
Задача матчинга в последнее время набирает всё большую популярность и используется во многих сферах: банки матчат транзакции, маркетплейсы – товары, а Google и другие IT-гиганты проводят соревнования по решению таких задач на Kaggle.
Для маркетплейса матчинг – очень важный процесс, который решает сразу несколько задач:
При поисковом ранжировании из множества товаров показывать сначала самые выгодные предложения.
Объединять множество товаров в одну сущность и показывать предложения одного и того же товара от разных селлеров.
Понимать, как предложения селлеров выглядят относительно друг друга, и поощрять их дополнительными бонусами.
Сегодня мы поговорим не только о решении этой задачи, но и о способах её реализации: offline (batch) vs online (realtime). Также обсудим, как и зачем переходить от первого ко второму.

Обычно матчинг реализуется в batch-формате. Так как данных для обработки слишком много, в игру вступает Spark со всеми своими преимуществами. Однако этот подход имеет много недостатков:
Со временем система становится неповоротливой: количество товаров всё время увеличивается, Spark-джобы работают дольше, постоянно масштабировать ресурсы нельзя из-за ограничений кластера и деятельности других команд.
Джобы могут падать по причине проблем на кластере, рестарты ещё больше оттягивают время прибытия актуальных матчей.
Чтобы получить матчи на конкретный товар, нужно ждать, пока алгоритм пробежит на миллионах товаров.
После создания нового товара время поиска матча исчисляется днями (данные должны поступить в Hadoop, алгоритм должен всё рассчитать и обработать).
Тяжело оценить время работы всего пайплайна.
Трудно проводить аналитику. На вопрос «Почему этот товар ни с чем не сматчился?» приходится довольно долго искать ответ в режиме ad hoc.
Всё это приводит к довольно интересной и амбициозной задаче – переходу с batch-поиска матчей на realtime.
В статье мы поговорим об архитектуре этого решения, посмотрим на метрики, которых нам удалось достичь, и порассуждаем об альтернативных подходах к реализации матчинга. Мы не будем углубляться в технические детали и имплементацию тех или иных алгоритмов, но, если вам будет интересно, в будущем сделаем серию технических туториалов по тому, как завести систему realtime-матчинга самому (маякните в комментариях :))
Для начала давайте посмотрим, с чего всё начиналось в команде матчинга и далее проследим переход от batch к realtime. Мы часто упоминаем batch-подход как нечто громоздкое, но для наглядности покажу схему запуска Spark-джоб в Airflow (каждый квадратик – отдельная джоба):

1. Batch-матчинг, LVL 1.
Фиксируем данные, для которых будем искать матчи.
Считаем недостающие эмбеддинги (BERT + ResNet).
Запускаем огромное количество последовательных кронджоб для пайплайна матчинга:
Поиск кандидатов с помощью разных алгоритмов и эвристик (kNN, ANN, Graph Search и др.).
Расчёт признаков для полученных кандидатов.
Инференс модели и применение порогов.
Применение различных видов фильтров (здесь подключается бизнес-логика).
Отправка найденных матчей с точностью >95%.
Главная боль: считать эмбеддинги только on-demand во время старта пайплайна – плохое решение. Если не хватает нескольких тысяч эмбеддингов, то это быстрый процесс, а если миллионов, то мы можем застрять на нём на много часов и заблокировать дальнейший процесс матчинга. Логично вынести этот процесс в фоновый режим.
2. Batch-матчинг, LVL 2.
Первым масштабным изменением было решение описанной выше проблемы. Необходимо было перевести инференс моделей для расчёта эмбеддингов в фоновый ETL процесс: слушаем Kafka топик с обновлениями товаров и обновляем по ним всевозможные векторы (на этом этапе появилась модель Prod2Vec). В момент старта самого пайплайна матчинга просто подбираем то, что уже успели рассчитать. Всё, что не успели, пойдёт в следующий запуск. Таким образом, мы смогли инференсить сетки 24/7: обрабатывать много событий и не тормозить пайплайн. Это первое, что мы сделали: вынесли довольно большую логическую часть из кронджоб и даже написали об этом статью.
