
Изображение сгенерировано ИИ с помощью сервиса rudalle.ru
В течение нескольких последних месяцев многих, похоже, не покидает ощущение, что на глобальном рынке ИТ могут произойти серьёзные структурные изменения. Сопоставимые с тем, что происходило при появлении графических операционок, или в эпоху бума доткомов, или с появлением смартфонов.
Кто-то предрекает, что «обычные» поисковики и соцсети уйдут в прошлое, а им на смену придёт ChatGPT. Предрекают большое количество новых возможностей — и настолько же большие потрясения на рынке труда: целые профессии станут не нужны. Есть и те, кто считает, что сильный искусственный интеллект совсем рядом и серьёзное внимание нужно уделять вопросам безопасности человечества перед лицом открывающихся угроз со стороны искусственного разума.
Мы оставим без особых комментариев потуги футуристов и визионеров и сосредоточимся на более практической задаче: можно ли определить, кем написан текст — машиной или человеком.
Что случилось?
В конце ноября 2022 года компания OpenAI представила всему миру нового нейросетевого чат-бота ChatGPT, который был собран на основе InstructGPT. Выпущенный чат-бот способен вести диалоги, отвечать на вопросы пользователей, исправлять ошибки и, самое главное, делать всё это точнее и информативнее предыдущих моделей. Аудитория продукта всего за два месяца достигла 100 млн человек. Пользователи по всему миру успели опробовать нейросеть для различного пула задач: например, ChatGPT сдал экзамен MBA, экзамены на врача и юриста в США и даже прошёл собеседование в Google. Согласитесь, такой насыщенной жизни можно только позавидовать!
В OpenAI тренировали нашумевший чат-бот, используя размеченные данные и методы обучения с подкреплением. В его основе работает модель InstructGPT (она же GPT-3.5), но в чём кардинальное отличие от GPT-3? Ведь в своё время и эта языковая модель с 175 млрд параметров также успела навести шороху. Дело в том, что стандартная GPT-3 зачастую генерировала текст, не соответствующий запросам пользователей, и не была нацелена на длительное ведение диалога. Именно эти особенности исследователи из OpenAI решили внести в новую версию и дообучили нейросеть на ответах пользователей. К примеру, были наняты люди, которые вручную составляли ответы на запросы, а затем на полученных парах «запрос — ответ» производилось дообучение с учителем. На другой стадии людей просили ранжировать выданные предыдущей версией модели ответы на те или иные входные тексты: от самого релевантного до полного несоответствия. Эти и ещё несколько методов позволили GPT-3.5 иметь за собой не только огромную базу выученных текстов, но и умение поддерживать диалог и отвечать более релевантным пользователю ответом.
Ну а дальше дело техники: сделали удобный API-интерфейс, пара удачных заголовков в СМИ — и всё, успех ChatGPT был неизбежен. Сегодня о нём не говорит только ленивый. Чат-бот может быть отличным помощником для решения повседневных задач, и в целом как программа он довольно удобный. Однако уже существуют случаи, когда сгенерированные тексты используются в неэтичных целях. Скорее всего количество таких попыток будет быстро расти. Насколько сегодня возможно отличать текст, сгенерированный нейросетью, от текста, созданного непосредственно человеком? Делимся интересными выводами, полученными на основе реального опыта.
А что было раньше?
Если вы думаете, что машинно сгенерированные тексты стали распространяться лишь с появлением семейства моделей GPT, то вы сильно ошибаетесь. Одни из первых детекторов появились аж в 2008 (!) году. Да, из разнообразия методов для генерации можно лишь выбрать биграммы или триграммы, но это лучше, чем ничего. В статье S. Badaskar приводит методы борьбы с такими текстами, они основаны на порождении признаков:
- эмпирических (подсчёт perplexity реальных и фейковых текстов, частота встречаемости пар слов),
- синтаксических (грамматические парсеры — Charniak Parser),
- семантических (учёт связей на уровне предложений и на уровне слов, тематическая избыточность, Yule’s Q-statistic, SVD).

Рис 1. Гистограммы, показывающие различие (а) уровня перплексии триграммной модели и (б) средних значений признаков тематической связности для сгенерированных текстов и написанных человеком.
Предполагаем, что каждый из этих признаков имеет численную разность для настоящих текстов и сгенерированных. Комбинация этих признаков позволяла достигать 90% accuracy c применением классификаторов AdaBoost и Support Vector Machine на датасетах тех времён (напомним, это 2000-е!).
Вопрос порождения признаков для идентификации сгенерированных текстов был актуален довольно длительный период времени, вплоть до 2018-го, именно Nguyen-Son в своей статье предложил признаки, основанные на статистическом анализе — законе Ципфа.
