
Технологии глубокого обучения за короткий срок прошли большой путь развития — от простых нейронных сетей до достаточно сложных архитектур. Для поддержки быстрого распространения этих технологий были разработаны различные библиотеки и платформы глубокого обучения. Одна из основных целей подобных библиотек заключается в том, чтобы предоставить разработчикам простые интерфейсы, позволяющие создавать и обучать нейросетевые модели. Подобные библиотеки позволяют своим пользователям обращать больше внимания на решаемые задачи, а не на тонкости реализации моделей. Для этого может понадобиться скрывать реализацию базовых механизмов за несколькими уровнями абстракции. А это, в свою очередь усложняет понимание базовых принципов, на которых основаны библиотеки глубокого обучения.

Статья, перевод которой мы публикуем, нацелена на разбор особенностей устройства низкоуровневых строительных блоков библиотек глубокого обучения. Сначала мы кратко поговорим о сущности глубокого обучения. Это позволит нам понять функциональные требования к соответствующему программному обеспечению. Затем мы рассмотрим разработку простой, но работающей библиотеки глубокого обучения на Python с использованием NumPy. Эта библиотека способна обеспечить сквозное обучение простых нейросетевых моделей. По ходу дела мы поговорим о различных компонентах фреймворков глубокого обучения. Библиотека, которую мы будем рассматривать, совсем невелика, меньше 100 строк кода. А это значит, что с ней будет достаточно просто разобраться. Полный код проекта, которым мы будем заниматься, можно найти здесь.
Обычно библиотеки глубокого обучения (вроде TensorFlow и PyTorch) состоят из компонентов, представленных на следующем рисунке.

Компоненты фреймворка глубокого обучения
Разберём эти компоненты.
Понятия «оператор» и «слой» (layer) обычно используются как взаимозаменяемые. Это — базовые строительные блоки любой нейронной сети. Операторы — это векторные функции, которые трансформируют данные. Среди часто используемых операторов можно выделить такие, как линейные (linear) и свёрточные (convolution) слои, слои субдискретизации (pooling), полулинейные (ReLU) и сигмоидальные (sigmoid) функции активации.
Оптимизаторы — это основа основ библиотек глубокого обучения. Они описывают методы подстройки параметров моделей с использованием неких критериев и с учётом цели оптимизации. Среди известных оптимизаторов можно отметить SGD, RMSProp и Adam.
Функции потерь — это аналитические и дифференцируемые математические выражения, которые используются в виде заменителя цели оптимизации при решении некоей проблемы. Например, функцию перекрёстной энтропии и кусочно-линейную функцию обычно используют в задачах классификации.
Инициализаторы предоставляют начальные значения для параметров модели. Именно эти значения параметры имеют в начале обучения. Инициализаторы играют важную роль в деле обучения нейронных сетей, так как неудачные начальные параметры могут означать то, что сеть будет обучаться медленно, или вовсе не сможет обучиться. Существует множество способов инициализации весов нейронной сети. Например — можно назначить им небольшие случайные значения из нормального распределения. Вот страница, на которой можно узнать о различных видах инициализаторов.
Регуляризаторы — это инструменты, которые позволяют избегать переобучения сети и помогают сети приобрести способность к обобщению. Бороться с переобучением сети можно явными или неявными способами. Явные методы предусматривают структурные ограничения весов. Например, минимизацию их L1-Norm и L2-Norm, что, соответственно, делает значения весов лучше рассеянными и более равномерно распределёнными. Неявные методы представлены специализированными операторами, которые выполняют трансформацию промежуточных представлений. Это производится либо посредством явной нормализации, например, с использованием техники пакетной нормализации (BatchNorm), либо путём изменения связности сети с использованием алгоритмов DropOut и DropConnect.
Вышеописанные компоненты обычно принадлежат к интерфейсной части библиотеки. Здесь под «интерфейсной частью» я понимают сущности, с которыми может взаимодействовать пользователь. Они дают ему удобные средства для эффективного проектирования архитектуры нейронной сети. Если говорить о внутренних механизмах библиотек, то они могут обеспечивать поддержку автоматического расчёта градиентов функции потерь с учётом различных параметров модели. Эту технику обычно называют автоматическим дифференцированием (Automatic Differentiation, AD).
Каждая библиотека глубокого обучения предоставляет пользователю некие возможности по автоматическому дифференцированию. Это даёт ему возможность сосредоточиться на описании структуры модели (графа вычислений) и передать задачу по вычислению градиентов AD-модулю. Разберём пример, который позволит нам узнать о том, как всё это работает. Предположим, мы хотим вычислить частные производные следующей функции по её входным переменным X₁ и X₂:
Y = sin(x₁)+X₁*X₂
Следующий рисунок, который я позаимствовал отсюда, показывает граф вычислений и вычисление производных посредством цепного правила.
