Для бизнес-приложений очень важна возможность быстро сформировать нужный отчёт. Для этого, в частности, важно быстро получить результат запроса (часто – очень сложного запроса) к СУБД. Что не всегда просто, потому что с этой СУБД работают на чтение и запись тысячи (а иногда - десятки тысяч) пользователей.
Чтобы не нагружать рабочую СУБД запросами для отчетов мы разработали механизм копий баз данных, копирующий данные (все или их часть) из рабочей БД в отдельную БД для отчетности. Пользователи могут строить отчеты на «отчетной» БД, быстрее получая результат и не нагружая рабочую базу.
Для дальнейшего ускорения формирования отчетности мы разработали Дата акселератор — собственную SQL-совместимую in-memory базу данных, ориентированную на максимальную производительность в задачах OLAP. Дата акселератор может использоваться в качестве «отчетной БД» и позволяет существенно (иногда – на порядки) ускорить формирование отчетов.

В ходе разработки Дата акселератора мы, конечно, не могли пройти мимо возможности ускорить исполнение запросов при помощи JIT-компиляции. Для этого мы используем LLVM — проект, который в силу доступности, открытости и активного развития стал фактически стандартом для задач такого рода.
В интернете, в том числе и на Хабре, достаточно информации о том, как устроен LLVM и о его внутреннем представлении (IR, Intermediate Representation), поэтому в этой статье мы сфокусируемся на том, как устроена генерация кода для исполнения SQL-запросов на высоком уровне, а также на управлении получившимся кодом.
JIT-компиляция
JIT-компиляция — это способ увеличения производительности программных систем, исполняющих заранее неизвестный код, путем компиляции специализированного машинного кода непосредственно в процессе работы системы. В случае Дата акселератора заранее неизвестный код — это поступающие от платформы 1С:Предприятие SQL-запросы для построения отчетов.
JIT-компиляция в нашем случае служит альтернативой интерпретации, при которой в системе имеется набор предварительно скомпилированных обобщенных алгоритмов, способных работать с любыми данными и произвольно комбинироваться друг с другом. К сожалению, такой подход влечет неизбежные накладные расходы, которые ограничивают производительность.
Компиляция кода во время исполнения запроса позволяет создавать высокоспециализированные версии алгоритмов, которые точно знают, как и с какими данными они работают, не содержат избыточного кода и лишних проверок, благодаря чему возможно существенное увеличение скорости работы системы.
Обзор системы обработки запросов
При обработке запроса Дата акселератор придерживается стандартной для большинства СУБД схемы:
парсинг (лексический и синтаксический анализ, проверка существования таблиц и типизации данных, построение исходного логического плана запроса);
оптимизация логического плана;
построение физического плана (выбор алгоритмов для различных операторов, разбиение запроса на отдельные задачи);
исполнение запроса.
Таким образом, система исполнения запросов работает с физическим планом — по сути, графом задач. Каждая задача в плане представляет собой дерево операторов, в каждом из которых выбран необходимый алгоритм, описано размещение данных в таблицах и временных структурах.
Система исполнения состоит из двух основных движков — интерпретируемого и использующего JIT-компиляцию кодогенерирующего. Интерпретатор поддерживает полный набор операторов, и вся новая функциональность появляется в первую очередь в нем. Не все операторы имеет смысл реализовать в кодогенерирующем движке — некоторые работают с малым объемом данных, другие могут содержать сложную, но малоизменяющуюся логику, для которой ускорение за счет более оптимизированного кода не покроет затраты времени на генерацию и компиляцию кода. Разбиение запроса на отдельные задачи позволяет нам гибко распределять исполнение по наиболее подходящим движкам.
Генерация кода для запроса
Для написания интерпретаторов хорошо себя зарекомендовала так называемая Volcano Execution Model. В этом подходе каждый оператор реализуется в виде итератора с единым интерфейсом, состоящим в общем виде из методов Open, Next и Close, что позволяет произвольно комбинировать итераторы между собой. Исполнение в такой модели запускается с самого верхнего оператора, а он вызывает методы дочерних итераторов в соответствии со своей логикой.
