
ВКонтакте — один из самых нагруженных сервисов в рунете. Ежемесячно социальную сеть посещают 97 млн пользователей со всего мира, с самыми разными устройствами и условиями сети. Среди ключевых потребностей аудитории — общение в онлайне. Каждый месяц 20 млн человек пользуются видеозвонками на нашей платформе, и вовлечённость растёт с каждым годом. Особенно высокой активность была в начале пандемии: выросла средняя продолжительность звонка и число групповых звонков. Именно тогда мы поняли, что нужно ускоряться и дать пользователям возможность общаться без ограничений.
Чтобы снять лимиты на число участников в одном звонке, мы реализовали принципиально новую схему работы с видео- и аудиопотоками: построили уникальную архитектуру, которая горизонтально масштабирует звонок на любое количество серверов и потребляет минимум ресурсов — как серверных, так и клиентских.
В этой статье разберёмся, что влияет на качество звука, как и какие из этапов передачи аудиоданных можно потюнить, чтобы обеспечить минимальную задержку и лучшее восприятие качества звонка. А также посмотрим на результаты внедрения нового аудиопайплайна в групповых звонках ВКонтакте.
Disclaimer 1: Выводы и заключения по конкурентам сделаны исключительно из общедоступной информации, общих наблюдений и измерений и могут быть ошибочными.
Disclaimer 2: Огромное влияние на качество передачи любых real-time данных оказывает сеть, но сетевой слой мы обсудим в отдельной статье. Здесь же сосредоточимся на том, что происходит с аудио на клиенте-источнике до передачи по сети; на клиенте-получателе после того, как данные уже пришли; а также на сервере между ними.
Постановка задачи
В мае 2020-го мы запустили минимальную версию групповых видеозвонков на 8 человек. В сентябре расширили возможности до 128 участников в звонке, а сейчас и вовсе избавляемся от этого ограничения — чтобы обеспечить безлимитное общение.
Для того чтобы заложить правильные архитектурные решения и выбрать направление развития, нам нужны были не только продуктовые требования, но и технологические. По результатам маркетингового исследования мы знали, что пользователи хотят качественные звонки, доступные на всех устройствах. На инженерный язык мы перевели это следующим образом:
качество, которое складывается из низких задержек и надёжной работы в нестабильной сети;
решение под мобильные платформы, веб и десктоп;
экономное потребление клиентских ресурсов;
без теоретического ограничения на число участников;
низкое потребление серверных ресурсов, даже при 10 000 участников;
Из этих требований и будем исходить в дальнейшем.
Обработка аудио на клиенте
Для начала рассмотрим звонок один на один и проследим путь аудио от микрофона Алисы до динамиков Бориса и обратно. На самом деле, чтобы попасть в сеть, звук проходит много этапов обработки на стороне клиентов.
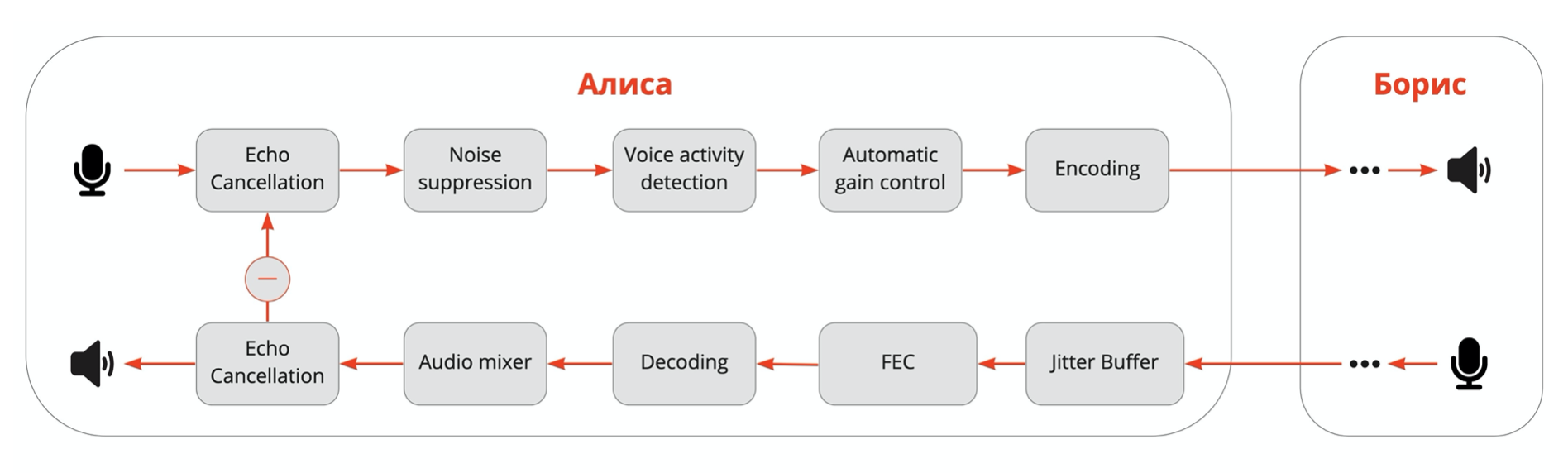
