Привет! За последние четыре месяца мы выпускали фичи и между релизами, поэтому в этой статье о том, что нового появилось в DataGrip за это время. Она приурочена к нашему новому релизу: 2020.2. Получилось длинно, но, надеемся, полезно.

Редактор больших значений
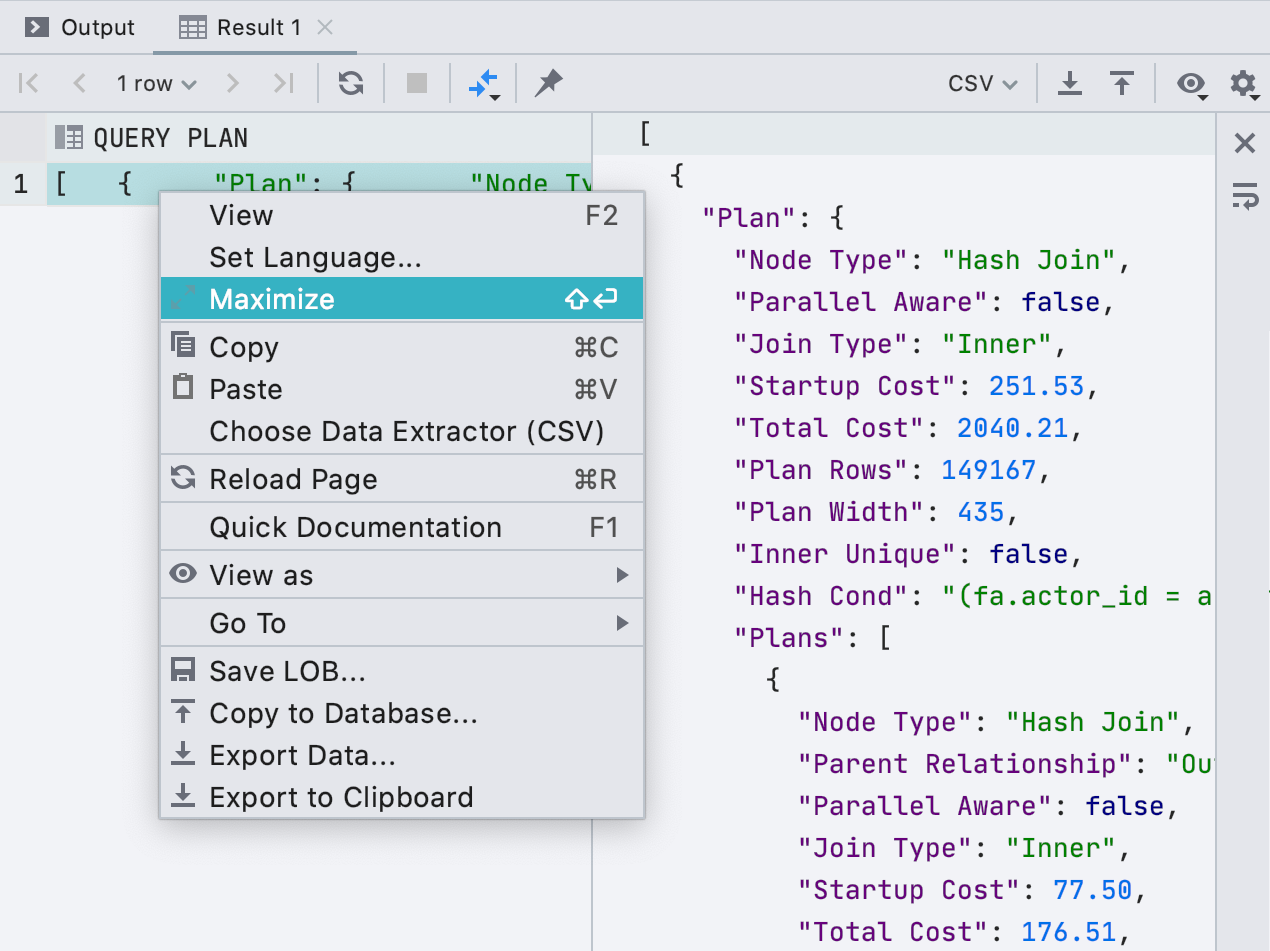
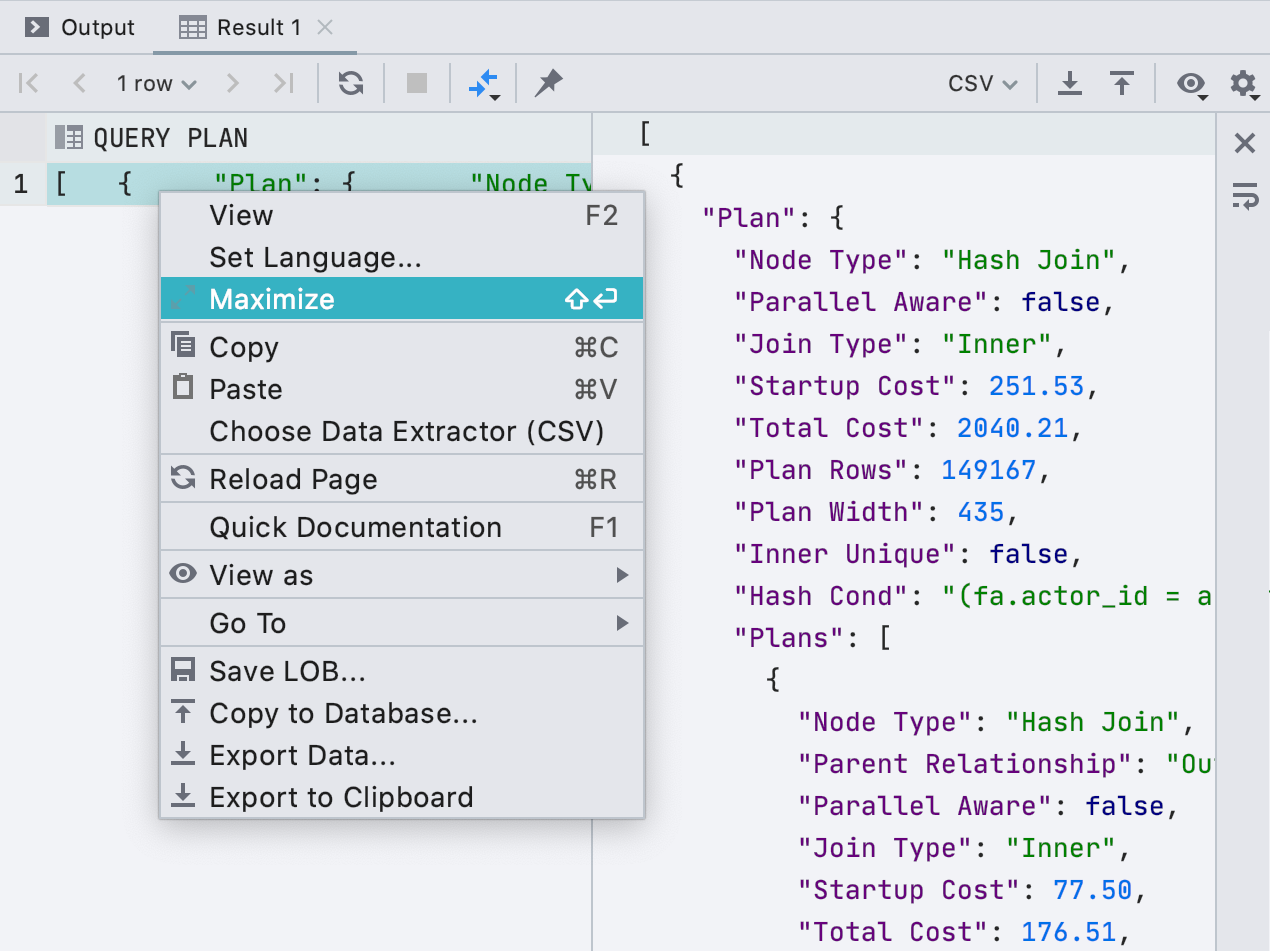
Мы приделали полноценный редактор к ячейкам. Если в ячейке длинное значение, например XML или JSON, его удобно открыть в отдельной панели. Для этого нажмите
Maximize в контекстном меню.
Предпросмотр запроса при редактировании
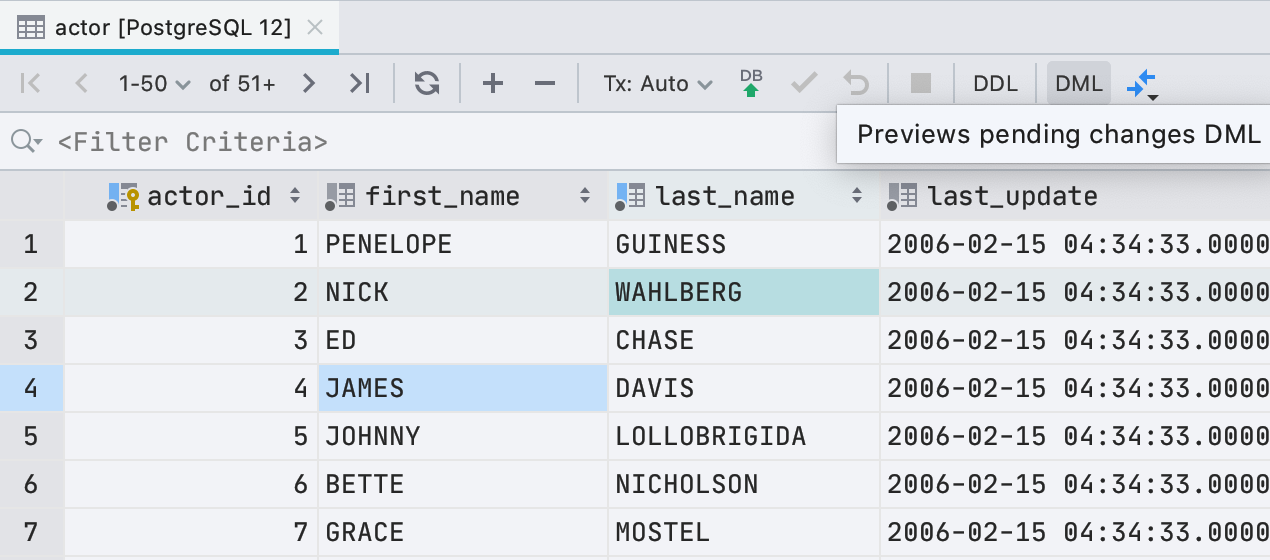
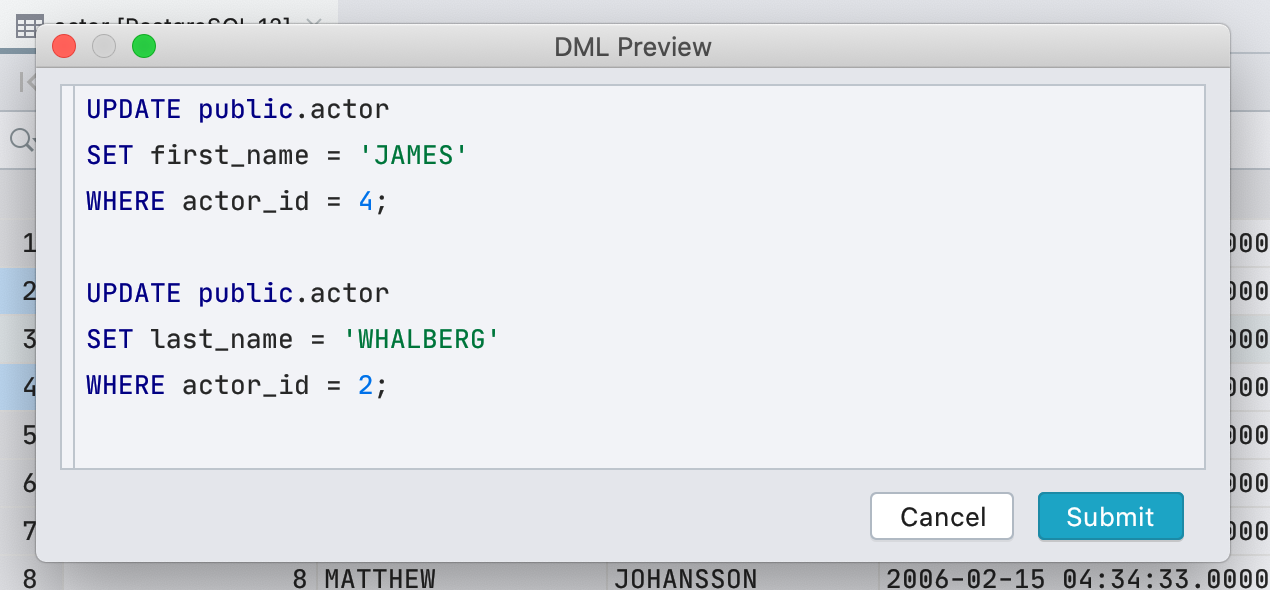
Теперь, прежде чем записать новые значения в редакторе данных, можно посмотреть, какой запрос будет выполнен. Для этого нажмите кнопку DML на панели инструментов.
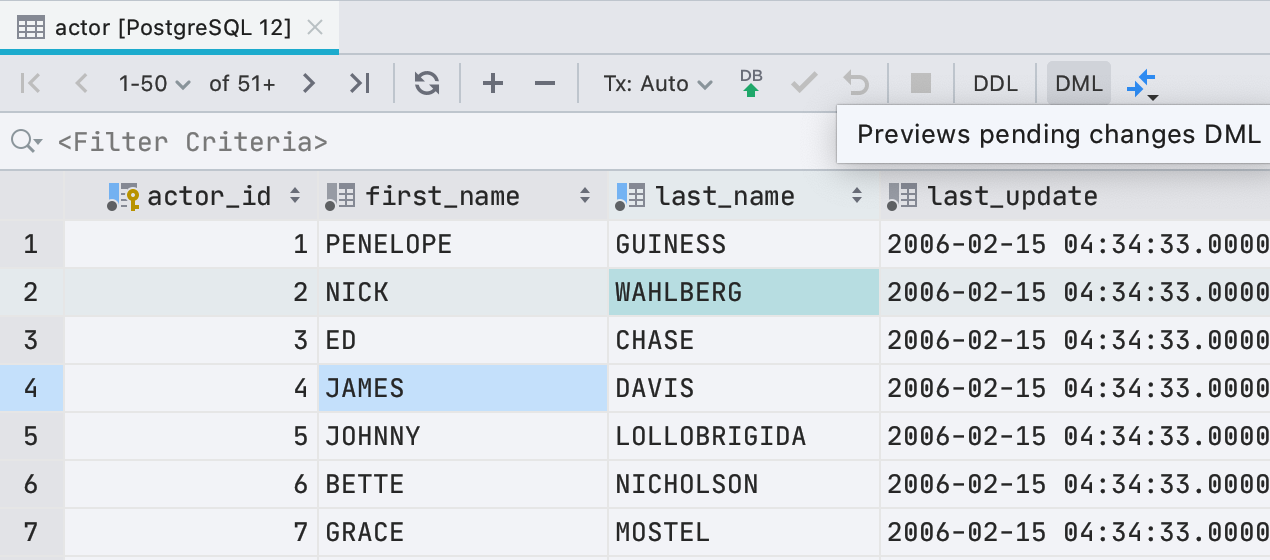
Если честно, это не именно тот запрос, который мы запустим, потому что для редактирования данных DataGrip использует JDBC-драйвер. Но в большинстве случаях то, что мы покажем будет совпадать с тем, что реально запустится.
