В своем небольшом проекте по моделированию случайных величин я столкнулся с проблемой низкой производительности вычисления математических выражений, вводимых пользователем, и долго искал разные способы ее решения: попробовал написать интерпретатор на С++ в надежде, что он будет быстрым, сочинил свой байт-код. Наиболее удачной идеей оказалась генерация классов JVM и их загрузка во время выполнения.
Узнав про KMath, я решил обобщить эту оптимизацию для множества математических структур и операторов, определенных на них.
KMath — это библиотека для математики и компьютерной алгебры, активно использующая контекстно-ориентированное программирование в Kotlin. В KMath разделены математические сущности (числа, векторы, матрицы) и операции над ними — они поставляются отдельным объектом, алгеброй, соответствующей типу операндов, Algebra<T>.
Таким образом, после написания генератора байт-кода, с учетом оптимизаций JVM можно получить быстрые расчеты для любого математического объекта — достаточно определить операции над ними на Kotlin.
Для начала нужно было разработать API выражений и только после этого приступать к грамматике языка и синтаксическому дереву. Также появилась удачная идея определить алгебру над самими выражениями, чтобы представить более наглядный интерфейс.
База всего API выражений — интерфейс Expression<T>, а простейший способ его реализовать — прямо определить метод invoke от данных параметров или, например, вложенных выражений. Подобная реализация была интегрирована в корневой модуль как справочная, хоть и самая медленная.
Более продвинутые реализации уже основаны именно на MST. К ним относятся:
API для парсинга выражений из строки в MST уже доступно в dev-ветке KMath как и более или менее окончательный генератор кода JVM.
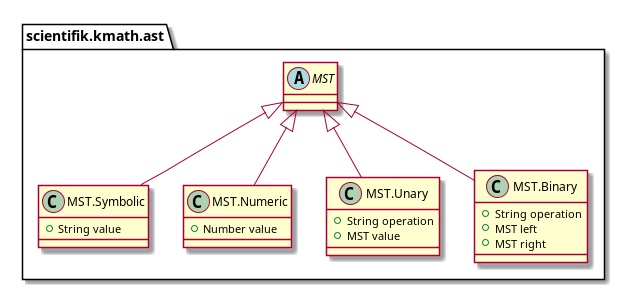
Перейдем к MST. Сейчас в MST представлены четыре вида узлов:

Первое, что с ним можно сделать, — это обойти и посчитать результат по имеющимся данным. Передав в целевую алгебру ID операции, например «+», и аргументы, например 1.0 и 1.0, мы можем надеяться на результат, если эта операция определена. В противном случае при вычислении выражение упадет с исключением.

Для работы с MST, помимо языка выражения, еще есть алгебра — например MstField:
Результатом метода выше является реализация Expression<T>, при вызове вызывающая обход дерева, полученного при вычислении функции, переданной в mstInField.
Но это не все: при обходе мы можем как угодно применять параметры дерева и не волноваться о порядке действий и арности операций. Именно это и используется для генерации байт-кода.
Генерация кода в kmath-ast — это параметризованная сборка класса JVM. Входные данные — MST и целевая алгебра, на выходе — инстанс Expression<T>.
Соответствующий класс, AsmBuilder, и еще несколько extension-функций предоставляют методы для императивной сборки байт-кода поверх ObjectWeb ASM. С их помощью обход MST и сборка класса выглядят чисто и занимают менее 40 строк кода.
Рассмотрим сгенерированный класс для выражения «2*x», приведен декомпилированный из байт-кода исходник на Java:
Сначала здесь был сгенерирован метод invoke, в котором были последовательно расставлены операнды (т.к. они находятся глубже в дереве), потом вызов add. После invoke был записан соответствующий бридж-метод. Далее было записано поле algebra и конструктор. В некоторых случаях, когда константы нельзя просто положить в пул констант класса, записывается еще поле constants, массив java.lang.Object.
Впрочем, из-за множества крайних случаев и оптимизаций реализация генератора довольно сложная.