Сначала срабатывает acoustic echo cancellation (AEC): он вырезает из входящего в микрофон сигнала то, что миллисекунды назад воспроизводилось динамиком устройства. Причём если Алиса слышит сама себя, то это значит, что AEC плохо отработал на стороне Бориса. Поэтому, когда в онлайн-митинге вы слышите эхо, нужно мьютить кого-то, кто просто слушает, а не того, кто говорит (наверное, этот навык на удалёнке все освоили). Но на всякий случай Google Meet теперь предупреждает, если от вас идёт эхо.
Второй обязательный этап — noise supression. Тут речь пока не про перфоратор (о сложном шумоподавлении говорим в отдельной статье), а о том, что элементарно встроенный микрофон в ноутбуке расположен рядом с вентилятором. Если не фильтровать такой стационарный шум и отправлять оригинальный звук, то будет совсем ничего не слышно.
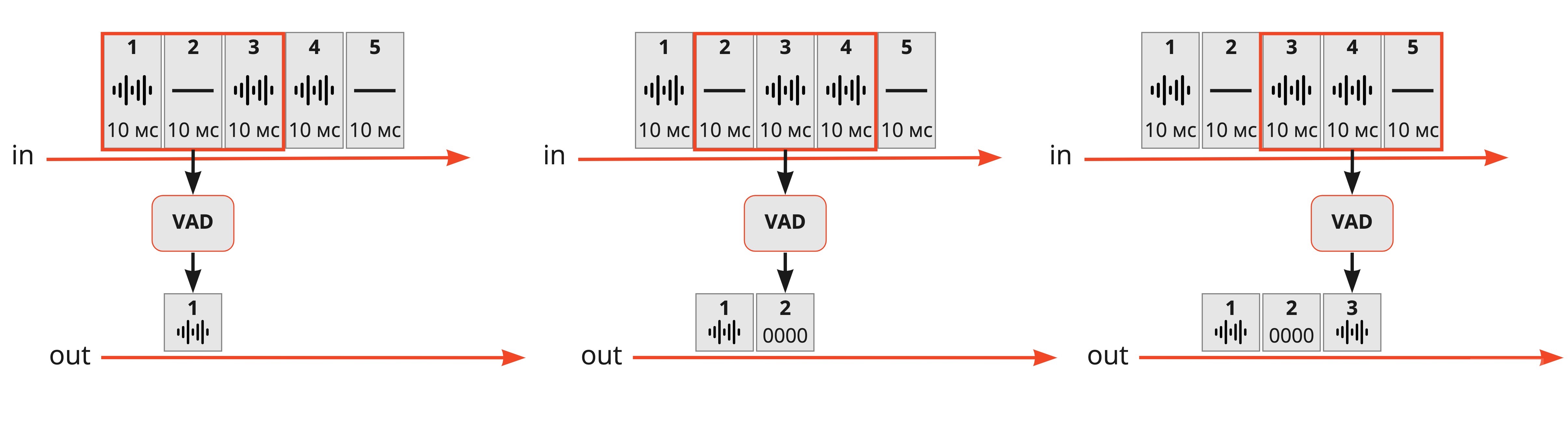
Дальше — voice activity detection (VAD), который оценивает, говорит ли Алиса в данный момент или нет. Нужен для того, чтобы оптимизировать передачу тишины по сети: или не посылать совсем, или кодировать с меньшим битрейтом.
Automatic gain control (AGC) выравнивает громкость, чтобы в групповом звонке вы слышали всех участников с одинаковой громкостью и вам не приходилось всё время регулировать её вручную.
И только после этого аудио от Алисы кодируется и отправляется по сети Борису.
Входящий аудиопоток тоже, как правило, проходит несколько этапов. Jitter buffer и FEC нужны, чтобы компенсировать сетевые эффекты. Jitter buffer борется с неравномерностью задержки (которая и называется jitter). Он выравнивает пакеты во времени, чтобы их можно было проиграть без щелчков и заиканий. Для этого используется буферизация, поэтому jitter buffer добавляет итоговую задержку. С помощью FEC (forward error correction) за счёт избыточного кодирования можно восстановить небольшой процент потерянных пакетов.
Кроме того, на этапе декодирования можно ускорить или растянуть аудио и ещё немного компенсировать задержку или потерю пакетов.
VAD помогает уменьшить влияние jitter buffer на задержку, определяя в сигнале тишину. Это во многих случаях позволяет незаметно ускорить или замедлить аудио, сжимая или растягивая паузы в речи. Можно ускорять и голос — например, с помощью алгоритма Sonic. Но если переборщить, то люди начнут говорить как гномики, — вы наверняка замечали такое в интернет-звонках.
И уже после декодирования в случае группового звонка срабатывает аудиомиксер. Он собирает все аудиодорожки так, чтобы их можно было воспроизвести одновременно.
Аудиокодеки
Для кодирования аудио в интернет-звонках и видеоконференциях де-факто стандартом является Opus. Он хорош на всём диапазоне частот, даёт низкую задержку и доступен в open source.
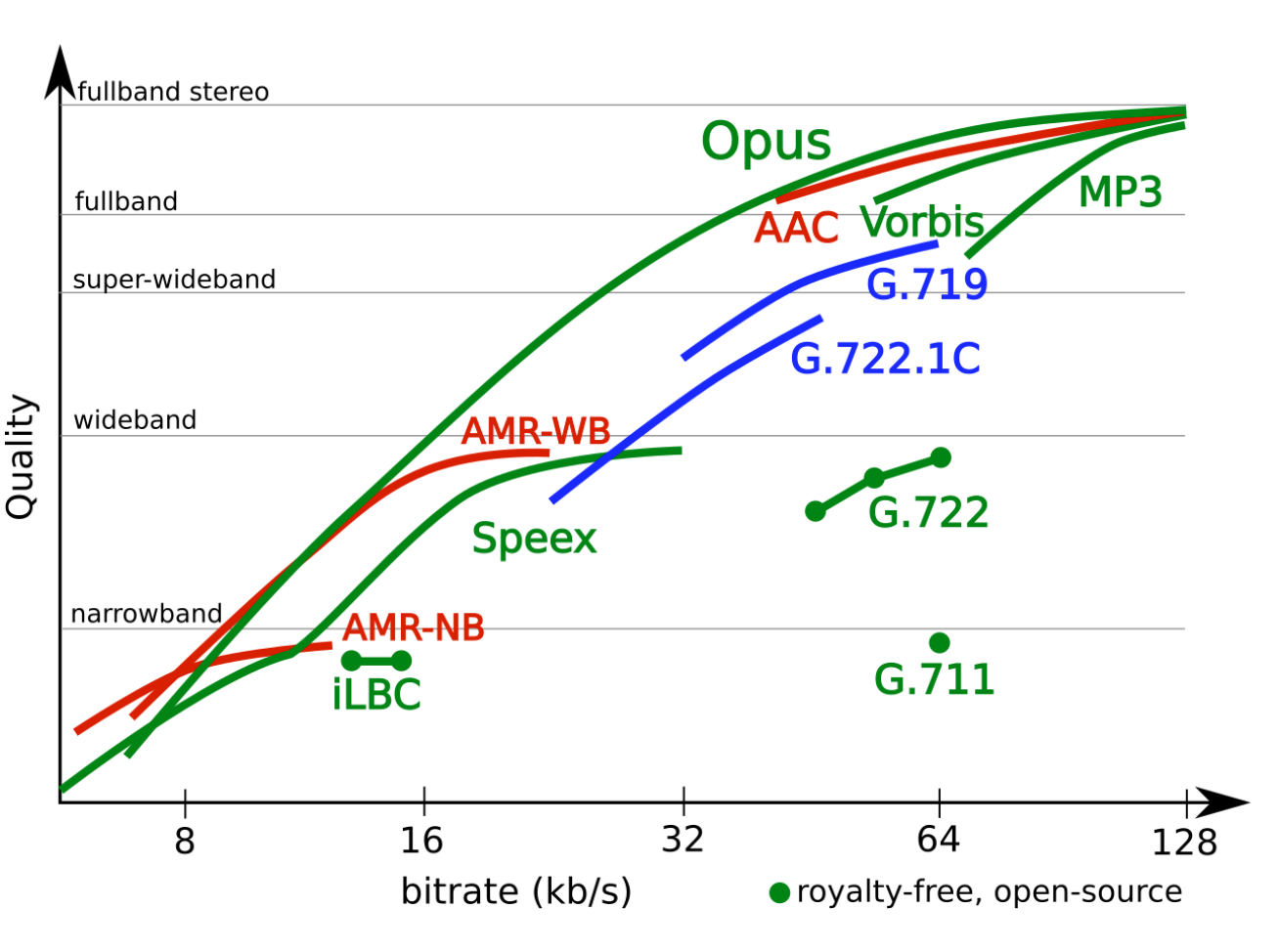
Кроме того, Opus тоже может починить (на самом деле — замаскировать) сетевую потерю пакетов. Для этого в кодеке есть механизм Packet loss concealment (PLC), который по сути «додумывает», как должен был звучать пропущенный кусочек. Для одного потерянного пакета в 20 мс это хорошо работает и на слух незаметно, больше уже получится странно.

