
Это расшифровка-перевод доклада Саши Гольдштейна, признанного лучшим на конференции DotNext 2016 Piter. С годами этот доклад стал лишь актуальнее прежнего: появление Mac на ARM-процессорах — еще один пример, почему разработчикам сегодня нужно думать не только о x86-архитектуре.

Речь пойдет о проблемах, с которыми вы можете столкнуться при написании многопоточного кода, если вы думаете, что достаточно умны, чтоб спроектировать свои собственные механизмы синхронизации.
То, что подходит процессорам Intel на архитектурах x86 и x86-64, может не подойти другой архитектуре. Как только вы перенесете свой код на другой процессор, например, на ARM для iPhone и Android, есть вероятность, что он перестанет работать как надо. Проблемы могут быть как очевидными (воспроизводиться с первого-второго раза), так и не очень (возникать только раз в миллион итераций). Вполне вероятно, что такие баги могут добраться до продакшна. Сегодня .NET и, конечно, C++ можно использовать не только на Windows и Intel, но и на других платформах, так что доклад будет полезен многим разработчикам.
Дисклеймер: статья предназначена для продвинутых читателей. Смотрите на свой страх и риск. За частое упоминание барьеров памяти и изменения порядка исполнения инструкций она получила возрастное ограничение 18+.
Вступление (My assumptions)
- Вы — C++ или C#-разработчик.
- Вы пишете многопоточный код (а кто не пишет?).
- Вы следите за корректностью кода и хотите, чтобы он правильно работал на различных платформах.
- Возможно, вы привыкли к заботливой x86-архитектуре, но теперь хотите убедиться, что ваш код остался корректным в суровых и опасных условиях ARM-архитектуры.
Agenda
- Атомарность, эксклюзивность и изменение порядка
- Примеры переупорядочивания памяти
- Что такое «модель памяти»
- Volatile и атомарные переменные
- Примеры сломанного кода и решения, как его починить
Атомарность
Итак, начнем с трех фундаментальных концепций — атомарность, эксклюзивность и изменение порядка. Когда мы говорим, что операция атомарна, мы имеем в виду, что она не может быть прервана. Это означает, что во время выполнения операции не может произойти переключение потока, операция не может частично завершиться. На оборудовании с 64-битными процессорами Intel можно быть уверенными, что операции чтения и записи значений меньше 64 бит являются атомарными. Эти операции не могут быть прерваны и не могут частично завершиться. Проблема в том, что большинство на первый взгляд простых операций, которые мы пишем на языках высокого уровня, на самом деле не являются атомарными. Очевидный пример, с которым многие из вас наверняка знакомы — увеличение значения на единицу. На C++, компилятор сгенерирует код наподобие такого:

Это последовательность инструкций, выполняющая считывание из памяти, добавление единицы и запись обратно в память. Каждая операция из этой последовательности атомарная, а вся последовательность, очевидно, не является атомарной операцией. Важно понимать, что многие операции кажутся атомарными на языках высокого уровня, но на самом деле таковыми не являются. В этом можно убедиться, посмотрев на сгенерированный машинный код.
Эксклюзивный доступ к памяти
Наличие атомарной операции — инструкции, которая не может быть прервана или частично завершена, не гарантирует эксклюзивный доступ к памяти. Если у вас есть два ядра, выполняющих увеличение значения на единицу, в итоге вы можете столкнуться с ситуацией, когда значение увеличится только один раз. Оба ядра считают ноль из памяти и запишут в свой кэш, оба ядра сохранят запись об увеличении значения в своем буфере, но только одна из этих записей победит и, в конечном итоге, будет сохранена в памяти.
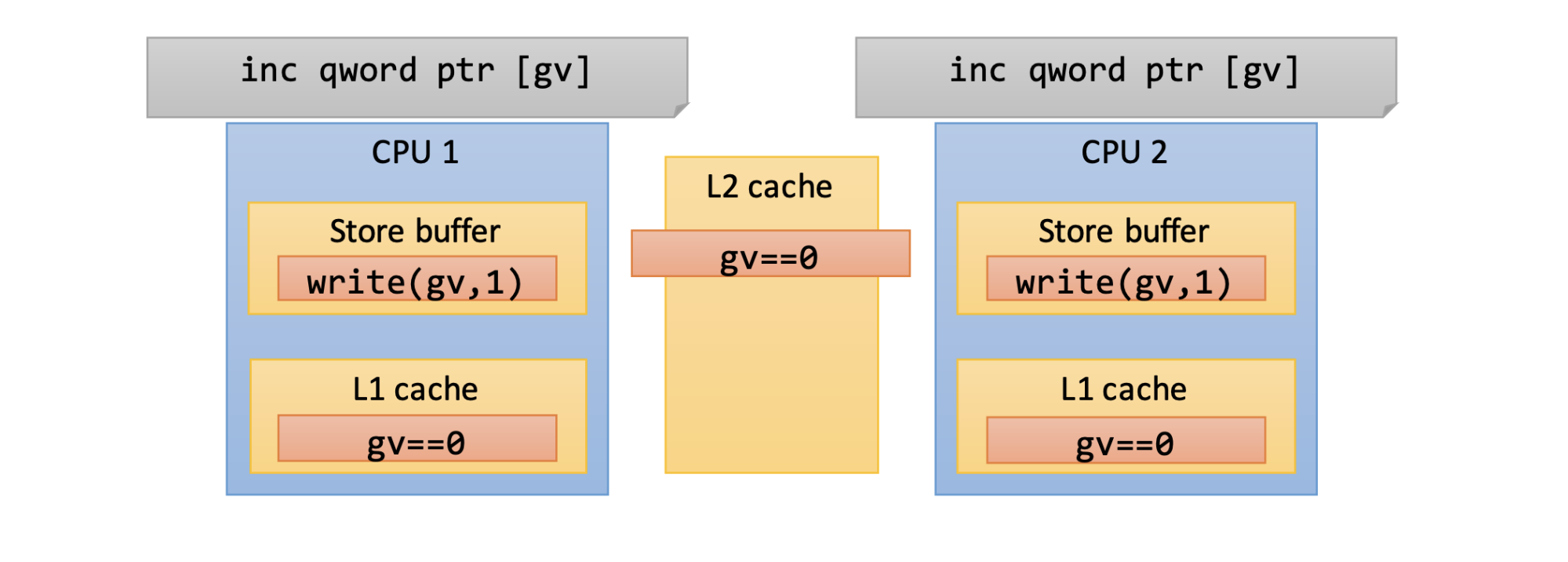
Так что атомарность операции не гарантирует эксклюзивный доступ к памяти. Ошибочно полагать, что атомарные операции всегда потокобезопасны. Атомарность — это одно, а эксклюзивность — другое. Но мы можем запросить эксклюзивный доступ к памяти, сообщить системе, что наше ядро собирается обновить значение, поэтому другие ядра не должны изменять его. На процессорах Intel это делается с помощью префикса lock, который можно применить к определенным инструкциям.
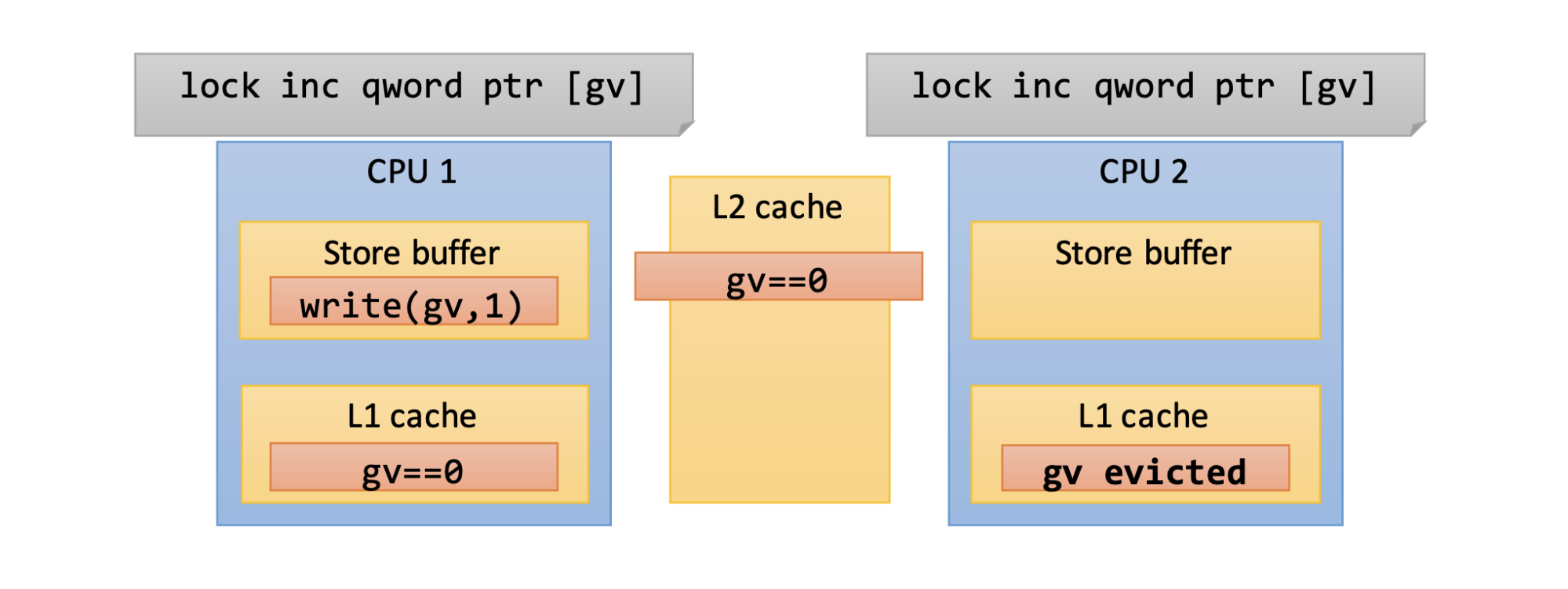
Раньше префикс полностью блокировал шину памяти. То есть пока выполняется инструкция, помеченная данным префиксом, другие ядра (CPU) в принципе не могли получить доступ к памяти. Довольно высокая плата за эксклюзивность. На современных системах (начиная с Pentium 4, возможно, даже более старых) префикс больше не блокирует шину памяти полностью. Теперь блокируется только часть памяти — достаточно убедиться, что линия кэша, где находится наше значение, не находится в кэше других ядер. Иначе говоря, если я обновляю значение на своем ядре, другие ядра временно не имеют доступ к этому значению. Это работает, но опять-таки, это довольно дорого, и, чем больше ядер, тем дороже обойдется операция. Резюмируя, эксклюзивность — это возможность ядра получить монопольный доступ к памяти. Это вторая концепция, о которой я хотел поговорить.
Больше об атомарных операциях вы можете узнать из доклада szKarlen Атомарные операции и примитивы в .NET.
Изменение порядка
Третья концепция — изменение порядка. И под этим определением подразумевается, что некоторые части системы могут взять операции, выполняемые вашим приложением, и переставить их. То есть они могут взять операцию записи и выполнить ее после чтения, хотя изначальный порядок был другим, могут взять две операции записи разных переменных и также изменить порядок выполнения. Например: одно ядро считает, что значение переменной равно 7, а другое ядро еще не заметило изменение значения и считает, что оно все еще равно 6. Такое различие информации, хранящейся в ядрах, может привести к проблемам. Далее в статье мы поговорим о нескольких примерах, которые, я надеюсь, лучше прояснят ситуацию.
Таким образом, атомарность, эксклюзивность и переупорядочивание памяти, не связаны между собой. Атомарность не гарантирует эксклюзивность, а эксклюзивность не гарантирует выполнение инструкций в определенном порядке.

