
In this article, I would like to propose an alternative to the traditional test design style using functional programming concepts in Scala. This approach was inspired by many months of pain from maintaining dozens of failing tests and a burning desire to make them more straightforward and more comprehensible.
Even though the code is in Scala, the proposed ideas are appropriate for developers and QA engineers who use languages supporting functional programming. You can find a Github link with the full solution and an example at the end of the article.
The problem
If you ever had to deal with tests (doesn’t matter which ones: unit-tests, integrational or functional), they were most likely written as a set of sequential instructions. For instance:
// The following tests describe a simple internet store.
// Depending on their role, bonus amount and the order’s
// subtotal, users may receive a discount of some size.
"If user’s role is ‘customer’" - {
import TestHelper._
"And if subtotal < 250 after bonuses - no discount" in {
val db: Database = Database.forURL(TestConfig.generateNewUrl())
migrateDb(db)
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
val svc = new SomeProductionLogic(db)
val result = svc.calculatePrice(packageId = 1)
result shouldBe 90
}
"And if subtotal >= 250 after bonuses - 10% off" in {
val db: Database = Database.forURL(TestConfig.generateNewUrl())
migrateDb(db)
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 100)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 120)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 130)
insertBonus(db, id = 1, packageId = 1, bonusAmount = 40)
val svc = new SomeProductionLogic(db)
val result = svc.calculatePrice(packageId = 1)
result shouldBe 279
}
}
"If user’s role is ‘vip’" - {/*...*/}In my experience, this way of writing tests is preferred by most developers. Our project has about a thousand tests on different levels of isolation, and all of them were written in such style until just recently. As the project grew, we began to notice severe problems and slowdowns in maintaining such tests: fixing them would take at least the same amount of time as writing production code.
When writing new tests, we always had to come up with ways to prepare data from scratch, usually by copying and pasting steps from neighboring tests. As a result, when the application’s data model would change, the house of cards would crumble, and we would have to repair every failing test: in a worst-case scenario — by diving deep into each test and rewriting it.
When a test would fail “honestly” — i.e. because of an actual bug in business logic — understanding what went wrong without debugging was impossible. Because the tests were so difficult to understand, nobody had the full knowledge always at hand on how the system is supposed to behave.
All of this pain, in my opinion, is a symptom of such test design’s two deeper problems:
- There is no clear and practical structure for tests. Every test is a unique snowflake. Lack of structure leads to verbosity, which eats up much time and demotivates. Insignificant details distract from what’s most important — the requirement that the test asserts. Copying and pasting become the primary approach to writing new test cases.
- Tests don’t help developers in localizing defects; they only signal there is a problem of some kind. To understand the state in which the test gets run, you have to plot it in your head or use a debugger.
Modeling
Can we do better? (Spoiler alert: we can.) Let’s consider what kind of structure this test may have.
val db: Database = Database.forURL(TestConfig.generateNewUrl())
migrateDb(db)
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)As a rule of thumb, the code under test expects some explicit parameters (identifiers, sizes, amounts, filters, to name a few), as well as some external data (from a database, queue or some other real-world service). For our test to run reliably, it needs a fixture — a state to put the system, the data providers, or both in.
With this fixture, we prepare a dependency to initialize the code under test — fill a database, create a queue of a particular type, etc.
val svc = new SomeProductionLogic(db)
val result = svc.calculatePrice(packageId = 1)After running the code under test on some input parameters, we receive an output — both explicit (returned by the code under test) and implicit (the changes in the state).
result shouldBe 90Finally, we check that the output is as expected, finishing the test with one or more assertions.
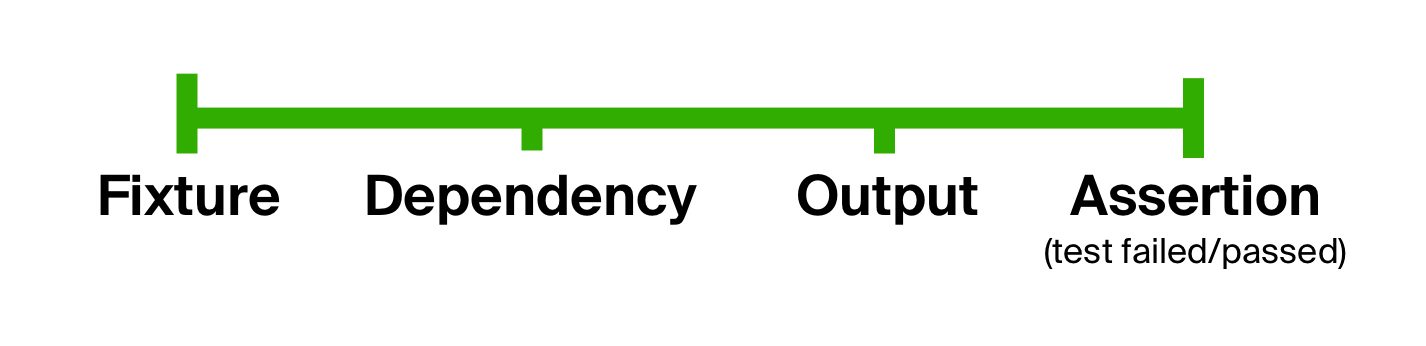
One can conclude that tests generally consist of the same stages: input preparation, code execution, and result assertion. We can use this fact to get rid of the first problem of our tests, i.e. overly liberal form, by explicitly splitting a test’s body into stages. Such an idea is not new, as it can be seen in BDD-style (behavior-driven development) tests.