PLC работает в комплекте с jitter buffer, но не нужно его путать с FEC (forward error correction). Хотя и то, и то призвано бороться с packet loss: PLC маскирует потерю единичного пакета, а FEC компенсирует её за счёт избыточного кодирования. PLC включается одной настройкой, то есть применить это у себя не стоит ничего. FEC чуть сложнее, но во многих случаях эта дополнительная работа оправдана.
Time stretching
Как вы уже поняли, мы всеми силами пытаемся минимизировать задержки. С latency порядка 0,5–1 секунды собеседники начинают друг друга перебивать — это очень мешает разговору и кажется, что заикается звук. Поэтому накопившиеся в сети или ещё где-то задержки мы пытаемся компенсировать на декодировании с помощью ускорения.
Рассмотрим следующую ситуацию (левый график): сначала пакеты приходят равномерно, с задержкой, равной размеру пакета, — 20 мс; потом что-то где-то немного застряло и пакеты пришли пачкой — с меньшим интервалом, но с большей задержкой.

Справа на картинке схематично показано, как будет воспроизводиться аудио в такой ситуации.
Сначала, понятно, всё хорошо — получаем 20 мс, проигрываем 20 мс, получаем новые 20 мс и т. д.
Дальше, когда вовремя не получим следующий пакет, ещё 20 мс замаскируем с помощью PLC.
А затем, делать нечего, придётся играть тишину (при этом ещё нужно сделать fade out, чтобы не был слышен щелчок при переходе на неё).
Когда застрявшая пачка пакетов дойдёт, начнём просто равномерно проигрывать эти пакеты, не обращая внимания, что накопилась задержка в 80 мс.
И только когда убедимся, что новые пакеты приходят равномерно, без потерь и дополнительных задержек, можно аккуратно ускорить их воспроизведение, чтобы компенсировать накопившиеся 80 мс задержки.
Для этого и придуман jitter buffer. Стандартного способа его реализации нет — у каждого VOIP-инженера есть свой кастомный «самый лучший» подход и собственные эвристики, как его лучше настроить. Потому что это всегда поиск баланса между latency и искажением.
Итого: что нам говорит теория работы со звуком в real time
При реализации звонков придётся разобраться в аббревиатурах AEC, NS, VAD, AGC и включить их в свой пайплайн.
Потерю пакетов можно починить с помощью FEC и замаскировать PLC. Оба механизма есть в самом популярном и распространённом аудиокодеке OPUS.
Проблемы сети можно нивелировать за счёт ускорения.
Чем лучше VAD, тем больше можно догнать без искажений.
Нужен jitter buffer, его настройки — это всегда компромисс между latency и количеством искажений.
Групповые звонки. Топология для передачи аудио
Чтобы перейти от p2p-звонков к групповым, базово есть два варианта серверной топологии:
либо микшировать все потоки в один и передавать его клиенту — называется MCU (Multipoint Conferencing Unit);
либо использовать сервер как ретранслятор пакетов, которые декодируются уже на клиенте, — это SFU (Selective Forwarding Unit).
Ещё в теории групповых звонков есть Mesh, когда каждый устанавливает прямое соединение с каждым. Но на практике для более чем четырёх участников это не работает.
Когда мы говорим только об аудио, казалось бы, трафик не очень большой и можно использовать SFU-топологию: отправлять аудио от каждого каждому.