Последняя — самая сложная часть, с которой многие люди не знакомы, поэтому мы изучим ее в деталях. Вопрос в том, выполняет ли компьютер код в том порядке, в котором вы его написали, или порядок выполнения может быть изменен? Различные части системы: процессор, компилятор, контроллер памяти могут изменять порядок операций. И это сделано не для того, чтобы проверить, на сколько вы хороший разработчик. Это оптимизация.
Примеры
Предположим, у вас есть цикл, считывающий значения из массива, но есть некоторое значение, к которому вы обращаетесь много раз.

Для компилятора было бы разумно вынести обращение к этому значению за пределы цикла, чтобы считать его только один раз и переиспользовать внутри цикла. Компилятор делает что-то подобное постоянно. Обычно мы не против, ведь это ускоряет наш код.
Следующий пример — это векторизация. Сегодня множество компиляторов автоматически генерируют другую версию цикла, которая использует векторные инструкции и векторные регистры в вашем процессоре. Если кратко, вместо того, чтобы считывать значение сначала из первого массива, потом записывать его во второй, потом считывать очередное значение из первого, потом опять записывать его во второй, вы считываете 4 значения из первого массива и записываете их во второй. Это своего рода изменение порядка считываний и записи. Мы снова не возражаем. Это оптимизация, и это хорошо.

