
У нас есть задача постоянно компилировать тонны плюсового кода. Наш проект — почти 200 000 cpp- и h-файлов, множество Git-веток, сотни разработчиков, десятки билд-агентов: его нельзя единожды скомпилировать, приходится перекомпилировать постоянно, параллельно, разные версии.
Наш проект необычный. Потому что эти 200 000 файлов — это результат автогенерации. Потому что пишем мы на PHP, а потом через KPHP все PHP-исходники превращаются в плюсы. Именно так разрабатывается бэкенд ВКонтакте.
Компилировать тысячи объектников долго. Локально это занимает много часов. Мы использовали distcc — но всё равно медленно. Мы даже пропатчили distcc для поддержки precompiled headers — но даже тогда медленно. И решили написать своё — чтоб стало, наконец, быстро.
В итоге мы написали замену distcc — компилятор nocc. Он не имеет никакого отношения к PHP и даже к KPHP, а просто предназначен для компиляции .cpp → .o в промышленных масштабах.
Это техническая статья про параллелизацию, демоны и специфику С++. Ссылки на GitHub и видео приложу в конце статьи.
Как вообще можно ускорить компиляцию С++
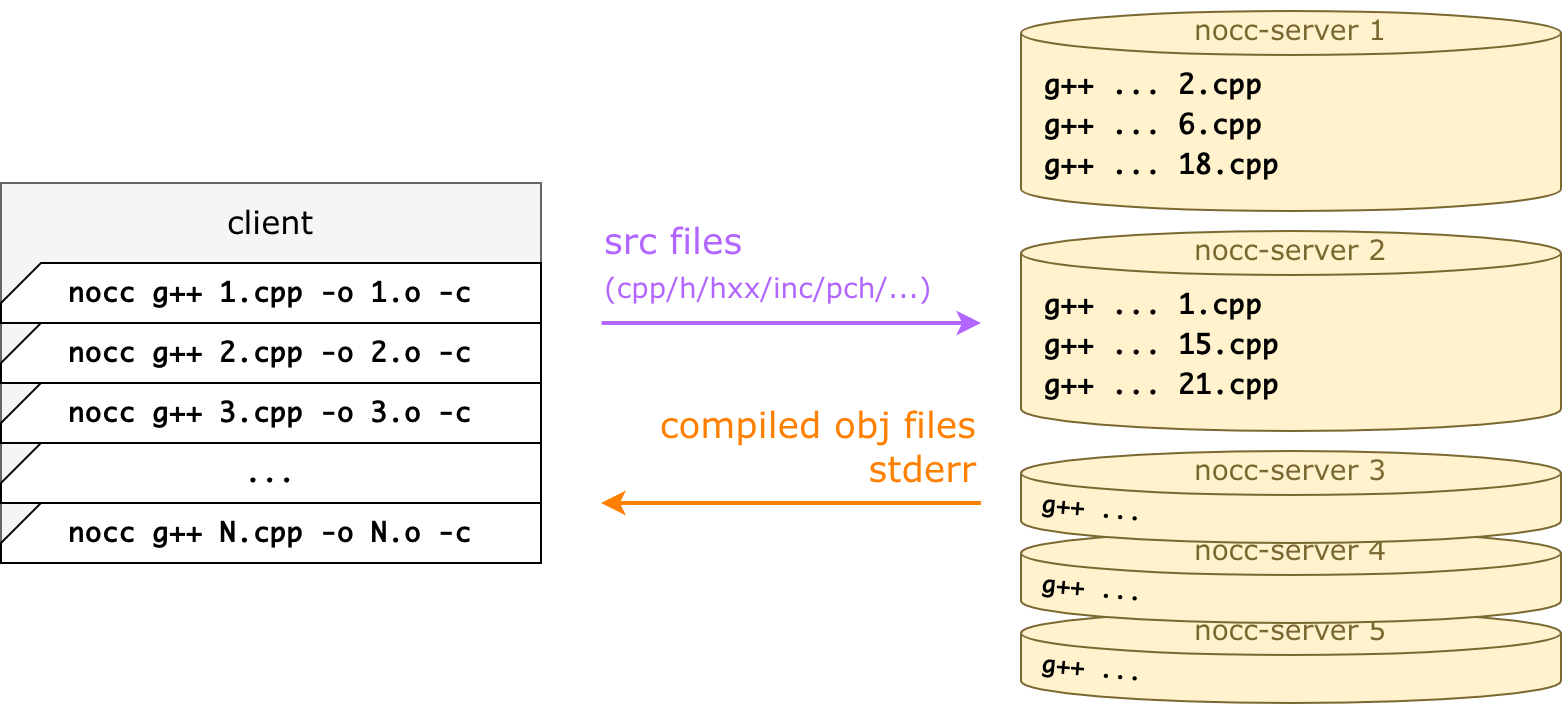
Основная идея у nocc и у distcc одинаковая: компиляция происходит не локально, а удалённо. То есть отдельно стоят серверы (компиляционные ноды, nocc-server), а клиент проксирует вызов g++/clang туда. Для этого клиенту вместо g++ 1.cpp ... достаточно вызвать nocc g++ 1.cpp ... — и файл будет скомпилирован не локально, а удалённо.