What about extendability? Any step of the testing process may, in turn, contain any amount of intermediate ones. For instance, we could take a big and complicated step, like building a fixture, and split it into several, chained one after another. This way, the testing process can be infinitely extendable, but ultimately always consisting of the same few general steps.

Running tests
Let’s try to implement the idea of splitting the test into stages, but first, we should determine what kind of result we would like to see.
Overall, we would like writing and maintaining tests to become less labor-intensive and more pleasant. The fewer explicit non-unique instructions a test has, the fewer changes would have to be made into it after changing contracts or refactoring, and the less time it would take to read the test. Test’s design should promote reusing of common code snippets and discourage mindless copying and pasting. It would also be nice if the tests would have a unified form. Predictability improves readability and saves time. For example, imagine how much more time would it take aspiring scientists to learn all the formulas if textbooks would have them written freely in common language as opposed to math.
Thus, our goal is to hide anything distracting and unnecessary, leaving only what is critically important for understanding: what is being tested, what are the expected inputs and outputs.
Let’s get back to our model of the test’s structure.
Technically, every step of it can be represented by a data type, and every transition — by a function. To get from the initial data type to the final one is possible by applying each function to the result of the previous one. In other words, by using function composition of data preparation (let’s call it prepare), code execution (execute) and checking of the expected result (check). The input for this composition would be the very first step — the fixture. Let’s call the resulting higher-order function the test lifecycle function.
def runTestCycle[FX, DEP, OUT, F[_]](
fixture: FX,
prepare: FX => DEP,
execute: DEP => OUT,
check: OUT => F[Assertion]
): F[Assertion] =
// In Scala instead of writing check(execute(prepare(fixture)))
// one can use a more readable version using the andThen function:
(prepare andThen execute andThen check) (fixture)A question arises, where do these certain functions come from? Well, as for data preparation, there’s only a limited amount of ways to do so — filling a database, mocking, etc. Thus, it’s handy to write specialized variants of the prepare function shared across all tests. As a result, it would be easier to make specialized test lifecycle functions for every case, which would conceal concrete implementations of data preparation. Since code execution and assertions are more or less unique for each test (or group of tests), execute and check have to be written each time explicitly.
// Sets up the fixture — implemented separately
def prepareDatabase[DB](db: Database): DbFixture => DB
def testInDb[DB, OUT](
fixture: DbFixture,
execute: DB => OUT,
check: OUT => Future[Assertion],
db: Database = getDatabaseHandleFromSomewhere(),
): Future[Assertion] =
runTestCycle(fixture, prepareDatabase(db), execute, check)By delegating all the administrative nuances to the test lifecycle function, we get the ability to extend the testing process without touching any given test. By utilizing function composition, we can interfere at any step of the process and extract or add data.
