
Имплементация «выключателя мертвеца (Dead Man’s Switch)» с помощью Opsgenie's Heartbeat
В отношении систем мониторинга существует простой вопрос, который приведет к появлению нескончаемой проблемы: «Кто следит за системой мониторинга?»
Ответ не так прост, так как первым побуждением будет добавить систему, которая будет контролировать нашу службу мониторинга. Но тогда кто будет следить за этой системой?
Однако у этой проблемы есть решение: Имплементация концепции Dead Man's Switch
Подытожим: до тех пор, пока система жива и здорова, отправляется heartbeat-сообщение. Если мы не получаем сигнал в течение некоторого времени, можно считать, что она мертва.
Эта концепция чрезвычайно уместна по двум основным причинам:
Название "Dead Man’s Switch" — звучит очень круто!
Это самый надежный способ получить уведомление о выходе системы из строя.
Главный недостаток такого подхода заключается в том, что очень сложно узнать, в чем причина сбоя.
Мониторинг и оповещение в Hellofresh
В Hellofresh мы де-факто используем стек Prometheus + Thanos. О нашем стеке мониторинга уже кратко рассказывалось в предыдущих постах, которые можно найти здесь и здесь.
Наш стек Thanos довольно прост: он скрейпит все наши prometheus-инсталляции и сохраняет метрики. Здесь нет ничего сложного.