Чтобы вызвать операцию от алгебры, нужно передать ее ID и аргументы:
Однако такой вызов дорог по производительности: для того чтобы выбрать, какой метод вызвать, RealField выполнит сравнительно дорогую инструкцию tableswitch, а еще нужно помнить о боксинге. Поэтому, хотя все операции MST можно представить в такой форме, лучше делать прямой вызов:
Никакой особенной конвенции о маппинге ID операций к методам в реализациях Algebra<T> нет, поэтому пришлось вставить костыль, в котором вручную прописано, что «+», например, соответствует методу add. Также есть поддержка для благоприятных ситуаций, когда для ID операции можно найти метод с таким же именем, нужным количеством аргументов и их типами.
Другая серьезная проблема — это боксинг. Если мы посмотрим на Java-сигнатуры методов, которые получаются после компиляции того же RealField, увидим два метода:
Конечно, легче не мучаться с боксингом и анбоксингом и вызвать бридж-метод: он тут появился из-за type erasure, чтобы правильно реализовывать метод add(T, T): T, тип T в дескрипторе которого на самом деле стерся до java.lang.Object.
Прямой вызов add от двух double тоже не идеален, потому что боксит возвращаемое значение (по этому поводу есть обсуждение в YouTrack Kotlin (KT-29460), но лучше вызывать именно его, чтобы в лучшем случае сэкономить два приведения типа входных объектов к java.lang.Number и их анбоксинга в double.
На решение этой проблемы ушло больше всего времени. Сложность здесь заключается не в создании вызовов к примитивному методу, а в том, что нужно сочетать на стеке и примитивные типы (как double), и их обертки (java.lang.Double, например), а в нужных местах вставлять боксинг (например, java.lang.Double.valueOf) и анбоксинг (doubleValue) — здесь категорически не хватало работы с типами инструкций в байт-коде.
У меня были идеи навесить свою типизированную абстракцию поверх байт-кода. Для этого мне пришлось глубже разобраться в API ObjectWeb ASM. В итоге я обратился к бэкенду Kotlin/JVM, подробно изучил класс StackValue (типизированный фрагмент байт-кода, который в итоге приводит к получению какого-то значения на стеке операндов), разобрался с утилитой Type, которая позволяет удобно оперировать с типами, доступными в байт-коде (примитивы, объекты, массивы), и переписал генератор с ее использованием. Проблема, нужно ли боксить или анбоксить значение на стеке, решилась сама собой путем добавления ArrayDeque, хранящего типы, которые ожидаются следующим вызовом.
В итоге мне удалось сделать генератор кода с помощью ObjectWeb ASM для вычисления выражений MST в KMath. Прирост производительности по сравнению с простым обходом MST зависит от количества узлов, так как байт-код линеен и в итоге не тратит время на выбор узла и рекурсию. Например, для выражения с 10 узлами разница во времени между вычислением с помощью сгенерированного класса и интерпретатора составляет от 19 до 30%.
Изучив проблемы, с которыми я столкнулся, я сделал следующие выводы:
Cпасибо, что прочитали.
Авторы статьи:
Ярослав Сергеевич Постовалов, МБОУ «Лицей № 130 им. академика Лаврентьева», участник лаборатории математического моделирования под руководством Войтишека Антона Вацлавовича
Татьяна Абрамова, исследователь лаборатории методов ядерно-физических экспериментов в JetBrains Research.
Узнав про KMath, я решил обобщить эту оптимизацию для множества математических структур и операторов, определенных на них.
KMath — это библиотека для математики и компьютерной алгебры, активно использующая контекстно-ориентированное программирование в Kotlin. В KMath разделены математические сущности (числа, векторы, матрицы) и операции над ними — они поставляются отдельным объектом, алгеброй, соответствующей типу операндов, Algebra<T>.
import scientifik.kmath.operations.*
ComplexField {
(i pow 2) + Complex(1.0, 3.0)
}Таким образом, после написания генератора байт-кода, с учетом оптимизаций JVM можно получить быстрые расчеты для любого математического объекта — достаточно определить операции над ними на Kotlin.
API
Для начала нужно было разработать API выражений и только после этого приступать к грамматике языка и синтаксическому дереву. Также появилась удачная идея определить алгебру над самими выражениями, чтобы представить более наглядный интерфейс.
