Comments 161
А может просто вдумчиво писать программы? В С++ тоже есть волшебный оператор "==" и его младший брат "="… и ничего, тонны кода работают же!
Эти гуру и до этих операторов добрались:
Советуют писать так, чтобы не перепутать = и ==
А для сравнения переменных можно и так написать
Советуют писать так, чтобы не перепутать = и ==
if (7 == x) { ... }А для сравнения переменных можно и так написать
if (x+0 == y) { ... }Строго говоря, сейчас это уже не так актуально как десять-пятнадцать лет назад. Актуальные компиляторы (Visual Studio 2005+, XCode, gcc под андроид) уже научились с грехом пополам выдавать варнинги в таких случаях. Главное — уровень варнингов задирать повыше и писать аккуратно, чтобы других варнингов не быо :).
Как хорошо, что ни разу в рабочем коде я этих x+0 не видел. Такая дикость!
CERT кстати рекомендует вообще отказываться от присваиваний в условиях, тогда подобные ошибки «на глаз» сразу видны.
CERT кстати рекомендует вообще отказываться от присваиваний в условиях, тогда подобные ошибки «на глаз» сразу видны.
Ещё в java что бы строку не проверять на null гуру делают так
if ("five".equals(someString) {
doSomething();
}
для С++ и волшебного оператора '==' давно придумали условие Мастера Йоды:
Вдумчиво писать программы можно. Разрешаю :).

Вдумчиво писать программы можно. Разрешаю :).
Вдумчиво писать никто не запрещает, но иногда случаются ошибки.
Я не кармадрочер, уже давно привык, что ее нет… Но почему блин если у комментария -3, то и кармы стало на 3 меньше, не поленились и тыкнули, а когда твой коммент набирает 120 плюсов, карма хер сдвинется.
Мне кажется, костыль не стоит свеч. Ошибка вывалится на стадии компиляции или обнаружится редактором. А смотреть и править такой изврат не очень приятно.
Вы сейчас о чем? Основная проблема как раз и заключается в том, что интерпретатор Python не считает это ошибкой.
Редактор, это, конечно, хорошо. Но программа часто несколько боьше по объему, нежели тривиальная домашняя страничка, в этот редактор влезающая. В случае массовой правки больших объемов регекспами/рефакторингом (а это большой такой источник ошибок) на двухсотом диффе глаз уже замылится и никакой редактор не спасет.
Редактор, это, конечно, хорошо. Но программа часто несколько боьше по объему, нежели тривиальная домашняя страничка, в этот редактор влезающая. В случае массовой правки больших объемов регекспами/рефакторингом (а это большой такой источник ошибок) на двухсотом диффе глаз уже замылится и никакой редактор не спасет.
Если у вас большие списки строчек в программе, которые вы еще и правите вручную, велика вероятность что с вашей программой уже что-то не так. Например переводы как вы поддерживать собираетесь?
Переводы чего? Имен JSON запросов? Расширений файлов? Списков файлов? Списков языков или локалей?
Указанный прием наиболее полезен в небольших скриптах внутренне автоматизации — они часто содержат списки строк, часто меняются и для них ниже контроль качества, нежели для кода, которые отгружается в production.
Есть ряд сценариев, где указанный метод применим. Перечисление таких сценариев выходит за рамки моей заметки :)
Указанный прием наиболее полезен в небольших скриптах внутренне автоматизации — они часто содержат списки строк, часто меняются и для них ниже контроль качества, нежели для кода, которые отгружается в production.
Есть ряд сценариев, где указанный метод применим. Перечисление таких сценариев выходит за рамки моей заметки :)
В небольших скриптах и руками можно отловить 1-2 ошибки которые возникнут, быстрее чем скобочки везде расставлять :) А в production'е надо еще всех в команде этому методу научить, а оно вряд ли кому надо.
Сам по себе метод интересный, но есть подозрение, что на практике малоприменимый.
Если много текстовых констант лучше уж их просто в отдельный файл положить без всяких запятых например одна константа на строчку.
Сам по себе метод интересный, но есть подозрение, что на практике малоприменимый.
Если много текстовых констант лучше уж их просто в отдельный файл положить без всяких запятых например одна константа на строчку.
В небольших скриптах и руками можно отловить 1-2 ошибки которые возникнут, быстрее чем скобочки везде расставлять :)
Скрипт скрипту рознь. Беда с данным косяком в том, что он оставляет относительно валидный список — и это позволяет скриптам работать и делать что-то, но не совсем то что нужно. Это опасно, приводит к рискам потерять много времени на борьбу с нёх. А скобочки расставляются быстро.
В целом применимость конечно нужно оценить. Я свой отдел на такой способ перевел — через годик можно будет сравнить эффект.
Может попробуете с внешними файлами для констант? Это как то более удобное и красивое решение на мой взгляд, и регэкспами редактировать удобнее, все таки надо разделять данные и код :)
Для внутренних скриптов автоматизации вынесение ряда данных из кода — это усложнение на пустом месте.