Еще один пример — это отбрасывание считываний. Компилятор может решить, что нет смысла считывать некоторое значение дважды, если можно считать его только один раз и сохранить результат.

И мы не против подобных оптимизациях и не очень хотим о них знать, пока они не приводят к ошибкам. Это весьма лицемерный подход: нельзя просто предположить, что компьютер понимает, сломают ли оптимизации код или нет, потому что компьютер не знает о наших намерениях. Например, вы реализуете очередь на C, C++ или C#. У вас есть функция enqueue(x new_element), которая кладет новое значение в очередь и обновляет переменную locked — присваивает ей значение 0.

Компьютер может переставить эти операции местами: сначала обновить locked, потом положить новый элемент в очередь. Вы можете сказать: «Это неправильная оптимизация, это сломает мой код, и вообще, у компьютера не должно быть возможности так делать!» Но эта оптимизация такая же, как и в предыдущих примерах. Процессор или компилятор могут изменить порядок выполнения связанных чтений и записей, потому что решат, что это ускорит некоторые части вашего кода. Как показано в предыдущем примере, это может полностью нарушить ваши планы, но это только из-за того, что вы не сообщили о них компьютеру.
Зачем нужны оптимизации?
Зачем компьютеры (компиляторы или процессоры) выполняют подобные оптимизации? Процессоры переставляют местами некоторые операции из-за конвейерной обработки.

Эта простая иллюстрация показывает, что инструкция внутри процессора проходит через несколько стадий. Так происходит у процессоров с MIPS-архитектурой сорокалетней давности. На современных процессорах Intel может быть 20 подобных фаз. Одна инструкция перемещается между фазами, пока другая инструкция находится в первой фазе, еще одна инструкция — во второй и так далее. То есть множество инструкций находятся в разных фазах в одно и то же время. И результатом может быть изменение порядка: первая инструкция, записывающая значение в память, выполнится после третьей инструкции, считывающей значение из памяти, хотя изначальный порядок был другим. Наличие нескольких стадий в выполнении инструкций может привести к изменению порядка этих инструкций, если только вы не скажете компьютеру, что не допускаете подобные перестановки и хотите, чтобы инструкции выполнялись в изначальном порядке.
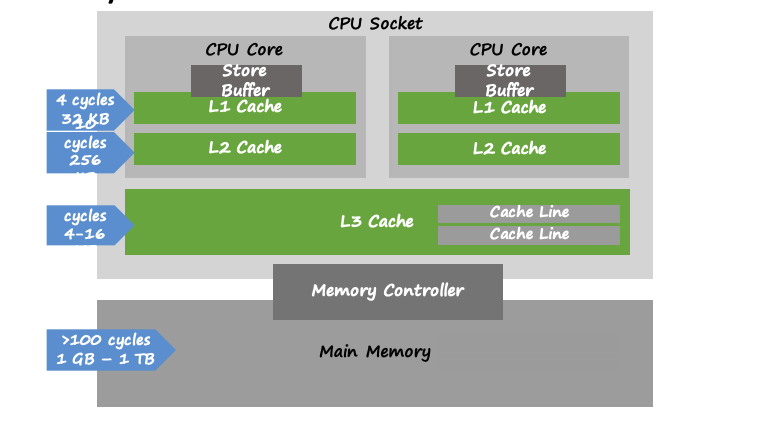
Последняя причина оптимизаций связана с задержками памяти; в основном, со временем, которое требуется для распространения изменений на всю систему памяти.
В современных процессорах Intel, например, у каждого ядра есть свой буфер — небольшая очередь, которая хранит последние операции записи. Этот буфер сбрасывается в память в фоновом режиме. То есть, если процессору пришла инструкция «Запиши Х в память» и он ответил «Сделано», на самом деле это может быть не так, и значение Х может находиться в буфере, который не видят другие ядра процессора. Буфер сбрасывается в память асинхронно. Даже после выгрузки буфера значение должно пройти несколько этапов кэширования, что также происходит довольно медленно.
Как понять, какие перестановки инструкций допустимы и что именно процессор будет считать верной оптимизацией? Есть одно правило, которое гласит, что необходимо соблюдать зависимости данных. Например, если в одном потоке сначала переменной Х присваивается значение 1, затем происходит считывание Х, последняя операция должна вернуть 1. Или если в потоке сначала какое-то значение присваивается переменной Х, затем какое-то значение присваивается переменной Y, и после этого происходит вычисление суммы Х и Y. Нет гарантий, какое присвоение произойдет раньше, но обе операции должны произойти до того, как X и Y будут считаны из памяти снова.
Но как только появляются несколько ядер, которые обращаются к несвязанным переменным, не соблюдается почти ничего. Например, на ARM-процессорах, которые находятся внутри большинства смартфонов, процессору, согласно спецификации, разрешено как угодно переставлять операции чтения и записи.

