Comments 330
С нетерпением жду выхода C++2 от Herb Sutter
https://github.com/hsutter/cppfront
который сделает C++ в десятки раз проще и безопаснее.
Зашел в репозиторий, и сразу же на втором скрине вижу в десятки раз более простой и безопасный код:
$cat hello.cpp2
// left-to-right, order-independent,
// context-free, "import std;" default
main: () -> int = {
hello("world\n");
}
hello: (msg: _) =
std::cout << "hello " << msg;Вот он, прорыв! Наконец-то кто-то, давно пишущий на плюсах, знающий язык вдоль и поперёк, решил избавить миллионы программистов от их ежедневных сложностей, переставив возвращаемый тип функции в конец, добавив двоеточий и стрелочек, ну чтобы всё было как у нормальных математиков в лучших академических кругах, и убрав необходимость писать фигурные скобки для однострочных функций. Ну теперь-то заживём!
В отличной статье Разработчик с мозгом груга есть замечательный момент:
груг хочет фильтровать список на java
«Ты преобразовал его в поток?»
ладно, груг преобразовал в поток
«Хорошо, теперь можно фильтровать»
хорошо, но теперь нужно вернуть список! а есть поток!
«Ты собрал свой поток в список?»
что?
«Определи Collector<? super T, A, R>, чтобы собрать поток в список»
груг клянётся могилой предка будет бить дубиной каждого в комнате, но считает до двух и остаётся спокойный
добавь обычную вещь типа
filter()для списка и пусть возвращает список, слушай меня разработчик java api большой мозг!никому не нужен «поток» и никто не слышал про «поток», не сетевой api, все груги java используют списки мистер большой мозг!
Никому не нужно указывать тип функции в конце её определения, слушай меня мистер большой мозг Герб Саттер! Это не проблема языка, которую надо исправлять, миллионы людей выучили этот синтаксис и привыкли к нему. Может быть в комнате, полной теоретиков программирования, указывание типа перед сигнатурой функции и звучит как анекдот, но я никогда в своей жизни не видел проблем ни с чтением, ни с работой такого кода.
Просто дайте мне, блин, обычные плюсы, ровно с тем же самым синтаксисом, но с
кучей дополнительного синтаксического сахара, позволяющего автоматизировать написание типового кода
сильно расширенной стандартной библиотекой, учитывающей современные и используемые стандарты
стандартным менеджером пакетов
удалёнными из языка совсем устаревшими конструкциями (да, я вижу, что они удалили
unionи адресную арифметику, что тоже дискуссионно)вменяемо оформленными ключевыми словами, а не безумными
[[nodiscard]]и самое главное - с возможностью писать как можно меньше кода, получая при этом самое очевидно ожидаемое поведение, которое не надо потом часами дебажить в отладчике
Иногда складывается впечатление, что люди, которые создают очередного убийцу плюсов, вообще не особо пишут на плюсах, либо пишут что-то академическое, либо очень специфичные вещи.
cppfront это конечно мертворожденное творение и явно нигде в итоге не будет использовано, но всё что вы перечислили это не то что нужно С++, даже наоборот, это всё категорически нельзя делать
Расскажите, пожалуйста, почему в C++ категорически нельзя делать стандартный менеджер пакетов, расширенную стандартную библиотеку и вменяемо оформленные ключевые слова?
Расскажите, пожалуйста, почему в C++ категорически нельзя делать стандартный менеджер пакетов
Сначала было бы хорошо сделать стандартную систему сборки. Исторически этим никто не занимался, поэтому расцвело сто цветов, из которых до наших дней дошло несколько широко известных (CMake, meson) и некоторое количество неизвестных (в том числе и закрытых, которые за пределы родивших их компаний никогда не выйдут).
Стандартным менеджером пакетов так же никто изначально не озадачился (поскольку тогда и понятия-то такого и не было), поэтому расцвело сто цветов... И тем, кто дожил до сегодняшнего дня (в первую очередь vcpkg и conan) приходится адаптироваться к тому, что есть и CMake, и meson, и autotools, и...
В общем, тот факт, что к моменту, когда в ИТ массово осознали, что требуется стандартный менеджер пакетов, в мире C++ (и чистого Си) уже было такое многообразие, справится с которым не так-то просто.
расширенную стандартную библиотеку
Главным образом принцип развития языка: работа через комитет и предложения. И большинству тех, кто продвигает C++, за эту деятельность ничего не платят.
Но еще и тот факт, что C++ применяется в слишком разнообразных условиях. Можно вспомнить хотя бы наличие запрета на исключения во многих проектах. Расширять stdlib в таких условиях гораздо сложнее, чем в каких-нибудь Ruby или Python.
и вменяемо оформленные ключевые слова?
Человеческая природа: вкусы у всех слишком разные. Поэтому чтобы не выбрала некая группа людей в результате тяжелых и длительных обсуждений, всегда найдется другая группа, которой результат принципиально не понравится. Вне зависимости от самого результата.
Стандартный менеджер пакетов == монополия, монополия == плохо. Есть другие пути, которые и развиваются успешно
"расширенная" стандартная библиотека это непонятно что, видимо json и прочий мусор в std, это там не нужно, потому что устаревает каждый день и всё равно все будут использовать сторонние библиотеки по разным причинам
По ключевым словам вообще непонятно в чём претензия, [[nodiscard]] это вообще аттрибут, а не ключевое слово, аттрибут кстати может быть и [[ewruriweire3432432]], потому что это мать его аттрибут, там произвольное пишется
Особенно учитывая, что you don't pay for what you don't use, если лично вам не нужно - просто не используйте, оно не раздует вам код и добавит каких-либо неудобств
Поскольку в C++ реализаций stdlib больше одной, то раздувание stdlib значительно увеличивает объем работы для мейнтейнеров этих самых реализаций. А это будет вести к тому, что в стандарте C++xx добавили что-то в stdlib, а до пользователей это доберется только спустя N лет, где N будет постепенно увеличиваться.
Так что нет, в мире C++ это не такой однозначный и убойный аргумент, как может показаться на первый взгляд.
Тут вполне работает классический подход, когда новые фичи, в процессе обсуждения их комитете для включения в новые стандарты реализуются и обкатываются в каком-нибудь Boost'е
Или не работают как в случае с Executors TS и Networking TS.
Так что хуже уже не будет.
Будет. Я вот, после долгих лет ожидания нормальной реализации C++98 в большинстве компиляторов, а потом ожидания нормальной реализации C++11 в большинстве компиляторов уже успел порадоваться тому, что было в C++14 и C++17. Но тут пришел C++20 и старые недобрые времена вернулись.
Поэтому лично я был бы только за то, чтобы в стандарт включали лишь фичи, которые уже готовы к релизу в большой тройке компиляторов. И если при этом stdlib остается прежних размеров, то ничего страшного. Компенсировать это можно развитием vcpkg и conan. А уж если бы вместо CMake что-то вменяемое стало стандартом де-факто для системы сборки, так ваааще. Но такого чуда, боюсь, я при жизни не увижу :(
json используют активно всего пару лет, он ещё и меняется (json5 всякий), через ещё пару лет его забудут, а С++ (просто напомню) уже >30 лет
Менеджер пакетов - это только лишь инструмент. Никто не запрещает использовать его со сторонними или вообще своими личными репозиториями пакетов.
то есть вместо того чтобы конкурировали собственно менеджеры вы разрешаете только делить всё на какие то большие репозитории с пакетиками, т.е. монополия на собственно сборщик этого всего остаётся
json используют активно всего пару лет
Вот ты и попался
json используют активно всего пару лет, он ещё и меняется (json5 всякий), через ещё пару лет его забудут
В требованиях добавить json в stdlib самое интересное -- это отсутствие требований добавить туда еще и XML. Видимо, требователи просто слишком молоды, чтобы застать период тотального доминирования XML-я. И ведь XML до сих пор используется.
Но товарищ выше сказал, что менеджеры пакетов тоже не нужны, поэтому we are trapped.
ТоварищЪ выше слишком экстремален даже для C++ного мира :)
Но в его суждениях есть здравое зерно: единый стандартный менеджер пакетов, если он будет централизованным и будет находиться под контролем какой-то одной организации (типа того, что сейчас мы видим в лице vcpkg и conan), не есть хорошо. Иногда включение обновлений для уже принятых в vcpkg/conan библиотек может занимать недели, буквально. Да, есть всякие способы кастомизировать vcpkg/conan под себя и не зависеть от глобального репозитория. Но это все-таки для других целей предназначено.
Плюс к тому, остается вопрос о том, что будет с тем же самым conan-ом, если спонсирующей его организации данное направление бизнеса покажется невыгодным. Повторится история biicode, из которого conan и вырос. А оно нам надо?
Вот если бы был придуман стандартный формат оформления пакетов и в состав компиляторов входил бы стандартный инструмент, который бы позволял вытянуть и собрать нужные зависимости... Вот это было бы да, круто.
Но, вроде как, в этом направлении работы не ведутся, либо про них особо не говорят :(
Сейчас коммитет как раз работает над стандартом описания для этих самых пакетных менеджров, чтобы и смейк и прочие базели научились читать некое "общее" представление и всё это многоообразие сборщиков будет иметь "общий язык"
Ну раз коммитет работает, то следует ожидать чего-то настолько же всратого, как система модулей из C++20 :(
Проще вряд ли получится.
Система модулей, кстати, не самое всратое из нововведений языка. Оно хотя бы работает. То, что оно не было сразу встроено в компиляторы, это жуткий косяк. И для критики, можно было бы, конечно, сделать что-то типа псевдонима, как в некоторых языках при подгрузке модуля, потому что синтаксически модули это просто другой вид include
Стандартный менеджер пакетов == монополия, монополия == плохо.
Единственный источник пакетов - это монополия. А стандартный менеджер пакетов это очень даже отличный план. Сравните с прочими языками - python, js, ruby, go, да даже D .
кучей дополнительного синтаксического сахара, позволяющего автоматизировать написание типового кода
А какой в вашей предметной области "типовой код"?
никому не нужен «поток» и никто не слышал про «поток», не сетевой api, все груги java используют списки мистер большой мозг!
…
слушай меня мистер большой мозг Герб Саттер! Это не проблема языка, которую надо исправлять, миллионы людей выучили этот синтаксис и привыкли к нему
По-моему, вы не поняли, о чём этот отрывок из статьи про гругов.
Когда я читал этот отрывок, я понял его так: сидят очень умные люди (я без сарказма), и рассуждают, как же нам вот так вот по всем математическим и логическим правилам организовать архитектуру языка, чтобы охватить все крайние случаи, и обобщить всё на свете. Потом придумывают свои идеальные с академической точки зрения решения, и выдают их в язык. Но в большинстве случаев программистам это не нужно, им не нужно даже задумываться о таких глубоких материях - дайте мне обычный метод, который берёт понятную структуру данных и выдаёт понятный результат, я вызову этот метод, получу результат и пойду дальше писать код, а не спотыкаться на каждой строчке, думая, а как вот тут с точки зрения теории программирования правильнее обработать данные. Просветите же меня, в чём я неправ, и о чём тот отрывок на самом деле.
В данном случае есть язык C++, у него есть проблемы, очередной очень умный человек пошёл эти проблемы решать, и в первом же своём идеальном примере показывает, что он там нарешал. А в примере возвращаемый функцией тип данных идёт не перед названием функции, а после - так, как делают все современные языки программирования, потому что так, несомненно, правильнее с точки зрения каких-нибудь там Теорий Построения Компиляторов или чего-нибудь такого же заумного. Но это никогда не было проблемой языка с точки зрения программиста, это не нужно было исправлять и тратить на это силы. Потратьте силы на более важные вещи, а int main пусть остаётся int main, а не main: () -> int.
и самое главное - с возможностью писать как можно меньше кода, получая при этом самое очевидно ожидаемое поведение, которое не надо потом часами дебажить в отладчике
Ха-ха. Тогда вам стоит поменять язык. В C++ либо очевидное поведение, либо меньше кода за счёт "сахара".
Суть в том, что Саттер хочет того же что и вы. И именно поэтому начал разработку C++2
переставив возвращаемый тип функции в конец,
я конечно понимаю, что у многих до сих пор остался Сишный фетиш на спиральные определения, но не очень понимаю чего он так вас подрывает.
Человек сделал препроцессор, который избавляет от многих болезненных точек и добавляет больше безопасности, при этом не отламывая совместимость с плюсовым кодом. Ну то есть буквально
с возможностью писать как можно меньше кода,
Ну, а про
очередного убийцу плюсов
Саттер - это человек который слишком любит плюсы, чтобы действительно писать убийцу плюсов. Фактически это Core Guidelines воплощённое в суперсете синтаксиса плюсов. Да ещё и экспериментальная, в первую очередь.
Вот бы еще люди прозрели до осознания того, что отсутствие менеджера пакетов это не баг, а фича.
Rust ещё не предлагали? Есть пакетный менеджер, код из вашего примера будет как-то так:
fn main() {
hello("world!");
}
fn hello(msg: &str) {
println!("hello {}", msg);
}
Так а что мешает использовать уже сейчас?
`x % 2` → `x & 1`
П.5, если вдруг не повезло с conan, то вот вам гайд https://www.reddit.com/r/cpp/comments/ix9n1u/why_is_it_such_an_abysmal_pain_to_use_libraries/?utm_source=share&utm_medium=web2x&context=3
namespace view = std::views;
auto even = [](int i) { return i % 2 == 0; };
auto half = [](int i) { return i / 2; };
auto range = view::all(list) |
view::filter(even) |
view::transform(half);Немного сложнее, но смысл передаётся так же хорошо.
Вы издеваетесь??
Так у нас, у C++ников, собственное представление о прекрасном!