Скорость обеспечивается за счёт того, что серверов много (у нас 32 в бою, например). Получается, если локально можно было запускать, к примеру, make -j40, то теперь можно make -j400, и nocc-клиент равномерно размажет это по серверам.
То есть nocc — это такая тонкая прослойка, которая умеет загружать файлы и проксировать командную строку. А ещё это очень умный кеш, чтобы не загружать один и тот же файл заново. И даже не компилировать повторно.
Запуск nocc прозрачен для клиента
С точки зрения вызова, билд-система должна уметь всего лишь одну простую штуку: подставлять произвольную строчку перед плюсовым компилятором, чтобы получилось nocc g++ ....
Это можно сделать и в make, и в CMake, и в Ninja. Например, для CMake это выглядит так:
cmake -DCMAKE_CXX_COMPILER_LAUNCHER=/path/to/nocc ..И всё, nocc-клиент будет отсылать .cpp на серваки.
Если командная строка невалидна или её нельзя выполнить удалённо, nocc просто исполняет её локально, и всё. Например, форсирует локальное исполнение без изменения опций. Например, линковка происходит локально. Или -march=native происходит локально. Если сервак недоступен, то опять-таки фоллбечимся. Поэтому вызов nocc безопасен всегда.
Клиентский nocc-процесс завершается с тем же exitCode / stdout / stderr, что и удалённый g++, поэтому вывод консоли останется без изменений.
Что происходит при `nocc g++ 1.cpp`
Пусть есть 1.cpp:
#include "1.h"
int square(int a) {
return a * a;
}И простой 1.h:
int square(int a);Вот что происходит при запуске nocc g++ 1.cpp -o 1.o -c:
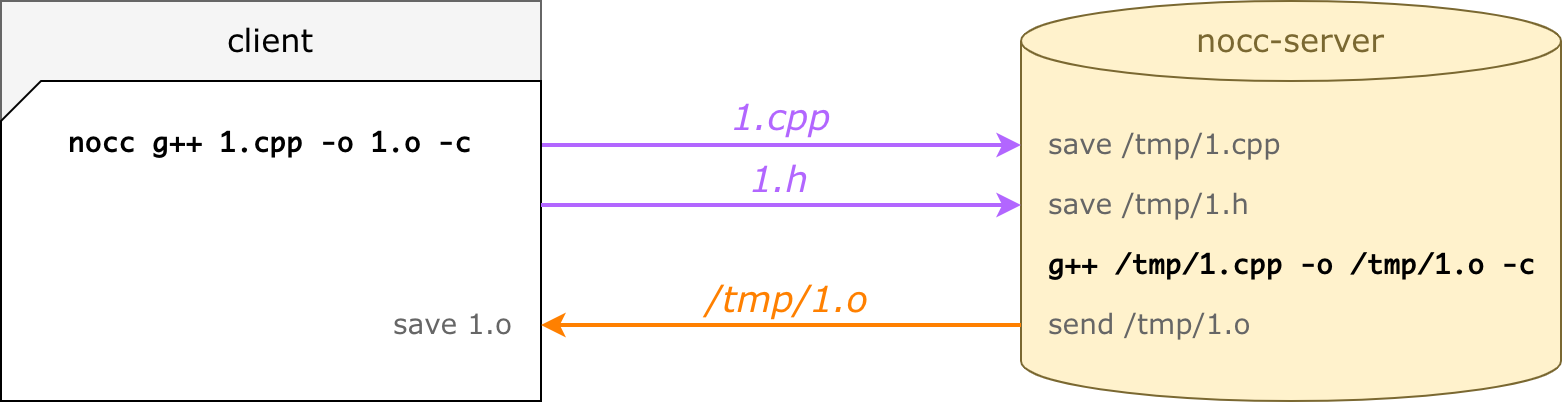
nocc парсит командную строку: входной файл, пути к инклудам, cxx-флаги и пр.;
для входного файла (1.cpp) nocc находит все зависимости, сканируя все
#includeрекурсивно (в примере это просто файл 1.h);nocc загружает файлы на выбранный сервер и ждёт;
nocc-server выполняет ту же командную строку (те же cxx-флаги, только пути подменены);
nocc-server пушит 1.o обратно;
nocc сохраняет 1.o — будто бы сделанный локально.
