Comments 37
Про морских львов — это уже не джедай, это хокку получается.
Хороший обзор, спасибо, отправил Марине инвайт, чтобы продолжение она смогла написать уже из своей учётной записи.
Что касается применения ТМ-инструментов, здесь необходимо сделать оговорку, чтобы такие программы не будут творить чудеса, если исходный контент не будет оптимизирован и последователен. Нередко внедрение ТМ-инструмента на стороне разработчика сопряжено с болезненным процессом изменения всего подхода к созданию контента, тренингом разработчиков, контент-менеджеров и технических писателей.
Если брать игры, то вот противоречивый пример из практики:
При переходе на новый уровень пользователю отображается текст поздравления и перечисления необходимых ачивок для перехода на следующий уровень:
Поздравляем! Вы перешли на уровень 1. Для перехода на следующий уровень получите А.
Молодец! Теперь вы на уровне 2. Чтобы перейти на следующий уровень, получите Б.
Ура! Вы достигли уровня 3. Для того, чтобы перейти на следующий уровень, получите В.
В memoQ эти тексты не будут считаться повторами, хотя смысл тот же. Если бы такие фразы были бы, например, в многостраничной документации к API, мы могли бы их оптимизировать следующим образом:
Поздравляем! Вы достигли уровня %n! Для перехода на следующий уровень получите %s.
Мы бы сэкономили время и деньги на локализации в каждом языке, но потеряли бы живость игровых текстов, сделали бы их более формальными.
Но в целом, конечно, без подобных систем эффективная локализация вообще немыслима. Лично я из всех подобных решений считаю memoQ наиболее эффективным и гибким, у нас в компании она тоже основной рабочий инструмент локализации.
Что касается применения ТМ-инструментов, здесь необходимо сделать оговорку, чтобы такие программы не будут творить чудеса, если исходный контент не будет оптимизирован и последователен. Нередко внедрение ТМ-инструмента на стороне разработчика сопряжено с болезненным процессом изменения всего подхода к созданию контента, тренингом разработчиков, контент-менеджеров и технических писателей.
Если брать игры, то вот противоречивый пример из практики:
При переходе на новый уровень пользователю отображается текст поздравления и перечисления необходимых ачивок для перехода на следующий уровень:
Поздравляем! Вы перешли на уровень 1. Для перехода на следующий уровень получите А.
Молодец! Теперь вы на уровне 2. Чтобы перейти на следующий уровень, получите Б.
Ура! Вы достигли уровня 3. Для того, чтобы перейти на следующий уровень, получите В.
В memoQ эти тексты не будут считаться повторами, хотя смысл тот же. Если бы такие фразы были бы, например, в многостраничной документации к API, мы могли бы их оптимизировать следующим образом:
Поздравляем! Вы достигли уровня %n! Для перехода на следующий уровень получите %s.
Мы бы сэкономили время и деньги на локализации в каждом языке, но потеряли бы живость игровых текстов, сделали бы их более формальными.
Но в целом, конечно, без подобных систем эффективная локализация вообще немыслима. Лично я из всех подобных решений считаю memoQ наиболее эффективным и гибким, у нас в компании она тоже основной рабочий инструмент локализации.
*что такие программы не будут творить чудеса. (не успел отредактировать)
Если говорить о приведенном вами примере, то на практике в игровых текстах очень часто встречаются стандартизированные фразы с переменными, даже в подобных случаях. Это уж как сами разработчики решат. Ну а что касается прогнозируемых затрат на локализацию, то тут все сопоставимо (и пропорционально затратам времени на исходный текст) – больше потратили времени, больше текста написали – значит и переводить его дольше придется. Ну, то есть все очевидно – как можно считать фразы/предложения повторными, если на языке оригинала сочинить 20 разных предложений с одинаковым смыслом не так уж и просто зачастую, что уж тогда о переводе говорить (тем более качественном).
Я бы с удовольствием почитал статью по этой теме но ориентированную как советы разработчикам. Например как организовывать все что нужно будет потом переводить. Плюс интересно почитать про использование MemoQ для своих проектов. т.е. когда в комманде 3-5 человек.