Однако настройка Prometheus довольно сложная. Мы используем helm чарт kube-prometheus-stack для инсталляции одного Prometheus на пространство имен в кластерах Kubernetes (пространства имен связаны с внутренними кланами). Основная причина этого — распределение скрейпинга, достижение мелкомодульной масштабируемости в соответствии с потребностями различных кланов и гораздо более быстрые операции обновления/перезапуска.
Помимо этих двух компонентов, мы также используем Alertmanager как систему оповещения и Opsgenie в качестве системы пейджинга.
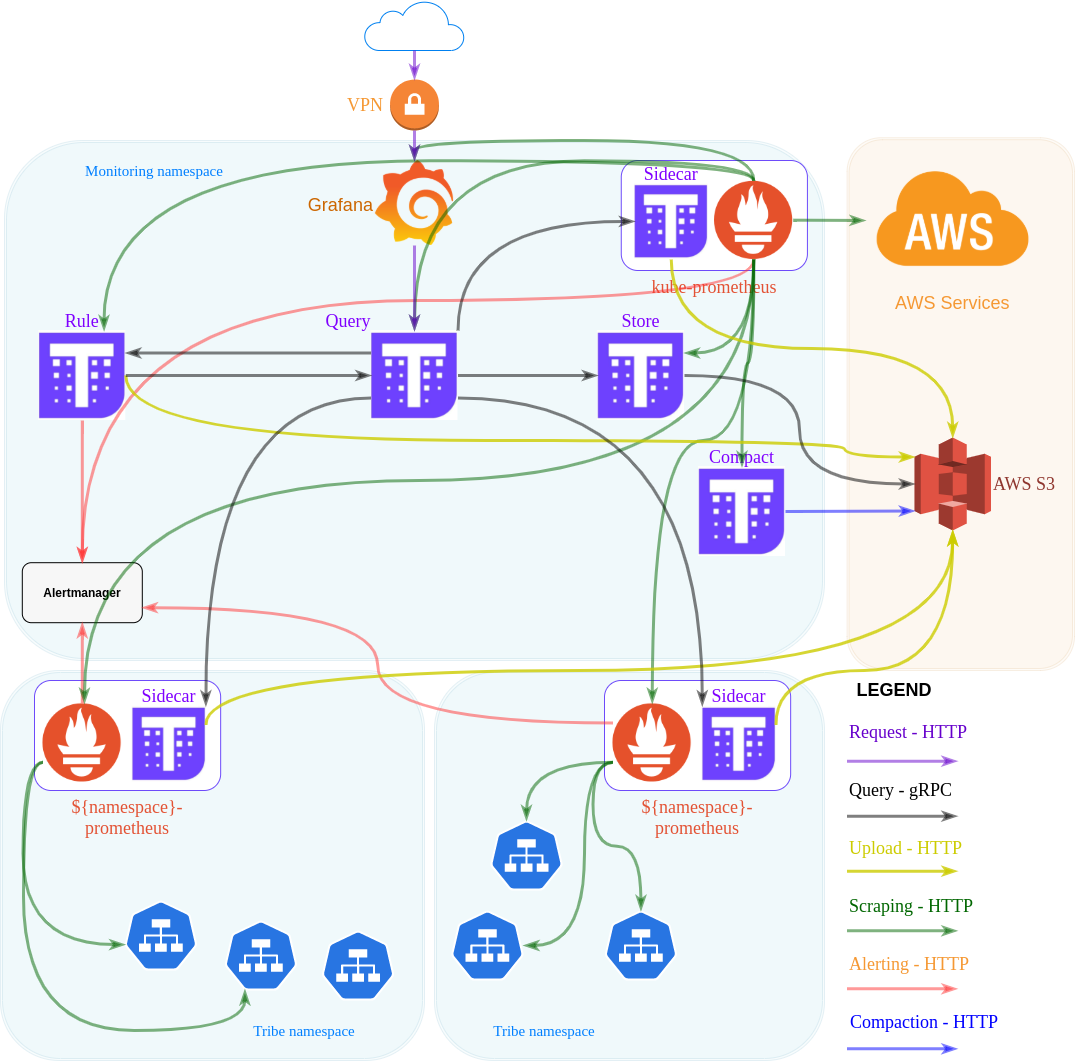
Отдельный Prometheus-сценарий
Имплементация Dead Man’s Switch для одной из наших Prometheus-инсталляций, показанных выше, довольно проста. Helm чарт даже поставляется с предварительно созданным алертом, как показано ниже:
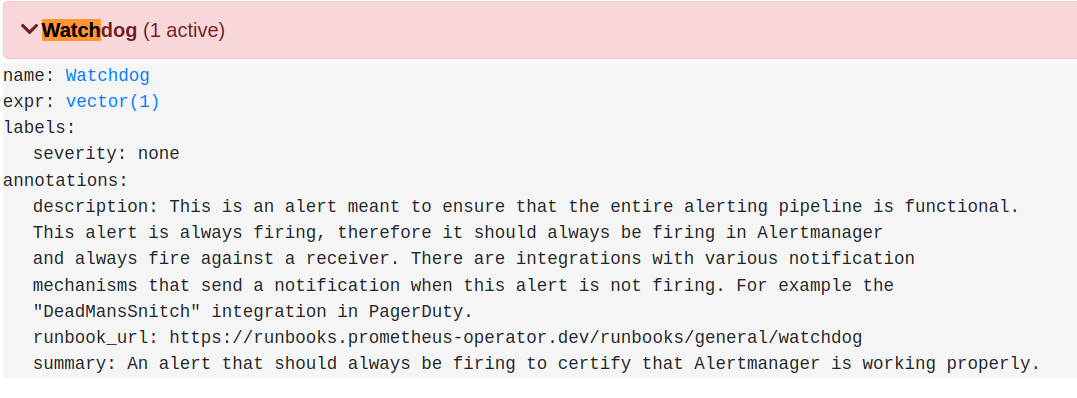
Затем мы создаем heartbeat в Opsgenie для каждого алерта Watchdog, и все готово!
Или нет?
Сценарий с несколькими Prometheus-инсталляциями
В предыдущем подходе есть оговорка. Мы правильно реализовали Dead Man’s Switch для всех наших Prometheus-инсталляций, однако Alertmanager в данном случае является общим компонентом.