Но если в звонке много участников и все они хотят одновременно говорить, то:
будет много суммарного исходящего трафика — порядка 1 Мбит/с для десяти участников и кодирования аудио в высоком качестве;
потребуется N – 1 декодеров на клиенте;
возможна нестабильная работа WebRTC при большом количестве входящих аудиопотоков (± 50 в зависимости от устройства и платформы).
Тогда попробуем собрать все аудиопотоки в один — реализуем MCU-топологию. Пока только для аудио. Однако если просто сложить все входящие аудиопотоки в один и раздать полученное всем участникам, то они услышат сами себя.

Поэтому после того, как мы смиксовали все аудио, нужно для каждого участника на серверной стороне вычесть персонально его дорожку, чтобы предотвратить эхо. Делается это простым вычитанием.
Ниже — упрощённая схема аудиотопологии.

Теперь вспомним о jitter buffer, который выравнивает пакеты во времени, может компенсировать потерю пакетов и частично задержку.
Сравним SFU- и MCU-подходы в аудиотопологии с точки зрения jitter buffer. В SFU, когда сервер по сути просто пересылает пакеты и ничего с ними не делает, все алгоритмы, компенсирующие сеть, в том числе jitter buffer, оказываются на стороне клиента.
Когда же мы выбираем MCU-топологию, то перед тем, как обработать аудио и собрать их в один поток, входящие пакеты нужно «отджиттерить» — на сервере перед микшером появляется jitter buffer. При этом клиентский jitter buffer тоже нужен — чтобы компенсировать задержки в сети между сервером и принимающим клиентом.

Два jitter buffer вместо одного в теории дают бóльшую задержку. Проиллюстрируем, почему это происходит, на графиках задержки.

