
Многие из постоянных посетителей ML-тренировок придерживаются обоснованного мнения, что участие в конкурсах — самый быстрый способ попасть в профессию. У нас даже была статья на эту тему. Автор сегодняшней лекции Артур Кузин на собственном примере показал, как можно за пару лет переквалифицироваться из сферы, вообще не связанной с программированием, в специалиста по анализу данных.
— Всем привет. Меня зовут Артур Кузин, я lead data scientist компании Dbrain.
У Эмиля был довольно обстоятельный доклад, рассказывающий про очень многие аспекты. Я сосредоточусь на том, что считаю наиболее важным и забавным. Перед тем, как приступить к теме доклада, я хочу представиться. Вообще говоря, я закончил физтех и где-то 8 лет, с третьего курса, работал в лаборатории, которая находится на этаже НК. Эта лаборатория занимается созданием микро- и наноструктур.
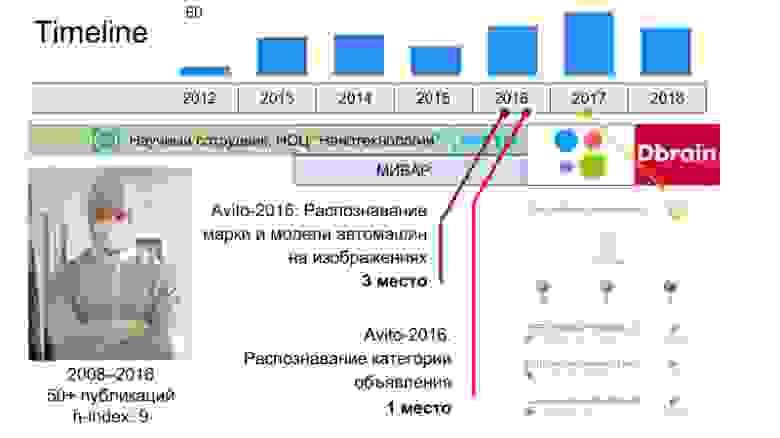
Я всё это время работал научным сотрудником, и это никак не было связано ни с ML, ни даже с программированием. Это показывает, насколько низок порог входа в машинное обучение, насколько быстро можно развиваться в этом. Дальше, в районе 2013 года, друзья позвали меня в стартап, который занимался ML. И в ходе 2–3 лет я изучал и программирование, и ML одновременно. Мой прогресс был довольно медленный — я изучал материалы, копался в этом, но это было не так быстро, как происходит сейчас. Для меня всё поменялось, когда я начал участвовать в соревнованиях по ML. Первый конкурс был от «Авито», про классификацию машин. Я не особо знал, как в нём участвовать, но сумел занять третье место. Сразу после этого стартовал другой конкурс, уже посвящённый классификации объявлений. Там были картинки, текст, описание, цена — это было комплексное соревнование. В нём я занял первое место, после чего почти сразу получил оффер и меня взяли в «Авито». Тогда не было позиции джуниора, меня взяли сразу миддлом — почти без релевантного опыта.
Дальше, когда я уже работал в «Авито», то начал участвовать в соревнованиях на Kaggle и примерно за год получил гранд-мастера. Сейчас я на 58 месте в общем рейтинге. Это мой профиль. Проработав в «Авито» полтора года, я перешёл в Dbrain и сейчас являюсь чем-то вроде руководителя направления по data science, координирую работу семи дата-саентистов. Всё, что я использую в работе, я узнал из соревнований. Поэтому я считаю, что это очень прикольная тема, и всячески пропагандирую участвовать в соревнованиях и развиваться.
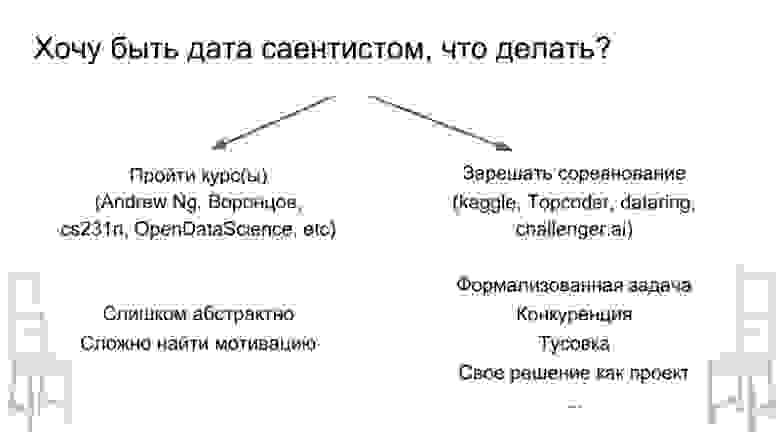
Меня иногда спрашивают, что нужно сделать, если хочется стать дата-саентистом. Здесь есть два пути. Первый прослушать какой-нибудь курс. Их довольно много, они все довольно качественные. Но для меня лично это вообще не работает. Все люди разные, но мне это не нравится, просто потому что, как правило, в курсах очень абстрактные задачи, и когда я прохожу какой-нибудь раздел, то не всегда понимаю, зачем мне нужно его знать. В противоположность этому подходу можно просто взять и начать решать соревнования. И это совершенно другой flow в плане подхода. Он отличается тем, что вы сразу приобретаете некий багаж знаний и начинаете изучать новую тему, когда сталкиваетесь с неизвестным. То есть вы начинаете решать и понимаете, что вам не хватает знаний о том, как обучать нейросеть. Вы берёте, гуглите и изучаете — только когда вам это необходимо. Это очень просто в плане мотивации, прогресса, потому что у вас уже есть строго сформулированная в рамках конкурса задача, целевая метрика и очень много поддержки в плане чатика Open Data Science. И, в качестве дальнего бонуса, — то, что ваше решение станет проектом, которого сейчас ещё нет.
Почему же это так весело? Откуда положительные эмоции? Идея в том, что, когда вы отправляете сабмит и он чуть-чуть лучше предыдущего, то говорят — ты улучшил метрику, это прикольно. Вы поднимаетесь вверх по лидерборду. В противоположность этому, если вы ничего не делаете и не отправляете сабмиты, то вы опускаетесь вниз. И это вызывает обратную связь: вам хорошо, когда вы прогрессируете, и наоборот. Это прикольный механизм, который эксплуатирует, кажется, только Kaggle. И другой момент: Kaggle эксплуатирует тот же механизм зависимости, что и игровые автоматы и Tinder. Вы не знаете, лучше ваш сабмит или хуже. Это вызывает ожидание результата, который вам неизвестен. Таким образом, Kaggle вызывает сильную зависимость, но она довольно конструктивна: вы развиваетесь и стараетесь улучшить своё решение.
Как получить первую дозу? Нужно залезть в раздел kernels. Там выкладывают некоторые куски пайплайнов или решения целиком. Отдельный вопрос — зачем люди это делают. Человек потратил время на разработку — в чём смысл выкладывать его в паблик? Им могут воспользоваться и обойти автора.
Идея в том, что, во-первых, лучшие решения не выкладывают. Как правило, эти решения неоптимальны с точки зрения обучения моделей, в них нет всех нюансов, но зато есть весь пайплайн от начала и до конца, чтобы вы не решали рутинные задачи, связанные с обработкой данных, постпроцессингом, сбором сабмита и т. д. Это понижение порога входа, чтобы привлечь новых участников. Надо понимать, что сообщество дата-саентистов очень открытое к обсуждению и, вообще, довольно позитивное. Я не встречал такого в научной среде. Основная мотивация — в том, что новые люди приходят с новыми идеями. Это развивает обсуждение задачи, соревнования и позволяет развиваться всему сообществу.
Если вы взяли чужое решение, запустили его, начали обучать, то следующее, что я крайне рекомендую сделать, — посмотреть в данные. Банальный совет, но вы не поверите, как много народу из топа им не пользуются. Чтобы понять, почему это важно, я советую посмотреть доклад Евгения Нижибицкого. Он рассказывает про лики в картиночных соревнованиях и про лик в Airbus, который тоже можно было увидеть, просто посмотрев в данные. Это занимает не очень много времени и помогает понять задачу. А лики в картинках были про то, что на разных платформах и в разных конкурсах можно было получить ответы теста из train. То есть вы могли не обучать никакую модель, а просто посмотреть в данные и понять, как можно собрать ответы для вашего теста — частично или полностью. Это такая привычка, которая важна не только в соревнованиях, но и в реальной практике, когда вы будете работать с дата-саентистами. В реальной жизни, скорее всего, задача будет сформулирована плохо. Её формулируете не вы, но вам нужно понимать, в чём её суть и суть данных. Привычка смотреть в данные очень важна, потратьте на неё время.
Дальше нужно понять, в чём состоит задача. Если вы посмотрели в данные и понимаете, каков таргет… Вы же, если я правильно понимаю, в большинстве своём, из Физтеха. У вас должно быть некое критическое мышление, наталкивающее вас на вопрос: почему люди, которые оформили соревнование, сделали всё правильно? Почему бы не поменять, например, целевую метрику, искать нечто другое, а уже из новой метрики собрать правильные вещи? На мой взгляд, сейчас, когда есть куча туториалов и чужого кода, сделать feed predict — не проблема. Обучить модель, обучить нейросеть — очень простая задача, доступная очень широкому кругу людей. Но важно понимать, какой у вас таргет, что вы предсказываете и как собрать вашу целевую метрику. Если вы предсказываете что-то нерелевантное в объективной реальности, то модель просто не обучается и вы получаете очень плохой скор.
Примеры. Было соревнование, которое проходило на Topcoder Konica-Minolta.

