Comments 107

Прошу близко к сердцу не воспринимать )
Ну, боевой язык, всё правильно.
Сложно не принимать близко к сердцу текст, вставленный картинкой с нездоровым размером шрифта.
Сложно не принимать близко к сердцу текст, вставленный картинкой с нездоровым размером шрифта.
Кстати, в варианте этой картинки — совсем не отчетливое общение. После такого приказа не понятно куда, что, кого и т. д. (если это, конечно, заранее не оговорено). А на поле боя вряд ли есть время подумать что означает это слово, у которого миллион значений.
В том и фокус, что формальный язык приказа слишком длинный, так как не опирается на контекст. Солдат, получивший приказ, не должен думать — он должен сразу действовать. Но если в области видимости только две цели, а командир стоит за спиной у стрелка, значит приказ «ё*ни по левому» будет воспринят однозначно и формула типа «Произведите выстрел по цели 123» — избыточна.
Можно сказать «огонь по левому» :) Но в вашем примере приказ четкий. Проблема как раз в приказе «е*ни» без какого-либо указания цели. Какой смысл в офицере, если он не может свои мысли сформулировать четко и понятно? Если солдат видит один вражеский танк и он ведет огонь, ему понятно что с ним нужно сделать и без приказа (если перед этим не было приказа не вести огонь). Если танков 10, то офицеру виднее что приоритетней, и это не задача солдата выбирать цель, он будет атаковать на свое усмотрение, пока ему явно не скажут какой важнее и что с ним нужно сделать.
Я думаю, тут и детали звучат лаконичнее. «Е*ни по той желтой по*ни», а не «Огонь по дальнему танку Пантера Е-350». Я не знаю точно, но мне кажется классификация НАТО боевых единиц как раз и призвана сократить такой приказ. Но у нас часто в эпических ситуациях люди понимают друг друга с бесконечной точностью, используя только мат и междометия.
Просто этот комментарий показывает, насколько изменяется размер текста при записи его в виде картинки ;)
Помню, пару лет назад, я стал замечать в интернетах картинки, на которых изображен текст. Вот тогда я почувствовал себя старым пердуном: «В мое время — писали текстом, а не картинками...».
UFO just landed and posted this here
В наше время картинки делали из букв, ascii art

Самое забавное — что это действительно работает.
Если запостить, например, вконтакте картинку с текстом и добавить к ней просто текст, то пользователи в любом случае сначала прочитают текст на картинке, а уже потом — сопровождающий текст, вне зависимости от размера шрифта.
Если запостить, например, вконтакте картинку с текстом и добавить к ней просто текст, то пользователи в любом случае сначала прочитают текст на картинке, а уже потом — сопровождающий текст, вне зависимости от размера шрифта.
Текст на 176.25% короче оригинала — это вы хорошо померили.
Им Чуров помогал.
А что вызывает у вас сомнение в размере? Получается, что текст в 2.7625 раз короче, если я нигде не ошибаюсь.
Ну текст отрицательной длины, чему вы удивляетесь?
У, шаманы! Перевели английский на русский — вышло на 8,35% длиннее. Перевели обратно — получили на 8,35% короче? Нет, на 1,37% длиннее. Можно переводить туда-сюда и дойти до бесконечности.
Очевидно, сравнивали не слова, а тексты. А переведенный текст будет всегда длиннее оригинала.
Ну и так вот сравнивать фонетическое письмо с иероглифическим не очень корректно.
Очевидно, сравнивали не слова, а тексты. А переведенный текст будет всегда длиннее оригинала.
Ну и так вот сравнивать фонетическое письмо с иероглифическим не очень корректно.
С точки зрения языкознания — может и некорректно, а вот с точки зрения локализации — очень даже. Делаешь программу на английском с планируемым переводом на немецкий — сделай кнопки на 14.29% шире и т. д.
Тоже неверно. 1 дело передавать смысл большого текста, другое — заменить 1 устоявшееся выражение другим. Не «Увеличить размер данного приложения до размера экрана и убрать заголовки», а «Полный экран». Да и на 1 фразе погрешности куда выше и надо смотреть на конкретный пример, а не статистику. Толщину прозы уже оценить можно более достоверно.
Я и не говорю, что исследование идеально, вон ниже дельные замечания делают:
habrahabr.ru/company/alconost/blog/197146/#comment_6838562
Просто в данном контексте иероглифы и буквы — это всего лишь символы. И есть практическое применение такому исследованию. А его качество — это уже другой вопрос.
habrahabr.ru/company/alconost/blog/197146/#comment_6838562
Просто в данном контексте иероглифы и буквы — это всего лишь символы. И есть практическое применение такому исследованию. А его качество — это уже другой вопрос.