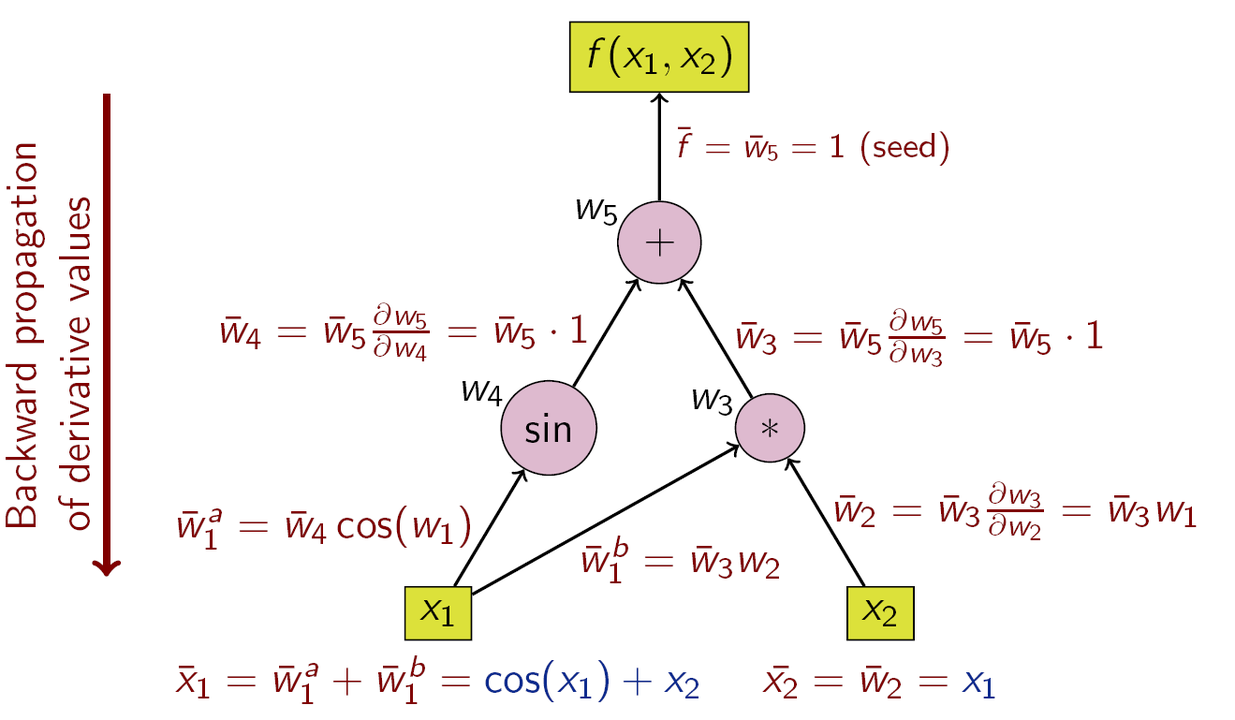
Вычислительный граф и вычисление производных по цепному правилу
То, что вы тут видите, это нечто вроде «обратного режима» автоматического дифференцирования. Хорошо известный алгоритм обратного распространения ошибки — это особый случай вышеописанного алгоритма для случая, когда функция, расположенная в верхней части, является функцией потерь. AD использует тот факт, что любая сложная функция состоит из элементарных арифметических операций и элементарных функций. В результате производные могут быть вычислены путём применения к этим операциям цепного правила.