Оно заключалось в следующем: у вас есть две картинки, верхняя, и на одной из них есть грязь, маленькая точка справа. Надо было ее выделить и отсегментировать. Казалось бы, очень простая задача, и нейросети должны решать ее на раз. Но проблема, что эти два снимка, которые делались либо с разницей во времени, либо с разных камер. В итоге одна картинка немного съехала относительно другой. Масштаб при этом был реально очень небольшой. Но была другая особенность этой задачи в том, что маски тоже небольшие. Есть картинка, которая съехала относительно другой, и при этом маска еще съехала относительно ее. Примерно понятно, в чем сложность.
Алексей Буслаев на третьем месте, он взял сиамскую нейросеть с двумя входами так, чтобы эти сиамские головы выучили некоторые преобразования относительно этой искаженной картинки. После этого у него эти фичи объединялись, был набор сверток, и получался некоторый предикт. Чтобы нивелировать этот косяк в данных, он собрал довольно сложную сеть. Я, например, еще ни разу не обучал сиамскую сеть, мне не приходилось это делать. Он это сделал, это очень прикольно, занял третье место. На первом месте оказался Евгений (нрзб.), который просто отресайзил картинку. Он увидел это как косяк в данных, потому что в них посмотрел, сделал ресайз картинки, и обучил ванильный UNet. Это очень простая нейросеть, она просто в учебнике, есть в статьях. Это показывает, что если посмотреть в данные и подобрать правильно таргет, то можно с простым решением оказаться в топе.
Я оказался на втором месте, потому что я дружу с Женей, после этого топкодеры на меня почему-то обиделись и не берут в команду на Kaggle. Но они очень крутые ребята, Topcoder заняли 5-6 место, это (нрзб.) и Виктор Дурнов. Александр Буслаев занял третье место. Они дальше объединились и показали класс на соревновании, которое было на Kaggle. Это как раз тоже пример очень красивого решения, когда чуваки не просто разработали монструозную архитектуру, а подобрали правильно таргет.