«Частота наиболее встречающего слова в написанном человеком тексте, примерно в два раза превышает частоту встречаемости следующего по списку наиболее употребляемых слов, в три раза — третье слово и так далее»
По заявлению авторов, это утверждение не выполняется для машинно сгенерированных текстов. Люди склонны использовать более сложные естественные языки, чем компьютеры. Помимо этого, было предложено извлекать сложные фразы, фразовые глаголы, идиомы и диалектовые особенности, употребление которых более свойственно человеку. Классификаторы использовались довольно классические: логистическая регрессия и SVM.

Рис 2. Предложенная схема для различения компьютерного текста и текста, написанного человеком, сочетающая в себе комбинацию признаков.
Эксперимент проведён на 100 английских книгах и их переводе, здесь перевод рассматривается как одна из разновидностей машинно сгенерированных текстов. Лучший результат достигнут на комбинации всех признаков, рассмотренных в работе.
Мы решили проверить применимость закона Ципфа для идентификации текста, сгенерированного современными моделями ИИ наподобие ChatGPT. Для анализа использовали параллельные тексты из датасета для определения машинно-сгенерированных текстов на русском языке. Примеры в нём содержат настоящие и сгенерированные статьи, каждая искусственная продолжена генеративной моделью по первому предложению из настоящей. Для одной такой пары текстов провели сравнительный анализ и построили кривые частот.

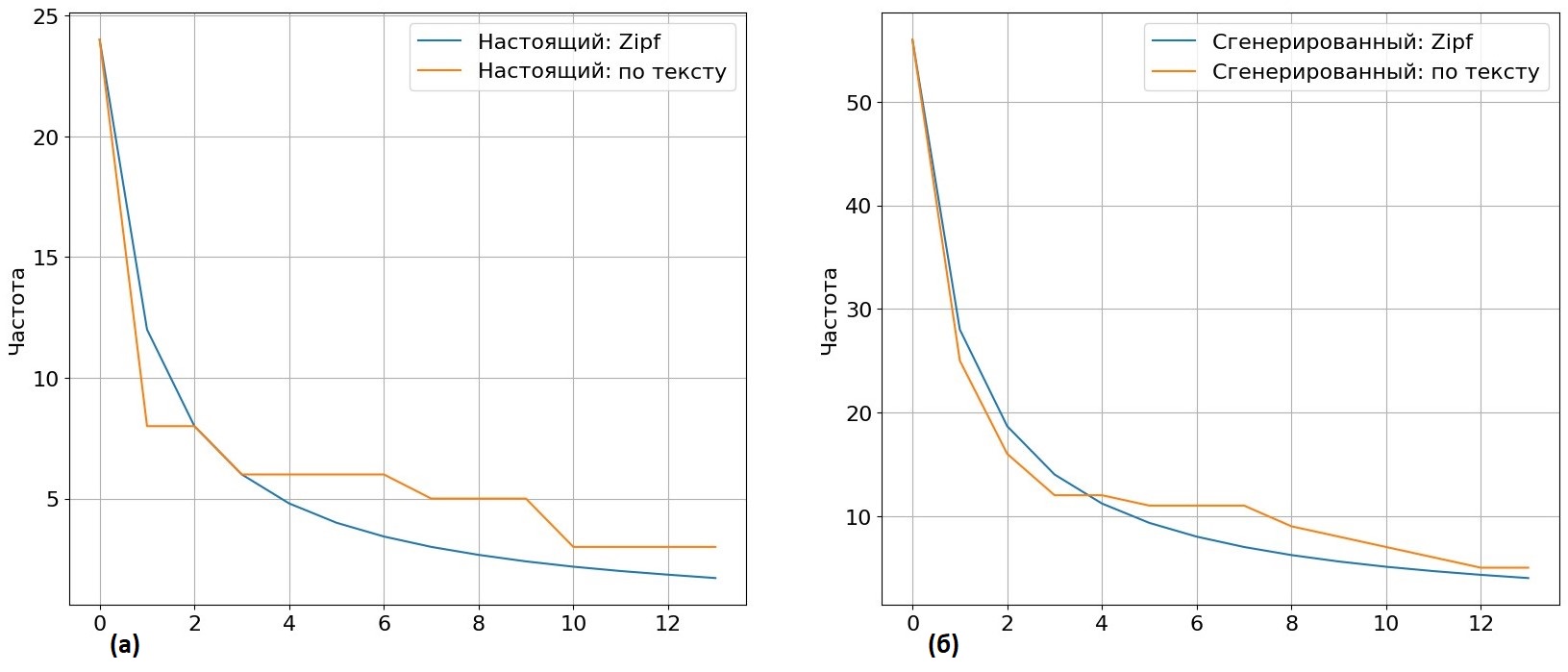
Рис 3. На рисунке (а) сравнительный анализ встречаемости в тексте и по закону Ципфа для настоящей статьи, в (б) — для сгенерированной.