В предыдущем разделе мы рассмотрели компоненты, необходимые для создания библиотеки глубокого обучения, предназначенной для создания и сквозного обучения нейронных сетей. Для того чтобы не усложнять пример, я имитирую здесь паттерн проектирования библиотеки Caffe. Тут мы объявляем два абстрактных класса —
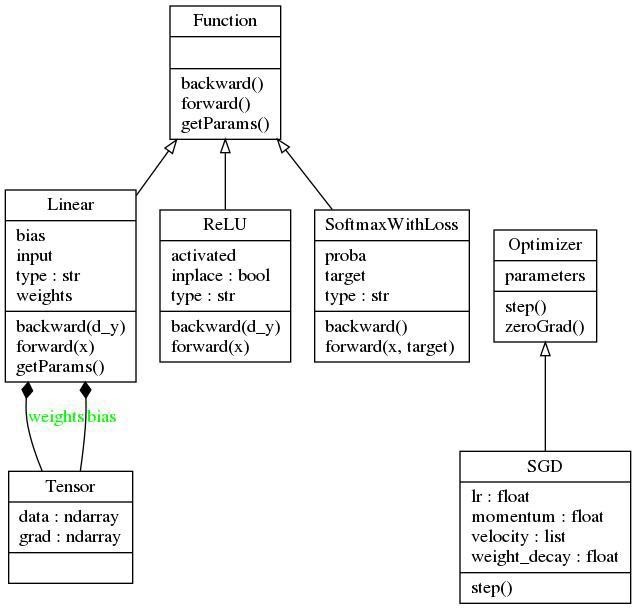
UML-диаграмма библиотеки
В момент написания этого материала данная библиотека содержит реализацию линейного слоя, функции активации ReLU, слоя SoftMaxLoss и оптимизатора SGD. В результате оказывается, что библиотека может быть использована для обучения классификационных моделей, состоящих из полносвязных слоёв и использующих нелинейную функцию активации. Рассмотрим теперь некоторые подробности об имеющихся у нас абстрактных классах.
Абстрактный класс
Все операторы реализуются через наследование абстрактного класса
Для того чтобы разобраться со всем этим на конкретном примере — взглянем на реализацию функции
Метод
Абстрактный класс
Все оптимизаторы реализуются путём наследования от базового класса
Теперь, чтобы лучше всё это понять, рассмотрим конкретный пример — реализацию алгоритма стохастического градиентного спуска (SGD, stochastic gradient descent) c поддержкой настройки импульса и сокращения весов:
Теперь у нас есть всё необходимое для обучения (глубокой) нейросетевой модели с помощью нашей библиотеки. Для этого нам понадобятся следующие сущности:
Следующий псевдокод описывает типичный цикл тестирования:
Хотя это в библиотеке глубокого обучения и необязательно, возможно, полезно будет включить вышеописанный функционал в отдельный класс. Это позволит не повторять одни и те же действия при обучении новых моделей (данная идея соответствует философии высокоуровневых абстракций фреймворков наподобие Keras). Для того чтобы этого добиться, объявим класс
Этот класс включает в себя следующие функциональные возможности:
Так как этот класс не является базовым строительным блоком систем глубокого обучения, я реализовал его в отдельном модуле
Теперь рассмотрим последний фрагмент кода, в котором производится обучение нейросетевой модели с использованием вышеописанной библиотеки. Я собираюсь обучить многослойную сеть на данных, расположенных в виде спирали. Меня на это подвигла данная публикация. Код для генерирования этих данных и для их визуализации можно найти в файле

Данные с тремя классами, расположенные в виде спирали
На предыдущем рисунке показана визуализация данных, на которых мы будем обучать модель. Эти данные нелинейно разделимы. Мы можем надеяться на то, что сеть со скрытым слоем сможет правильно найти нелинейные решающие границы. Если собрать воедино всё то, о чём мы говорили, то получится следующий фрагмент кода, который позволяет обучить модель:
Ниже показано изображение, на котором можно видеть те же данные и решающие границы обученной модели.

Данные и решающие границы обученной модели
С учётом всё увеличивающейся сложности моделей глубокого обучения наблюдается тенденция к росту возможностей соответствующих библиотек и к росту объёмов кода, необходимых для реализации этих возможностей. Но самый основной функционал подобных библиотек всё ещё можно реализовать в сравнительно компактном виде. Хотя та библиотека, которую мы создали, и может использоваться для сквозного обучения простых сетей, она всё ещё, во многих отношениях, ограничена. Речь идёт об ограничениях в сфере возможностей, которые позволяют фреймворкам глубокого обучения использоваться в таких областях, как машинное зрение, распознавание речи и текстов. Этим, конечно, возможности подобных фреймворков не ограничиваются.
Полагаю, что все желающие могут сделать форк проекта, код которого мы тут рассматривали, и, в качестве упражнения, внести в него то, что им хотелось бы в нём видеть. Вот некоторые механизмы, которые вы можете попробовать реализовать самостоятельно:
Надеюсь, этот материал позволил вам хотя бы краем глаза увидеть то, что происходит в недрах библиотек для глубокого обучения.
Уважаемые читатели! Какими библиотеками для глубокого обучения вы пользуетесь?