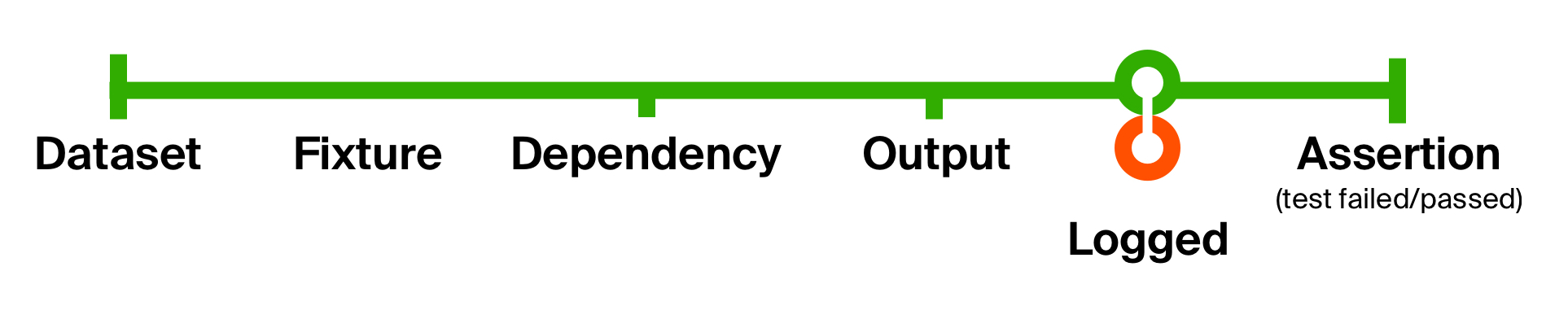
To better illustrate the capabilities of such an approach, let’s solve the second problem of our initial test — the lack of supplemental information for pinpointing problems. Let’s add logging of whatever code execution has returned. Our logging won’t change the data type; it only produces a side-effect — outputting a message to console. After the side-effect, we return it as is.
def logged[T](implicit loggedT: Logged[T]): T => T =
(that: T) => {
// By passing an instance of the Logged typeclass for T as an argument,
// we get an ability to “add” behavior log() to the abstract “that” member.
// More on typeclasses later on.
loggedT.log(that) // We could even do: that.log()
that // The object gets returned unaltered
}
def runTestCycle[FX, DEP, OUT, F[_]](
fixture: FX,
prepare: FX => DEP,
execute: DEP => OUT,
check: OUT => F[Assertion]
)(implicit loggedOut: Logged[OUT]): F[Assertion] =
// Insert logged right after receiving the result - after execute()
(prepare andThen execute andThen logged andThen check) (fixture)With this simple change, we have added logging of the executed code’s output in every test. The advantage of such small functions is that they’re easy to understand, compose, and get rid of when needed.

As a result, our test now looks like this:
val fixture: SomeMagicalFixture = ??? // Comes from somewhere else
def runProductionCode(id: Int): Database => Double =
(db: Database) => new SomeProductionLogic(db).calculatePrice(id)
def checkResult(expected: Double): Double => Future[Assertion] =
(result: Double) => result shouldBe expected
// The creation and filling of Database is hidden in testInDb
"If user’s role is ‘customer’" in testInDb(
state = fixture,
execute = runProductionCode(id = 1),
check = checkResult(90)
)The test’s body became concise, the fixture and the checks can be reused in other tests, and we don’t prepare the database manually anywhere anymore. Only one tiny problem remains...
Fixture preparation
In the code above we were working under an assumption that the fixture would be given to us from somewhere. Since data is the critical ingredient of maintainable and straightforward tests, we have to touch on how to make them easily.
Suppose our store under test has a typical medium-sized relational database (for the sake of simplicity, in this example it has only 4 tables, but in reality, it can have hundreds). Some tables have referential data, some — business data, and all of that can be logically grouped into one or more complex entities. Relations are linked together with foreign keys, to create a Bonus, a Package is required, which in turn needs a User, and so on.

Workarounds and hacks only lead to data inconsistency and, as a result, to hours upon hours of debugging. For this reason, we are not making changes to the schema in any way.
We could use some production methods to fill it, but even under shallow scrutiny, this raises a lot of difficult questions. What will prepare data in tests for that production code? Would we have to rewrite the tests if that code’s contract changes? What if the data comes from somewhere else entirely, and there are no methods to use? How many requests would it take to create an entity that depends on many others?
insertUser(db, id = 1, name = "test", role = "customer")
insertPackage(db, id = 1, name = "test", userId = 1, status = "new")
insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30)
insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20)
insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)Scattered helper methods, like those in our very first example, are the same issue under a different guise. They put the responsibility of managing dependencies upon ourselves which we’re trying to avoid.
Ideally, we would like some data structure that would present the whole system’s state at just a glance. A right candidate would be a table (or a dataset, like in PHP or Python) that would have nothing extra but fields critical for the business logic. If it changes, maintaining the tests would be easy: we merely change the fields in the dataset. Example:
val dataTable: Seq[DataRow] = Table(
("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price")
, (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0)
, (2, "customer", Vector(250) , Vector.empty , 225.0)
, (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0)
, (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0)
, (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0)
)
From our table, we create keys — entity links by ID. If an entity depends on another, a key for that other entity also gets created. It may so happen that two different entities create a dependency with the same ID, which can lead to a primary key violation. However, at this stage it’s incredibly cheap to deduplicate keys — since all they contain are IDs, we can put them in a collection that does deduplication for us, for example, a Set. If that turns out insufficient, we can always implement smarter deduplication as a separate function and compose it into the test lifecycle function.