Реальность такова, что современные генеративные модели (в датасете тексты семплировались из ruGPT-3), обучившись на терабайтах текстов, написанных людьми, вполне способны соблюдать закон Ципфа, причём порой даже лучше, чем человек.
А что сейчас?
Появление архитектуры «трансформер» открыло новое поле для исследований. Изменился подход для генерации текстов, они стали более связными и способными удерживать смысл на протяжении нескольких предложений. Правда, и методы борьбы с такими текстами также претерпели изменения. Причём успех генерации зависел не только от выбранной модели с миллионом или даже миллиардом параметров, но и от методов декодирования. Всё упиралось и упирается до сих пор в принцип работы текстовых генеративных моделей: на каждом шаге выдавать распределение вероятностей следующего токена. Анализ стратегий (top-k, top-p, temperature sampling) провел D. Ippolito, и, как оказалось, для каждой стратегии количество токенов, необходимое для детектирования машинно сгенерированного текста, различается. Это означает, что для получения обширной обобщающей способности будущего детектора он должен быть устойчив к текстам, порождённым разными моделями с различными методами декодирования.
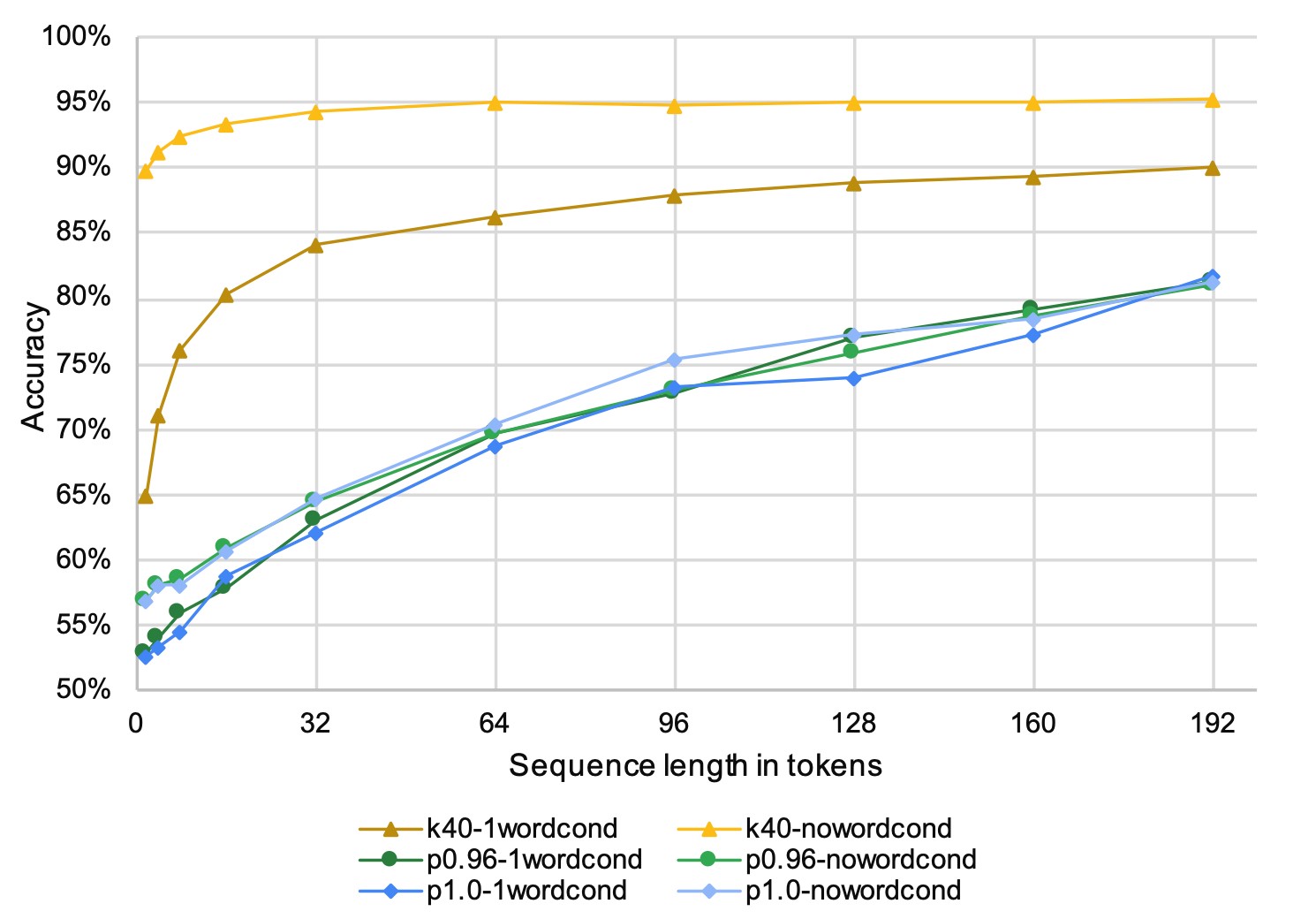
Рис 4. Точность возрастает по мере увеличения длины последовательностей, используемых для обучения дискриминатора.