Предположим, сеть мигнула сначала на плече от клиента (Алисы) до сервера, а потом ещё один раз по дороге от сервера до принимающего клиента (Бориса). Верхний ряд графиков показывает задержку в SFU-топологии: в этом примере на разных отрезках сети скучились и задержались разные пакеты. Поэтому jitter buffer на устройстве Бориса без проблем выровнял оба сбоя последовательно — точно так же, как сделал бы это в p2p-соединении.
Нижний ряд — задержка в MCU-топологии. Jitter buffer перед сервером выровнял первую получившуюся нерегулярность и при этом был вынужден нарастить задержку до 80 мс. Меньше этого задержка на втором плече уже не будет, но если сеть мигнёт опять (на плече от сервера до Бориса), то второй jitter buffer добавит ещё задержку, чтобы компенсировать застревание пакетов.
На практике и в других сценариях всё может сработать и в обратную сторону. Поэтому нам в любом случае приходится идти на компромисс и выбирать: без аудиомикса не нужны два jitter buffer и теоретическая задержка меньше, но требуется много клиентских ресурсов — и это ограничивает количество говорящих участников в звонке.
В групповых звонках ВКонтакте для аудио мы используем MCU-топологию и отправляем на клиент один аудиопоток. При этом нагрузка на серверный CPU в среднем получается около 5% на кодирование и декодирование аудио для одного участника и меньше 0,05% на собственно микс аудио. Дополнительной задержки, связанной именно с микшированием аудио, нет, так как мы просто суммируем семплы. Остаётся только джиттерная задержка, которая не константна и зависит от клиентов. У нас медиана по джиттерной задержке 60 мс.
Настройка кодирования под сеть
Мы поддерживаем звонки на вебе, поэтому используем WebRTC — открытый стандарт, предназначенный для передачи real-time данных между браузерами.
В глубине WebRTC спрятан audio network adapter, который умеет смотреть на параметры сети — потери и пропускную способность — и адаптировать параметры кодирования.
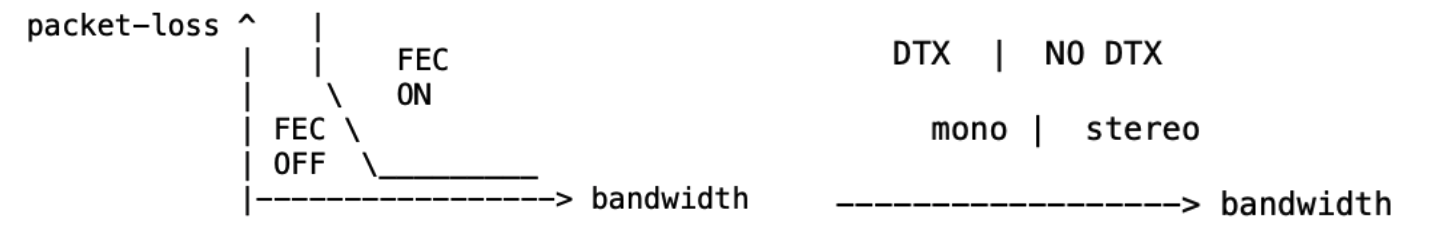
Во-первых, можно попросить кодек включать Forward Error Correction при больших потерях и достаточной пропускной способности. Если пропускная способность позволяет, то почему бы не добавить поток под коррекцию потерь и слегка не пожертвовать битрейтом ради более стабильного сигнала.
Во-вторых, можно не отправлять пакеты, когда участник молчит. Это называется DTX — discontinuous transmission. Аудиоадаптер позволяет настроить порог пропускной способности, при превышении которого отключать режим DTX. Кроме того, можно переключать channelCount=1/2 (mono/stereo) также в зависимости от ширины сетевого канала.
В-третьих, адаптер может управлять размером фрейма в зависимости от пропускной способности, а в случае её недостатка предпочесть низкой задержке эффективное использование канала.
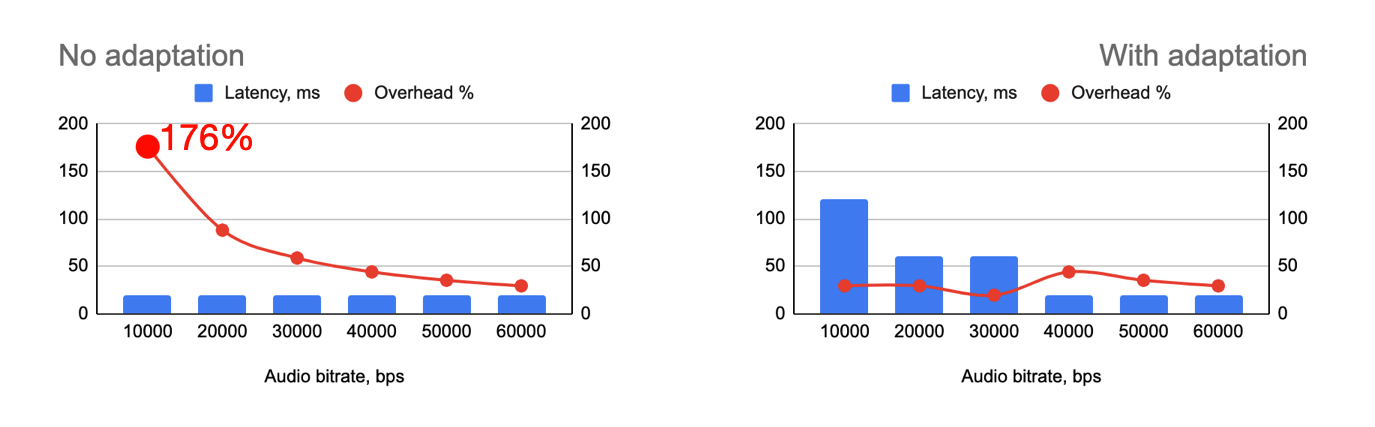
При этом на каждый пакет добавляется overhead: IPv4(20) + UDP(8) + RTP(12) + SRTP(4) = ориентировочно 44 байт (+20 если используем IPv6).
Чтобы включить этот audio network adapter и автоматически подстраивать параметры под сеть, передаём protobuf-конфигурацию в googAudioNetworkAdaptorConfig.
Аккуратный тюнинг конфигурации позволяет очень дёшево, буквально на ровном месте, получить неплохой выигрыш по качеству и объёму данных. Например, на Android packet loss стал меньше в два раза, а round trip time сократился примерно на 20%: с 220 до 180 мс на Wi-Fi, с 255 до 215 мс на LTE, с 470 до 370 мс на 3G.
Почему-то адаптер хорошо спрятан, но теперь вы знаете, где его искать, — и как легко улучшить свои интернет-звонки.
Аудиопайплайн
Стандартный подход мы разобрали в первой части статьи. Посмотрим, чем отличается пайплайн в звонках ВКонтакте.

