

Привет, Хабр! Я Игорь Латкин, архитектор в KTS. Мы занимаемся различными цифровыми продуктами для бизнеса, специализируемся на HRTech, EdTech и DevOps. Также у нас есть несколько собственных продуктов, и один из них тесно связан с очередями сообщений. Об этом интересном решении я хочу сегодня рассказать. Эта статья — конспект моего диалога с архитектором Tarantool Монсом Андерсоном. Посмотреть видео можно в записи. Бонусом в конце — ответы на вопросы зрителей.
Наш продукт и его связь с очередями
SmartBot — это конструктор ботов для социальных сетей и различных мессенджеров. Его история началась в 2017, когда к KTS приходили заказчики и просили решить разные бизнес-задачи на основе ботов в Telegram, WhatsApp или на какой-то другой площадке. Нередко такие боты были связаны с машинным обучением, то есть нужно было по-умному обрабатывать сообщения пользователей. Поэтому у нас родилась мысль: почему бы нам не сделать SaaS, чтобы пользователи могли сами себе собрать бота и сразу запустить. То есть, не прибегая к программированию решить свои бизнес-потребности. Так и появился SmartBot, а в будущем — новая версия Smartbot Pro.
На самом деле это огромное решение, которое постоянно дополняется. Можно сказать, что это LowCode инструмент: внутри есть собственный язык Smart Query, который позволяет произвольно обрабатывать события. Ещё внутри есть рассылки, интеграции с различными службами оплаты и внешними сервисами, а также омниканальность — то есть мы поддерживаем сразу несколько социальных сетей и мессенджеров в едином сценарии.

Представим, что чат-бот — это маленькая коробочка, которая взаимодействует с соцсетями и мессенджерами. Мы запускаем один сервис на виртуальной машине в облаке, и он ходит в соцсеть, забирает оттуда сообщения, обрабатывает и отправляет ответы пользователю.
Но если копнуть глубже, то внутри этой маленький коробочки есть очень много всего: рассылки, интеграции, обработка фотографий и видео, статистика, машинное обучение, отправка писем и уведомлений. И все эти компоненты должны как-то взаимодействовать с внешним миром и между собой. Например, мы должны начинать задачу обработки видео, чтобы сформировать картинку предпросмотра и отправить её в чат. Очевидный путь, по которому можно выстроить это взаимодействие — очереди.
Почему именно очереди
Очереди позволяют сделать систему в некоторой степени отказоустойчивой. Допустим, мы из одного сервиса пытаемся обратиться к другому, и можем сделать это по HTTP, либо по GRPC, не важно. Во время этой коммуникации многое может пойти не так: оборвётся сеть, будет недоступен сервис. А очередь позволит хранить обращения серверов и последовательно их обрабатывать. Рассмотрим пример. Допустим, есть три сервиса: Incoming Messages, Message Processing и Reply worker:

Incoming messages — сервис, который каким угодно образом вытаскивает сообщения из социальной сети и складывает их в очередь. Другой сервис — Message Processing — занимается их обработкой, движением пользователя по сценарию, взаимодействию с внешними и внутренними системами. Так у нас появляется возможность масштабирования: мы можем, независимо от скорости получения сообщений от социальной сети, увеличить количество реплик, например, обработчиков, и обрабатывать сообщения быстрее, чтобы снизить нагрузку на сервис. При этом мы не зависим от соцсети, и если получили сообщение, то рано или поздно его обработаем. Также у нас появляется возможность повторных попыток и применения любой другой логики сверху.
То же самое верно и наоборот: с помощью очереди можно создать reply worker, который будет контролировать RPS к социальной сети — насколько много сообщений в секунду мы отправляем. Это также можно сделать через очередь. И рассылка в эту схему тоже прекрасно ложится. Мы отправляем социальной сети все наши чанки, кладём в очередь и потихоньку её разгребаем, отправляя рассылку за адекватное время.
С машинным обучением всё тоже работает через очереди по понятной схеме:

Наш обработчик обращается к каким-то сторонним сервисам, в том числе ко внутреннему vectorizer, чья задача — векторизировать текст. Имея текст на естественном языке, мы получаем числовое представление этого предложения. Затем сравниваем с информацией в базе, чтобы понять, по какой ветви в дальнейшем будет двигаться пользователь: написал нам «привет», спросил «как дела» или «какая погода в Москве». Для этого нужно сопоставлять, что написал пользователь, с зашитым сценарием на этапе проектирования чат-бота.