Я думаю, что мы можем попробовать собрать лучший опыт наших клиентов (если они, конечно, разрешат) и представить в виде советов. Для разработчиков и всех интересующихся есть прекрасная книга Game Localization Handbook. В ней довольно очевидные вещи, но она, тем не менее, невероятно полезна для получения полного представления о процессе.
Огромное спасибо за инвайт!
Это абсолютно верно, текст должен быть оптимизирован. Но, признаться, мы довольно редко сталкиваемся с тем, что описано в примере. Гораздо чаще разработчики прекрасно понимают, что текст должен быть единообразен, а вот избыточным введением переменных грешат. А переменные нельзя вводить без учета особенностей языков, на которые будет в последствии переведена игра. Возникают ситуации, когда при подстановке значения переменной предложение получается абсолютно несогласованным. За примером ходить далеко не нужно:
Get {X} [cash] for {Y} [feez]?
Получить 100 монета за 10 алмазы?
Здесь как ни перестраивай фразу, все равно плохо. Разработчики сказали, что помочь ничем не могут. Поэтому feez оставили как алм., а с остальным даже не помню, что сделали. На этапе локализационного тестирования должны были подобрать какой-то вариант, вписывающийся в контекст.
Это нескончаемая боль. Только единицы стараются решить эту проблему на этапе разработки.
Это абсолютно верно, текст должен быть оптимизирован. Но, признаться, мы довольно редко сталкиваемся с тем, что описано в примере. Гораздо чаще разработчики прекрасно понимают, что текст должен быть единообразен, а вот избыточным введением переменных грешат. А переменные нельзя вводить без учета особенностей языков, на которые будет в последствии переведена игра. Возникают ситуации, когда при подстановке значения переменной предложение получается абсолютно несогласованным. За примером ходить далеко не нужно:
Get {X} [cash] for {Y} [feez]?
Получить 100 монета за 10 алмазы?
Здесь как ни перестраивай фразу, все равно плохо. Разработчики сказали, что помочь ничем не могут. Поэтому feez оставили как алм., а с остальным даже не помню, что сделали. На этапе локализационного тестирования должны были подобрать какой-то вариант, вписывающийся в контекст.
Это нескончаемая боль. Только единицы стараются решить эту проблему на этапе разработки.
Обычно проблемы плюрализации в принципе не решаемы со стороны разработчика на уровне текста (если конечно в штате нет программистов-полиглотов, знающих все языки локализации и избегающих подобных моментов).
Один из хороших выходов (для указанного вами варианта) составление списков (по заданым правилам + словарь исключений или вручную) для форм слова в единственном и множественных числах для каждого языка. Как-то так:
Конечно тут есть минусы: разработчики должны думать о i18n до того, как выпустят продукт. Как следствие, эти строки нужно обрабатывать основной программой после перевода, т.е. всевозможнные хаки вроде выдирания ресурсов из бинарника или внедрения в память тут, скорее всего, не сработают.
Кроме того, если команда разработчиков рассматривает перевод на другие языки как стадию «после всей остальной работы» то у нее могут быть неприятные сюрпризы, к примеру, когда красивое слово «apple» в основном меню шириной в 120 пикселей превращается в «Unternehmenssteuerfortentwicklungsgesetz».
Расскажите, как решают это проблему ваши заказчики?
Один из хороших выходов (для указанного вами варианта) составление списков (по заданым правилам + словарь исключений или вручную) для форм слова в единственном и множественных числах для каждого языка. Как-то так:
Get {X}[EN, apple, apples, apples]
Получить {X}[RU, яблоко, яблока, яблок]
Конечно тут есть минусы: разработчики должны думать о i18n до того, как выпустят продукт. Как следствие, эти строки нужно обрабатывать основной программой после перевода, т.е. всевозможнные хаки вроде выдирания ресурсов из бинарника или внедрения в память тут, скорее всего, не сработают.
Кроме того, если команда разработчиков рассматривает перевод на другие языки как стадию «после всей остальной работы» то у нее могут быть неприятные сюрпризы, к примеру, когда красивое слово «apple» в основном меню шириной в 120 пикселей превращается в «Unternehmenssteuerfortentwicklungsgesetz».