Жить стало значительно проще, и ETA алгоритмов стал более-менее предсказуемым. Но появились новые боли:
Бизнес хотел получать актуальные матчи быстрее.
Различные заказчики хотели получать по запросу матчи для конкретных товаров.
Мы хотели иметь надёжное отказоустойчивое контейнеризированное решение, которое не зависит от состояния файловой системы HDFS и деятельности других команд.
Стало ясно, что удовлетворить всех, сохранив при этом batch-подход, невозможно и нужно придумать что-то другое.
3. Realtime-матчинг, LVL 3.
Пришло время поговорить об архитектуре realtime пайплайна. Первая версия выглядит следующим образом:
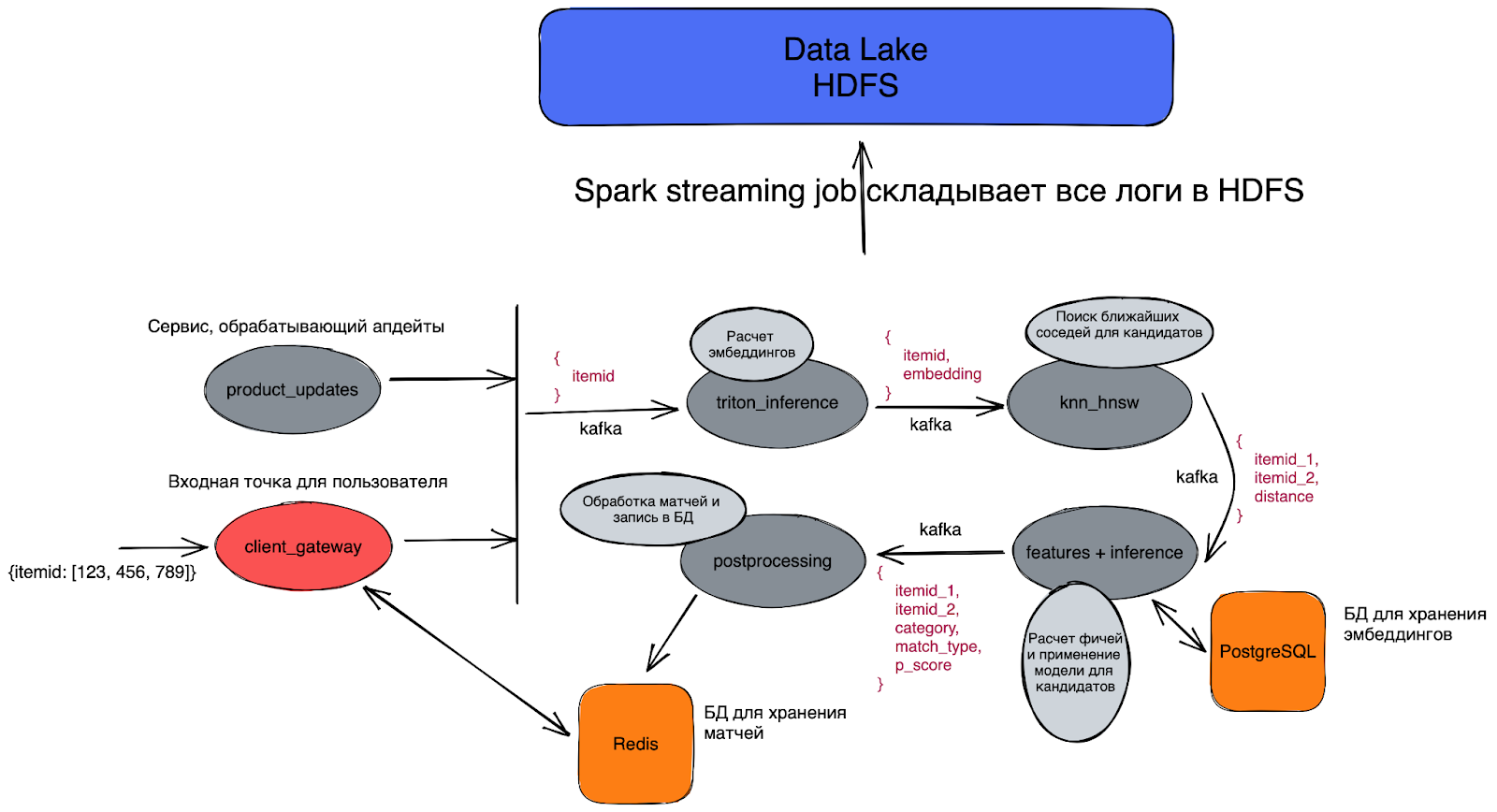
На вход могут поступать запросы на матчинг из разных источников.