sealed trait Key
case class PackageKey(id: Int, userId: Int) extends Key
case class PackageItemKey(id: Int, packageId: Int) extends Key
case class UserKey(id: Int) extends Key
case class BonusKey(id: Int, packageId: Int) extends KeyGenerating fake data for fields (e.g., names) is delegated to a separate class. Afterward, by using that class and conversion rules for keys, we get the Row objects intended for insertion into the database.
object SampleData {
def name: String = "test name"
def role: String = "customer"
def price: Int = 1000
def bonusAmount: Int = 0
def status: String = "new"
}
sealed trait Row
case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row
case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row
case class UserRow(id: Int, name: String, role: String) extends Row
case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends RowThe fake data is usually not enough, so we need a way to override specific fields. Luckily, lenses are just what we need — we can use them to iterate over all created rows and change only the fields we need. Since lenses are functions in disguise, we can compose them as usual, which is their strongest point.
def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] =
(rows: Set[Row]) =>
rows.modifyAll(_.each.when[UserRow])
.using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)Thanks to composition, we can apply different optimizations and improvements inside the process: for example, we could group rows by the table to insert them with a single INSERT to reduce test execution time or log the database’s entire state.
def makeFixture[STATE, FX, ROW, F[_]](
state: STATE,
applyOverrides: F[ROW] => F[ROW] = x => x
): FX =
(extractKeys andThen
deduplicateKeys andThen
enrichWithSampleData andThen
applyOverrides andThen
logged andThen
buildFixture) (state)Finally, the whole thing provides us with a fixture. In the test itself, nothing extra is shown, except for the initial dataset — all the details are hidden by function composition.

Our test suite now looks like this:
val dataTable: Seq[DataRow] = Table(
("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price")
, (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0)
, (2, "customer", Vector(250) , Vector.empty , 225.0)
, (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0)
, (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0)
, (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0)
)
"If the buyer's role is" - {
"a customer" - {
"And the total price of items" - {
"< 250 after applying bonuses - no discount" - {
"(case: no bonuses)" in calculatePriceFor(dataTable, 1)
"(case: has bonuses)" in calculatePriceFor(dataTable, 3)
}
">= 250 after applying bonuses" - {
"If there are no bonuses - 10% off on the subtotal" in
calculatePriceFor(dataTable, 2)
"If there are bonuses - 10% off on the subtotal after applying bonuses" in
calculatePriceFor(dataTable, 4)
}
}
}
"a vip - then they get a 20% off before applying bonuses and then all the other rules apply" in
calculatePriceFor(dataTable, 5)
}And the helper code:
// Reusable test’s body
def calculatePriceFor(table: Seq[DataRow], idx: Int) =
testInDb(
state = makeState(table.row(idx)),
execute = runProductionCode(table.row(idx)._1),
check = checkResult(table.row(idx)._5)
)
def makeState(row: DataRow): Logger => DbFixture = {
val items: Map[Int, Int] = ((1 to row._3.length) zip row._3).toMap
val bonuses: Map[Int, Int] = ((1 to row._4.length) zip row._4).toMap
MyFixtures.makeFixture(
state = PackageRelationships
.minimal(id = row._1, userId = 1)
.withItems(items.keys)
.withBonuses(bonuses.keys),
overrides = changeRole(userId = 1, newRole = row._2) andThen
items.map { case (id, newPrice) => changePrice(id, newPrice) }.foldPls andThen
bonuses.map { case (id, newBonus) => changeBonus(id, newBonus) }.foldPls
)
}
def runProductionCode(id: Int): Database => Double =
(db: Database) => new SomeProductionLogic(db).calculatePrice(id)
def checkResult(expected: Double): Double => Future[Assertion] =
(result: Double) => result shouldBe expected
Adding new test cases into the table is a trivial task that lets us concentrate on covering more fringe cases and not on writing boilerplate code.
Reusing fixture preparation on different projects
Okay, so we wrote a whole lot of code to prepare fixtures in one specific project, spending quite some time in the process. What if we have several projects? Are we doomed to reinvent the whole thing from scratch every time?
We can abstract the fixture preparation over a concrete domain model. In the world of functional programming, there is a concept of typeclasses. Without getting deep into details, they’re not like classes in OOP, but more like interfaces in that they define a certain behavior of some group of types. The fundamental difference is that they’re not inherited but rather instantiated like variables. However, similar to inheritance, the resolving of typeclass instances happens at compile time. In this sense, typeclasses can be grasped like extension methods from Kotlin and C#.
