
Новый эпизод нашего сериала о любопытных историях из практики. Использовать эти истории для развлечения или как практические рекомендации — решать вам, но мы сразу предупреждаем, что приводимые в них инструкции зачастую далеки от универсальных. Вместо этого вы можете встретить обходные пути для решения специфичных проблем в специфичных условиях. Зато они всегда расширяют кругозор и помогают посмотреть на некоторые технологии и их применение под новым углом.

В этой серии:
переносим Ceph с одного бэкенда на другой;
подпираем костылём бесконечное падение liveness- и readiness-проб в Kubernetes;
устраняем баг в Kubernetes-операторе для Redis.
История 1. Как мы сбежали от прожорливого BlueStore
Внимание!
Все нижеописанные действия в этой истории НЕ рекомендуются как лучшие практики. Мы выполняли их на свой страх и риск, осторожно и осознанно. Эта история о том, что бывает, когда всё пошло по наклонной, а другие варианты решения не подходили.
При развертывании Ceph-хранилища у одного из клиентов в качестве бэкенда мы изначально выбрали BlueStore. Он производителен, надежен и функционален, для обработки данных используются внутренние механизмы кэширования, а не page cache.
Однако через некоторое время заметили, что Ceph просто «съедает» всю память узла: мы получали Out of memory, узел перезагружался. Можно было бы заняться тюнингом выделения памяти в BlueStore, но данный бэкенд требует больше памяти, которой у нас не было. Имея в распоряжении кластер не самых богатых мощностей и без возможности их нарастить, мы приняли нестандартное решение: мигрировать на FileStore. В Ceph уже были данные, которые нельзя было терять (но имелись актуальные бэкапы).
Расскажем, как мы это делали пошагово.
Важно: все действия должны выполняться на гипервизоре с OSD на борту.
Смотрим, как разбиты диски, на каких разделах работает Ceph. Для этого воспользуемся командой
lsblk.
Получаем список OSD:
ceph osd tree.
Выставляем количество репликаций объектов в 2:
ceph osd pool set kube size 2.
Важно: намеренное снижение избыточности перед потенциально деструктивными операциями в кластере очень опасно. В нашем случае это было сознательное допущение, так как «под рукой» были бэкапы всех необходимых данных.
Помечаем OSD на «выброс» из кластера:
ceph osd out <OSD_ID>. Дожидаемся окончания ребалансировки и убеждаемся, что все pg имеют статусactive+clean. Для этого можно использовать команду:watch ceph -s.

Останавливаем сервис OSD, чтобы Ceph не пытался запустить его:
service ceph-osd@<OSD_ID> stop.Параллельно наблюдаем за использованием OSD, чтобы ребалансировка не прервалась:
watch ceph osd df.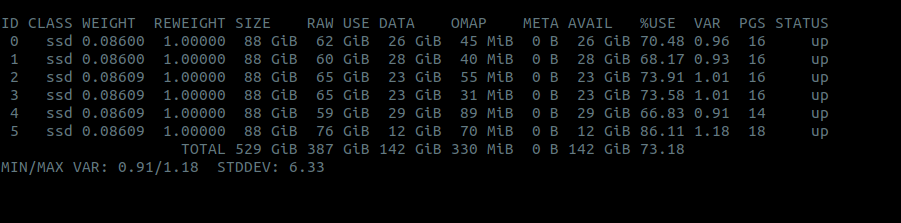

Чистим раздел от данных и файловой системы. Для этого смотрим, какие партиции используются Сeph’ом:
ceph-volume lvm list.