BTW, никто же не говорит о том, что данный способ красив, удобен и приминим везде. Ниша у него довольно специфическая. Статья о том, что такой способ есть. А применять ли его, и если применять то где — это ваше личное дело. В программировании вообще можно разными способами задачи решать. Так что я тут ассортимент демонстрирую, а не способ пропагандирую. Можно и внешние файлы для констант. Разных способов вообще много.
BTW, никто же не говорит о том, что данный способ красив, удобен и приминим везде. Ниша у него довольно специфическая. Статья о том, что такой способ есть. А применять ли его, и если применять то где — это ваше личное дело. В программировании вообще можно разными способами задачи решать. Так что я тут ассортимент демонстрирую, а не способ пропагандирую. Можно и внешние файлы для констант. Разных способов вообще много.
Действительно, сколько работаю с питоном особо не сталкивался с этим. Могу предложить хранить такие данные в отдельных *.json файлах, где подобные приколы будут пресечены на месте парсером. Я для бэкендов храню их в отдельном git репозитории и подключаю сабмодулем к основному проекту.
AS3, однако, считает пропущенную запятую в точно таком же массиве ошибкой.
Имхо, такие вещи в Питоне наводят меня на мысль держаться от него в стороне. Пропуск подобных вещей напоминает мне некоторые браузеры (IE), которые хавают любой кривой HTML без вопросов и выводят из него то, что считают нужным. Хорошо, что есть strict mode и XHTML.
Как бы я решал эту проблему, если бы она у меня возникла — написал бы простенький лексический анализатор для отлова пропущенной запятой в массиве и прогнал весь код через него.
Может, кто-нибудь накидает, кстати?
Имхо, такие вещи в Питоне наводят меня на мысль держаться от него в стороне. Пропуск подобных вещей напоминает мне некоторые браузеры (IE), которые хавают любой кривой HTML без вопросов и выводят из него то, что считают нужным. Хорошо, что есть strict mode и XHTML.
Как бы я решал эту проблему, если бы она у меня возникла — написал бы простенький лексический анализатор для отлова пропущенной запятой в массиве и прогнал весь код через него.
Может, кто-нибудь накидает, кстати?
Все с ног на голову. Питон пропускает две строки без запятой не потому, что кто-то не доглядел, когда писался парсер. А потому что в нем есть такой синтаксис: две строки, написанные друг за другом склеиваются в одну на этапе парсинга. Это удобно в ряде случаев, когда строка слишком длинная и её нужно разбить на несколько строчек в исходном тексте.
Да я верю, что это придумано для удобства, чтобы не ставить плюс, что в ряде случаев это удобно и так далее. Вот только это породило конкретную проблему у автора топика. Которую он предлагает решить, обрамив каждую строку скобками. В результате, чтобы не ставить один плюс, мы ставим две скобки — супер!
Да я верю, что это придумано для удобства, чтобы не ставить плюс, что в ряде случаев это удобно и так далее. Вот только это породило конкретную проблему у автора топика. Которую он предлагает решить, обрамив каждую строку скобками. В результате, чтобы не ставить один плюс, мы ставим две скобки — супер!
Я предложил решение, которое исправляет эту проблему. С помощью создания утилиты на любом языке и прикручивания ее в дев цикл автор может сохранить код в чистоте и избавить программистов от лишних движений. Вот только Питон от этого лучше не станет. Лучше бы у него был какой-нибудь strict mode, или warning бы выдавался.
Я предложил решение, которое исправляет эту проблему. С помощью создания утилиты на любом языке и прикручивания ее в дев цикл автор может сохранить код в чистоте и избавить программистов от лишних движений. Вот только Питон от этого лучше не станет. Лучше бы у него был какой-нибудь strict mode, или warning бы выдавался.
> В результате, чтобы не ставить один плюс, мы ставим две скобки — супер!
Не мы, а автор. И дело не в плюсе, а в приоритете операций. + довольно низкоприоритетная операция, а слияние строк на этапе парсинга — наивысший приоритет. В результате:
Не мы, а автор. И дело не в плюсе, а в приоритете операций. + довольно низкоприоритетная операция, а слияние строк на этапе парсинга — наивысший приоритет. В результате:
'some string'
'another'.startswith('some') == TrueПожалуйста, никогда так не делайте, если ваш код может читать кто-то другой.
Если очень хочется, то хотя бы:
languages = """english
russian
italian
spanish""".split()
Если в строке случится пробел — то будет проблема :).
split("\n")
?
Можно разделить по переводу строки.
Можно. И тогда первый же регексп который добавит перевод строки в одну их строк списка разрушит цивилизацию :).
Это общая проблема разделителя. Простого решения у нее нет, любое простое решение — это бомба замедленного действия до первого неудачного регекспа по коду. А сложное решение неэффективно — слишком много строчек кода непонятно зачем :).
Это общая проблема разделителя. Простого решения у нее нет, любое простое решение — это бомба замедленного действия до первого неудачного регекспа по коду. А сложное решение неэффективно — слишком много строчек кода непонятно зачем :).
В функции/методе такие многострочники выглядят ужасно.
За такой код надо увольнять.
Редкостный бред.
Писать надо сразу правильно, а главное помнить одно «есть только один способ правильно сделать что-то» в Питоне,
и стоит ему следовать.
Вы сейчас показали хрень.
Редкостный бред.