To log an object, we don’t need to know what’s inside, what fields and methods it has. All we care about is it having a behavior log() with a particular signature. Extending every single class with a Logged interface would be extremely tedious and even then not possible in many cases — for example, for libraries or standard classes. With typeclasses, this is much easier. We can create an instance of a typeclass called Logged, for example, for a fixture to log it in a human-readable format. For everything else that doesn’t have an instance of Logged we can provide a fallback: an instance for type Any that uses a standard method toString() to log every object in their internal representation for free.
trait Logged[A] {
def log(a: A)(implicit logger: Logger): A
}
// For all Futures
implicit def futureLogged[T]: Logged[Future[T]] = new Logged[Future[T]] {
override def log(futureT: Future[T])(implicit logger: Logger): Future[T] = {
futureT.map { t =>
// map on a Future lets us modify its result after it finishes
logger.info(t.toString())
t
}
}
}
// Fallback in case there are no suitable implicits in scope
implicit def anyNoLogged[T]: Logged[T] = new Logged[T] {
override def log(t: T)(implicit logger: Logger): T = {
logger.info(t.toString())
t
}
}Besides logging, we can use this approach throughout the whole process of making fixtures. Our solution proposes an abstract way to make database fixtures and a set of typeclasses to go with it. It’s the project using the solution’s responsibility to implement the instances of these typeclasses for the whole thing to work.
// Fixture preparation function
def makeFixture[STATE, FX, ROW, F[_]](
state: STATE,
applyOverrides: F[ROW] => F[ROW] = x => x
): FX =
(extractKeys andThen
deduplicateKeys andThen
enrichWithSampleData andThen
applyOverrides andThen
logged andThen
buildFixture) (state)
override def extractKeys(implicit toKeys: ToKeys[DbState]): DbState => Set[Key] =
(db: DbState) => db.toKeys()
override def enrichWithSampleData(implicit enrich: Enrich[Key]): Key => Set[Row] =
(key: Key) => key.enrich()
override def buildFixture(implicit insert: Insertable[Set[Row]]): Set[Row] => DbFixture =
(rows: Set[Row]) => rows.insert()
// Behavior of splitting something (e.g. a dataset) into keys
trait ToKeys[A] {
def toKeys(a: A): Set[Key] // Something => Set[Key]
}
// ...converting keys into rows
trait Enrich[A] {
def enrich(a: A): Set[Row] // Set[Key] => Set[Row]
}
// ...and inserting rows into the database
trait Insertable[A] {
def insert(a: A): DbFixture // Set[Row] => DbFixture
}
// To be implemented in our project (see the example at the end of the article)
implicit val toKeys: ToKeys[DbState] = ???
implicit val enrich: Enrich[Key] = ???
implicit val insert: Insertable[Set[Row]] = ???When designing this fixture preparation tool, I used the SOLID principles as a compass for making sure it’s maintainable and extendable:
- The Single Responsibility Principle: each typeclass describes one and only one behavior of a type.
- The Open/Closed Principle: we don’t modify any of the production classes; instead, we extend them with instances of typeclasses.
- The Liskov Substitution Principle doesn’t apply here since we don’t use inheritance.
- The Interface Segregation Principle: we use many specialized typeclasses as opposed to a global one.
- The Dependency Inversion Principle: the fixture preparation function doesn’t depend on concrete types, but rather on abstract typeclasses.
After making sure that all of the principles are satisfied, we may safely assume that our solution is maintainable and extendable enough to be used in different projects.
After writing the test lifecycle function and the solution for fixture preparation, which is also independent of a concrete domain model on any given application, we’re all set to improve all of the remaining tests.
Bottom line
We have switched from the traditional (step-by-step) test design style to functional. Step-by-step style is useful early on and in smaller-sized projects, because it doesn’t restrict developers and doesn’t require any specialized knowledge. However, when the amount of tests becomes too large, such a style tends to fall off. Writing tests in the functional style probably won’t solve all your testing problems, but it might significantly improve scaling and maintaining tests in projects, where there’s hundreds or thousands of them. Tests that are written in the functional style turn out to be more concise and focused on the essential things (such as data, code under test, and the expected result), not on the intermediate steps.
Moreover, we have explored just how powerful can function composition and typeclasses be in functional programming. With their help, it’s quite simple to design solutions with extendability and reusability in mind.
Since adopting the style several months ago, our team had to spend some effort adapting, but in the end, we enjoyed the result. New tests get written faster, logs make life much more comfortable, and datasets are handy to check whenever there are questions about some logic’s intricacies. Our team aims to switch all of the tests to this new style gradually.
Link to the solution and a complete example can be found here: Github. Have fun with your testing!