Мы заменили два элемента: voice activity detection и noise suppression. В них отошли от традиционных алгоритмов, которые доступны из коробки в WebRTC.
Voice activity detection
VAD получает на вход кусочек аудио и анализирует, есть ли в нём человеческая речь. VAD в WebRTC основан на Gaussian mixture model и на выходе классифицирует каждые 10, 20 или 30 мс как голос или тишину.
Мы заменили его на гораздо более актуальную классификацию поверх градиентного бустинга. Наш подход отличается от WebRTC тем, что каждые 10 мс анализируются без учёта контекста, но на окне в 30 мс со сдвигом. На выходе или речевой сигнал, или нолики, если в этом интервале участник не говорил.
Иметь кастомный и более эффективный VAD выгодно. Когда мы лучше отделяем речь от шума, то:
передаём меньше трафика;
снижаем нагрузку на микширование;
jitter buffer нагоняет без искажений;
не проходят и не звучат в фоне лишние шумы вроде стука клавиатуры, если нет голоса.
Эффективность определяем в первую очередь тем, что по сравнению с VAD из WebRTC у нас получилось меньше ложных срабатываний. На сложном тесте при false_rejection = 1%, то есть заданных условиях, когда не более 1% голоса можно принять за шум, VAD на GMM из WebRTC даёт false_acceptance = 83%, а у нас на CatBoost false_acceptance = 55%. По сути это значит 30% сэкономленного трафика. Плюс у нас получилось на 20% меньше ускорений с искажениями.
Шумоподавление
О том, как реализовано шумоподавление, подробно рассказали в отдельной статье. Здесь только кратко перечислим, зачем оно нужно и что даёт.
Замечательный сосед с перфоратором мешает не только тому, у кого он за стенкой, но и всем участникам звонка. Если встроить в сервис видеоконференций шумоподавление, то субъективное восприятие качества связи повысится, потому что посторонний шум не будет отвлекать от разговора.
Но чтобы технология шумоподавления действительно сделала звонки лучше, она должна удовлетворять довольно жёстким требованиям:
работать в real time (не добавлять больше 20 мс задержки);
качественно давить шум на уровне state-of-the-art решений;
быть легковесной, чтобы работать на клиентских устройствах, то есть занимать как можно меньше памяти и требовать как можно меньше CPU.
У WebRTC есть встроенный noise suppression, основанный на эвристических алгоритмах, но с помощью современных нейросетевых подходов можно добиться большего.
Среди нескольких возможных архитектур мы выбрали ту, которая лучше всего удовлетворяет нашим требованиям, — DTLN. Ещё немного её модифицировали и написали на C++, чтобы быстрее работала. Сейчас нейросеть обрабатывает окно в 30 мс за ~0,2 мс, real-time factor > 40.
PESQ | ROM | |
Исходный сигнал | 1,71 | — |
WebRTC | 1,8 | 0 |
RNNoise | 1,93 | 0,35 Мбайт |
NSNet | 2,05 | 11 Мбайт |
DTLN (baseline) | 2,41 | 3,9 Мбайт |
DTLN (VK) | 2,54 | 5,3 Мбайт |
Наша модель отстаёт по качеству от лучших решений не более чем на 10%, бесшовно интегрируется с WebRTC и Opus и cкачивается на телефон on-demand.
Суммарный эффект от внедрения VAD и технологии шумоподавления:
сэкономили 30% аудиотрафика;
уменьшили число ускорений звука с искажениями на 60%;
повысили качество на 40% по метрике PESQ.
Всё круто, всем по кастомному VAD и шумодаву, но нужно быть аккуратными.
Когда мы впервые запустили клиентский шумодав, то увидели существенный рост в починке latency с искажениями. Оказалось, что из-за дополнительной нагрузки на клиентский CPU вырос jitter — вариация задержки, которая как раз и чинилась на сервере.

Ниже график по 75-му перцентилю аудио-jitter.

Когда CPU загружен, кодек или сетевой стек могут не справляться с равномерной работой и генерировать дополнительную задержку.
Поэтому в комплект к шумодаву обязательно нужен back pressure CPU. Например, когда у телефона садится батарейка, он резко начинает её экономить и зажимает нагрузку на CPU. В результате растут jitter и задержка — и падает качество всего звонка, а не отдельно шумоподавления. Шумодав в этот момент надо просто выключить.
На вебе клиентский шумодав не сделать, а убирать шум мы всё равно хотим. Поэтому для пользователей браузеров пайплайн звонка выглядит по-другому: вся основная обработка переносится с клиента на сервер (это верно для групповых звонков, в p2p никакого сервера нет).

Медиана серверной passtrough latency = 60 мс, 99-й перцентиль — 500.
Где мы относительно конкурентов
Итак, столько всего наворотили, что надо свериться с рынком: не получилась ли задержка из-за аудиомикса и двойного jitter buffer больше всех, не потеряли ли в качестве из-за ускорения и обработки.
Для этого нужна методология измерения и задержек, и качества.
Как измерить качество
Для оценки качества проведём сигнал через весь пайплайн и сеть — и каким-то образом оценим или сравним с оригиналом то, что получится на выходе.
MOS (mean opinion score) — стандартная метрика в VOIP, показывает среднюю субъективную оценку качества, обычно по шкале от 1 (плохо) до 5 (отлично). То есть если попросить 100 пользователей оценить качество звонка по пятибалльной шкале и взять среднее этих оценок, то получится MOS.
Но есть и стандартизованные алгоритмические способы для вычисления MOS в области телекоммуникации. Например, есть POLQA и PESQ (Perceptual Evaluation of Speech Quality), которые некоторым образом моделирует субъективное восприятие.

Кроме того, как и везде, в метриках оценки качества звонка не прошли мимо использования deep learning. Метрика NISQA обучена на датасете из 14 000 образцов с использованием 97 000 MOS-рейтингов. NISQA считается на порядки быстрее POLQA и PESQ, но её важно использовать после VAD, так как она работает только на речевых сигналах.
В рамках этой статьи будем ссылаться на PESQ как индустриальный стандарт, но внутри ВКонтакте мы обычно пользуемся более классной NISQA.
Как измерить latency
Чтобы сравнить нашу задержку с тем, что получается у других сервисов видеоконференций, пришлось собрать вот такую схему:

Есть два физических телефона, которые звонят друг другу через разные VOIP-приложения. Они подключены к компьютеру, на котором вычисляется PESQ-метрика для полученного аудио относительно исходного.

Аудиосигнал с компьютера подаётся на микрофонный вход смартфона-источника при помощи прямого кабельного соединения (для электрического согласования уровней использовался делитель напряжения). Аудиосигнал с гарнитуры приёмника, также через кабель, подаётся на микрофонный вход звуковой карты компьютера.
Эта схема хоть и выглядит сложной, зато позволяет тестировать любые приложения — даже те, которые нельзя запустить вместе на одном компьютере. Но надо учесть, что физические устройства ввода-вывода добавляют свою неизвестную задержку и какие-то искажения вносит Wi-Fi. Поэтому, чтобы оценить базовую задержку, нужно проводить контрольное измерение без VOIP.

Если сервис работает на вебе или у него есть десктопное приложение и можно завести звонок для двух пользователей на одном компьютере, то всё становится намного проще — можно соединить вход-выход через драйвер. Virtual Audio Cable (VAC), как говорится на сайте, справляется с этой задачей десятилетиями.