Только единицы стараются решить эту проблему на этапе разработки.
Расскажите, как решают это проблему ваши заказчики?
Расскажите, как решают это проблему ваши заказчики?
А вот как вы про яблоки описали, так обычно и решают. Кто-то в полной мере для всех переменных, кто-то только для комбинации «число + переменная». Это снимает огромное количество проблем.
разработчики должны думать о i18n до того, как выпустят продукт.
Да!
Кстати, например, для веба ребята из Mozilla выпустили фреймфорк l20n, который как раз облегчает работу в подобных случаях. Я бы очень хотел его испытать на каком-нибудь проекте, пока возможность не подвернулась.
В ОС Android грамотно разобрались с такого типа переменными:
По ссылке можно найти подробную информацию об этом.
Plurals
<?xml version="1.0" encoding="utf-8"?>
<resources>
<plurals name="numberOfSongsAvailable">
<item quantity="one">Znaleziono jedną piosenkę.</item>
<item quantity="few">Znaleziono %d piosenki.</item>
<item quantity="other">Znaleziono %d piosenek.</item>
</plurals>
</resources>По ссылке можно найти подробную информацию об этом.
Кстати мне кажется, что если сделать похожую систему, но с полным прописыванием условий
Например так:
Получиться отличная платформа для локализации!
Например так:
Скрытый текст
<entry name="numberOfAppler">
<sub rule="n&100==11">$(n%100; concat=auto) Одиннадцать яблоко</sub>
<sub rule="n%10==1">$(n%10; concat=auto) Одно яблоко</sub>
.....
<sub rule="">$n яблок</sub>
</entry>
Получиться отличная платформа для локализации!
СЗОТ
Вспомнился старый проект Русефекация от ag.ru russo.ag.ru/
Иногда переводы пиратов были в разы лучше, чем лицензии.
Вспомнился старый проект Русефекация от ag.ru russo.ag.ru/
Иногда переводы пиратов были в разы лучше, чем лицензии.
Я до определенного возраста официальных локализаций в глаза не видела:) И были очень талантливые команды. Но, к сожалению, пиратские переводы, даже самые хорошие, грешат отсебятиной. И это видно, когда начинаешь сравнивать исходный вариант с переводом. В общем-то, professionals vs. fans — это нескончаемая тема для обсуждения.
Поразительно! У меня знакомый пытался открыть с другом компанию, которая бы занималась локализацией. Но говорит, что найти клиентов, которым нужен перевод ПО с английского на русский крайне сложно. Если не ошибаюсь, за месяц поисков они нашли двух программистов и одну компанию. Со всех суммарно заработали около 100$ и решили, что надо закрываться. Мол сложно найти клиентов и сложно им объяснить, что это им нужно, а не просто от балды доп.язык.
Мы сами дискредитируем российский рынок, поощряя пиратство и неофициальные локализации. Поэтому многие сомневаются, что русская локализация окупится. Нам иногда очень подолгу приходится убеждать заказчиков, что для того или иного продукта будет неплохо добавить также русский язык. И в основном на русский мы переводим free-to-play проекты. Поэтому меня нисколько не удивляет та история, которую вы рассказали.
А почему free-to-play? С ними какие-то другие особенности?
Простите, тогда немного не пойму, раз вы говорите о тех же сложностях. А что же тогда пользуется популярностью, скажем так?
Простите, тогда немного не пойму, раз вы говорите о тех же сложностях. А что же тогда пользуется популярностью, скажем так?
Не уверена, что я поняла вопрос. Во free-to-play проще денег с пользователей накачать, только и всего:) А если мы говорим об игре или программе на ПК за фиксированную стоимость, то я уверена, что очень большое количество пользователей в первую очередь будет искать ее на торрент-трекере. Поэтому разработчики и не спешат раскошеливаться на официальную русскую локализацию. А крупные клиенты уже давно все распределены между вендорами. Я не обладаю какой-то точной статистикой, но в моем окружении 90% людей крутят пальцем у виска, узнав, что у меня на всех ПК дома лицензионный Windows и Ofiice стоят. Я даже иногда вру, что скачала, конечно же, чтобы не объяснять в тысячный раз мое мнение на этот счет.