Не надо так делать, пожалуйста. Сделайте кнопки разиновыми. Всё что содержит текс должно тянуться. И будет хорошо. Ещё шрифты потому что разные. По символам некорректно считать.
Это само собой. Но примерные различия стоит учесть.
Рассмотрим крайний случай: я создал интерфейс на китайском, разместил 10 кнопок в ряд. Потом перевел на русский. И все кнопки, увеличив ширину начали либо занимать неприлично много места, либо разъехались по нескольким строчкам. На практике такое часто бывает, менее драматично, правда.
Я пытаюсь сказать что сами элементы должны быть резиновыми, но место, куда они будут тянуться, нужно предусмотреть заранее.
Рассмотрим крайний случай: я создал интерфейс на китайском, разместил 10 кнопок в ряд. Потом перевел на русский. И все кнопки, увеличив ширину начали либо занимать неприлично много места, либо разъехались по нескольким строчкам. На практике такое часто бывает, менее драматично, правда.
Я пытаюсь сказать что сами элементы должны быть резиновыми, но место, куда они будут тянуться, нужно предусмотреть заранее.
С кнопками как раз не работает, там длина изменяется в разы, всем Überspringen, поцоны!
> А переведенный текст будет всегда длиннее оригинала.
Не всегда. Переводить можно по разному. Можно дословно, а можно так, чтобы просто передать смысл фразы (причем в этом случае тоже куча ньюансов, если ЦА «в теме» контекста — то можно обойтись короткой фразой, а если нет — то получается длиннее).
Да и с дословным переводом тоже не все так просто. Во всех языках есть некие устойчивые обороты, аналогов которым может и не быть на другом языке, соотв. длина перевода тут увеличивается (либо уменьшается, зависит от направления перевода).
Не всегда. Переводить можно по разному. Можно дословно, а можно так, чтобы просто передать смысл фразы (причем в этом случае тоже куча ньюансов, если ЦА «в теме» контекста — то можно обойтись короткой фразой, а если нет — то получается длиннее).
Да и с дословным переводом тоже не все так просто. Во всех языках есть некие устойчивые обороты, аналогов которым может и не быть на другом языке, соотв. длина перевода тут увеличивается (либо уменьшается, зависит от направления перевода).
>переводить туда-сюда и дойти до бесконечности
Вспомнилась статья Переслегина, где затрагивалась тема многократного перевода:
В одном из таких экспериментов коротенькая фраза «С “пепси” к новой жизни!» обернулась следующим «жутким, додревним» заклинанием: «Шипучая вода поднимет ваших предков из их могил».
Вспомнилась статья Переслегина, где затрагивалась тема многократного перевода:
В одном из таких экспериментов коротенькая фраза «С “пепси” к новой жизни!» обернулась следующим «жутким, додревним» заклинанием: «Шипучая вода поднимет ваших предков из их могил».
UFO just landed and posted this here
Картинка не совсем корректна. Если перевести дословно с немецкого на русский слово «Kugelschreiber», то получится «шариковая ручка», что на один знак, считая пробел, длинее немецкого эквивалента. А «ручка», на самом деле, переводится как «Stift» и имеет, как и в русском варианте, 5 знаков.
Какое-то бессмысленное исследование
Позанудствую.
Если пишете длинное «Kugelschreiber», то по-русски полностью будет ещё длиннее: «шариковая ручка», а если используете короткое разговорное «ручка», то в немецком разговорное слово будет ещё короче: «Stift».
Постоянно натыкаюсь на перевод по словарю или гуглотранслэйтом в приложениях.
Позанудствовал.
Если пишете длинное «Kugelschreiber», то по-русски полностью будет ещё длиннее: «шариковая ручка», а если используете короткое разговорное «ручка», то в немецком разговорное слово будет ещё короче: «Stift».
Постоянно натыкаюсь на перевод по словарю или гуглотранслэйтом в приложениях.
Позанудствовал.
/занудство ON
Да, подмечено верно — еще просто schreiber.
У нас с офисе народ обычно так говорит именно про ручки.
Собственно Kugelschreiber заставило задуматься над профессионализмом переводчиков.
/занудство OFF
Да, подмечено верно — еще просто schreiber.