Это означает, что если Alertmanager выйдет из строя, наши дежурные операторы получат 14 различных оповещений о том, что Prometheus не работает, поскольку все opsgenie Heartbeats начнут выдавать пейджинг. Этого хотелось бы избежать, пусть даже придется отказаться от чего-то другого.
Вторая версия нашего решения заключается в преобразовании Dead Man's Switch в "catch-all" алерт. Он станет более «абстрактным» и высокоуровневым, а его срабатывание будет означать расплывчатое «Что-то не так в нашем стеке мониторинга».
Этим чем-то может быть любая из наших Prometheus-инсталляций, сам Alertmanager или даже thanos-ruler (поскольку теперь он тоже будет включен).
В итоге у нас получилось следующее правило, которое будет вычисляться в thanos-ruler:
name: PrometheusHeartbeat
expr: count(sum by(job) (prometheus_build_info) >= 1) == count(sum by(label_operator_prometheus_io_name) (kube_statefulset_labels{label_operator_prometheus_io_name!=””,namespace=”monitoring”}))
for: 1mЧтобы разложить это правило:
count(sum by(job) (prometheus_build_info) >= 1): Это вернет количество работоспособных Prometheus-инсталляций. Работоспособная в данном контексте означает, что по крайней мере 1 из 2 реплик запущена и работает и что Prometheus можно соскрейпить (посколькуprometheus_build_infoпредоставляется самим Prometheus).
count(sum by(label_operator_prometheus_io_name)
(kube_statefulset_labels{label_operator_prometheus_io_name!="",namespace="monitoring"})): Это подсчитает количество контроллеров statefulset, определенных для Prometheus. Причина, по которой мы выбрали эту метрику, заключается в том, что она исходит из другого источника, нежели сам Prometheus (в данном случае — из kube-state-metrics). Это важно, поскольку данный запрос описывает наше работоспособное/желаемое состояние и не зависит от доступности Prometheus. Используемые метки специфичны для нашего случая использования (например, все наши Prometheus-инсталляции развернуты в пространстве имен мониторинга).
И соответствующий приемник согласуется с правилами в Alertmanager:
config:
route:
group_by: [‘destination_app’, ‘alertname’, ‘job’]
group_wait: 30s
group_interval: 10m
repeat_interval: 12h
receiver: ‘slack-receiver’ routes:
— match:
alertname: ‘PrometheusHeartbeat’
repeat_interval: 1m
group_interval: 1m
receiver: opsgenie-heartbeatreceivers:
— name: opsgenie-heartbeat
webhook_configs:
— url: ‘https://api.opsgenie.com/v2/heartbeats/prom-heartbeat/ping’
send_resolved: false
http_config:
authorization:
type: GenieKey
credentials: “”Однако при использовании этого подхода есть серьезный недостаток. Как только дежурный инженер получает пейджинг, у него нет подробной информации о том, что именно случилось. Вот почему важно объединить такое пейджинговый алерт с действительно простым в выполнении и использовании runbook. В нашем случае, к счастью, так как все развернуто на Kubernetes, существует несколько быстрых команд из runbooks для определения виновного в подобной ситуации.
Принятие концепции Dead Man's Switch является одним из самых надежных способов получения уведомлений о состоянии вашего стека мониторинга. И, как вы видите, существует множество способов ее реализации. Каждый из них имеет свои преимущества и недостатки. Если вы используете одну Prometheus-инсталляцию, то можете просто использовать Watchdog-алерт, о котором мы говорили ранее, и не переживать о других проблемах. Если у вас несколько установок Prometheus, то решение может быть немного сложнее. Об этом говорилось во втором варианте нашего решения.
Всех желающих приглашаем на открытый урок «Service mesh. Знакомство с Istio и Envoy». Разберем, что такое service mesh вообще и познакомимся с одним из его представителей — Istio. Научимся устанавливать его в кластер и настраивать политики по управлению трафиком. Регистрация по ссылке.