Новое отображение логических ячеек
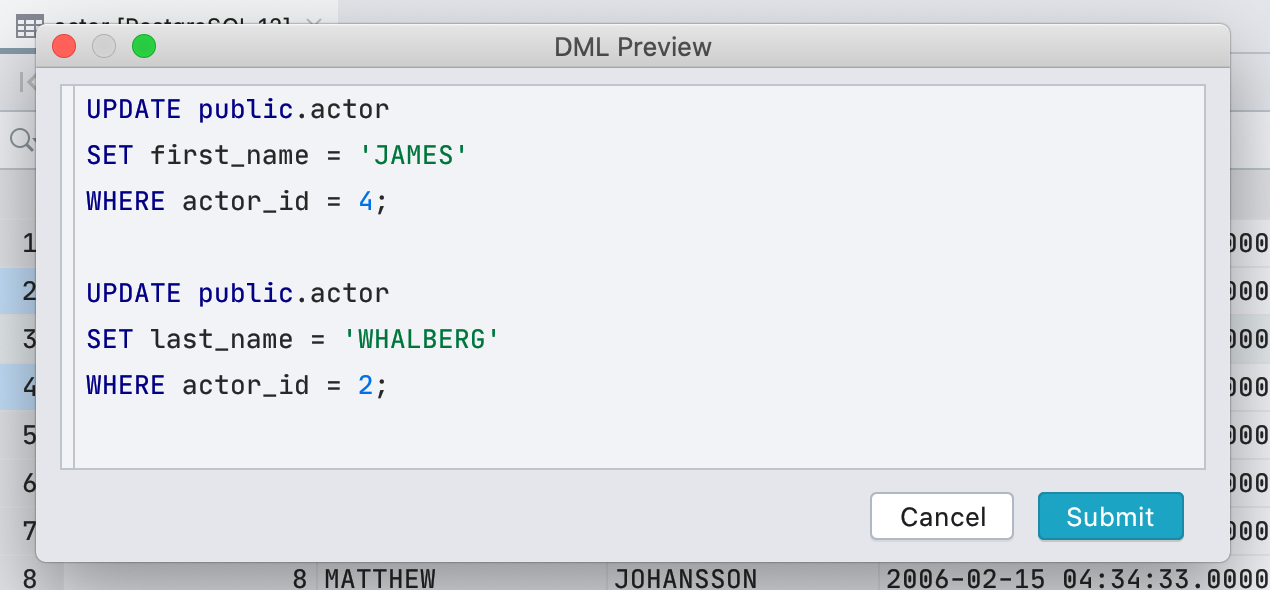
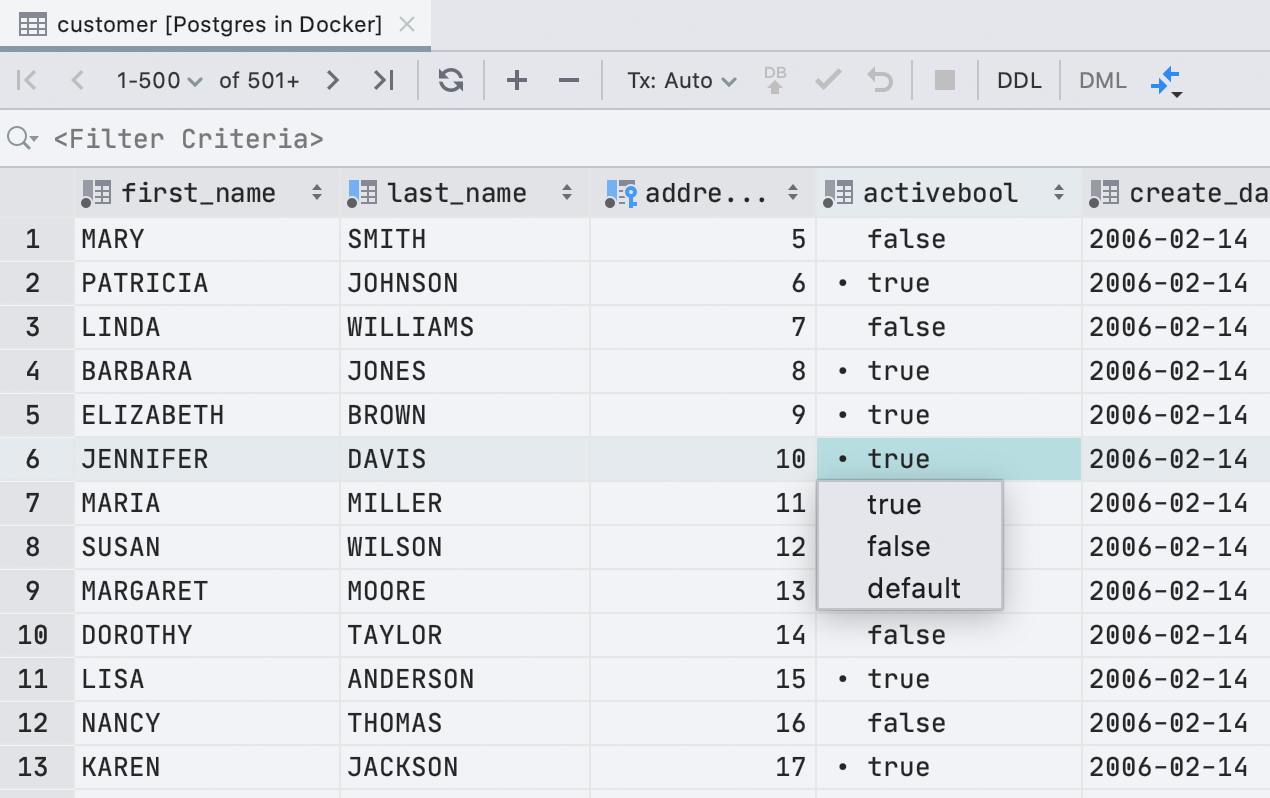
Раньше для отображения ячеек с типом boolean мы использовали чекбокс. Это было неудобно: не все понимали, как отличать null от false, а default, computed и null и вовсе отображались одинаково. Мы решили не мудрить и писать значение текстом.
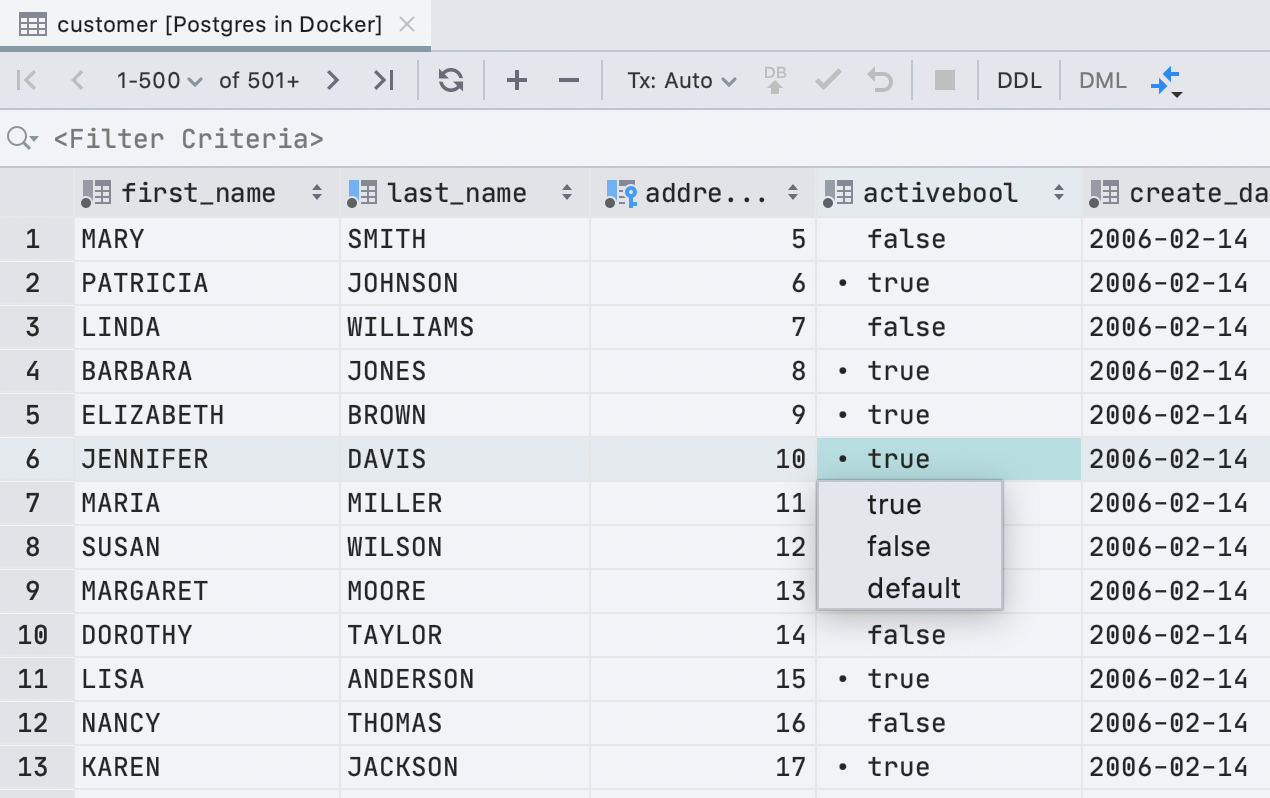
У чекбокса был один плюс: легко визуально находить значения true. В новом интерфейсе эту задачу выполняет точка.
Нам повезло: в английском языке все возможные значения начинаются с разных букв. Поэтому для редактирования достаточно нажать первую букву нужного вам значения: f, t, d, n, g или c. Если напечатать что-то другое, покажем выпадающий список. А пробел переключает между доступными значениями.