Статья, перевод которой мы публикуем, нацелена на разбор особенностей устройства низкоуровневых строительных блоков библиотек глубокого обучения. Сначала мы кратко поговорим о сущности глубокого обучения. Это позволит нам понять функциональные требования к соответствующему программному обеспечению. Затем мы рассмотрим разработку простой, но работающей библиотеки глубокого обучения на Python с использованием NumPy. Эта библиотека способна обеспечить сквозное обучение простых нейросетевых моделей. По ходу дела мы поговорим о различных компонентах фреймворков глубокого обучения. Библиотека, которую мы будем рассматривать, совсем невелика, меньше 100 строк кода. А это значит, что с ней будет достаточно просто разобраться. Полный код проекта, которым мы будем заниматься, можно найти здесь.
Общие сведения
Обычно библиотеки глубокого обучения (вроде TensorFlow и PyTorch) состоят из компонентов, представленных на следующем рисунке.
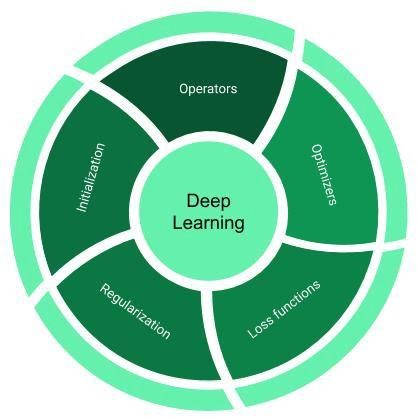
Компоненты фреймворка глубокого обучения
Разберём эти компоненты.
▍Операторы (operators)
Понятия «оператор» и «слой» (layer) обычно используются как взаимозаменяемые. Это — базовые строительные блоки любой нейронной сети. Операторы — это векторные функции, которые трансформируют данные. Среди часто используемых операторов можно выделить такие, как линейные (linear) и свёрточные (convolution) слои, слои субдискретизации (pooling), полулинейные (ReLU) и сигмоидальные (sigmoid) функции активации.
▍Оптимизаторы (optimizers)
Оптимизаторы — это основа основ библиотек глубокого обучения. Они описывают методы подстройки параметров моделей с использованием неких критериев и с учётом цели оптимизации. Среди известных оптимизаторов можно отметить SGD, RMSProp и Adam.
▍Функции потерь (Loss functions)
Функции потерь — это аналитические и дифференцируемые математические выражения, которые используются в виде заменителя цели оптимизации при решении некоей проблемы. Например, функцию перекрёстной энтропии и кусочно-линейную функцию обычно используют в задачах классификации.
▍Инициализаторы (Initializers)
Инициализаторы предоставляют начальные значения для параметров модели. Именно эти значения параметры имеют в начале обучения. Инициализаторы играют важную роль в деле обучения нейронных сетей, так как неудачные начальные параметры могут означать то, что сеть будет обучаться медленно, или вовсе не сможет обучиться. Существует множество способов инициализации весов нейронной сети. Например — можно назначить им небольшие случайные значения из нормального распределения. Вот страница, на которой можно узнать о различных видах инициализаторов.
▍Регуляризаторы (Regularizers)
Регуляризаторы — это инструменты, которые позволяют избегать переобучения сети и помогают сети приобрести способность к обобщению. Бороться с переобучением сети можно явными или неявными способами. Явные методы предусматривают структурные ограничения весов. Например, минимизацию их L1-Norm и L2-Norm, что, соответственно, делает значения весов лучше рассеянными и более равномерно распределёнными. Неявные методы представлены специализированными операторами, которые выполняют трансформацию промежуточных представлений. Это производится либо посредством явной нормализации, например, с использованием техники пакетной нормализации (BatchNorm), либо путём изменения связности сети с использованием алгоритмов DropOut и DropConnect.
Вышеописанные компоненты обычно принадлежат к интерфейсной части библиотеки. Здесь под «интерфейсной частью» я понимают сущности, с которыми может взаимодействовать пользователь. Они дают ему удобные средства для эффективного проектирования архитектуры нейронной сети. Если говорить о внутренних механизмах библиотек, то они могут обеспечивать поддержку автоматического расчёта градиентов функции потерь с учётом различных параметров модели. Эту технику обычно называют автоматическим дифференцированием (Automatic Differentiation, AD).
Автоматическое дифференцирование
Каждая библиотека глубокого обучения предоставляет пользователю некие возможности по автоматическому дифференцированию. Это даёт ему возможность сосредоточиться на описании структуры модели (графа вычислений) и передать задачу по вычислению градиентов AD-модулю. Разберём пример, который позволит нам узнать о том, как всё это работает. Предположим, мы хотим вычислить частные производные следующей функции по её входным переменным X₁ и X₂:
Y = sin(x₁)+X₁*X₂
Следующий рисунок, который я позаимствовал отсюда, показывает граф вычислений и вычисление производных посредством цепного правила.
