Введение
Звук – HiFi-стриминг с большой командой инженеров. Мы используем передовые технологии и современный стек, и экспериментируем, чтобы решать сложные, нестандартные задачи. Одна из технологий – GraphQL.
Эта статья изначально создавалась как гайд по работе с GraphQL для инженеров Звука (системные аналитики, разработчики, QA). При этом статья может быть полезна всем, кто никогда не работал с GraphQL, но очень хочет понять, зачем он может быть нужен, и как поможет решить задачу вашего бизнеса.
В статье есть ответы на следующие вопросы:
Как мы используем GraphQL
GraphQL очень хорошо работает в случае, когда необходимо в приложении одни и те же объекты отображать в разных местах приложения с разным набором данных. У нас это альбомы, артисты, плейлисты, профили и т.д.
Для примера возьмём два варианта отображения артистов в Звуке:
1. Запрос данных артистов на странице Топ-100 https://zvuk.com/top100 (внизу страницы). Здесь запрашивается минимальный для отображения набор данных — id артиста, имя и аватарка. Причём запрашивается сразу несколько артистов.

Примеры запроса и ответа
Запрос

Ответ

2. Запрос данных артистов на странице артиста – https://zvuk.com/artist/3253180. Тут данных уже намного больше: id, имя, аватарка, топ популярных треков (включая данные самого трека), релизы (включая данные релиза), а также похожие артисты (включая данные).
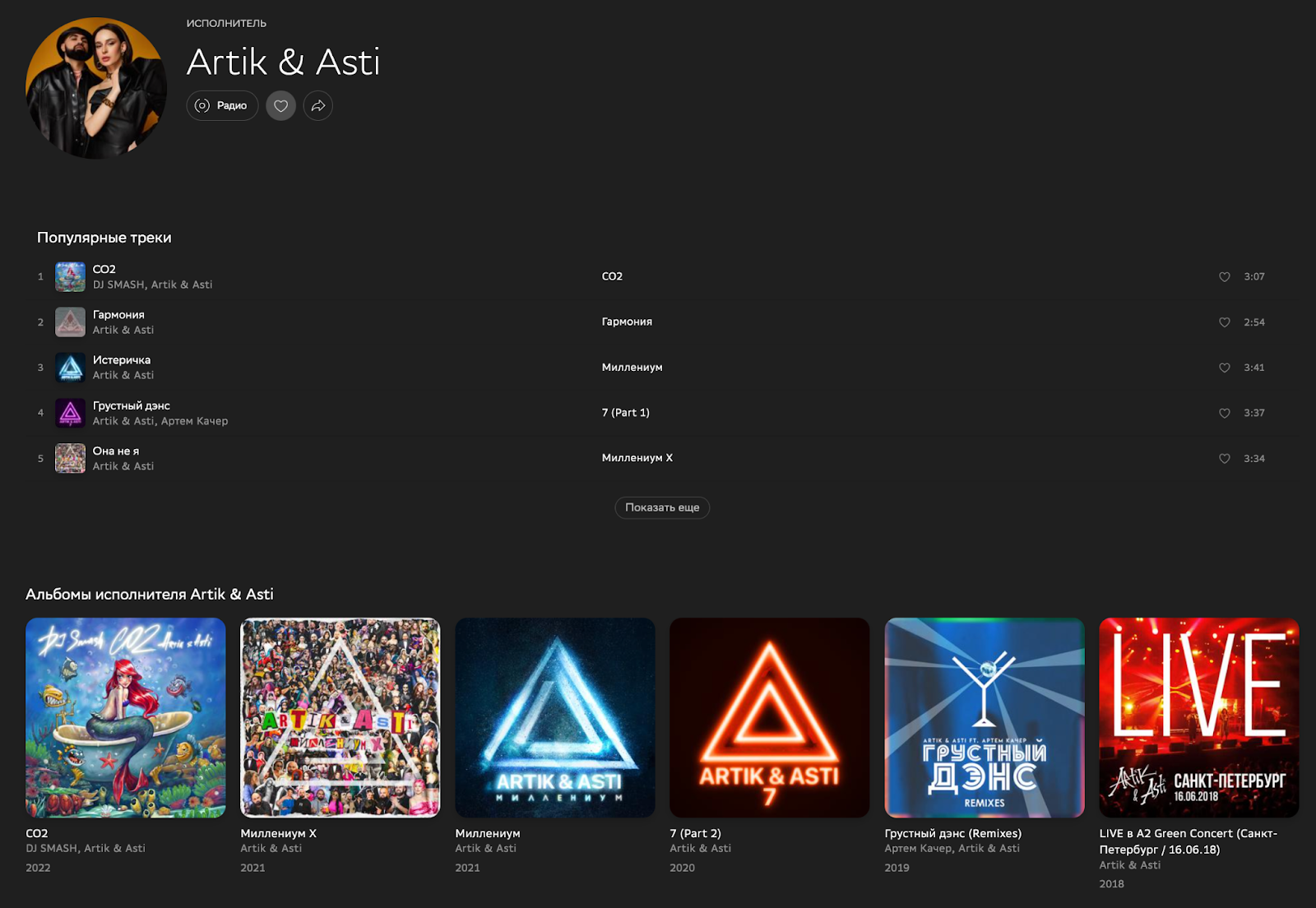
Пример запроса и ответа
Запрос