На выходе отдаём пары товаров, которые являются матчами с разной степенью уверенности.
Весь realtime состоит из нескольких основных этапов: подсчёт эмбеддингов для запроса, поиск кандидатов для матчинга, расчёт признаков и инференс модели.
Если уж мы делаем realtime, то всё должно быть очень быстро. Никого не устроит система, находящая матч за полдня, потому что это мало чем отличается от offline подхода.
Входная точка
На входе читаем Kafka-топик, в который попадают запросы на матчинг (клиент отправил запрос в endpoint и хочет поматчить конкретные товары, обновились или появились новые товары — и мы хотим найти свежие матчи и т. д.).
Расчёт эмбеддингов
Для полученных товаров нужно посчитать эмбеддинги, чтобы в будущем искать кандидатов на матчинг с помощью kNN. Делать это можно множеством способов: держать модель в памяти и инференсить на CPU, использовать форматы ONNX, OpenVINO, TensorRT.
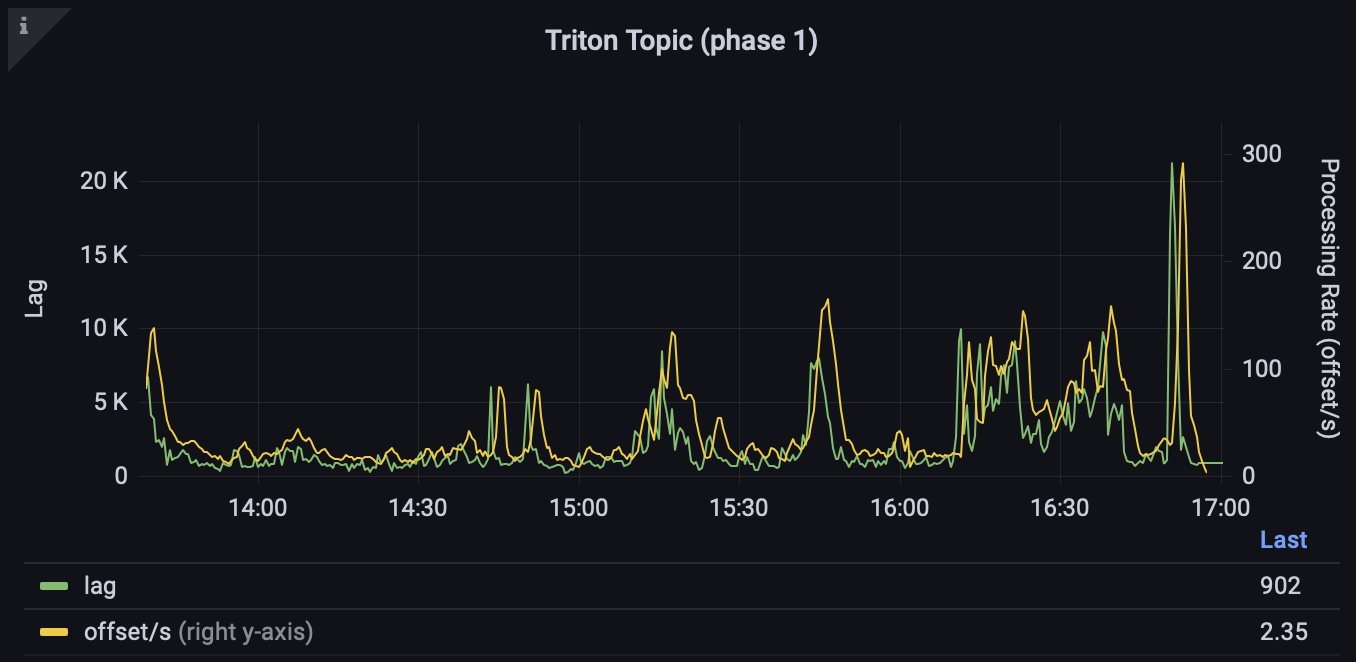
Самым быстрым (и оптимальным) решением, очевидно, будет инференс на картах, и для таких кейсов существует очень удобный Triton Inference Server от NVIDIA, предоставляющий gRPC/HTTP-интерфейс для применения моделей практически в любом формате. Соответственно, сервис получает товар, достаёт необходимую информацию, делает предобработку и ходит в Triton за эмбеддингом. Таким образом, мы с лёгкостью считаем до 350 эмбеддингов в секунду (при этом смысла ускоряться ещё нет, так как последующие этапы будут bottleneck’ом).