В реальности мы ставим много серверов для компиляции
На клиентской стороне запускается куча nocc-процессов одновременно. Каждый запуск — один .cpp → .o вызов, прозрачно для билд-системы. Он компилирует файл удалённо и умирает, ведь nocc это просто тонкая прослойка к ремоуту.
Для каждого cpp выбирается удалённый сервер, вычисляются все зависимости, недостающие загружаются, и сервер отправляет обратно готовый объектник. Это происходит параллельно для всех клиентов.
Для большей производительности все коннекты на самом деле держит один nocc-daemon:
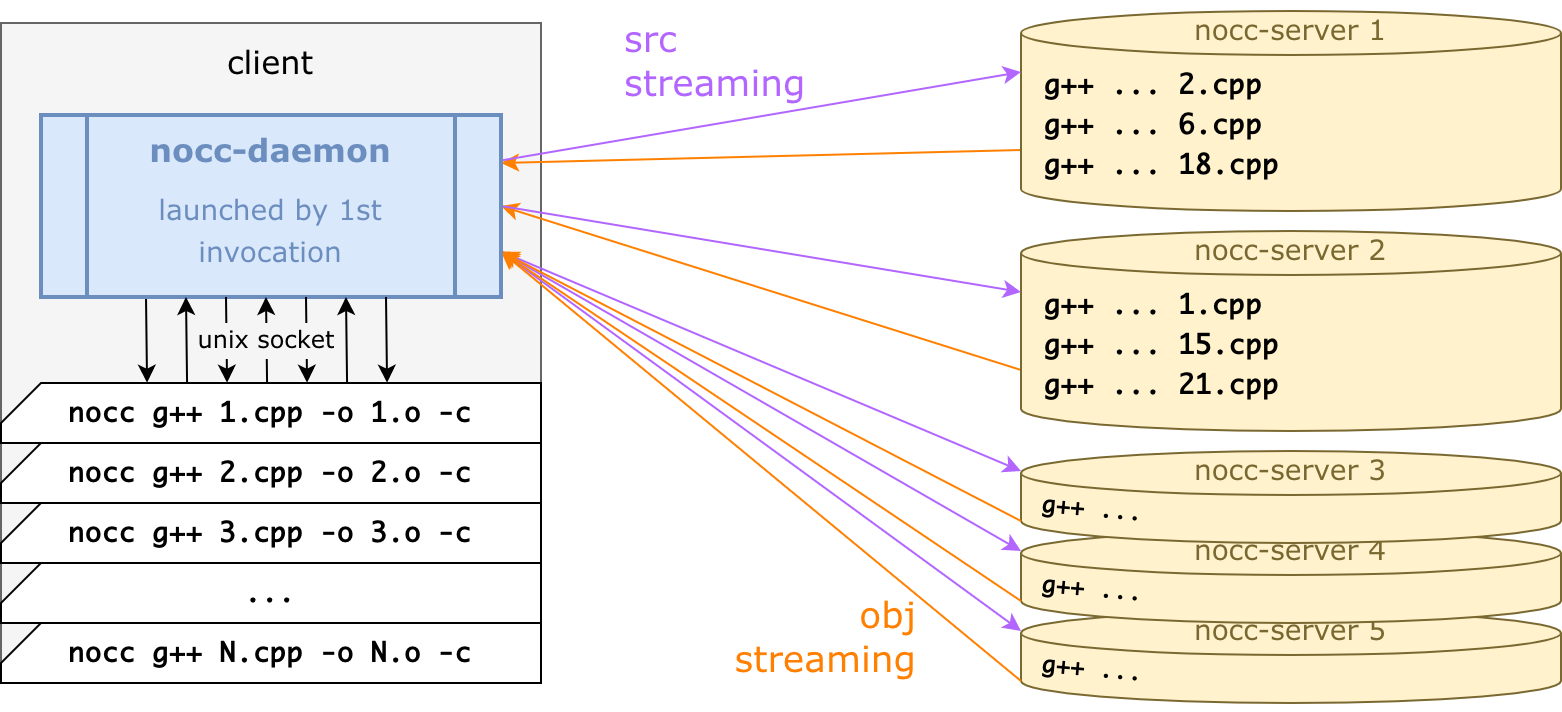
nocc-демон написан на Go — а nocc очень лёгкая обёртка C++ с единственной целью: передать командную строку в демон, дождаться ответа и умереть.