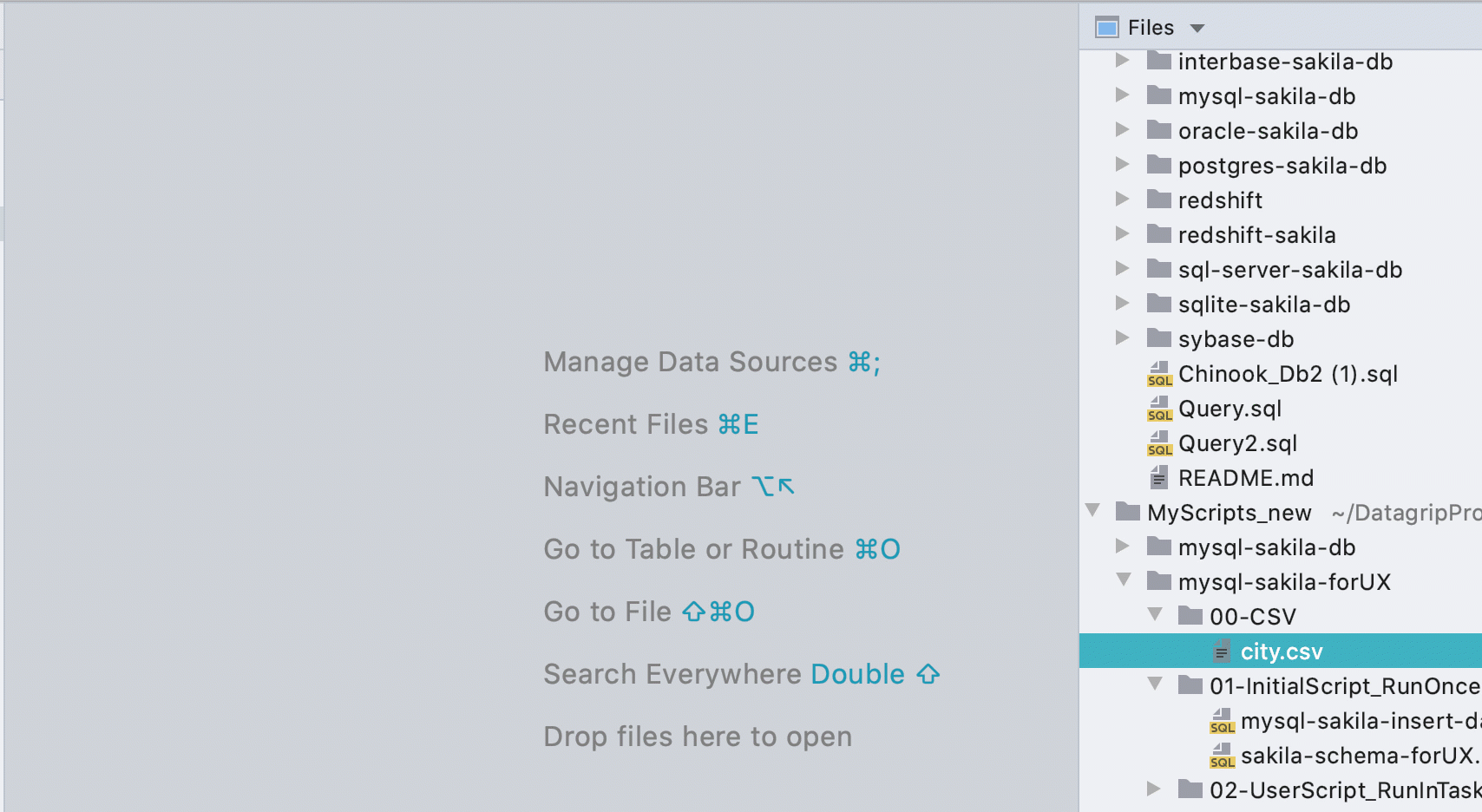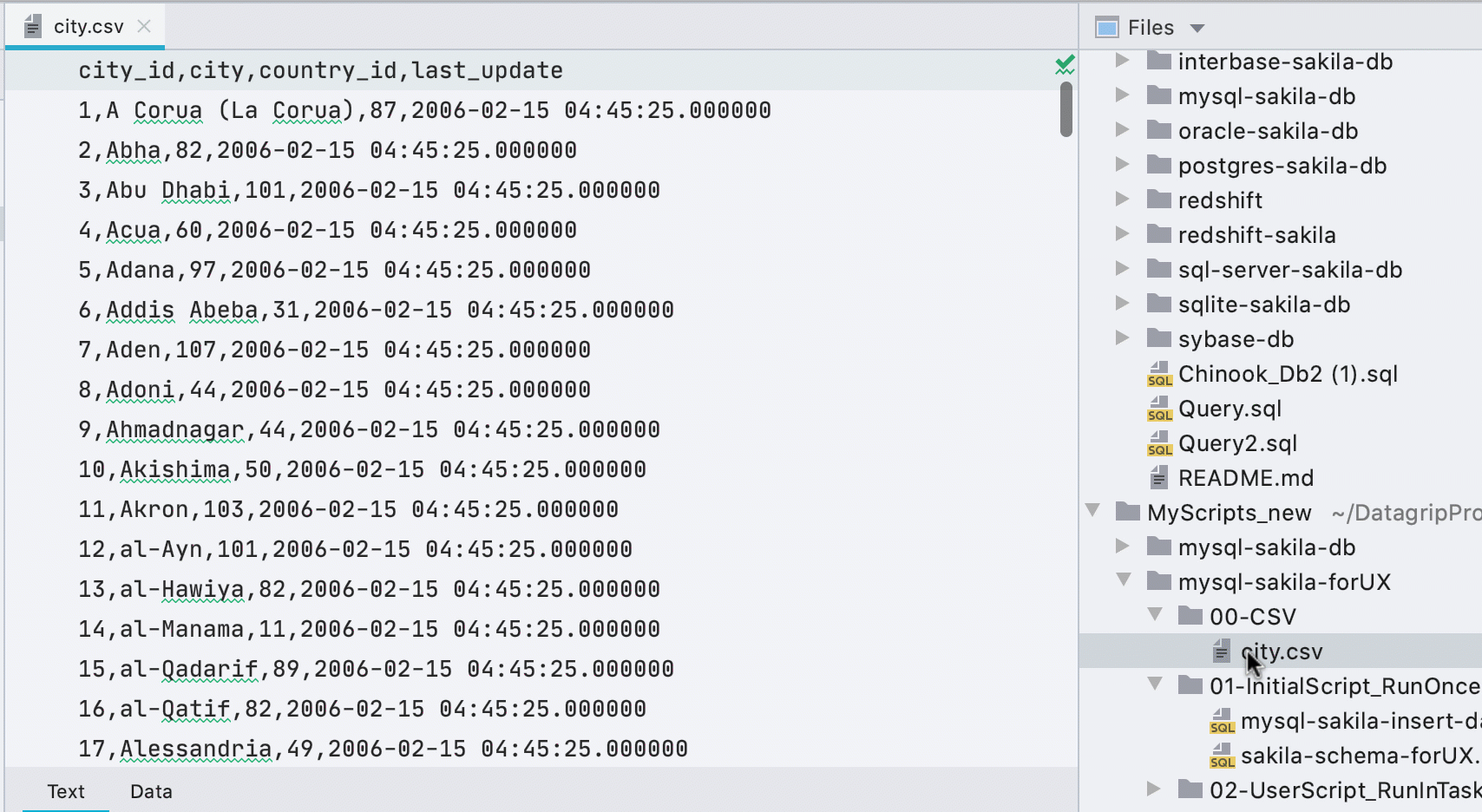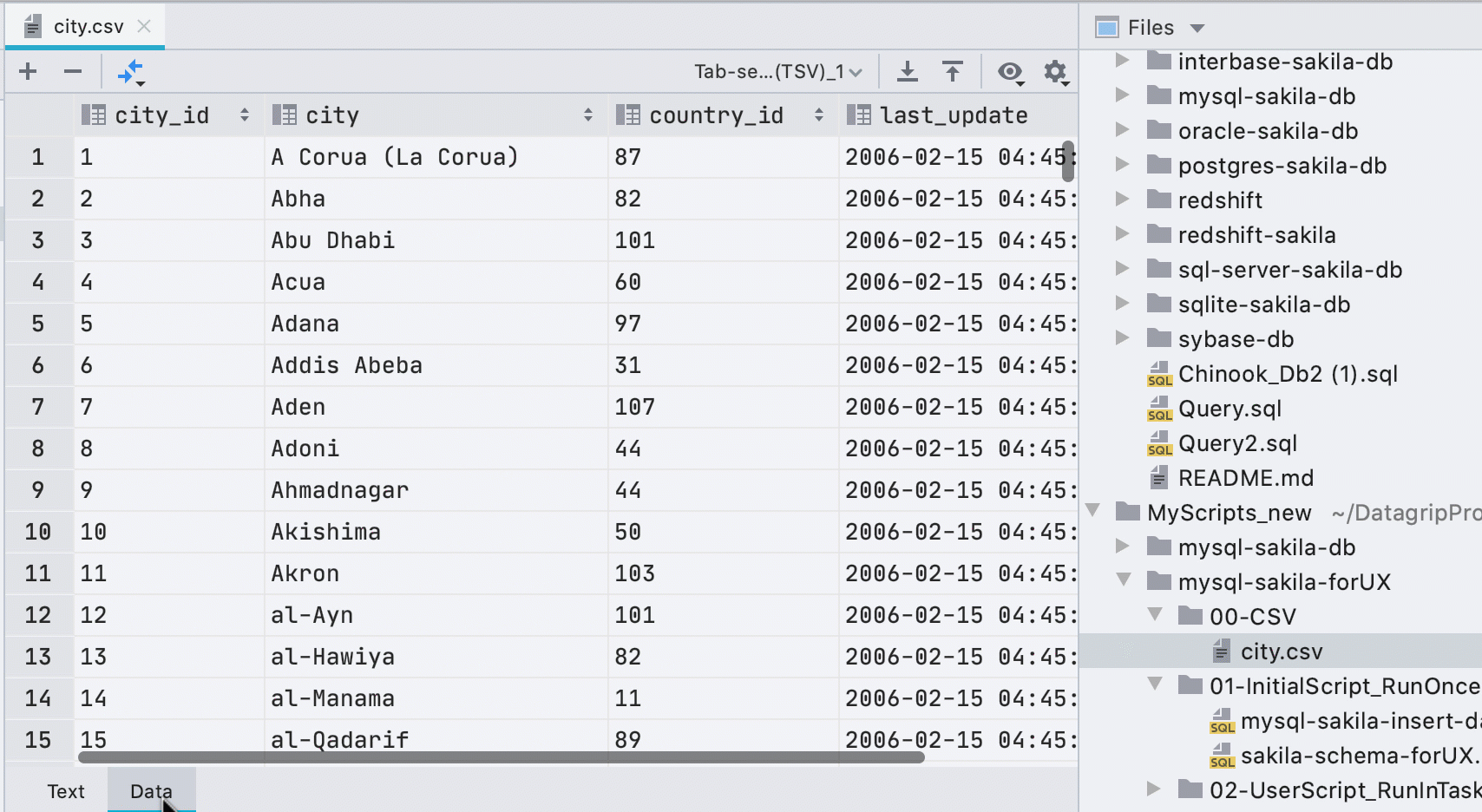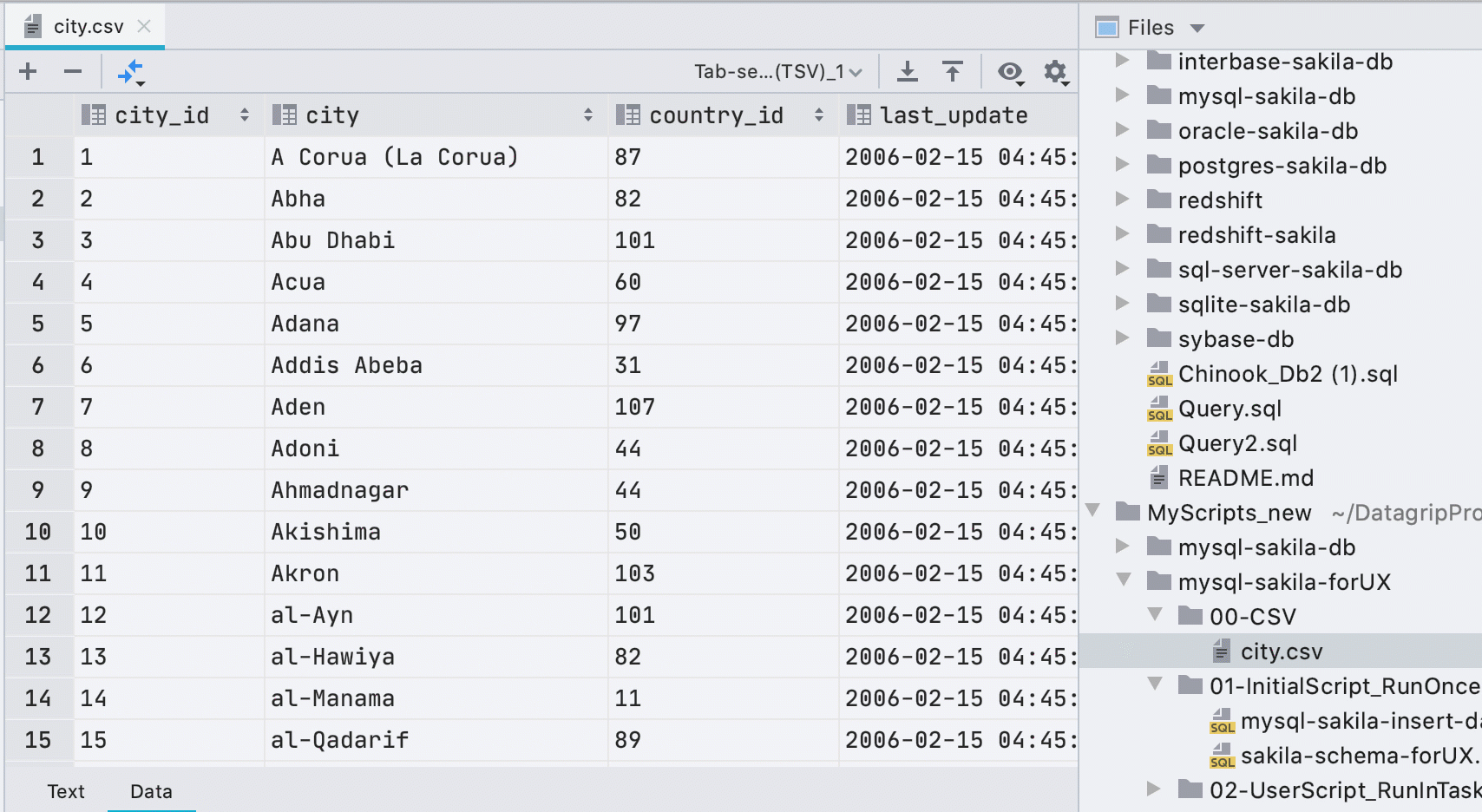
Автоматический редактор данных для CSV файлов
Раньше надо было вызывать редактор данных из контекстного меню, а небольшая желтая плашка при открытии CSV-файлов рекламировала сторонний плагин. Теперь мы сами определяем, что к чему, и показываем вкладку Data для CSV-файлов.
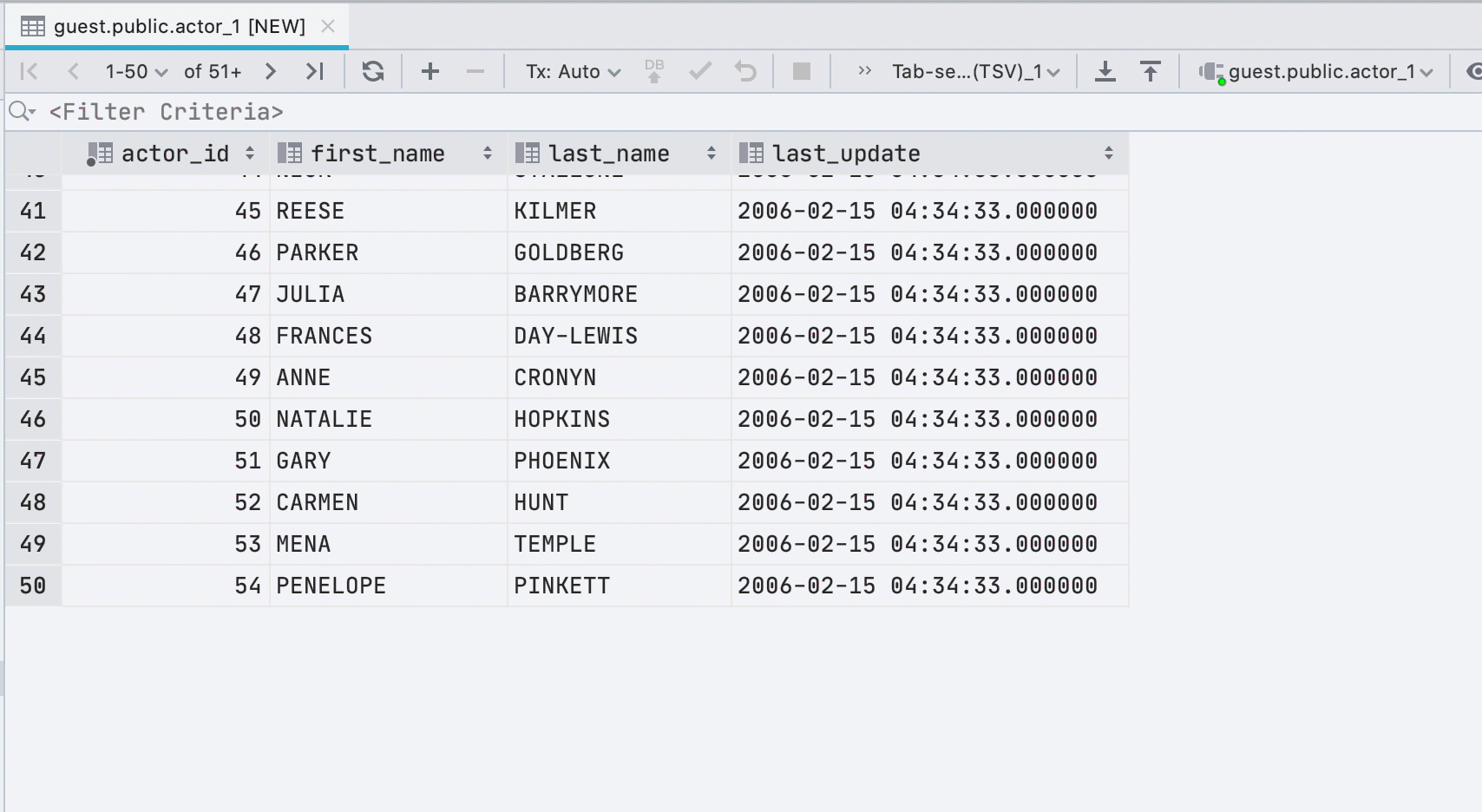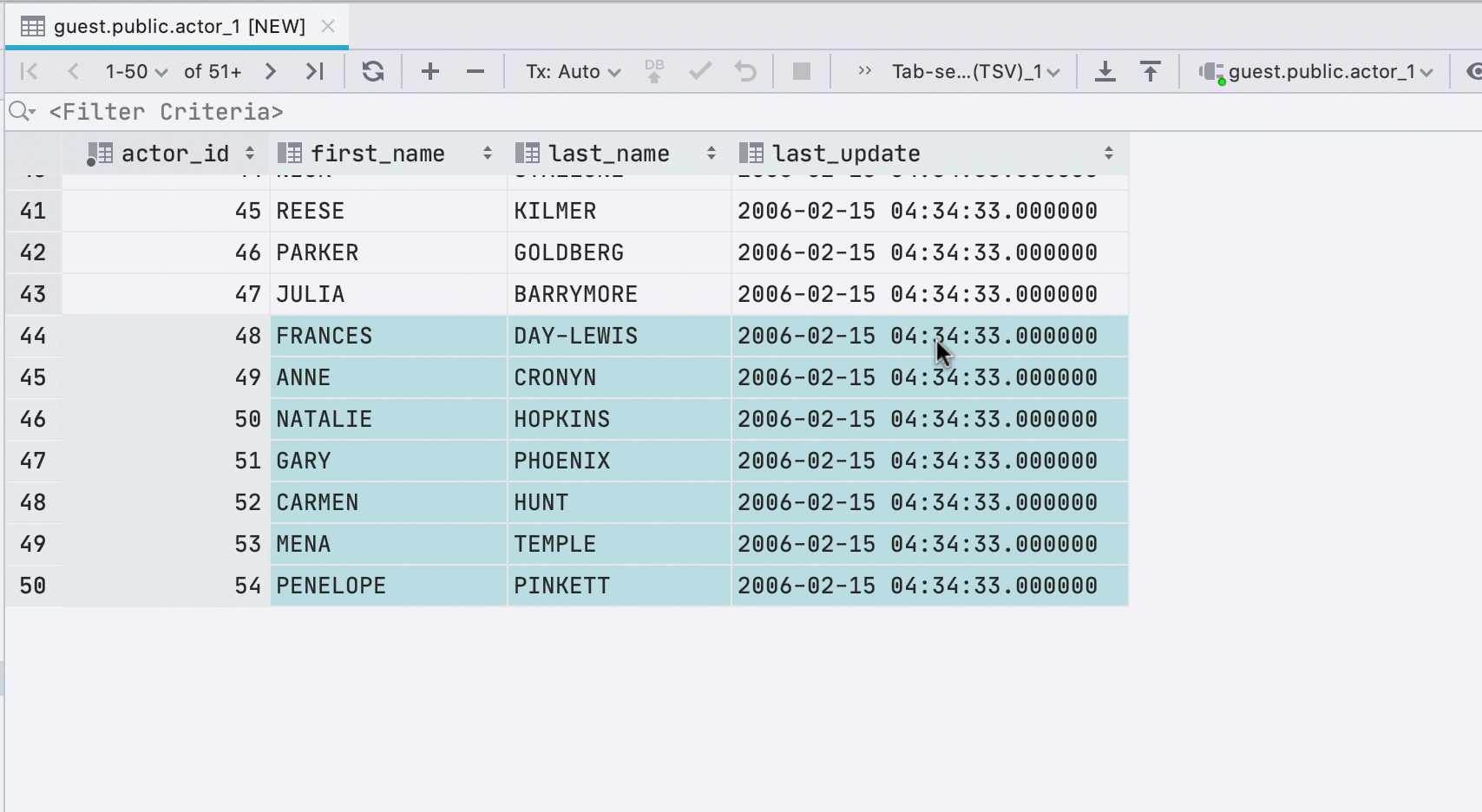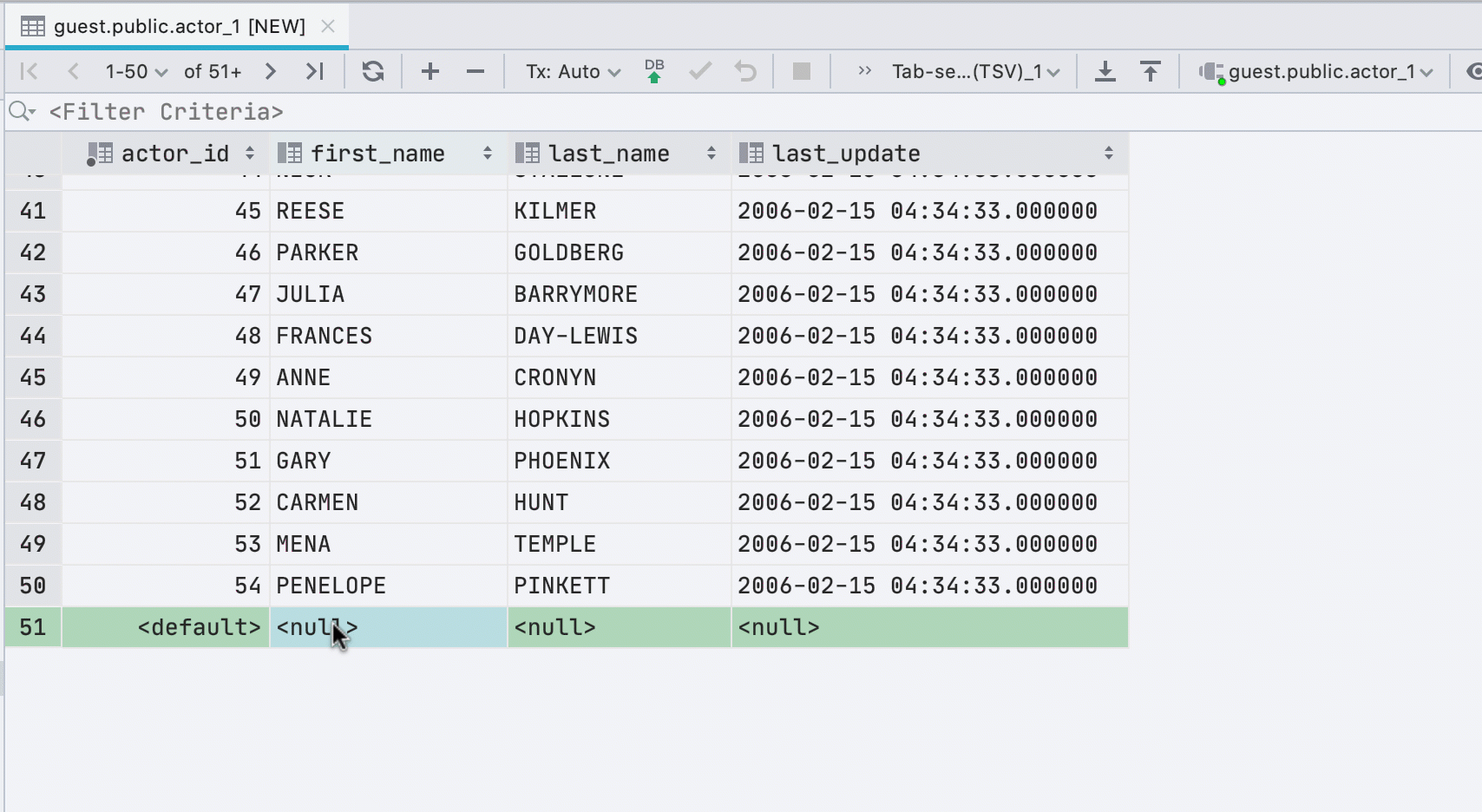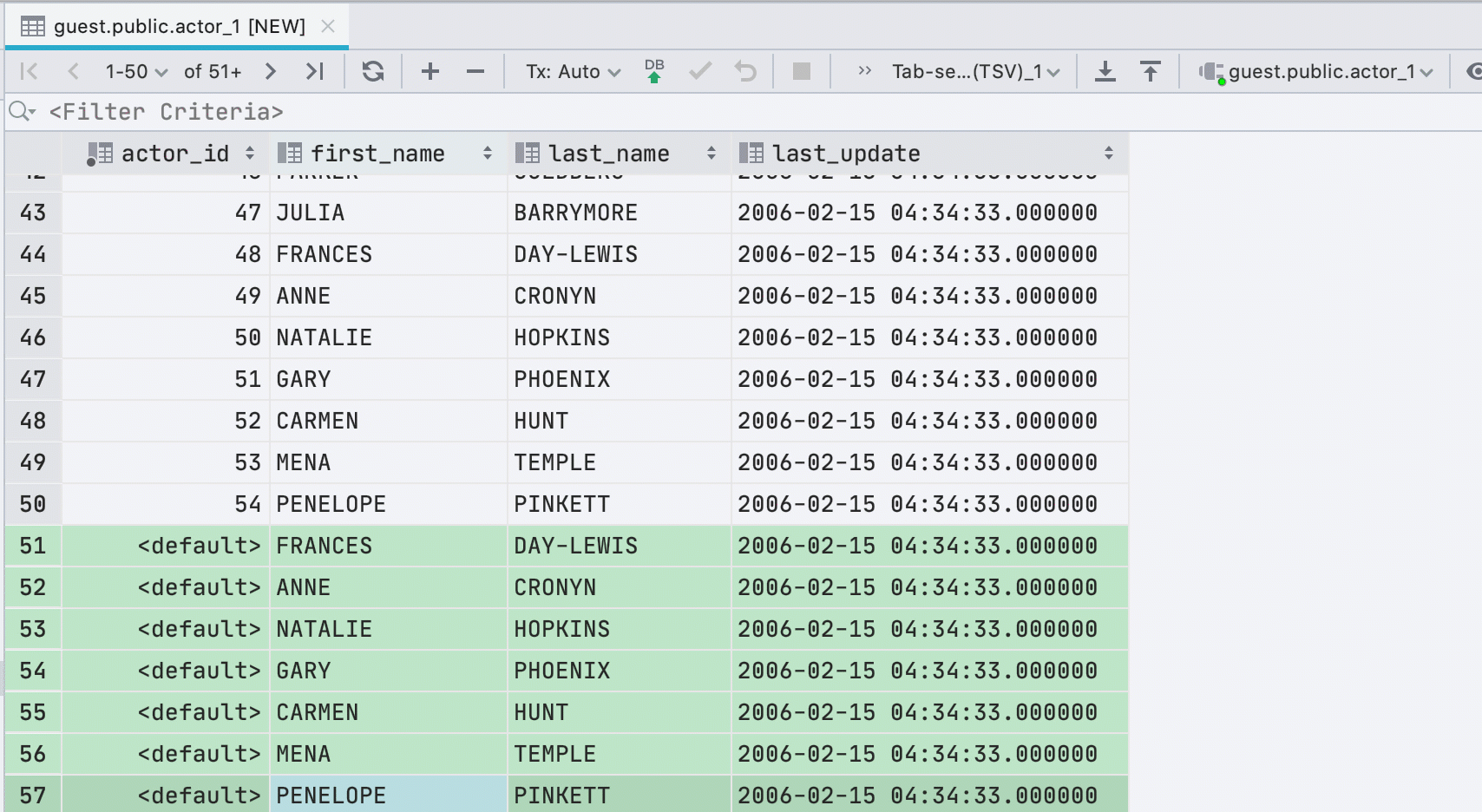
Новые строки при вставке значений
Если вы вставляете данные в таблицу из буфера обмена, то мы автоматически создадим нужное количество новых строк.
Новый интерфейс для недогруженных данных
Иногда DataGrip не может загрузить все данные в ячейку, если они занимают много памяти. Это определяется настройкой Database | Data views | Max LOB length. Раньше мы вставляли текст об этом прямо в значение ячейки, и это неудобно. Сейчас это маленькая отдельная плашка:

Экспорт в буфер обмена из контекстного меню
В прошлом релизе мы сделали диалоговое окно для экспорта, не учтя один маленький случай: стало менее удобно копировать весь результат в буфер обмена мышкой. Теперь это можно сделать из контекстного меню.
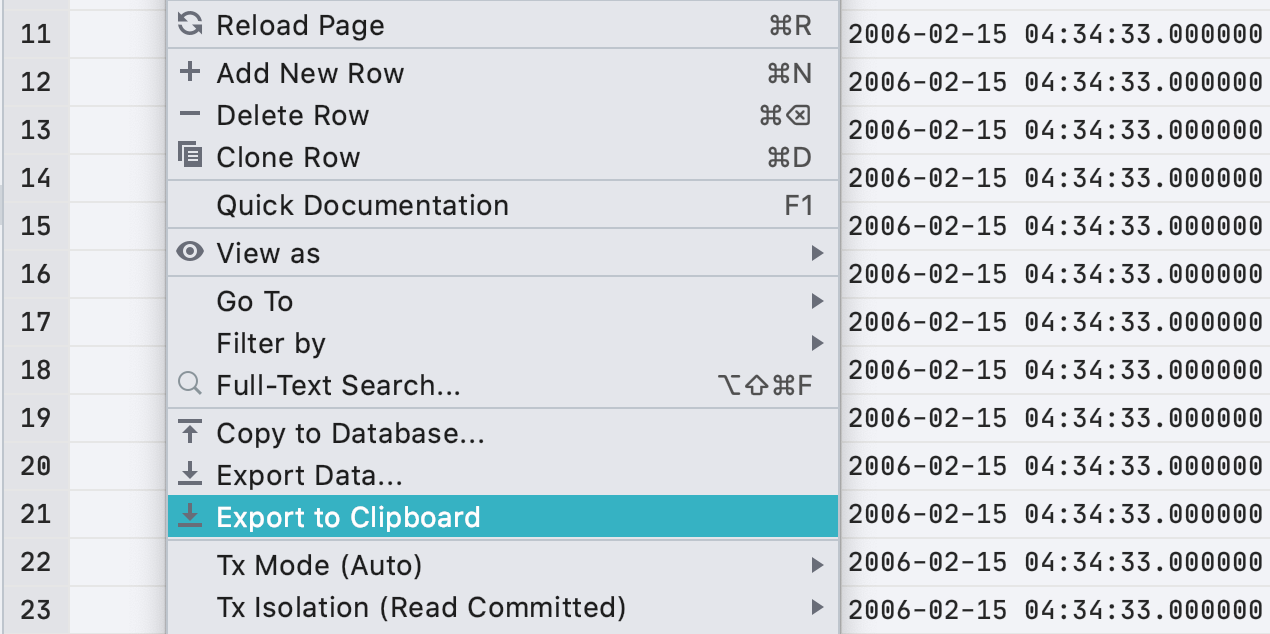
Напомним, что это действие копирует весь результат или таблицу. А Ctrl/Cmd+C или действие
Copy копирует только выделенный фрагмент.
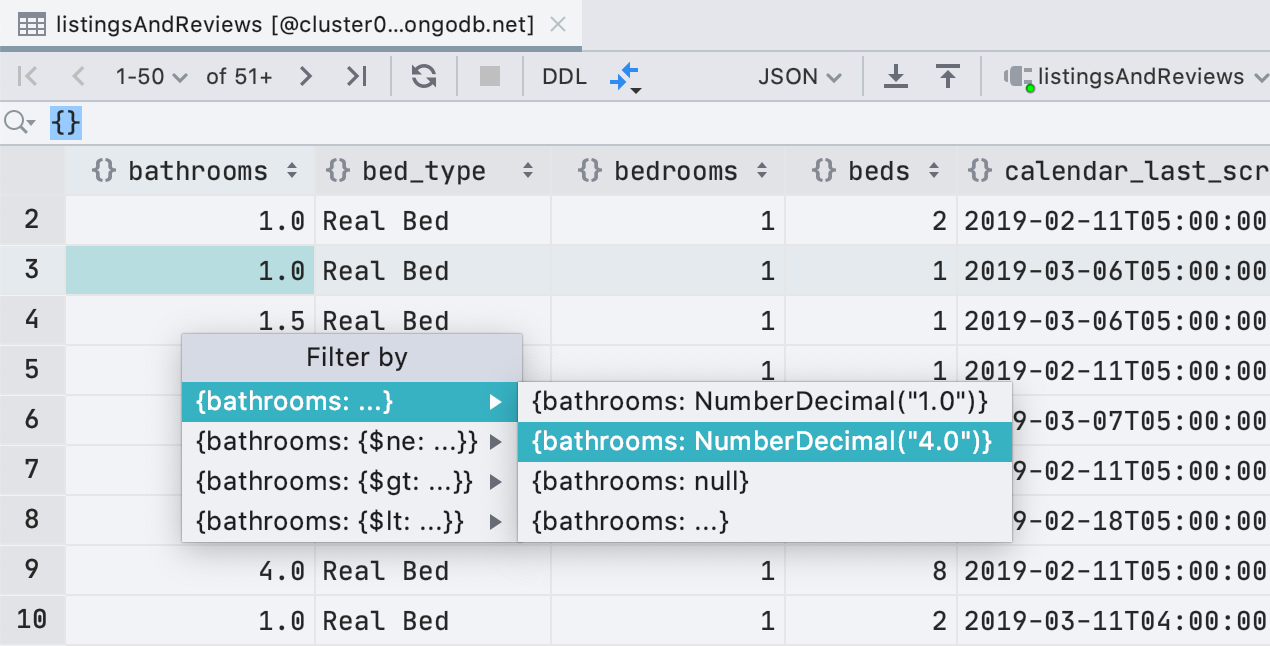
Улучшения фильтрации для MongoDB
Помимо ObjectId и ISODate, теперь можно фильтровать по UUID, NumberDecimal, NumberLong, и
BinData. Также, если у вас в буфере обмена подходящее значение для UUID/ObjectId/ISODate, DataGrip предложит использовать его для фильтрации.
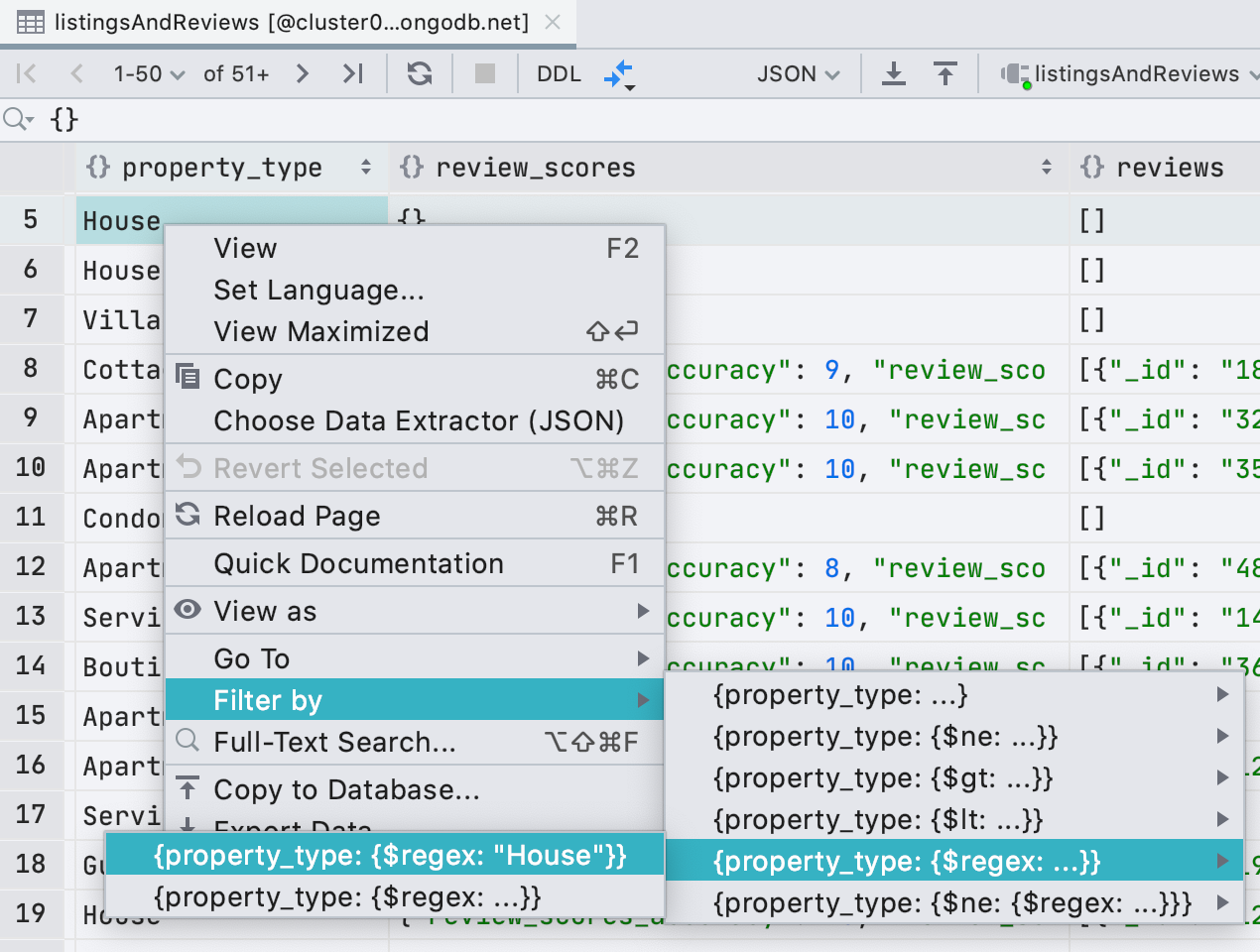
Еще мы добавили в условия фильтра регулярные выражения, чтобы вы не слишком скучали по
LIKE из фильтра в реляционных базах.
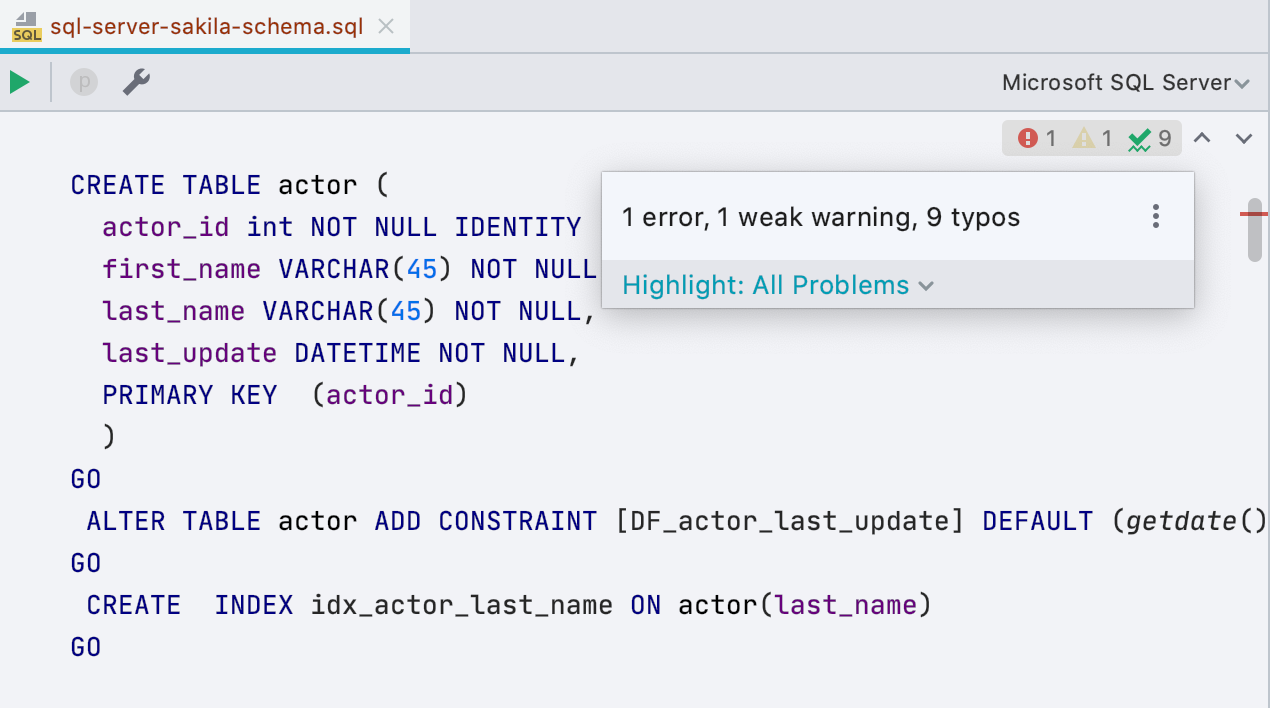
Новый виджет с инспекциями
Справа от редактора появилась маленькая панель — она расскажет, сколько в скрипте ошибок, а сколько мест вызывает подозрение. Оттуда можно навигироваться или выбирать — что подсвечивать, а что нет. Сочетание клавиш F2 всё еще работает для того же самого.
Предложение переименовать
Это появилось во многих наших IDE: если вы переименовали что-нибудь не при помощи встроенного рефакторинга, а поменяли имя в коде, вам предложат сделать рефакторинг и переименовать и все использования. Вот, например, как это работает с алиасами:

Автодополнение JOIN стало лучше
Раньше, чтобы мы предложили условие для JOIN полностью, нужно было набрать это ключевое слово. Теперь понимаем, что нужно, как только вы набрали
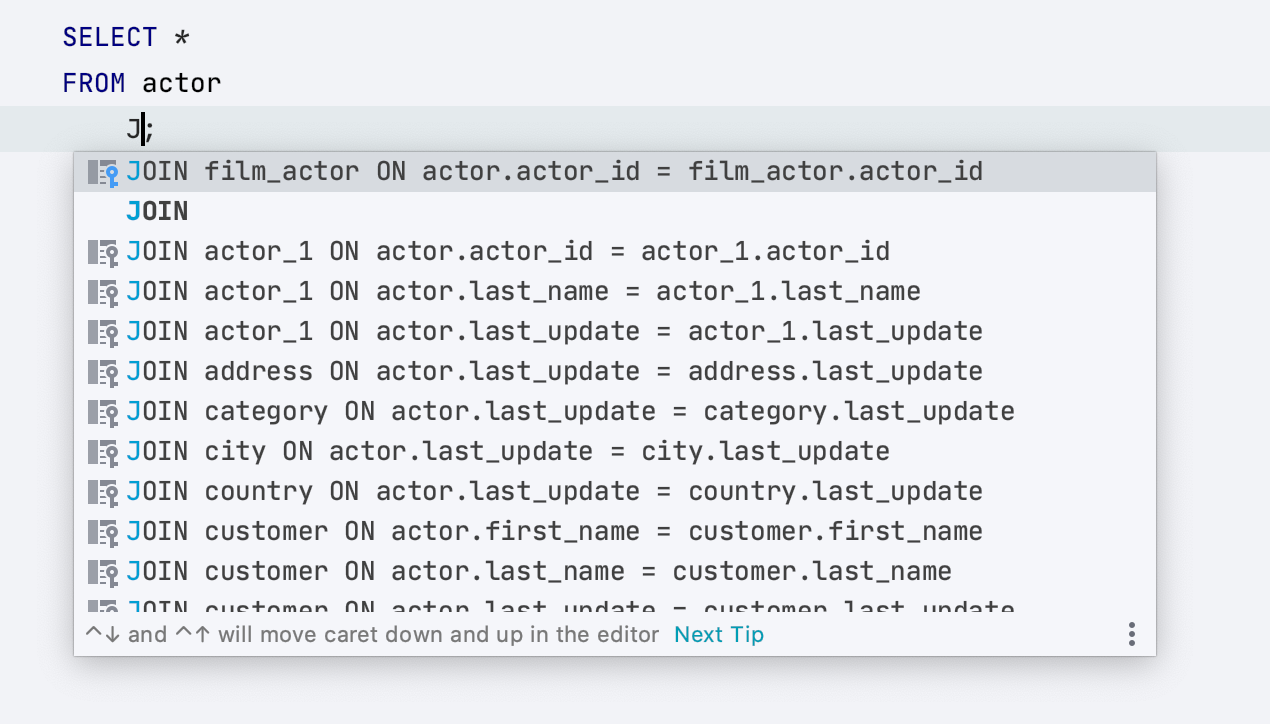
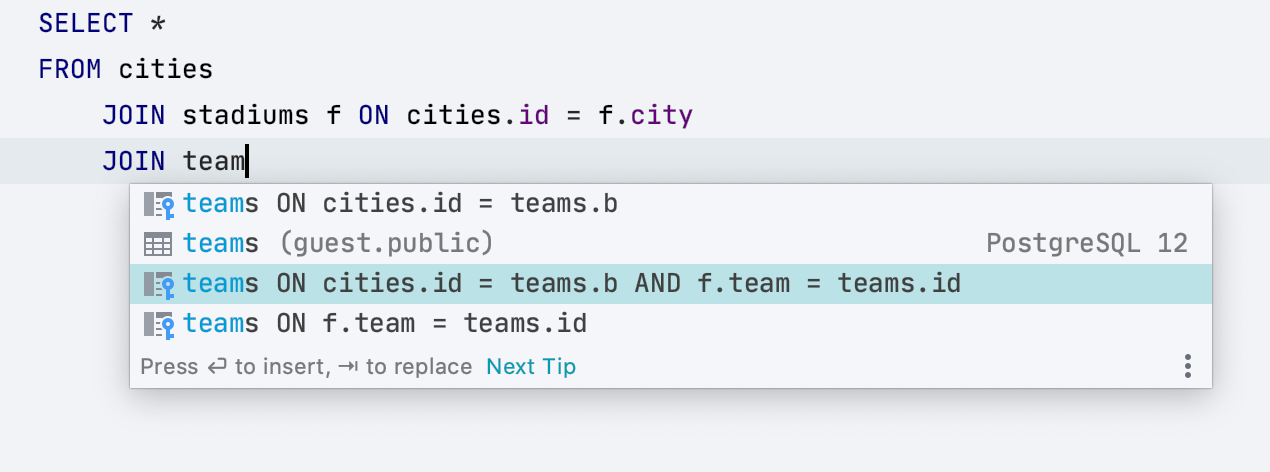
Еще научились предлагать двойные условия, если так выставлены ключи таблиц.
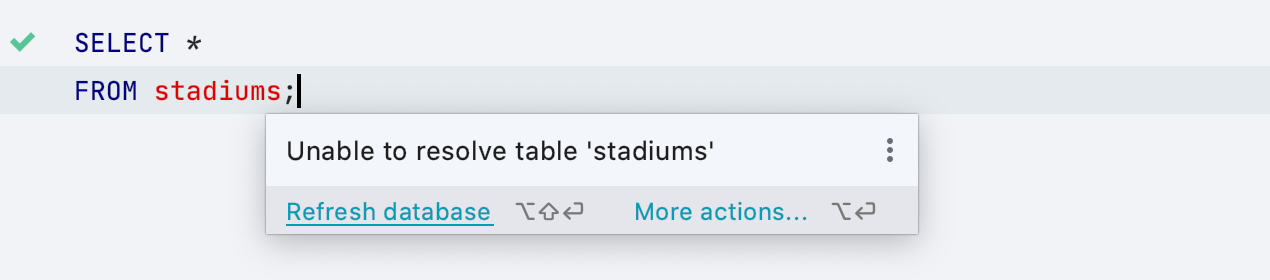
Обновить информацию о базе
Если DataGrip ничего не знает об объектов из ваших запросов, то сообщит вам об этом. Иногда это происходит, если вы просто опечатались. Также бывает, что файл был ассоциирован не с тем источником данных. Еще одна причина такого события — объект уже появился, но DataGrip не получил информации о нем из базы. Для этого мы добавили возможность запустить обновление структуры базы из редактора, если объект неизвестен.
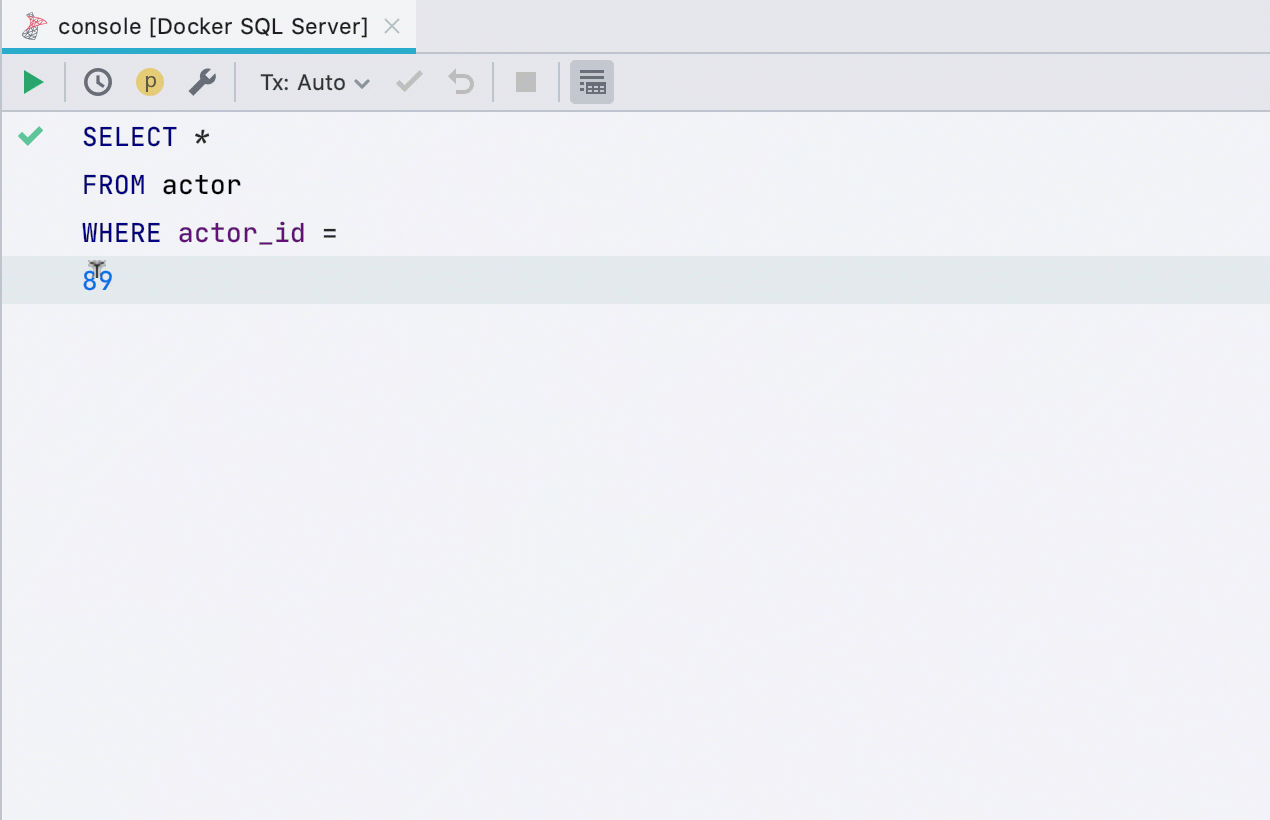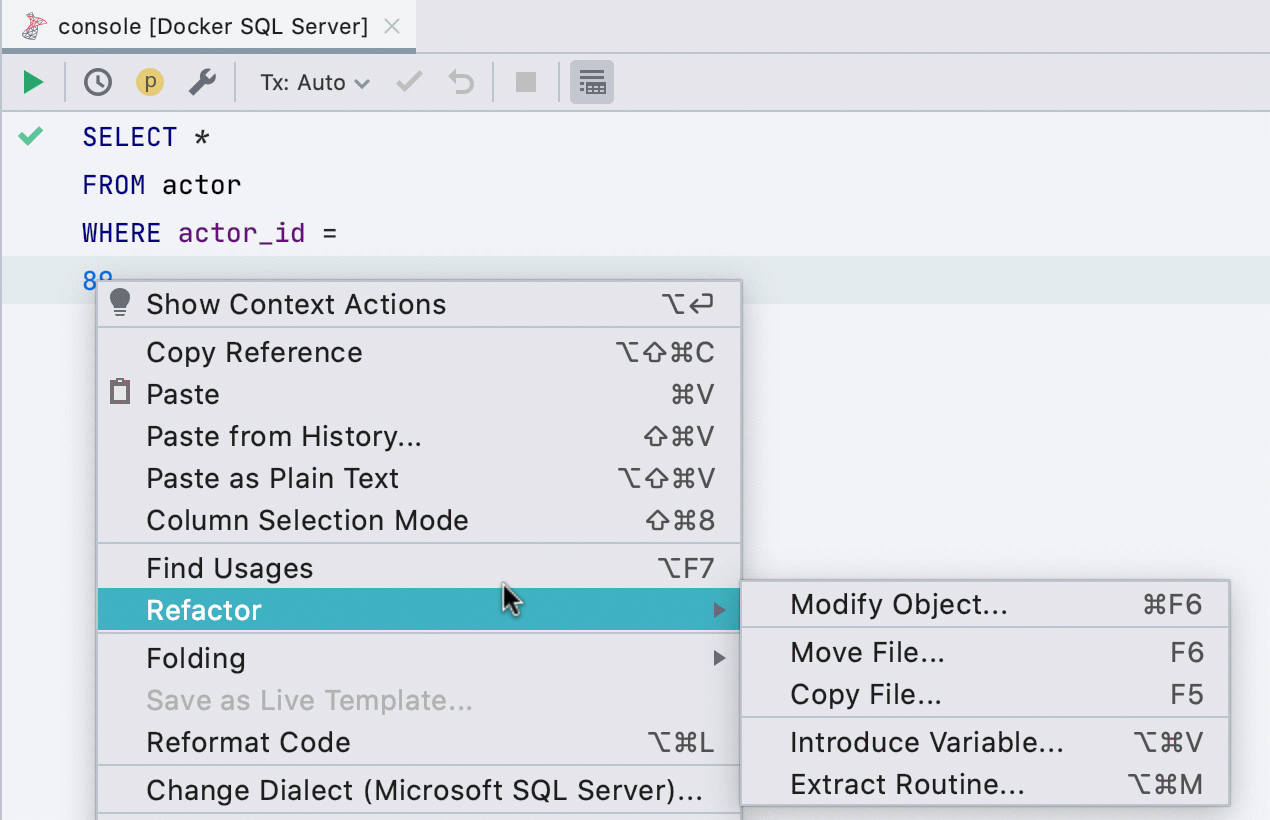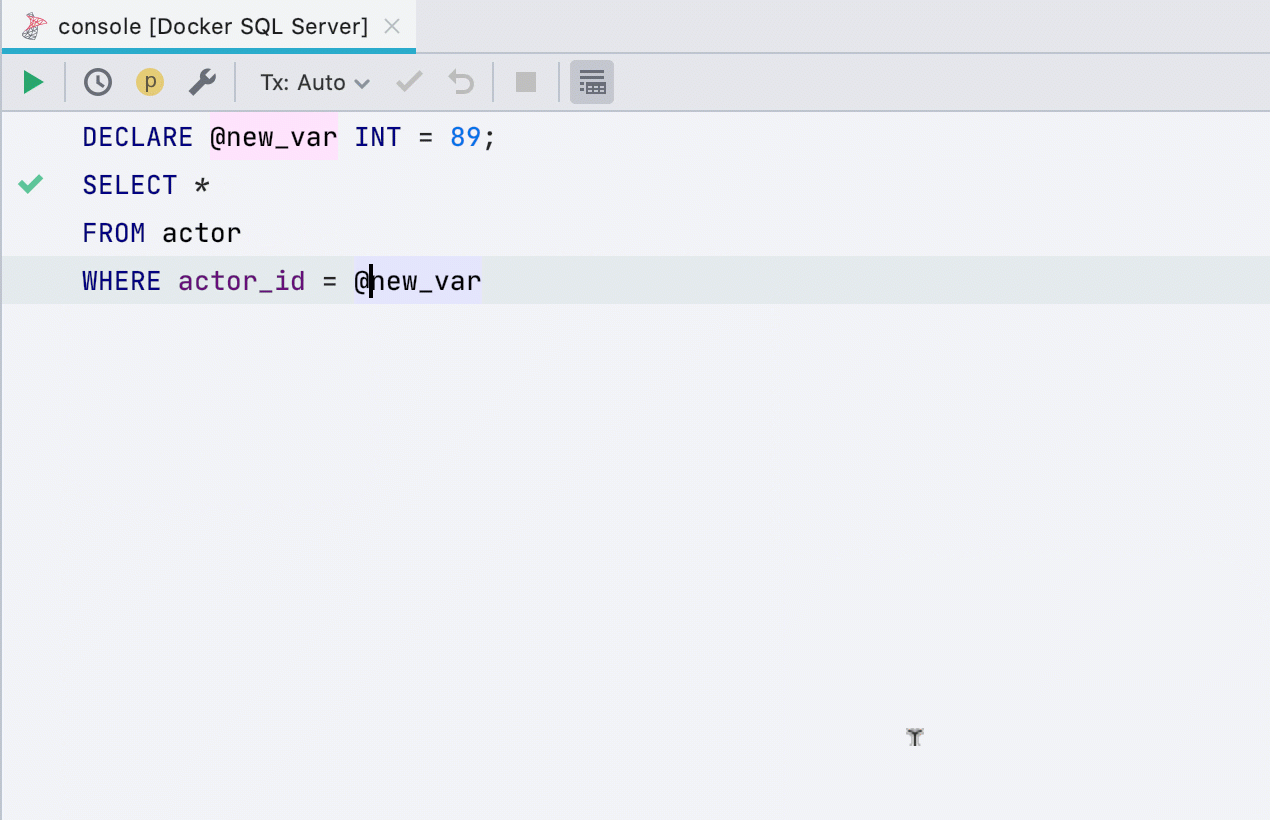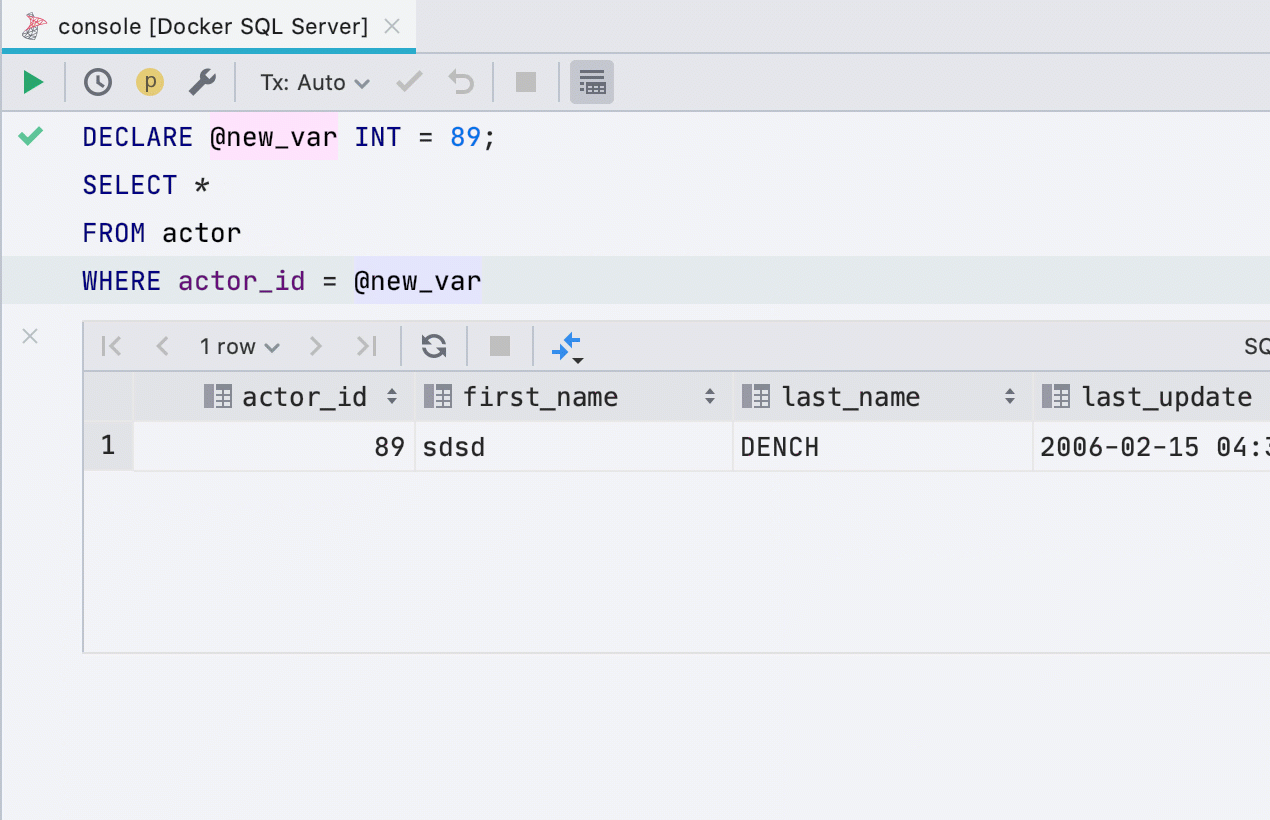
Выделить переменную
Этот рефакторинг раньше работал не для всех баз, теперь работает в SQL Server, Db2, Exasol, HSQL, Redshift и Sybase.
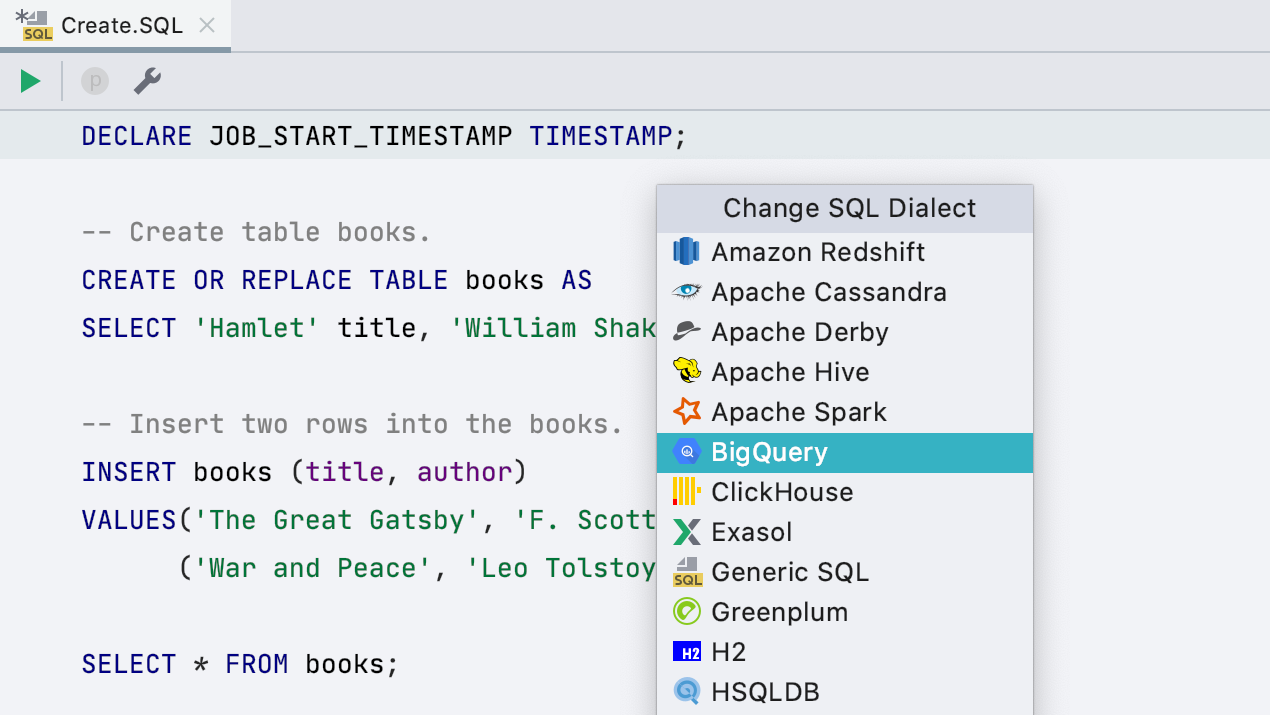
Подсветка Google BigQuery
В списке диалектов пополнение: Google BigQuery. Пока это не полноценная поддержка базы, а только правильная подсветка кода. Соответственно, для запуска запросов не надо выделять код, мы сами определим, что запустить.
Подсветка TextMate
Как и другие наши IDE, DataGrip теперь умеет подсвечивать код при помощи плагина TextMate. Может пригодиться, если у вас есть скрипты на Python, lua, javascript. Полный список языков есть в Settings/Preferences | Editor | TextMate bundles.
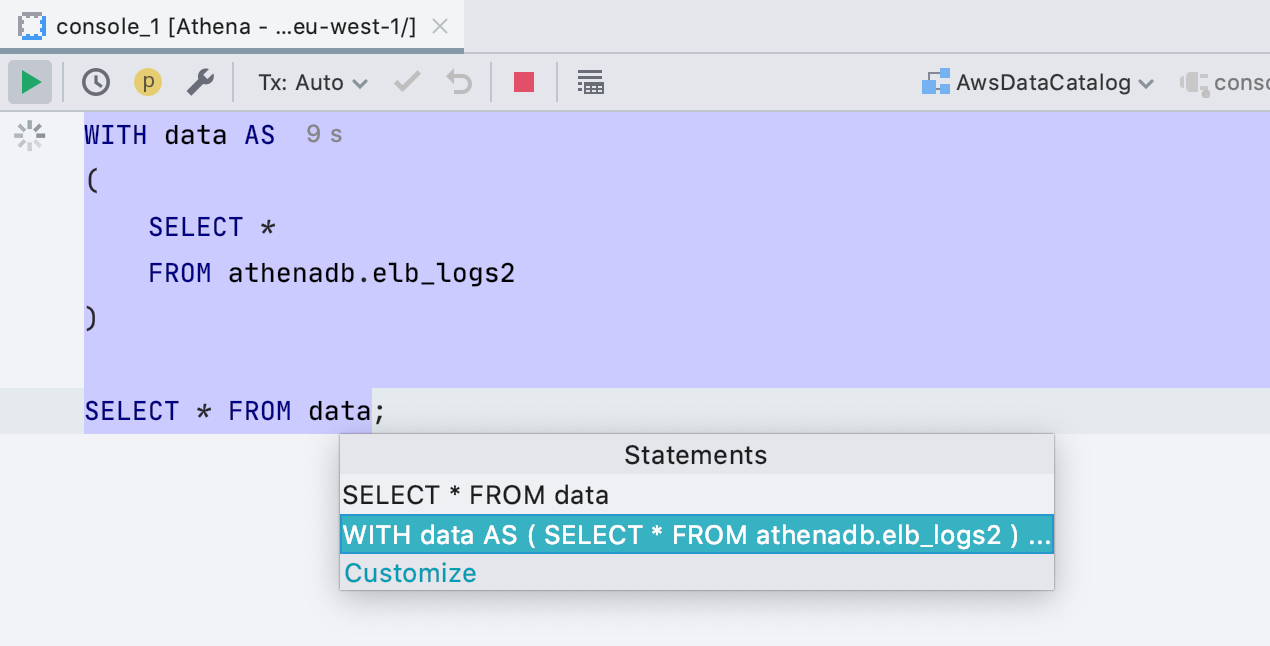
SQL 2016 в качестве диалекта <Generic>
Если работаете с базой, которую мы не поддерживаем, запросы парсятся и подсвечиваются диалектом <Generic>. Раньше это был SQL 92, теперь SQL 2016. Самое важное — теперь мы корректно обрабатываем запросы с блоком WITH, соответственно они не только правильно подсвечены, но и запускать их можно без выделения кода.
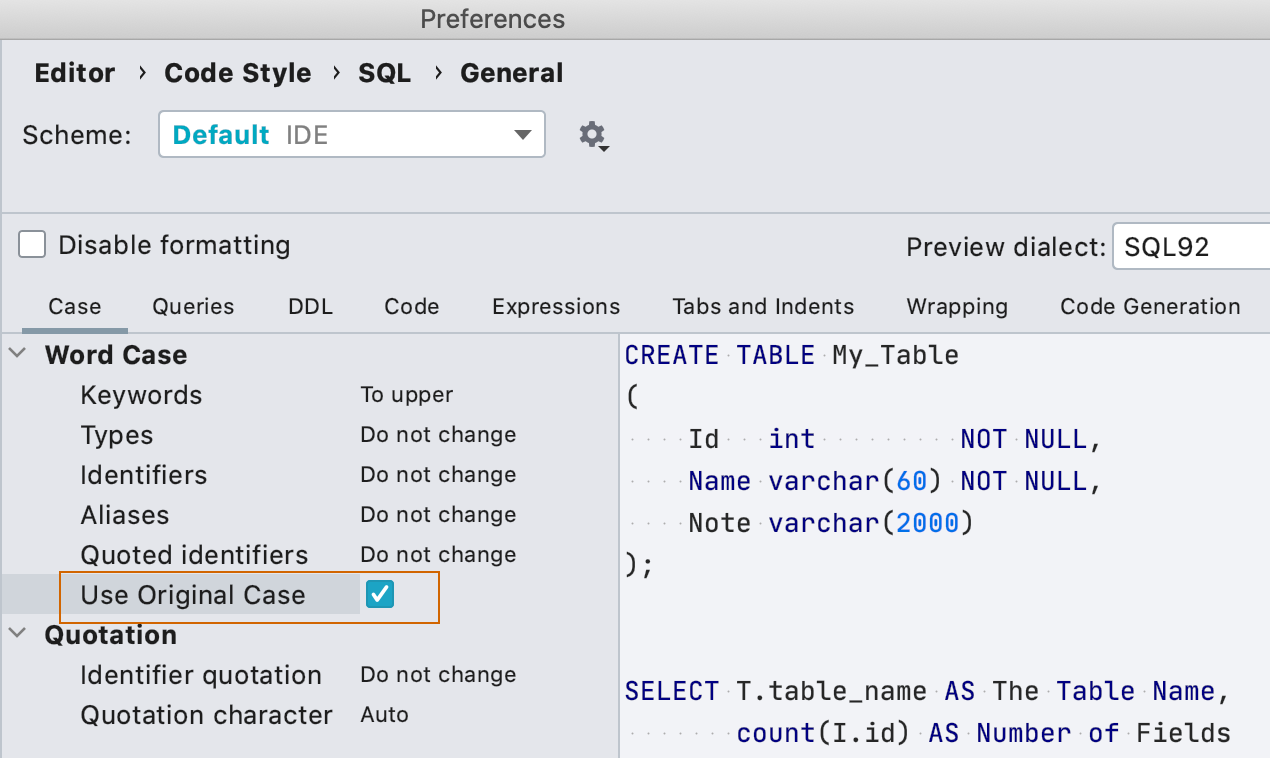
Регистр имён объектов в форматировании
В настройках форматирования были три настройки для имён объектов базы данных — прописными, строчными или не менять. Но оказалось, что есть и четвертый случай: пользователи хотят использовать тот регистр, который был использован при создании объекта в скрипте. Мы это поддержали.
В примере таблица Actor создана с первой заглавной, и в использовании мы привели имя таблицы к такому же регистру.