У нас с офисе народ обычно так говорит именно про ручки.
Собственно Kugelschreiber заставило задуматься над профессионализмом переводчиков.
/занудство OFF
Проверить уровень профессионализма переводчиков легко: напишите нам на nitro@alconost.com пару строк о себе, получите в ответ купон на пополнение счета и сделайте заказ на перевод на немецкий.
Нет уже, извините — с русскими я давно зарекся работать уже — после таких пользователи жаловались, что переводы были сделаны гуглом, хотя обещали переводы нативами.
Ну и еще пара стоп-факторов — с теми, кто продвигается спамом я не работаю принципиально и в название у вас созвучно «алгогольной» теме.
Плюс не вижу смысла менять проверенных партнеров, с которыми давно и успешно работаю — тем более делать проверку за собственные деньги.
Ну и еще пара стоп-факторов — с теми, кто продвигается спамом я не работаю принципиально и в название у вас созвучно «алгогольной» теме.
Плюс не вижу смысла менять проверенных партнеров, с которыми давно и успешно работаю — тем более делать проверку за собственные деньги.
В советских школах в конце восьмидесятых других ручек не было. И на уроках немецкого давали только один перевод — Kugelschreiber. Сразу же, прям в четвёртом классе. Kugelschreiber, Bleistift und die sowietische Regierung. Очень удобные для четвероклассника слова :-)
Среднее значение, конечно, хорошо, но мало. Надо еще и дисперсию посчитать.
А то увеличите на 14% поля, а в результате половина текста поместится, а половина не поместится. А надо, чтобы всё поместилось с вероятностью 99.9%.
Может тогда и вылезут те 30%, рекомендованные гайдлайнами. У нас, кстати, тоже резерв 30% от английской версии.
А то увеличите на 14% поля, а в результате половина текста поместится, а половина не поместится. А надо, чтобы всё поместилось с вероятностью 99.9%.
Может тогда и вылезут те 30%, рекомендованные гайдлайнами. У нас, кстати, тоже резерв 30% от английской версии.
UFO just landed and posted this here
А ещё короче — кириллический английский, лайк зыс ван) Не очень в тему, но всегда удивляло, как в английском (и других европейских языках) могла укорениться такая чудовищная письменность. Настолько дурацкая, что даже пришлось придумать ещё одну, чтобы понять, как же всё-таки это произнести.
UFO just landed and posted this here
Про польский ничего не знаю, а про немецкий с испанским вы, должно быть, шутите. На вскидку:
Немецкий:
И т.д. и т.п.
Испанский:
Немецкий:
Sch = «Ш»
Tsch = «Ч»
S = или «С» или «З»
H = в начале слова «Х», в середине слова беззвучен, если не предварён «C».
И т.д. и т.п.
Испанский:
J = «Х»
H = не читается никогда.
B / V = «Б» или «В», в зависимости от контекста
Две идущие подряд «C» = внезапно, читаются как «КС»
G = вообще «Г», но перед гласными «E», «I» — «Х»
GUE, GUI = «U» не читается. Но если надо, то меняем «U» на "Ü" и читаем "Ü" как «У»
Например во французском этот изъян тоже явно присутствует, про другие сказали выше.
Насколько я слышал, тут дело не только в том, как слова читались сотни лет назад, а еще и в том, что писцам платили за длину текста. Вот и возникал соблазн добавить букв, чтобы было подлиннее. Хотя, может, и выдумка:)
Ну не знаю… У нас при локализации китайский был единственным из использовавшихся языков, на котором практически не приходилось править размеры контролов (а когда приходилось, то в большей части случаев в сторону уменьшения). Вообще, для меня был приятный язык — и с точки зрения лаконичности, и с точки зрения ускорителей — на иероглифы их не повесишь, так что просто использовались английские.
А самым неприятным был итальянский, наверное — он и длинный, и букв в нем мало, так что часто возникали проблемы.
А самым неприятным был итальянский, наверное — он и длинный, и букв в нем мало, так что часто возникали проблемы.
UFO just landed and posted this here
Кстати, об акселераторах. Я их среди языков с нефонетическим письмом видел только рядом с японским. Например, Skype.