Получается, итоговая схема работы такая:
Самый первый запуск nocc стартует nocc-демон в фоне: демон коннектится по gRPC к сервакам и в целом делает всю работу.
Каждый nocc-вызов отправляет
g++ ...в демон через Unix-сокет, демон ждёт объектник, сохраняет его, и nocc-процесс умирает.nocc-процессы стартуют и умирают: билд-система сама запускает их, не задумываясь об этом.
nocc-демон умирает через 15 секунд (эвристическая оценка того, что процесс компиляции завершился).
nocc — это очень умный распределённый кеш
Главная фишка на практике заключается в том, что второй, третий и последующие запуски быстрее, чем первый. Даже если почистить папку build, даже на другой машине, даже в другой папке.
Это всё благодаря удалённым кешам:
кеш исходников — nocc не загружает файл, если он уже был загружен;
кеш объектников — nocc не компилирует файл, если он уже был скомпилирован.
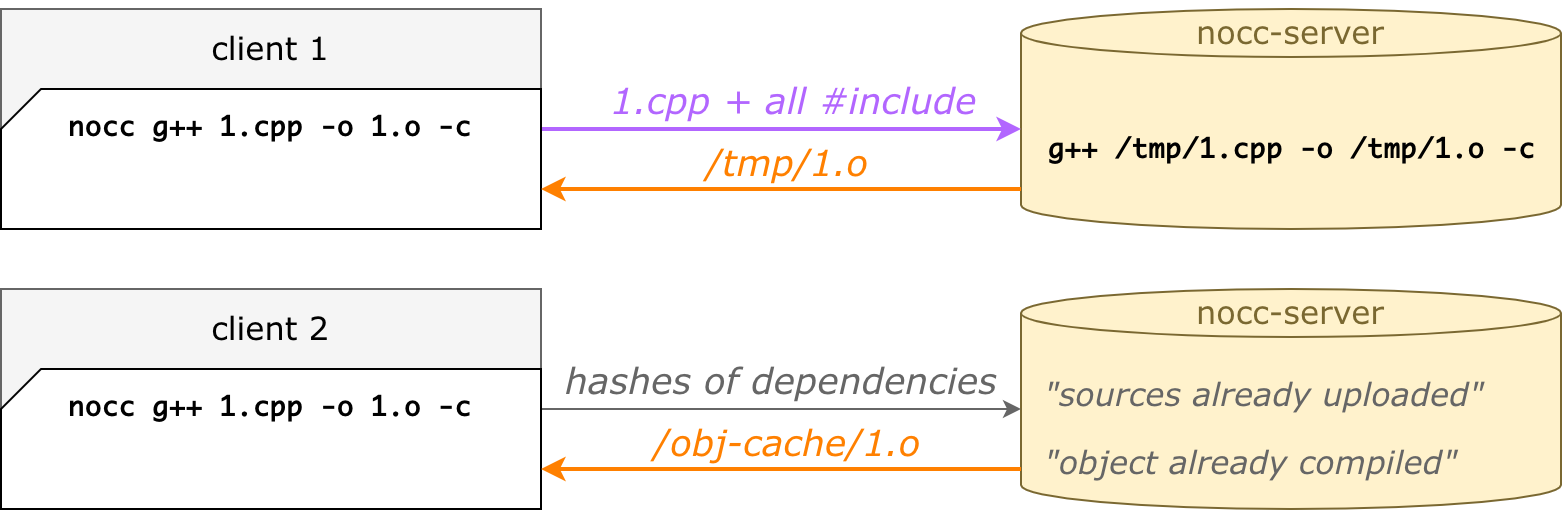
Такой подход значительно уменьшает времена сборок на различных билд-агентах, даже если локальные кеши дропнуты или билд-агент новый.