Мы ищем скрипты создания только внутри того же файла, где происходит форматирование. Если же хотите, чтобы форматтер нашёл объявление объекта в соседнем файле, создайте из своих файлов источник данных на основе DDL.
Несколько кареток в выделенном фрагменте
Теперь вы можете выделить фрагмент кода и поставить каретку в каждую его строчку. Используйте для этого действие Add Carets to Ends of Selected Lines или сочетание клавиш Shift+Alt+G

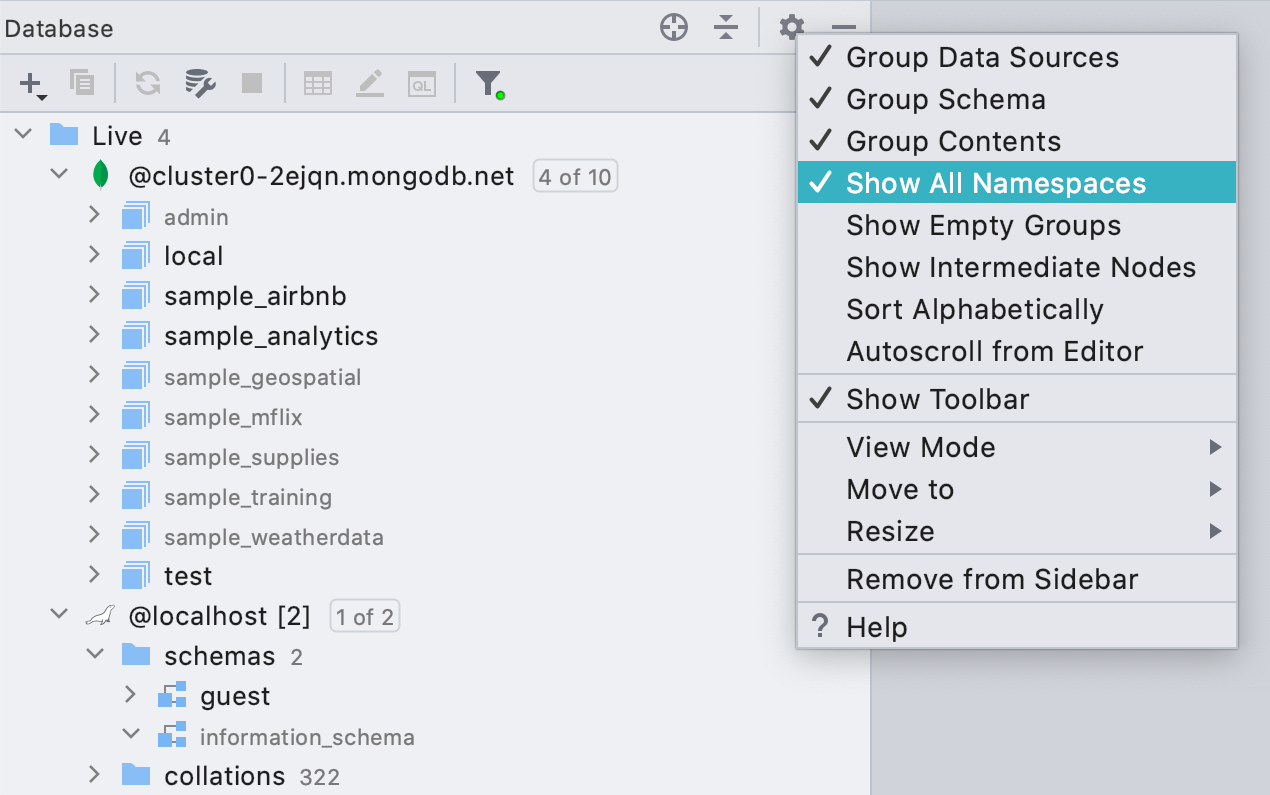
Все базы и схемы в дереве
По умолчанию мы показываем в дереве только те базы и схемы, которые вы выбрали сами. Дерево не ленивое, а вся метаинформация об объектах используется для дальнейшей работы IDE. Поэтому мы загружаем только то, что нужно, чтоб случайно не повиснуть на гигантской базе.
Однако многие привыкли к инструментам, которые всегда показывают все объекты, и люди, которые не знакомы с нашей концепцией могут терять из виду базы и схемы. Поэтому мы сделали настройку Show All Namespaces, и когда она включена, в дереве будут показаны все базы и схемы, даже если информация об их объектах не загружена. Такие схемы и базы отмечены серым шрифтом.
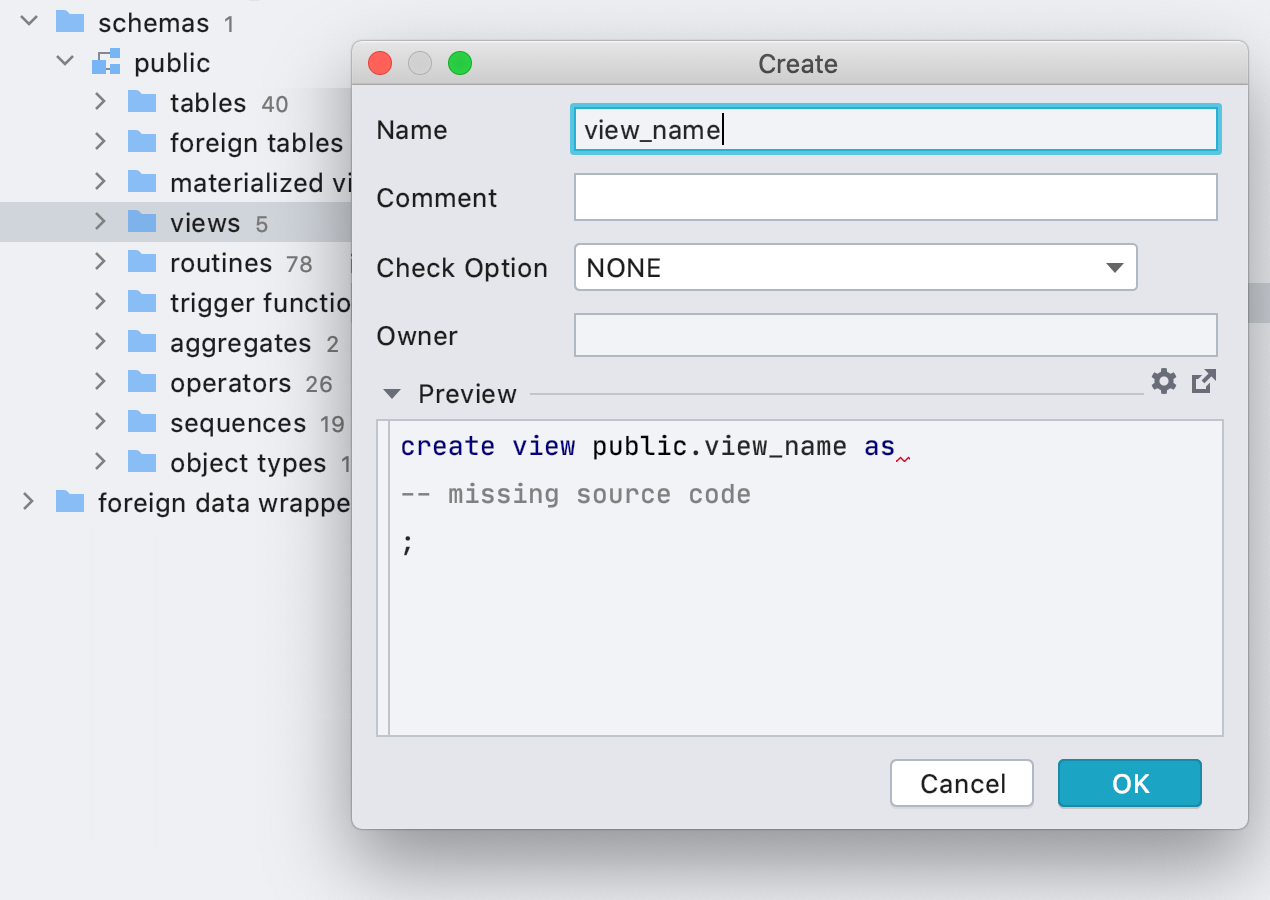
Интерфейс для создания представлений
Мы обычно говорим, что функция генерации кода в редакторе (Alt+Ins или Cmd+N) покрывает многие потребности разработчика по созданию объектов, но иногда это всё же менее удобно. Поэтому мы начали добавлять интерфейсы для создания объектов: в новой версии можно создавать представления.
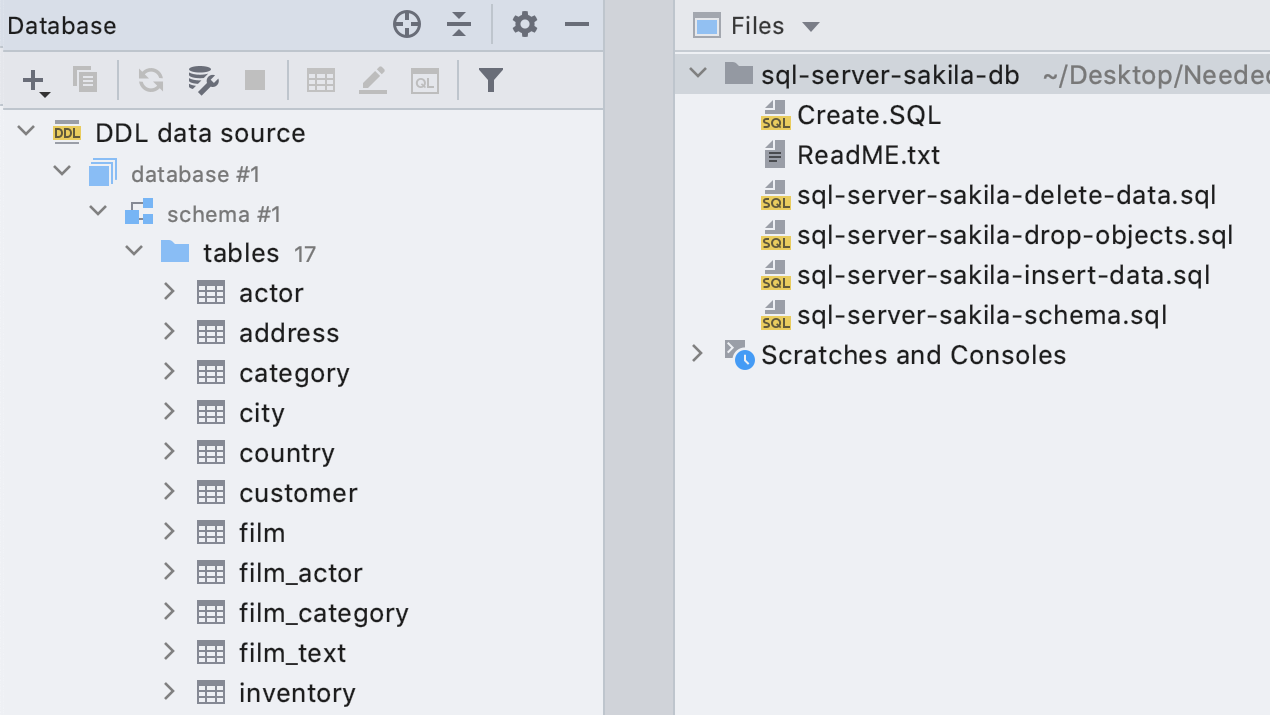
Файлы скриптов в панели Files
Если вы создали источник данных на основе DDL, эти файлы автоматически попадут в панель
Files. Так вам будет удобно их просматривать и редактировать.
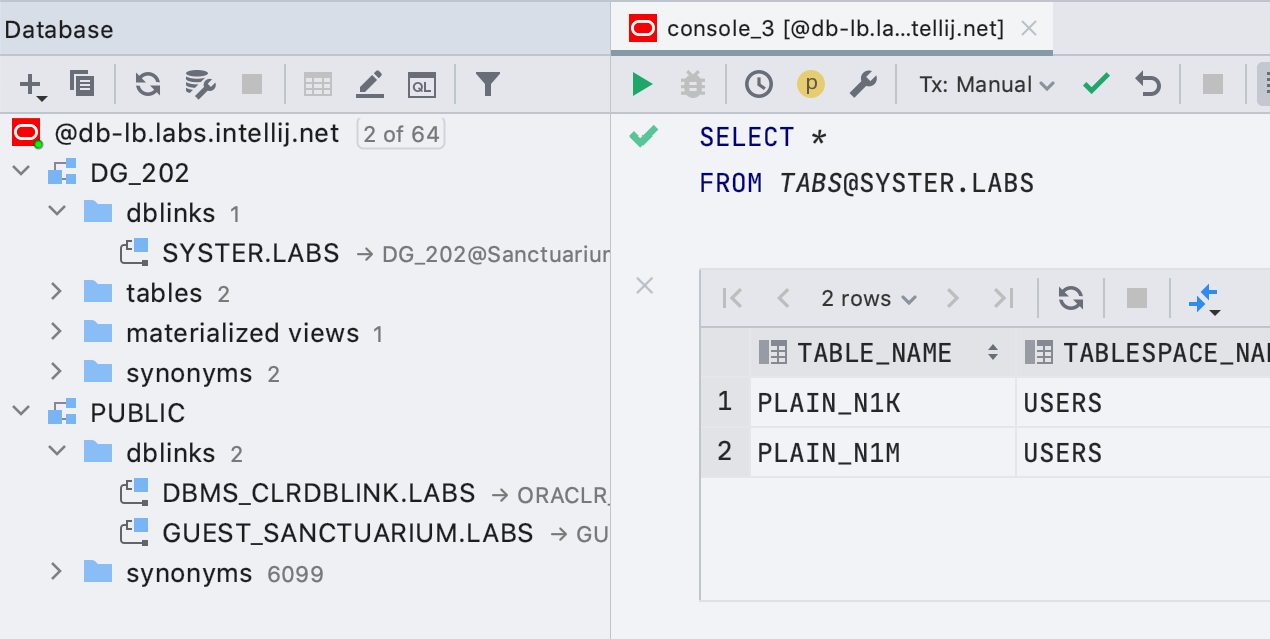
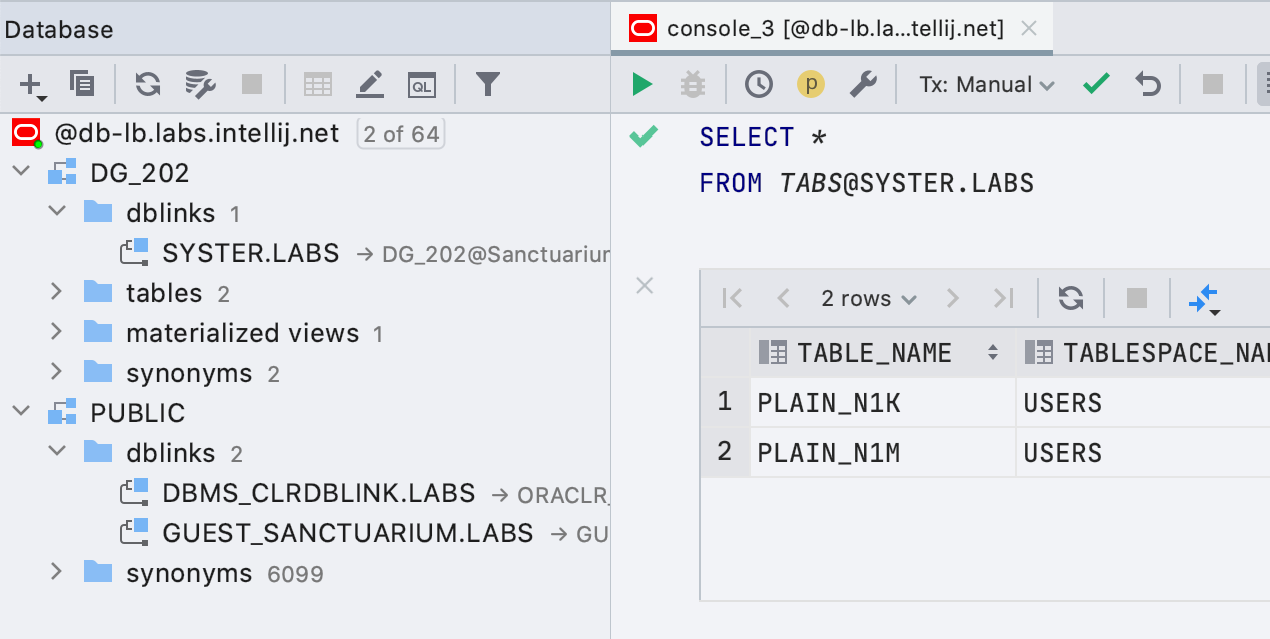
Простая поддержка ссылок на базы данных в Oracle
Ссылки на базы данных теперь показываются в проводнике, а запросы, которые их используют, подсвечены правильно.
Больше никаких длинных имён вкладок
Вы часто жаловались, что вкладки неконтролируемо разрастаются.
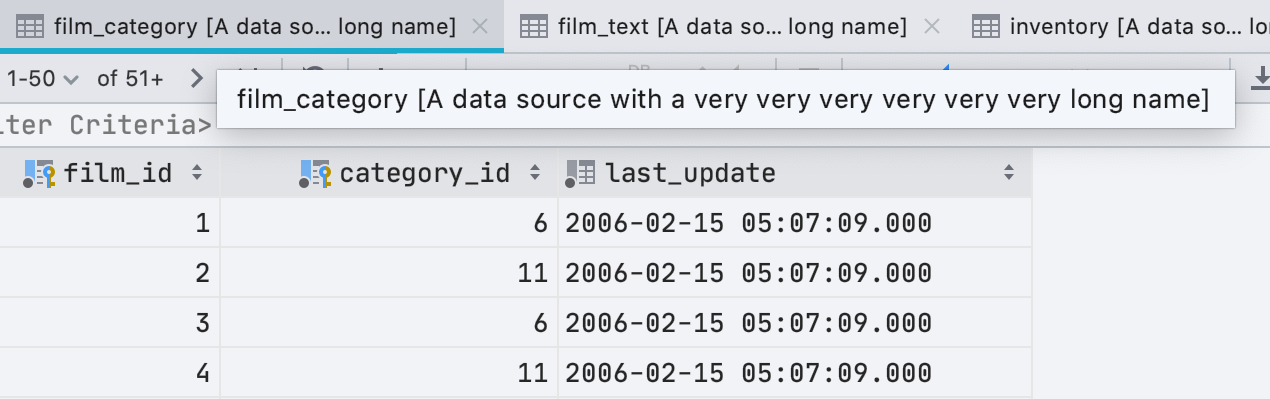
Отныне:
Поддержка MongoDB shell
Месяц назад мы обновили драйвер, который используем для подключения к MongoDB и он стал поддерживать MongoDB shell. Это означает, что заработали новые команды и методы, например help, db.getCollectionInfos(), db.getCollectionNames(), db.collection.remove() и другие. Подробная статья на английском о поддержке MongoDB shell здесь.
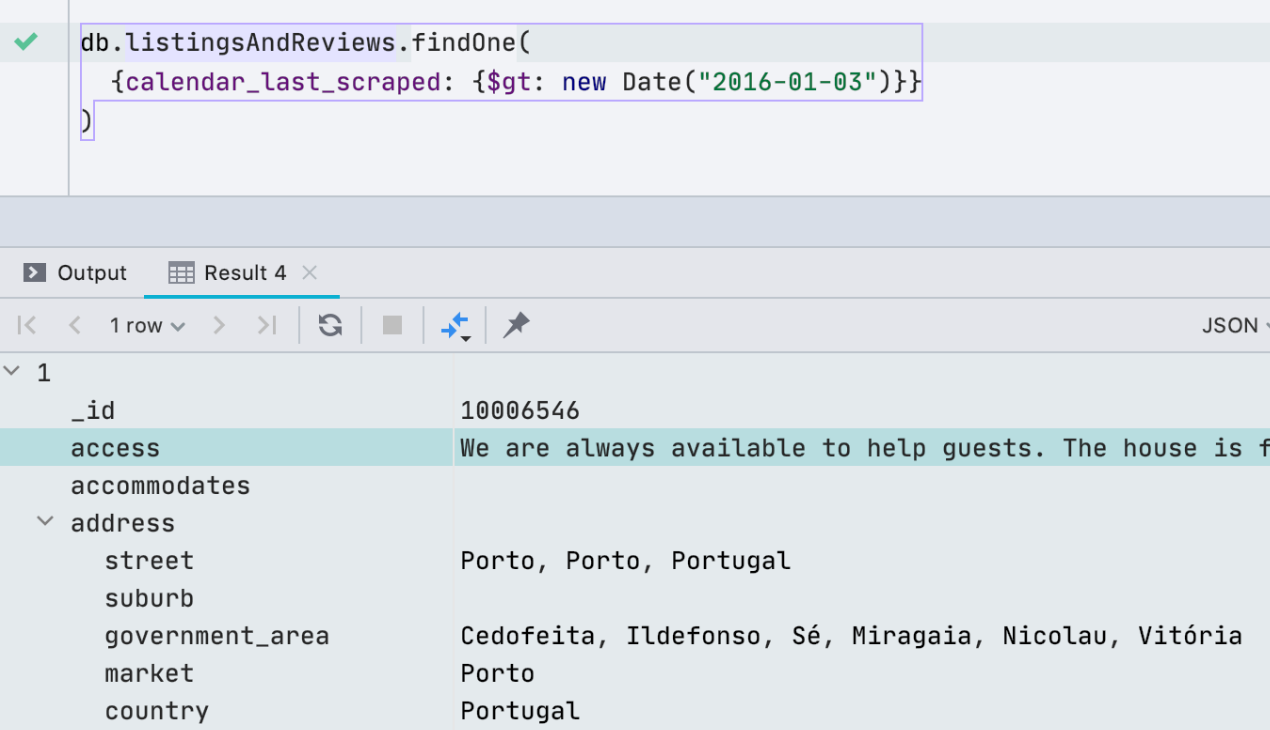
Нативные библиотеки в настройках драйвера
Теперь можно указать путь к нативной библиотеке, которая нужна драйверу. Вот несколько случаев, когда это может понадобится.
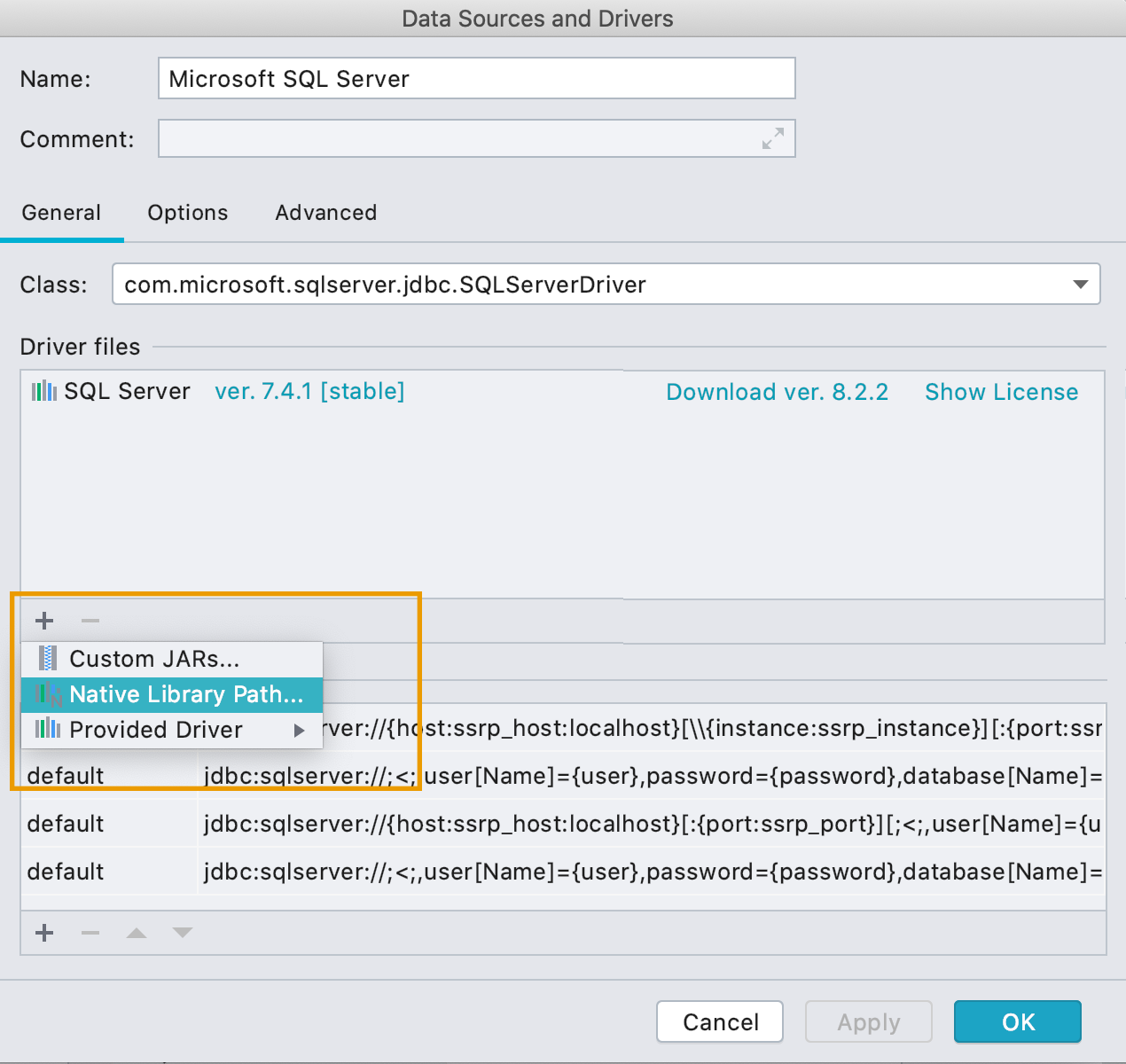
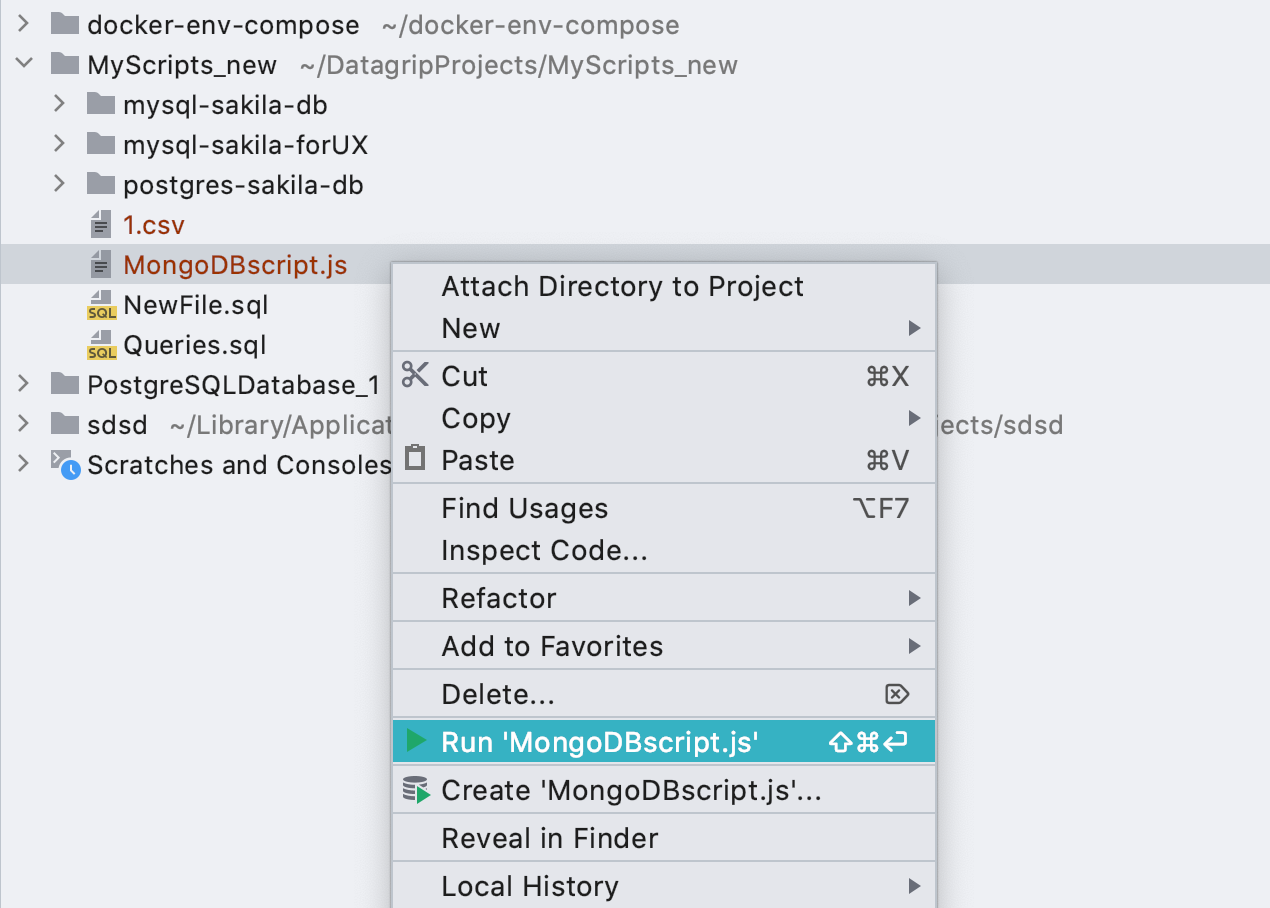
Конфигурации запуска для файлов *.js
Теперь конфигурации запуска работают и для скриптов базы MongoDB.
Интеграция с Git и Github работает из коробки
Наш опрос показал, что довольно много людей хранят скрипты в системах контроля версий, поэтому мы решили упаковывать два самых популярных плагина в этой области.
Спасибо за внимание! Напомним, что у нас есть свой канал в Телеграме, там можно задавать вопросы и делиться опытом. Но если нашли баг, лучше сразу пишите в трекер, чтобы он не потерялся. Ну и сюда, конечно, тоже комментарии пишите :)
На этом всё!
Команда DataGrip