А вы взяли и сразу с козырей зашли... Хорошо же сидели, ну в самом-то деле ;)
Так у нас, у C++ников, собственное представление о прекрасном!
Именно так!

Мне ещё нравится "QTextStream::allocate() can not be used as a function", что совершенно очевидно означает, что у вас в проекте две разные зависимости тянут две разные версии библиотеки CGAL.
Концепты придут, порядок наведут
самое ужасное, ни один разработчик IDE так и не додумался фолдить куски этой тарабарщины и хоть как-то подсвечивать синтаксис... Наверняка еще и эвристик можно накрутить, чтобы хоть как-то на человеческий язык переводить. Ах ну да, я забыл что плюсовики должны перманентно страдать
Есть питоновские скрипты для вывода ошибок, но тут уже не понятно почему не добавляют «адекватности», то ли потому, что питон, то ли потому, что мазохизм
yoavbls реализовал эту идею в Апреле
Pretty TypeScript Errors vscode github Released on 12.04.2023
Люди упросили добавить это в WebStorm , что и было сделано в версии 2023.2 WEB-60634 WEB-40945
Может когда-нибудь и для C++ появится
Этот код понятнее чем код питона
P.S. views::all тут лишнее
С# LINQ:
collection.Where(i => i % 2 == 0).Select(i => i / 2)
если не нужны ленивые вычисления, то добавим
collection.Where(i => i % 2 == 0).Select(i => i / 2).ToList();
После такой работы со множествами, хочется плакать в других языках.
Rust:
let result: Vec<_> = collection
.into_iter()
.filter(|i| i % 2 == 0)
.map(|i| i / 2)
.collect();в расте нет реальных итераторов, это всё крайне ограниченные примеры работающие только для интов
Можно пример того, что по-вашему не работает?
сортировка на чём то кроме span, да и вообще в расте +- всё завязано либо на input итераторы, либо на span (слайс по растовому), все операции определены только для них, и то дублируются в разных контейнерах(коллекциях), что делает невыразимым громадное количество вещей, таких как поиск в мапе и возвращение не option, а итератора
И это прямое следствие того как устроены в расте дженерики, язык не способен выразить то что от него требуется(а то что выражено - крайне криво и на костылях, вплоть до того что в стандартной библиотеке раста используются фичи раста, которых нет в других частях собственно языка)
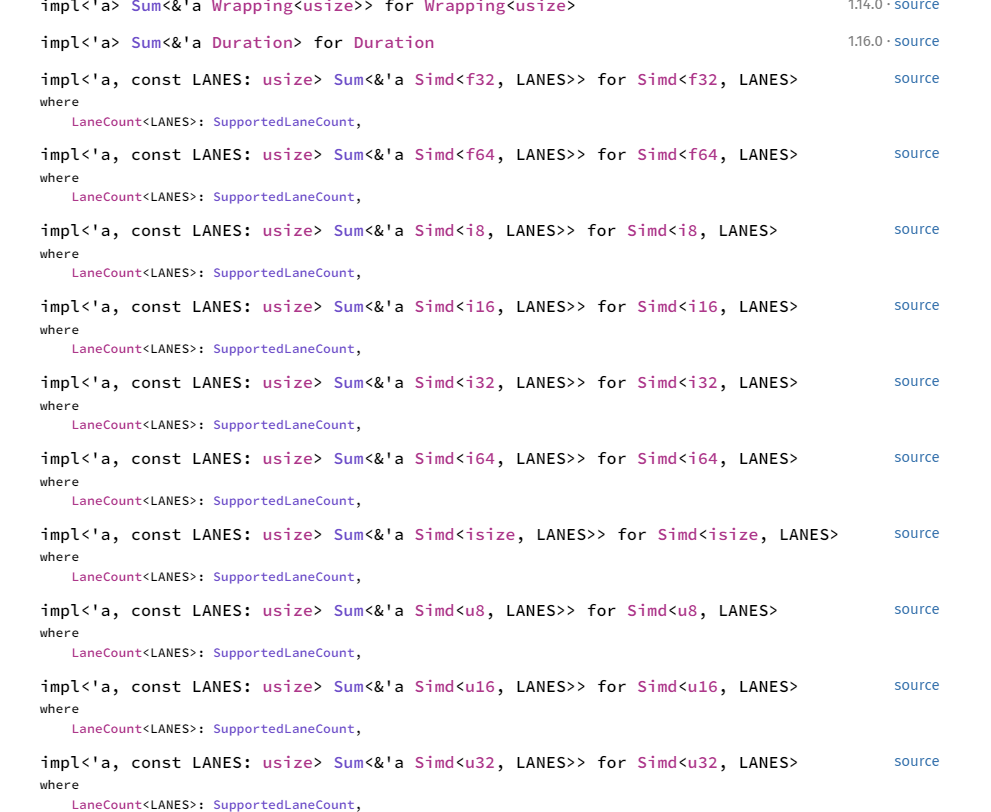
P.S. посмотрите на количество реализаций Sum, фактически на каждый тип макросом/вручную раскрыта реализация, это не один шаблон функции как в С++, а вот такой вот ужас
Что-то я не понял проблемы. Слайсы универсальны для любых контейнеров и их можно сортировать. Итераторы универсальны для любых контейнеров и их можно возвращать при условии, что объект, на который ссылается итератор, будет продолжать где-то храниться (или вы хотите владеющие итераторы?). Поиск по мапе тоже прекрасно работает.
Можно конкретный пример того, что по-вашему невозможно или неприемлемо сложно сделать в Rust?
Я привёл 2 конкретных примера,
1. сортировка того что не является слайсом(например вью на Vec которое reversed или deque из С++, которого в расте нет, но убогость коллекций в расте это отдельная проблема, хоть это и вытекает из невыразительности языка)
возвращение итератора на объект из мапы, чтобы второй раз не искать его
auto it = map.find(key);
if (it != map.end())
use(*it);
VS
// 2 поиска в мапе
if (map.contains(key))
use(map.find(key));Это реальный итератор, то что в расте - не итератор, он не способен указывать на какой-то объект,
Кажется, я понял - вам не нравится отсутствие так называемых "random access iterators"? Если так, то хорошо (хотя по личному опыту я прекрасно обхожусь без них)
Хотя, немного погуглив, я обнаружил, что std::iter::RandomAccessIterator раньше существовал, но был удалён, потому что оказался никому не нужен.
В связи с чем назревает вопрос — а действительно ли он нужен?
1.1. Действительно ли есть необходимость сортировать что-то, что не является слайсом? В реальном проекте я просто сделаю что-то вроде v.sort_by(|a, b| b.cmp(a)), и я ещё не встречал ситуаций, когда этого оказалось бы недостаточно.
1.2. Действительно ли есть необходимость сортировать deque? Я иногда использовал deque для создания, ну, собственно очереди, и мне никогда не приходило в голову её сортировать, потому что зачем?
2. Зачем из мапы возвращать итератор на объект, когда можно возвращать сам объект (или ссылку на него)?
if let Some(it) = map.get(&key) {
// Один поиск, в "it" ссылка на объект
use_it(it)
}Есть ли задачи, которые жизненно необходимо решать именно через random access iterators и никак иначе?
Зачем из мапы возвращать итератор на объект, когда можно возвращать сам объект (или ссылку на него)?
чтобы не искать его второй раз, когда захочется вставить значение или сделать ещё миллиард операций которые может захотется сделать с мапой, например итерация от этого места до конца
Действительно ли есть необходимость сортировать deque?
именно так и отвечают последователи раста - а нам и не надо. Т.е. не надо работать никогда ни с чем, кроме как с последовательной памятью, отлично
Действительно ли есть необходимость сортировать что-то, что не является слайсом?
спросите тех кто делает крейты для сортировки таких последовательностей. В расте это делается "просто" - делают вектор индексов, его сортируют, потом расставляют по индексам получившимся элементы. Это очевидно имеет ограничения и невероятный оверхед
И главное: в С++ можно написать один шаблон функции, который будет просто работать и который можно дальше специализировать. Например в С++17 добавили новый вид ренжей - сделали для них более эффективную реализацию не меняя интерфейс или просто реализация захотела более эффективную сортировку интов - добавили не меняя интерфейс.
В расте такое невозможно из-за того как дженерики работают, поэтому там есть только слайс и операции на нём, т.к. не смотря на то что на компиляции всё известно, компилятор раста не способен ничего сказать о пришедшем типе, например проверить что он удовлетворяет требованию Х (в С++ можно проверить практически что угодно и на этой основе решить как поступать)
чтобы не искать его второй раз, когда захочется вставить значение
А зачем, если его можно заменить через ту же самую ссылку it?
итерация от этого места до конца
А вот это уже интереснее, тут я действительно могу представить какую-нибудь задачу
не надо работать никогда ни с чем, кроме как с последовательной памятью
Ну, простите, покажите когда надо?
делают вектор индексов, его сортируют, потом расставляют по индексам получившимся элементы
Ещё раз простите, но, блин, зачем? Чаще всего коллекция, которую нужно отсортировать, изначально и является вектором. Можно пример коллекции, которая должна НЕ являться вектором и её жизненно необходимо сортировать для решения задачи?
новый вид ренжей [...] В расте такое невозможно из-за того как дженерики работают
Это было бы возможно, если бы ренж реализовали как трейт. Почему так не сделали — не знаю (возможно, потому что, опять простите меня, не нужно?), но если сильно захотеть, то принципиальных ограничений вроде бы не вижу
Впрочем, в Rust уже существует какой-то std::ops::RangeBounds, но почему-то не особо применяется — возможно, потому для полноценной работы требуется включать найтли-фичу associated_type_bounds, но раз она в принципе существует, то можно понадеяться, что в будущих версиях ренж допилят
проверить что он удовлетворяет требованию Х
Именно для этого в Rust и существуют трейты. Я чего-то не понимаю?
А зачем, если его можно заменить через ту же самую ссылку
it?
ссылка теряет информацию о позиции элемента в контейнере
Ну, простите, покажите когда надо?
практически любой контейнер кроме вектора это не последовательная память, т.е. постоянно надо
принципиальных ограничений вроде бы не вижу
а они есть
Всё в трейтах не выразишь, потому что они кривые и невыразительные
void func(auto x) {
if constexpr (fooable<x>) {
x.foo();
}
else {
x.bar();
}
}Вот это уже невыразимо, в расте нужно написать требование на Х в сигнатуре, при этом || в системе трейтов раста не существует
ссылка теряет информацию о позиции элемента в контейнере
И что? Пусть теряет, мне не жалко. На протяжении всей этой ветки вы не завершаете свои мысли и не поясняете, какие реальные задачи это мешает решить, из-за чего мне очень тяжело вас понимать.
практически любой контейнер кроме вектора это не последовательная память, т.е. постоянно надо
Когда «постоянно» надо? Вы опять не завершили свою мысль. Из других контейнеров помимо вектора и deque я могу вспомнить разве что BTreeMap и «печально известный» linked list, но первый отсортирован по определению и позволяет итероваться по себе (хотя и не на уровне random access iterator), а второй вообще непонятно зачем нужен
Вот это уже невыразимо
Понял (вот тут держите от меня плюс)
И что? Пусть теряет, мне не жалко.
весь смысл в том чтобы информацию не терять и дважды/трижды не искать. Именно поэтому лист в расте такой бесполезный - на нём нельзя сделать ни одной операции листа.
Вставка в середину? Ищи за O(N)
Убрать из середины? Ищи за O(N)
Потому что нет понятия итератор, чтобы можно было взять этот самый итератор и по нему вставить до / после, удалить элемент и тд
Из других контейнеров помимо вектора и deque
контейнеры бывают не только в стандартной библиотеке
И контейнеры лишь частные случаи ренжей, я уже приводил пример
void foo(auto rng) { std::ranges::sort(rng); }
foo(std::vector<int>{}); // работает, contiguous range
foo(std::vector<int>{} | reverse); // работает, но уже рандом аксес
В расте второе уже сломается, а таких ситуаций - бесконечное множество
контейнеры бывают не только в стандартной библиотеке
Это понятно, но вопрос никуда не делся — зачем? Вот эти все примеры с контейнерами и итераторами, отсутствие которых в Rust вас не радует, мне не были нужны ни в одной из тех задач, которые мне приходилось решать. Наверное, у меня просто не возникало таких задач, в которых это было бы необходимо, но из-за того, что вы опять не завершили свою мысль и продолжаете увиливать от описания реальных задач, а не выдуманных синтетических примеров, я продолжаю вас не понимать
Отвечу за него, например есть такая область как геймдев и компьютерная графика, где кроме стандартных векторов, есть дохрена других контейнеров по которым нужно итерироватся, например octree, BVH, sparse vectors и куча куча других, по которым нужно эффективно итерироватся. Не говоря уже о куче разных графов, типа графа сцены, графа материалов, графа поведения, графа смешивания анимаций и т.д а раст + графы == боль.
Эх, всё-таки стоит когда-нибудь написать свой игровой движок для общего развития
impl Iter for Octree {
fn next() -> Option<Self> {}
} Ничто не мешает вам сделать так. Ровно то же самое что придётся сделать и в плюсах, разве что только на самой структуре. Для графов есть Box/RefCell. Тот же Bevy вполне успешно работает с графом сцены и прочими. Самое забавное, что для того чтобы иметь нормальную производительность для больших игр вам придётся приводить все эти графы к некоторому линейному виду и не сильно принципиально на каком языке вы это делаете. Без совсем сырых указателей конечно больно, но Rust именно для этого и был придуман.
А если перед использованием этой информации из итератора в контейнер что-нибудь положат?
Грубо говоря compile time выражения включая трейты пока ещё в процессе, это верно, но оно и в плюсах не сказать чтобы давно появилось. Можно конечно попробовать такое на макросах провернуть, но в среднем композиция была выбрана чтобы избежать подобной ереси как выше.