Здесь задача заключалась в том, что нужно сегментировать клетки, при том не просто говорить, где клетка есть, а где нет, а нужно было выделять отдельные клетки, типа инстасегментация каждых независимых клеток. При этом до этого соревнования было очень много соревнований на сегментацию, и утверждалось, что задача на сегментацию решена сообществом ODS довольно хорошо, на уровне state of the craft, некоторый передний край науки, который позволяет решить эту задачу хорошо.
При этом задача инстасегментации, когда вам нужно разделить клетки, решалась очень плохо. State of the art до этого соревнования был MacrCNN, который представляет собой типа детектор, некоторый фичэкстрактор, дальше блок, который производит сегментацию масок, и это все довольно сложно тренировать, вам нужно тренировать каждые куски пайплайна отдельно, это целая песня.
Вместо этого Topcoder разработали пайплайн, когда вы предсказываете только клетки и границы. Пайплайн-сегментация усложняется минорно и позволяет вам делать очень красивую сегментацию, вычитание границ из клеток. После этого они подняли планку в плане точности этого алгоритма, при этом у них отдельная нейросеть предсказывает клетки лучше, чем все, что делали академики в этой области до этого. Это прикольно для топкодеров и очень плохо для академиков. Насколько я знаю, недавно академики пытались опубликовать статью на этом датасате, ее отклонили, потому что они не смогли превзойти результат на Kaggle. Для академиков настали сложные времена, теперь надо делать что-то нормальное, а не просто делать инкриптальные работы в своей области.
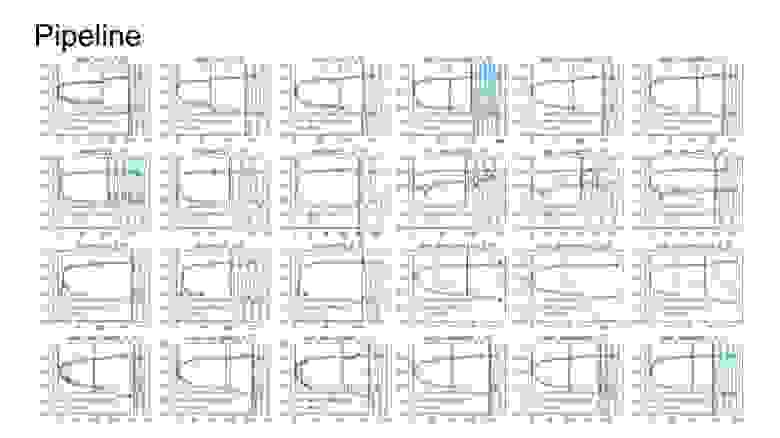
Следующая вещь, за которую я очень сильно топлю, не только в Kaggle, но еще и в работе, — это пайплай-обучение. Я не вижу много ценностей в том, чтобы сделать монструозную архитектуру нейросети, придумать клевые фишки с аттеншеном, с конкатинациями фичей. Это все работает, но гораздо более важно просто уметь обучить нейросеть. И в этом нет рокет саенса, это довольно простая вещь, учитывая что сейчас есть куча статей, туториалов и так далее. Я вижу очень много ценностей в том, чтобы у вас был именно пайплайн обучения. Я понимаю под этим код, который запускается по конфигу, и контролируемо, предсказуемо и довольно быстро обучает вам нейросеть.
На этом слайде представлены логи обучения с соревнования, которое проходит сейчас, Kaggle соль. У меня еще есть куча видеокарт, это тоже некоторый бонус. Идея в том, что с помощью пайплайна я провел grid search поиска архитектур, которые мне показались наиболее интересными. Я просто сделал один конфиг запуска для всех архитектур, условно, форум по зоопарку нейросетей, прошелся и обучил все нейросети, не принимая никаких усилий. Это очень большой бонус, и это то, что я переиспользую от соревнования к соревнованию и в работе. Поэтому я крайне агитирую не просто обучать нейросети, но еще думать о том, что вы обучаете и что вы пишите в плане пайплайна, что вы должны это переиспользовать.

