
Для поисковых систем важнейшим был всегда вопрос приоритезации сайтов в выдаче. Данный вопрос поднимает две проблемы:
1. Как определить сайт, отвечающий запросу наиболее точно (релевантность).
2. Если пользователи не найдут искомого через поисковик, пользователи предпочтут пользоваться другим поисковиком.
Алгоритм ранжирования также имеет большое значение для правильной оценки онлайн-активов, отсутствие которой в своё время было в числе факторов, породивших образование доткомовского пузыря, в то время как на деле интернет-ресурсы действительно могут являться заурядным ресурсом, подлежащим купле и продаже. Наконец, без понимания «веса сайта» не смогла бы развиваться отрасль онлайновой рекламы. В этих случаях оказывается задействован механизм оценки и мы сталкиваемся с потребностью определить достоверные критерии подобной оценки параметров успешности, релевантности и качества сайта в сравнении с другими ресурсами.
Таким образом, вопрос о присвоении сайту тех или иных параметров на основе собранных данных — первостепенная задача как для поисковиков, так и для работников цифровой индустрии.
Существующие способы учета
Задача ранжирования и оценки интернет-ресурсов может решаться и решается математически и относится к области собора и обработки крупных объёмов статистических данных. Это могут быть:
- PR (Stanford University и Google)
- Browserank (Microsoft)
- DA (Moz)
- TrustRank (Stanford University и Yahoo!)
- ТиЦ (Яндекс)
- DwellRank (Blippex)
Ранжирование по ссылочной массе
Алгоритм ранжирования Google названный в честь Ларри Пейджа, одного из основателей компании — один из первых и, по сути, приведший к созданию гигантской компании в силу своей исчерпывающей актуальности на момент создания в 1996 году.
Этот механизм, равно как и похожие на него, будет оперировать такими понятиями как «ссылочная масса» или «ссылочный граф». В максимально упрощённом виде это будет звучать так: чем больше других ресурсов ссылается на ресурс, тем более значим этот ресурс. Соответственно, он и ранжируется выше. Дальнейшее усложнение алгоритма, нацеленное на более тонкую его настройку, призвано отсеять ссылки со спам-ресурсов путём присвоения того или иного веса ресурсу и соответственно «цены», как в прямом, так и в переносном смысле, тем ссылкам, которые будут на нём располагаться.
Ранжирование по пользовательскому поведению
Поисковики совершенно очевидно не откажутся от ранжирования по ссылочной массе, несмотря на все заверения, однако алгоритмы ранжирования постепенно усложняются и вот уже факторы, основанные на количестве и «цене» ссылок используются для ранжирования наряду с примерно двумя стами других, в которых в особую группу выделяются факторы, основанные на данных о пользовательском поведении по отношению к сайтам и находящимся между ними ссылкам.
Источники данных
Данные собираются через:
1. Надстройки для браузеров (Alexa)
2. Метрику (Яндекс.Метрика, Google Analytics)
3. Специализированные браузеры (Chrome, Яндекс.Браузер)
Эти данные используются при ранжировании, формировании цены на сайт, на размещаемые на нём рекламные материалы и на соответствующие публикации.
Желание каждой поисковой системы создать свой собственный браузер и подать его как более быстрый, удобный, содержащий в себе множество дополнительных плюшек — это лишь попытка привлечь пользователей на свою сторону с целью сбора данных. Именно поэтому многие пользователи переходят на альтернативные поисковики: как например ничего не собирающий о пользователе — если верить создателям — DuckDuckGo и другие.
Одной из первых попыток создать алгоритм ранжирования, основанный на данных о поведении пользователей, а конкретно — переходам по ссылкам, был BrowseRank, обнародованный в 2008 году на SIGIR, о котором мы уже подробно рассказывали в нашем блоге.
Различия в ранжировании по тем или иным алгоритмам очевидны:
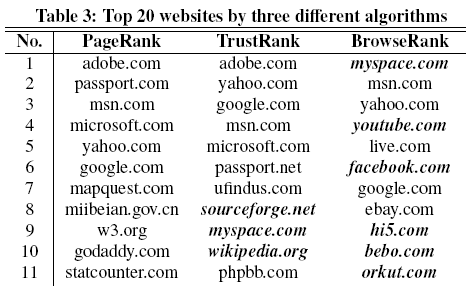
Источник
Выводы
Когда речь заходит о поисковых алгоритмах, мы сталкиваемся с такой проблемой, как неразглашение: как это работает достоверно никто не знает, кроме сотрудников поисковых систем. Таким образом учли «опыт сын ошибок трудных», когда каждый новый удачный и полезный метод ранжирования оказался очень быстро заспамленным методами так называемого «черного» продвижения. Теперь свой алгоритм стараются сделать непрозрачным для SEO специалистов, чтобы на него нельзя было повлиять «взломом», «накрутками» и любым другим путём иначе как через «белые факторы», такие как создание правильной инфраструктуры сайта, разумного контента и удовлетворения нужд потребителя. Несколько «просевший» фактор ранжирования по наличию ссылок дополняется факторами, основанными на поведении пользователей и переходах по ссылкам, как гораздо менее подверженные влиянию извне и, как следствие, предположительно более достоверные.
Больше по теме:
Анализ поведения пользователей и персонализация поисковой выдачи. Исследование Яндекс.
BrowseRank — Обзор.
История появления BrowseRank
Презентация BrowseRank (оригинальный текст на английском)