Всё ещё не вижу проблемы. `.entry` делает ровно это же
map
.entry(key)
.and_modify(use)вью на Vec которое reversed или deque из С++
vec.into_iter().rev().map(use)Или я чего-то не понимаю?
entry это костыль и дополнительная сущность, которая пытается покрыть как раз описанные проблемы, но как с entry найти элемент и потом от него до конца проитерироваться, например? Или сделать любую другую операцию, которую не предусмотрели те кто писал entry?
Итератор это хорошая абстракция, которая позволяет делать невероятно много, не добавляя лишних сущностей(таких как entry)
vec.into_iter().rev().map(use)Или я чего-то не понимаю?
Как это теперь отсортировать? Это же не слайс
Без превращения в линейный кусок памяти - никак. То есть .collect::<Vec<_>>().sort_by(sorter). Ровно также будет вести себя сортировка и в плюсах.
Ровно также будет вести себя сортировка и в плюсах.
В смысле? Тот жеstd::sort()в плюсах работает со стандартной парой итераторов, указывающих на начало и конец сортируемого диапазона, и ему пофигу как то, что он сортирует, расположено в памяти. Как и практически всем стандартным алгоритмам из std - они работают с итераторами.
Строго говоря в Rust стандартные сортировки сейчас гвоздями прибиты к вектору/слайсу. Также как и по всей стандартной либе есть несколько вариантов map/flat_map и прочие проблемы в том же духе. Ничто не мешает написать собственную функцию `sort(impl Iterator)`,и сортировать как хочется. Но утверждать при этом, что итераторы у раста какие-то ненастоящие как минимум странно. Ну, а отсутвие генерик сортировщиков и прочих обобщённых алгоритмов в стандартной библиотеке компенсируется экосистемой крейтов.
Даже если переписать эту сигнатуру в более «реалистичном» виде fn sort<T: PartialOrd>(iter: impl Iterator<Item = T>) я что-то не очень представляю, как с её помощью написать сортировку, кроме как скопировать/склонировать все элементы в новый Vec. А если элементы не позволяют себя клонировать, то не представляю вообще хоть как-нибудь
Вот, например, топологическую сортировку делают. Для перемещения можно использовать std::mem::swap или std::mem::replace
а вот и нет, в С++ сортировка будет работать, потому что она не требует последовательной памяти
Другие примеры подобных ренжей это
iota(n, m) и все её модификации-последовательность чисел от n до m, которая в памяти не лежит и соответственно слайс там не взять
stride - например 1 3 5 7, последовательность с пропусками, тоже память не последовательная. В случае reverse кстати память поледовательная, но не выполняется требование что ++ итератора даст следующий элемент(он даст предыдущий)
Или у вас есть 2 вектора A и B, которые ведут себя как один вектор struct { A, B } (это может быть flat map или zip(rng1, rng2 к примеру)
Ну и ещё таких примеров масса, со всеми ними раст работать откажется
iota(n, m) -> (n..m), с баундчеком n < m.
stride -> iter::step_by
reverse -> iter::rev
flat map или zip(rng1, rng2 к примеру)
Есть и zip и map/flat_map, да ещё и в парарллель. Причём буквально с релиза в 2015. В то время как простой string_view появился в 17 стандарте, а прочие view только в 21, да и те не все. Кстати не без влияния ржавчины.
Так что вас ограничивает только отсутвие функций в стандартной библиотеке, принимающих итераторы на вход - сортеров, миксеров, траверсеров и прочих алгоритмов. Для этого люди пишут отдельные крейты, да.
А причём тут это вообще? Да, в раст прямо в язык затащили n..m, ограничив его только для интов.
В С++ эта штука работает для чего угодно, у чего есть оператор ++ (например те же итераторы) и реализовано на уровне библиотеки, а не языка
И речь была про другое - что это всё random access ренжи, но на них нельзя взять слайс и соответственно сортировать(в расте)
И нет, это не фиксится на уровне библиотек, во первых потому что это должно быть в стандарте(чтобы все знали что есть такое и реализовывали интерфейс для этих итераторов), во вторых потому что в расте это неосуществимо из-за того как там работает unsafe и ссылки
возвращение итератора на объект из мапы, чтобы второй раз не искать его […] Это реальный итератор, то что в расте — не итератор, он не способен указывать на какой-то объект,
if let Entry::Occupied(mut it) = map.entry(key) {
use(it.get_mut());
}Слайсы универсальны для любых контейнеров
буквально для одного контейнера они "универсальны", они не могут представить ничего кроме последовательной памяти(массива)
фактически на каждый тип макросом/вручную раскрыта реализация
Макросом — это не вручную, никакого ужаса тут нет. Вот тут уже держите меня минус за дезинформацию
Судя по этому треду, BidirectionalIterator в расте выразим, но только по immutably borrowed элементам. Почему его нет в стандартной библиотеке, я не знаю. А по мутабельным элементам нельзя by design, в соответствии с правилами borrow checker'а:
The reason is simply aliasing vs mutability.
Iteratoris designed so that you can retain references to the elements that it yielded, so that if you can go back and forth you would be able to have multiple references to the same element (aka: aliasing). Now, imagine that the references in question are mutable: you now have multiple mutable references to the same element, BOOM. So, since yielding mutable references is desirable, theIteratortrait has given up aliasing.
Насчёт реализаций Sum. В плюсах нет std::sum(), так что предолагаю, что вы Sum::sum() сравниваете с std::accumulate(). Это не совсем корректно, потому что последняя принимает начальное значение и ней не нужно ничего знать про 0. На расте для такого тоже тривиально пишется единственная реализация на трейтах:
use std::iter::Iterator;
use std::ops::Add;
pub fn accumulate<T, I>(it: I, init: T) -> T
where
T: Add<Output=T>,
I: Iterator<Item=T>
{
it.fold(init, Add::add)
}
Посмотрел исходники sum(), по сути там три реализации (вручную написанных макроса): для интов, для флоатов и для Simd. Отличаются они в основном тем, как задаётся изначальное значение: $zero, 0.0 или Simd::splat(0 as $type). В расте нет неявных приведений типов как в плюсах, так что нельзя везде написать просто 0. Честно, не знаю, почему они не завезли в стандартную библиотеку что-то типа num::traits::Zero и не сделали на трейтах вместо макросов. Не вижу для этого особых преград со стороны языка.
Ужас в том, что для компилятора каждая написанная макросом реализация - это хуже чем написанная вручную, её ещё раскрывать надо
Т.е. в С++ будет шаблон, который инстанцируется ТОЛЬКО если в коде пригодился шаблон для этих типов
А в расте компилятор даже если вы не используете эти SIMD<i32, 64 8 43 53> всё равно будет генерировать код, замедлять компиляцию и тд(а компиляция и без этого в расте медленнее чем в С++ сильно)
В общем получается, что в С++ сложность компиляции O(N) где N это количество вашего кода, а в расте O(M) где M это количество кода на расте в мире(т.к. для каждого типа всё раскрывается каждый раз)
Генерировать код эти реализации не будут, потому что они всё ещё обобщённые по Iterator. Пользователь их будет инстанцировать только для конкретных используемых пар Iterator и T.
Вы правы, что даже эти обобщённые реализации требуют время компилятора (на раскрытие макросов и проверку типов). Но есть важный нюанс: это актуально, только если вы сами собираете стандартную библиотеку раста. Обычно она уже собранная. Так что на пользователе это никак не отражается. Наоборот, за него уже сделана вся работа по тайпчекингу тела шаблона. А тело плюсового шаблона будет тайпчекаться для каждого инстанцирования, и при большом количестве инстанцирований это будет медленнее. Тайпчекнутые шаблоны рулят. Тело шаблона должно быть корректным для любого инстанцирования. Надо сразу прописывать нужные constraints в сигнатуре шаблона. Substitution failure is an error! В расте ошибка инстанцирования это обычная ошибка типов в месте инстанцирования, а не монструозная непонятная простыня куда-то внутрь шаблона. В плюсах только в 20 стандарте с концептами взялись за эту проблему
Это миф, инстанцировать раст дженерик не легче чем С++ шаблон, там также нужно всё проверить(и даже больше), никакая часть работы не переносится в некий "тайпчекинг"
Доказательство этому элементарное - у этих функций разный генерируемый ассемблер, т.е. для каждого набора аргументов таки нужно сделать разную функцию/тип
Про кодогенерацию я ничего не говорил. Там работы одинаково много в обоих языках. Но про "всё проверить" вы объективно неправду говорите сейчас. Проверяется только, соответствуют ли входные типы констрейнтам и соотносятся ли у этих типов лайфтаймы как надо. За счёт проверки лайфтаймов работы на этом этапе больше чем в плюсах, тут вы правы. Но типы и лайфтаймы в теле шаблона и вызываемых им шаблонах повторно не проверяются. Это абсолютно точно. Если не согласны, аргументируйте с хоть одним примером ошибки инстанцирования в расте, которая происходит в теле шаблона.
Но типы и лайфтаймы в теле шаблона и вызываемых им шаблонах повторно не проверяются
они и в С++ не проверяются дважды, просто когда что то ломается это ошибка компиляции
Объясните пожалуйста, как по-вашему компилятор может во время инстанцирования выявить и кинуть ошибку типов, не выполняя собственно проверку типов?
Я докажу вам что компилятор раста ничего заранее не проверяет приведя контрпример:
struct A<T>(T);
pub fn foo<T>(x:T) {
if false { return }
foo(A(x));
}
pub fn main() {
foo(5); // если закомментировать, то код компилируется
}Комментируете foo(5) - код компилируется.
То есть только на этапе подстановки реально проверяется что происходит и код "тайпчекается"
Что и требовалось доказать
Более того, если сделать if true { return; }, то код ВНЕЗАПНО тоже компилируется, что говорит о том что компилятор просто проигнорировал что идёт дальше, а это либо баг компилятора, либо очередная невероятная глупость разработчиков языка
Я докажу вам что компилятор раста ничего заранее не проверяет
Вы доказали только то, что он не проверяет возможность получить бесконечный рекурсивный тип. Это интересный кейс, и да, я пересмотрел своё прошлое мнение, что в расте не бывает ошибок внутри инстанцирования. Мой обновлённый тейк: в расте не бывает ошибок внутри инстанцирования, связанных с несоответствием лайфтайму или констрейнту (а это большинство ошибок с дженериками).
только на этапе подстановки реально проверяется что происходит и код "тайпчекается"
Код просто подставляется, не тайпчекаясь. Ошибка, которую выдаёт ваш пример, это не ошибка проверки типов, а ошибка рекурсии при выполнении "тупой" безусловной подстановки. Хотя разумеется можно сказать, что к ней приводит дыра в системе типов или их проверке при объявлении шаблона. Возможно, потом починят.
В С++ есть 2 стадии подстановки:
1. читаем шаблон, проверяем синтаксис и не dependent вещи, "связываем" то что не dependent сразу
когда подставлены типы, происходит просто подтановка, никакой дополнительной "проверки" там не надо, ошибка выходит сама по себе, если подстановка невалидна, в расте это также. Т.е. невозможно подставлять не делая проверку, это неотделимые вещи
В расте абсолютно то же самое, только есть ограничения глупые от языка, такие что например нельзя сделать foo<I + 1>, потому что а хрен знает почему, спросите разработчиков языка
Раст делает всё возможное, чтобы не существовало dependent типов, типы выражений и типы значений вынесены на уровень грамматики (например *x это всегда lvalue в расте)
А если нет dependent типов, то и проверять собственно нечего, но это не говорит о том что в расте хорошо, это говорит о том что раст забирает возможности писать код
Объясните пожалуйста, как по-вашему компилятор может во время инстанцирования выявить и кинуть ошибку типов, не выполняя собственно проверку типов?
f = map (`div` 2) . filter even
Пусть меня поправят более опытные люди, но в питоне это будет выглядеть как-то так:
r = (i / 2 for i in list if i % 2 == 0)
По-моему, всё выглядит понятно. Ну или я уж слишком сильно привык к питону..
как минимум код ругнётся на то что list - это такое ключевое слово.Ну и в вашем случае будет генератор, который станет бесполезен после использования. Если цепочка трансформаций вырастает, то кода будет заметно больше. Можно ли склонировать генератор, чтобы использовать его в нескольких независимых вещах это отдельный вопрос.
Да знаю я, что list - это ключевое слово, но сил хватило только заменить range на r. А насчёт генератора, насколько я понимаю исходный пример на C++, там результат auto range - это тоже что-то вроде генератора, а не список или вектор.
А вообще, каюсь, я написал тот комментарий, ещё не читав саму статью. Сообственно, в статье есть код на Питоне, очень похожий на мой:
# смысл — положить в новый список x // 2 (половина x)
# для всех x из списка list, если x делится на 2
[x // 2 for x in list if x % 2 == 0]
Только деление на 2 чуть другое и на выходе - список, а не генератор.
Не хочу устраивать холивары, но если язык не устаревает, может синтаксис как-то поправить на попроще? Ну чтобы избежать таких крокодилов "std::chrono::system_clock::now()" например.
Это то как раз элементарно alias'ится
Это не часть синтаксиса, это неймспейсы и типы, назвать их можно как угодно, если захочется
namespace time = std::chrono;
using clock = time::system_clock;
clock::now();Легко!
using sclock = std::chrono::system_clock;
sclock::now();А я не хочу называть "как угодно" я хочу просто напистать
import time
print(time.time())
А не вспоминать каждый раз какой лютейший треш напридумывали обкуренные создатели chrono.
А не вспоминать каждый раз какой лютейший треш напридумывали обкуренные создатели chrono.