Здесь я выделил некоторые ключевые вещи, которые должны быть в пайплайне обучения. Это конфиг запуска, который полностью определяет процесс обучения. Где вы указываете все параметры про данные, про нейросети, про лоссы — все должно быть в конфиге запуска. Это должно быть контролируемо. Дальше логирование. Красивые логи, которые я показал, это результат того, что я записываю каждый свой шаг.
Модульность означает, что у вас не должно занимать много времени, чтобы добавить новую нейросеть, новую аугментацию, новый датасет. Это все должно быть очень просто и поддерживаемо.
Воспроизводимость — это просто фиксация сидов, при том не только рандомных в NumPy и Random, но еще есть некоторые пайторчовые штуки, дальше расскажу. И переиспользуемость. Один раз разработав пайплайн, его можно использовать в других задачах. И это большой бонус, те кто начинают участвовать в соревнованиях рано, могут дальше эти пайплайны использовать в соревнованиях и в работе, это все дает большой бонус перед другими участниками.
Некоторые могут спросить: я же не умею кодить, что же делать, как разработать пайплайн? Есть решение.
Сергей Колесников — это мой коллега, который работает в Dbrain, он давно разрабатывает такую штуку. Сначала он называл ее PyTorch Common, потом назвал «Прометей», сейчас это называется «Каталист». Скорее всего, через неделю название будет другое, но ссылка будет на следующее название, переходите по ссылке «Каталист».
Идея в том, что Сергей разработал некоторую либу, которая представляет собой trainloop. И она в текущей версии обладает почти всеми свойствами, что я описал. Там есть еще куча примеров, как сделать классификацию, сегментацию и куча других прикольных штук, которые он разработал.
Здесь перечень фичей, которые есть, и они развиваются. Вы можете взять эту либу, и начать обучать с помощью нее свои алгоритмы, свои нейросети на соревновании, которое сейчас проходит. Я рекомендую всем это сделать.
В противоположность, есть другая либа FastAI, недавно выпустили версию 1.0, но там отвратительный код и ничего непонятно.
Вы можете ее освоить, это даст вам некоторый прирост, но из-за того, что она очень плохо написана в плане кода, у них свой флоу в плане того, как это должно быть написано. Начиная с некоторого момента, вы не будете понимать, что происходит. Поэтому я не рекомендую FastAI, я рекомендую пользоваться либой «Каталист».
Теперь предположим, вы прошли через все это, у вас есть свой пайплайн, свое решение, и можно теперь участвовать в команде. Как раз Эмилю задавали вопрос, насколько оправданно объединяться в команду, если вы участвуете, как это происходит. Мне кажется, что объединяться в команду стоит в любом случае, даже если вы находитесь не в топе, а где-то в середине. Если вы разрабатывали свое решение сами, то оно всегда отличается от решения других людей в некоторых мелочах. И при объединении оно почти всегда дает буст с другими участниками.
Кроме этого это весело, это некоторая командная работа в плане того, что теперь у вас будет общий репозиторий, где вы сможете посмотреть код друг друга, у вас есть общий формат сабмитов и чатик, где происходит все веселье. Социальное взаимодействие и soft skills тоже очень важны в работе, которые тоже стоит развивать.

В этом большой бонус в том плане, что теперь вы видите код других людей, как они делают то или иное решение. И я довольно часто заглядываю в репозиторий со своими предыдущими командами, нахожу там прикольные решения в плане самого кода. Это то, что можно вынести из соревнований в виде командного взаимодействия.
Предположим, вы прошли весь этот круг. Что вы вынесли?

Скорее всего, вы научились запускать чужой код. Очень надеюсь, что вы привили привычку смотреть в данные. Вы понимаете задачу, научились вести эксперименты, у вас есть какое-то свое решение, и теперь вы можете оформить его в виде проекта. Если посмотреть абстрактно, то это очень похоже на нормальную работу в какой-нибудь IT-компании. Если вы прошли через соревнование и показали хороший результат, это сильный пункт в резюме, по крайней мере, для меня. Я где-то прособеседовал человек 20-25, когда принимал на работу в Dbrain. Там можно было выделить некоторые граничные случаи. Был чувак, который просто позапускал public kernel, и не особо в них разобрался. Это выглядело плохо для меня, я как раз хотел, чтобы чувак разбирался в вопросе, я его не взял.
Другой чувак, который честно сказал, что оверфидился на лидерборд, но при этом рассказал все детали своего решения, которое было на Datascience Bowl, мы его взяли, мне с ним очень нравится работать. Kaggle и ваше решение там довольно сильный пункт в вашем резюме, если вы сможете правильно его оформить в виде презентации, хорошо показать для будущего работодателя.
Если вопросы про личную выгоду, надеюсь, я закрыл, зачем же это нужно компаниям?

Я работал в «Авито», они регулярно устраивали конкурсы по анализу данных. Для этого есть несколько причин. Когда проводится конкурс, нужно собрать как минимум датасет, и очень хорошо сформулировать задачу, которая представляет собой некоторую боль.
То есть формулировка задачи плюс датасет — это уже очень много для компании. Например, когда «Авито» проводили конкурсы по дубликатам, это было еще до того, как я начал с ними работать, они просто собрали датасет, переобучили старые модели и сильно подняли качество. Сбор датасета — это работа, которая нужна, чтобы поднять качество моделей.
Кроме того, когда много участников работают с одним датасетом, они достают некоторые инсайты, полезную информацию о том, как устроены эти данные. Не говоря о том, что по итогам соревнования можно понять, какая верхняя планка этого решения. Если лучшие дата-саентисты решают эту задачу, скорее всего, это потолок того, что можно достичь на этой задаче.
И кроме того, не секрет, что обычно соревнования — это еще и хантинг. Компания обычно берет на работу людей из топа, чтобы они реализовали это решение у нас. Например, после дубликатов «Авито» позвали на работу Дмитрия Соболевского, который работал со мной столько же времени. Это был большой бонус для «Авито» — они нашли замотивированного человека, который хотел допиливать это решение для продакшена.
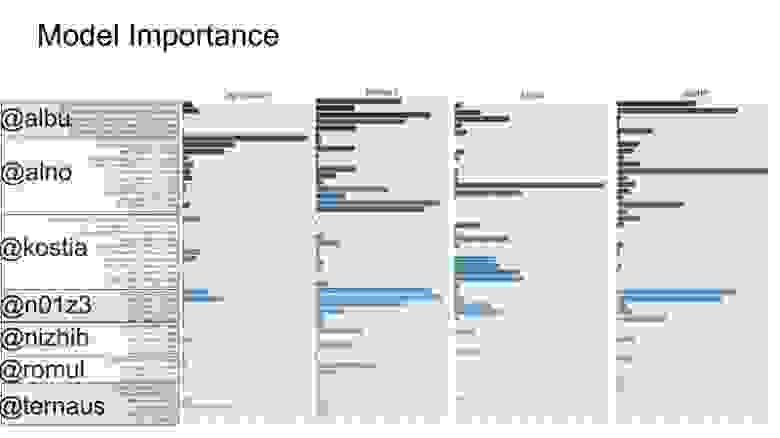
Если посмотреть на место сотрудников, то конкурсы — это еще и некоторое прокси к уровню их скиллов. Есть задача, которую пилит дата-саентист внутри компании. И непонятно, насколько хорошо он это делает — при условии, что он достаточно мотивирован. Чтобы сравнить его перфоманс, то, насколько адекватно он делает свою работу, можно просто поучаствовать в соревнованиях. Здесь приведена сложная вещь — importance вклада каждой модели в XGBoost второго уровня. Если вы не особо в теме, то тут показано, насколько важна каждая модель в ансамбле. Но это ничего не говорит о качестве модели. Здесь показано, как я участвовал с семью чуваками. Вроде как на тот момент мои модели были нормальные, давали хороший код в ансамбль. Это обеспечивало некоторое спокойствие, что я свою работу делаю хорошо.
Если компании не хотят участвовать, не хотят организовывать, у них просто есть какая-то релевантная задача, то, как правило, после соревнования люди выкладывают обзоры своих решений и даже код. И если у вас самих есть релевантная задача, которая очень сильно похожа, то можно взять и получить некоторый горячий старт в виде обзора литературы, обзора решений из топа.

