Всем привет! Трансформеры уже захватили мир машинного обучения, начав свой путь с обработки текстов, перешли в другие области как: аудио, работа с графами, работа видео. В этом посте хотел бы остановиться на теме dense prediction в компьютерном зрении (segmentation, monodepth estimation) и поделиться работами на эту тему.
Работы, которые будут представлены далее, используют Transformer Block и с помощью него строят все архитектуры. Если вы не знакомы с его Transformer Block, то рекомендую следующий блог. И так мы начинаем.
Основополагающий статьей для применения трансформеров в мире компьютерного зрения является Vision Transformer (ViT). С неё мы и начнем
ViT

В этой работе авторы адаптировали модель трансформера, применяемую в NLP, для задач классификации, стараясь внести как можно меньше изменений в сравнении с оригинальной архитектуру. Архитектуру можно увидеть на картинке. Transformer Encoder отличается от оригинальной работы только расположение нормализационного слоя. В оригинальной работе он находится после MLP и Multi-Head Attention.
Исходное изображение подаётся на вход после следующих преобразований. Исходное изображение разбивается на патчи размером 16x16. Затем они выпрямляются в вектор. Таким образом, мы получаем H/16  W/16 векторов, которые мы и подаём на вход модели.
W/16 векторов, которые мы и подаём на вход модели.
DPT
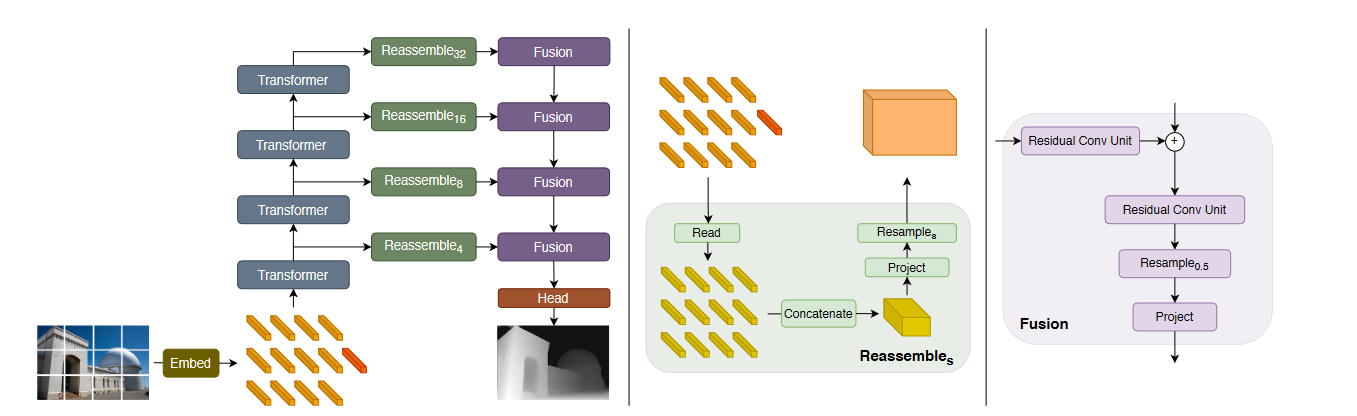
В этой статье авторы предложили подход по обобщению архитектуры ViT для Dense задач. В качестве архитектуры они модифицировали FuseNet.
В архитектуре нам интересны 3 модуля: encoder, decoder и connection module.
В качестве encoder они использовали стандартный ViT, беря для Fusion части выходы определенных блоков. Connection module состоит из 3 частей: read, concatenate и resample.
Read нужен, чтобы избавиться от токена [CLS]. Авторы предложили 3 метода: выкинуть его и использовать остальные, прибавить его ко всем токенам и сконкатенировать его со всеми токенами и применить MLP.
Concatenate восстанавливает токены обратно в изображение. Затем изображение скейлиться в меньшую размерность при помощи strided convolution (по аналогии с FuseNet или UNet). И в конце применяется fusion после чего изображение увеличивается. Вот и вся идея данной архитектуры.
Pyramid Vision Transformer

В этой статье авторы модифицировали ViT на основе идей CNN моделей. Основная идея в CNN - постепенное уменьшение размеров обрабатываемого представления для того, чтобы convolution имели более большой receptive field. Такой же подход применили и авторы. В процессе прохода по модели постепенно уменьшается разрешение, что позволяет иметь информацию с разного масштаба изображения (от маленьких ребер до гигантского небоскрёба). Реализовали уменьшение размерности изображения при помощи уменьшение размера токенов (и соответственно spatial resolution изображения). Из отдельных деталей архитектуры можно выделить, как они решили проблему подсчета большого числа attention. Для этого, чтобы делать это эффективно они уменьшали размерность векторов, которые подаются на вход
Swin