Однако для генерируемого кода лучше подходит в каком-то смысле противоположный подход. Каждый исходный оператор мы превращаем в одну или несколько секций, которые вкладываются одна в другую. Основа кодогенерации — секции-циклы, которые возникают из операторов, представляющих чтение данных, таких как сканирование таблицы, чтение временных структур, хэш-таблиц и подобных. Остальные операторы превращаются в секции, которые вкладываются внутрь циклов. Для управления потоком исполнения секции имеется возможность сделать break или continue в соответствующем цикле.
В такой модели исполнение начинается с самого нижнего оператора чтения данных, а верхний оператор дерева оказывается вложен внутрь самого внутреннего цикла и пассивно потребляет данные, которые до него дошли.
В качестве примера рассмотрим следующий запрос:
select * from T1 inner join T2 on T1.a = T2.aСхематичный физический план и получившаяся иерархия секций кодогенерации для него представлены на иллюстрации:
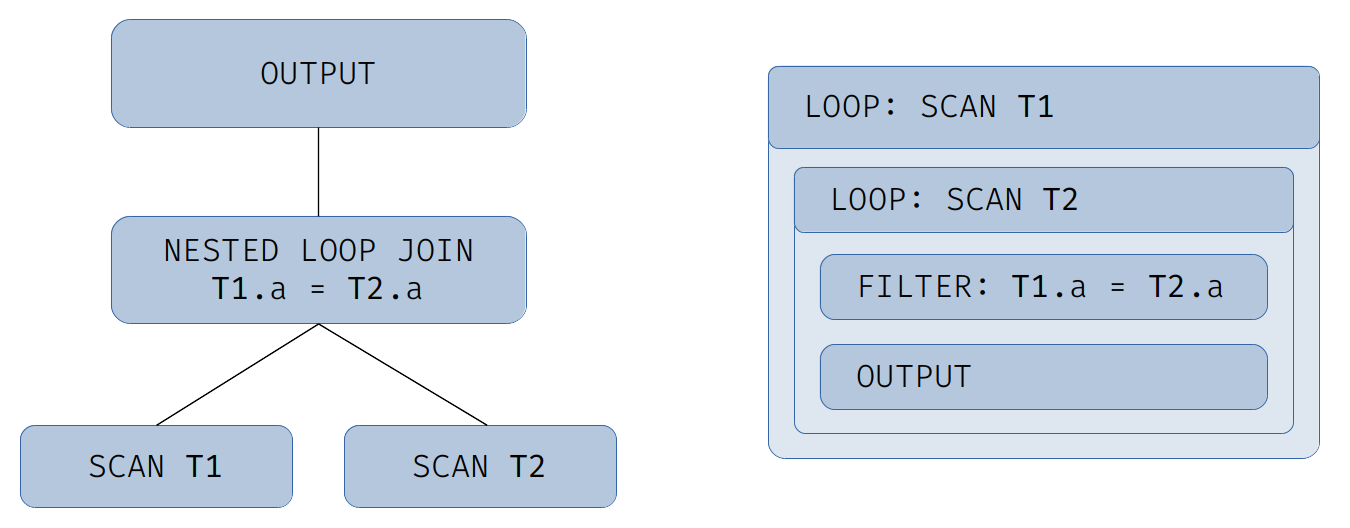
Результат генерации можно представить следующим псевдокодом:
for (row1 : T1)
for (row2 : T2)
if (row1.a != row2.a)
continue
output(row1, row2)Представьте, что вы пишете не универсальную базу данных, а набор функций, исполняющих конкретные операции над данными заранее известной структуры. Представленный выше псевдокод очень похож на то, что написал бы человек, реализующий такую операцию. Таблицы могли бы быть массивами заранее определенных структур, операции сравнения — встроенными операциями языка или дополнительно реализованными функциями, и так далее.