В качестве примера — курс на Coursera о том, как выигрывать соревнования. Дальше — сайт ML-тренировок и ODS-чатик для обсуждения. У меня всё.
— Всем привет. Меня зовут Артур Кузин, я lead data scientist компании Dbrain.
У Эмиля был довольно обстоятельный доклад, рассказывающий про очень многие аспекты. Я сосредоточусь на том, что считаю наиболее важным и забавным. Перед тем, как приступить к теме доклада, я хочу представиться. Вообще говоря, я закончил физтех и где-то 8 лет, с третьего курса, работал в лаборатории, которая находится на этаже НК. Эта лаборатория занимается созданием микро- и наноструктур.

Я всё это время работал научным сотрудником, и это никак не было связано ни с ML, ни даже с программированием. Это показывает, насколько низок порог входа в машинное обучение, насколько быстро можно развиваться в этом. Дальше, в районе 2013 года, друзья позвали меня в стартап, который занимался ML. И в ходе 2–3 лет я изучал и программирование, и ML одновременно. Мой прогресс был довольно медленный — я изучал материалы, копался в этом, но это было не так быстро, как происходит сейчас. Для меня всё поменялось, когда я начал участвовать в соревнованиях по ML. Первый конкурс был от «Авито», про классификацию машин. Я не особо знал, как в нём участвовать, но сумел занять третье место. Сразу после этого стартовал другой конкурс, уже посвящённый классификации объявлений. Там были картинки, текст, описание, цена — это было комплексное соревнование. В нём я занял первое место, после чего почти сразу получил оффер и меня взяли в «Авито». Тогда не было позиции джуниора, меня взяли сразу миддлом — почти без релевантного опыта.
Дальше, когда я уже работал в «Авито», то начал участвовать в соревнованиях на Kaggle и примерно за год получил гранд-мастера. Сейчас я на 58 месте в общем рейтинге. Это мой профиль. Проработав в «Авито» полтора года, я перешёл в Dbrain и сейчас являюсь чем-то вроде руководителя направления по data science, координирую работу семи дата-саентистов. Всё, что я использую в работе, я узнал из соревнований. Поэтому я считаю, что это очень прикольная тема, и всячески пропагандирую участвовать в соревнованиях и развиваться.
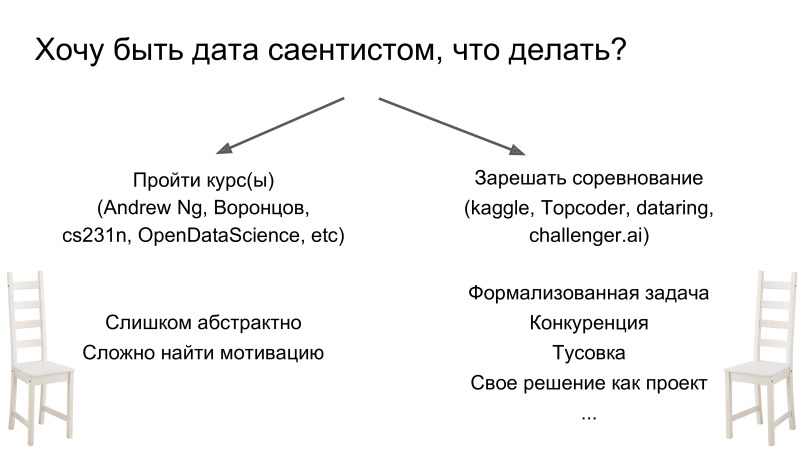
Меня иногда спрашивают, что нужно сделать, если хочется стать дата-саентистом. Здесь есть два пути. Первый прослушать какой-нибудь курс. Их довольно много, они все довольно качественные. Но для меня лично это вообще не работает. Все люди разные, но мне это не нравится, просто потому что, как правило, в курсах очень абстрактные задачи, и когда я прохожу какой-нибудь раздел, то не всегда понимаю, зачем мне нужно его знать. В противоположность этому подходу можно просто взять и начать решать соревнования. И это совершенно другой flow в плане подхода. Он отличается тем, что вы сразу приобретаете некий багаж знаний и начинаете изучать новую тему, когда сталкиваетесь с неизвестным. То есть вы начинаете решать и понимаете, что вам не хватает знаний о том, как обучать нейросеть. Вы берёте, гуглите и изучаете — только когда вам это необходимо. Это очень просто в плане мотивации, прогресса, потому что у вас уже есть строго сформулированная в рамках конкурса задача, целевая метрика и очень много поддержки в плане чатика Open Data Science. И, в качестве дальнего бонуса, — то, что ваше решение станет проектом, которого сейчас ещё нет.