Редактор данных
Редактор больших значений
Мы приделали полноценный редактор к ячейкам. Если в ячейке длинное значение, например XML или JSON, его удобно открыть в отдельной панели. Для этого нажмите
Maximize в контекстном меню.
Предпросмотр запроса при редактировании
Теперь, прежде чем записать новые значения в редакторе данных, можно посмотреть, какой запрос будет выполнен. Для этого нажмите кнопку DML на панели инструментов.
Если честно, это не именно тот запрос, который мы запустим, потому что для редактирования данных DataGrip использует JDBC-драйвер. Но в большинстве случаях то, что мы покажем будет совпадать с тем, что реально запустится.
Новое отображение логических ячеек
Раньше для отображения ячеек с типом boolean мы использовали чекбокс. Это было неудобно: не все понимали, как отличать null от false, а default, computed и null и вовсе отображались одинаково. Мы решили не мудрить и писать значение текстом.
У чекбокса был один плюс: легко визуально находить значения true. В новом интерфейсе эту задачу выполняет точка.
Нам повезло: в английском языке все возможные значения начинаются с разных букв. Поэтому для редактирования достаточно нажать первую букву нужного вам значения: f, t, d, n, g или c. Если напечатать что-то другое, покажем выпадающий список. А пробел переключает между доступными значениями.
Автоматический редактор данных для CSV файлов
Раньше надо было вызывать редактор данных из контекстного меню, а небольшая желтая плашка при открытии CSV-файлов рекламировала сторонний плагин. Теперь мы сами определяем, что к чему, и показываем вкладку Data для CSV-файлов.
Новые строки при вставке значений
Если вы вставляете данные в таблицу из буфера обмена, то мы автоматически создадим нужное количество новых строк.
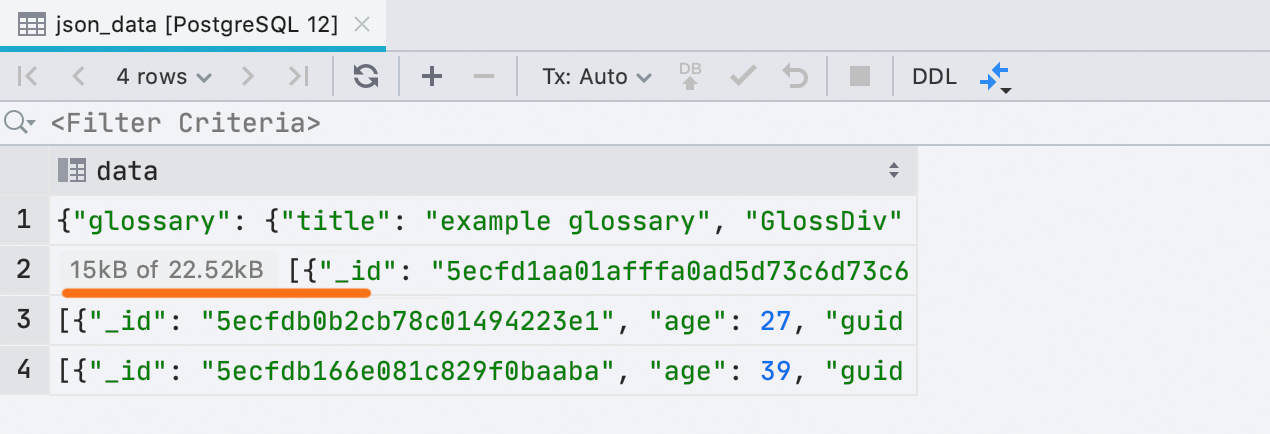
Новый интерфейс для недогруженных данных
Иногда DataGrip не может загрузить все данные в ячейку, если они занимают много памяти. Это определяется настройкой Database | Data views | Max LOB length. Раньше мы вставляли текст об этом прямо в значение ячейки, и это неудобно. Сейчас это маленькая отдельная плашка:
Экспорт в буфер обмена из контекстного меню
В прошлом релизе мы сделали диалоговое окно для экспорта, не учтя один маленький случай: стало менее удобно копировать весь результат в буфер обмена мышкой. Теперь это можно сделать из контекстного меню.