Какие преимущества нам дает такой подход? Во-первых, структура получающегося кода близка к обычному коду, который пишут программисты, а значит, оптимизатор LLVM хорошо с ним знаком и может применить весь арсенал своих оптимизаций.
Во-вторых, в отличие от обобщенных операторов в итераторной модели, большинство операторов, работающих с конкретными данными, представлены отдельными фрагментами кода, что упрощает задачу алгоритмам предсказания ветвлений современных процессоров.
В-третьих, в отличие от итераторной модели, где каждый следующий оператор получает от нижележащего кортеж данных, структура которого скрыта, здесь мы можем специализировать код оператора в разных ветках алгоритма. Например, в случае оператора Left Outer Join, когда для строки из левой таблицы не найдено соответствие в правой, вместо значений правой части подставляются null. Здесь можно сгенерировать две версии тела цикла: одна будет специализирована для правой части, состоящей полностью из значений null, а вторая — для обычных данных правой таблицы.
Большой запрос — это не всегда много кода
Бизнес-приложения со сложной логикой могут создавать весьма большие запросы к базе данных. Но большие запросы не всегда приводят к большому объему генерируемого кода. Рассмотрим некоторые приемы, которые мы для этого используем.
Переиспользование результатов алгебраических выражений. Часто в запросах можно встретить повторяющиеся фрагменты алгебраических выражений. Например, одно поле результата — некоторое сложное выражение от нескольких колонок, а второе — похожее выражение, отличающееся некоторой дополнительной операцией. В таком случае мы выделяем одинаковые подвыражения, вычисляем их один раз, и переиспользуем результат по необходимости. Рассмотрим пример:
select a + b, (a + b)/2 from T1В таком запросе мы выделим выражение (a + b) и вычислим его один раз вместо двух.
Данный анализ выполняется с учетом условной видимости результата. Например, если подвыражение находится в одной из веток оператора CASE, оно может быть переиспользовано в рамках этой ветки, но не в других:
select
case when c = 1 then a + b
when c = 2 then (a + b)/2
end
from TВ таком запросе выражение (a + b) из первой ветки оператора CASE нельзя переиспользовать во второй ветке, так как у них разные условия.
Теоретически эта оптимизация может быть выполнена ранее, на стадии общей оптимизации запроса, однако на практике это может потребовать вставки новых операторов в план запроса, что ведет к раздуванию плана. В результате этой оптимизации на некоторых запросах количество генерируемого кода сокращается до 4 раз.
Выделение части кода в отдельные функции. Описанная выше возможность специализации кода в разных ветках алгоритма при неудачном использовании может обернуться неприятными последствиями. Например, при генерации кода для последовательности вложенных Left Outer Join можно получить экспоненциальный рост количества кода (в зависимости от числа операторов Join). Это может произойти из-за того, что для первого оператора генерируется две копии вложенного оператора, у каждой из которых в свою очередь будет создано две копии последующих операторов и так далее.
Для борьбы с раздуванием кода мы отслеживаем размер получающихся функций и при необходимости можем автоматически выделять части кода в отдельные функции. Это не только позволяет сократить размер кода, но и облегчает задачу оптимизатору LLVM, который сможет более эффективно работать с компактными функциями, а при наличии возможности — произвести встраивание функций в тех местах, где это дает наибольший выигрыш.
Оптимизация и компиляция
Результат генерации — модуль LLVM, содержащий код LLVM IR. Перед тем, как этот код можно будет исполнить, его необходимо оптимизировать и скомпилировать.
LLVM предлагает несколько стандартных уровней оптимизации. Это эквиваленты флагов от -О0 (нет оптимизации) до -О3 (максимальная оптимизация), знакомых пользователям компиляторов GCC и Clang. Также есть возможность выбрать свой набор алгоритмов оптимизации и порядок их применения.