Ответ

Смысл в том, что клиентские приложения (WEB, IOS, Android) могут запрашивать только тот набор данных, который необходим для конкретного экрана. При этом, на бэкенде не приходится программировать несколько методов по отдельности. В GraphQL программируется каждое отдельное поле или объект (если это возможно).
Почему мы выбрали GraphQL?
Наш продукт устроен так, что в нём часто используются одни и те же объекты в разных представлениях (артисты на примере выше). Для решения этой проблемы есть следующие варианты:
Создавать разные API методы для каждого представления объекта только с необходимым набором данных.
Создать один метод для получения всех данных объекта.
В первом варианте получается очень много разработки на бэкенде, а во втором клиентские приложения часто будут получать очень много лишних данных. Решением этой проблемы может являться GraphQL.
GraphQL позволяет нам один раз запрограммировать объект со всеми его полями, а уже клиентское приложение отправит запрос только за теми данными, которые нужны ему прямо сейчас.
GraphQL Schema
Что это?
В GraphQL для разработки API пишется схема определённого вида. В схеме описываются:
Объекты – в GraphQL они задаются ключевым словом type и пишутся с большой буквы.
Поля объектов. У поля должно быть описано:
Название поля (всегда пишется с маленькой буквы)
Что возвращает это поле (всегда пишется с большой буквы):
Может быть один из типов (String, Int, Boolean и тд)
Другой объект (type)
Может ли это поле быть null (другими словами — обязательность). Обязательность обозначается знаком «!«
Методы запроса данных (query). У метода должно быть описано:
Название метода
Входные параметры
Выходные типы или объекты
Методы изменения данных (mutation). У этих методов должно быть описано то же самое:
Название метода
Входные параметры
Выходные типы или объекты
ENUM, UNION.
Связи с другими микросервисами (об этом тоже дальше).
Типы GraphQL
У GraphQL типы можно разделить на две группы:
Стандартные GraphQL типы. Например, это:
ID
Int
String
Boolean
DateTime и тд.
Пользовательские (то есть созданные нами) GraphQL типы. Например, это:
Artist
Track
Release
Profile и тд.
Пример GraphQL схемы
Это пример схемы нашего сервиса мета-информации (в нём хранится информация обо всех треках, релизах, артистах и тд)

Здесь, например, описана сущность Трек, которая обладает следующими полями:
id – обязательное поле (обозначается знаком «!«) со стандартным GraphQL типом ID.
Название – поле, возвращающее стандартный GraphQL тип String – «Строка».
Продолжительность – поле, возвращающее стандартный GraphQL тип Int – «Целое число».
Есть ли у трека качество Flac – поле, возвращающее стандартный GraphQL тип Boolean – «Булево поле».
Артисты – поле, возвращающее массив объектов с типом Artists,
Здесь идёт ссылка на объект «Артист», объявленный нами в этой же схеме (вторая картинка). Объект «Артист» также имеет свои поля.
Query
Query – метод запроса данных в GraphQL. Для создания нового метода надо задать его внутри типа Query.