Развивались не только генеративные модели, но и классификаторы. Здесь можем заметить плавный переход от total probability (общая вероятность текста) и bag of words (мешок слов) + логистическая регрессия к fine-tuning BERT-модели. Совокупность текстов и дискриминаторов данного подхода позволила авторам достичь 90% по метрике accuracy при детекции текстов, сгенерированных GPT-2. Лучшее качество показали при fine-tuning BERT’а, а более универсальной стратегией декодирования, которая оказалась устойчива к текстам с отличающимися методами сэмплирования, стала top-p. Отдельно стоит отметить зависимость качества детектирования от размера машинно-сгенерированного текста. Мы провели исследование, по результатам которого стало ясно, что для корректной детекции документов, особенно длинных, важна ещё и длина подаваемой в модель последовательности токенов. Лишь при дообучении на 512 токенах для английского и 256 для русского transformer-based-модели достигали плато в исследуемых метриках. Это можно объяснить тем, что в длинных документах связь между фрагментами может крыться не только на уровне слов внутри предложения, но и на уровне самих предложений и абзацев.
На сегодняшний день лидирующий подход среди дискриминаторов — это дообучение BERT-подобных предобученных моделей. Заметим, что внимание к текстам сгенерированным GPT-семейством, набирало обороты неспроста. В 2020 году A. Uchendu провел анализ корпусов от имеющихся на тот момент генеративных моделей (GPT-like, CTRL, Grover, XLM, PPLM и FAIR), и именно GPT-like-модели показали наивысшие результаты при сравнении лингвистических признаков на предмет «человекоподобности». Анализ также показал, что fine-tune RoBERT’ы обошёл по качеству детекции ранее используемые методы: свёрточные и рекуррентные нейронные сети.
Сейчас картина в сфере генерации и детектирования выглядит следующим образом: у генеративных моделей появляется всё больше параметров, их обучают на постоянно увеличивающемся количестве текстов из интернет-источников, задействуют обучение с подкреплением и фидбэк пользователей, в то же время детекторы строятся на основе BERT-подобных моделей, которые могут быть применены совместно со статистическим/лингвистическим анализом фрагментов. С другой стороны, на это можно посмотреть как на real-time-обучение генеративно-состязательных сетей (GAN), где генеративная модель пытается запутать дискриминативную, а та, в свою очередь, учится верно отличать примеры. Кто окажется сильнее — покажет время.
- важно понимать, откуда могут приходить тексты и какими методами они могли быть получены, — всё это должно учитываться при формировании обучающей выборки,
- необходимо подумать о длине фрагмента, которую вы хотите отправлять на классификацию: есть зависимость между количеством токенов и результатом детекции,
- для первичного этапа классификации можно использовать предобученные BERT-подобные модели, а для повышения точности дискриминатора можно провести трешхолдинг или применить старые и незабытые лингвистические признаки.

ChatGPT, напиши мне, пожалуйста, диплом...
Совсем недавно российское образовательное сообщество наблюдало интересную ситуацию: студент РГГУ Александр Жадан защитил диплом, который был написан при помощи ChatGPT. Громкие заголовки в стиле «Нейросеть написала диплом», «ИИ за вечер сделал ВКР», «Дипломы будут писать нейросети» буквально разрывали медиапространство, поэтому мы решили разобраться в этой ситуации и проверить, всё ли так однозначно.
Спойлер: дипломная работа была получена не одним простым запросом наподобие того, что стоит в названии этой секции.