Выполняем ceph-volume lvm zap <lvm_partition_for_remove OSD>.
Удаляем данные OSD для мониторов, включая OSD ID- и CRUSH-позиции:
ceph osd purge <OSD_ID> --yes-i-really-mean-it.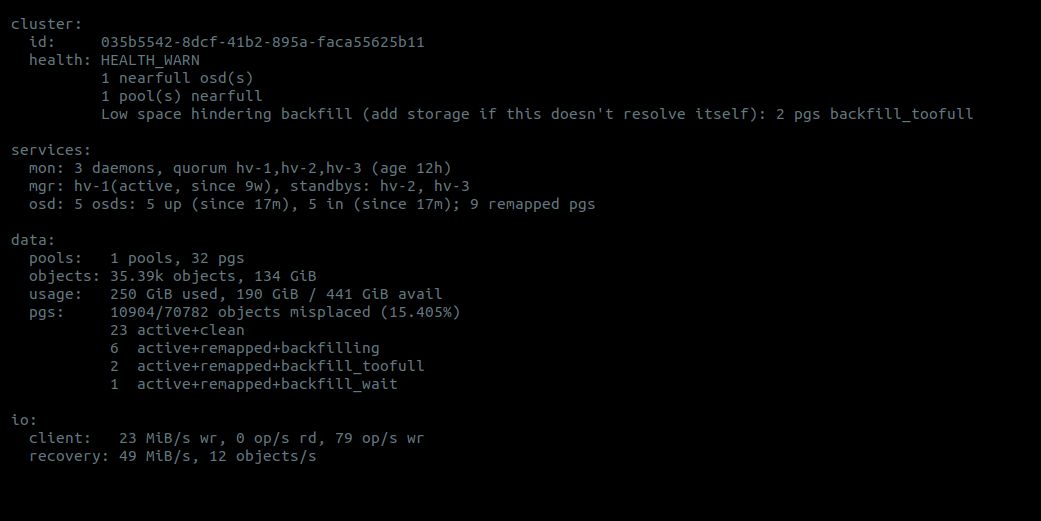

Удаляем неиспользуемый LVM-том:
lvremove vgname/lvname.
Преобразуем таблицу разделов MBR в GPT (ды, мы «сорвали куш» и имели таблицу MBR):
a) если не установлена утилита
gdisk— устанавливаем:apt install gdisk;b) создаем новый раздел с расположением на секторах
34-2047и типомef02.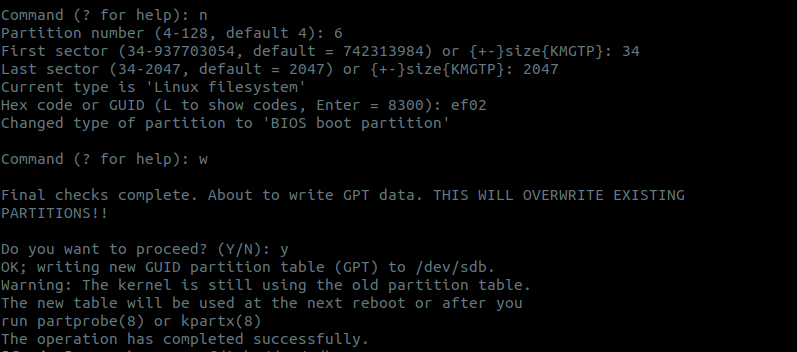

Создаем разделы для новой OSD:
a)
fdisk /dev/sdX;b) удаляем раздел, который использовался удаленной OSD:
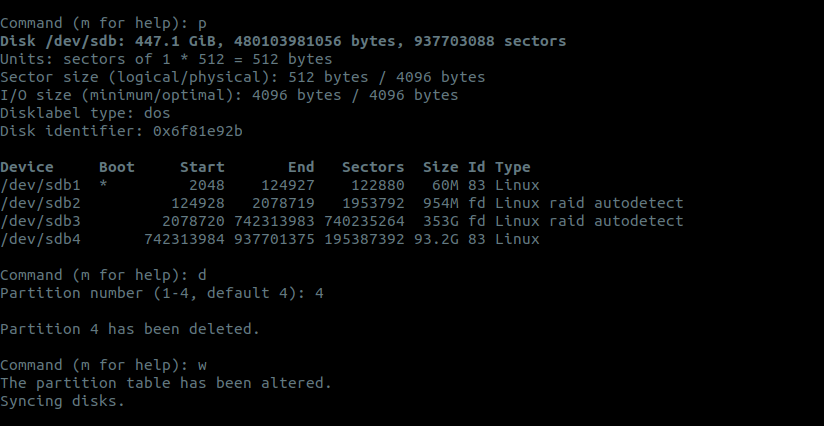
c) Создаем два новых раздела: первый — для журналирования, второй — для данных:


Выполняем
grub-install /dev/sdX.
Финальные шаги — действия, которые необходимо выполнить на узле, что используется для деплоя из-под пользователя ceph-deploy.
Начинаем с команды:
ceph-deploy osd create --filestore --data /dev/sdXY --journal /dev/sdXY <target_hypervisor>.
Дожидаемся завершения установки и ребалансировки.
Выставляем количество репликаций объектов в 3:
ceph osd pool set kube size 3.
История 2. Бесконечно падающие пробы
В одном из проектов мы столкнулись с проблемой постоянно падающих liveness- и readiness-проб у приложений в production-окружении. Из-за этого все экземпляры приложения могли быть недоступны, как и сам клиентский сервис. Инженеру приходилось вручную рестартить проблемные приложения — это спасало, но ненадолго.
Клиент знал об этой ситуации, но, к сожалению, приоритеты бизнеса были таковы, что изменений на стороне приложения ждать не приходилось. Поэтому, несмотря на все наши представления об идеальных мирах Dev и Ops, пришлось автоматизировать… костыль.
Решение: shell-operator
Чтобы не тратить время на рутинную и неблагодарную работу, мы решили сделать оператор, который выполняет rollout restart необходимых приложений. Рестарт происходит при условии, что нет ни одного работоспособного экземпляра приложения. Механизм был реализован на Bash с помощью shell-operator.
Как это работает:
подписываемся на изменение ресурса Deployment;
при каждом изменении сверяем два поля:
.status.replicasи.status.unavailableReplicas;если значения равны — выполняется rollout restart. В противном случае ждем дальше.
Всё это было согласовано с клиентом. И заодно мы начали высылать клиенту алерты, когда количество доступных реплик приложения уменьшается.
Внимательный читатель мог задаться вопросом, почему не подошла liveness-проба. Дело в том, что постоянно падающая liveness-проба приводила к CrashLoopBackOff, что в своё время увеличивало счётчик рестартов и, соответственно, время для следующего перезапуска Pod’а.
Подводный камень
Оператор работал исправно. Мы всё реже напоминали о проблемах с пробами, и клиенту получившаяся времянка нравилась. Но как-то раз он решил перекатить Deployment с одной репликой — и тут началось интересное… Приложение ушло в бесконечный рестарт:
shell-operator видел новый Pod, статус которого на момент его обнаружения был отличен от
Ready;Pod перезапускался согласно логике… и так — по кругу.
Пришлось сделать дополнительную проверку с отложенным запуском в 15 секунд: если через 15 секунд после первой проверки количество реплик у приложения по-прежнему равно нулю, выполняется перезапуск.
Итоговый ConfigMap с получившимся хуком выглядит так:
apiVersion: v1
kind: ConfigMap
metadata:
name: hooks
data:
deployment-restart-hook.sh: |
#!/usr/bin/env bash
ARRAY_COUNT=jq -r '. | length-1' $BINDING_CONTEXT_PATH
if [[
cat <<EOF
configVersion: v1
kubernetes:
- name: OnDeploymentReady
apiVersion: apps/v1
kind: Deployment
namespace:
nameSelector:
matchNames: ["production"]
executeHookOnEvent:
- Modified
jqFilter: .status.replicas == .status.unavailableReplicas
EOF
else
if [[ $type == "Synchronization" ]] ; then
echo Got Synchronization event
exit 0
fi
for IND in `seq 0 $ARRAY_COUNT`
do
objName=`jq -r ".[$IND].object.metadata.name" $BINDING_CONTEXT_PATH`
nsName=`jq -r ".[$IND].object.metadata.namespace" $BINDING_CONTEXT_PATH`
echo "Deployment ${objName} in namespace ${nsName} not ready and will restart now!"
if [[ ${objName} != "null" ]]; then
sleep 15;
echo "Waiting approve what deployment ${objName} don't have ready replicas"
statusReplicas=" class="formula inline">(kubectl -n statusUnavailableReplicas=" class="formula inline">(kubectl -n ${nsName} get deployment ${objName} --output=jsonpath={.status.unavailableReplicas})
if [[ $statusReplicas == $statusUnavailableReplicas ]]; then
echo "Restarting deployment ${objName}"
kubectl -n ${nsName} rollout restart deployment ${objName}
fi
fi
done
fi