Например, для запроса данных о треках создаётся следующий query:
Название – getTracks.
Входные параметры – массив id треков (массив здесь обязателен, внутри массива тоже не может быть null).
Возвращаемый объект – тип Трек.
Для запроса данных надо написать query вот такого вида:
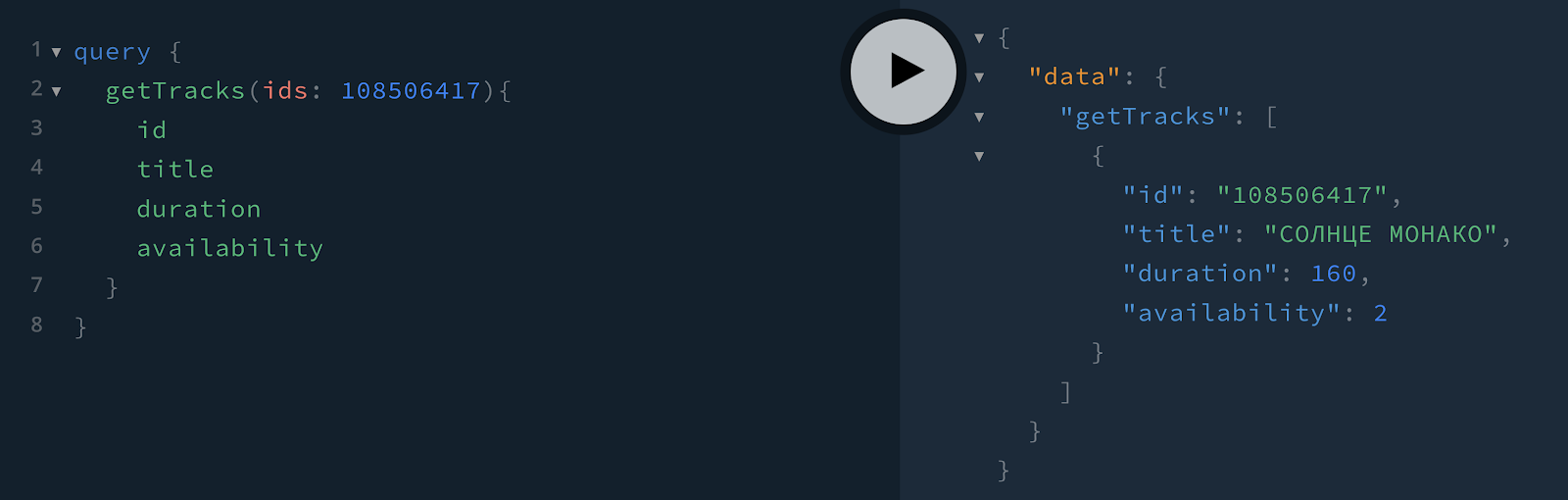
В ответ мы получаем те данные, которые мы запросили.
Если мы хотим получить не только название трека, но ещё и артистов, который исполняют этот трек, то надо выполнить вложенный запрос. Пример запроса:
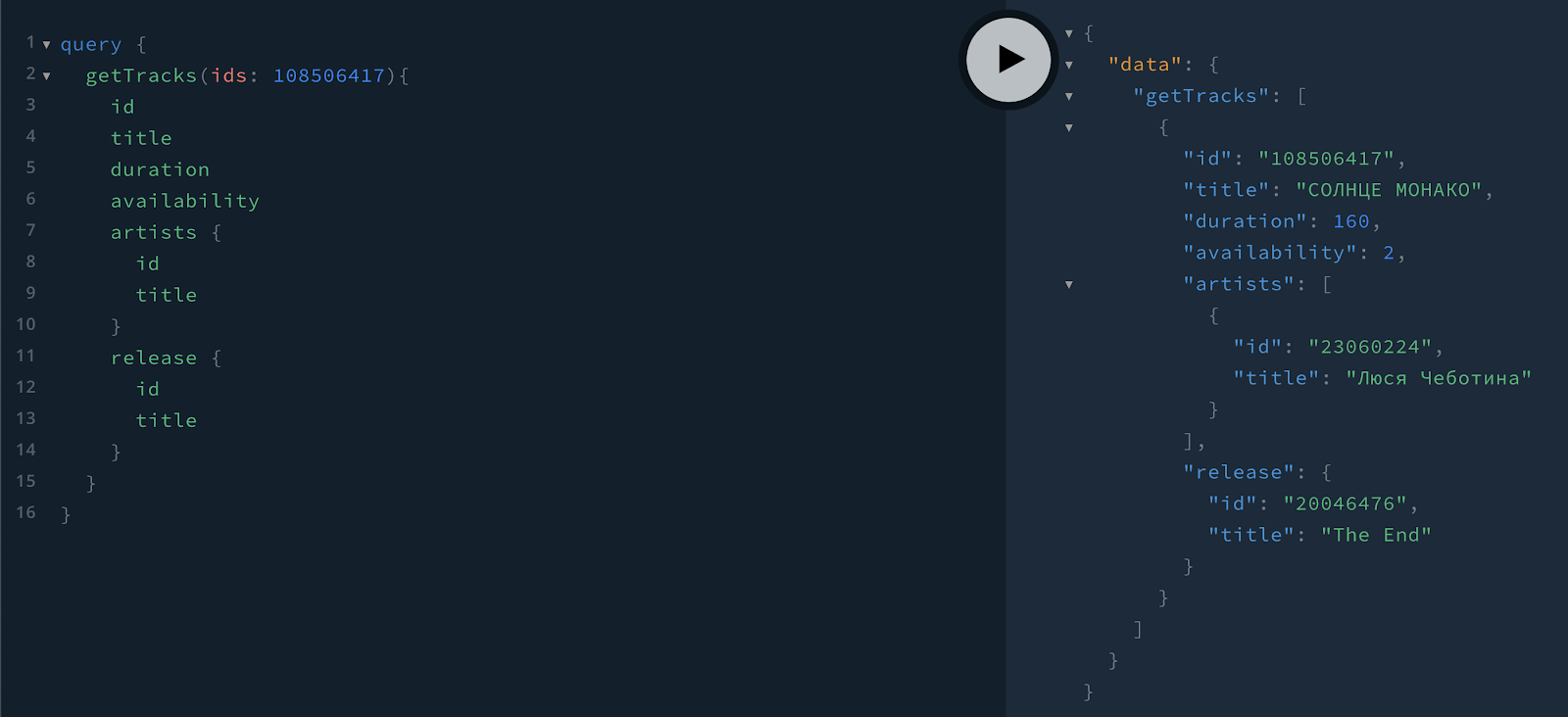
В ответе мы видим связь трека и артиста, который этот трек исполняет.
Mutation
Мутация – метод изменения данных. Для создания мутации её надо описать внутри типа Mutation.
Пример описания мутации – добавление и удаление сущностей из коллекции (коллекция – это хранилище любимых треков, альбомов и артистов пользователя). Здесь используется вложенность мутаций. Нужно это только для удобства.

На примере использование мутаций выглядит так:

Мы добавили трек с id 108506417 в коллекцию. В ответе нам вернулся null. Ошибки нет, всё успешно.
Можно выполнить запрос Query, чтобы получить треки из коллекции. Добавленный только что трек – там!

ENUM
Enum – конструкция для ограничения того, что можно передать в API. Например, при запросе добавления трека в коллекцию мы передавали туда тип CollectionItemType, который является enum и может принимать только следующие значения:
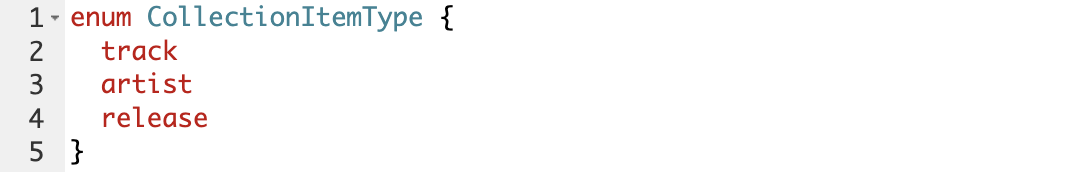
Если бы мы передали в запросе строку, которая не является одним из этих типов — на уровне API мы не смогли бы выполнить запрос.
UNION
Union – конструкция, которая позволяет одному объекту иметь разный набор данных. Например, у нас в Звуке есть несколько типов профилей – обычные пользователи, профили компаний и профили артистов. У профилей компаний есть сайт, которого нет у остальных типов. А у профилей артистов есть ссылка для донатов и связанный с профилем артист из сервиса информации о контенте. Для организации таких разных профилей используется UNION.

