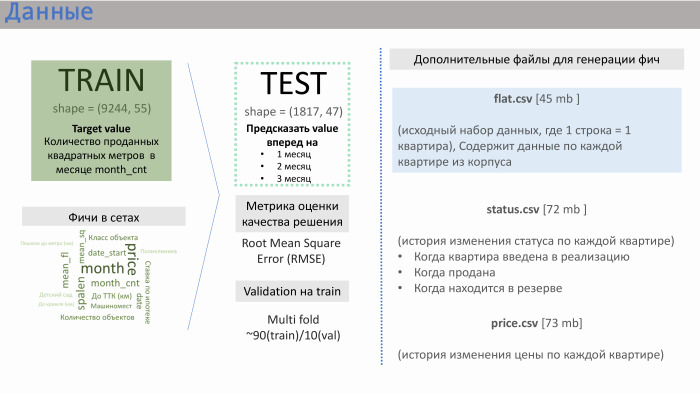
Что предоставляла из себя строка? Она содержала данные по продажам. То есть в качестве value (в данном случае — target) у нас были продажи по квадратным метрам для квартир, усредненных по конкретному корпусу. Было примерно 10 тысяч таких строк. Фичи в сетах, которые нагенерил сам ПИК, приведены на слайде с примерной значимостью, которую мы получили.
Мне тут помог опыт работы в девелоперских компаниях. Такие фичи, как расстояние квартиры до Кремля или до Транспортного кольца, количество машиномест, — они не очень сильно влияют на продажи. Влияние оказывают класс объекта, спальность, и, что особенно важно, количество квартир в реализации в данный момент. ПИК не сгенерил эту фичу, но они предоставили нам три дополнительных файла: flat.csv, status.csv и price.csv. И мы решили взглянуть на flat.csv, поскольку там как раз были данные по количеству квартир, по их статусу.
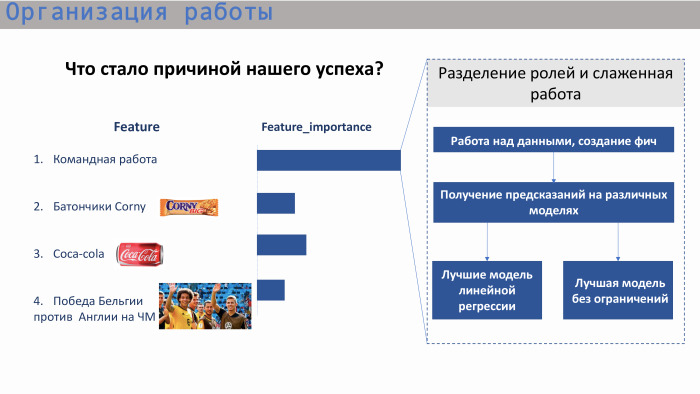
И если задаваться вопросом, что послужило успехом нашего решения, то это определенная командная работа. Мы с самого начала этого соревнования работали очень слаженно. Мы сразу обсудили где-то минут за 20, чем мы будем заниматься. Пришли к общему выводу, что первым делом надо работать с данными, потому что любой data scientist понимает: в данных очень много заложено и часто победа получается из-за какой-то фичи, которую команда сгенерила. После работы с данными мы, в первую очередь, использовали различные модели. Мы решили посмотреть, какой результат дают наши фичи в каждой из этих моделей, и дальше сделали акцент на модели без ограничений и модели линейной регрессии.
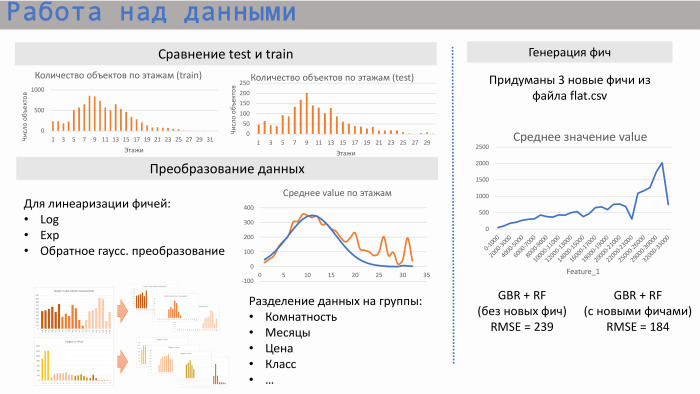
Мы начали работать с данными. Первым делом мы посмотрели, как между собой соотносятся тесты train set, то есть пересекаются ли области этих данных. Да, они пересекаются: и по количеству квартир, и по спальности, и по некой средней этажности.
Дальше для линейной регрессии мы начали выполнять некие преобразования. Это как стандартные логарифмы экспоненты. Например, в случае со средним этажом это было обратное гауссовское преобразование для линеаризации. Также мы заметили, что иногда лучше разделить данные по группам. Если мы берем, например, расстояние от квартиры до метро или ее комнатность, то там немножко другие рынки, и лучше разделить, делать различные модели для каждой такой группы.
Из файла flat.csv мы сгенерили три фичи. Одна из них представлена здесь. Видно, что она имеет достаточно хорошую линейную зависимость, кроме этого проседания. Что это была за фича? Она соответствовала количеству квартир, которые находятся в реализации на данный момент. И эта фича очень хорошо работает при низких значениях. То есть не может быть больше проданных квартир, чем то количество, которое находится в реализации. Но в этих файлах, на самом деле, был заложен некий человеческий фактор, потому что они часто составляются человеком. Мы прямо видели там точки, которые выбиваются из этого района, потому что они были забиты немножко неправильно.