Что нам было нужно от очереди
Мы выбрали семь функций, которые были нужны в нашем проекте:
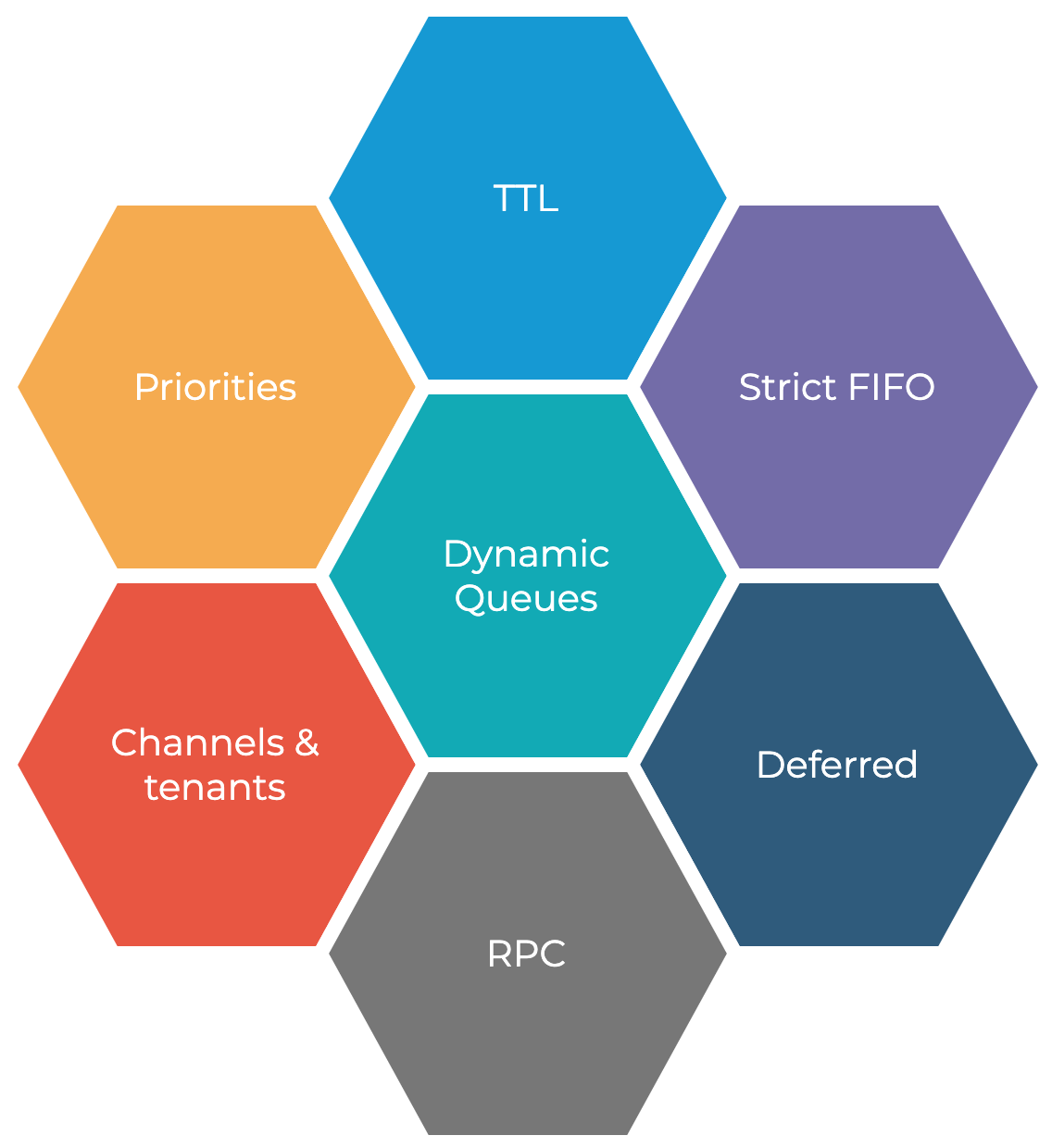
Динамические очереди, то есть создание очередей в динамике, прямо из кода. Этому требованию удовлетворяют практически все существующие брокеры сообщения, поэтому мы на этом останавливаться не будем.
TTL. Обрабатывать сообщение нужно за адекватное время, а если не успеваем, то удаляем его из очереди. Нам очень хотелось, чтобы TTL был либо для каждого сообщения, либо сразу для всей очереди. Забегая вперёд, скажу, что это несколько раз спасало во время недоступности нашего сервиса. Нам не очень хотелось, чтобы система «лежала» 5-10 минут без ответа, пользователь заспамил её, а потом она заспамила в ответ. Поэтому решили — пусть сообщения пропадут, пользователь в состоянии инициировать действие в чат-боте заново, например, написав сообщение, если он видел, что мы не отвечали.
Channels & Tenants. Нам хотелось иметь возможность устраивать подканалы внутри очередей. Они называются каналами или tube’ами, в зависимости от брокера.
Deferred. Отложенные сообщения нам тоже нужны непростые. Они тесно связаны со Strict User FIFO. В SmartBot есть шаг, который называется таймер. Он позволяет выполнить какое-то действие через определённое время, например, «отправить через минуту сообщение пользователю». Посмотрим на пример:

Допустим, мы знаем, что вебинар состоится в 17:00. Значит, мы хотим отправить сообщение всем пользователям ровно в 17 часов вечера. Это очевидное использование, но для нас очень важно, чтобы мы могли также отменять эти события по ID и User ID. Например, отменить все отложенные сообщения конкретного пользователя или проекта. Также, мы такую механику использовали в рассылках для распределения чанков по времени.