Пространства имен существеннейшим образом облегчают жизнь в больших проектах. И там глубина вложенности, да и сами названия пространств имен, будут гораздо круче, чем в случае std::chrono. C++ные пространства имен позволяют с этим жить не просто нормально, более чем хорошо.
Так что претензии к синтаксису C++ есть, но вот с конкретным примером вы знатно промахнулись.
А нечего тянуть в глобальный скоуп всё подряд по дефолту. Ещё одно не удобное плюсовое решение.
PS. Неймспейсы это костыль который вставили вместо того чтобы сделать по нормальному.
А нечего тянуть в глобальный скоуп всё подряд по дефолту.
И что же такое "всё подряд" в C++ в глобальный скоуп тянется по дефолту?
PS. Неймспейсы это костыль который вставили вместо того чтобы сделать по нормальному.
По-нормальному это как модули в Python-е?
Всё подряд - означает что все определения из h файла будут подтянуты в глобальный скоуп по дефолту.
По нормальному - как в питоне или в расте, когда нужно явно указывать что именно тащится из модуля (или обращаться через модуль).
Всё подряд - означает что все определения из h файла будут подтянуты в глобальный скоуп по дефолту.
Так ведь благодаря наличию пространств имен в глобальный скоуп ничего не подтягивается. Условный import time в C++ реализуется двумя строчками вместо одной:
#include <my_time>
using namespace my_time;
При этом как раз синтаксис здесь вообще ни при чем. В выражении std::chrono::system_clock::now() элементами синтаксиса являются разве что :: и это не сильно хуже, чем какой-нибудь org.chrono.system_clock.now().
Так ведь благодаря наличию пространств имен в глобальный скоуп ничего не подтягивается.
У вас проблемы с причинно-следственной связью. Из за того что в глобальный скоуп всё подтягивается приходится использовать неймспейсы чтобы этого избежать.
Условный
import timeв C++ реализуется двумя строчками вместо одной
Мне нужен конкретный time а не условный которого в C++ нету. Как нету и целой кучи других нормальных вещей которые на плюсах сделать можно немного включив мозги и подумав о том кто будет этим пользоваться. Вместо этого разработчики стандарта выдают решения которые напоминают наркоманский бред.
При этом как раз синтаксис здесь вообще ни при чем.
Я про синтакис ничего и не писал, в данном конкретном случае виноват не синтаксис а в первую очередь ущербный модуль chrono (и во вторую очередь организация файлов / модулей / кода).
Из за того что в глобальный скоуп всё подтягивается приходится использовать неймспейсы чтобы этого избежать.
Вы, похоже, не знаете как работает include. Это простая текстовая подстановка в место, в котором include задействовали. Поэтому ни про какой глобальный скоуп include не знает. Например, пусть у нас есть файл a.ipp вида:
int a;
struct demo { int b; };
и файл main.cpp, в котором мы делаем include этого a.ipp:
// Содержимое появится в глобальном скоупе.
#include "a.ipp"
void f() {
// Содержимое появится в скоупе функции f.
#include "a.ipp"
}
namespace my {
// Содержимое появится в скоупе пространства имен my.
#include "a.ipp"
class outer {
// Содержимое появится в скоупе класса outer.
#include "a.ipp"
};
}
...
Да, пространства имен как раз сделаны для того, чтобы не захламлять гобальный скоуп. Но с момента их появления (а это более 30 лет назад), про захламление глобального скоупа (или автоматического подтягивания чего-либо в глобальный скоуп) говорить уже не приходится.
Мне нужен конкретный time а не условный которого в C++ нету.
Вообще-то есть. Вам просто не нравится то, что он лежит не прямо в std::
И, если я вас правильно понял, если бы в Python-е в модуле time лежал бы класс Clocks, внутри которого бы лежал класс System, внутри которого уже был бы метод time, и вызов приходилось бы делать как Clocks.System.time(), то у вас были бы такие же претензии и к Python-у. Не так ли?
Я про синтакис ничего и не писал
Ой, да ладно, кому вы рассказываете:
но если язык не устаревает, может синтаксис как-то поправить на попроще? Ну чтобы избежать таких крокодилов "std::chrono::system_clock::now()"
А нечего тянуть в глобальный скоуп всё подряд по дефолту. Ещё одно не удобное плюсовое решение.
Это наследство языка C. Вы явно не программист на C++, раз пишете такое. В те времена, когда эти языки появились не было тех проблем, что сейчас пытаются решить в других языках. Тут как бы стоит вообще сделать ремарку, что если бы не именованные пространства C++ был бы ещё хуже C в плане удобства написания больших проектов. Именованные пространства как раз спасают. А в связке с псевдонимами, еще и упрощают написание кода
А теперь обратитесь в питоне к таймеру высокого разрешения. Не подсматривая в документацию
Так тоже можно, если очень хочется. Создаем где-нибудь в проекте файл time.hpp:
#pragma once
#include <chrono>
inline int64_t time() {
return std::chrono::system_clock::now().time_since_epoch().count();
}И уже в нужном месте делаем почти точно также, как и в Python:
#include <iostream>
#include "time.hpp"
int main() {
std::cout << time() << std::endl;
}Правда в C++ так не очень принято, да и пространства имен все-таки отличная вещь.
Серьезно?
std::chrono::system_clock::now().time_since_epoch().count()
6 уровенй вложения с неочевидными названиями vs 2 супер очевидных в питоне. И так во всем в плюсах.
По моему, это наоборот классно, что одной строчкой сразу видно, откуда что тянется. И по названиям можно предположить, как будет вести себя функция в разных ситуациях.
А в питоне ты вызываешь time и лезешь в документацию проверять, подойдёт ли оно для твоего кейса.
И что значит count() в данном случае? Вот я не понимаю без документации. Это секунды? Тики процессора? И чем это лучше чем условный time? И на тему документации. Вот я нажал с ctrl на time и открыл описание:
Return the current time in seconds since the Epoch.Теперь для плюсов. Нажал на count(), и что я вижу?
_LIBCPP_INLINE_VISIBILITY _LIBCPP_CONSTEXPR rep count() const {return __rep_;}Ну просто офигеть как всё понятно. rep count, есть даже _LIBCPP_CONSTEXPR пометка не ужели не ясно. Даже тип понятно какой - rep! Каждый день типом rep пользуюсь, ну что не ясно то.
Для time_since_epoch к слову абсолютно тоже самое.
Так вы смотрите в какой-то рандомной реализации, вместо того чтобы смотреть собственно в документацию
Я в IDE смотрю. Перехожу по функции и читаю документацию. В питоне к системным функциям ко всем есть нормальный docstring, а в плюсах вместо этого кишки реализации из которых ниче не понять.
это не документация
всё там понятно, если знать С++
в разных реализациях питона там одинаковый docstring?))
А, ну вы видимо лучше меня знаете понятно мне или нет.
функция буквально делает return X;
этот X там на соседней строчке как единственное поле структуры, что тут может быть непонятно?
Кстати, std::chrono::system_clock::now().time_since_epoch().count() — очень хороший пример «продуманности» библиотеки chrono.
что тут может быть непонятно?
Непонятно «что значит count() в данном случае?» микросекунды? наносекунды?
вместо того чтобы смотреть собственно в документацию
Покажите, пожалуйста, как найти в документации С++ ответ на этот вопрос? И где эта документация C++ вообще находится?
Серьёзно, я не прикалываюсь. Во времена Microsoft Visual C++ 6.0 в качестве таковой я пользовался установленным с диска MSDN. Сейчас пользуюсь в основном cppreference.com. Но ни то, ни другое официальной документацией C++ не является.
Но вернёмся к нашему примеру.
В «документации» к методу count сказано:
Return value
The number of ticks for this duration.
Ок, количество «тиков».
А теперь попробуйте без компиляции какого-либо C++-кода [а используя только «документацию»] ответить на вопрос: а сколько это будет в секундах?
Причём просьба ответить для различных компиляторов C++ (GCC и MSVC [а количество тиков в секунде у них отличается]) и без использования Google. И ещё прошу подробно описать по шагам процесс поиска ответа на такой простой вопрос. [В Python ответ находится в первом же предложении в документации к функциям time.time() и time.time_ns(), в документации, которая устанавливается вместе с Python и которую не нужно искать в Интернете.]
Каждый разработчик на С++ знает такие сайты как cppreference, где подробно всё описано, более продвинутые знают где почитать стандарт
Непонятно «что значит count() в данном случае?» микросекунды? наносекунды?
если duration это секунды, то количество секунд, если микросекунды, то количество микросекунд, выглядит логично
А теперь попробуйте без компиляции какого-либо C++-кода [а используя только «документацию»] ответить на вопрос: а сколько это будет в секундах?
а зачем мне это, если .count для других целей используется? Если мне нужно будет узнать сколько это в секундах, я напишу duration_cast<seconds> или что-то в этом духе
Так а кто не даёт?
#include <time.h>
printf("%ld", ::time(NULL));Угу, вот только проблема, printf и time это функции языка С а не C++, который кстати говоря создали аж в 1972 году. А модуль chrono в C++ впихнули в 2011-м. Почему одним хватило мозгов сделать нормальный print и нормальный time (спорно - другие функции там тоже дичь), а другим нет?
Почему одним хватило мозгов сделать нормальный print
Это Си-шный-то printf сделан нормально? O_o
У сишного printf-а есть проблемы, но с точки зрения разработчика мне нужен нормальный print с шаблонами и форматированием, а не вот это вот извращение: << " " << " value = " << " value.
одним хватило мозгов сделать нормальный print
У сишного printf-а есть проблемы
И как это все укладывается в одной голове, хз...
А что и как можно улучшить в сишном printf? Если у нас нет виртуальной машины и базового класса Object и нельзя сделать {0}? Спрашиваю не флейма ради, а саморазвития для.
1) На шаблонах можно сделать чтобы основные типы определяло само а в пользовательских определяло и использовало кастомную функцию (при её наличии).
2) Сделать аналог f-строк питонячьих (синтаксический сахар на этапе компиляции), чтоб писать типо printf(f"Result is {obj.method()}");
И вместо вывода адреса в заданном формате по переданному указателю будет unresolved method to_string()? А главное, настройки форматирования данного типа, очевидно, переедут из декларативной строкозаготовки в императивный вызов.
Зачем вообще нужно форматирование строк? Два самых частых юзкейса — вывод пользователю (например, сообщение про не найденный файл) и подготовка DSL (например, запрос на SQL). Я считаю, и в том, и в другом случае надо принципиально держать код отдельно от шаблона строки (в первом случае по соображениям локализуемости, во втором — по соображениям безопасности, таким как sanitizing). Из того, что во многих современных языках (например, ES) появилась эта сомнительная фича, не следует, что такое форматирование лучше сишного.
А что и как можно улучшить в сишном printf?
Посмотрите на то, что сделано в fmtlib и std::print (C++23).
Не знаю, кто и за что минусует, а мой point очень прост. Язык безнадёжно испорчен «обкуренными создателями chrono». Но совершенно необязательно идти у них на поводу. Как вариант можно вернуться на уровень C, и в этом нет ничего плохого. Ещё можно взять какую-нибудь другую библиотеку для работы со временем (правда, я не знаю такие — может, в POCO что-нибудь найдётся?). Ну и, наконец, если не нужна кросс-платформенность, можно работать с примитивами операционной системы (в силу специфики моих проектов, я делал именно так).
Модули пока ещё не завезли. В 23+ оно будет схоже с java и c#.
но уже сейчас понятно — если C++ языку ищут замену, значит, её нет
"если я ищу мороженное, вкуснее того что я обычно ем, значит в мире не существует, И НЕ БУДЕТ существовать мороженного вкуснее того что я знаю".
Rust ?....
Для больших объектов операция копирования может быть очень затратной. Такое поведение в C++ имеет свои причины. Главные из которых — использование стека и принципиальное отсутствие сборщика мусора
Как связан GB и процесс копирования ?
std::print("x = {}, y = {}, x + y = {}", x, y, x + y);
интересно, кто у кого подсмотрел, С++ у Rust или наоборот.
C++ славится высокой производительностью. Проверим, так ли он хорош. В качестве конкурента рассмотрим популярный язык Java
ну это совсем позорище, ктож в здравом уме сравнивает компилируемый язык с JIT ? компил. и интерпретируемый ?
А кто лучше, вертолёт или трактор ? трактор или бугати широн ?
ну это совсем позорище, ктож в здравом уме сравнивает компилируемый язык с JIT ? компил. и интерпретируемый ?
это демонстрация идеи, что не нужно писать какой то плохой код, чтобы получить перфоманс, т.к. компилятор способен анализировать код(в джаве - не способен)
интересно, кто у кого подсмотрел, С++ у Rust или наоборот.
Да, print оказывается изобрёл раст, в С и питоне и куче других языков этого никогда не было
Хороший вопрос, как связаны копирование и сборщик мусора. Объясняю. Часто копировать приходится, потому что нужно передать владение объектом. В модели со сборщиком мусора объектом владеет глобальный пул и передавать владение не нужно. В модели без сборщика мусора - нужно) Отсюда копирования.
С JIT как раз можно производить profile guided рекомпиляцию, причем С++ код тоже можно джитить ( смотреть llvm )
интересно, кто у кого подсмотрел, С++ у Rust или наоборот.
Емнип питон первый завёз их в виде f-string. Раст это дело облагородил по своему и тоже добавил. Где-то между двумя этими событиями появилась плюсовая библиотека fmt, которая завезла такое форматирование в плюсы. Ну и не так давно похожий синтаксис попал и в стандарт js. За остальные языки не скажу.
В примере с суммой элементов, такой результат, наверное, только при включённой оптимизации, но тогда странно почему Компилятор вообще этот цикл не выкинул, только если сумма куда то выводится, хотя в примере с Java она никуда не выводится
Да, в бенчмарках я заботился о том, чтобы оптимизатор не выоптимизировал то, что измеряется)
В Java не выводится, но разница во времени означает, что цикл выполнялся
Вы написали про проблему с зависимостями, но conan даже близко не стоит рядом с pip, Да и системы сборки оставляют желать лучшего.