То есть процессору разрешено переставлять две операции чтения, чтение и запись, запись и чтение, и две операции записи между собой. Единственная причина, по которой мы не видим подобное каждый день — мы редко используем эти процессоры. Чаще мы используем более надежную модель, которой на данный момент придерживается Intel. В ней единственная разрешенная перестановка — запись после чтения. То есть, если у вас есть две операции — запись, затем чтение, процессор может выполнить чтение раньше. И это единственное, что процессор Intel позволяет оптимизировать. К сожалению, другие системы могут иметь другие гарантии.
Примеры переупорядочивания памяти
Небольшой пример, демонстрирующий разницу выполнения кода на разных архитектурах. Ниже представлен небольшой фрагмент C++ кода.

Счетчик g_shared _counter лежит в общей памяти. Есть два потока, каждый из которых 20 миллионов раз ограничивает доступ к счетчику (g_protector.lock()), увеличивает его на единицу и освобождает доступ (g_protector.unlock()). К реализации lock() мы вернемся немного позже. Предположим, что кто-то, кому вы доверяете, предоставил вам реализацию.
Я запустил этот код на iPhone-симуляторе и в конце вывел значение счетчика на экран. Результат выполнения оказался верным — на экране через некоторое время отобразилось сорок миллионов. Ура! Но я запускал iOS-симулятор на своем маке, внутри которого — процессор Intel. А если вместо симулятора протестировать код на реальном iPhone? Результат — 39999999. Близко, но не сорок миллионов. Итак, блокировка счетчика сломалась, причем только на ARM и только один раз из сорока миллионов.
Еще немного более практических примеров для лучшего понимания происходящего. Допустим, у нас есть небольшой фрагмент C или C++ кода, в котором первый поток сравнивает с null глобальную переменную, и если она действительно равна null, использует ее, а в то же время второй поток создает новый объект и кладет его в глобальную переменную.

Операции в коде выглядят атомарными, и чтение из памяти, и запись в память происходит только один раз. Казалось бы, здесь нет многократных изменений, которые могут помешать друг другу, поэтому код должен работать. Однако, на ARM, например, он работать не будет, так как конструктор во втором потоке также производит запись в память (инициализирует объект). Эта операция записи может произойти после записи значения в глобальную переменную. Тогда первый поток увидит частично инициализированную переменную, то есть переменную, создание которой еще не закончено. При этом код выглядит довольно чисто. На Intel данный код будет работать, потому что там, в отличие от ARM, не разрешены перестановки операций записи.
Второй пример — первый поток обновляет переменную, затем присваивает флагу значение true, а второй поток проверяет значение флага и, если оно равно true, использует переменную.

Как вы можете заметить, этот пример очень похож на пример выше. Операции записи значений переменной и флага могут быть переставлены. Если это произойдет, второй поток увидит, что флаг установлен, но, при этом переменная еще не инициализирована. Более того, теоретически, на некоторых платформах, может быть изменен порядок выполнения операций чтения во втором потоке. То есть вполне возможная ситуация — сначала считывается значение переменной, затем проверяется флаг. И, как результат, мы попытаемся использовать неинициализированную переменную. В общем, данный пример не будет работать на платформах с моделью памяти, разрешающей разного вида перестановки, даже если все операции в примере атомарные и эксклюзивные (нет двух потоков, модифицирующих одну и ту же часть памяти).
Финальный пример, который на этот раз я запущу на Windows — алгоритм синхронизации Петерсона. Возможно, вы слышали о нем на курсе по операционным системам. Ниже упрощенная версия этого алгоритма.