Японский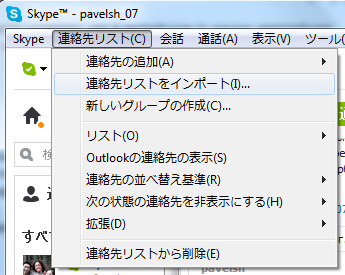

Китайский упрощенный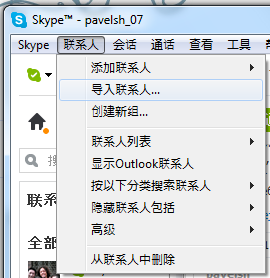

UFO just landed and posted this here
Именно так, иероглифы печатают более крупным шрифтом; кроме того, иероглиф вписывается в квадрат, поэтому текст выглядит словно набран моноширинным шрифтом.
Ну, печатать интерфейс мы не печатали, конечно. А так размеры были одинаковые для всех языков. Корейцы и китайцы не жаловались вроде. Возможно, изначальный размер был для европейских избыточным, кстати.
В интерфейсах подавляющее большинство пунктов меню состоят из одного существительного (файл, правка, настройки) или одного глагола (вырезать, удалить, сохранить) или простых словосочетаний, например, глагол + пара дополнений (показать историю, добавить в закладки). Так что усреднять литературные тексты как раз не надо было, просто сравнение средней длины существительного из словаря подошло бы лучше.
Английский Китайский (Упрощенный) -61.97%
Английский Китайский (Традиционный) -63.80%
А можно узнать, как это так получилось? Кол-во знаков должно было остаться одинаковым для обоих вариантов.
Английский Китайский (Традиционный) -63.80%
А можно узнать, как это так получилось? Кол-во знаков должно было остаться одинаковым для обоих вариантов.
Все просто. Если сравнивать по знакоместам — то получается совсем круто. Большинство китайских слов — двухсложные. Если у нас в оригинале было 2 слова каждое из 6-7 букв, то на выходе — 4-5 знакомест.
Например: Connect — 链接.
Например: Connect — 链接.
Я в курсе про словарный состав китайского языка:) Вопрос был в том, как у них получился разный процент у китайского традиционного и китайского упрощённого. Кол-во «знакомест» там одинаково. Одинаково. Различается только написание иероглифов. И, кстати, даже не всех.
Вы еще скажите, что любой мало-мальский грамотный локализатор знает, что даже для упрощенного китайского — средняя ширина символа далеко не равна латинице/кириллице.
Даже в приведенных примерах — чётко видно, что один символ на китайском минимум полтора символа других алфавитов.
Даже в приведенных примерах — чётко видно, что один символ на китайском минимум полтора символа других алфавитов.
Ещё раз повторюсь — где здесь звучал вопрос о соотношении «любой вариант китайского — какой-либо не_китайский язык»? Меня удивила разница в процентах между традиционным и упрощённым написанием. Т.к. при одинаковых переводах её быть не должно. Но ниже на мой вопрос уже ответили — habrahabr.ru/company/alconost/blog/197146/#comment_6839676 :)
Возможно, дело в том, что на Тайване используют другие слова для передачи тех же технических терминов. В некоторых компьютерных книжках (типа, Освой Ворд за неделю) встречаются таблички, где сравнивается терминология материковой и тайваньской версий.
Читайте внимательнее условия эксперимента. Брались 1000 переводов для каждой пары языков, а не 1000 текстов переводилось на все языки.
Почему английский язык обозначен флагом Либерии? У них государственный язык конечно английский, но все же… :)

По моему опыту — самая жесть — это новогреческий
пароль
пароль
Тайский еще интереснее
А на финский не пробовали переводить? Язык тоже богатый длиннющими словами.
Словом Kugelschreiber вот уже много много лет пользуется лишь «стремительно стремящийся к нулю» процент немцев.
ГДРовцы сокращали его до Kuli (сравните с Горби и Трабби), а в ФРГ как говорили Stift (штифт), так и сейчас говорят.
ГДРовцы сокращали его до Kuli (сравните с Горби и Трабби), а в ФРГ как говорили Stift (штифт), так и сейчас говорят.
Главное не длина языка, а умение им владеть.
Английский -> Русский: +9.11%
Русский -> Английский +1.39%
Как так? Почему во втором варианте, тогда не минус?:) Видимо я чего-то не понимаю. Просто думал что если в одну сторону перевод увеличивается, то в другую должен уменьшаться.
Русский -> Английский +1.39%
Как так? Почему во втором варианте, тогда не минус?:) Видимо я чего-то не понимаю. Просто думал что если в одну сторону перевод увеличивается, то в другую должен уменьшаться.
Sign up to leave a comment.
Померяемся языками, чей длиннее?