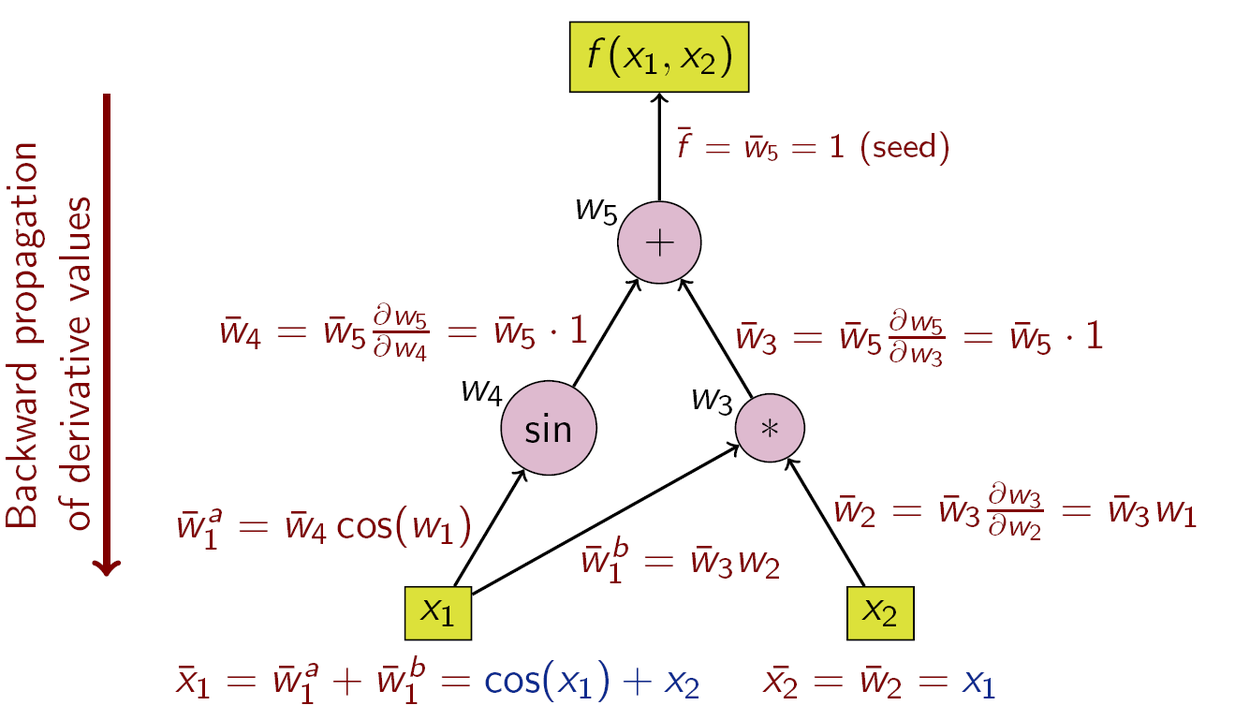
Вычислительный граф и вычисление производных по цепному правилу
То, что вы тут видите, это нечто вроде «обратного режима» автоматического дифференцирования. Хорошо известный алгоритм обратного распространения ошибки — это особый случай вышеописанного алгоритма для случая, когда функция, расположенная в верхней части, является функцией потерь. AD использует тот факт, что любая сложная функция состоит из элементарных арифметических операций и элементарных функций. В результате производные могут быть вычислены путём применения к этим операциям цепного правила.