Писать надо сразу правильно, а главное помнить одно «есть только один способ правильно сделать что-то» в Питоне,
и стоит ему следовать.
Вы сейчас показали хрень.
Правда я молодец? :)
А еще я больше пятнадцати лет занимаюсь разработкой программ за деньги и руковожу исследовательским отделом.
За такой код не надо увольнять — это хороший код, если применен к месту.
Ну и кому из нас верить?
А еще я больше пятнадцати лет занимаюсь разработкой программ за деньги и руковожу исследовательским отделом.
За такой код не надо увольнять — это хороший код, если применен к месту.
Ну и кому из нас верить?
Ваша статья как раз познавательна об особенностях Питона, а я имел ввиду
то что написал hamst.
Каждый раз чтобы интерпретатор делал сплит по статическому тексту чтобы превратить это в список? это за гранью добра и зла.
то что написал hamst.
Каждый раз чтобы интерпретатор делал сплит по статическому тексту чтобы превратить это в список? это за гранью добра и зла.
Мотивируйте, пожалуйста, почему это бред/хрень?
Потому что, при вызове ф-ии или инициализации, интерпретатор будет разбирать вашу строку и делать из нее список.
Проще явно правильно написать один раз.
Проще явно правильно написать один раз.
Т.е. основной момент — производительность, согласен, но хочу сказать, что там, где пишут такой код, идут на это сознательно.
Решений, в которых удобство поддержки длинных списков важнее скорости, не так уж и мало, к примеру, я активно использую такой подход в системах сборки на scons в небольших проектах для редактирования списка исходников. Сопровождать оформленые таким образом списки мне сильно удобней.
Решений, в которых удобство поддержки длинных списков важнее скорости, не так уж и мало, к примеру, я активно использую такой подход в системах сборки на scons в небольших проектах для редактирования списка исходников. Сопровождать оформленые таким образом списки мне сильно удобней.
Этот способ плох тем, что нельзя комментировать строки или отключать некоторые через закомментирование.
Хотя (на примере не питона)…
Хотя (на примере не питона)…
string languages = @"english
russian
" /* это типа итальянский -> */ +@"italian
spanish".Split("\n");
Тогда уже сплит по \n, а то вдруг в строке будет пробел. Но это все равно бред так делать :))
eyeofhell, спасибо за статью, но овчинка выделки не стоит. Конструкция выглядит очень неестественно для Python. Если пишется маленький скрипт, то такую ошибку поймать не сложно. А если проект большой, то уж лучше pylint, тесты и т.д.
Я и не претендую на то, что это очередная серебряная пуля. И отдельно подчеркнул, что не считаю данный способ особо красивым и удобным. У него плюсы в надежности.
Стоит или не стоит овчинка выделки — это разработчик решает в каждом конкретном случае сам. В моей практике данный способ хорошо подошел для скриптов внутренней автоматизации, где таких списков много, меняются они часто, а контроль качества ниже, чем для production кода.
В любом случае я считаю что чем больше забавных и интересных приемов знает разработчик — тем легче ему писать и читать код. Даже если какие-то приемы никогда не применяются. Вот будет через год кто-нибудь читать код с гитхаба, увидит такие строчки — и вместо того чтобы дивься и начать разбираться — вспомнит, что это специфический защитный костыль, о котором год назад на хабре писал какой-то лох с непонятной закорючкой на аватарке :). Профит.
Опять же, может в комментах чего дельного напишут. Питон для меня не то чтобы очень профильная технология, есть возможность узнать что-нить новое и интересное малой кровью
Стоит или не стоит овчинка выделки — это разработчик решает в каждом конкретном случае сам. В моей практике данный способ хорошо подошел для скриптов внутренней автоматизации, где таких списков много, меняются они часто, а контроль качества ниже, чем для production кода.
В любом случае я считаю что чем больше забавных и интересных приемов знает разработчик — тем легче ему писать и читать код. Даже если какие-то приемы никогда не применяются. Вот будет через год кто-нибудь читать код с гитхаба, увидит такие строчки — и вместо того чтобы дивься и начать разбираться — вспомнит, что это специфический защитный костыль, о котором год назад на хабре писал какой-то лох с непонятной закорючкой на аватарке :). Профит.
Опять же, может в комментах чего дельного напишут. Питон для меня не то чтобы очень профильная технология, есть возможность узнать что-нить новое и интересное малой кровью
Питона не знаю, но языков, которые бы не ругнулись на изначальном примере — не встречал
Ruby?
[ 'a', 'b' 'c' ] == [ 'a', 'bc' ]
С\C++ хотя бы:
Вполне себе рабочий код. Варнинги, конечно, кидает, но ошибки компиляции нет будет.
char * data[] = {
"str1",
"str2"
"str3",
"str4"
};
Вполне себе рабочий код. Варнинги, конечно, кидает, но ошибки компиляции нет будет.
Тут хотя бы варнинги. В профессиональной разработке задирают до 4-го уровня и правят все что вылезает, так что в плюсах оно не так страшно.
а кто мешает написать хотя бы
char* data[4] = { ... }Clojure.
