Comments 18
ребят go, c++, rust слабее .net .
Парадигма "производительность - выбирай более низкоуровневый язык" , всё?
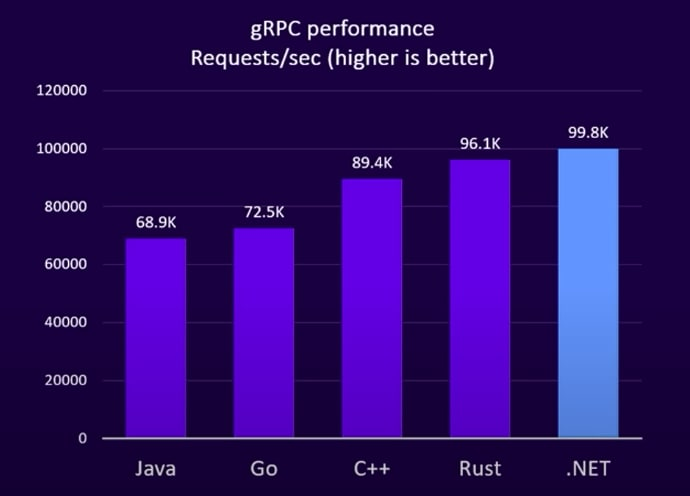
Разница в пределах стат погрешности. Но в целом, .net видимо довольно хорошо написали реализацию grpc.
производительность - выбирай более низкоуровневый язык
Приведенная "парадигма" очевидно никогда не была истинной - для того чтобы писать на чем-то "более низкоуровневом" и иметь от этого какой-то прирост производительности надо уметь писать на этом "более низкоуровневом" как минимум не хуже чем те кто писал "более высокоуровневые" инструменты
ох уже эти свидетели языков, с gc, который не дает никакого overhead.
А откуда дровишки-то? Я таких в паинте тоже нарисовать могу
Не совсем. Дело в том, что в тестах techempower, который показывает самый производительный Web фреймворк используется не коробочное решение, а максимально затюненое решение. Затюненое до такой степени, что читать код невозможно.
Был статья на хабре об этом.
https://habr.com/ru/post/701352/
Т.е. в реальной жизни все так - именно в классической парадигме.
Есть хорошая статья здесь же на Хабре, которая описывает как команда .NET добилась таких результатов и в целом грамотный обзор этих сравнений.
https://habr.com/ru/post/701352/
Неплохо бы репо с кодом на гитхабе добавить
Эхо-сервер gRPC в статье на 6 минут с пометкой "Сложный"?) Я не понимаю эту категоризацию сложностей материалов
Просвятите пожалуйста за место классического rpc в 2023г
Не программирую уже очень давно, лет 15 наверное. Но последнее что писал, так это была CORBA на С++. И как раз застал времена окончания корбы и появления SOAP (и всего этого околодинамического через веб).
Были жуткие баттлы и дискусии преимущества и недостатков разных подходов. Вкратце сторонники RPC-style (корба, dcom, и т.п.) упирали на эффективность работы решения в части общей производительности, сетевого трафика, которая минимум раз в 10 была быстрее тогда. У сторонников динамического подхода основным аргументом была гибкость, и то , что в отличие от корбы трафик инкапсулировался в хттп, т.е. не надо было пилить дырки в фаерволе.
Если отвлечься от неудобства самой корбы (особенно ее жуткого маппинга на C++), то вцелом RPC-технологии именно и предполагали статический подход: описываем интерфейсы, потом отдельным компилятором файл интерфефсов превращается в C++ исходник с заглушками, который далее надо было наполнять изнутри. И все было хорошо, пока не было нужды меняьт этот файл интерфейсов и заново генерировать реализацию. Адаптация старого кода в новый - уже головная боль разработчика.
В общем статический подход уступил пусть неэффективному, но динамическому в век интернета и зарождения веб-сервисов. Потом соап уступил место более вмеyяемому json (ну эту эпоху я уже пропустил).
А как дела обстоят сейчас. к чему пришло?
(P.S. в качестве ностальгии вспоминаю уютный форум corba.kubsu.ru, вдруг кто из олдскульщиков его помнит)
В эпоху микросервисов проще пересобрать всю статику и не давать разрастаться микро до размеров монолита. В итоге адаптация занимает минимум времени. Плюс ко всему ещё всякие интеграционные тесты пишут, чтобы взаимодействие с остальными микросервисами проверять. Поэтому, если не забывать всё это делать, то головная боль не настолько великая.
т.е. круг замкнулся и подход: .idl->idl-compiler->interface_stub.cpp/.->comilier снова в тренде?
а как сейчас принято, когда надо менять интерфейсы и вносить изменения дальше по цепочке?
Круг замкнулся, правда в модерновых языках сборка интерфейсов делается не выходя из языка.
Для остального есть semver. Делаем версию микро с изменениями, прогоняем тесты, пушим в местный регистри в качестве зависимости. Берём зависимый микро, поднимаем версию для него до актуальной, чиним что сломалось, прогоняем тесты, интеграцию, пушим в местный регистри с новой версией. Ну и так далее. Когда последний консумер удовлетворён поднимаем версию микро в CI конфигах.
SOAP — это такая же "статика", отличие тут в текстовом формате против бинарного.
И погубила Корбу не её статичность, а непонятные усложнения на пустом месте (позже они же погубили SOAP). Задача клиента RPC — просто вызвать метод и получить ответ. Задача сервера — просто получить запрос и вернуть значение. А вместо этого надо настраивать какие-то брокеры запросов, предварительно выбрав нужный. Там, среди тех брокеров, хоть были in-process реализации, или в то время до такого примитивизма даже не додумались?
А ещё есть проблема своевременной реакции вендоров — с этими закрытыми брокерами любая проблема грозит стать неразрешимой.
Возьмём необходимость обратных вызовов. Даже такой древний протокол, как FTP, умел работать через NAT. GIOP научился использовать TCP соединение в обе стороны только в 1.2 версии, вышедшей в 1998 году. Ну, это спека в 1998 году вышла, а вот в брокере от Sun двунаправленные соединения не поддерживались даже в 2004м году.
Кстати, SOAP поверх HTTP эту проблему не решает никак. К счастью, SOAP оказался куда более гибким, его можно хоть в тот самый двусторонний TCP завернуть, хоть в более поздние веб-сокеты.
Интересно было бы посмотреть на rust gRpc с flatbuffers вместо protobuf (for perfomance reason). gRpc + flatbuffers на c++ вроде можно (хотя были казусы, когда тима gRpc ломала возможность вставить flatbuffers заместо protobuf) - соответственно, интересно, можно ли так-же на rust?
Дока про Rust есть, соотвественнно и крейт где-то должен быть.
Как создать микросервис на Rust при помощи gRPC