Чтобы было понятнее, о чём мы будем говорить дальше, рассмотрим состояния, в которых могут находиться наши сообщения (задачи в очереди):

Это идеальная схема, к которой мы хотели бы прийти. У нас есть некоторое состояние Ready, то есть задача может быть взята обработчиком на исполнение. После взятия она переходит в состояние Taken, а после успешной обработки может перейти в состояние Done и удалиться из очереди. Чтобы обеспечить отложенные события, кажется логичным использовать другое состояние — скажем, Waiting. И чтобы очередь сама автоматически переводила сообщение в состояние Ready. Возьмём пример:
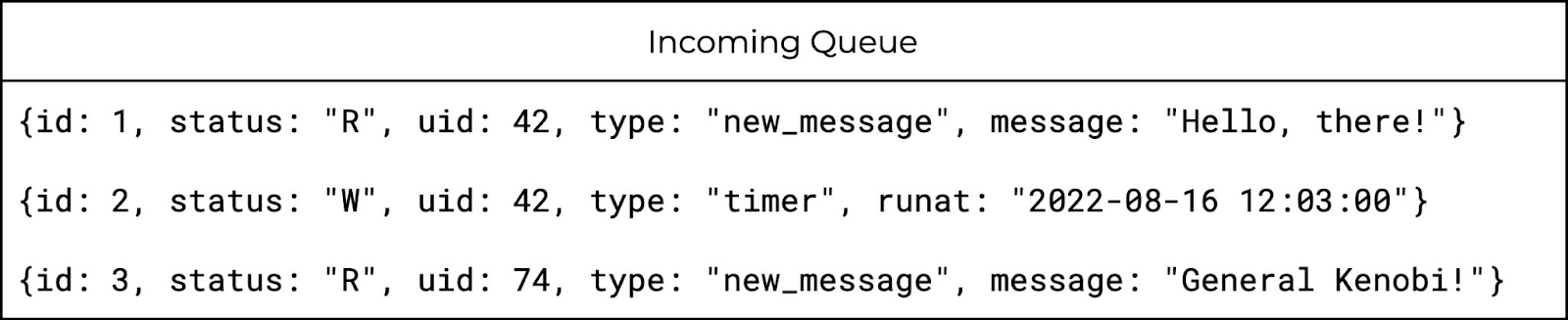
У нас есть три сообщения в очереди: два для одного пользователя, одно для другого. Одно событие находится в состоянии Ready, второе — в состоянии Waiting, третье — в состоянии Ready. В итоге, наши обработчики смогут взять два сообщения в состоянии Ready, и в какой-то момент второй элемент в очереди перейдёт в Ready и тоже будет обработан.
Strict User FIFO. Строгий FIFO есть почти в любом брокере, но нам нужен был именно прямой порядок по пользователям. Он вроде бы обеспечивается, если мы отсортируем наше событие по ID, но на самом деле ситуация немного другая. Представим, что у нас есть шесть сообщений: четыре от одного пользователя и два от другого:
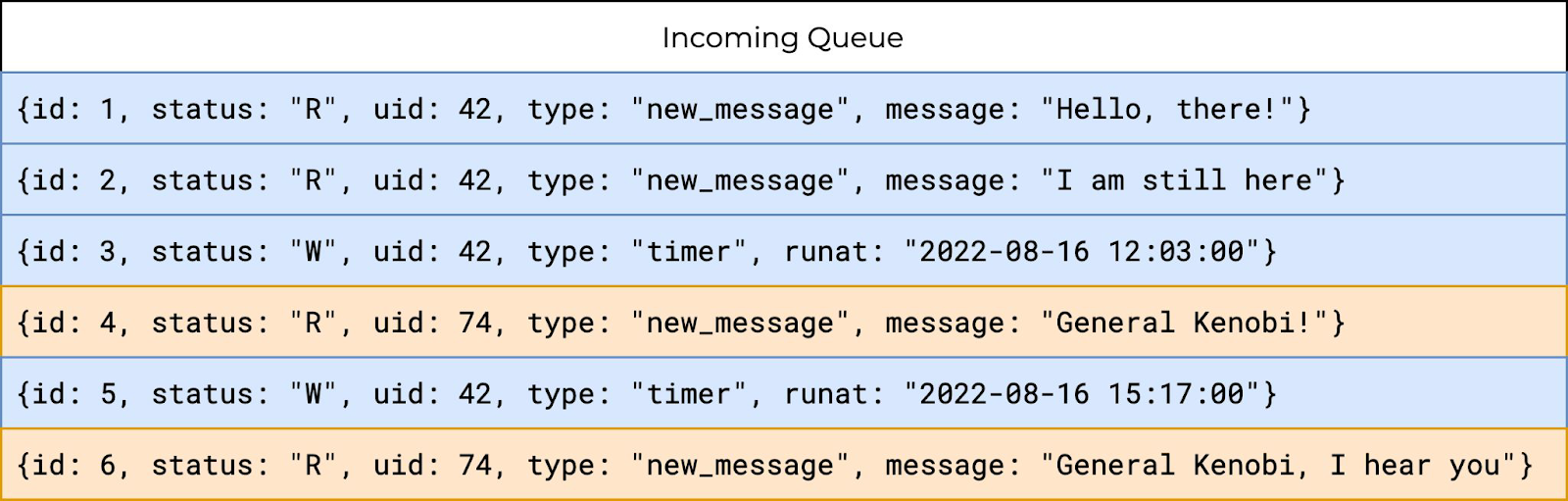
Три сообщения находятся в Ready, и теоретически все они могут быть взяты обработчиками на исполнение. Какой-то обработчик возьмёт синее сообщение, другой тоже синее, а третий — уже жёлтое. Но для нас это совершенно неприемлемо, потому что нужна блокировка по пользователю, чтобы обработчик не брал сообщение пользователя, который уже обрабатывается. То есть нужен строгий порядок по User ID как между обработчиками, так и между их подпрограммами:
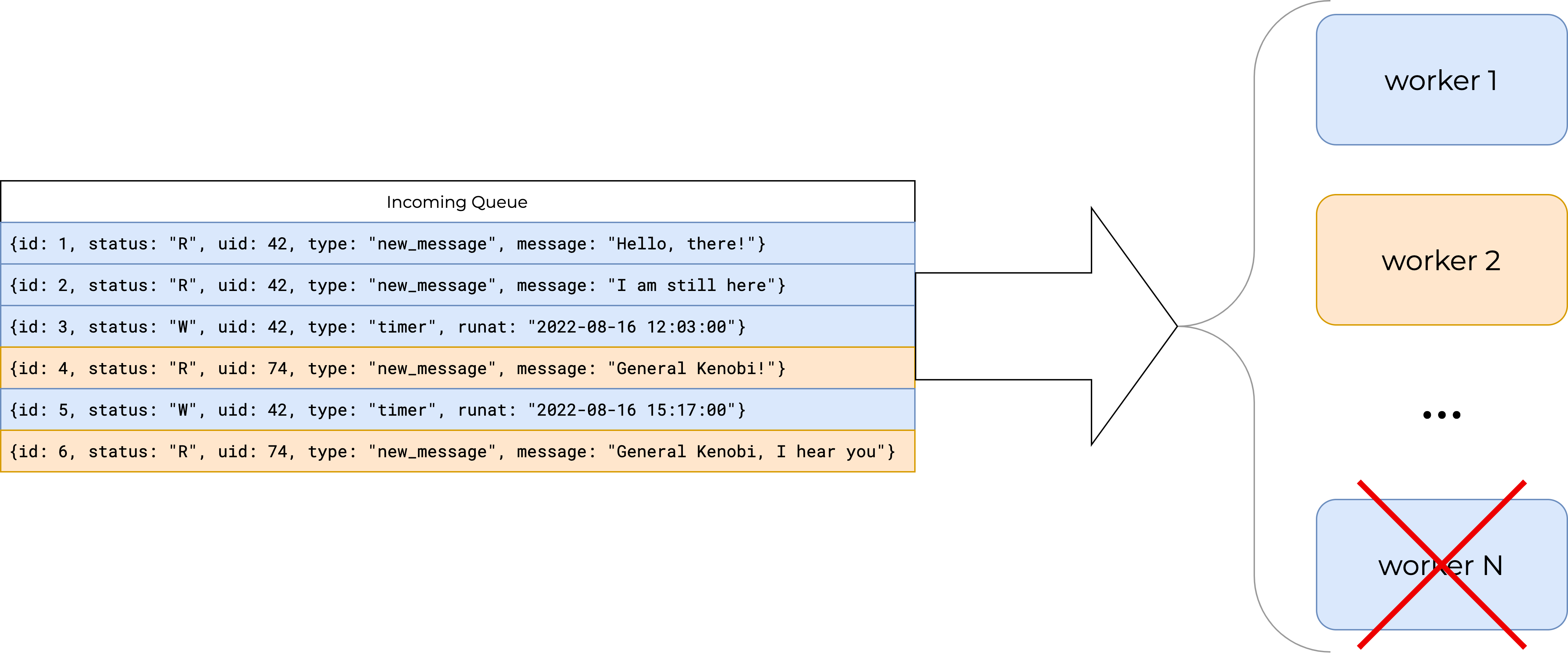