У профиля есть поле additionalData с типом ExtraProfileData, который является UNION. Соответственно, в зависимости от типа профиля он содержит те данные, которые у него должны быть. В схеме это описывается так:
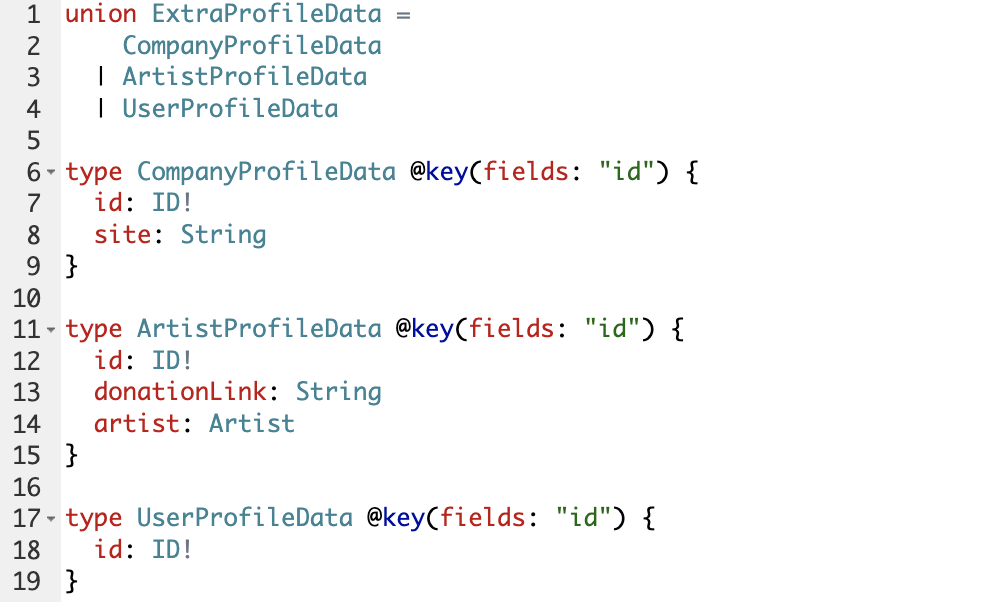
Пример запроса и ответа с UNION
Для выполнения запроса таких данных используется специальная конструкция.
При запросе объекта с UNION необходимо указать ключевое слово __typename. В ответ на это поле сервис вернёт одно из значений UNION (CompanyProfileData, ArtistProfileData, UserProfileData)
У каждого из объектов UNION может быть разный набор полей. Чтобы определить, какие поля мы хотим получить, надо указать конструкцию «... on CompanyProfileData». А дальше в этом объекте указать нужные поля.
Выглядит это так:
Запрос

Ответ для компании

Ответ для обычного пользователя

При выполнении одного запроса (с разными id) мы получаем те данные, которые есть у конкретного профиля. Так у профиля компании мы получаем сайт, а у пользователя никаких дополнительных данных нет.
GraphQL в микросервисной архитектуре
Причём тут микросервисы?
В микросервисной архитектуре данные о какой-то сущности могут находиться в разных базах данных и разных микросервисах. В REST подходе это решается несколькими возможными вариантами: несколько запросов с клиента в разные сервисы, соединение данных на каком-то самописном сервисе и тд. В GraphQL для решения этой проблемы мы используем инструмент Apollo Federation.
Apollo Federation
Apollo Federation – open-source решение, которое позволяет значительно снизить количество необходимой разработки. Официальная документация Apollo: https://www.apollographql.com/docs/federation/
Архитектура Apollo Federation
Архитектура Apollo Federation состоит из:
Клиентов – потребителей информации, которые понимают GraphQL и умеют делать запросы на этом языке (Apollo Clients для React, iOS, Kotlin).
Шлюза (Траслятора). На backend cоздаётся новый уровень в слое обработки запросов, предоставляющий доступ к GraphQL для клиентов. Когда клиентское приложение придёт за данными, то сервис на этом уровне выполнит запросы в сервисы, которые являются источниками нужных данных (Apollo Federation).
Набора подграфов – отдельных серверных служб, в каждой из которых определена GraphQL-схема части суперграфа, за которую она отвечает. Эти сервисы выступают источниками данных для сервиса Federation.
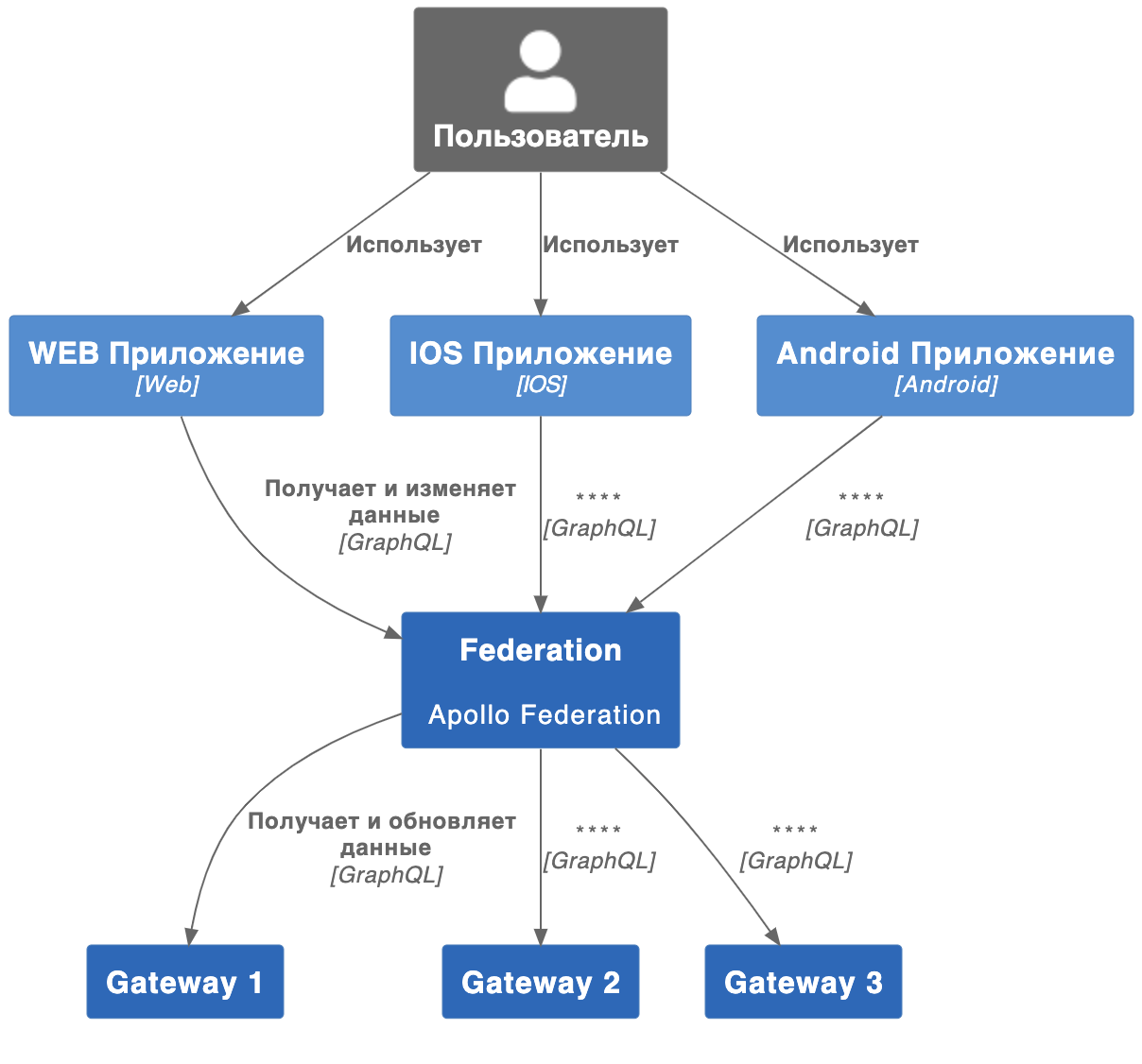
Как это работает у нас