Для тестирования используем отрывки с русской речью из базы ITU P.50 в оригинальном виде и с добавлением различных шумов (звука улицы, толпы, машины).
Ниже — сводная таблица замеров на мобильных клиентах:
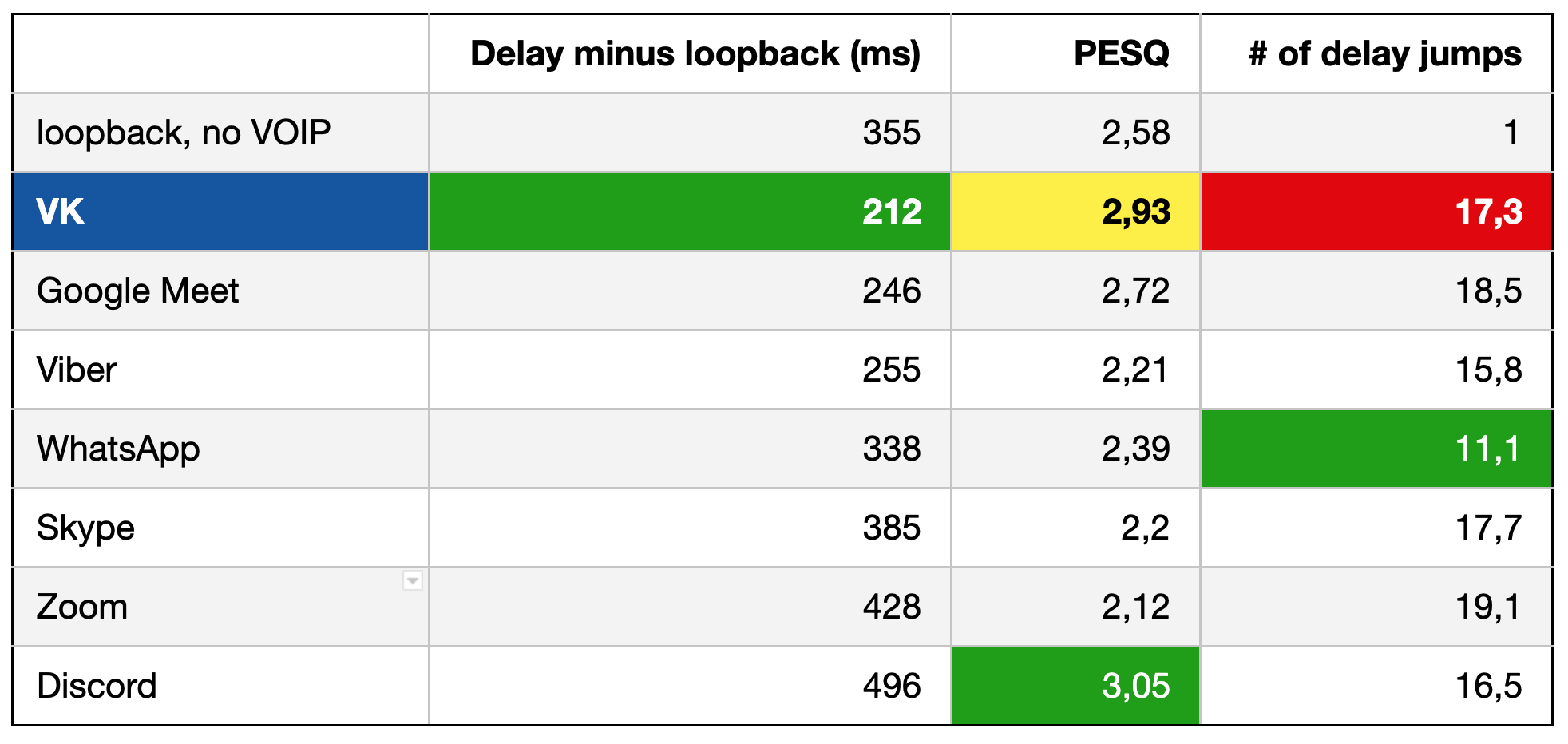
Получилась очень хорошая задержка на фоне остальных сервисов, хорошее значение метрики качества — проиграли только Discord.
Последний столбец показывает, сколько раз менялась задержка и приходилось ли что-то склеивать. Это совсем не обязательно вносит искажения, чаще всего склеивается тишина. То, что наше значение тут выше, значит, что jitter buffer стремится к минимальной задержке, но при этом чуть чаще что-то догоняет.
В групповых звонках с компьютера относительная картина по задержкам примерно такая же, как и для смартфонов.
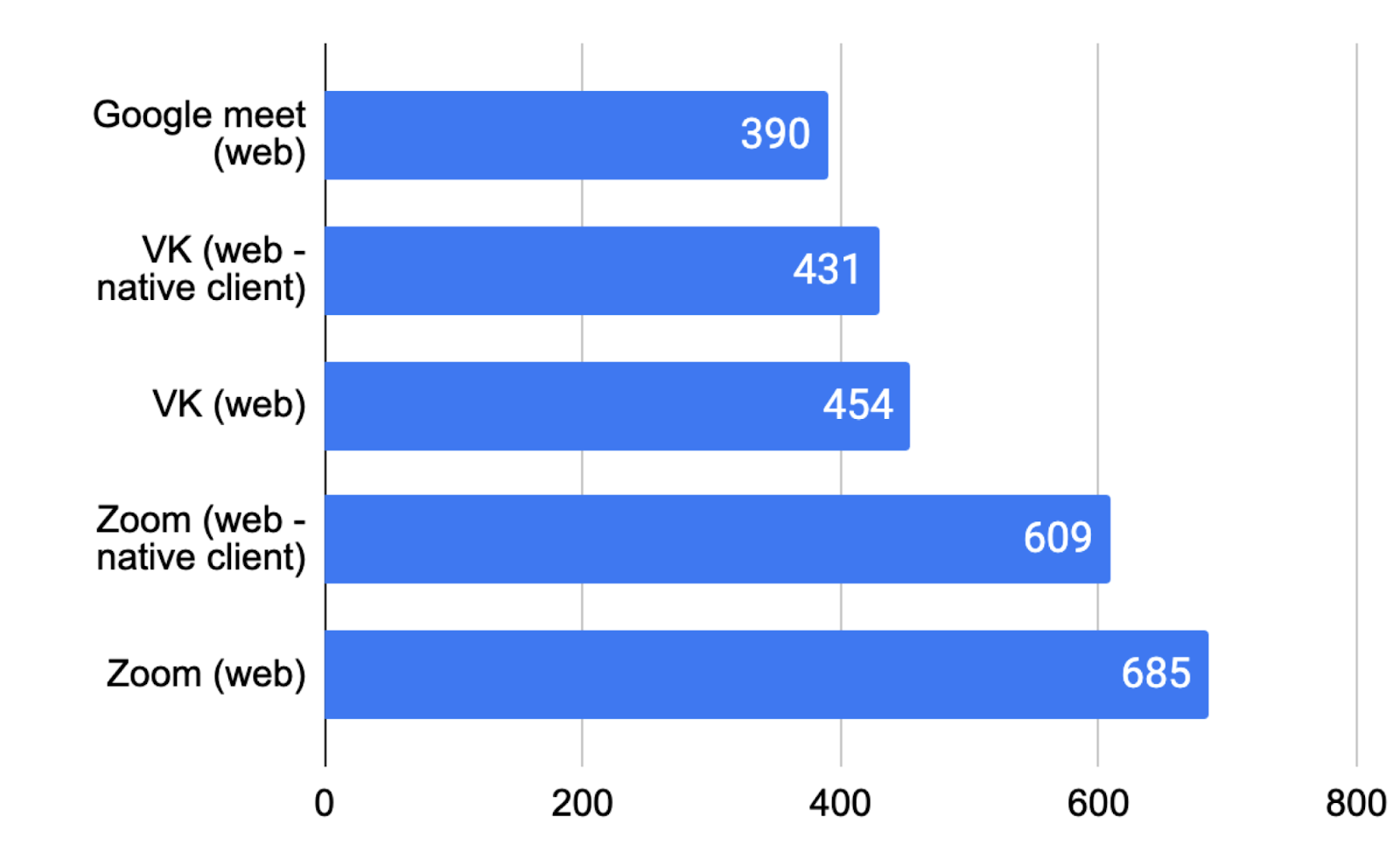
Нативный десктопный клиент (скачать и протестировать можно тут) ожидаемо впереди — в том числе потому что в нём, в отличие от веба, мы можем использовать кастомный пайплайн.
Теория vs практика
Вспомним теорию групповых топологий: MCU, то есть микширование в один поток на сервере, теоретически не ограничено по числу участников, но даёт большую задержку; SFU (сервер-ретранслятор) выдерживает максимум 50 участников, но задержка должна быть меньше.
Из chrome://webrtc-internals/ можно увидеть, что Google Meet микширует, то есть у него MCU. В статьях Zoom написано, что они этого не делают, у них SFU.
Внимание, вопрос: как Zoom с SFU делает конференции на 1 000 участников и почему задержка у них больше?