В каждом обработчике порядок также не просто синхронный — он внутри запускает ещё сотни корутин, чтобы быстрее обслуживать очереди и эффективнее использовать ресурсы сервера. Важно было сделать так, чтобы обработчики не задумывались, откуда они берут сообщение. То есть чтобы после взятия они были уверены, что сообщение можно обрабатывать, иначе зачем очередь его выдавала? Нужно, чтобы логика по выдаче задач лежала целиком на очереди.
RPC и Priorities. Вернёмся к нашей модели машинного обучения, к Vectorizer:
У нас есть два источника, откуда Vectorizer получает задачи на работу. Во-первых, это Message Processing. Нам нужно прямо сейчас обработать и векторизовать какое-то предложение, которое написал пользователь, потому что ему надо ответить. Но также у нас есть периодичная кластеризация, при которой мы берём большие объёмы текста и в фоновом режиме обучаем модель заново, настраивая её веса. Короче, делаем ML-магию внутри Vectorizer.
Нам хотелось, чтобы это выглядело очень просто. Чтобы мы брали, отправляли, выполняли какой-то вызов (скажем,
rpc.send()) и получали в ответ уже сами векторы. 
Но что в этой ситуации у нас происходит под капотом? Существует, скажем так, две очереди:

Одна из них создаётся динамически каждый раз для каждого обработчика, это так называемая очередь ответов. И есть очередь на исполнение Vectorizer, в которую с различным приоритетом отправляют задачи два процесса — message processing и text clustering. Vectorizer их обрабатывает и в ответную очередь отправляет ответ — сами числа и числовые векторы.
Приоритеты здесь тоже очень важны, поскольку message processing — это то, что исполняется прямо сейчас. И нам очень важно получить ответ быстрее. Если у нас есть выбор между двумя задачами — обработать текущего пользователя или кластеризацию, — то мы лучше выберем обработку пользователя, и пускай кластеризация подождёт в своей очереди с пониженным приоритетом.