У нас есть несколько баз данных, над ними находятся сервисы с GraphQL интерфейсом. Несколько сервисов с GraphQL интерфейсами объединяются сервисом Federation.
Что такое Federation? Сервис Federation собирается сам на основе схем других сервисов с GraphQL интерфейсами. Благодаря схемам остальных сервисов Федерация знает, где какие данные лежат. И сама за этими данными сходит, когда на неё придёт запрос. Сервис Federation не надо программировать, только настроить.
Как сделать связь между сервисами Apollo Federation
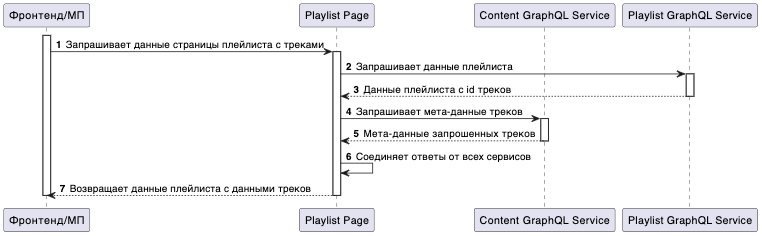
У нас в Звуке есть сервис Playlist GraphQL Service, который хранит в себе данные обо всех плейлистах. При этом в базе данных есть поле tracks, в котором просто лежит массив id треков (например — [ 123, 456, 789 ]). В сервисе плейлистов НЕТ данных треков (названия, картинки и тд).