Дело в том, что Zoom использует такой трюк: они считают, что все сразу не говорят. И отправляют аудиопотоки только тех участников, которые что-то говорят или как-то шумят. Поэтому могут поддержать звонок на 1 000 участников, но по сути это вебинар с отдельными спикерами. Недостаток у этого решения понятный: чем больше участников говорят, тем выше битрейт и нагрузка. Это можно частично компенсировать хорошим VAD и шумоподавлением, которое у Zoom, одного из немногих, есть.
А задержка, очевидно, зависит не только от топологии, но и от многих других решений, раз Google Meet и ВКонтакте с миксом впереди по этому показателю.
Результаты и выводы
Наш пайплайн для аудио включает в себя: AEC и AGC, кастомный VAD на CatBoost и нейросетевой шумодав. Кодируем с помощью аудиокодека Opus, который реализует нам FEC и PLC для починки потери пакетов. Если аббревиатуры непонятны, go to beginning :)
По latency и качеству аудио по метрике PESQ мы на уровне рынка (в большой степени благодаря шумоподавлению), при этом наше решение экономит сеть и CPU пользователей.
Для групповых звонков мы выбрали MCU-топологию, про которую на основе измерений узнали, что микширование — это не всегда большие задержки и что вообще не всё решает топология. При этом серверная нагрузка, связанная с микшированием аудио, пренебрежимо мала (меньше 0,1% CPU на участника) — и мы можем сделать звонки на столько участников, на сколько хватит серверов. Тысячи людей в одном звонке — легко.
Stay tuned, в следующих статьях расскажем о работе с видео и архитектуре всего сервиса видеозвонков, ориентированной на неограниченное число участников.
Кстати, сегодня мы запустили десктопное нативное приложение для видеозвонков на 2 048 человек и анонсировали неограниченное количество участников в ближайший месяц — подробности о технологической функциональности есть в релизе.
Благодарности: собирать данные и готовить статью помогали Иван Григорьев, Виталий Шутов, Андрей Петухов.