База всего API выражений — интерфейс Expression<T>, а простейший способ его реализовать — прямо определить метод invoke от данных параметров или, например, вложенных выражений. Подобная реализация была интегрирована в корневой модуль как справочная, хоть и самая медленная.
interface Expression<T> {
operator fun invoke(arguments: Map<String, T>): T
}Более продвинутые реализации уже основаны именно на MST. К ним относятся:
- интерпретатор MST,
- генератор классов по MST.
API для парсинга выражений из строки в MST уже доступно в dev-ветке KMath как и более или менее окончательный генератор кода JVM.
Перейдем к MST. Сейчас в MST представлены четыре вида узлов:
- терминальные:
- символы (то есть переменные)
- числа;
- унарные операции;
- бинарные операции.
Первое, что с ним можно сделать, — это обойти и посчитать результат по имеющимся данным. Передав в целевую алгебру ID операции, например «+», и аргументы, например 1.0 и 1.0, мы можем надеяться на результат, если эта операция определена. В противном случае при вычислении выражение упадет с исключением.

Для работы с MST, помимо языка выражения, еще есть алгебра — например MstField:
import scientifik.kmath.ast.*
import scientifik.kmath.operations.*
import scientifik.kmath.expressions.*
RealField.mstInField { number(1.0) + number(1.0) }() // 2.0Результатом метода выше является реализация Expression<T>, при вызове вызывающая обход дерева, полученного при вычислении функции, переданной в mstInField.
Генерация кода
Но это не все: при обходе мы можем как угодно применять параметры дерева и не волноваться о порядке действий и арности операций. Именно это и используется для генерации байт-кода.
Генерация кода в kmath-ast — это параметризованная сборка класса JVM. Входные данные — MST и целевая алгебра, на выходе — инстанс Expression<T>.
Соответствующий класс, AsmBuilder, и еще несколько extension-функций предоставляют методы для императивной сборки байт-кода поверх ObjectWeb ASM. С их помощью обход MST и сборка класса выглядят чисто и занимают менее 40 строк кода.
Рассмотрим сгенерированный класс для выражения «2*x», приведен декомпилированный из байт-кода исходник на Java:
package scientifik.kmath.asm.generated;
import java.util.Map;
import scientifik.kmath.asm.internal.MapIntrinsics;
import scientifik.kmath.expressions.Expression;
import scientifik.kmath.operations.RealField;
public final class AsmCompiledExpression_1073786867_0 implements Expression<Double> {
private final RealField algebra;
public final Double invoke(Map<String, ? extends Double> arguments) {
return (Double)this.algebra.add(((Double)MapIntrinsics.getOrFail(arguments, "x")).doubleValue(), 2.0D);
}
public AsmCompiledExpression_1073786867_0(RealField algebra) {
this.algebra = algebra;
}
}Сначала здесь был сгенерирован метод invoke, в котором были последовательно расставлены операнды (т.к. они находятся глубже в дереве), потом вызов add. После invoke был записан соответствующий бридж-метод. Далее было записано поле algebra и конструктор. В некоторых случаях, когда константы нельзя просто положить в пул констант класса, записывается еще поле constants, массив java.lang.Object.
Впрочем, из-за множества крайних случаев и оптимизаций реализация генератора довольно сложная.
Оптимизация вызовов к Algebra
Чтобы вызвать операцию от алгебры, нужно передать ее ID и аргументы:
RealField { binaryOperation("+", 1.0, 1.0) } // 2.0Однако такой вызов дорог по производительности: для того чтобы выбрать, какой метод вызвать, RealField выполнит сравнительно дорогую инструкцию tableswitch, а еще нужно помнить о боксинге. Поэтому, хотя все операции MST можно представить в такой форме, лучше делать прямой вызов:
RealField { add(1.0, 1.0) } // 2.0Никакой особенной конвенции о маппинге ID операций к методам в реализациях Algebra<T> нет, поэтому пришлось вставить костыль, в котором вручную прописано, что «+», например, соответствует методу add. Также есть поддержка для благоприятных ситуаций, когда для ID операции можно найти метод с таким же именем, нужным количеством аргументов и их типами.