Реализация
В предыдущем разделе мы рассмотрели компоненты, необходимые для создания библиотеки глубокого обучения, предназначенной для создания и сквозного обучения нейронных сетей. Для того чтобы не усложнять пример, я имитирую здесь паттерн проектирования библиотеки Caffe. Тут мы объявляем два абстрактных класса —
Function и Optimizer. Кроме того, здесь имеется класс Tensor, который представляет собой простую структуру, содержащую два многомерных массива NumPy. Один из них предназначен для хранения значений параметров, другой — для хранения их градиентов. Все параметры в различных слоях (операторах) будут иметь тип Tensor. Прежде чем мы пойдём дальше — взглянем на общую схему библиотеки.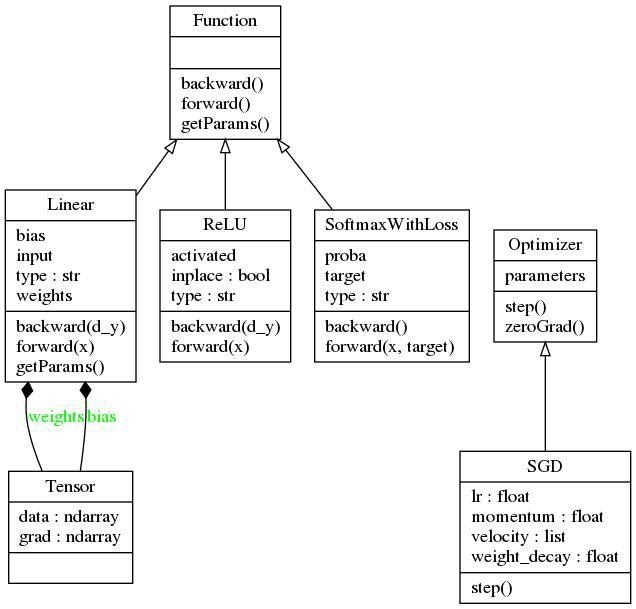
UML-диаграмма библиотеки
В момент написания этого материала данная библиотека содержит реализацию линейного слоя, функции активации ReLU, слоя SoftMaxLoss и оптимизатора SGD. В результате оказывается, что библиотека может быть использована для обучения классификационных моделей, состоящих из полносвязных слоёв и использующих нелинейную функцию активации. Рассмотрим теперь некоторые подробности об имеющихся у нас абстрактных классах.
Абстрактный класс
Function предоставляет интерфейс для операторов. Вот его код:class Function(object):
def forward(self):
raise NotImplementedError
def backward(self):
raise NotImplementedError
def getParams(self):
return []Все операторы реализуются через наследование абстрактного класса
Function. Каждый оператор должен предоставлять реализацию методов forward() и backward(). Операторы могут содержать реализацию необязательного метода getParams(), возвращающего их параметры (если таковые имеются). Метод forward() получает входные данные и возвращает результат их трансформации оператором. Он, кроме того, решает внутренние задачи, необходимые для вычисления градиентов. Метод backward() принимает частные производные функции потерь по отношению к выходам оператора и реализует расчёт частных производных функции потерь по отношению к входным данным оператора и к параметрам (если они есть). Обратите внимание на то, что метод backward(), в сущности, предоставляет нашей библиотеке возможность по выполнению автоматического дифференцирования.Для того чтобы разобраться со всем этим на конкретном примере — взглянем на реализацию функции
Linear:class Linear(Function):
def __init__(self,in_nodes,out_nodes):
self.weights = Tensor((in_nodes,out_nodes))
self.bias = Tensor((1,out_nodes))
self.type = 'linear'
def forward(self,x):
output = np.dot(x,self.weights.data)+self.bias.data
self.input = x
return output
def backward(self,d_y):
self.weights.grad += np.dot(self.input.T,d_y)
self.bias.grad += np.sum(d_y,axis=0,keepdims=True)
grad_input = np.dot(d_y,self.weights.data.T)
return grad_input
def getParams(self):
return [self.weights,self.bias]Метод
forward() реализует трансформацию вида Y = X*W+b и возвращает результат. Кроме того, он сохраняет входное значение X, так как оно нужно для вычисления частной производной dY функции потерь по отношению к выходному значению Y в методе backward(). Метод backward() получает частные производные, вычисленные по отношению к входному значению X и параметрам W и b. Более того, он возвращает частные производные, вычисленные по отношению к входному значению X, которые будут переданы в предыдущий слой.Абстрактный класс
Optimizer предоставляет интерфейс для оптимизаторов:class Optimizer(object):
def __init__(self,parameters):
self.parameters = parameters
def step(self):
raise NotImplementedError
def zeroGrad(self):
for p in self.parameters:
p.grad = 0.Все оптимизаторы реализуются путём наследования от базового класса
Optimizer. Класс, описывающий конкретную оптимизацию, должен предоставлять реализацию метода step(). Этот метод обновляет параметры модели с использованием их частных производных, вычисленных по отношению к оптимизируемому значению функции потерь. Ссылка на различные параметры модели предоставляется в функции __init__(). Обратите внимание на то, что универсальный функционал по сбросу значений градиентов реализован в самом базовом классе.Теперь, чтобы лучше всё это понять, рассмотрим конкретный пример — реализацию алгоритма стохастического градиентного спуска (SGD, stochastic gradient descent) c поддержкой настройки импульса и сокращения весов:
class SGD(Optimizer):
def __init__(self,parameters,lr=.001,weight_decay=0.0,momentum = .9):
super().__init__(parameters)
self.lr = lr
self.weight_decay = weight_decay
self.momentum = momentum
self.velocity = []
for p in parameters:
self.velocity.append(np.zeros_like(p.grad))
def step(self):
for p,v in zip(self.parameters,self.velocity):
v = self.momentum*v+p.grad+self.weight_decay*p.data
p.data=p.data-self.lr*vРешение реальной задачи
Теперь у нас есть всё необходимое для обучения (глубокой) нейросетевой модели с помощью нашей библиотеки. Для этого нам понадобятся следующие сущности:
- Модель: граф вычислений.