Почему же это так весело? Откуда положительные эмоции? Идея в том, что, когда вы отправляете сабмит и он чуть-чуть лучше предыдущего, то говорят — ты улучшил метрику, это прикольно. Вы поднимаетесь вверх по лидерборду. В противоположность этому, если вы ничего не делаете и не отправляете сабмиты, то вы опускаетесь вниз. И это вызывает обратную связь: вам хорошо, когда вы прогрессируете, и наоборот. Это прикольный механизм, который эксплуатирует, кажется, только Kaggle. И другой момент: Kaggle эксплуатирует тот же механизм зависимости, что и игровые автоматы и Tinder. Вы не знаете, лучше ваш сабмит или хуже. Это вызывает ожидание результата, который вам неизвестен. Таким образом, Kaggle вызывает сильную зависимость, но она довольно конструктивна: вы развиваетесь и стараетесь улучшить своё решение.
Как получить первую дозу? Нужно залезть в раздел kernels. Там выкладывают некоторые куски пайплайнов или решения целиком. Отдельный вопрос — зачем люди это делают. Человек потратил время на разработку — в чём смысл выкладывать его в паблик? Им могут воспользоваться и обойти автора.
Идея в том, что, во-первых, лучшие решения не выкладывают. Как правило, эти решения неоптимальны с точки зрения обучения моделей, в них нет всех нюансов, но зато есть весь пайплайн от начала и до конца, чтобы вы не решали рутинные задачи, связанные с обработкой данных, постпроцессингом, сбором сабмита и т. д. Это понижение порога входа, чтобы привлечь новых участников. Надо понимать, что сообщество дата-саентистов очень открытое к обсуждению и, вообще, довольно позитивное. Я не встречал такого в научной среде. Основная мотивация — в том, что новые люди приходят с новыми идеями. Это развивает обсуждение задачи, соревнования и позволяет развиваться всему сообществу.
Если вы взяли чужое решение, запустили его, начали обучать, то следующее, что я крайне рекомендую сделать, — посмотреть в данные. Банальный совет, но вы не поверите, как много народу из топа им не пользуются. Чтобы понять, почему это важно, я советую посмотреть доклад Евгения Нижибицкого. Он рассказывает про лики в картиночных соревнованиях и про лик в Airbus, который тоже можно было увидеть, просто посмотрев в данные. Это занимает не очень много времени и помогает понять задачу. А лики в картинках были про то, что на разных платформах и в разных конкурсах можно было получить ответы теста из train. То есть вы могли не обучать никакую модель, а просто посмотреть в данные и понять, как можно собрать ответы для вашего теста — частично или полностью. Это такая привычка, которая важна не только в соревнованиях, но и в реальной практике, когда вы будете работать с дата-саентистами. В реальной жизни, скорее всего, задача будет сформулирована плохо. Её формулируете не вы, но вам нужно понимать, в чём её суть и суть данных. Привычка смотреть в данные очень важна, потратьте на неё время.
Дальше нужно понять, в чём состоит задача. Если вы посмотрели в данные и понимаете, каков таргет… Вы же, если я правильно понимаю, в большинстве своём, из Физтеха. У вас должно быть некое критическое мышление, наталкивающее вас на вопрос: почему люди, которые оформили соревнование, сделали всё правильно? Почему бы не поменять, например, целевую метрику, искать нечто другое, а уже из новой метрики собрать правильные вещи? На мой взгляд, сейчас, когда есть куча туториалов и чужого кода, сделать feed predict — не проблема. Обучить модель, обучить нейросеть — очень простая задача, доступная очень широкому кругу людей. Но важно понимать, какой у вас таргет, что вы предсказываете и как собрать вашу целевую метрику. Если вы предсказываете что-то нерелевантное в объективной реальности, то модель просто не обучается и вы получаете очень плохой скор.
Примеры. Было соревнование, которое проходило на Topcoder Konica-Minolta.

Оно заключалось в следующем: у вас есть две картинки, верхняя, и на одной из них есть грязь, маленькая точка справа. Надо было ее выделить и отсегментировать. Казалось бы, очень простая задача, и нейросети должны решать ее на раз. Но проблема, что эти два снимка, которые делались либо с разницей во времени, либо с разных камер. В итоге одна картинка немного съехала относительно другой. Масштаб при этом был реально очень небольшой. Но была другая особенность этой задачи в том, что маски тоже небольшие. Есть картинка, которая съехала относительно другой, и при этом маска еще съехала относительно ее. Примерно понятно, в чем сложность.

Алексей Буслаев на третьем месте, он взял сиамскую нейросеть с двумя входами так, чтобы эти сиамские головы выучили некоторые преобразования относительно этой искаженной картинки. После этого у него эти фичи объединялись, был набор сверток, и получался некоторый предикт. Чтобы нивелировать этот косяк в данных, он собрал довольно сложную сеть. Я, например, еще ни разу не обучал сиамскую сеть, мне не приходилось это делать. Он это сделал, это очень прикольно, занял третье место. На первом месте оказался Евгений (нрзб.), который просто отресайзил картинку. Он увидел это как косяк в данных, потому что в них посмотрел, сделал ресайз картинки, и обучил ванильный UNet. Это очень простая нейросеть, она просто в учебнике, есть в статьях. Это показывает, что если посмотреть в данные и подобрать правильно таргет, то можно с простым решением оказаться в топе.
Я оказался на втором месте, потому что я дружу с Женей, после этого топкодеры на меня почему-то обиделись и не берут в команду на Kaggle. Но они очень крутые ребята, Topcoder заняли 5-6 место, это (нрзб.) и Виктор Дурнов. Александр Буслаев занял третье место. Они дальше объединились и показали класс на соревновании, которое было на Kaggle. Это как раз тоже пример очень красивого решения, когда чуваки не просто разработали монструозную архитектуру, а подобрали правильно таргет.