Аа… Всё. Про free-to-play понял. Я кстати сам не любитель не лицензионных вещей.
Если вас не затруднит, скажите пожалуйста, а какая услуга в российских компаниях, занимающихся локалицией тогда пользуется популярностью? То есть условно-говоря, Запад боится, что мы тут все пользуемся пиратским софтом, а потому вряд ли им есть интерес делать локализацию. Но тогда что они заказывают? Или тут обратная ситуация, когда наши компании делают локализацию наших же проектов на другие языки?
Если вас не затруднит, скажите пожалуйста, а какая услуга в российских компаниях, занимающихся локалицией тогда пользуется популярностью? То есть условно-говоря, Запад боится, что мы тут все пользуемся пиратским софтом, а потому вряд ли им есть интерес делать локализацию. Но тогда что они заказывают? Или тут обратная ситуация, когда наши компании делают локализацию наших же проектов на другие языки?
Спасибо за статью, полагал, что переводится всё чуть ли не в блокноте.
Подготовленное к локализации iOS-приложений имеет несколько файлов Localizable.strings (для каждого языка) условно такого содержания:
В используемой вами TM-программе MemoQ я не увидел, чтобы выводились какие-либо комментарии к переводимым строкам. Возникает вопрос: насколько вообще актуально писать развернутые комментарии? Если ли в этом смысл или при переводи их всё-равно никто читать не будет?
P.S. Насколько я понимаю, если необходим перевод на несколько десятков языков, то сначала всё переводится на английский, а потом уже с английского осуществляется перевод на суахили и клингонский. Как в этом случае передать специфику выражений, сохранить общую стилистику текста?
Подготовленное к локализации iOS-приложений имеет несколько файлов Localizable.strings (для каждого языка) условно такого содержания:
/* Надпись на кнопке алерта, при нажатии на которую осуществляется открытие определенного URL-а в Safari */
"openUrlButtonTitle" = "Перейти на сайт";
/* Надпись на кнопке алерта, при нажатии на которую происходит отмена перехода на сайт */
"alertCancelButtonTitle" = "Отмена";В используемой вами TM-программе MemoQ я не увидел, чтобы выводились какие-либо комментарии к переводимым строкам. Возникает вопрос: насколько вообще актуально писать развернутые комментарии? Если ли в этом смысл или при переводи их всё-равно никто читать не будет?
P.S. Насколько я понимаю, если необходим перевод на несколько десятков языков, то сначала всё переводится на английский, а потом уже с английского осуществляется перевод на суахили и клингонский. Как в этом случае передать специфику выражений, сохранить общую стилистику текста?
Единственный способ подгрузки, который сразу пришел в голову (прошу прощения, скриншот мелковат):
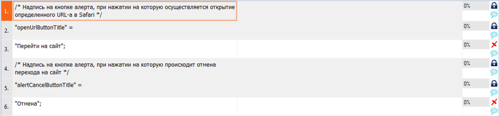
То есть комментарий подгружается полностью, сегментация по знаку равно, а все, что переводчику трогать не надо, мы блокируем. После этого переводчику объясняем, как в проекте выглядят комментарии. Но тут сразу есть куча недостатков: много ручной работы, комментарии не в поле комментарии, поэтому переводчик может запутаться. Хотя это лучше, чем полное отсутствие комментариев.
Сами комментарии очень полезны, но, на мой взгляд, их ценность возросла бы, если бы они были написаны на английском. При этом английский может быть сколько угодно не идеальный, главное, чтобы можно было уловить смысл.
С посткриптумом вы угадали. Наша компания переводит на все остальные языки именно с английского. Это объясняется тем, что очень сложно найти достаточное количество переводчиков, которые бы отлично понимали русский исходник. Такие команды можно набрать для языков FIGS, но у нас просто нет такой потребности, потому что заказчики либо пишут сами на английском, либо в любом случае переводят на английский. Носителей японского или китайского с отличным знанием русского очень мало. А уж когда приходится переводить на малайский или тагалог, то тут вообще можно даже не пытаться искать.