Пример из scikit-learn. Модель из GBR и Random Forest без фич давала RMSE 239, а с тремя этими фичами — 184.
Саша расскажет про модели, которые мы использовали.
Александр Дроботов:
— Пару слов про наш подход. Как ребята уже сказали, мы все разные, пришли из разных сфер, разное образование. И подходы были у нас разные. На финальном этапе Леша больше использовал XGBoost от Яндекса (скорее всего, имеется в виду CatBoost — прим. ред.), Сережа — библиотеку scikit-learn, я — LightGBM и линейную регрессию.

Модели XGBoost, линейная регрессия и Prophet — три варианта, которые показали у нас самый лучший score. Для линейной регрессии у нас был блендинг из двух моделей, а для общего конкурса — XGBoost, и мы добавили немножко линейной регрессии.

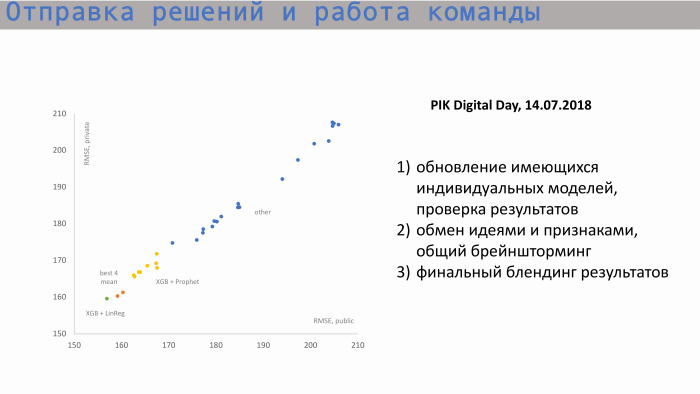
Вот процесс отправки решений и работы команды. На графике слева по оси X — public RMSE, значение метрики, а по оси Y — значение private score, RMSE. Мы начинали примерно с этих позиций. Здесь индивидуальные модели каждого из участников. Затем, после обмена идеями и создания новых фич, мы начали приближаться к нашему самому лучшему score. Наши значения по индивидуальным моделям были примерно такими. Самая лучшая индивидуальная модель — XGBoost и Prophet. Prophet создавал прогноз для накопленных продаж. Там был такой признак, как start square. То есть мы знали, какое количество квартир у нас total, понимали, какое значение историческое, и incremental-значение стремилось к total-значению. Prophet строил прогноз на будущее, выдавал значения в следующих периодах и подавал их в XGBoost.
Блендинг наших лучших индивидуальных score находится где-то здесь, вот эти две оранжевые точки. Но этого score нам не хватало, чтобы попасть в топ.
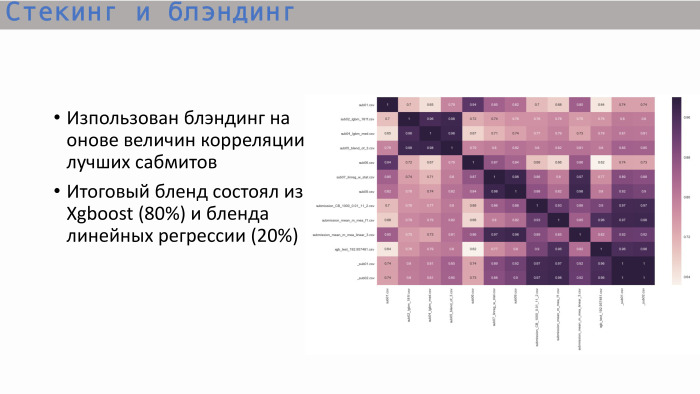
Изучив обычную матрицу корреляции самых лучших сабмитов, мы увидели следующее: деревья — и это логично — показывали корреляцию, близкую к единице, а самое лучшее дерево давал XGBoost. Он показывает не такую высокую корреляцию с линейной регрессией. Мы решили заблендить эти два варианта в пропорции 8 к 2. Именно так мы и получили самое лучшее финальное решение.
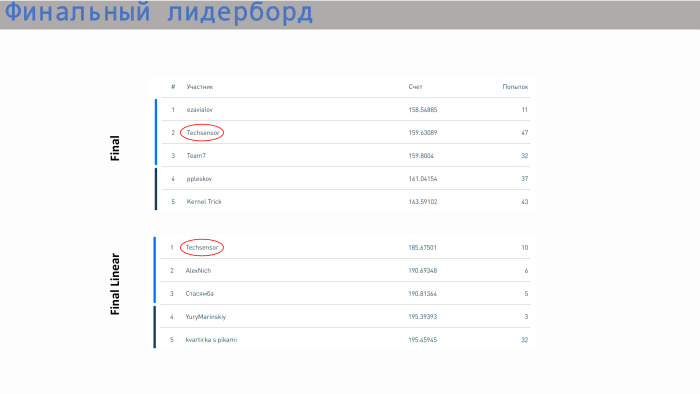
Это лидерборд с результатами. Наша команда заняла второе место по моделям без ограничений и первое место по линейным моделям. Что касается score — здесь все значения довольно близкие. Разница не очень большая. По линейной регрессии уже идет шаг в районе 5. У нас все, спасибо!