Напомним, что это действие копирует весь результат или таблицу. А Ctrl/Cmd+C или действие
Copy копирует только выделенный фрагмент.
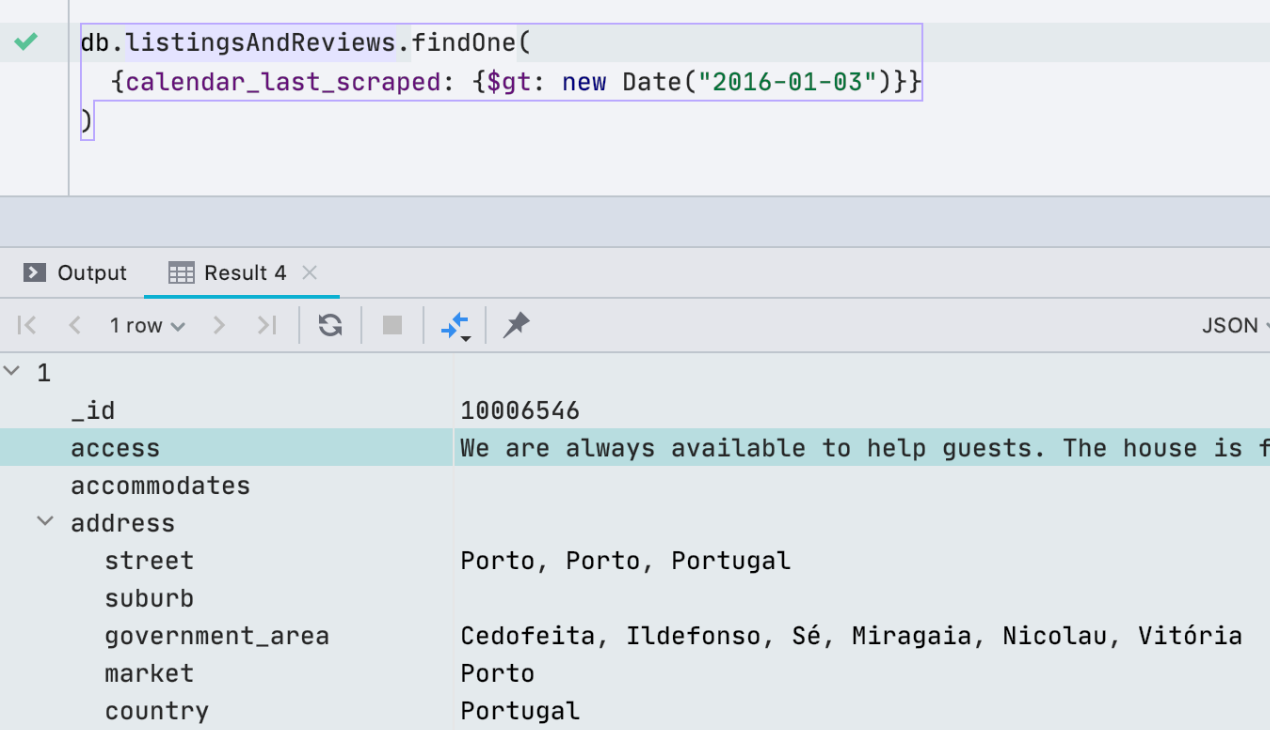
Улучшения фильтрации для MongoDB
Помимо ObjectId и ISODate, теперь можно фильтровать по UUID, NumberDecimal, NumberLong, и
BinData. Также, если у вас в буфере обмена подходящее значение для UUID/ObjectId/ISODate, DataGrip предложит использовать его для фильтрации.
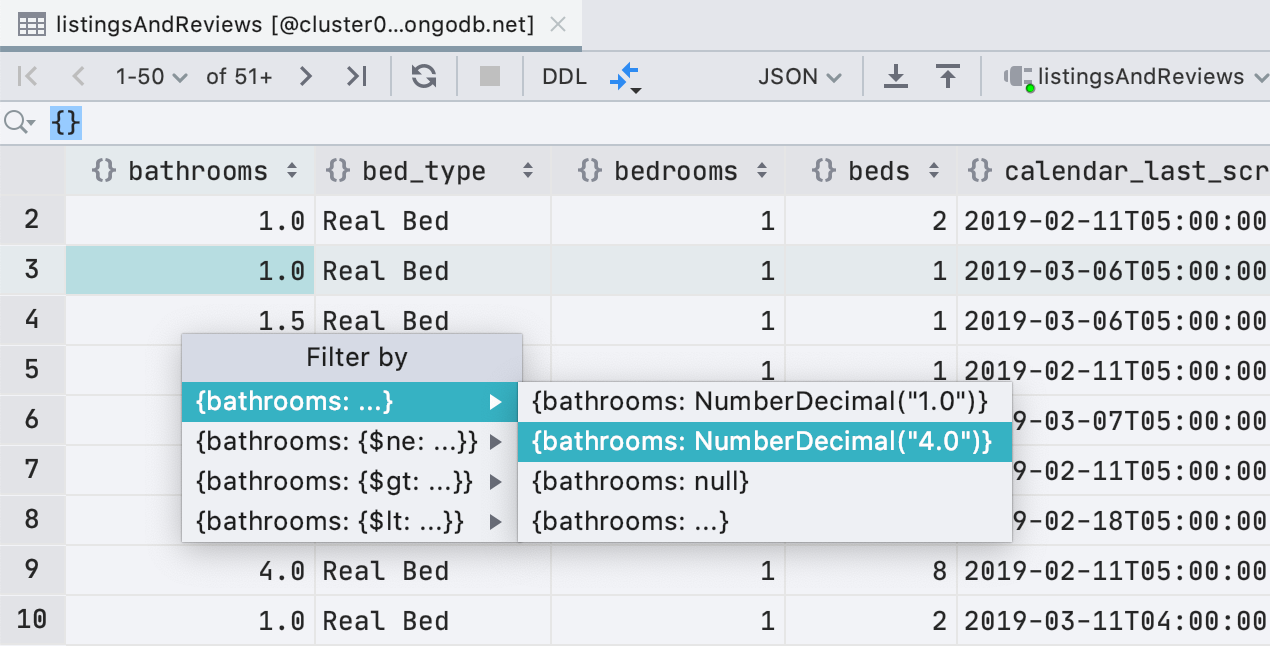
Еще мы добавили в условия фильтра регулярные выражения, чтобы вы не слишком скучали по
LIKE из фильтра в реляционных базах.

Редактор SQL
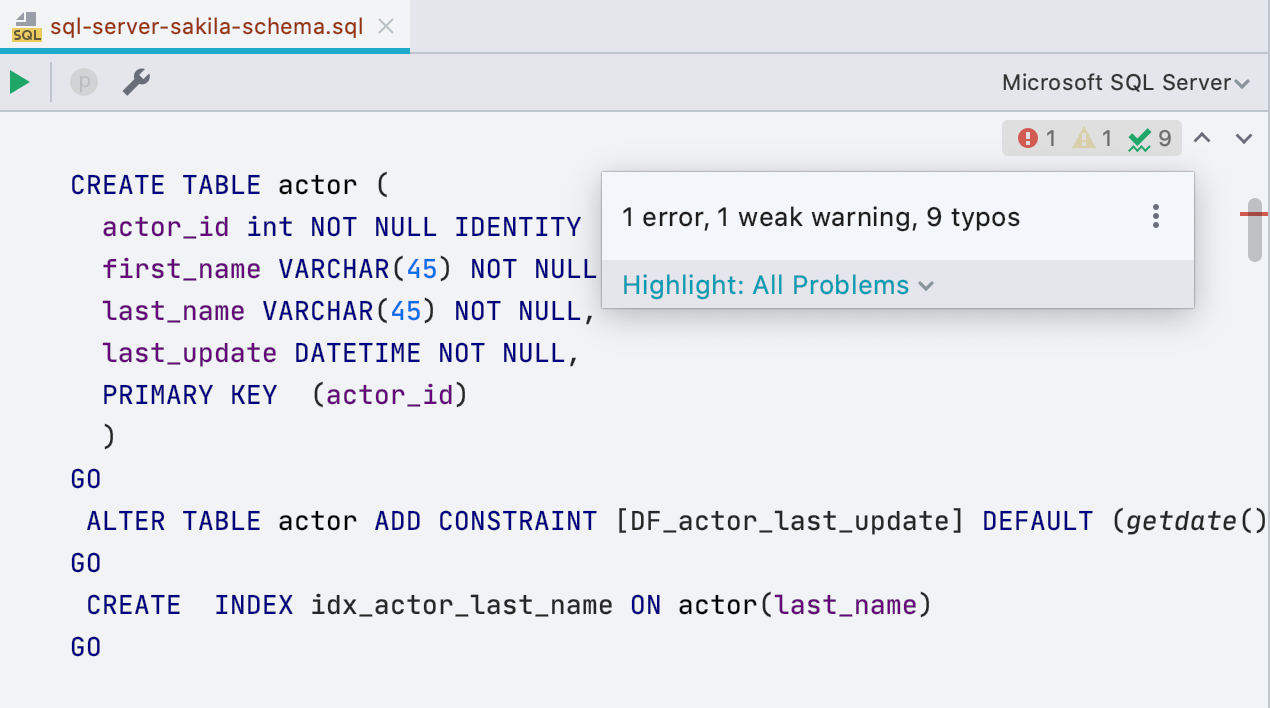
Новый виджет с инспекциями
Справа от редактора появилась маленькая панель — она расскажет, сколько в скрипте ошибок, а сколько мест вызывает подозрение. Оттуда можно навигироваться или выбирать — что подсвечивать, а что нет. Сочетание клавиш F2 всё еще работает для того же самого.
Предложение переименовать
Это появилось во многих наших IDE: если вы переименовали что-нибудь не при помощи встроенного рефакторинга, а поменяли имя в коде, вам предложат сделать рефакторинг и переименовать и все использования. Вот, например, как это работает с алиасами:
Автодополнение JOIN стало лучше
Раньше, чтобы мы предложили условие для JOIN полностью, нужно было набрать это ключевое слово. Теперь понимаем, что нужно, как только вы набрали
'J'.
Еще научились предлагать двойные условия, если так выставлены ключи таблиц.

Обновить информацию о базе
Если DataGrip ничего не знает об объектов из ваших запросов, то сообщит вам об этом. Иногда это происходит, если вы просто опечатались. Также бывает, что файл был ассоциирован не с тем источником данных. Еще одна причина такого события — объект уже появился, но DataGrip не получил информации о нем из базы. Для этого мы добавили возможность запустить обновление структуры базы из редактора, если объект неизвестен.

Выделить переменную
Этот рефакторинг раньше работал не для всех баз, теперь работает в SQL Server, Db2, Exasol, HSQL, Redshift и Sybase.
Подсветка Google BigQuery
В списке диалектов пополнение: Google BigQuery. Пока это не полноценная поддержка базы, а только правильная подсветка кода. Соответственно, для запуска запросов не надо выделять код, мы сами определим, что запустить.

Подсветка TextMate
Как и другие наши IDE, DataGrip теперь умеет подсвечивать код при помощи плагина TextMate. Может пригодиться, если у вас есть скрипты на Python, lua, javascript. Полный список языков есть в Settings/Preferences | Editor | TextMate bundles.

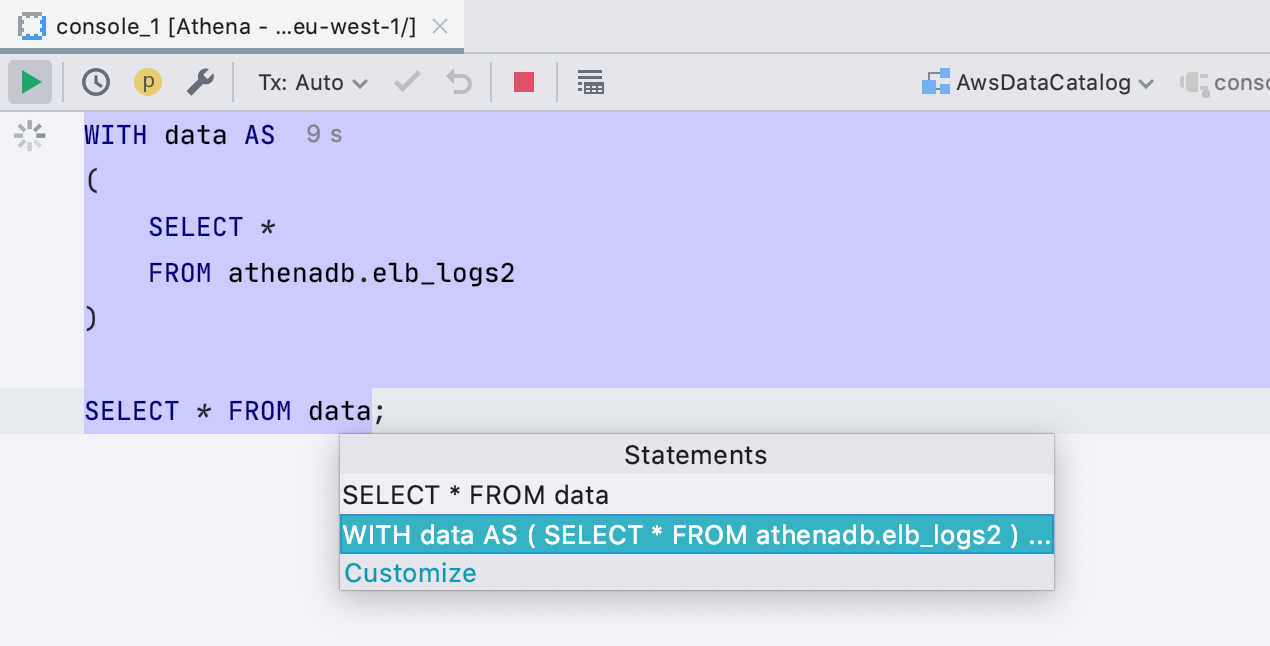
SQL 2016 в качестве диалекта <Generic>
Если работаете с базой, которую мы не поддерживаем, запросы парсятся и подсвечиваются диалектом <Generic>. Раньше это был SQL 92, теперь SQL 2016. Самое важное — теперь мы корректно обрабатываем запросы с блоком WITH, соответственно они не только правильно подсвечены, но и запускать их можно без выделения кода.
Регистр имён объектов в форматировании
В настройках форматирования были три настройки для имён объектов базы данных — прописными, строчными или не менять. Но оказалось, что есть и четвертый случай: пользователи хотят использовать тот регистр, который был использован при создании объекта в скрипте. Мы это поддержали.

В примере таблица Actor создана с первой заглавной, и в использовании мы привели имя таблицы к такому же регистру.
Мы ищем скрипты создания только внутри того же файла, где происходит форматирование. Если же хотите, чтобы форматтер нашёл объявление объекта в соседнем файле, создайте из своих файлов источник данных на основе DDL.
Несколько кареток в выделенном фрагменте
Теперь вы можете выделить фрагмент кода и поставить каретку в каждую его строчку. Используйте для этого действие Add Carets to Ends of Selected Lines или сочетание клавиш Shift+Alt+G
Проводник базы данных
Все базы и схемы в дереве
По умолчанию мы показываем в дереве только те базы и схемы, которые вы выбрали сами. Дерево не ленивое, а вся метаинформация об объектах используется для дальнейшей работы IDE. Поэтому мы загружаем только то, что нужно, чтоб случайно не повиснуть на гигантской базе.
Однако многие привыкли к инструментам, которые всегда показывают все объекты, и люди, которые не знакомы с нашей концепцией могут терять из виду базы и схемы. Поэтому мы сделали настройку Show All Namespaces, и когда она включена, в дереве будут показаны все базы и схемы, даже если информация об их объектах не загружена. Такие схемы и базы отмечены серым шрифтом.

Интерфейс для создания представлений
Мы обычно говорим, что функция генерации кода в редакторе (Alt+Ins или Cmd+N) покрывает многие потребности разработчика по созданию объектов, но иногда это всё же менее удобно. Поэтому мы начали добавлять интерфейсы для создания объектов: в новой версии можно создавать представления.

Файлы скриптов в панели Files
Если вы создали источник данных на основе DDL, эти файлы автоматически попадут в панель
Files. Так вам будет удобно их просматривать и редактировать.

Простая поддержка ссылок на базы данных в Oracle
Ссылки на базы данных теперь показываются в проводнике, а запросы, которые их используют, подсвечены правильно.
Общее
Больше никаких длинных имён вкладок
Вы часто жаловались, что вкладки неконтролируемо разрастаются.

Отныне:
- Настройка Database | General | Always show qualified names for database objects выключена по умолчанию, то есть имена объектов будут квалифицированы схемой, только если открыто два объекта с одним именем из разных схем.
- Если имя источника данных больше 20 символов, мы его подрежем.
- Если у вас только один источник данных, мы не будем его показывать во вкладках.
- Если имя объекта со всеми его классификаторами — более 36 символов, его мы тоже подрежем.
Поддержка MongoDB shell
Месяц назад мы обновили драйвер, который используем для подключения к MongoDB и он стал поддерживать MongoDB shell. Это означает, что заработали новые команды и методы, например help, db.getCollectionInfos(), db.getCollectionNames(), db.collection.remove() и другие. Подробная статья на английском о поддержке MongoDB shell здесь.
Нативные библиотеки в настройках драйвера
Теперь можно указать путь к нативной библиотеке, которая нужна драйверу. Вот несколько случаев, когда это может понадобится.

- В SQL Server вы можете указать путь к mssql-jdbc_auth-<version>-<arch>.dll для аутентификации по SSO, если вы настраиваете драйвер вручную. По умолчанию, аутентификация по SSO работает из коробки.
- В базе данных Oracle вы можете указать библиотеку ocijdbc, чтобы использовать OCI драйвер.
- В SQLite, можно указать расширения, загружаемые в
рантайме, чтобы потом было легко использовать их при написании запросов, не указывая каждый раз полный путь.
Конфигурации запуска для файлов *.js
Теперь конфигурации запуска работают и для скриптов базы MongoDB.
Интеграция с Git и Github работает из коробки
Наш опрос показал, что довольно много людей хранят скрипты в системах контроля версий, поэтому мы решили упаковывать два самых популярных плагина в этой области.

Спасибо за внимание! Напомним, что у нас есть свой канал в Телеграме, там можно задавать вопросы и делиться опытом. Но если нашли баг, лучше сразу пишите в трекер, чтобы он не потерялся. Ну и сюда, конечно, тоже комментарии пишите :)
На этом всё!
Команда DataGrip