Какие инструменты для реализации мы рассматривали
Сначала это были RabbitMQ, Kafka и NSQ. По ним мы составили табличку:

С последними двумя строками всё понятно, их рассматривать не будем. Приоритеты есть в RabbitMQ, во всех остальных нужно делать какие-то свои решения поверх очереди, нас это не устраивало. Lookup, удаление задач по ID — это все-таки слишком сложное требование для брокера сообщений, потому что никто такого не умеет. С TTL ситуация получше: в RabbitMQ есть dead letter queue, которую можно легко реализовать. В Kafka можно настроить TTL по партициям. В NSQ просто нет TTL, или мы не поняли, как его там приготовить.
И две самые главные для нас функции: Deferred и Strict User FIFO. Они должны были работать в паре, то есть в одной очереди у нас должен был быть строгий порядок по
user_id, и в ней же мы должны уметь обрабатывать отложенные события. В Kafka отложенные события оказались совершенно недоступны. В RabbitMQ реализовать их можно, но не очень красиво и удобно — опять же, через dead letter queue.А вот strict user FIFO из коробки не мог обеспечить никто. Пришлось бы делать какое-то решение поверх очереди, настраивать синхронизацию между очередью и этим решением — в общем, всё было бы тяжело.
У нас в KTS есть отдел спецпроектов, в котором мы, в том числе, разрабатываем чат-ботов. У нас получилось найти решение проблемы Strict User FIFO, но с использованием RabbitMQ:

Есть плагин X-Consistent-Hash. Каждый обработчик поднимает свою собственную очередь, а x-consistent-hash exchange, хешируя идентификатор пользователя, назначает его в одну из очередей. Ни один обработчик не может получить задачи по пользователю, который обрабатывается другим обработчиком, потому что мы хешируем
user_id. Но здесь тоже есть свои подводные камни:- Тяжело всё это поддерживать. Нам нужно следить за столькими очередями, сколько у нас обработчиков, а их количество может расти. То есть, если мы вдруг не справляемся с нагрузкой, мы хотим добавить ещё обработчиков, и, как следствие, у нас увеличивается количество очередей.
- Если мощностей достаточно или слишком много, мы расходуем лишние ресурсы процессоров и памяти, а значит платим лишние деньги — давайте уменьшим количество обработчиков. Как это сделать автоматически? У нас есть, решение, но оно всё-таки ручное. Мы должны каким-то образом заставить Exchange перестать отправлять в эту очередь сообщения. Допустим, мы хотим обработчика N исключить из нашего балансировщика, поэтому должны перестать слать сообщения в эту очередь, начать хешировать на меньшее количество очередей, затем опустошить очередь и наконец удалить обработчика.
Всё это отпугивает, потому что хочется, чтобы очередь просто работала, без беспорядка и с отложенными сообщениями. Тогда мы стали смотреть в сторону Tarantool.
Немного о Tarantool
Вообще, Tarantool не брокер сообщений, и 10 лет назад в нём не было никаких очередей. Tarantool — это сервер приложений с БД на борту, платформа для in-memory вычислений. У него есть реляционная схема, которая похожа на таблицы, и поддержка различных вторичных индексов. Но при этом мы можем дописывать внутри Tarantool произвольную сложную логику на Lua, Rust или C.
На языке Lua 10 лет назад, была реализована первая библиотека очереди. С тех пор у неё появилось несколько реализаций с разными возможностями. Есть официальная базовая библиотека tarantool-queue, есть различные решения от сообщества, как, например, moonlibs/xqueue. И есть статья на Хабре, в которой рассказано, как с нуля сделать очередь на Tarantool под свои задачи. И действительно, сделать очередь на Tarantool — это максимум 500 строк, а может и меньше. Фактически вы немного меняете задачу своей базы данных и превращаете её в очередь.
Очередь на Tarantool
В первой реализации SmartBot мы использовали tarantool-queue. Но в ней тоже не было функции Strict User FIFO, поэтому мы стали искать другие решения. И зацепились за moonlibs/xqueue.

Она всего лишь берёт ваш space и навешивает на него дополнительную логику в виде методов: положить задачу в очередь, ack'нуть задачу в очереди, отпустить её и так далее. Всё, что мы привыкли делать с очередями, xqueue добавляет поверх обычных методов Tarantool.
Как это выглядит? Представим, что у нас есть space — аналог таблицы в реляционных базах данных. И мы хотим, чтобы у нас было какое-то количество полей:
- ID, чтобы идентифицировать каждую задачу;
- статус, в котором находится каждая задача;
- приоритеты;
- tube;
- kind — тип сообщения, чтобы мы могли отличать, например, сообщение пользователя от события таймера, и так далее.
Ещё у нас есть поля нашей предметной области — id проекта, канала, чата, пользователя. RPC делается банально: добавляем два поля — откуда пришло сообщение и в какую очередь нужно отправить ответ, и, data — сама полезная нагрузка.
Зачем нам нужны поля предметной области? Почему недостаточно просто ID задачи и дополнительных полей в data? Именно такая структура очереди, позволяет нам делать то, что ни одни из брокеров не умеет делать, из коробки: поиск и удаление задач по идентификатору, либо по какому-то другому полю и даже более сложным фильтрам. К примеру, мы хотим взять все задачи проекта, либо все задачи, у которых kind начинается на какой-то префикс. Всё это в Tarantool возможно благодаря вторичным индексам и хранимым процедурам.