Ссылка со слайда
Здесь задача заключалась в том, что нужно сегментировать клетки, при том не просто говорить, где клетка есть, а где нет, а нужно было выделять отдельные клетки, типа инстасегментация каждых независимых клеток. При этом до этого соревнования было очень много соревнований на сегментацию, и утверждалось, что задача на сегментацию решена сообществом ODS довольно хорошо, на уровне state of the craft, некоторый передний край науки, который позволяет решить эту задачу хорошо.
При этом задача инстасегментации, когда вам нужно разделить клетки, решалась очень плохо. State of the art до этого соревнования был MacrCNN, который представляет собой типа детектор, некоторый фичэкстрактор, дальше блок, который производит сегментацию масок, и это все довольно сложно тренировать, вам нужно тренировать каждые куски пайплайна отдельно, это целая песня.
Вместо этого Topcoder разработали пайплайн, когда вы предсказываете только клетки и границы. Пайплайн-сегментация усложняется минорно и позволяет вам делать очень красивую сегментацию, вычитание границ из клеток. После этого они подняли планку в плане точности этого алгоритма, при этом у них отдельная нейросеть предсказывает клетки лучше, чем все, что делали академики в этой области до этого. Это прикольно для топкодеров и очень плохо для академиков. Насколько я знаю, недавно академики пытались опубликовать статью на этом датасате, ее отклонили, потому что они не смогли превзойти результат на Kaggle. Для академиков настали сложные времена, теперь надо делать что-то нормальное, а не просто делать инкриптальные работы в своей области.

Следующая вещь, за которую я очень сильно топлю, не только в Kaggle, но еще и в работе, — это пайплай-обучение. Я не вижу много ценностей в том, чтобы сделать монструозную архитектуру нейросети, придумать клевые фишки с аттеншеном, с конкатинациями фичей. Это все работает, но гораздо более важно просто уметь обучить нейросеть. И в этом нет рокет саенса, это довольно простая вещь, учитывая что сейчас есть куча статей, туториалов и так далее. Я вижу очень много ценностей в том, чтобы у вас был именно пайплайн обучения. Я понимаю под этим код, который запускается по конфигу, и контролируемо, предсказуемо и довольно быстро обучает вам нейросеть.
На этом слайде представлены логи обучения с соревнования, которое проходит сейчас, Kaggle соль. У меня еще есть куча видеокарт, это тоже некоторый бонус. Идея в том, что с помощью пайплайна я провел grid search поиска архитектур, которые мне показались наиболее интересными. Я просто сделал один конфиг запуска для всех архитектур, условно, форум по зоопарку нейросетей, прошелся и обучил все нейросети, не принимая никаких усилий. Это очень большой бонус, и это то, что я переиспользую от соревнования к соревнованию и в работе. Поэтому я крайне агитирую не просто обучать нейросети, но еще думать о том, что вы обучаете и что вы пишите в плане пайплайна, что вы должны это переиспользовать.

Здесь я выделил некоторые ключевые вещи, которые должны быть в пайплайне обучения. Это конфиг запуска, который полностью определяет процесс обучения. Где вы указываете все параметры про данные, про нейросети, про лоссы — все должно быть в конфиге запуска. Это должно быть контролируемо. Дальше логирование. Красивые логи, которые я показал, это результат того, что я записываю каждый свой шаг.
Модульность означает, что у вас не должно занимать много времени, чтобы добавить новую нейросеть, новую аугментацию, новый датасет. Это все должно быть очень просто и поддерживаемо.
Воспроизводимость — это просто фиксация сидов, при том не только рандомных в NumPy и Random, но еще есть некоторые пайторчовые штуки, дальше расскажу. И переиспользуемость. Один раз разработав пайплайн, его можно использовать в других задачах. И это большой бонус, те кто начинают участвовать в соревнованиях рано, могут дальше эти пайплайны использовать в соревнованиях и в работе, это все дает большой бонус перед другими участниками.
Некоторые могут спросить: я же не умею кодить, что же делать, как разработать пайплайн? Есть решение.

Ссылки со слайда: первая, вторая, третья
Сергей Колесников — это мой коллега, который работает в Dbrain, он давно разрабатывает такую штуку. Сначала он называл ее PyTorch Common, потом назвал «Прометей», сейчас это называется «Каталист». Скорее всего, через неделю название будет другое, но ссылка будет на следующее название, переходите по ссылке «Каталист».
Идея в том, что Сергей разработал некоторую либу, которая представляет собой trainloop. И она в текущей версии обладает почти всеми свойствами, что я описал. Там есть еще куча примеров, как сделать классификацию, сегментацию и куча других прикольных штук, которые он разработал.
Здесь перечень фичей, которые есть, и они развиваются. Вы можете взять эту либу, и начать обучать с помощью нее свои алгоритмы, свои нейросети на соревновании, которое сейчас проходит. Я рекомендую всем это сделать.
В противоположность, есть другая либа FastAI, недавно выпустили версию 1.0, но там отвратительный код и ничего непонятно.
Вы можете ее освоить, это даст вам некоторый прирост, но из-за того, что она очень плохо написана в плане кода, у них свой флоу в плане того, как это должно быть написано. Начиная с некоторого момента, вы не будете понимать, что происходит. Поэтому я не рекомендую FastAI, я рекомендую пользоваться либой «Каталист».