- Данные и целевое значение: данные для обучения сети.
- Функция потерь: заменитель цели оптимизации.
- Оптимизатор: механизм обновления параметров модели.
Следующий псевдокод описывает типичный цикл тестирования:
model #граф вычислений
data,target #учебные данные
loss_fn #цель оптимизации
optim #оптимизатор, предназначенный для обновления параметров сети и минимизации функции потерь
Repeat:#повторять до тех пор, пока модель не сойдётся, или повторять заданное количество эпох
optim.zeroGrad() #установка всех градиентов в ноль
output = model.forward(data) #получение выходных данных модели
loss = loss_fn(output,target) #вычисление потерь
grad = loss.backward() #вычисление градиента потерь по отношению к выходу
model.backward(grad) #вычисление градиентов для всех параметров
optim.step() #обновление параметров моделиХотя это в библиотеке глубокого обучения и необязательно, возможно, полезно будет включить вышеописанный функционал в отдельный класс. Это позволит не повторять одни и те же действия при обучении новых моделей (данная идея соответствует философии высокоуровневых абстракций фреймворков наподобие Keras). Для того чтобы этого добиться, объявим класс
Model:class Model():
def __init__(self):
self.computation_graph = []
self.parameters = []
def add(self,layer):
self.computation_graph.append(layer)
self.parameters+=layer.getParams()
def __innitializeNetwork(self):
for f in self.computation_graph:
if f.type=='linear':
weights,bias = f.getParams()
weights.data = .01*np.random.randn(weights.data.shape[0],weights.data.shape[1])
bias.data = 0.
def fit(self,data,target,batch_size,num_epochs,optimizer,loss_fn):
loss_history = []
self.__innitializeNetwork()
data_gen = DataGenerator(data,target,batch_size)
itr = 0
for epoch in range(num_epochs):
for X,Y in data_gen:
optimizer.zeroGrad()
for f in self.computation_graph: X=f.forward(X)
loss = loss_fn.forward(X,Y)
grad = loss_fn.backward()
for f in self.computation_graph[::-1]: grad = f.backward(grad)
loss_history+=[loss]
print("Loss at epoch = {} and iteration = {}: {}".format(epoch,itr,loss_history[-1]))
itr+=1
optimizer.step()
return loss_history
def predict(self,data):
X = data
for f in self.computation_graph: X = f.forward(X)
return XЭтот класс включает в себя следующие функциональные возможности:
- Описание вычислительного графа: метод
add()позволяет определять модель, состоящую из последовательности слоёв. Внутри класса все операторы хранятся в спискеcomputation_graph. - Инициализация параметров: класс, перед началом обучения, автоматически инициализирует параметры модели небольшими случайными числами, взятыми из нормального распределения.
- Обучение модели: с помощью метода
fit()класс предоставляет универсальный интерфейс для обучения модели. Этому методу для работы нужны обучающие данные, оптимизатор и функция потерь. - Получение вывода модели: метод
predict()является универсальным интерфейсом, который позволяет классу предоставлять доступ к прогнозам, сделанным обученной моделью.