Если коротко, два потока хотят получить доступ к критической секции. Также есть два флага, по одному на каждый поток. Если flag1 равен единице, значит, поток 1 хочет получить доступ к критической секции. То же самое для второго потока. Каждый поток кладет единицу в свой флаг, затем проверяет чужой флаг. Если другой флаг также равен единице, значит, оба потока хотят получить доступ к критической секции одновременно. Это неразрешимый спор, попробуем заново. Мы присвоим флагу значение 0 и повторим все сначала (часть с goto). Эти действия будут повторяться до тех пор, пока один из флагов во время проверки не будет равен нулю. Такая ситуация означает, что один из потоков не хочет получить доступ к критической секции. Кажется, что алгоритм должен работать, пусть и не очень эффективно, ведь раз за разом повторяется одно и то же. Это как вежливый обмен мнениями: «Ты хочешь получить доступ к критической секции, я тоже хочу получить доступ, давай договоримся и найдем компромисс». Но, оказывается, на x86-архитектуре алгоритм не будет работать, так как операции чтения и записи в каждом потоке могут быть переставлены. Может получиться так, что один поток проверит флаг другого потока до того, как установит свой собственный флаг. Тогда возможна ситуация, в которой каждый поток будет думать, что другой поток не хочет получить доступ к критической секции, хотя на самом деле это не так.

Проблема в том, что подобную ситуацию не так-то просто зафиксировать, ведь такое происходит довольно редко (14 раз за 26551 повторение). Вы можете подумать, что ваш алгоритм синхронизации работает правильно, ведь вы проверили его сотни раз. Возможно, у вас есть автотесты, которые проверили его тысячи раз и не обнаружили этот редкий баг. Его сложно обнаружить, а если получилось, удачи — воспроизвести его еще раз будет непросто. Что будет, если подобный алгоритм с таким небольшим, казалось бы, незначительным шансом на поломку будет внедрен в большую программу? Будет очень неприятно :(
Что такое «модель памяти»?
Несколько слов о модели памяти перед тем, как мы перейдем к части о защите от подобных феноменов. Термин «последовательная согласованность» (sequential consistency) появился давно, и мы могли бы посвятить ему весь доклад целиком, но это будет довольно скучно. Главная идея — результат выполнения многопоточного кода должен быть таким же, как если бы код выполнялся в порядке, определенным программой. То есть система не должна разрешать как-либо изменять порядок выполнения операций чтения и записи. Но, как мы говорили ранее, перестановки операций не происходят из-за того, что система желает нам зла, это просто оптимизации. И последовательная согласованность препятствует этому.
Следующее определение — последовательная согласованность для программ без состояний гонки (sequential consistency for data-race-free programs или SC-DRF). На сегодняшний день эту модель использует большинство языков. Детали, опять-таки, довольно скучны, но в целом, состояние гонки — это именно то, что вы думаете. Состояние гонки происходит, когда у вас есть несколько потоков, каждый из которых обращается к определенной переменной, то есть к определенной области в памяти, и хотя бы один из потоков производит запись в память. Если ваш код не предотвращает это, у вас произойдет состояние гонки. SC-DRF означает, что если в коде нет состояний гонки, система обеспечивает последовательную согласованность. Все будет выглядеть так же, как при выполнении в порядке, предусмотренном программой. И это, в большей степени, то, что вы можете получить от оборудования сегодня, то, что, например, ARM может предложить. Если вы предпримете необходимые шаги, чтобы гарантировать отсутствие гонок, система предоставит вам последовательную согласованность между несколькими ядрами.
Все это довольно скучно и теоретично, но это определяет модель памяти. Например, для C++11 модель памяти — это SC-DRF. То есть C++, язык и библиотеки, предоставляют инструменты для избавления от состояний гонки. И если состояний гонки действительно нет в вашем коде, компилятор C++ гарантирует последовательную согласованность. И мы получаем нечто похожее от модели CLR, из официальной спецификации ECMA (the European Association of computer manufacturers). Если вы позаботитесь о состояниях гонки, то получите последовательную согласованность и отсутствие багов. Тем не менее, текущая реализация .NET, CLR, предлагает немного больше — она избавляется от некоторых перестановок, не предусмотренных ECMA-спецификацией. По сути, реализация от Microsoft более дружелюбна к разработчикам, чем ECMA-спецификация. Но, даже со всем вышесказанным, пример с алгоритмом Петерсона все еще не будет работать.
Надеюсь, теперь вы понимаете, почему речь идет не только о моделях памяти. Говорить об этом не так интересно, как об атомарности, эксклюзивности и изменении порядка выполнения кода, об избавлении от состояний гонки.
Good fences make good neighbours (крепкие заборы — дружные соседи)
Под заборами из подзаголовка мы будем понимать барьеры, которые предотвращают перемещение некоторых операций в памяти. И начнем мы с ключевого слова volatile, с которым связано некоторое недопонимание. В C++ volatile предотвращает изменения порядка выполнения кода, производимые компилятором. Компилятором, прошу заметить, не процессором. Это ключевое слово: не оказывается никакого эффекта на действия процессора.
Поэтому если вернуться к примеру с алгоритмом Петерсона и добавить volatile к каждому флагу, баг с перестановками все еще будет проявлять себя. Что ж, если говорить о предотвращении состояний гонки, volatile в C++ довольно бесполезен. Вы можете проверить это сами, посмотрев на сгенерированный код. В C# volatile предотвращает перестановки не только компилятора, но и процессора, создавая однонаправленные барьеры (далее я объясню, что это такое). Однако, volatile не гарантирует отсутствие состояния гонки и перестановок.
Примеры сломанного кода и решения, как его починить
Теперь давайте взглянем на настоящие барьеры памяти. Вспомним пример с двумя потоками, где в одном происходит инициализация глобальной переменной, а в другом — чтение и использование этой переменной.