В целом, наш опыт показывает, что в плане производительности получаемого машинного кода существенно превзойти стандартные наборы оптимизаций затруднительно. Но вот сам процесс оптимизации ускорить мы можем. Дело в том, что генерируемый код обладает несколькими особенностями, отличающими его от «естественного», написанного человеком. В первую очередь это большое количество ветвлений, нередко с тривиальными или константными условиями, а также общая переусложненность графа исполнения. В арсенале LLVM есть готовые оптимизации, решающие именно эти проблемы — это оптимизации, направленные на удаление недостижимого кода и упрощение графа исполнения. Применение этих оптимизаций на раннем этапе существенно упрощает код и ускоряет стандартный процесс оптимизации.
Как известно каждому программисту, работающему с компилируемыми языками, компиляция, особенно с высоким уровнем оптимизации, — процесс не самый быстрый. Но наша задача — исполнять запросы быстро, а значит, мы не можем себе позволить остановиться и ждать компиляции кода даже секунду. У нас есть несколько способов ускорить этот процесс.
Так как план запроса состоит из отдельных задач, то код для этих задач мы можем генерировать и компилировать параллельно.
Описанное в предыдущем разделе разбиение кода на функции также ускоряет компиляцию, так как многие алгоритмы оптимизации LLVM гораздо быстрее работают с небольшими функциями.
И, наконец, мы можем варьировать уровень оптимизации в зависимости от размера получившегося кода: если несмотря на все усилия размер функции получился слишком большим, мы уменьшим уровень оптимизации. Таким образом мы частично пожертвуем производительностью скомпилированной функции, но существенно выиграем во времени компиляции. Разумеется, оценка этого баланса — отдельная непростая задача.
Переиспользование кода
Несмотря на все ухищрения, позволяющие сократить время компиляции, идеальным решением было бы избежать ее совсем. И такая возможность у нас есть благодаря кэшированию. LLVM позволяет удерживать в памяти скомпилированный код вместе с некоторыми управляющими структурами, а при необходимости освободить занятую кодом память – очистить кэш от старых записей.
Увеличить эффективность кэша нам позволяет все то же разбиение запроса на отдельные задачи. Код для них кэшируется независимо, и может быть применен в другом запросе, при условии совпадения соответствующих задач.
Также здесь открывается широкий простор для оптимизаций. Например, нередко запросы отличаются лишь значениями констант. В таком случае можно компилировать обобщенную версию кода, а фактические значения передавать в него в виде параметров. Подобные оптимизации — одно из направлений нашей дальнейшей работы над системой JIT-компиляции.
Тестирование
Пришло время посмотреть, какой эффект дает JIT-компиляция запросов на практике. Для этого мы взяли запросы из состава теста TPC-H, который считается одним из отраслевых стандартов для сравнения СУБД аналитической направленности. Данный тест подразумевает генерацию 8 таблиц данных и включает 22 запроса.
Чтобы не загромождать график, мы ограничились первыми десятью запросами теста, и для каждого измерили, во сколько раз ускоряется исполнение запроса при использовании JIT-компиляции по сравнению с использованием интерпретатора. Чтобы продемонстрировать влияние времени компиляции, для каждого запроса приведены два результата — с использованием кэширования кода и без. Масштаб графика логарифмический.

Типичное ускорение составило от 3 до 5 раз, а в некоторых особо удачных случаях кодогенерация дает выигрыш в десятки раз. Можно заметить, что для многих запросов разница между запусками с использованием кэша кода и без него находится в пределах погрешности. Частично это объясняется быстротой компиляции, частично тем фактом, что исполнение одних задач идет параллельно с компиляцией кода для других. Тем не менее, даже в этих случаях кэширование позволяет сократить потребление вычислительных ресурсов.
Заключение
JIT-компиляция запросов — перспективный метод увеличения производительности СУБД, и в сочетании с in-memory моделью хранения данных является одной из ключевых технологий, обеспечивающих высокое быстродействие Дата акселератора. В тестах и реальных внедрениях Дата акселератором в режиме реального времени обрабатываются данные до десятков и сотен миллионов строк, в практических внедрениях используются базы данных размером до нескольких терабайт.