В этой статье авторы обратили внимание на следующее отличие текста от картинок. В NLP текст имеет одинаковый масштаб - слово, но в Computer Vision масштаб разный. У нас может быть картинка кота на всё изображение и кота только в маленькой части экран. Для понимая, что это кот масштаб нам не важен. Но для моделей трансформеров важен. Поэтому стандартный ViT, который имеет один scale, будет неэффективен по сравнению с моделями, использующими разный scale. Модель Swin Transformer, решает эту проблему, используя Patch Merging. Начиная с очень маленьких токенов, мы постепенно увеличиваем их scale
Но тут возникает проблема того, что число токен становится слишком огромным, а так как подсчет полной матрицы attention квадратичен по размеру изображения, мы будем тратить слишком много времени на подсчет attention. Как решение авторы предложили следующее: разбить изображения на окна и считать attention внутри некоторого окна. Однако тут возникает проблема в том, что не учитываются взаимодействия элементами из различных окон. Так если окна не пересекаются, то у нас нет взаимодействия с токенами с различных окон. Для авторы предложили использовать shifted window механизм.
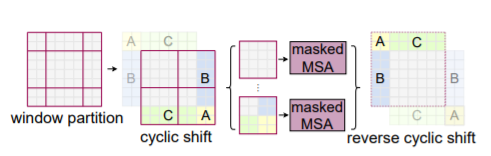
Мы сдвигаем наши окна на M/2 по вертикали и горизонтали. Таким образом у нас получается 9 патчей между которыми мы хотим посчитать attention. Из-за сдвига у нас будет считаться attention между токенами, находящимися в разных окнах. Поэтому обмен информацией между окнами происходит. Но возникает вопрос как считать attention в этом случае. Нам во многом оставить процедуру подсчета attention такой же, но нужно что-то поменять. Простая идея дополнять окна более маленького размера до нужного. Но авторы предложили другой подход: циклических сдвинуть изображения и посчитать Masked Self Attention (добавляю маску на матрицу attention, чтобы убрать взаимодействия с другими регионами), таким образом, сделав только 4 подсчета.
HRFormer
И последняя архитектура в нашем блоге это HRFormer.

Это работа является адаптацией HRNet с использованием трансформеров. Суть HRNet архитектуры в одновременном использовании различных resolution и обмена информации между ними. Пример на картинке выше. Мы производим операции на различных масштабах. Подход отличается от Swin, так как мы используем разные масштабы в течении всего обучения
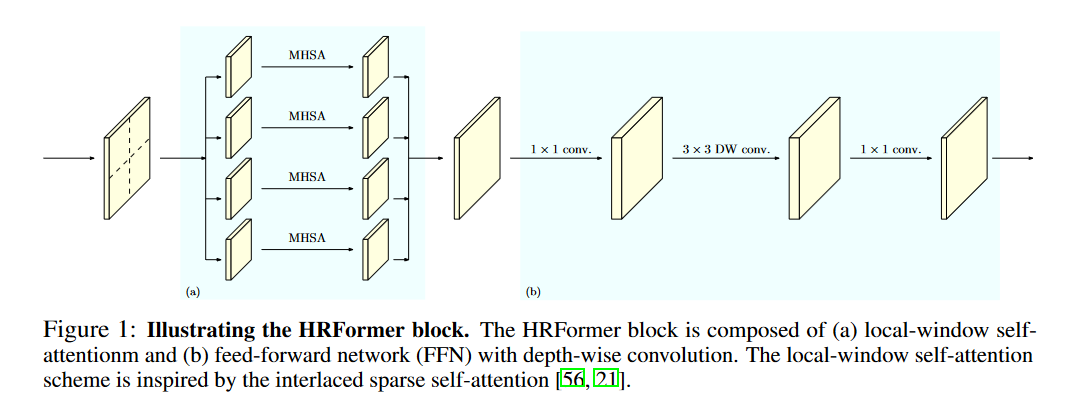
Основным блоком для архитектуры является HRFormer Block, где мы добавляем Depthwise convolution после MHSA. Depthwise convolution решает проблему обмена информации между непересекающимися окнами. Иллюстрация как это работает ниже
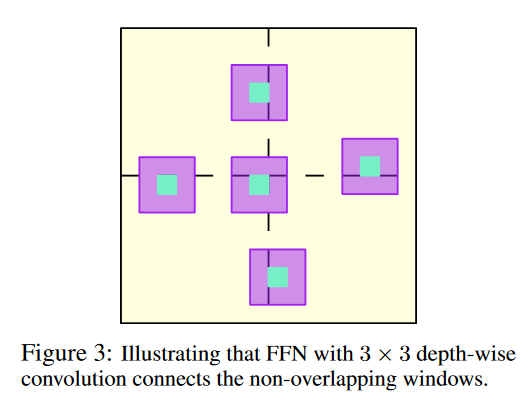
Conclusion
В этой статье я постарался обзорно описать архитектуры моделей трансформеров, используемых для dense prediction. Основные механизмы, которые предложили работы это:
Использование более мелких патчей 4x4 (вместо 16x16)
Использование Windowed attention, для упрощения вычислительной сложности
Использование механизмов передающих информацию между окнами (Shifted Window, Depthwise convolution)
Использование информации с различных масштабов/
Если вам интересны мои обзоры, то подписывайтесь на телеграм канал Awesome DL
Sources
A. Vaswani, N. Shazeer, et. al, Attention Is All You Need, (2017), 31st Conference on Neural Information Processing Systems.
Gong, Y., Chung, Y. A., & Glass, J. (2021). Ast: Audio spectrogram transformer. arXiv preprint arXiv:2104.01778.
Zhang, J., Zhang, H., Xia, C., & Sun, L. (2020). Graph-bert: Only attention is needed for learning graph representations. arXiv preprint arXiv:2001.05140.
Bertasius, Gedas, Heng Wang, and Lorenzo Torresani. "Is space-time attention all you need for video understanding." arXiv preprint arXiv:2102.05095 2.3 (2021): 4.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
Ranftl, R., Bochkovskiy, A., & Koltun, V. (2021). Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 12179-12188).
Wang, W., Xie, E., Li, X., Fan, D. P., Song, K., Liang, D., ... & Shao, L. (2021). Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 568-578).
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., ... & Guo, B. (2021). Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 10012-10022).
Yuan, Y., Fu, R., Huang, L., Lin, W., Zhang, C., Chen, X., & Wang, J. (2021). HRFormer: High-Resolution Transformer for Dense Prediction. arXiv preprint arXiv:2110.09408.