Добавление барьера во второй поток предотвратит перестановку операции записи и создания объекта. Это обеспечит безопасность, которой мы добивались. MemoryBarrier() — это реальная функция, которую вы можете использовать в C++ на Windows и Visual Studio. Аналог этой функции в .NET называется Thread.MemoryBarrier() — это статический метод класса Thread, который предотвращает перемещение операций через барьер.
Если посмотреть на реализацию, там используется специальная инструкция, благодаря которой CPU понимает, что нужно запретить перестановки через эту точку. Конкретно на Intel единственное, о чем стоит беспокоиться такому барьеру, — это операции чтения после записи. Поэтому барьеры на Intel обходятся не так дорого, как барьеры на ARM. Если на ARM вы разбросаете барьеры случайным образом по всему коду, последствия могут оказаться плачевными. В нашем случае добавление барьера в алгоритм Петерсона поможет избежать ранее описанного бага с перестановками.

Типы барьеров
Барьеры бывают двунаправленными и однонаправленными. Однонаправленный барьер предотвращает перестановки, но только в одном направлении. Стрелочки на картинке помогут разобраться.

Функции Monitor.Enter и Monitor.Exit гарантируют, что в одном из направлений операция точно не будет переставлена. Операции между двумя функциями не разрешено пересекать барьеры. Иными словами, операции не могут сбежать из под лока. В .NET чтение и запись переменной, помеченной ключевым словом volatile, создает однонаправленные барьеры, такие же, как на примере с Monitor. В C++11 появился довольно полезный класс, называемый std::atomic. Такая атомарная переменная дает вам полный контроль над тем, какой барьер вы в итоге получите.
Вернемся к примеру с счетчиком, лежащим в общей памяти, и посмотрим на реализацию spinlock. Она базируется на флаге, который принимает значения 0 или 1.
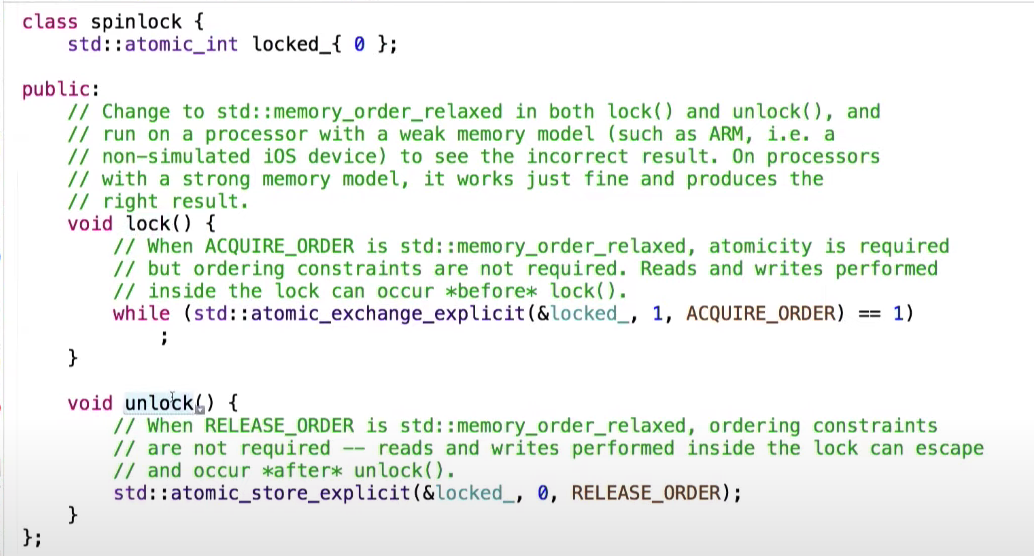
В текущей реализации методы lock и unlock используют атомарные переменные, а также я четко указываю порядок или, точнее, барьер, который мне нужен. У меня есть две версии, которые я могу использовать.