(def a ["qwe",
"asd"
"zxc",
"rty"])
(def b ["qwe"
"asd",
"zxc"
"rty"])
(= a b) => true
Еще один рецепт забыли! — уйти с питона на руби :)
Боюсь, там та же проблема. И даннный костыль, кстати, тоже применим. У Python и Ruby синтаксис похож.
BTW, вынесу ка я это в заголовок. Чтобы рубисты не пропустили.
BTW, вынесу ка я это в заголовок. Чтобы рубисты не пропустили.
Там нет такой проблемы.
Да и вообще, в руби строки так редко объявляют, там используют символы:
# В одну строку объявлять можно так:
%w(str1 str2 str3)
# Когда в столбик:
['str1',
'str2'
'str3'] # Синтаксическая ошибка
Да и вообще, в руби строки так редко объявляют, там используют символы:
[:str1, :str2, :str3]
Тут нет такой проблемы, дико что эту ситуацию питон не воспринимает как ошибку.
Во, начали душить питонщики, не любят троллинга змеюки :)
Если б было на что переходить, ruby это каменное дитя питона и слона…
Не будьте букой, это просто троллинг :) я вот смотрю какой язык, такие и люди: питон (относительно строгий язык) — и руби (раздолбайский, т.е. можно все).
P.S. Руби уже быстрее питона :)
P.S. Руби уже быстрее питона :)
Где он быстрее?
Не могу найти где я это читал, но можете в гугле поискать тесты Ruby 1.9.3
Что я делаю не так?
shootout.alioth.debian.org/u64q/benchmark.php?test=all&lang=python3&lang2=yarv
shootout.alioth.debian.org/u64q/benchmark.php?test=all&lang=python3&lang2=yarv
python3 используется 3 монахами.
Вполне таки себе используется.
Я уже его использовал, использовал бы больше да gevent пока еще не перешел на него.
Я уже его использовал, использовал бы больше да gevent пока еще не перешел на него.
нифига. очень даже используется. мэйнтстрим активно переходит (вот даже джанга на днях зарелизится с поддержкой 3 ветки)
Иначе говоря, самый популярный фрэимворк (а так flask) все еще не поддерживает 3 ветку. gevent (которая 100500 раз лучше ноды) не поддерживает. Вакансий на 3 ветку нет. Не вижу мэинсттрима. Большая часть библиотек все еще не может в python3. О каком переходе мы говорим?
gevent в новом релизе на libev ее поддерживает.
bottle поддерживает.
И какая часть библиотек не поддерживает python3?
greenlet поддерживают. Остальная часть спокойной сработает 2to3.py кроме некоторых редких экземпляров.
bottle поддерживает.
И какая часть библиотек не поддерживает python3?
greenlet поддерживают. Остальная часть спокойной сработает 2to3.py кроме некоторых редких экземпляров.
pylons и pyramid давно поддерживают.
джанга с весны(пока в альфе, релиз на подходе)
я уже больше года замечательно живу с третьим. проблемм с библиотеками почти нет.
джанга с весны(пока в альфе, релиз на подходе)
я уже больше года замечательно живу с третьим. проблемм с библиотеками почти нет.
Угу, ждём когда Армин Роханер Werkzeug и Flask на Py3 переведут. А всё идёт к тому, что он это сделаёт одним из последних :(
Werkzeug в dev ветке вроде как уже.
Угу, только пока это не Армин: github.com/mitsuhiko/werkzeug/issues/212
1) python2 все ещё быстрее чем python3 (как минимум в тестах на том же shootout)
2) а куда блин подевался python2 из shootout?!?
3) я не монах)
4) 3.3 python имхо вызовет шквальный переход.
2) а куда блин подевался python2 из shootout?!?
3) я не монах)
4) 3.3 python имхо вызовет шквальный переход.
Почему 3.3 вызовет шквальный переход? Какие у него киллер плюшки?
Почитайте ченджлог же
Моё имхо:
1) перейти с 2.х проще на 3.3 чем на 3.2 и уж тем более чем на 3.1
2) оно наконец не медленнее 2го питона практически. Понятно что в некоторых случаях и быстрее
3) оно наконец без ucs2/ucs4 сплита юникода
4) море синтаксического сахара, наподобие raise from None
3й уже даже в генте ворочается как системный питон без проблем. Всё. Пора)
Моё имхо:
1) перейти с 2.х проще на 3.3 чем на 3.2 и уж тем более чем на 3.1
2) оно наконец не медленнее 2го питона практически. Понятно что в некоторых случаях и быстрее
3) оно наконец без ucs2/ucs4 сплита юникода
4) море синтаксического сахара, наподобие raise from None
3й уже даже в генте ворочается как системный питон без проблем. Всё. Пора)
perl выдаёт ошибку, и спасибо ему за это.
Правда, я всё равно использую первый способ, запятые в каждой строчке — так проще местами менять.
Правда, я всё равно использую первый способ, запятые в каждой строчке — так проще местами менять.
groovy выдает ошибку и спасибо ему за это (С)
Именно из-за таких штук придумали языки со строгим синтаксисом и типизацией такие как Паскаль, Ява, C#,…
А можно просто покрывать всё тестами, и не страдать от строгого синтанксиса и типизации.
т.е. покрывать тестами то, что должен делать компилятор и система типов — это «не страдать»?