У нас получился брокер очередей с базой данных на борту. Или даже, скорее, база данных с брокером. Мы пользуемся ею, в основном, как очередью, но и про базу не забываем: можем вытащить произвольную задачу «чтобы посмотреть», не меняя её статус в очереди.
Теперь для более наглядного пояснения вернёмся к диаграмме состояний. Напоминаю наше желаемое состояние:
В xqueue оно немного другое:
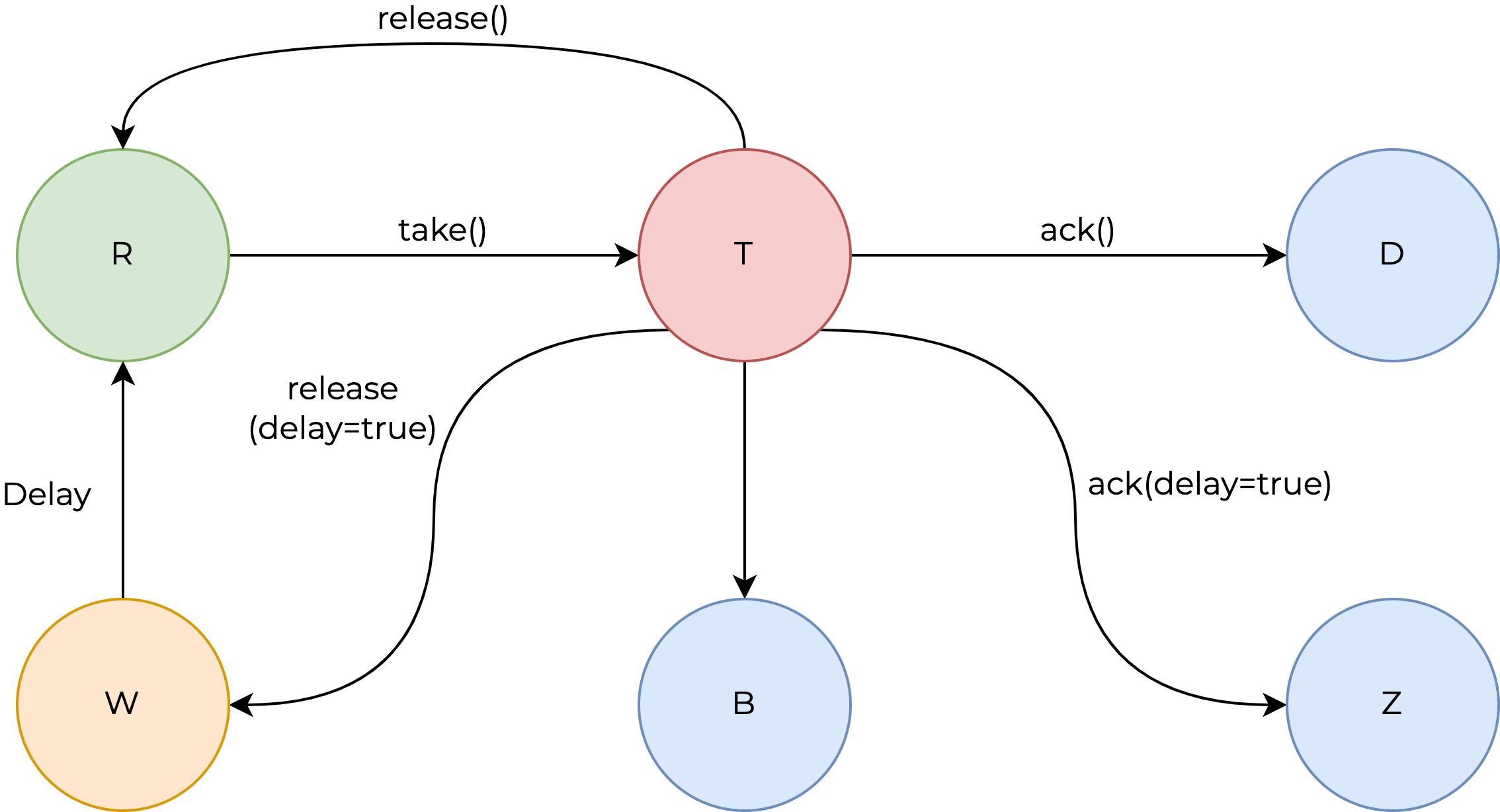
Появляются ещё два состояния:
- Buried — задача отложена на какой-то срок, может быть, навсегда, но сейчас она находится в очереди
- Zombie — задача, которую мы, вроде бы, завершили, но решили немного задержать в очереди.
На самом деле этими двумя состояниями мы не пользуемся.