В первой версии, которая используется сейчас, обе инструкции используют memory_order_relaxed. Иначе говоря, какие-либо барьеры отсутствуют.

А это значит, что если в функции lock нет барьеров, и в функции unlock нет барьеров, операции записи, производимые внутри lock, могут быть выполнены до или после метода. Значит, блокировка не очень хорошая, она не выполняет свою основную функцию.
Сейчас возьмем вторую версию, в которой методы lock и unlock используют однонаправленный барьер.

Теперь при запуске кода на iPhone скорость выполнения уменьшилась — это цена за добавление барьеров памяти, но результат оказывается верным.
Мы можем использовать std::atomic, барьеры памяти для избавления от состояний гонки. Иногда при смешивании однонаправленных барьеров результат выполнения может отличаться от ожидаемого. Например, если в алгоритме Петерсона пометить флаги ключевым словом volatile в C#, или сделать их атомарными в C++, мы получим однонаправленные барьеры для операций чтения и записи.

К сожалению, наличие этих барьеров не мешает двум инструкциям поменяться местами. То есть ни volatile, ни std::atomic не решат проблему с перестановками, здесь поможет только полный барьер. Довольно сложно продумать такие моменты даже с двумя переменными, а если их больше, все становится еще более запутанно.
В финале хотелось бы рассказать о потокобезопасной реализации синглтона. Задача — реализовать синглтон в C++ и сделать его потокобезопасным. Начнем с очень простой и очевидно нерабочей и определенно не потокобезопасной реализации, в которой несколько потоков могут инициализировать синглтон одновременно.

Прекрасно. Добавим в реализацию блокировку lock.

Это все еще не будет работать, так как два потока могут одновременно попасть внутрь блокировки и инициализировать синглтон.
Реализуем блокировку с двойной проверкой, которая выглядит следующим образом.

Я делаю проверку, вызываю lock, затем снова проверяю, не инициализировал ли кто-то переменную. И это все еще не будет работать, так как мы можем получить исключение во время инициализации. Тогда не произойдет разблокировка, или вызов метода unlock, и весь процесс будет заблокирован.
Хорошо, обработаем исключения.

Но этот код также не будет работать по причине, которую мы рассматривали ранее. Операции записи, производимые конструктором, могут произойти после операции присвоения значения переменной instance. Если это произойдет, другой поток может подумать, что синглтон уже инициализирован, хотя это не так. Вы можете сказать: «Хорошо, давайте добавим volatile к переменной instance».

Однако, опять-таки, volatile в C++ не оказывает никакого влияния на оптимизации процессора. Единственное, что действительно поможет, — это std::atomic.

Есть еще более простой способ создания потокобезопасного синглтона.

Если вы добавите статическую переменную в функцию, стандартом гарантируется, что эта переменная будет инициализирована только один раз, даже если у нескольких потоков есть доступ к этой функции.
- Аналогичный раздел о синглтонах на C# есть в книге C# In Depth
- Больше информации о производительности .NET в книгах Pro .NET Performance Саши Гольдштейна, и Writing High-Performance .NET Code Бэна Уотсона
Вывод
Вместо того, чтобы самостоятельно искать интересные и изощренные способы сохранения атомарности, эксклюзивности и верного порядка исполнения кода, попробуйте положиться на кого-нибудь другого. Попробуйте спрятаться за чьей-нибудь реализацией. Статья дает общее представление о проблеме и предлагает несколько инструментов для ее решения, но, все же, лучше использовать проверенные инструменты.
Это был доклад с DotNext. А в апреле состоится новый DotNext, и какие доклады будут там, зависит в том числе от вас: приём заявок ещё открыт.