Как читать графики
Базовую терминологию Kafka можно посмотреть, например, здесь или в нашей статье про Streaming.
Lag – отставание от самого свежего сообщения в топике.
Offset/s – количество сообщений, обрабатываемых приложением в секунду.
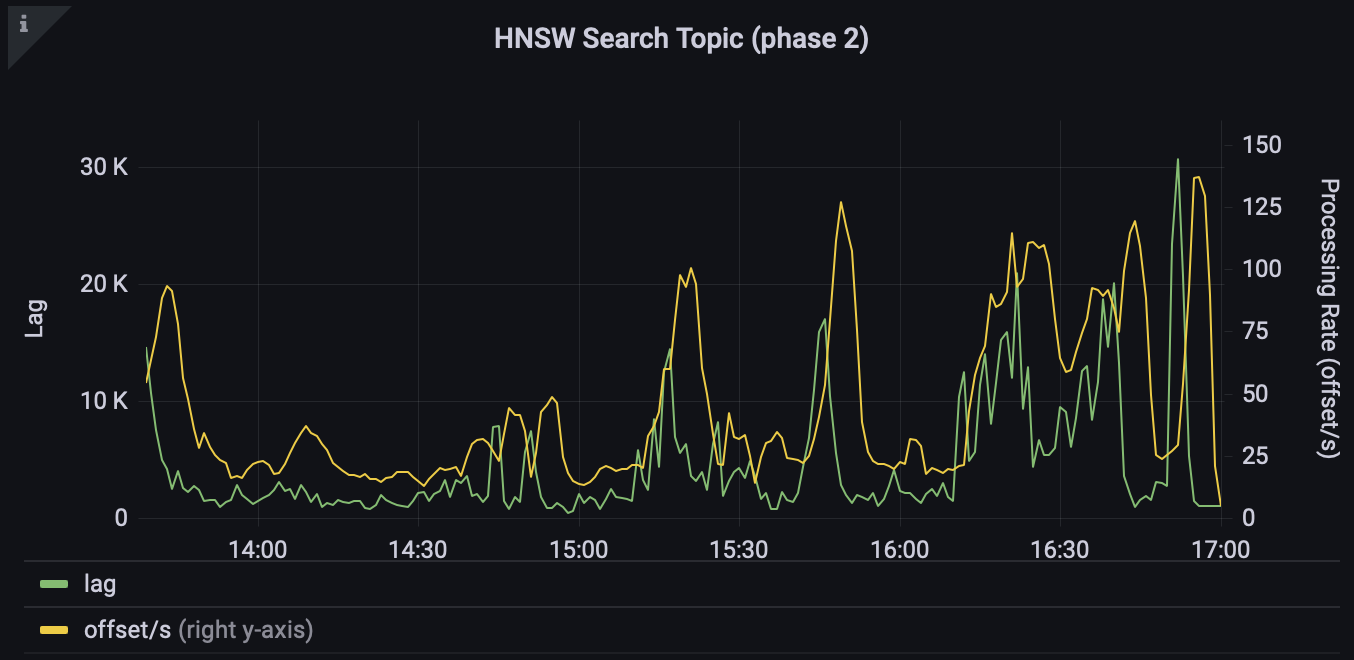
Поиск ближайших соседей (приближённый), или ANN
Если у нас есть эмбеддинг конкретного товара, то что мешает просто найти ближайших соседей и получить кандидатов в матчи? Оказывается, много что:
Искать мы хотим среди всего множества товаров Ozon, а их больше 100 млн. Где держать такой индекс?