При этом у нас есть сервис Content GraphQL Service, который хранит в себе мета-информацию по трекам (и не только).
Если мы выполним запрос данных плейлиста непосредственно к Playlist GraphQL Service, то сможем получить только id треков из этого плейлиста (так как в этом сервисе просто нет других данных).
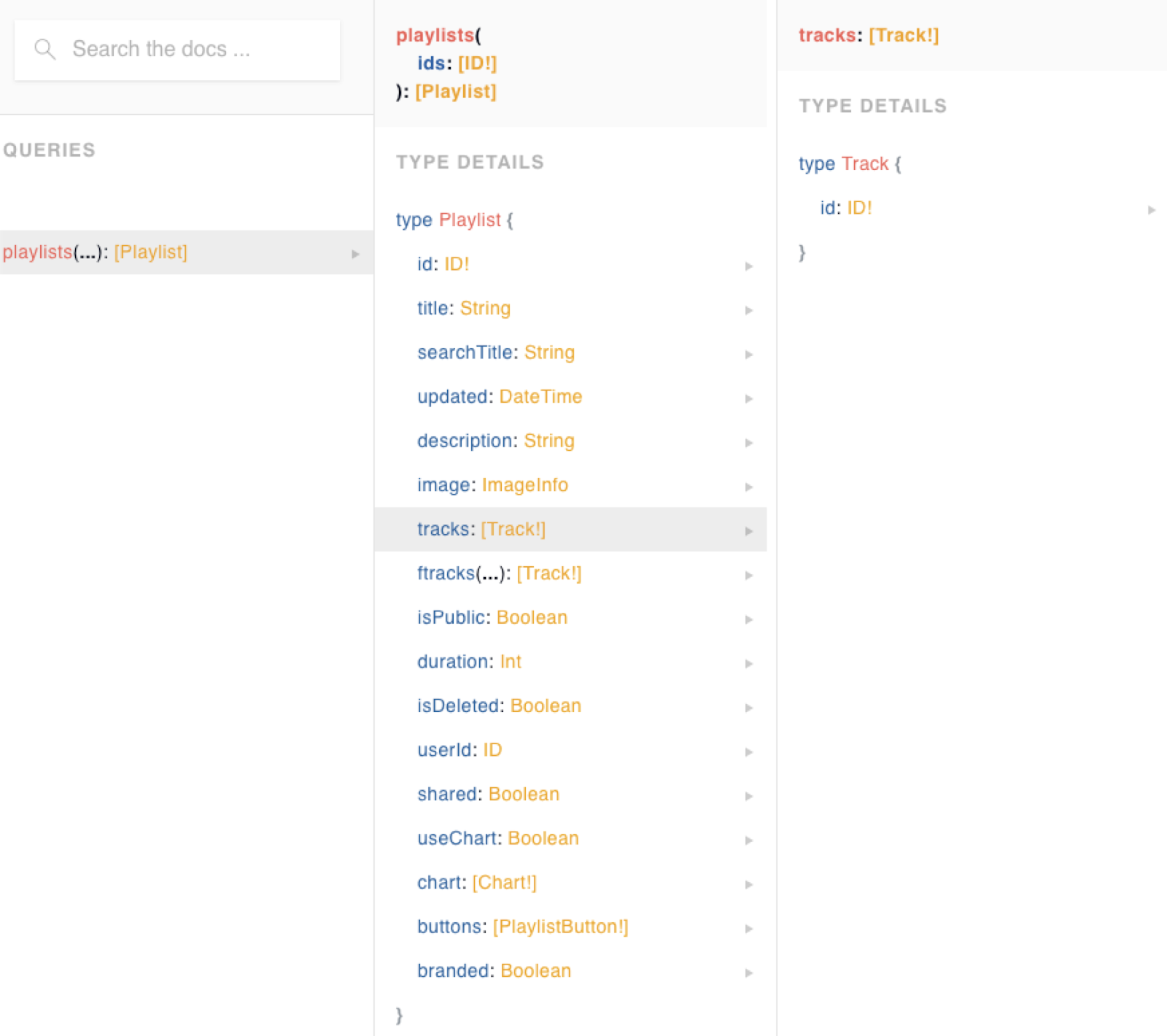
А при запросе к Federation мы видим в документации намного больше полей у трека, которые на самом деле лежат в Content GraphQL Service.
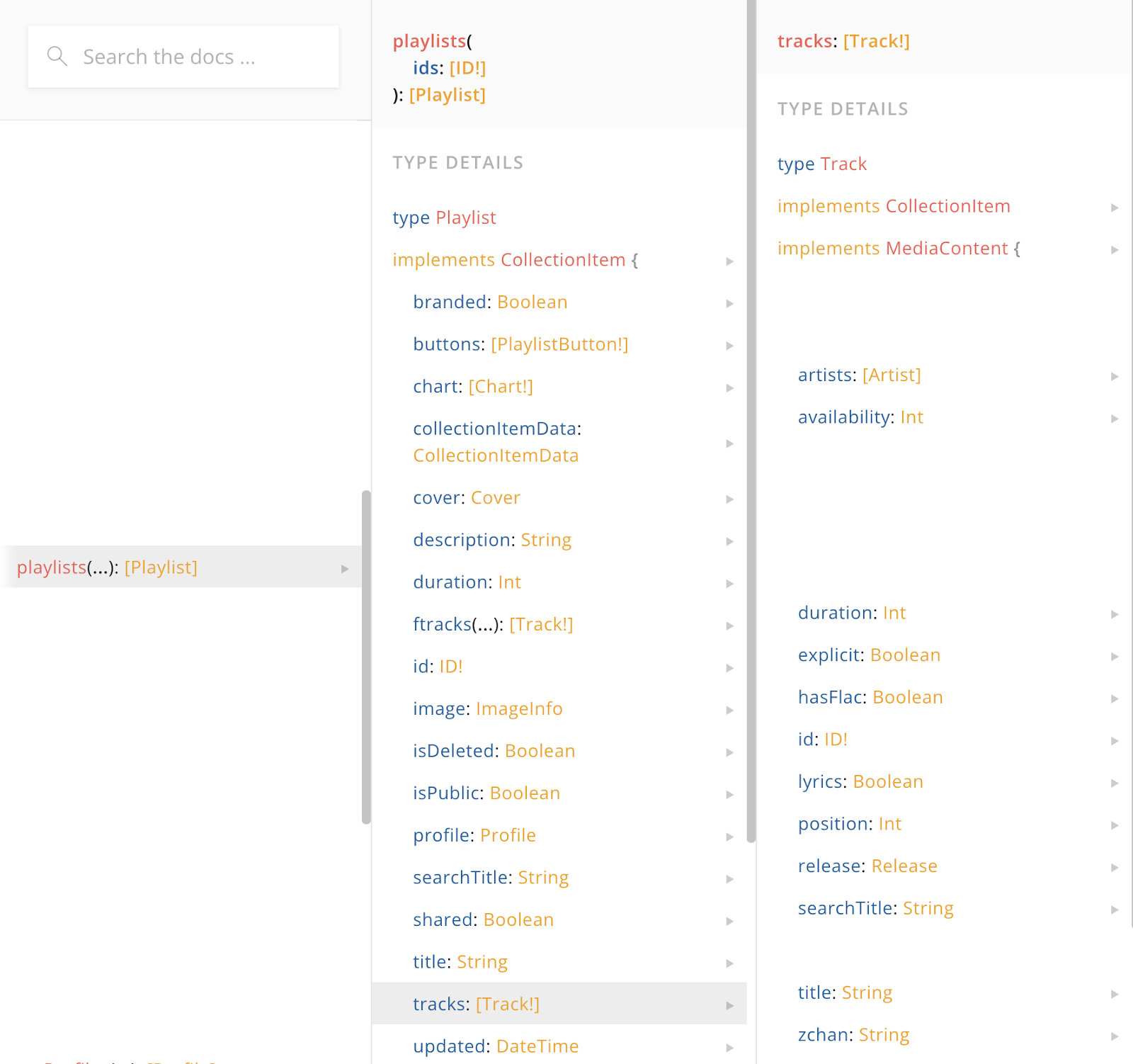
Можно выполнить один запрос сразу за всеми данными плейлиста. Для клиентских приложений всё выглядит так, как будто Федерация связывает между собой данные из разных сервисов и предоставляет единый удобный интерфейс.
Часть GraphQL схемы Playlist GraphQL Service:

Часть GraphQL схемы Content GraphQL Service:

Как сделать связь сущностей
Пример связи плейлистов и треков. Ещё раз отмечу – в сервисе плейлистов лежат только id треков, а в в сервисе мета лежит вся остальная мета-информация.
В Content GraphQL Service у сущности Track мы прописываем @key (fields: «id»), которые обозначают, что поле id – первичный ключ, по которому сущность можно связать с одноимёнными сущностями в других сервисах
В Playlist-Gateway надо создать сущность Track и прописать ей
@key (fields: «id») – по этому полю надо этот трек связывать с другими
@extends – эта сущность – наследник
@external около поля id значит, что это поле исходно находится в другом сервисе
В Playlist GraphQL Service у сущности Playlist поле tracks может возвращать тип Track, который мы уже обозначили в этом сервисе на шаге 2.
Теперь можно делать запросы, описанные выше.
Как это работает?
Благодаря тому, что на каждом сервисе есть описанная GraphQL Схема, Федерация знает, в какой сервис за какими данными надо обращаться. Так что для примера с плейлистами выполняется следующая последовательность шагов:
Запрос плейлистов с треками приходит на Федерацию (Federation)
Федерация идёт за данными плейлиста в Playlist GraphQL Service
Федерация получает данные плейлиста, и, в том числе, id треков, которые находятся в плейлисте
С этими id Федерация обращается в Content GraphQL Service для получения мета-данных треков
Федерация получает мета-данные треков, соединяет все данные из разных сервисов в один JSON и возвращает его на Фронт

Ещё один пример
У нас в Звуке есть социальная механика на пересечении музыки и технологий: пользователи могут проверить, насколько их вкусы совпадают, а ещё скоро появится возможность обогатить собственную коллекцию и получить плейлисты с рекомендациями на базе совместных предпочтений c треками в HiFi-качестве.
Каждый пользователь приложения Звук может увидеть жанровое совпадение предпочтений с другими слушателями в процентом соотношении. Оценка музыкальной совместимости базируется на анализе истории прослушиваний и действий пользователя внутри Звука — лайках и дизлайках