По рассказам самого А. Жадана, план работы после долгих правок был составлен совместно с научным руководителем. Далее выпускник делал запросы по каждой из частей теоретической секции в ChatGPT на английском языке (так скорость выше, а дело всё в токенизаторе OpenAI для русского языка). Получив ответ на английском, Александр Жадан переводил его при помощи «Яндекс.Переводчика» на русский язык, правив ошибки в падежах, склонениях и другие недочёты. Добавлять источники студент также просил нейросеть, однако многие из них приходилось перепроверять и дополнять указанием страниц цитирования, поиск которых он проводил сам. В практической части А. Жадан немного изменил подход: взяв за основу похожую работу, выпускник подавал запрос в ChatGPT на перефразирование существующего текста, подставляя далее собственные значения. Суммарно студент потратил на работу с ChatGPT 23 часа: 15 часов ушло на написание и 9 часов — на редактирование.
Мы решили подробнее изучить список литературы, несмотря на то что он был откорректирован самим студентом. Выяснилось, что некоторые источники выглядят довольно подозрительно:

Рис 5. Выявленные ошибки в библиографическом списке диплома студента РГГУ
Чаще всего среди приведённых источников можно заметить несоответствие даты выпуска, автора и журнала. Однако встречались также работы с указанием несуществующих страниц и даже библиографические ссылки, которые вообще не удалось найти при поиске. Описанные проблемы встречаются как среди русскоязычной, так и среди англоязычной литературы, приведённой в дипломной работе. Мы не можем исключать варианта ошибок самого студента при редактировании, однако, по его словам в недавно вышедших интервью, первоначальные ссылки бывали и хуже. Связано это напрямую со способностью ChatGPT «сочинять на ходу»: зачастую можно встретить правильную, на первый взгляд, ссылку, однако в ней мог быть догенерирован неверный год или страницы. Это наталкивает на мысль, что для научных работ проверка литературы — обязательный шаг для выявления машинной генерации.
Вишенка на сгенерированном торте — логические ошибки в тексте. Жадан несколько раз упоминал и приводил пример (см. рис. 6), что исправлял такие недочёты локально, однако на более глобальном уровне они всё же остаются. Но поймать их не так-то просто! Наша команда уже решала подобную задачу в рамках конкурса «ПРО//ЧТЕНИЕ» и мы знаем, какие методы можно использовать для поиска таких ошибок. Можно точно сказать, что модуль обнаружения логических ошибок — незаменимый компонент для идентификации машинно-сгенерированных текстов.

Рис 6. Пример А. Жадана из своей дипломной работы до корректировки введения
Пресса особо отмечает, что текст диплома прошёл проверку на плагиат. Уровень оригинальности 82% до некоторой степени может оправдать наличие описанных проблем – может оказаться, что работам с высоким уровнем оригинальности в вузах будут просто уделять меньше внимания.
Следовательно, Антиплагиату необходимы методы, помогающие распознать сгенерированные тексты. Так получилось, что наша команда уже давно присматривалась в теме и делала наработки по обнаружению машинно-сгенерированных текстов. Нам осталось «сдуть пыль» с сервиса детектирования машинно-сгенерированных текстов. Когда мы «прогнали» через него дипломную работу студента РГГУ, то он показал, что более 20% всего текста было сгенерировано. Причём для среднестатистической студенческой работы этот показатель менее 1%. Стоит отметить, что в данном случае речь не идет о «чистой» генерации – текст диплома подвергался редактированию самим студентом.
Заметим, что мы использовали модель детекции из исследований, которые были представлены в сентябре прошлого года и не содержали тексты, сгенерированные ChatGPT, так как её тогда просто не было… Однако, как показывает практика, получив качественный детектор для нескольких видов GPT-подобных моделей, уровень классификации будущих поколений моделей остаётся на хорошем уровне.
Готовь сани летом, а телегу зимой
Собственно «телега» была сделана некоторое время назад и стояла «на запасном пути». Теперь она пригодилась, и к летней сессии детектор машинно-сгенерированных текстов уже будет работать в промышленном окружении.
Если в проверяемом документе обнаружатся сгенерированные фрагменты, в отчёт о проверке будет вводиться соответствующая информация. Мы провели дополнительные работы и подготовили сервис. На закрытом бета-тесте на сбалансированной тестовой выборке сервис показал 11 ложноположительных срабатываний на 1000 текстах, написанных людьми, и смог идентифицировать 97% текстов такого же объёма, написанных нейросетью. Основываясь на полученных результатах, система «Антиплагиат» предоставит пользователям возможность видеть фрагменты проверяемых работ, которые могли быть получены при помощи инструментов ИИ. Детектор обучен на большом наборе академических данных и настроен на сведение ложных срабатываний к минимуму.

Рис 7. Пример секции, указывающей на наличие сгенерированного фрагмента в проверяемом тексте
И все-таки творите собственным умом!