Так как этот класс не является базовым строительным блоком систем глубокого обучения, я реализовал его в отдельном модуле
utilities.py. Обратите внимание на то, что метод fit() использует класс DataGenerator, реализация которого находится в том же модуле. Этот класс представляет собой всего лишь обёртку для обучающих данных и генерирует мини-пакеты для каждой итерации обучения.Обучение модели
Теперь рассмотрим последний фрагмент кода, в котором производится обучение нейросетевой модели с использованием вышеописанной библиотеки. Я собираюсь обучить многослойную сеть на данных, расположенных в виде спирали. Меня на это подвигла данная публикация. Код для генерирования этих данных и для их визуализации можно найти в файле
utilities.py.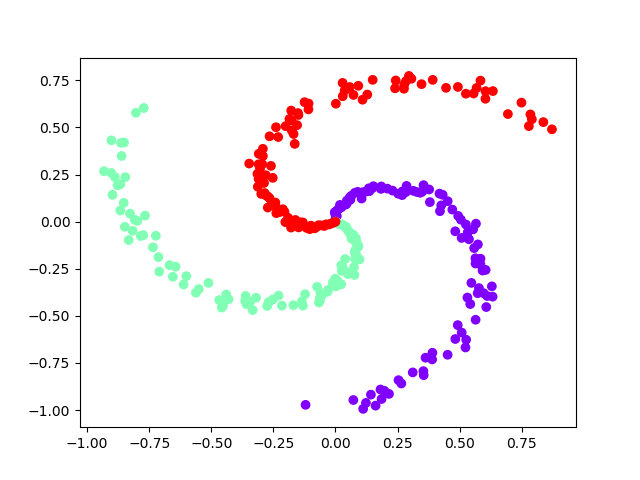
Данные с тремя классами, расположенные в виде спирали
На предыдущем рисунке показана визуализация данных, на которых мы будем обучать модель. Эти данные нелинейно разделимы. Мы можем надеяться на то, что сеть со скрытым слоем сможет правильно найти нелинейные решающие границы. Если собрать воедино всё то, о чём мы говорили, то получится следующий фрагмент кода, который позволяет обучить модель:
import dl_numpy as DL
import utilities
batch_size = 20
num_epochs = 200
samples_per_class = 100
num_classes = 3
hidden_units = 100
data,target = utilities.genSpiralData(samples_per_class,num_classes)
model = utilities.Model()
model.add(DL.Linear(2,hidden_units))
model.add(DL.ReLU())
model.add(DL.Linear(hidden_units,num_classes))
optim = DL.SGD(model.parameters,lr=1.0,weight_decay=0.001,momentum=.9)
loss_fn = DL.SoftmaxWithLoss()
model.fit(data,target,batch_size,num_epochs,optim,loss_fn)
predicted_labels = np.argmax(model.predict(data),axis=1)
accuracy = np.sum(predicted_labels==target)/len(target)
print("Model Accuracy = {}".format(accuracy))
utilities.plot2DDataWithDecisionBoundary(data,target,model)Ниже показано изображение, на котором можно видеть те же данные и решающие границы обученной модели.
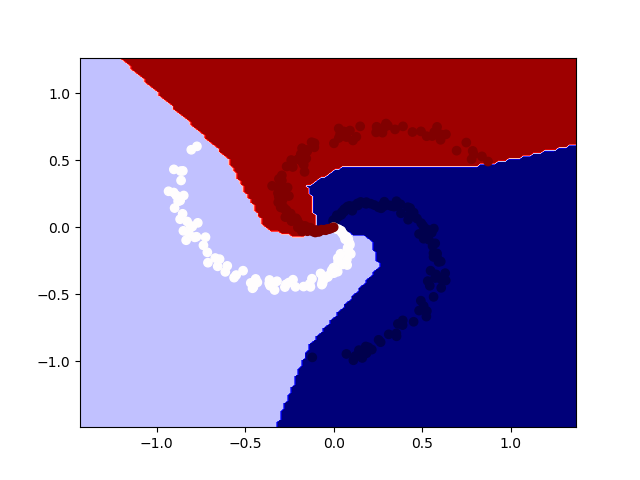
Данные и решающие границы обученной модели
Итоги
С учётом всё увеличивающейся сложности моделей глубокого обучения наблюдается тенденция к росту возможностей соответствующих библиотек и к росту объёмов кода, необходимых для реализации этих возможностей. Но самый основной функционал подобных библиотек всё ещё можно реализовать в сравнительно компактном виде. Хотя та библиотека, которую мы создали, и может использоваться для сквозного обучения простых сетей, она всё ещё, во многих отношениях, ограничена. Речь идёт об ограничениях в сфере возможностей, которые позволяют фреймворкам глубокого обучения использоваться в таких областях, как машинное зрение, распознавание речи и текстов. Этим, конечно, возможности подобных фреймворков не ограничиваются.
Полагаю, что все желающие могут сделать форк проекта, код которого мы тут рассматривали, и, в качестве упражнения, внести в него то, что им хотелось бы в нём видеть. Вот некоторые механизмы, которые вы можете попробовать реализовать самостоятельно:
- Операторы: свёртка, субдискретизация.
- Оптимизаторы: Adam, RMSProp.
- Регуляризаторы: BatchNorm, DropOut.
Надеюсь, этот материал позволил вам хотя бы краем глаза увидеть то, что происходит в недрах библиотек для глубокого обучения.
Уважаемые читатели! Какими библиотеками для глубокого обучения вы пользуетесь?