private val methodNameAdapters: Map<Pair<String, Int>, String> by lazy {
hashMapOf(
"+" to 2 to "add",
"*" to 2 to "multiply",
"/" to 2 to "divide",
...private fun <T> AsmBuilder<T>.findSpecific(context: Algebra<T>, name: String, parameterTypes: Array<MstType>): Method? =
context.javaClass.methods.find { method ->
...
nameValid && arityValid && notBridgeInPrimitive && paramsValid
}Другая серьезная проблема — это боксинг. Если мы посмотрим на Java-сигнатуры методов, которые получаются после компиляции того же RealField, увидим два метода:
public Double add(double a, double b)
// $FF: synthetic method
// $FF: bridge method
public Object add(Object var1, Object var2)Конечно, легче не мучаться с боксингом и анбоксингом и вызвать бридж-метод: он тут появился из-за type erasure, чтобы правильно реализовывать метод add(T, T): T, тип T в дескрипторе которого на самом деле стерся до java.lang.Object.
Прямой вызов add от двух double тоже не идеален, потому что боксит возвращаемое значение (по этому поводу есть обсуждение в YouTrack Kotlin (KT-29460), но лучше вызывать именно его, чтобы в лучшем случае сэкономить два приведения типа входных объектов к java.lang.Number и их анбоксинга в double.
На решение этой проблемы ушло больше всего времени. Сложность здесь заключается не в создании вызовов к примитивному методу, а в том, что нужно сочетать на стеке и примитивные типы (как double), и их обертки (java.lang.Double, например), а в нужных местах вставлять боксинг (например, java.lang.Double.valueOf) и анбоксинг (doubleValue) — здесь категорически не хватало работы с типами инструкций в байт-коде.
У меня были идеи навесить свою типизированную абстракцию поверх байт-кода. Для этого мне пришлось глубже разобраться в API ObjectWeb ASM. В итоге я обратился к бэкенду Kotlin/JVM, подробно изучил класс StackValue (типизированный фрагмент байт-кода, который в итоге приводит к получению какого-то значения на стеке операндов), разобрался с утилитой Type, которая позволяет удобно оперировать с типами, доступными в байт-коде (примитивы, объекты, массивы), и переписал генератор с ее использованием. Проблема, нужно ли боксить или анбоксить значение на стеке, решилась сама собой путем добавления ArrayDeque, хранящего типы, которые ожидаются следующим вызовом.
internal fun loadNumeric(value: Number) {
if (expectationStack.peek() == NUMBER_TYPE) {
loadNumberConstant(value, true)
expectationStack.pop()
typeStack.push(NUMBER_TYPE)
} else ...?.number(value)?.let { loadTConstant(it) }
?: error(...)
}Выводы
В итоге мне удалось сделать генератор кода с помощью ObjectWeb ASM для вычисления выражений MST в KMath. Прирост производительности по сравнению с простым обходом MST зависит от количества узлов, так как байт-код линеен и в итоге не тратит время на выбор узла и рекурсию. Например, для выражения с 10 узлами разница во времени между вычислением с помощью сгенерированного класса и интерпретатора составляет от 19 до 30%.
Изучив проблемы, с которыми я столкнулся, я сделал следующие выводы:
- нужно сразу изучить возможности и утилиты ASM — они сильно упрощают разработку и делают код читаемым (Type, InstructionAdapter, GeneratorAdapter);
- нет смысла тратить время на подсчет MaxStack самостоятельно, если это не критично для производительности, — есть ClassWriter COMPUTE_MAXS и COMPUTE_FRAMES;
- очень полезно изучать бэкенды компиляторов реальных языков;
- следует разбираться в синтаксисе дескрипторов и, в частности, сигнатур, чтобы не ошибаться при использовании дженериков;
- и наконец, далеко не во всех случаях нужно лезть настолько глубоко — есть более удобные способы работать с классами в рантайме, например, ByteBuddy и cglib.
Cпасибо, что прочитали.
Авторы статьи:
Ярослав Сергеевич Постовалов, МБОУ «Лицей № 130 им. академика Лаврентьева», участник лаборатории математического моделирования под руководством Войтишека Антона Вацлавовича
Татьяна Абрамова, исследователь лаборатории методов ядерно-физических экспериментов в JetBrains Research.