Более того, это прекрасно ложится на Git-разработку. Кто-то сбилдил свою ветку, а потом вмержился в мастер — а на сервере есть уже готовые объектники. И неважно, что у нас PHP, а С++ получается на выходе — это всё равно работает.
Кеш исходников работает на хешах от файлов. Когда nocc ищет #include рекурсивно, для всех файлов он считает SHA256. Изначально он отправляет серваку список хешей — а сервак отвечает, какие отсутствуют. Чаще всего при повторных компиляциях уже всё есть, и аплоадить ничего не нужно. Файлы вытесняются по LRU и не превышают заданный объём на диске.
Кеш объектников устроен похожим образом. Мы комбинируем хеши всех зависимостей, а также все cxx-опции — тоже получаем SHA256, которым индексируем объектник. Так что при повторной компиляции тех же исходников с теми же опциями объектник будет уже готов. Легко понять, что одному cpp-файлу могут соответствовать несколько объектников. Например, с дебаг-символами и без них — это разные опции командной строки, приводят к разным хешам, и оба объектника хранятся в объектном кеше, они оба готовы. Это не какой-то исключительный случай, так само получается, и получается хорошо.
Некоторые сведения из архитектуры и реализации nocc
Как nocc выбирает сервер для компиляции
Очень просто на самом деле: (хеш от имени файла) % N. Безо всякой там балансировки по нагрузке и так далее — просто хеш от basename, даже без папки.
Логика простая: на разных CI-машинах билд проекта идёт в разных tmp-папках, а мы хотим, чтобы одни и те же cpp (и их инклуды, что важно) попадали всегда на одни и те же ноды.
Даже если сам cpp изменился, вероятнее всего, большинство инклудов осталось прежними, зачем их лить заново. Даже если сервак недоступен, не нужно отправлять на другой, а лучше исполнить локально: сервак быстро поднимут, а мусор на других серваках не нужен.
Как происходит удалённая компиляция
Каждый демон имеет уникальный clientID, и все файлы, которые он заливает (cpp, h, inc, gch) складываются в отдельную папку (working dir), фактически зеркалируя файловую структуру клиента. Всё что нужно — это при запуске g++ подменить пути:

Когда файлы зависят от системных хедеров (типа <iostream>), они тоже проверяются, но загружаются только при различиях. Одинаковые системные файлы можно не загружать, #include <iostream> на сервере отработает так же.
Напомню, что на серваке есть кеш исходников. Те зависимости, которые уже загружались, берутся из кеша: просто делается хардлинка в тот же working dir. Это равносильно тому, что файл загружен, так что g++ его прекрасно увидит по нужному пути.
Кастомная парсилка
#include
Для каждого cpp нужно собрать рекурсивное дерево зависимостей.
Можно было бы сделать это через флаг g++ -M: он запускает только препроцессор (не компиляцию), а выдаёт список зависимостей (а не результат препроцессора).
Но в nocc встроен собственный парсер инклудов, который делает то же самое, только в разы быстрее. Он сам парсит cpp- и h-файлы, находит #include, резолвит их и продолжает рекурсивно. Он учитывает -I / -iquote / -isystem из командной строки, знает про системные пути и даже про #include_next. Быстрее это потому, что работает в демоне, и мы там можем всё кешировать: инклуды из разных cpp часто пересекаются, а при билде часто используются одни и те же пути в опциях. Получается, не нужно на каждый cpp вызывать препроцессор, и это ощутимо экономит время.
Конечно, в отличие от g++ -M, nocc ничего не делает с #ifndef и прочими. Поэтому он находит больше инклудов, чем нужно, и какие-то даже могут не существовать. Но это нормально, потому что потом при удалённой компиляции они будут просто недостижимы, и удалённый g++ невозмутимо отработает.
И кстати, параллельно с поиском инклудов считаются и хеши всех зависимостей, ведь контент файла мы уже загрузили.
Кастомная парсилка инклудов работает, только когда они могут быть статически зарезолвлены. Всякие там #include MACRO() не раскроешь, тут нужен честный препроцессор на клиентской стороне. Какой-нибудь boost активно это использует, поэтому с проектами на boost'е печаль. Есть опция, чтобы отключить кастомную парсилку. Отключение, конечно, замедляет, но в итоге всё равно получается выиграть у distcc по скорости.