Давайте посмотрим на примеры задач из очереди:
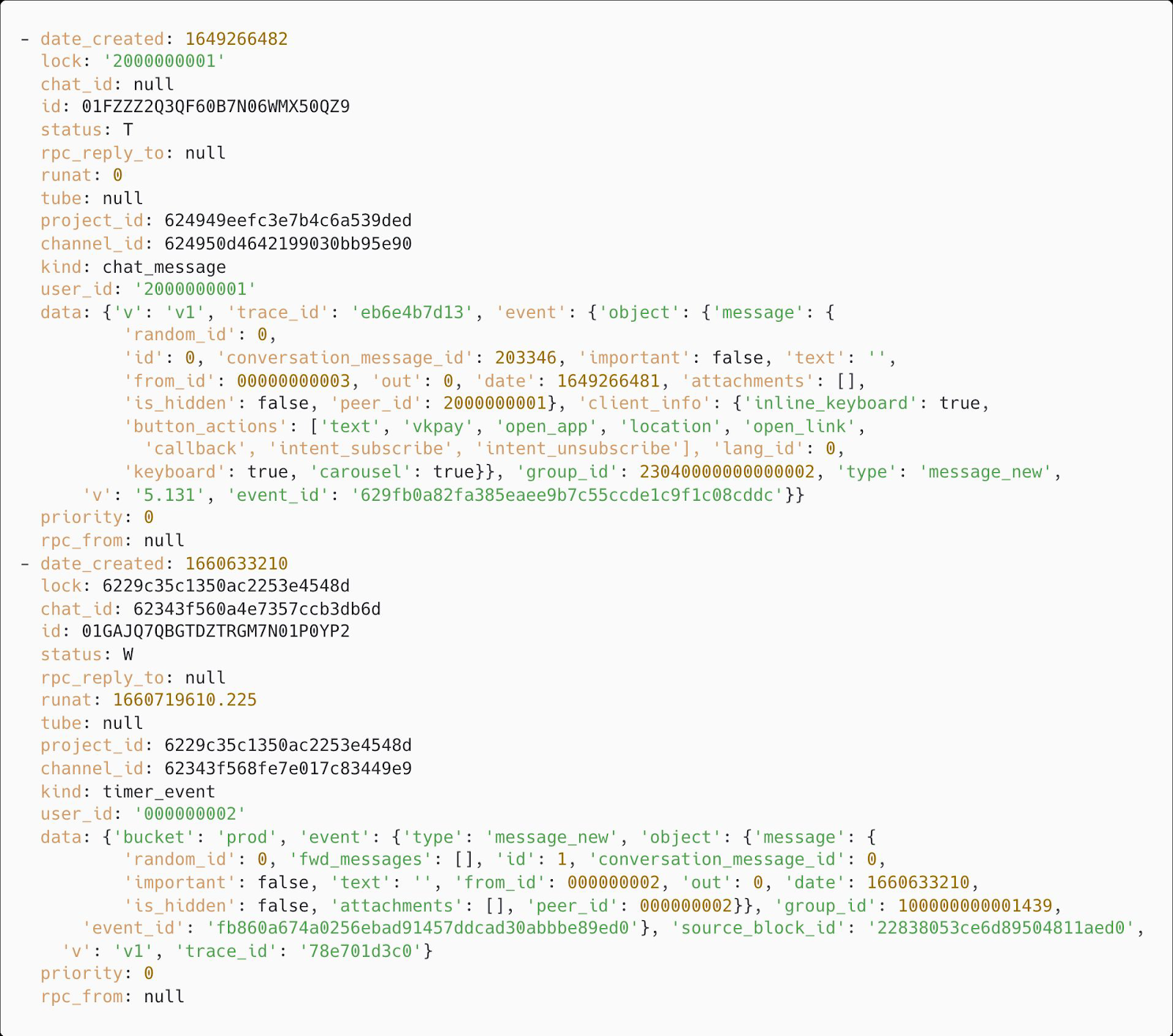
У нас есть идентификаторы тасков. Хоть они строковые, они сортируемые и упорядочены. Это позволяет нам обеспечивать строгий порядок просто сообщений в очереди. Мы использовали ULID в качестве идентификатора сообщений — он распределённый и подходит для разных узлов системы. При этом он лексикографический и сортируемый, то есть ULID, выпущенный позже, будет больше по значению, чем выпущенный ранее. Использовать время в нашей ситуации было нельзя, потому что две задачи, пришедшие в одну миллисекунду, получали бы один идентификатор. ULID тоже основан на времени, но позволяет решить проблему одного и того же момента времени
В целом нам даже удалось реализовать простой фреймворк поверх нашего брокера. SmartBot написан на Python, поэтому библиотека для работы с этой очередью также была написана на Python.

Разработчики SmartBot, просто пользуются готовыми обёртками, не задумываясь, Tarantool там внутри или не Tarantool. И просто работают, как бы они работали с теми же RabbitMQ или Kafka.