Как можно быстро искать среди такого количества товаров при непрерывном потоке входящих сообщений?
На каких векторах делать поиск?
В этих вопросах могут помочь алгоритмы приближённого поиска ближайших соседей (Approximate Nearest Neighbors, или ANN), которые вместо линейной сложности поиска O(n) (ведь нам нужно определить расстояния до каждого эмбеддинга из базы) дают сублинейную. Существует много реализаций таких алгоритмов, с ними можно ознакомиться, например, здесь. Помимо самого алгоритма, мы можем поднять Spark Structured Streaming, которое будет в realtime искать кандидатов, и ускорить процесс поиска за счёт масштабирования. В качестве алгоритма поиска мы выбрали HNSW, так как:
Есть реализация на Spark.
Хорошие результаты в бенчмарках.
Получили хороший trade-off в качестве и времени под нашу задачу матчинга.
При построении индекса мы шардируем его на количество воркеров. Во время инференса запрос идёт на каждый шард, там ищутся K кандидатов и из них выбирается топ K (то есть мы выбираем K из K * n_shards). Такой индекс строим по активному ассортименту раз в день. С классическим BERT с размерностью эмбеддинга 768 HNSW будет работать очень долго. Для того чтобы ускорить процесс, мы обучили BERT с размером выходного эмбеддинга 64. При этом попробовали множество подходов – и в итоге смогли получить модель, которая немного уступает в полноте большой модели. Увеличивая число соседей, мы решаем эту проблему.
Конечно, здесь возникает много вопросов. Почему не использовать Elasticsearch (с плагинами для поиска по эмбеддингам) или другие поисковые движки? Можно ли поднимать индекс в K8s и использовать FAISS с GPU? Все эти варианты нужно тестить и сравнивать между собой, что требует немалого количества времени. При запуске MVP вариант со Spark Structured Streaming оказался самым простым в реализации, и полученные метрики полностью устроили: в секунду мы можем находить и обрабатывать 50 кандидатов для 300 товаров.
Расчёт признаков и применение модели
Если на вход предыдущим сервисам шли товары, то в сервис расчёта признаков и инференса модели приходят уже пары товаров – кандидаты на матчинг, то есть количество обрабатываемых сообщений увеличивается в 50 раз (если находим 50 соседей). В данном сервисе нам нужно:
Посчитать признаки для модели.
Применить модель и отфильтровать результаты по порогам.
Применить дополнительные бизнес-фильтры.
Несмотря на то что подсчёт признаков – довольно тяжёлый этап, сервис должен быть максимально быстрым и справляться с большим потоком сообщений. При этом сама ML-модель для матчинга (в нашем случае – CatBoost) в offline использует около 50 парных признаков. Посчитать их все заранее и положить в key-value хранилище мы не можем из-за слишком большого количества сочетаний пар, а вычислять их все в realtime означало бы замедлить процесс настолько, что подход потерял бы смысл. Но есть решение!
Первичный фильтр из ANN по расстоянию: для каких-то товаров 50 соседей может быть слишком много, поэтому можно фильтровать их по некоторому порогу практически с нулевой потерей полноты.
Помимо модели, используем простой алгоритм матчинга на партномерах, атрибутах и текстах. Уже что-то, но совсем низкая полнота :(
Используем дистанцию из ANN в качестве готового признака (расстояние по текстам, тогда не нужно повторно доставать эмбеддинги и что-то считать).
Картиночные эмбеддинги кладём в PostgreSQL со схемой itemid – embedding, на itemid вешаем хеш-индекс – и получаем своего рода key-value хранилище для операций вида
SELECT * FROM table WHERE itemid = 123(о различных видах индекса можно почитать, например, здесь). Считать картиночные векторы в realtime довольно дорого, так как требуется скачивать картинку. В идеале нужно иметь очень большую базу Redis или wide-column БД, например, Cassandra.Используем только быстрые фичи. Мы сделали профилирование признаков по скорости работы, посмотрели на важности и определили, какие из них точно необходимо выкидывать, какие желательно выкинуть, а какие можно оставить.