Precompiled headers
nocc их поддерживает, причём по-хитрому. Когда клиентский код хочет сделать pch:
nocc g++ -x c++-header -o all-headers.h.gch all-headers.h… то nocc это перехватывает и делает all-headers.h.nocc-pch вместо .gch/.pch на клиенте — и потом компилирует на сервере в реальный .gch/.pch.

Две главных причины для такого:
Если делать gch локально, его всё равно нужно залить на все серваки. Но gch-файлы большие, и одновременный аплоад на N серверов упарывает сеть.
Если .gch-файлы (g++) могут работать после заливки, то .pch (clang) — уже нет. Clang не будет использовать файл, скомпилированный на другой машине, и хитрые опции типа
--relocatable-pchтут не помогут.
Файлик .nocc-pch — это просто текст с содержимым всех зависимостей. Клиентский nocc его делает быстро — значительно быстрее, чем клиентский g++ делает gch.
Когда работает кастомная парсилка инклудов, то, видя #include "all-headers.h", она находит all-headers.h.nocc-pch и загружает его как обычную зависимость. После загрузки сервер делает настоящий precompiled header и сохраняет all-headers.h и all-headers.h.gch до рестарта. А потом при использовании также делаются хардлинки в нужные места в working dir разных клиентов.
На клиенте gch не делается: если всё хорошо, он не нужен. Если же сеть недоступна и nocc пойдёт локально, компиляция отработает и без gch, ничего не сломается.
Что это дало и стоило ли всё это придумывать?
Да, стоило. Экономим много. VKCOM — гигантский монолит, и каждый разработчик постоянно хочет пересобирать свою версию.
Я говорил, что мы раньше использовали distcc. Он работает совсем по-другому, вообще не похоже на nocc, но это тоже удалённая компиляция. Разработчики distcc пишут, что есть pump mode, который делает немножко похоже, но нам не удалось заставить его работать. Возможно, на синтетических тестах он работает, а на реальных объёмах нет. Именно поэтому ещё три года назад мы пропатчили distcc, сделав ему поддержку pch-заголовков.
Поэтому будем сравнивать: оригинальный distcc, наш патченный distcc, первый nocc-запуск и последующие запуски nocc (в чистой клиентской папке).
Оригинальный distcc | 10077,2 с. |
Патченный distcc + pch | 660,9 с. |
nocc, 1-й запуск | 398,2 с. |
nocc, 2-й, 3-й и другие запуски | 72,6 с. |
Практически все наши кейсы соответствуют последней строчке, так как серваки запущены всегда, и чаще всего нам нужно докомпилировать небольшие изменения. То есть в большинстве случае имеем ускорение относительно оригинального distcc почти в 150 раз! И даже в менее экстремальном случае экономим минимум половину времени.
А ещё — то, что уже говорили:
скорость не зависит от build-агента;
быстрая пересборка при переключении веток;
быстрая пересборка мастера после мержа.
Обращу внимание, что это замеры лишь компиляции кучи .cpp → .o. Линковка сюда не входит. Так же, как и не входит другая локальная работа, которую nocc не ускоряет.
Скорее всего, в вашем случае профит будет не такой большой, но всё-таки будет. Например, если скомпилировать из исходников clang-компилятор через CMake, получаем ускорение только в 1,5 раза относительно distcc на полном цикле. Почему так мало? Потому что процесс выглядит как «быстрая компиляция, долгая линковка, быстрая компиляция, долгая линковка». Если вычесть время линковки, то ускорение будет, как и ожидается, очень приличным. Но там линковка занимает почти всё время. У KPHP-сборки просто более высокая степень параллелизма, без промежуточных этапов, так уж мы устроены.
Выводы
Да какие особо выводы? Хорошая, рабочая штука. Быстрая, потому что демон, потому что #include ищем без препроцессора. По факту, это очень умный remote cache с уклоном в С++. Нам экономит очень много вычислительных ресурсов и времени на сборку. Webpack собирает js-ки в 10 раз дольше, чем KPHP + nocc — миллионы строк кода.
Если вы используете distcc, попробуйте nocc. Вероятно, заработает, если нет макросов внутри инклудов. Кто хочет, почитайте обо всём на GitHub. И звёздочку поставьте :)
Кстати, на прошлом HighLoad++ я выступал с докладом, где рассказывал про всё это. Посмотреть его можно по ссылке ниже.
Полезные ресурсы