Модули. Появились в 20-м стандарте, до сих пор не работают. Еще пару лет ждем пока появятся в том же cmake, потом еще лет 5 пока нужные библиотеки перепишут с использованием модулей (а может и не перепишут).
переписать библиотеку на модули это дело минутное,
1. добавляешь export перед namespace библиотеки(или перед кокретными функциями или типами из библиотеки, которые хочешь сделать частью модуля)
2. создаёшь файл и сверху пишешь
export module module_name;
#define LIBNAME_EXPORT export
#include ... // все хедера библиотекиНу и всё, модуль готов
Да, к сожалению... Поэтому про модули не упоминал
Опять Яндекс Практикум? Сначала Go, теперь вот C++.
Глаз цепляется за каждое утверждение. Некоторые утверждения просто непонятны. Например array.get(j) Это из какой явы код?
Как бенчмаркали Java?
GC не обязан останавливать мир.
GC не мешает RTTI.
Вообще, странный выбор соперников Python и Java.
Про array.get(j). Это, насколько я помню, из AbstractList:
public abstract E get(int index)
Returns the element at the specified position in this list.
Автор использует ArrayList, в котором этот метод также есть.
https://habr.com/ru/companies/yandex_praktikum/articles/758744/#:~:text=популярная идиома RTII
"популярная идиома RTII" - опечатка, RAII - Resource Acquisition Is Initialization
Спасибо, да, опечатка)
GC не мешает RAII.
Вот пример RAII из scheme:
(with-output-to-file some-file
(lambda () (printf "hello world")))
Для чистки ресурсов используются "таможенники" (custodians).
Это не RAII — аналог такого и в C#/джаве есть (using/try with resources).
В яве и c# можно забыть сделать t-w-r, в scheme нет.
Да ладно? Как язык помешает мне вместо with-output-to-file использовать open-output-file?
Никак. Это другой механизм. Так же, как и RAII не запрещает создавать не-RAII объекты. Считай, что порты, получаемые with-output-to-file и open-output-file это разные объекты.
Джавский-же OutputStream можно использовать двояко.
Допустим, но в таком случае RAII есть и в С и вообще везде где можно передать аргументом функцию:
void with_file(const char *file_name, const char *access_mode, void proc(FILE*));Но такая классификация теряет смысл. Плюс сила RAII в том, что такие объекты не требуют специального обращения. Их можно хранить в контейнерах или положить полем в другой объект, а с данным механизмом так не получится.
Ну, поскольку RAII это, скорее, набор техник для конкретного языка, то в сравнении напрямую не вижу большого смысла.
Захватили ресурс в конструкторе, освободили в деструкторе.
Я всё ещё склоняюсь к тому, что GC не мешает RAII.
Дык, при наличии GC традиционных деструкторов обычно и нет, только "финализаторы", которые непонятно когда будут вызваны. Но похоже каждый из нас останется при своём мнении. (:
Но это не должно нам помешать разобраться в предмете получше.
Я размышляю так: гуглю RAII и вижу, что RAII это C++ техника, которая.... На других сайтах, RAII не привязывется непосредственно к C++, при этом приводятся примеры на очень даже managed языках.
В целом, думаю, можно говорить, что RAII это не только про плюсы.
Теперь смотрю непосредственно на суть RAII. Суть я вижу в том, что когда объект, представляющий внешний ресурс создан, то он готов к использованию этого внешнего ресурса, а когда мы этот объект лексически упускаем, то внешний ресурс освобождается. Вот тут, наверно, и зарыта собака. К этому я ещё вернусь.
Означает ли, что RAII должен применяться ко ВСЕМ внешним ресурсам? Думаю, что нет. Случаи бывают разные.
Какие есть механизмы ограничения времени жизни?
В C++, Rust и подобных время жизни объекта ограничено лексическим скоупом, после которого вызывается деструктор.
В управляемых языках, время жизни может быть задано в виде лямбды, в которую передаётся объект или в виде thunk с параметром. Так же, может быть специальная конструкция типа try-with-resources.
Все эти механизмы гарантируют аксиому "на время выполнения указанного кода внешний ресурс будет проинициализирован, а после будет освобождён, и управлять этим нельзя или не нужно".
В чём же порылась собака? В том, что объект может "убежать" из лексического скоупа через копирование, ссылки или другие механизмы. Например, я могу положить объект в коллекцию и вернуть её из функции. Что будет с ресурсом? Я не специалист в C++, но догадываюсь, что там можно запретить move конструктор и компилятор просто не даст скопировать объект, а взятый указатель будет невалиден (т.е. объект не сможет убежать из функции).
В t-w-r мы получим просто "закрытый" объект. Он у нас будет, но будет не функциональный.
В лямбдах та же история с закрытым объектом.
Но, поскольку интернет согласен с тем, что RAII это не только про C++, но и про другие языки с другой семантикой, то я считаю, что указанное поведение ("закрытый" объект) вполне в духе RAII.
И GC тут не при чём.
Как-то так.
На других сайтах, RAII не привязывется непосредственно к C++, при этом приводятся примеры на очень даже managed языках.
Можно ссылку или по каким ключевым словам загуглить? Спрашиваю просто из любопытства — интересно почитать другие мнения. Вижу в (английской) википедии оговорки, что мол если сборка мусора сделана через подсчёт ссылок, то она детерминирована и можно использовать RAII. Справедливо, правда сами примеры не очень убедительны (например, отдельная реализаций питона).
В управляемых языках, время жизни может быть задано в виде лямбды, в которую передаётся объект или в виде thunk с параметром.
Я что-то упускаю или управляемость тут не при чём? В С++ или расте можно сделать такой же интерфейс для работы с ресурсами.
Я не специалист в C++, но догадываюсь, что там можно запретить move конструктор и компилятор просто не даст скопировать объект
Стоит разделять копирование и перемещение. В С++ их запрещать можно отдельно. Собственно, с перемещением как раз никаких проблем нет: перемещать объект-ресурс наоборот удобно. Это может быть возврат или передача (владения) в функцию, положить/забрать из контейнера, перемещать как часть другого объекта и т.д. Лично я именно это беспроблемное использование и вижу "киллер фичей" RAII, альтернативы такого не предлагают. Опять же, если придираться, то где в приведённом изначально схемовском апи собственно инициализация?
И GC тут не при чём.
По прежнему считаю, что называть разные механизмы одинаково не очень полезно, а скорее вредно так как усложняет обсуждение. В языках с GC можно устроить ручное управление памятью — заводим кусок памяти, который никогда не освобождается и руками размещаем там объекты. Но кому будет лучше, если мы станем называть джаву языком с ручным управлением памятью?
GC тут, как минимум, при том, что он заставляет придумывать новые механизмы, а не полностью повторять плюсовый.
Со сборщиком мусора была бы невозможна популярная идиома RTII
Может всё-таки RAII? RTII эт что-то новенькое, даже не гуглиться, может конечно имелось в виду RTTI но по контексту не подходит совсем.
За бенчмарк Java - сразу двойка. Для этого есть специальные инструменты, учитывающие "прогрев" HotSpot, а не вот эта вот самодеятельность с таймерами. size() в цикле тоже вызывать не надо. И вообще есть улучшенный for и streams. Ну, в целом тут C++ наверняка и выйдет вперёд, но не с таким отрывом.
По поводу сетевой библиотеки - ну украли бы уже классы сокетов из Java и не мучались.
а в С++ size() в цикле вызывать можно и проблемы нет, что собственно этот бенчмарк и должен продемонстрировать
А классы сокетов - зачем? Все эти сокеты и протоколы уже есть в библиотеках, а вот стандартного из коробки нет - потому что нетривиально сделать хорошую реализацию подходящую всем
А мы не сравнивали C++ и Java) Мы сравнивали оверхэд в этих языках. Если сохранить size(), то оверхед цикла по диапазону может только вырасти сильнее. И да, мы сравнивали непрогретый цикл на Java с непрогретым на Java. Так что результат на мой взгляд репрезентативен
Ох уж этот Яндекс. Корпорация IUMO выпускает новый процессор @ssshot. Давайте попробуем угадать что будет в SDK? Rust? Go? М.б. Carbon? Нет, там будет LCC для C, C++ и Fortran. При любом раскладе поставлю на то что C++ там будет.
Я каждый раз удивляюсь, когда говорят, что в C++ слабая стандартная библиотека. Да, там нет встроенных сокетов, json, http или 3D движка, но зачем, если для этого есть сторонние библиотеки? Зато есть stl, который даст фору станадртным библиотекам любых популярных языков (не уверен про Rust разве что). Каждый раз, когда я пишу на других языках, я удивляюсь тому насколько мне не хватает stl. И это касается и разнообразия контейнеров, и алгоритмов, и деталей вроде возможности итерироваться по ключам и значениям map одновременно. Stl не совершенен, но в большинстве других языков всё ещё гораздо хуже.
P.S. Ranges деалют stl не только мощной, но и выразительной, за что им большое спасибо.
зачем, если для этого есть сторонние библиотеки
На работе надо было работать с json. В одной популярной библиотеки код почему-то не работал, пришлось использовать QJson. Была бы стандартная ситуации не работает не было бы.
"код почему-то не работал" будет всегда, потому что всегда можно написать неработающий код
Был случай, когда пришлось принимать данные из сторонних приложений в формате JSON.
Штуки 3 библиотеки пробовал, были разные проблемы.
Оказалось проще написать свой (быдло)код, чем разбираться, что с библиотеками не так. Возможно, данные были кривые, но повлиять на других разработчиков возможности не было, да и времени тоже. Надо, чтобы работало.
Для тех, кому как и мне не хватает даже стандартных контейнеров slt, есть eastl.
А что там за особенные контейнеры, если не секрет? Есть описание? Репозиторий с исходниками я видел, но какого-то описания там не нашел (может, плохо искал).
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2007/n2271.html
EASTL additional functionality (not found in std STL or TR1)
Из того чем пользуюсь постоянно. std::map и std::unordered_map в большинстве случаев ужасное зло.
fixed_vector
fixed_string
fixed_map
fixed_hash_map
vector_set
vector_multiset
vector_map
vector_multimap
ring_buffer
Спасибо. В каком смысле и в каких задачах std::map - ужасное зло? Нужно какое-то экстремальное быстродействие?
Если вы парсите условный json и в мапе у вас условные десятки ключей, то map вам будет только мешаться, будет большой оверхед по памяти по бранч пердикшену, по кэш миссам, оверхед на хеширование, кучу лишних аллокаций при вставке элемента, а в итоге проще и быстрее просто линейно пройтись по всем ключам и найти нужный. Лучше взять vector_map, для этого. Если же у вас десятки тысяч значений и map вам действительно нужен то std::map как правило имеет просто ужаснy/ производительность по сравнению с аналогами: https://martin.ankerl.com/2019/04/01/hashmap-benchmarks-04-02-result-RandomFind_2000/
Если же у вас десятки тысяч значений и map вам действительно нужен то std::map как правило имеет просто ужаснy/ производительность по сравнению с аналогами: https://martin.ankerl.com/2019/04/01/hashmap-benchmarks-04-02-result-RandomFind_2000/
Только вот std::map - это не hashmap. Причем тут эта ссылка?
В книге "Оптимизация программ на C++" Гантерота написано, что когда количество элементов в контейнере меньше сотни, то почти вообще без разницы с точки зрения быстродействия, какой контейнер использовать. Особенно если в реальной задаче, где делается не только миллион поисков случайных элементов в одном и том же контейнере, а ещё и другие задачи. Кроме того, если ускоряемый код по времени исполнения занимает 1% от исполнения всего кода, можно хоть в 100 раз ускорить, но общее ускорение никто не заметит. Нужно профилировать не кусок кода, а весь код и смотреть по ситуации. Я потому и спросил, в какой реальной задаче std::map можно заменить чём-то другим и получить ускорение всей задачи, а не только поиска по std::map.
Автор клоун, статья - рекламный высер.
О, а вот и одно очень дружелюбное коммьюнити подтянулось... мгновенный переход на личности с первого комментария.
Переход на личности - это не хорошо, но статья на самом деле плохая. Передергивание фактов, умалчивание проблем языка. Нужно признавать ошибки и стараться их решать, помогать их решать. А когда C++ рекламируют, тем что он незаменим, это же глупость. Нет незаменимых. Это же не автор статьи решает, это решает руководитель проекта, владелец бизнеса и тд.
Я сам разработчик на C++. Я знаю язык достаточно чтобы утверждать, что язык устарел. Но при этом в нём ещё есть порох. Ситуация с C++ это «суперпозиция». С одной стороны в самом языке всё есть для написания хорошего кода, с другой у языка есть комитет и стандартная библиотека. Если разрабатывать высокоуровневый код для прикладных программ, то стандартная библиотека очень помогает. Спускаешься на «нижний» уровень, стандартная библиотека начинает мешать. А без стандартной библиотеки C++ практически превращается в C, но с более удобным синтаксисом, но с менее очевидным поведением компилятора. То есть C++ есть за что ругать. И за это его и ругают. Нужно просто, как я уже писал, это не скрывать, а демонстрировать пути решения. А большинство рекламных статей наоборот всё переиначивают. Будто С++ был создан сверхлюдьми. Он был создан людьми. Именно поэтому у него есть проблемы. Как у других языков. Как у Rust, неоднократно упоминаемого в сравнении с C++. Rust повезло тем, что он разрабатывался с оглядкой на проблемы C++, но даже это не спасло его от проблем
без стандартной библиотеки C++ практически превращается в C, но с более удобным синтаксисо
вот именно что нет, он остаётся С++
А то как устроена стандартная библиотека стало возможно потому что С++ такой какой он есть, на С(и на Java и на C# и на растеЕ) просто невозможно написать такие абстракции, которые написаны в С++ в stl
[x // 2 for x in list if x % 2 == 0]
Автор ни разу не писал на Python? Иначе зачем использовать встроенную функцию в качестве названия переменной? Или это ChatGPT вам такой пример выдал?