Тестами надо покрывать не проверку типов, а бизнес-логику.
бизнес-логику надо покрывать тестами в любом случае, причем здесь типизация и синтаксис?
Тесты штука хорошая, но при ограниченном бюджете все что хочется не всегда удается тестами покрыть. Просто потому, что тот бизнес, который за бизнес логику платит деньги, иногда хочет здесь и сейчас :). Приходится балансировать.
BTW, не все одинакого удобно покрывается тестами. Тот же скрипт сборки или деплоя — его тестами покрыть и поддерживать в актуальном состоянии задача очень нетривиальная, я покрывал :(.
BTW, не все одинакого удобно покрывается тестами. Тот же скрипт сборки или деплоя — его тестами покрыть и поддерживать в актуальном состоянии задача очень нетривиальная, я покрывал :(.
Расскажите лучше, как защититься от случайного использования строки в контексте, где ожидается список строк.
Автоматической защиты я не знаю, в питоне строка — это список символов :). Ну или что-то очень к нему близкое. Можно поставить прямой запрет в API:
def myapifunction( self, somelist ) :
assert hasattr( somelist, '__iter__' ), "passing string instead of a list?"
...
isinstance(x, basestring)? Или я уже ниче не понимаю)
Покрываем код тестами.
И какой именно тест поможет найти эту ошибку в, например, скрипте юнит-тестов? Или в скрипте развертывания сервера на тестовом окружении? Или в скрепте настройки чего-нибудь? Юнит-тесты — штука дорогая. Покрывать ими, к примеру, утилиты внутренней автоматизации — дорого.
Именно утилиты внутренней автоматизации нужно покрывать тестами в первую очередь.
Если весь проект ляжет тупо из-за того, что была ошибка в скрипте раскладки (к примеру) — попа будет болеть долго.
Если весь проект ляжет тупо из-за того, что была ошибка в скрипте раскладки (к примеру) — попа будет болеть долго.
Покрывать тестами вообще все — дорого. Это можно себе позволить только если деньги или время не лимитированы. При наличии лимита по бюджету и срокам приходится балансировать между запасом прочности сейчас, запасом гибкости на будущее и сроком, к которому это можно собрать.
BTW, я разве где-то написал что описанный трюк позволяет отказаться от тестов? Вы так активно меня в этом упрекаете в комментах, что можно заподозрить мое темное альтер-его в том, что оно по-тихому отредактировало пост и написало там какую-нить ересь :).
BTW, я разве где-то написал что описанный трюк позволяет отказаться от тестов? Вы так активно меня в этом упрекаете в комментах, что можно заподозрить мое темное альтер-его в том, что оно по-тихому отредактировало пост и написало там какую-нить ересь :).
Если проект не будет написан к дедлайну, то попа болеть не будет, но и источника боли тоже не будет. Нет проекта — нет денег, нет работы.
Совсем не pythonic-way. Больше похоже на JavaScript.
Про PEP-8 автор, конечно, не в курсе, — советую ознакомиться.
И проблемой это не является — вкрутить проверку кода на соответствие PEP8 (утилиты "pep8", или даже "flake8", что ещё кошернее) в редактор при сохранении или в git (mercurial) хуком при коммите — дело трёх минут.
Про PEP-8 автор, конечно, не в курсе, — советую ознакомиться.
И проблемой это не является — вкрутить проверку кода на соответствие PEP8 (утилиты "pep8", или даже "flake8", что ещё кошернее) в редактор при сохранении или в git (mercurial) хуком при коммите — дело трёх минут.
Чтобы не было голословным:
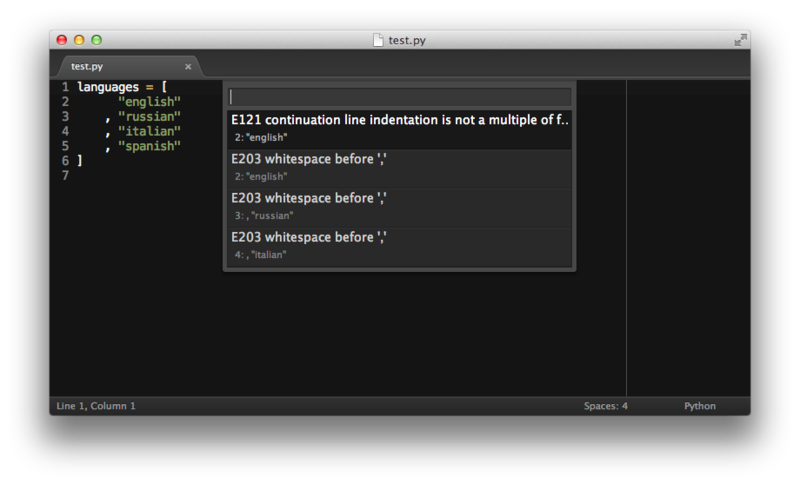
$ cat test.py
languages = [
"english"
, "russian"
, "italian"
, "spanish"
]
$ pep8 test.py
test.py:2:7: E121 continuation line indentation is not a multiple of four
test.py:2:16: E203 whitespace before ','
test.py:3:16: E203 whitespace before ','
test.py:4:16: E203 whitespace before ','

При чем тут 'whitespace before ','? На приведенном скриншоте — три ложных срабатывания на запятую перед литералом и одно неверное форматирование. См. мой пример ниже.