Заказчики очень часто задают вопрос по поводу того, не потеряется ли смысл исходного текста, какие-то нюансы при таком способе перевода. Как показывает наш опыт, при качественном переводе с русского на английский какие-либо потери сводятся к минимуму. Но английский нужно проверять очень тщательно, так как любая ошибка перейдет во все остальные локализации. Это не наш уникальный опыт. Все крупные издатели используют в качестве исходного текста английский, даже если игра была изначально на польском, французском или любом другом языке.

То есть комментарий подгружается полностью, сегментация по знаку равно, а все, что переводчику трогать не надо, мы блокируем. После этого переводчику объясняем, как в проекте выглядят комментарии. Но тут сразу есть куча недостатков: много ручной работы, комментарии не в поле комментарии, поэтому переводчик может запутаться. Хотя это лучше, чем полное отсутствие комментариев.
Сами комментарии очень полезны, но, на мой взгляд, их ценность возросла бы, если бы они были написаны на английском. При этом английский может быть сколько угодно не идеальный, главное, чтобы можно было уловить смысл.
С посткриптумом вы угадали. Наша компания переводит на все остальные языки именно с английского. Это объясняется тем, что очень сложно найти достаточное количество переводчиков, которые бы отлично понимали русский исходник. Такие команды можно набрать для языков FIGS, но у нас просто нет такой потребности, потому что заказчики либо пишут сами на английском, либо в любом случае переводят на английский. Носителей японского или китайского с отличным знанием русского очень мало. А уж когда приходится переводить на малайский или тагалог, то тут вообще можно даже не пытаться искать.
Заказчики очень часто задают вопрос по поводу того, не потеряется ли смысл исходного текста, какие-то нюансы при таком способе перевода. Как показывает наш опыт, при качественном переводе с русского на английский какие-либо потери сводятся к минимуму. Но английский нужно проверять очень тщательно, так как любая ошибка перейдет во все остальные локализации. Это не наш уникальный опыт. Все крупные издатели используют в качестве исходного текста английский, даже если игра была изначально на польском, французском или любом другом языке.
Есть способ поизящнее

Убрать лишнее с помощью регулярных выражений: переводчику доступен для редактирования только текст, но остальную разметку он видит.

Убрать лишнее с помощью регулярных выражений: переводчику доступен для редактирования только текст, но остальную разметку он видит.
Да, это гораздо изящнее. А что это за фильтр?
Это встроенный RegEx text filter, я набросал в нём условия для импортируемого текста: до полезного текста пробел, знак равенства, пробел, кавычка; после импортируемого текста — кавычка.
Вообще, это самая потрясная фича в memoQ, можно работать с абсолютно любой разметкой: если разработчик приходит с YAML, JSON, lua или вообще каким-то самописным форматом текстовых ресурсов, то это не становится проблемой — любой текст можно выдернуть, не трогая разметку.
Вообще, это самая потрясная фича в memoQ, можно работать с абсолютно любой разметкой: если разработчик приходит с YAML, JSON, lua или вообще каким-то самописным форматом текстовых ресурсов, то это не становится проблемой — любой текст можно выдернуть, не трогая разметку.
О, я поняла. Спасибо! Я его редко использую, потому как работаю сейчас в основном с одним клиентом, а у него все в xls. Но раз этот фильтр такой потрясающий, то буду чаще к нему обращаться в случае необходимости!
В SDL Trados Studio тоже можно вроде бы регулярными выражениями поделить контент на переводимый и не.
А можно напичкать любой [текстовый] файл тегами, превратив в XML, или написать конвертер для вытягивания строк в XML и последующей обратной вставки переводов.
А можно напичкать любой [текстовый] файл тегами, превратив в XML, или написать конвертер для вытягивания строк в XML и последующей обратной вставки переводов.
Sign up to leave a comment.
«Нетворческая» сторона локализации игр. Как мы делаем это