Итоговая времянка — двойной костыль. Есть ли этому оправдание — вопрос, освещение которое требует самостоятельной статьи. А пока мы продолжаем время от времени напоминать клиенту о необходимости доработки liveness- и readiness-проб…
История 3. redis-operator и потерявшийся приоритет
Для запуска Redis в Kubernetes долгое время мы пользовались redis-operator от spotahome. До поры мы не замечали глобальных проблем (кроме той, что уже обсуждали пару лет назад), но однажды столкнулись с неработающим priorityClassName.
Priority Class — это функция, которая позволяет учитывать приоритет Pod’а (из его принадлежности к классу) при планировании. Если Pod не может быть запущен на подходящем узле из-за нехватки ресурсов, то планировщик (scheduler) пытается «вытеснить» Pod’ы с более низким приоритетом и переместить их на другие узлы кластера, чтобы освободить ресурсы и запустить ожидающий Pod.
Выставлять Priority Class нужно осторожно, так как в случае его неверного определения могут быть самые неожиданные последствия.
У приложений был установлен priorityClass с value 10 000. А у манифестов, созданных с помощью оператора, приоритет не выставлялся, несмотря на его описание в ресурсе redisfailover. Поэтому Pod’ы приложения «вытесняли» Redis.
На момент решения нами этой проблемы последняя версия redis-operator’а была годичной давности, так как разработчик давно его не обновлял, из-за чего мы были вынуждены подготовить свой релиз. И нам удалось даже найти PR с фиксом (пользуясь случаем, передаем привет @identw!). Однако совсем недавно, в январе, появился новый релиз на GitHub (пока только RC), где эта задача решается «из коробки». Поэтому свою инструкцию по сборке спрячем в спойлер.
Инструкция по сборке
Мы воспользовались werf и субмодулями:
1. Добавляем субмодули и локаемся на одном из коммитов (чтобы не нарваться на внезапное обновление оператора):
git submodule add https://github.com/spotahome/redis-operator.git
cd redis-operator
git checkout $commit2. Создаем werf.yaml, который использует Dockerfile внутри субмодуля:
project: redis-operator
configVersion: 1
---
image: redisOperator
dockerfile: docker/app/Dockerfile
context: redis-operator3. В CI добавляем конструкцию werf build.
В итоге получаем собранный образ оператора на нужной версии коммита. Далее можем использовать его в Helm-чарте с помощью {{.Values.werf.image.redisOperator }}.
В итоговом образе есть нужные изменения с priorityClassName— всё работает, как задумано!
Кто-то может задаться вопросами: «А как планируется уместить приложение и Redis при условии, что у них одинаковые классы? Кто-то окажется в статусе Pending?».
Данный вопрос больше относится к теме capacity planning, нежели к проблемам стабильности приложения… Но в целом ответ таков: в данном случае клиент вкладывается в «железо», так как работоспособность Redis’а напрямую влияет на клиентское приложение, и его (Redis’а) «вытеснение» приводило к неприятным последствиям. Также мы провели ревизию потребляемых ресурсов на основе рекомендаций VPA, которая помогла «умерить аппетит» некоторых побочных приложений. (Кстати, в нашем блоге есть перевод подробной статьи про VPA.)
Заключение
В реальной жизни инженерам приходится сталкиваться не только с особенностями технологий, но и с приоритетами бизнеса или, как в последнем случае, с полузаброшенными Open Source-проектами… Тем интереснее работа, и тем больше любопытных историй из нашей практики! Скоро вернемся с новой порцией.
P.S.
Читайте также в нашем блоге:
«Практические истории из наших SRE-будней. Часть 4» (проблема ClickHouse с ZooKeeper, обновление MySQL, битва Cloudflare с Kubernetes);
«Практические истории из наших SRE-будней. Часть 3» (миграция Linux-сервера, Kubernetes-оператор ClickHouse, реплика PostgreSQL, обновление CockroachDB);
«Практические истории из наших SRE-будней. Часть 2» (Kafka и Docker, ClickHouse и MTU, перегретый Kubernetes, pg_repack для PostgreSQL).