Цель языка Python и большинства подобных - оторваться от уровня реального железа,
одна из основных целей языка С/С++ - НЕ потерять связь с железом при этом по возможности ее скрывать.
Чтобы это понять нужно попробовать ответить на вопросы:
В каком еще языке можно писать ассемблерные вставки? Как быть с кодом в котором приходится использовать ассемблерные вставки при переходе на какой-то вновь изобретенный язык? А какие еще языки так же просто разрешают работу с регистрами?
Почему низкоуровневый код вообще на С пишется в основном?
В общем возникает вопрос:
Какой смысл сравнивать синтаксис языков созданных для разных целей?
Но, хотя, наверно, это прикольно, и наверно даже вполне полезно, если ты понимаешь что разница предопределена целеполаганием.
Если коротко подытожить, то ответ на вопрос почему плюсы не устаревают примерно таков:
Потому что на них тоже вполне можно говнокодить!
Особенно ужаснул пример с вектором который куда то мувается при создании класса.
Что это почему это... я ничего не понимаю.
Есть же с 11х плюсов как минимум синтаксис для приема аргументов в виде ссылок:
Schoolmates(std::vector<Students> &students) {}
То что в языках типа джаваскрипта все объекты по дефолту передаются в виде ссылок то это не потому что там сборщик мусора есть, а в плюсах нет. А потому что в плюсах есть ссылки и поинтеры, а в джаваскриптах их нет. В php например ссылки есть и функции/методу можно передать в виде ссылки не только массив / объект, но и простую переменную по которой функция будет записывать/читать значения на стеке выше. Не смотря на то что это скриптовый язык со сборщиком мусора. Вообще сборщик мусора это только про долгоживущие объекты т.е. созданные через new (или malloc ) в Си или плюсах каждый такой объект надо руками удалять, тогда как в джаве их сборщик мусора сам удаляет если они больше ниоткуда не видны. А обычные стековые объекты самоуничтожаются при выходе вместе с куском стека в котором бы.
Есть же с 11х плюсов как минимум синтаксис для приема аргументов в виде ссылок:
ссылки появились... немного раньше чем С++11
И в примере всё было правильно, а у вас какая то дичь написана с бесполезной ссылкой
в Си или плюсах каждый такой объект надо руками удалять
не надо, прочитайте статью
Я и написал что минимум, ранние плюсы просто не застал.
не надо, прочитайте статью
В статье не дано никаких разъяснений. Открыл документацию по плюсам:
std::string str = "Salut";
std::vector<std::string> v;
v.push_back(str);
std::cout << "After copy, str is " << std::quoted(str) << '\n';
v.push_back(std::move(str));
std::cout << "After move, str is " << std::quoted(str) << '\n';
std::cout << "The contents of the vector are { " << std::quoted(v[0])
<< ", " << std::quoted(v[1]) << " }\n";
/* After copy, str is "Salut"
After move, str is ""
The contents of the vector are { "Salut", "Salut" }*/То есть оно просто вместо копирования меняет данные на стеке, полезно если структуру или вектор заполняли только для того что бы передать объекту и забыть про них, но это точно никакого отношения к долгоживущим объектам и их очищению не имеет.
Кроме того в примере из статьи при вызове конструктора данные сначала копируются в его контекст (так как как я и написал не проставлена ссылка), а потом героически переносятся в объект.
Кроме того в примере из статьи при вызове конструктора данные сначала копируются в его контекст (так как как я и написал не проставлена ссылка), а потом героически переносятся в объект.
Но ведь это не так.
std::vector<Students> foo()
{
[...]
}
std::vector<Students> v;
Schoolmates s1(foo()); // Нет ни одного копирования
Schoolmates s2(std::move(v)); // Нет ни одного копирования
Schoolmates s3(v); // Одно копирование, которое было бы в любом случаеВ статье не дано никаких разъяснений.
Статья предполагает хотя бы базовое знакомство с языком, а у вас оно отсутствует.
В статье std::move() вызывается в контексте конструктора, а не в контексте того, где его (конструктор) вызывают.
Манипуляция не пройдет.
Статья предполагает хотя бы базовое знакомство с языком, а у вас оно отсутствует.
Где предполагает? Классы из библиотеки libstdc++ это база языка? Не знал.
Простите, что ворвусь в диалог.
Классы из библиотеки libstdc++ это база языка?
Тут есть нюанс. Программист на С++ фактически обязан знать стандартную библиотеку языка. В текущее время вообще считается, что программист на любом языке программирования обязан знать возможности стандартной библиотеки этого языка. Но с C++ несколько иначе. Некоторые особенности языка неоднозначны. И отрицательные последствия использования этих особенностей нивелируются за счёт возможностей стандартной библиотеки. И поэтому программиста на C++ очень легко можно определить. Знаком ли он с этими особенностями. То есть знание стандартно библиотеки для программиста на C++ это база
и вызове конструктора данные сначала копируются в его контекст, а потом героически переносятся в объект.
Да, это действительно очень непривычно для тех, кто не знаком с мув-семантикой, и кажется, что происходит так как вы написали. Но в реальности, всё лучше: данные копируются или муваются в его контекст. И вот второй случай как раз благоприятный для нас. А если данные не смогли мувнуться в конструктор - что ж, значит копирования не избежать. Тогда в принципе без разницы, в какой момент сделать это копирование: при переносе в контекст конструктора, или внутри конструктора.
move-семантика не такая самоочевидная штука, и нужно неплохо вникнуть в неё, чтобы понять, что передача по значению - единственный верный способ в современном C++.
move-семантика не такая самоочевидная штука, и нужно неплохо вникнуть в неё, чтобы понять, что передача по значению - единственный верный способ в современном C++.
Я бы, всё же, не обобщал. В гугловском протобафе, вот, вставку строк сделали через получение std::string по значению. В результате, если работаешь через интерфейсы, то за всей их виртуальщиной компилятор ничего оптимизировать не может, и получится мув при передаче, и ещё один мув при переносе в поле-член. Вот такая вот экономия на лишней перегрузке получилась: мелочь, а таки платим за то, что не используем.
То есть оно просто вместо копирования меняет данные на стеке, полезно если структуру или вектор заполняли только для того что бы передать объекту и забыть про них, но это точно никакого отношения к долгоживущим объектам и их очищению не имеет.
К долгоживущим объектам и их очищению имеют отношение unique_ptr и shared_ptr.
нет, ничего компилятор здесь не уберёт и не может, RVO/NRVO контексты в появляются как раз при передаче по значению
const & как раз создаст лишнее копирование, потому что чтобы передать значение придётся его создать, т.е. foo(bar()) даже если возвращается из bar() вектор по значению будет лишний раз скопировано внутри foo, т.к. вы в foo принимаете константную ссылку
Что проверять-то? Ну будет copy, которого можно избежать
в исходном примере 0 копирований, один мув
В "исходном примере" ничего никуда не перемещается:
https://godbolt.org/z/jd5vjWv9f
Program returned: 0
Program stdout
class ctx students: 3
main ctx students: 3А вызывается копирование вектора при передаче в конструктор, что логично. И только когда мы в конструкторе указываем что вектор принимаем ссылкой:
https://godbolt.org/z/d4T8b1W45
Program returned: 0
Program stdout
class ctx students: 3
main ctx students: 0Происходит перемещение данных вместо копии для чего и был придуман std::move.
Ваши примеры с пустыми классами да еще с -O3 непонятно вообще о чем и про что.
ты в конструктор то мувни, по лвалуе ссылке он принимает и мувает оттуда. Что ж за люди такие
Если "мувает" тот кто вызывает https://godbolt.org/z/Pj3aGn1f6
тогда мув внутри конструктора просто не нужен, о чем вообщем то и начался разговор. А если предполагается реализация поведения как у раста, когда при передаче массива куда либо, он исчезает из текущего контекста, то тогда надо проставлять ссылку.
Здесь же мы имеем "пример использования мува" который полагается на то, что ему мувнут данные где то там на стеке выше, а у него мув просто так для галочки. Причем этот мув для галочки еще и вызывает дополнительные накладные расходы без пользы и смысла.
Это хорошо если по два, а если конструктор принимает скажем 4 аргумента?
Немного вмешаюсь.
Соглашусь, что читать сообщения об ошибках в шаблонах бывает сложно, но это проявляется в сложных шаблонах. В большинстве случаев это дело привычки.
Это от части заблуждение. Тем более в этом случае. Инстанцировать шаблон, скопировав ветку ast и подставив типы раз в 100 быстрее, чем парить 16 деклараций конструкторов класса с учётом всех неоднозначностей грамматики и семантики языка. Если очень хочется, можно написать явные инстанцирования, или явные специализации в cpp файле.
Тут конечно не поспоришь. Правда это имеет смысл только с динамической линковкой. Правда не стоит забывать, что inline функции могут хорошо оптимизироваться компилятором, что в итоге сыграет в плюс.
Разбудите меня через 0x100 лет и спросите, что делают в Яндексе. И я отвечу -- пишут статьи о том, что альтернатив C++ нет.
Ждем от яндекса через 2-3 года переход с C++ на Carbon, считаю необходимым назначить тимлидом команды, которая будет переводить весь легаси яндекса на карбон автора статьи)
но уже сейчас понятно — если C++ языку ищут замену, значит, её нет.
Полнейшая чушь. Из-за большой кодовой базы переход на другие языки условному бизнесу не выгодны. На время перехода нужно держать две команды разработчиков, одна на C++, другая - на том языке, на который идёт переход. Неясны перспективы перехода, там может быть махровое легаси с огромным техническим долгом, которое работает за счёт хард-код хаков, и требуется фактически только переписывать с нуля. И еще и документация нужна, которой на изи может и не быть. А так как работает, зачем трогать?
C++ сейчас конкурирует с теми языками, что изначально разрабатывались для замены языка C++. Rust, Go, Odin, Jai, Nim, D, еще Carbon светится на горизонте. Только к 20-у стандарту коммитет стал осознавать, что если они ещё 10 лет промаринуются в своём болоте, то они начнут терять членов, а с ними и пользователей языка. Потому что некоторые альтернативы и вправду очень не дурно выглядят на фоне C++
А где проблема с поддержкой честных модулей? Формально она как бы недавно появилась,но практически все SKD и библиотеки, которые приходится использовать, никто под модули переделывать не торопится. А отсюда долгое время компиляции и костыльные решения для ее осуществления.
Потому что поддержка на самом деле так и не появилась. Клочки модулей есть по разным компиляторам, но полноценной поддежки пока нет ни у кого, насколько мне известно. Под какие-то из этих имплементаций в CMake внедряется поддержка оных, но пока что всё довольно плохо с ними. Потому никто и не спешит
Главная проблема С++ - что в него постоянно добавляют что-то новое. В итоге язык превратился в свалку разных подходов и парадигм, слабо совместимых друг с другом. И код, написанный на С++ разными людьми, часто выглядит как код на разных языках. На мой взгляд, следовало бы заморозить его в 98 году, а все новое делать уже в рамках других, специализированных языков, и не тащить груз совместимости.
а все новое делать уже в рамках других, специализированных языков
Так это и так мог делать кто угодно. А комитет как раз заинтересован в совместимости (не смотря ни на что).
а все новое делать уже в рамках других, специализированных языков
Ага и назвать его C++++, хотя погодите-ка...
В любой живой язык добавляют новое, от этого никуда не деться...
Всё это позволяет сделать вывод: C++ хоть и старый язык, но вовсе не устаревший.
И здесь я тоже сделаю ремарку. C++ таки устарел. Но из-за огромной существующей кодовой базы его тащат. И будут тащить пока это выгодно условному бизнесу. Нововведений в сам язык не так много. Большая часть, так называемых, нововведений языка - это очередное раздувание стандартной библиотеки. При чём часть вещей в стандартной библиотеке - это костыли для избавления от выстрелов в ногу от добавленных ранее вещей. Я до сих пор кекаю с std::move
Вот ребят не знаю я... Сложное у меня к плюсам отношение. Мой основной опыт работы - электроника, встроенные системы и т.п. Там очень важна "прозрачность" языка. Т.е. чтобы посмотрев на код, было более не менее понятно, во что это превратит компилятор. Одно дело если программа работает на столе у бухгалтера. И совсем другое дело, если она управляет коробкой скоростей автомобиля. Полезет она за каким-нибудь умным указателем в интернет, и что тогда ??? Поэтому пишу я практически на чистом С. Очень осторожно используя свойства ++, там где это реально оправдано и безопасно. Во всяком случае никогда не использую шаблоны, перезагрузку операторов и т.п. И мне вполне хватает. Мне вообще немного непонятна мотивация развития современного С++. Исходно это системный язык не слишком высокого уровня. Главное требование к такому языку - "прозрачность" кода, а не абстракции. Для абстракций есть языки куда более приятные. Прошу прощения если кого-то обидел, я не ради флейма, а просто высказаться. Во всяком случае спасибо автору за отличную статью.
Кстати, C++ уже и до Windows-драйверов добрался, правда, там почти для всего надо изобретать свои велосипеды. См., например, Developing Kernel Drivers with Modern C++ - Pavel Yosifovich
Он туда добрался уже лет 20 как. Я на своей первой работе в 2006 году ковырял виндовые драйвера на плюсах.