Подумали над подходом к обучению модели. Какие есть варианты, кроме классического подхода, где учим модель классификации, а датасет собираем с привлечением сервисов разметки и внутренних эвристик? Нам удалось завести немного другой подход:
Сначала мы собрали датасет с позитивами (истинные матчи) и негативами (примеры не матчей) с помощью сервисов разметки – так, как делали это всегда.
К датасету добавили большую историю предсказаний от offline модели, которая была обучена на намного большем количестве признаков и имеет хорошую полноту.
Вместо классификации получили задачу регрессии, при этом у нас появляются не просто примеры матч/не матч, а матчи разной степени уверенности. На выходе можно либо просто использовать ответы из регрессии, либо прогнать их через сигмоиду. Получилась своего рода дистилляция модели.
Полученный датасет оказался больше классического в десять раз. Этот трюк помог нам достичь впечатляющего качества и даже находить новые матчи, которые старая модель была неспособна обнаружить.
Внимательный читатель заметит, что здесь возникает feedback loop от offline модели. И да, и нет:
В некотором смысле нас устраивает, что модель будет обучаться на примерах offline модели и при этом будет иметь в 2.5 раза меньше признаков и работать в realtime.
Помимо этого, мы использовали большой датасет, собранный отдельно и тщательно очищенный. Таким образом, мы получили датасет с таргетом
 от модели и точные примеры 0 и 1 – от собственной разметки. Это позволило покрыть большую область неопределённости и сделать шаг на пути к откалиброванности модели (хотя здесь ещё есть над чем работать).
от модели и точные примеры 0 и 1 – от собственной разметки. Это позволило покрыть большую область неопределённости и сделать шаг на пути к откалиброванности модели (хотя здесь ещё есть над чем работать).
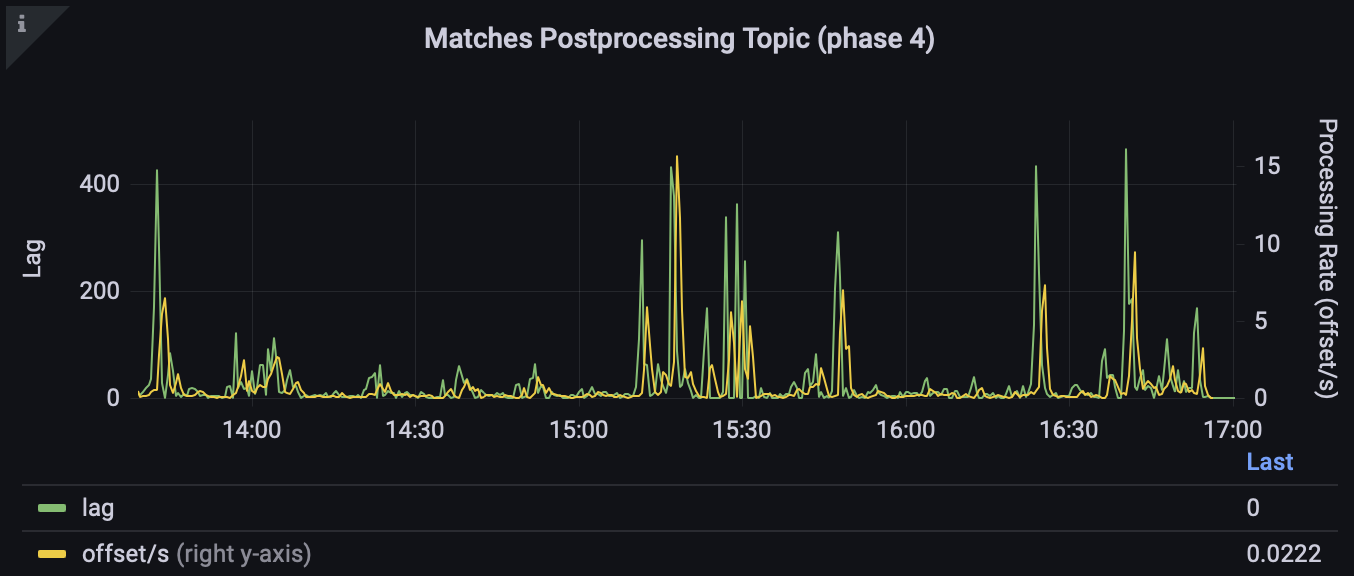
В результате получился сервис, стабильно держащий нагрузку в 900 пар в секунду на одном K8s поде.