Теперь предположим, вы прошли через все это, у вас есть свой пайплайн, свое решение, и можно теперь участвовать в команде. Как раз Эмилю задавали вопрос, насколько оправданно объединяться в команду, если вы участвуете, как это происходит. Мне кажется, что объединяться в команду стоит в любом случае, даже если вы находитесь не в топе, а где-то в середине. Если вы разрабатывали свое решение сами, то оно всегда отличается от решения других людей в некоторых мелочах. И при объединении оно почти всегда дает буст с другими участниками.
Кроме этого это весело, это некоторая командная работа в плане того, что теперь у вас будет общий репозиторий, где вы сможете посмотреть код друг друга, у вас есть общий формат сабмитов и чатик, где происходит все веселье. Социальное взаимодействие и soft skills тоже очень важны в работе, которые тоже стоит развивать.
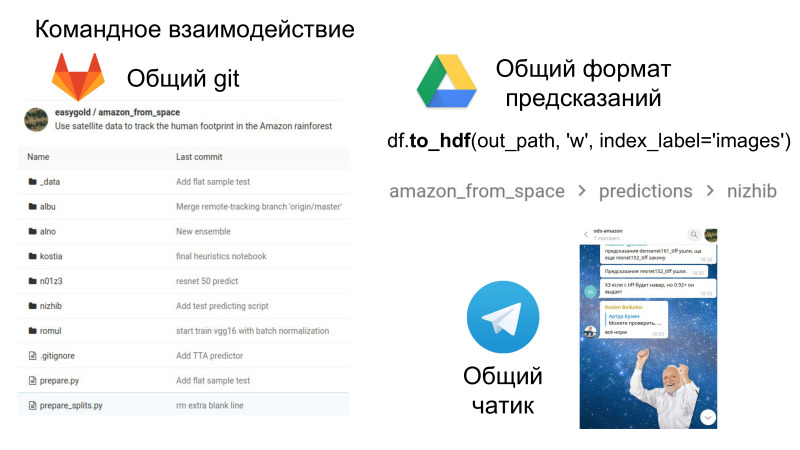
В этом большой бонус в том плане, что теперь вы видите код других людей, как они делают то или иное решение. И я довольно часто заглядываю в репозиторий со своими предыдущими командами, нахожу там прикольные решения в плане самого кода. Это то, что можно вынести из соревнований в виде командного взаимодействия.
Предположим, вы прошли весь этот круг. Что вы вынесли?

Скорее всего, вы научились запускать чужой код. Очень надеюсь, что вы привили привычку смотреть в данные. Вы понимаете задачу, научились вести эксперименты, у вас есть какое-то свое решение, и теперь вы можете оформить его в виде проекта. Если посмотреть абстрактно, то это очень похоже на нормальную работу в какой-нибудь IT-компании. Если вы прошли через соревнование и показали хороший результат, это сильный пункт в резюме, по крайней мере, для меня. Я где-то прособеседовал человек 20-25, когда принимал на работу в Dbrain. Там можно было выделить некоторые граничные случаи. Был чувак, который просто позапускал public kernel, и не особо в них разобрался. Это выглядело плохо для меня, я как раз хотел, чтобы чувак разбирался в вопросе, я его не взял.
Другой чувак, который честно сказал, что оверфидился на лидерборд, но при этом рассказал все детали своего решения, которое было на Datascience Bowl, мы его взяли, мне с ним очень нравится работать. Kaggle и ваше решение там довольно сильный пункт в вашем резюме, если вы сможете правильно его оформить в виде презентации, хорошо показать для будущего работодателя.
Если вопросы про личную выгоду, надеюсь, я закрыл, зачем же это нужно компаниям?

Я работал в «Авито», они регулярно устраивали конкурсы по анализу данных. Для этого есть несколько причин. Когда проводится конкурс, нужно собрать как минимум датасет, и очень хорошо сформулировать задачу, которая представляет собой некоторую боль.

Ссылка со слайда
То есть формулировка задачи плюс датасет — это уже очень много для компании. Например, когда «Авито» проводили конкурсы по дубликатам, это было еще до того, как я начал с ними работать, они просто собрали датасет, переобучили старые модели и сильно подняли качество. Сбор датасета — это работа, которая нужна, чтобы поднять качество моделей.
Кроме того, когда много участников работают с одним датасетом, они достают некоторые инсайты, полезную информацию о том, как устроены эти данные. Не говоря о том, что по итогам соревнования можно понять, какая верхняя планка этого решения. Если лучшие дата-саентисты решают эту задачу, скорее всего, это потолок того, что можно достичь на этой задаче.
И кроме того, не секрет, что обычно соревнования — это еще и хантинг. Компания обычно берет на работу людей из топа, чтобы они реализовали это решение у нас. Например, после дубликатов «Авито» позвали на работу Дмитрия Соболевского, который работал со мной столько же времени. Это был большой бонус для «Авито» — они нашли замотивированного человека, который хотел допиливать это решение для продакшена.

Если посмотреть на место сотрудников, то конкурсы — это еще и некоторое прокси к уровню их скиллов. Есть задача, которую пилит дата-саентист внутри компании. И непонятно, насколько хорошо он это делает — при условии, что он достаточно мотивирован. Чтобы сравнить его перфоманс, то, насколько адекватно он делает свою работу, можно просто поучаствовать в соревнованиях. Здесь приведена сложная вещь — importance вклада каждой модели в XGBoost второго уровня. Если вы не особо в теме, то тут показано, насколько важна каждая модель в ансамбле. Но это ничего не говорит о качестве модели. Здесь показано, как я участвовал с семью чуваками. Вроде как на тот момент мои модели были нормальные, давали хороший код в ансамбль. Это обеспечивало некоторое спокойствие, что я свою работу делаю хорошо.
Если компании не хотят участвовать, не хотят организовывать, у них просто есть какая-то релевантная задача, то, как правило, после соревнования люди выкладывают обзоры своих решений и даже код. И если у вас самих есть релевантная задача, которая очень сильно похожа, то можно взять и получить некоторый горячий старт в виде обзора литературы, обзора решений из топа.

В качестве примера — курс на Coursera о том, как выигрывать соревнования. Дальше — сайт ML-тренировок и ODS-чатик для обсуждения. У меня всё.