Не, ну это как бы уже давно. И я ещё успел драйвера под винду на плюсах немного пописать. Я немного о другом. О жестком реальном времени и довольно ограниченных ресурсах. Например запихнуть серьёзную задачку в STM32 причем не самый крупный. Вот там действительно приходится внимательно следить за тем что делается и как оно делается. И тут плюсы скорее вредят, чем помогают. Кстати и Rust у меня по этой же причине не пошел. Непонятный он какой-то... Хотя вроде затачивался тоже в том числе под bare metall. Впрочем может у меня просто руки кривые и голова туповата.
Полезет она за каким-нибудь умным указателем в интернет, и что тогда ???
По этой причине мы пишем для встроенных систем на Haskell!
Может, это не совсем "тру" программирование железок, но в последних версиях Arduino IDE подвезли фичи C++20. Там и шаблоны есть, и лямбды, и много чего еще.
Да нет, почему не совсем тру ! Самое что ни на есть тру, пожалуй даже трулялистее многого другого. Ибо дуньки как правило мелкие (те же AtMega) и за тем во что превращается код, там надо реально следить. А подвезли - очень просто. ЧТОБ БЫЛО. Мода, ничего не поделаешь. Более того, куча народа этим будет пользоваться ! Особенно начинающие. Пока с накоплением опыта не убедятся, что лучше этого не делать. Я сейчас читаю книжку Anton's OpenGL 4 Tutorials https://antongerdelan.net/opengl/ (кстати хочу перевести её на русский и бесплатно выложить для всех желающих, автор мне разрешил). Казалось бы совершенно другая область. И таких суровых ограничений там нет. Тем не менее автор про себя говорит что тоже пишет в моем стиле и всем его рекомендует. Увы, программирование последние лет 30 развивалось во многом под действием хайпа и самой злокачественной рекламы. То всё должно быть объектно-ориентированным, то с паттернами носятся как с писаной торбой. Старички вроде меня ещё помнят "венгерскую нотацию", про которую слава Творцу сейчас забыли. Сейчас (опять таки слава Творцу) положение начинает потихоньку выправляться. Разум возвращается.
Я сейчас читаю книжку Anton's OpenGL 4 Tutorials https://antongerdelan.net/opengl/ (кстати хочу перевести её на русский и бесплатно выложить для всех желающих, автор мне разрешил). Казалось бы совершенно другая область. И таких суровых ограничений там нет. Тем не менее автор про себя говорит что тоже пишет в моем стиле и всем его рекомендует.
Т.е. вы рекомендуете в C++ писать вот в таком стиле:
int main() {
// start GL context and O/S window using the GLFW helper library
if (!glfwInit()) {
fprintf(stderr, "ERROR: could not start GLFW3\n");
return 1;
}
...
GLFWwindow* window = glfwCreateWindow(640, 480, "Hello Triangle", NULL, NULL);
if (!window) {
fprintf(stderr, "ERROR: could not open window with GLFW3\n");
glfwTerminate();
return 1;
}
Реально? (Речь прежде всего о рукопашном вызове glfwTerminate).
Смотря где и когда. Если Вы в этом деле новичок (как я), то так и только так, и никак иначе. Всё нужно вызывать собственными ручками и видеть это в коде. Тогда рано или поздно (скорее рано) придет понимание того как это всё работает. Почему мне кстати не нравятся книги Алекса Борескова. Если Вы уже достигли какого-то опыта и понимания, разумеется всё это будет завернуто в некие обертки (как это делает Боресков). Впрочем ни на чем не настаиваю. Я сейчас активно осваиваю современный OpenGL (занимался этим последний раз лет 20 назад, сейчас он совсем другой), и мне просто так легче учиться. У других могут быть другие предпочтения.
Если Вы в этом деле новичок (как я), то так и только так, и никак иначе.
Простите, а зачем вам вообще C++? Ну т.е. если вы сходу отказываетесь от его преимуществ.
Байки про суровое реальное время можно не рассказывать.
Например очень удобная штука классы, виртуальные функции и т.п. Я не против ++. Я исключительно за разумное и оправданное применение этих возможностей. Не слишком затемняющее код.
Например очень удобная штука классы
Особенно их деструкторы. Но вы шлете их лесом, потому что сперва нужно вызывать функции вроде glfwTerminate вручную.
виртуальные функции
Не слишком затемняющее код.
Ну да, ну да. А шаблоны они вот прям нипанятнашта с кодом делают. На фоне косвенных виртуальных вызовов. Ага.
Я исключительно за разумное и оправданное применение этих возможностей.
Звучит как за все хорошее против всего плохого.
Звучит как за все хорошее против всего плохого..
Да, вобщем-то где-то так оно и есть... Ну не за всё же плохое мне быть против всего хорошего ! Можно сказать, что скорость байка ограничивается в первую очередь видимостью на дороге. Способны Вы видеть, во что разворачиваются конструкции языка - пользуйтесь ради бога ! Нет - лучше воздержитесь. Особенно если программа управляет чем-то реальным и небезопасным.
Способны Вы видеть, во что разворачиваются конструкции языка - пользуйтесь ради бога ! Нет - лучше воздержитесь.
Именно поэтому вы:
Во всяком случае никогда не использую шаблоны, перезагрузку операторов и т.п.
Это все генерирует гораздо худший (со всех точек зрения) код, чем виртуальные вызовы. Конечно же.
А кто Вам сказал что я ВСЕГДА отвергаю шаблоны и ВСЕГДА пользуюсь виртуальными вызовами ??? Неприятность с шаблонами в том, что их сложность быстро нарастает, по мере того, как человек что называется входит во вкус. И скоро сам становится не в состоянии контролировать свой код. Особенно когда вернется к нему года через три после написания. Ещё раз, я целиком и полностью за любые языковые фичи. Но там где во-первых они оправданы, и во-вторых не приводят к потере контроля. Если Вы гуру в С++, наверно можете творить всё что душе угодно. Мои знания (а особенно самоуверенность !) куда скромнее. Поэтому я предпочитаю осторожность и консерватизм.
Ну послушайте, я же ничего не выдумываю, я вам привожу ваши же слова из вашего же комментария. Вот они в более развернутом контексте:
Поэтому пишу я практически на чистом С. Очень осторожно используя свойства ++, там где это реально оправдано и безопасно. Во всяком случае никогда не использую шаблоны, перезагрузку операторов и т.п. И мне вполне хватает.
Тут же русским языком по белому написано "никогда не использую". Как по мне, так "никогда не использую" тождественно "ВСЕГДА отвергаю".
Хотя, судя по другим вашим комментариям, вы в одном месте говорите одно, а в другом -- другое:
Мне надо было реализовать это на FPGA, для чего конвейеризовать алгоритм. Я написал это с использованием шаблонов и перезагрузки операторов.
И вот непонятно, чему в ваших простынях текста верить: тому, что вы "никогда не используете шаблоны" или тому, что вы на шаблонах написали быстрое преобразование Фурье по алгоритму Кули-Тьюки.
И вот непонятно, чему в ваших простынях текста верить: тому, что вы "никогда не используете шаблоны" или тому, что вы на шаблонах написали быстрое преобразование Фурье по алгоритму Кули-Тьюки.
Чего непонятного-то ??? Я пользуюсь только тем, что в данной конкретной задаче ОПРАВДАНО и УМЕСТНО. Принцип KISS слыхали ??? Keep It Simple, Stupid ! Вот это именно оно и есть.
Чего непонятного-то ???
Непонятно как можно говорить, что вы "никогда не используете шаблоны", если вы их таки используете там, где это уместно.
Возможно, вы какой-то специальный смысл вкладываете в слово "никогда".
Я где-то утверждал, что я вообще не знаю что такое шаблоны и как они работают ??? Я где-то утверждал, что не пользуюсь (хотя и с осторожностью) средствами которые в задаче вполне уместны ??? Не знаю какой смысл я вкладываю в слово "никогда", но Вы мне кажется пришли сюда исключительно чтобы почесать своё ЧСВ овер 80-го левела. Извините коллега, но мне такие разговоры не интересны. С Вашего позволения хочу пожелать Вам хорошего вечера (или незабываемой ночи) и откланяться.
Я где-то утверждал, что не пользуюсь (хотя и с осторожностью) средствами которые в задаче вполне уместны ???
В общем-то да. Цитаты я уже дважды приводил, повторять не буду. Из вашего стартового сообщения практически однозначно следует, что вы просто никогда не используете шаблоны и перегрузку операторов поскольку это делает код непредсказуемым в ваших условиях.
Плохо здесь то, что неопытные разработчики прочитают мнение "гуру с десятилетиями опыта в рил-тайме" и вынесут для себя "что в рил-тайме ни шаблоны, ни перегрузка операторов не используются". Что, мягко говоря, будет не совсем правильным выводом.
Дорогой коллега, повторяю в тысячу первый раз. Для тех кто даже не в танке, а в бронепоезде. Применяется абсолютно всё, что разработчик знает и умеет (если конечно оно не противоречит стандартам кодирования принятым в команде). Самоограничение (если мы говорим о realtime) только одно. Четкое понимание, во что примерно это превращается компилятором. Понимаешь во что превращаются твои шаблоны - ради бога ! Не понимаешь - лучше реши задачу как-то по-другому. Это единственное что я хотел сказать. В десктопной разработке это ограничение существенно мягче. Там можно позволить себе больше.
Так а что заставило вас написать что вы никогда не используете шаблоны и перегрузку операторов? Вы не понимаете во что это разворачивается? Вы увидели, во что разворачивается и убедились, что получается ужас-ужас и что лучше все делать в стиле старого-доброго Си?
PS. Вопрос вызван тем, что мне сложно представить, чтобы какой-нибудь условный std::min/std::max, будучи шаблоном, приводил к каким-то фатальным последствиям для написанного для real-time кода.
Знаете, у меня сложилось впечатление, что Вы либо очень крутой гуру в С++, либо у Вас очень мало практического опыта в разработке. Расскажу одну поучительную историю. В СССР при найме водителей-дальнобойщиков был такой довольно жесткий тест. Человеку показывали глубокую яму, с битым стеклом. Ставили в 5 метрах от края, завязывали глаза и предлагали идти вперёд. Тех кто отказывался идти вообще, не брали. Тех кого приходилось ловить на краю ямы, тоже. Брали тех, кто спокойно проходил 3 метра, но потом его трактором не сдвинешь. Подумайте, как это соотносится с использованием тонких мест С++ в практической разработке.
Знаете, у меня сложилось впечатление, что Вы либо очень крутой гуру в С++, либо у Вас очень мало практического опыта в разработке.
Вы не угадали ни там, ни там.
Но я (да и полагаю, не только я) был бы признателен, если бы вы оперировали фактами, а не аналогиями. Типа: использовал такой-то шаблон с таким-то компилятором, убедился, что генерируется туева хуча одинакового кода в разных единицах трансляции, которые затем не убираются линкером и это оказалось недопустимо, переписал на вызовы Си-шных функций и количество кода пришло в норму.
Почему бы при программировании железок не использовать шаблоны (например, чтобы не писать повторящийся код для разных типов данных), auto и какие-нибудь инициализации вроде ={}? Среди прочего, это уменьшает вероятность ошибок в каких-то случаях. Лямбды, например, сужают область видимости - позволяют что-то внутри посчитать и результат вычисления выдать в неизменяемую переменную, которая объявлена как const.
Я как-то сделал учебный проект на Arduino с наследованием классов и виртуальными функциями. Подменяешь один класс-потомок на другой, и на экранчике светодиоды начинают другую анимацию показывать. И добавить еще одну анимацию очень просто - добавляешь еще один класс-потомок с другим алгоритмом, из базового класса при этом один и тот же код в цикле вызывает одну и ту же функцию.
Я не знаю, о каком хайпе идет речь - если есть удобный инструмент, позволяющий решить задачу, почему бы им не воспользоваться?
Целиком и полностью согласен. Моя первая программа, совершенно сознательно написанная на С++, была вычислением быстрого преобразования Фурье по алгоритму Кули-Тьюки. Мне надо было реализовать это на FPGA, для чего конвейеризовать алгоритм. Я написал это с использованием шаблонов и перезагрузки операторов. А потом просто заменил комплексные числа, на некий класс, сбрасывающий в лог граф вычислений. Откуда конвейерная схема для FPGA получилась уже достаточно прозрачно. Да, это можно было бы написать и на С. Но куда менее удобно. Однако такие задачи у меня были не слишком часто. Куда чаще жесткое реальное время и весьма ограниченные ресурсы. Отсюда и мой стиль... Ещё раз, я не против удобных инструментов. Но только там, где их применение оправдано.
del
Как же мне не нравится std::move...
Мы буквально не можем использовать переменную, которая после передачи в функцию может перестать быть инициализированной.
То есть у нас код, в котором переменная которая нормально работает(и мы, может быть, даже в начале проверили что она ввлидная) в один прекрасный момент достаточно прозрачно и незаметно становится невалидной.
Простите, но я лучше буду пользоваться указателями.
после передачи в функцию может перестать быть инициализированной.
не может
незаметно становится невалидной.
не становится, ну либо вы сами такой кривой тип написали(не соответствующий требованиям мува)
Ну не невалидной, а in unspecified state. Какая разница. Пользоваться без переинициализации ей больше нельзя, но компилятор об этом ничего не скажет. Да, в собственном классе можно написать какой угодно specified мув, но это не отменяет того, что стандартные контейнеры из STL ведут себя так, как я написал выше. И что их использование, что написание своих мувов это один сплошной footgun
пользоваться можно, это буквально тоже самое, что просто изменить вектор
vector x;
change(x);
по вашему это уже "footgun", ведь 'x' изменился
Это не буквально тоже самое. Как много вы видели конструкторов объектов, которые изменяют состояния входящих объектов? Ожидаете ли вы такого поведения от конструктора? Ожидаете ли вы в принципе, что конструктор что-то меняет во внешних переменных?