При том, что этот код — некорректен с точки зрения pep8. Так писать нельзя.
А вы можете привести пример вертикального списка строк, который пройдет валидацию PEP8? :)
languages = ["english",
"russian",
"italian",
"spanish"]
languages = [
"english",
"russian",
"italian",
"spanish",
]
Ну вот у меня pep8 для
и
показывает одинаковый набор ошибок. Тоесть факта потери запятой в упор не видит. Назовите, чтоли, операционку и версию питона на которой я могу это чудо лицезреть? Или может какой волшебный ключик ему скормить надо?
languages = [
"english",
"russian",
"italian",
"spanish",
]
и
languages = [
"english",
"russian",
"italian"
"spanish",
]
показывает одинаковый набор ошибок. Тоесть факта потери запятой в упор не видит. Назовите, чтоли, операционку и версию питона на которой я могу это чудо лицезреть? Или может какой волшебный ключик ему скормить надо?
Это не потеря запятой. Это не ошибка. Это базис, основа языка Python. Почитайте что-нибудь про язык, прежде чем начинать на нём писать, или возвращайтесь на Си или переходите на раби-перл-что-там-ещё — вам так проще будет.
EDIT: OS X 10.8.2, Python 2.7.3
EDIT: OS X 10.8.2, Python 2.7.3
То есть вы считаете, что если программист при написании вертикального списка опечатался и не поставил запятую (а в реальном мире такое иногда случается) — то это не ошибка? :)
Ошибка — это когда программа неправильно работает. То, что правила конкатенации строковых литералов в питоне не делают написанное синтаксической ошибкой — не значит, что это вообще не ошибка и с такими опечатками не надо бороться :).
Пишите еще, с интересом читаю вашим комменты :)
Ошибка — это когда программа неправильно работает. То, что правила конкатенации строковых литералов в питоне не делают написанное синтаксической ошибкой — не значит, что это вообще не ошибка и с такими опечатками не надо бороться :).
Пишите еще, с интересом читаю вашим комменты :)
То есть если программист вместо — поставил + это ошибка парсера, вм, компилятора, а не программиста?
Это я к тому, что Питон все по правилам делает, а программист пытается навязать свое в данном посте.
Это я к тому, что Питон все по правилам делает, а программист пытается навязать свое в данном посте.
Я прямо даже не знаю что написать. На тролля вы не похожи, а такой набор слов ответили :(.
Если программист вместо '-' поставил '+', то это логическая ошибка в программе. Логическая ошибка от синтаксической отличается тем, что с точки зрения языка программа валидна и может работать, но работает не так как нужно разработчику. А так, как он написал :)
Потеря запятой — это логическая ошибка. Получившаяся программа будет запускаться и работать — но не так, как ожидает разработчик. Это как в известном анекдоте — компьютер делает не то что вы хотите чтобы он делал, а что вы ему сказали делать.
Питон все делает правильно, и в этом печалька. Потому как программисту в данном конкретном случае не нужно чтобы питон что-нибудь делал — ему нужно обнаружить и исправить ошибку. Описанные в статье подходы, начиная от статического анализатора и заканчивая волшебными круглыми скобочками это позволяют сделать.
Если программист вместо '-' поставил '+', то это логическая ошибка в программе. Логическая ошибка от синтаксической отличается тем, что с точки зрения языка программа валидна и может работать, но работает не так как нужно разработчику. А так, как он написал :)
Потеря запятой — это логическая ошибка. Получившаяся программа будет запускаться и работать — но не так, как ожидает разработчик. Это как в известном анекдоте — компьютер делает не то что вы хотите чтобы он делал, а что вы ему сказали делать.
Питон все делает правильно, и в этом печалька. Потому как программисту в данном конкретном случае не нужно чтобы питон что-нибудь делал — ему нужно обнаружить и исправить ошибку. Описанные в статье подходы, начиная от статического анализатора и заканчивая волшебными круглыми скобочками это позволяют сделать.
И проблемой это не является — вкрутить проверку кода на соответствие PEP8 (утилиты «pep8», или даже «flake8», что ещё кошернее) в редактор при сохранении или в git (mercurial) хуком при коммите — дело трёх минут.
И как эта проверка будет работать?
$ pypm install pep8
$ echo "l = [ 'a'," > test.py
$ echo " 'b'" >> test.py
$ echo " 'c' ]" >> test.py
$ echo "" >> test.py
$ pep8 test.py
.\test.py:1:21: E231 missing whitespace after ','
.\test.py:5:2: W292 no newline at end of file
Здесь, насколько я вижу, только ошибочное срабатывание под windows детектирования newline. Можете привести рабочий пример срабатывания валидатора на проблемный код в топике?
А это не ошибочный код — с точки зрения питона код в топике валидный — я сам так разбиваю строки, когда они слишком длинные. Поэтому ни один валидатор не поймёт, корректен ли этот код, или это ощибка кодера.
ИМХО, проблема высосана из пальца, и решение просто ужасно.