Сервис постобработки матчей
На данном этапе у нас уже есть матчи с определённым порогом. Дело за малым. В этом сервисе мы решаем, что с ними делать: отправляем в топики другим командам матчи разной степени уверенности, сохраняем их в Redis с TTL (Time to live – время, через которое ключ в Redis удалится) один день для быстрого доступа.
Что получилось в итоге и на каком железе мы живём
Итого мы имеем сервис, который позволяет клиенту обратиться за поиском матча для выбранного товара. Запросы от клиента проверяются в Redis (может быть, мы нашли матчи ранее). Если матчей нет, добро пожаловать в пайплайн. Помимо запросов от клиентов, много других источников шлют в Kafka запросы на матчинг (например, все обновления товаров и создание новых). Всё это приходит на вход в Triton Inference Server, который поднят в K8s с нодами по 8 GPU NVIDIA A40. Таких мощностей нам более чем достаточно.
Далее ищем соседей в Streaming сервисе поиска кандидатов, где в памяти уже лежит построенный HNSW индекс по активному ассортименту Ozon. Индекс распределён на 64 экзекутора (по четыре ядра и 8 ГБ оперативной памяти в каждом). Найденные пары идут в расчёт признаков и инференс CatBoost. За секунду на одном поде K8s обрабатывается порядка 900 пар. Поставив 10 партиций в Kafka топике (и, соответственно, десять K8s подов), получаем 9000 пар в секунду. После этого записываем матчи в необходимые топики и базы данных. Всё это, разумеется, покрыто мониторингом и алёртами, а также дополнительно складывается в HDFS для дальнейший аналитики и улучшения пайплайна.
Если смотреть с точки зрения end-to-end времени ответа, то при стабильной работе без пиковой нагрузки Kafka-топиков получаем такой график:
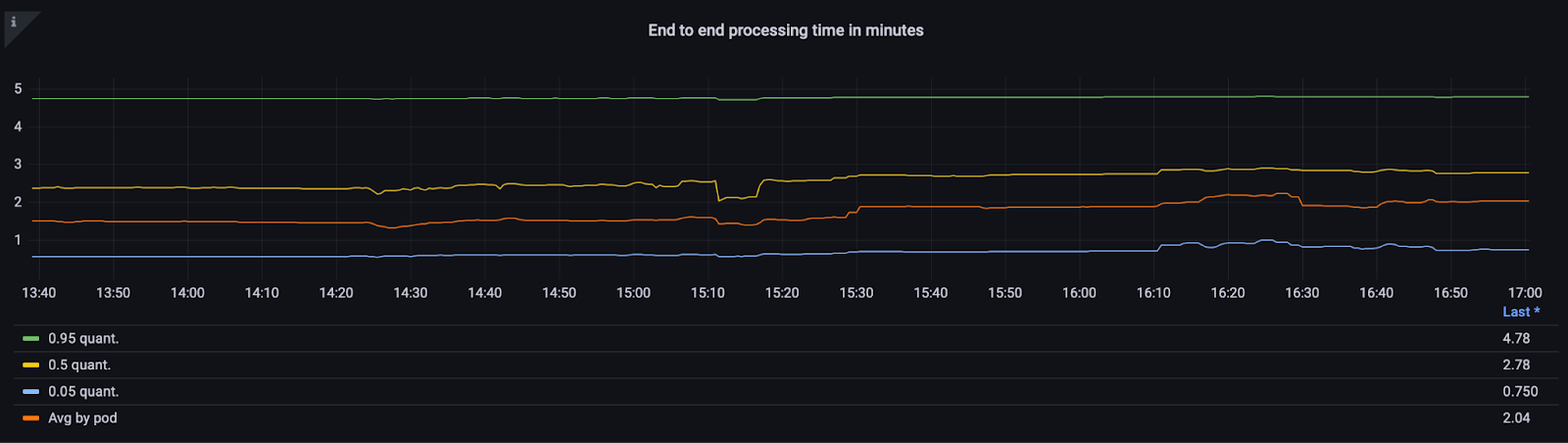
То есть в среднем мы находим матч за 2 минуты! А ещё совсем недавно приходилось ждать дни. Приятное ускорение.