Часто ли вы используете функции, которые меняют состояние переменных непредсказуемо? То есть вы даже посмотрев на код функции не можете сказать, в каком состоянии будет переменная.
И вся эта мув семантика без проблем заменяется умными указателями. С абсолютно понятным и предсказуемым поведением. Причем при работе с указателями любой класс будет себя вести одинаково. И вот этого "вы сами написали кривой класс" не имеет значения, потому что класс в перемещении указателя не фигурирует.
Мув семантика - это костыль, которые прикрутили, потому что народ боится указателей. Но указатели есть и будут важной частью плюсов. Не любишь указатели - просто выбери другой язык. Не надо из-за этого костыли прикручивать.
И вся эта мув семантика без проблем заменяется умными указателями. С абсолютно понятным и предсказуемым поведением.
В целом согласнен, но с указателями в какой-то момент всё упирается в производительность, а мы же про С++ говорим.
Мув семантика - это костыль, которые прикрутили, потому что народ боится указателей.
Не согласен. Мув семантику прикрутили как оптимизацию. Чтобы можно было создать скажем вектор на стеке, избежать лишней аллокации и double indirection при его использовании, но при этом потом всё равно суметь его мувнуть. Или чтобы внутри вектора можно было эффективно свапать произвольные T, лежащие по значению, а не только скажем указатели и стандартные классы (для которых гипотетически могли написать те же мув костыли, но не публикуя их как часть стандарта).
Надо было просто делать как в расте. Чтобы компилятор знал про moved out состояние и запрещал его использовать. Ну и move by default в расте это очень круто, но в плюсах этого конечно не будет, потому что совместимость
Был бы на уровне компиляции запрет на использование объекта после move - у меня и вопросов бы не было. А так добавили еще один инструмент, который делает код плохо поддерживаемым.
Какую проблему вы видите с указателями? Мув почти никогда не беспатный. Да, он дешевый, ну так и копирование shared указателя дешевое.
Ну я же написал: лишние аллокации и indirection. Для каких-то кодбаз кстати даже копирование shared_ptr слишком дорогое, потому что оно атомарное, а это не всем нужно. Поправьте, если я неправ, но разделения аналогичного Rc/Arc в плюсы ещё не завезли.
копирование shared указателя дешевое
С инкрементом refcount и гарантиями атомарности, которые даёт shared_ptr, - уже не дёшево
Мув из раста работает только для локальных переменных и то частично
struct X {
A a;
B b;
};
X value;
auto y = std::move(value.a); // как это сделать с деструктивным мувом?
vector<X> vec = ...;
auto x = std::move(vec[5]); // тоже никак
Насколько я знаю, эту ситуацию постепенно улучшают. В первом случае b всё ещё можно использовать. И value тоже можно будет, если переинициализировать a в той же функции. Либо, в случае с такой POD структурой, можно вообще её деструктурировать в отдельные переменные и потом собрать новую.
С вектором вероятно сложнее. Но если мы заранее знаем новое значение для мувнутого элемента, то тут достаточно std::mem::swap() с локальной переменной. Или даже если не знаем, но для элемента реализован Default.
Я сейчас в дороге с телефона, так что неудобно в подтверждение писать код или искать ссылки, извините.
Тут нечего сказать, вы абсолютно некомпетентны. Умные указатели вместо мув семантики это надо выдумать
Про некомпетентность рассуждает человек, который не знал что стандартные типы после мува по стандарту имеют Undefined State.
Поправочка, valid but unspecified state ? Люблю плюсы, столько разных слов на un
Использование переменной в Undefined State ведет к Undefined Behaviour.
Это и к вопросу "это тоже самое что change(x)" - после change(x) - состояние x вполне определено и не меняется от реализации компилятора. после move - переменную нельзя использовать ни для чего кроме повторной инициализации.
Простите мою педантичность, но нет, в общем случае не ведёт. Компилятор не сделает что угодно (как при UB), он сделает именно то, что написано в реализации конкретной стандартной библиотеки для этого контейнера. Если в реализации написано занулить мувнутый вектор, значит с этой библиотекой читать его size абсолютно безопасно и всегда вернётся 0. UB может произойти только косвенно, например если попытаться прочитать элемент, не проверив size. Но это не зависит от того, вектор мувнутый или просто пустой. Просто надо проверять состояние объекта после мува. Не обязательно делать unconditional переинициализацию. Но с духом поста я согласен, unspecified мутация это хуже, чем просто мутация.
я прекрасно знаю что у них за стейт, он VALID, т.е. все методы продолжают работать как обычно
по вашему это уже "footgun", ведь 'x' изменился
Как любитель функционального стиля, я скажу да ? Но если серьёзно, то да, тут вы правы, по сути это обычная clobbering мутация (в случае стандартных контейнеров). Но блин, введение мув семантики всё равно же потребовало изменений на уровне языка: как минимум синтаксис для rvalue references (&&). Кто им мешал на уровне языка сделать ещё и проверку как в расте, чтобы нельзя было использовать clobbered объекты? Хотя бы раз, хотя бы от единственного блин footgun защитить программиста? Хотя бы спустя 30 лет развития языка?
Кто им мешал на уровне языка сделать ещё и проверку как в расте
Отсутствие видимой конкуренции от Rust на момент введения move-семантики. Хоть Rust и 2006 года, мир его увидел в 2015 году. А к тому времени комитет решил проблему по своему через стандартную библиотеку
В 2015 вышел стабильный Rust 1.0. Судя по статье на вики, как минимум в 2012 был релиз 0.2. Мне лень копать, когда точно раст опубликовали. Ну и в целом про конкуренцию немного странный аргумент. У самого раста же тоже не было конкуренции с растом) И affine types уже были на тот момент исследованы в других экспериментальных языках, это не изобретение раста.
через стандартную библиотеку
В том-то и дело, что нет. Я же написал про rvalue references
Мне лень копать
А копать не нужно. Это просто знать надо, что move-семантика появилась в С++11 (2011 год). Но это лишь стандарт, а сама идея появилась раньше. И на момент появления идеи не было прямых примеров для такого, чтобы язык смог в себя это забрать. Потому что тогда это считалось нормой для низкоуровневых языков
Я не очень разбираюсь в C++, но поржал, спасибо
Статья изобилирует манипулятивными приёмами и неверными утверждениями.
1. Код на питоне в одну строчку, код на С++ - 6. Это не немножко сложнее, это фиаско.
2. Да, в С++ много избыточных копирований И перемещений.
Главное отличие в методе close — в C++ он не нужен. В Python вы обязаны самостоятельно позаботиться о закрытии файла. ... В C++ закрытие произойдёт автоматически, потому что момент удаления объекта строго определён. Это достигается благодаря отсутствию сборщика мусора.
В большинтсве случаев не обязаны:
with open(name) as f:
...
# тут файл будет автоматически закрытНе благодаря отсутствию сборщика мусора, а благодаря тому что в С++ есть такая фича. В Си, например, автоматического закрытия не сделать.
Сравнение в java некорректное. Неизвестно, в какой момент включится jit компиляция и изменит производительность. Мерять точно надо не так
Дело в том, что C++ полностью исключил вызовы функций при оптимизации.
Добро пожаловать в статически компилируемые языки. И в языках с jit такое тоже возможно.
Код на питоне в одну строчку, код на С++ - 6. Это не немножко сложнее, это фиаско.
код измеряется не в строчках, а в понятности для чтения, в С++ тоже это можно написать в одну, просто так будет менее удобно читать
В питоне код менее читаемый, хрен пойми что это вообще значит x for x in x
list.filter{ it % 2 == 0 }.map{ it / 2 }Вот это - простой, короткий и читаемый код на Kotlin. Код на Python - тоже простой и читаемый для тех, кто знаком с синтаксисом Python.
Код на С++ ни в каком виде не удобно читать из-за тяжеловесных объявлений лямбда-функций и вложенных неймспейсов.
namespace view = std::views;
auto even = [](int i) { return i % 2 == 0; };
auto half = [](int i) { return i / 2; };
auto range = view::all(list) |
view::filter(even) |
view::transform(half);
// покороче, но не сильно лучше
auto range = view::all(list) |
view::filter([](int i) { return i % 2 == 0; }) |
view::transform([](int i) { return i / 2; });Вся статья манипуляция ради рекламы курсов. И самое обидное, что до такого опускается Яндекс
Очередная демонстрация того, что Java бенчмарки лучше писать используя JMH.
Benchmark (size) Mode Cnt Score Error Units
MyBenchmark.index 10 avgt 5 4,431 ? 0,029 ns/op
MyBenchmark.index 1000 avgt 5 252,146 ? 0,791 ns/op
MyBenchmark.index 100000 avgt 5 26894,154 ? 900,024 ns/op
MyBenchmark.iter 10 avgt 5 5,582 ? 0,016 ns/op
MyBenchmark.iter 1000 avgt 5 248,616 ? 1,010 ns/op
MyBenchmark.iter 100000 avgt 5 27130,305 ? 1030,116 ns/opHidden text
@State(Scope.Benchmark)
@Warmup(iterations = 5)
@Fork(1)
@Measurement(iterations = 5)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class MyBenchmark {
@Param({ "10","1000","100000" })
int size;
List<Integer> ii;
@Setup
public void setup() {
ii = new ArrayList<>(IntStream
.range(0, size)
.mapToObj(i -> i)
.toList());
}
@Benchmark
public long iter() {
long s = 0;
for (int i : ii) {
s += i;
}
return s;
}
@Benchmark
public long index() {
long s = 0;
for (int j = 0; j < ii.size(); ++j) {
s += ii.get(j);
}
return s;
}
}В результате сложные и элегантные языковые конструкции при компиляции превращаются в простой и эффективный машинный код. В этом сила C++.
Вот эта мысль, по моему мнению, является самой важной в этой статье.
Не теряя удобства, получаем Результат.
Другая важная мысль - это почтенный возраст! Привычка - дело сильное. Многие программисты, уверенно шпарящие в C++, даже и не собираются переходить на что-то новое.
Я кончено в Яндексе не работаю и в команде «разработчик с++» не состою, но так вот случайно получилось что большую часть своей профессиональной жизни пишу на си крест крест, уан лав, все дела. Помню как с замиранием сердца включал заветный std=c++11 в gcc4.8, разбирался с мув семантикой и писал первую лямбду в продакшн коде. К сожалению, с++ остается инструментом в котором есть тысяча и один способ выстрелить себе в ногу и для того чтобы начинать новый проект на нем нужны очень, очень веские причины. С каждым новым стандартом порог входа становится все выше, для понимания почему комитет сделал так а не иначе нужно знать контекст в котором это решение принималось. После с++ переход на любой современный язык программирования это как пересесть с жигули на мерседес, от простоты и понимания что все может быть гораздо проще текут слезы. Но есть и хорошие новости - кода напилено столько что работы хватит всем и на долго
C++ мёртв для тех, кто хоть раз попробовал написать что-то на современных популярных языках.
C++ жив потому что инертную кодовую базу еще долго придётся тащить, и за это будут платить.
Утверждение неимоверно сильное и поэтому ложное. Я писал на всём "современном": Go, C#, даже чуть на TypeScript и Rust, а на D не только писал, но и преподавал. Особенно сильно у меня пригорело с C#, потому что я думал, что язык продвинутее и современнее старого C++, а по большинству моментов выяснилось обратное. Мы с коллегой даже начинали подборку "WTF это появилось сейчас, а не 15 лет назад", когда супер базовые (с нашей точки зрения) функции и классы появлялись только в самых последних версиях стандарта.
Есть не мало областей, в которых C++ практически на передовой дизайна языков. Да, своеобразно, да сложно, да тонна наследия и обратной совместимости, но после LINQ std::range выглядит как манна небесная.
Есть множество областей, где действительно можно поругать C++ за отсталость: отсутствие пакетного менеджера (CMake FetchContent для меня решает проблему, но не идеально), слабые гарантии безопасности с повсеместным UB, и так далее. Но почему-то я чаще вижу, что его ругают необосновано те, кто не осилил даже синтаксис.
1) Претензия #1: слабая стандартная библиотека? нет генераторов?
std::generate + insert iterators кажется еще в c++98 были, это раз. STL, имхо, одна из лучших библиотек коллекций. Ну а list comprehensions, std::ranges... просто взгляните на Scala, и поймете, что и то, и другое - одинаково убоги
2) Претензия #2: много избыточных копирований?
из плюсов убрали указатели, а я не заметил? rvalue reference, там, move semantics уже 12 лет как существуют
3) Претензия #3: нет GC?
нет GC - есть RAII. GC не собирает сокеты/файлы, RAII - можно ненароком сделать цикл из shared_ptr. И то, и другое - одинаково неудобно. Имхо, в Scala есть GC, и со ScalaARM, или bracket и тд как-то живем. С точки зрения производительности RAII лучше, не надо stop-the-world и накладных расходов на него (в java они большие)
4) Претензия #4: плохой ввод/вывод?
мм, меня как-то std::istream/ostream всегда устраивали, не сказал бы, что где-то еще он прям сильно лучше
5) Претензия #5: нет пакетов
раньше обходились пакетным менеджером системы, но да, по сравнению с java - отстой
6) Претензия #6: сложность в изучении
Книги Майерса "55 граблей C++", "Еще 35 граблей C++", "50 граблей STL" не дадут соврать) Но справедливости ради, у java тоже есть подобный труд от Д. Блоха, только потоньше.
Шаблонное программирование - читаем Александреску "Как я поел грибов современное проектирование на C++" и просвещаемся, тем более книге 20 лет
Про будущее C++
https://www.youtube.com/watch?v=ELeZAKCN4tY
IMHO, оно лучезарное.
C++ фарева! :)
Почему C++ не устаревает