Вернёмся к нашей таблице сравнений и добавим туда Tarantool:
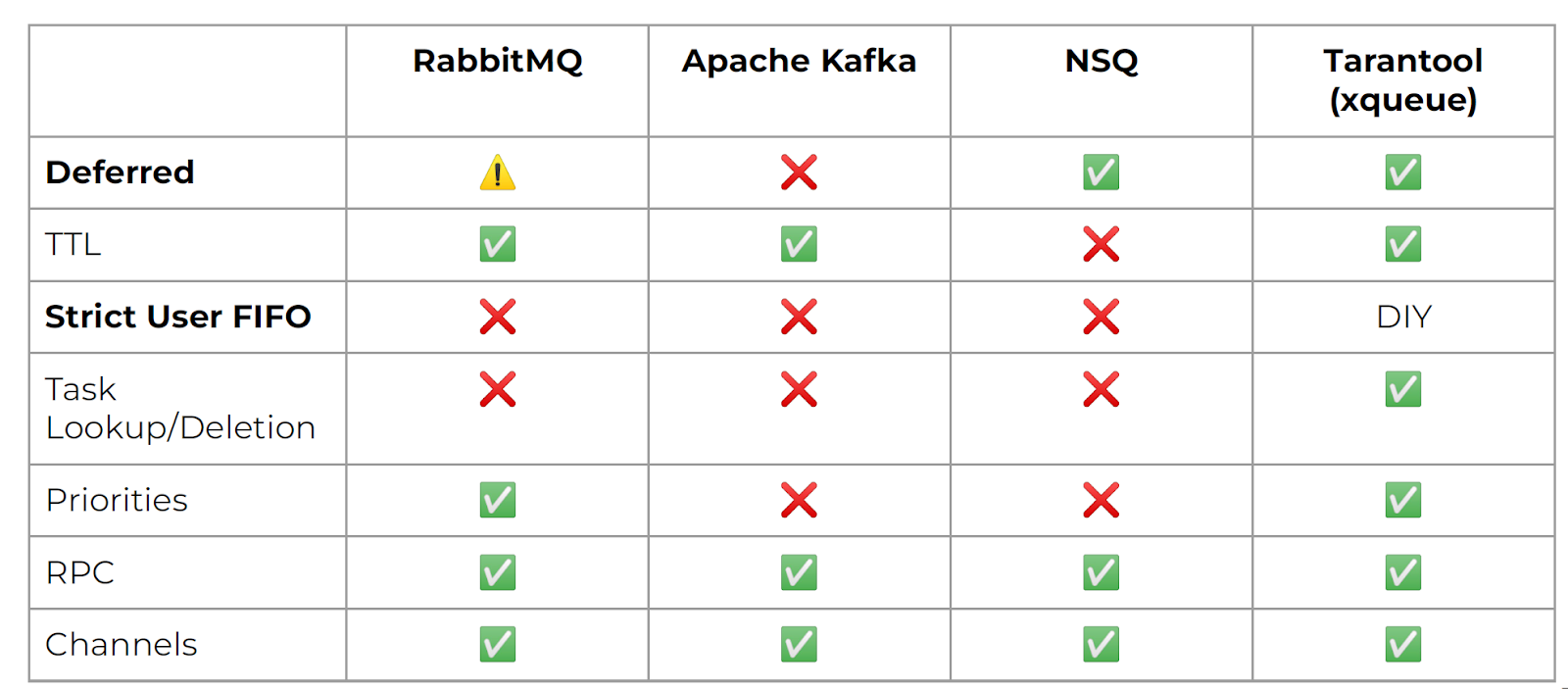
Сам по себе он, конечно, ничего не умеет. А вот его готовая библиотека, или 500 строк на Lua, дают буквально всё, что нужно. Можно брать и пользоваться.
Strict User FIFO у нас из коробки не появился, в xqueue его нет. Чтобы он заработал, мы внесли 200 с небольшим изменений и дополнений. Оказалось, что достаточно добавить всего один статус — мы назвали его Locked:

Когда задача поступает в очередь, выполняется простой поиск по индексу, в нашем случае — по
user_id: есть ли в очереди задача, пользователь которой уже обрабатывается. Если есть, мы присваиваем сообщению статус Locked, а если нет, то присваиваем Ready. Как перевести из статуса Locked в Ready? Во время ack мы просто проверяем, есть ли заблокированные задачи, и разблокируем их. Звучит просто, но в другом брокере такое сделать не получилось бы, а в Tarantool удалось легко.Для нас важно было поместить всю функциональность в очередь потому, что мы хотели сделать «не слишком умные» обработчики. Чтобы они просто могли взять задачу правильным образом, а все трудные вопросы по распределению задач между ними, по управлению подочередями и отложенными событиями решал брокер.
Что в итоге получилось
В нашем продукте есть множество микросервисов. Все они хотят взаимодействовать между собой, и каждому нужны какие-то функции в очереди. Благодаря Tarantool у нас получилось создать комбайн. Мы приходим в него и говорим: «Создай мне очередь с TTL, блокировкой по пользователям и deferred-сообщения» — очередь готова. Хотим добавить ещё RPC, включаем эту функцию — и всё работает.
То есть получилась в некотором роде универсальная система очередей — по крайней мере, универсальная для нас. Разработчики проекта не задумываются, куда писать сообщения и в каком порядке они придут. Они заказывают нужную очередь и пользуются. А брокер выступает в качестве чёрного ящика. Вся ответственность за правильный порядок выполнения задач лежит целиком на очереди.
Если бы мне сейчас пришлось делать всё с нуля, я выбирал бы решение в зависимости от потребностей. Для проекта с последовательными сообщения хватило бы RabbitMQ или Kafka. Но как только мы хотим от очереди большего — залезть в историю, добавить логику, Deferred или Strict User FIFO, — привычные решения уже не подходят. Сложность системы будет возрастать экспоненциально, а функциональности ты не добавляешь. Просто решаешь какие-то недостатки выбранного решения, а пользователь не получает новых возможностей.
Поэтому в похожем проекте, где нужна большая настраиваемость, я пошёл бы по тому же самому пути. Либо комбинировал бы: можно входящий поток сообщений просто складывать в Kafka для большей пропускной способности и затем перекладывать их в Tarantool для сложной обработки. Возможно, это дало бы даже ещё большую отказоустойчивость.
Подробнее про Smartbot Pro можно посмотреть тут.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