Вот честно, — ни разу вообще не сталкивался на практике с такого рода ошибками, а из-за невнимательности разработчика можно наделать гораздо более серьёзные ошибки.
Код таких неопытных программистов я всегда (!) прогояю через code-review — в таком случае выявляются 99% таких (и всех других прочих) опечаток.
Ну и тесты, тесты, тесты, тесты, тесты.
ИМХО, проблема высосана из пальца, и решение просто ужасно.
Вот честно, — ни разу вообще не сталкивался на практике с такого рода ошибками, а из-за невнимательности разработчика можно наделать гораздо более серьёзные ошибки.
Код таких неопытных программистов я всегда (!) прогояю через code-review — в таком случае выявляются 99% таких (и всех других прочих) опечаток.
Ну и тесты, тесты, тесты, тесты, тесты.
Вот честно, — ни разу вообще не сталкивался на практике с такого рода ошибками
Значит мало скриптов внутренней автоматизации пишете :). Меня всегда умиляет, когда человек с одним специфическим опытом работы, например в разработке веб страничек, пытается растянуть свой опыт на все программирование вообще, потом на всю разработку вообще, ну и затем на все айти вообще. Для комплекта.
Программирование — оно большое. И между написанием веб странички и созданием драйвера ядра довольно мало общего, хотя и то и другое «программируется программистами на кампутере».
Если бы проблема была высосана из пальца — стал бы я о ней писать? Закономерность была выявлена в последний год, когда в компании активнее стали использовать питон для написания скриптов сборки, тестирования и деплоя. И решение я пополз искать далеко не после первого кейса с такой ошибкой :).
Скажем так, мой опыт гораздо шире и глубже, чем вам показалось.
Переходить на личности и «умиляться», уподобляясь вам не буду.
P.S. Вот за такой лапшевидный php-style код: bitbucket.org/eyeofhell/sigma/ я бы гнал своего бойца в три шеи. Слава Богу, таких не держим ;)
Переходить на личности и «умиляться», уподобляясь вам не буду.
P.S. Вот за такой лапшевидный php-style код: bitbucket.org/eyeofhell/sigma/ я бы гнал своего бойца в три шеи. Слава Богу, таких не держим ;)
Могу только за вас порадоваться и пожелать творческих успехов. Пишите еще, с интересом читаю вашим комменты :). Особенно про лапшу в сигме — то-то я там новую декомпозицию на общей шине сделал. Вот как оказывается лапша-то возникает :).
Взаимно.
А ваш код тоже можно почитать? Поделитесь ссылкой, пожалуйста.
В профиле всё есть.
первый же файл…
Тесты, это, конечно, хорошо. Но люди опечатываются. Даже вы. И лишний трюк в копилку разработчика еще никому не вредил.
Владимир — откуда столько агрессии? Я вас чем-то обидел? Написал что-то оскорбляющее ваши профессиональные чувства? Вы тут в каждом комменте пытаете доказать что я не умею программировать. От чего такая реакция на обычную обзорную заметку об интересном и забавном способе борьбы с опечатками? Я же не декларирую что это серебряная пуля и что так надо делать. Просто еще одна возможность, о которой мало кто знает. Для общего развития, так сказать. Программистам же надо развиваться?
case 'l':
port = atoi(optarg);
case '?':
syslog(LOG_ERR, "Unknown option character")
break;
Тесты, это, конечно, хорошо. Но люди опечатываются. Даже вы. И лишний трюк в копилку разработчика еще никому не вредил.
Владимир — откуда столько агрессии? Я вас чем-то обидел? Написал что-то оскорбляющее ваши профессиональные чувства? Вы тут в каждом комменте пытаете доказать что я не умею программировать. От чего такая реакция на обычную обзорную заметку об интересном и забавном способе борьбы с опечатками? Я же не декларирую что это серебряная пуля и что так надо делать. Просто еще одна возможность, о которой мало кто знает. Для общего развития, так сказать. Программистам же надо развиваться?
Извините, был взволнован.
Бывает. BTW, интересный трюк моего авторства для C и C++. Позволяет избежать потере бряка:
Не стандарт, конечно — но компилируется на всем, до чего я смог дотянуться :).
switch( subject )
{
break; case 'a' :
foo();
break; case 'b' :
bar();
break; default :
assert( false );
}
Не стандарт, конечно — но компилируется на всем, до чего я смог дотянуться :).
Интересный приём, спасибо.
Ошибку в «mrad» поправил, спасибо за замечание.
Ошибку в «mrad» поправил, спасибо за замечание.
Выглядит плохо. Не пройдет ни один review по code style.
Я думал, я один тут заморочен на code style, code review, единости и целостности проекта, соответствие его общемировым стандартам и практикам, лёгкостью поддержки и развития посредством расширения команды разработчиков.
Удваиваю.
EDIT: не туда написал. ответ на комментарий Semy.
Удваиваю.
EDIT: не туда написал. ответ на комментарий Semy.
Эта штука сделана не для того чтобы ревью проходить. Она сделана чтобы бряки не терялись :).
Хотя да, и условие йоды, и это выглядит не лучшим образом. Тут, конечно, лучше настроенный lint — но, опять же, lint по дефолту не расмматривает потерянный break как ошибку — нужно вводить специальные метки в комметариях и тонкую настройку. А continous integration не везде есть.