Реализовано это так, что у нас есть профиль в сервисе Profile GraphQL Service
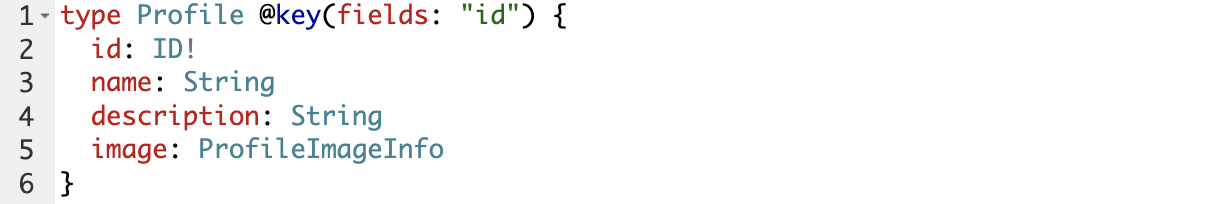
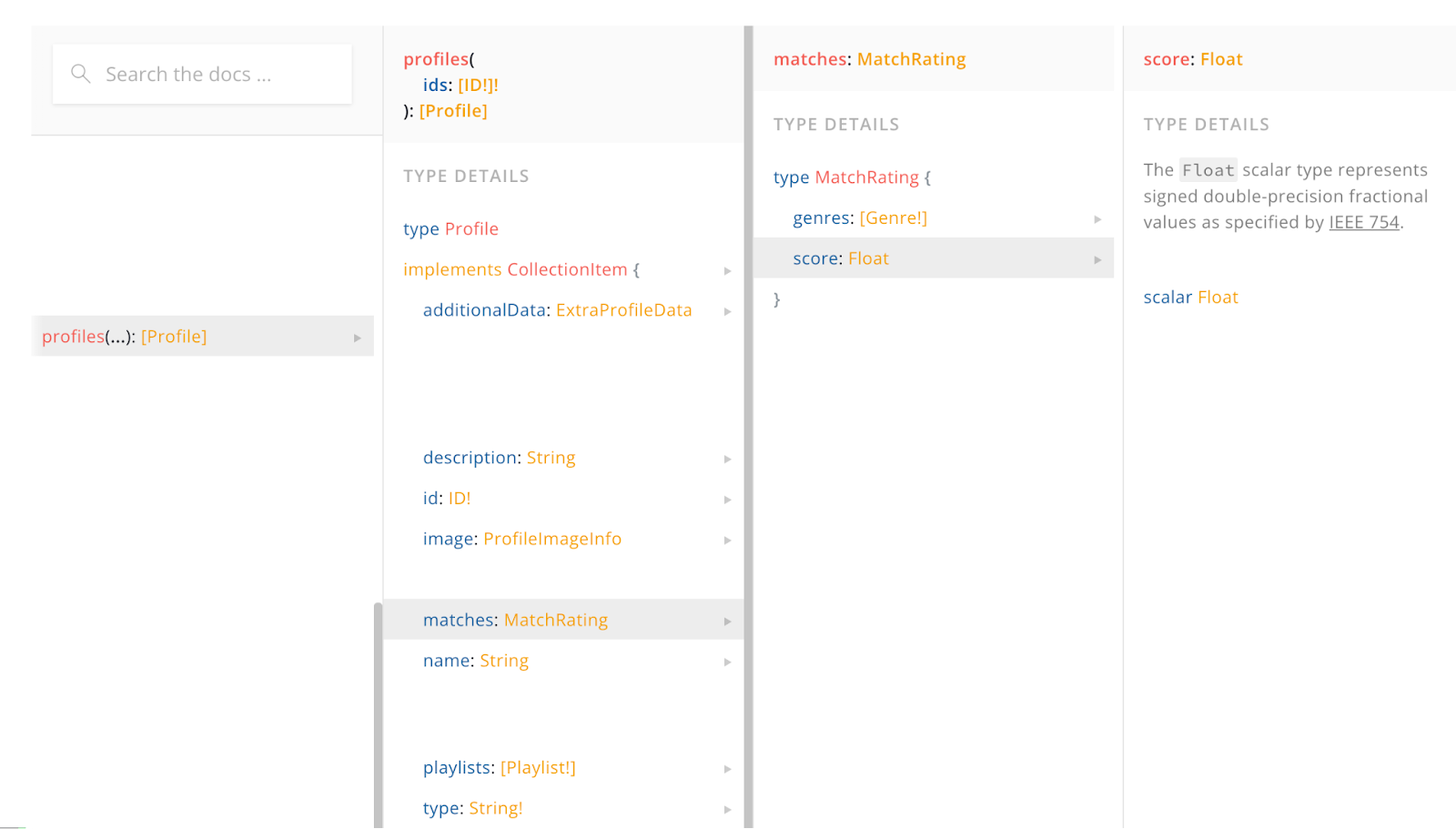
И у нас есть сервис Matchrating GraphQL Service, который производит расчёт и расширяет профиль этим числом score.

Это работает так, что когда на Федерацию приходит запрос профиля, где одним из полей будет поле matches, то Федерация сама знает, что за этим полем надо сходить в Matchrating GraphQL Service.
В итоге на Федерации документация выглядит так, что клиенты (IOS, Android, WEB) могут вообще не задумываться о том, где там что лежит.
Что было бы без GraphQL?
Ответ довольно очевиден – мы бы и дальше использовали REST. При этом нам пришлось бы намного больше сервисов программировать и поддерживать. Если рассмотреть пример со страницей плейлистов, то вполне можно было бы решить эту задачу и без использования GraphQL:
Отправка множества запросов данных с клиента, что значительно увеличивает нагрузку на фронтенд или мобильное приложение

Программирование и поддержка некоторого сервиса, который будет объединять данные из нескольких сервисов. По сути мы просто сами должны программировать аналог сервиса Federation (который, напомню, не требует разработки с нашей стороны)


При использовании REST API клиенты (фронтенд и мобильные приложения) всегда получали бы много лишних данных, которые не нужны им в данный момент для отрисовки страницы. GraphQL отдаёт клиентам только те данные, которые они запросили. Чем меньше данных, тем быстрее они загружаются с сервера в мобильное приложение.
Плюсы GraphQL
GraphQL создавался как альтернатива REST API и решает следующие проблемы:
Позволяет клиенту запрашивать только те данные, которые ему нужны.
Снимает необходимость несколько раз обращаться за данными.
Уменьшает зависимость клиента от сервера.
Делает разработку более эффективной за счет декларативного описания данных для API.
Минусы GraphQL
GraphQL, как и любая технология, имеет свои недостатки. Вот некоторые из них:
Уязвимость для атак на исчерпание ресурсов из-за избыточно сложных запросов с большой вложенностью (треки -> авторы трека -> треки авторов -> авторы трека -> …).
В GraphQL сложнее организовать ограничение доступа к данным. Каждый клиент может запросить почти всё, что хочет.
N+1 SQL-запросы (чтобы заполнить все поля-функции данными, может потребоваться новый SQL-запрос на каждое поле). У нас эта проблема решается использованием DataLoader’ов.
Более сложный подход к кэшированию в связи с тем, что в GraphQL нет возможности использовать стандартные для многих механизмы HTTP-кэширования. Для формирования ответа запрос GraphQL должен обязательно дойти до бэкенда.
Итог
Мы считаем, что в Звуке достоинства GraphQL значительно перевешивают недостатки. Благодаря этой технологии мы значительно упрощаем разработку и снижаем время доставки новых фичей до пользователей нашего сервиса.
Полезные ссылки
Официальная документация Apollo: https://www.apollographql.com/docs/federation/
Популярная статья на Habr с базовым объяснением концепции GraphQL: https://habr.com/ru/post/326986/

Нижников Евгений
Системный аналитик в Звуке, автор этой статьи