Основные выводы
Какие-то из них применимы не только к матчингу, какие-то – довольно специфичны:
На каждый сервис нужно вешать кэш (Redis/Memcached) и экономить время на перерасчёте данных. Пользователи бывают разные, и вы точно столкнётесь с тем, что вам закинули 1000 одинаковых товаров. Простого LRU (Least Recently Used – метод policy eviction) с TTL здесь более чем достаточно.
Такой сценарий использования Triton Inference Server позволяет инференсить сети не только в realtime. Он поддерживает несколько различных моделей (картинки, заголовки, описания, атрибуты), и к нему могут обращаться все команды Ozon, которым нужны эмбеддинги. Зачастую не нужно обучать свои модели или использовать предобученные на общих датасетах, если есть готовый сервис, способный держать нагрузку и выдающий качественные эмбеддинги, обученные на товарах Ozon.
Kafka – очень удобный способ выстроить потоковую обработку между независимыми сервисами. При этом в самих сервисах никто не мешает принимать также HTTP/gRPC запросы от клиентов.
Мониторьте всё, что только можно, вешайте алёрты, дампите всё в data lake хранилище для постаналитики – это точно пригодится в будущем и позволит оперативно среагировать, если что-то пойдёт не так.
Не бойтесь начать делать MVP с простых решений. Можно бесконечно сидеть над дизайном и постоянно его улучшать, но в какой-то момент нужно начать делать. При этом заранее подумайте о возможных проблемах. Заложите фундамент для шардирования баз, бэкапов, алёртинга.
Алгоритм kNN резко увеличивает количество сообщений, которые нужно обрабатывать, поэтому сервис расчёта признаков и инференса должен быть супербыстрым.
kNN выдает K соседей, но все ли из них хорошие кандидаты для матчинга? Это можно оценить по расстоянию – и совсем далёких не отсылать дальше, тем самым снижая нагрузку на сервис инференса.
4. Что дальше?
Как я уже говорил, мы получили MVP, который уже находит матчи в realtime. Это здорово, но есть огромное пространство для дальнейших экспериментов:
Всё описанное реализовано на Python. Это не очень хороший выбор при условии, что в Ozon есть огромное количество платформенных решений на Go (load balancers, consistent hashing, service overview и пр.). Перепишем всё на Go :)
Хочется непрерывно обновлять поисковый индекс, если появляются новые товары, таким образом постоянно расширяя базу.
Я говорил про универсальный сервис по инференсу сеток, который будет служить на благо всего Ozon. Его пока нет, но скоро должен появиться.
Есть задача повысить производительность баз с эмбеддингами, чтобы получать ответы ещё быстрее.
Мы планируем углубиться в модель и поискать новые подходы, которые позволят ещё больше увеличить полноту.
Будем собирать фидбэк от бизнеса, писать новые метрики, разбирать корнер кейсы и делать матчинг ещё лучше!
Надеюсь, у меня получилось сделать краткий обзор архитектуры realtime пайплайна матчинга, рассказать о подходах, которые мы выбрали, и о трудностях, с которыми столкнулись. Не хотелось перегружать статью техническими деталями, но, если вам интересны нюансы, дайте знать в комментариях: возможно, вас заинтересовал какой-то конкретный этап матчинга, и в будущем мы сделаем его разбор и расскажем о нашем решении в деталях и с примерами кода.
Давайте также обсуждать альтернативные подходы. Может, что-то можно было сделать лучше? Я уверен, что вместе мы найдём новые крутые решения и идеи для экспериментов.