Хотя да, и условие йоды, и это выглядит не лучшим образом. Тут, конечно, лучше настроенный lint — но, опять же, lint по дефолту не расмматривает потерянный break как ошибку — нужно вводить специальные метки в комметариях и тонкую настройку. А continous integration не везде есть.
Имхо все ваши проблемы решает самописная утилита-«защита от дурака». Потерянные брейки не рассматриваются как ошибки, естественно, потому, что пропуск брейка может быть сделан намеренно, упростив структуру программы. Так же, как и запятая в массиве может быть пропущена специально. Утилита-фильтр выведет строки, где вам надо отревьювить код более внимательно, и вы уже будете решать, надо оно там вам или нет.
Позволю себе самоцитироваться :)
BTW, у меня нет проблем. Но я ищу способы улучшить, расширить и углубить. Исследовательская деятельность в целях изучения перспектив и потенциального улучшения процессов.
Тут, конечно, лучше настроенный lint — но, опять же, lint по дефолту не расмматривает потерянный break как ошибку — нужно вводить специальные метки в комметариях и тонкую настройку. А continous integration не везде есть.
BTW, у меня нет проблем. Но я ищу способы улучшить, расширить и углубить. Исследовательская деятельность в целях изучения перспектив и потенциального улучшения процессов.
Элегантный, хотя и лисповатый способ, спасибо. Хотя мне все чаще мечтается о клавиатурах с обратной связью, бьющие током за нажатие комбинаций <Ctr-C> + <Ctrl-V>.
Ну и, господа, пять страниц комментариев на тему «как правильно ставить скобочки»! Блестяще! :)
Ну и, господа, пять страниц комментариев на тему «как правильно ставить скобочки»! Блестяще! :)
Слишком категорично: copy/paste скорее добро, чем зло.
Потому что он помогает избежать опечаток при переносе всяких URL, id, и т.п.
Потому что он помогает избежать опечаток при переносе всяких URL, id, и т.п.
Нет-нет, не надо 10 киловольт и обугленных пальцев за любую копипасту. Я о другом.
Строго говоря, copy/paste вообще вне добра и зла. Это просто инструмент, который требует осторожности. То есть, прежде чем воткнуть скопированное, надо остановиться и немножко подумать. И почему-то мне кажется, что легкий неприятный разряд тока заставит многих помедлить, прежде чем воткнуть голые данные/кусок кода/копию настроек. А там, глядишь, мелькнет мысль «а может, сделать константу/функцию/секцию general в конфиге».
Строго говоря, copy/paste вообще вне добра и зла. Это просто инструмент, который требует осторожности. То есть, прежде чем воткнуть скопированное, надо остановиться и немножко подумать. И почему-то мне кажется, что легкий неприятный разряд тока заставит многих помедлить, прежде чем воткнуть голые данные/кусок кода/копию настроек. А там, глядишь, мелькнет мысль «а может, сделать константу/функцию/секцию general в конфиге».
Главное, знать этому меру. А то придётся копипастить названия секций и ключей конфига.
Или сделать конфиг ключей конфигов :)
Или сделать конфиг ключей конфигов :)
Слабый разряд злостные копипастеры перетерпят, а потом и привыкнут не замечать.
Надо подключать социальную составляющую: над головой копипастера загорается лампочка, воет сирена и страшный голос вещает: Имярек скопипастил 1420 знаков!
Надо подключать социальную составляющую: над головой копипастера загорается лампочка, воет сирена и страшный голос вещает: Имярек скопипастил 1420 знаков!
Атож. Зато я узнал что в Python и Ruby такой синтаксис чутое различается. И что отвечая на комментарий нужно не на синие кружочки слева смотреть, а на синюю стрелочку справа нажимать. Сплошной профит. Главное, чтобы подушка кармы была большой, у меня этот топик уже десятку съел :).
UFO just landed and posted this here
да ну прекратите.
это то же самое что и переменную перепутать. Тоже не просто дебажить и тоже надо код читать.
ни разу не имел проблем с пропавшими запятыми чесслово
это то же самое что и переменную перепутать. Тоже не просто дебажить и тоже надо код читать.
ни разу не имел проблем с пропавшими запятыми чесслово
Прочитал статью, порадовался, что у меня таких проблем нет.
Хотя не могу не поделиться своим наблюдением, там где «нужно» писать вертикально, то запятая теряется (у меня напремер в js). Но, когда я пишу списки на питоне, запятые не теряются никогда, потому что я их не пишу вертикально. Я правда за всю свою практику ни одного случая потери запятой в списке не помню, где бы это вылились в содержание топика.
Хотя не могу не поделиться своим наблюдением, там где «нужно» писать вертикально, то запятая теряется (у меня напремер в js). Но, когда я пишу списки на питоне, запятые не теряются никогда, потому что я их не пишу вертикально. Я правда за всю свою практику ни одного случая потери запятой в списке не помню, где бы это вылились в содержание топика.
Что люди только не придумают, лишь бы не пользоваться IDE
Sign up to leave a comment.
Python: надежная защита от потери запятой в вертикальном списке строк