Эта история началась с того, что к нам (в компанию Amvera) пришел клиент, которому нужна была система распознавания речи. Да не простая, а качественно распознающая разговоры с микрофонов на АЗС, то есть речь в сильных шумах. Цель заказчика простая – контролировать, упоминают ли кассиры акции, предлагают ли установить мобильное приложение и выпить кофе. Вы наверняка все это сами слышали на заправках.
Но есть проблема. Хорошо распознать простую чистую речь могут почти все известные решения. Но речь, где на фоне играет радио, слышны звуки с других касс, громкость речи говорящих разная и присутствует много отраслевой лексики (бренды сигарет, марки топлива), качественно распознать не смогло ни одно «коробочное» решение.
Вызов принят! Мы решили за ограниченное время справиться с этим кейсом.
Шаг 1 – транскрибируем несколько файлов и замеряем качество распознавания на своем решении и решении конкурентов.
Для измерения качества распознавания используем метрику WER.
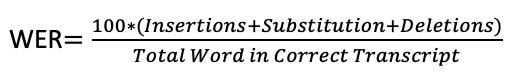
Пример расчета:
Исходные данные: Стационарный *** телефон зазвонил поздней ночью
Гипотеза: Стационарный синийi айфонs прозвонилs поздней ночью
WER = 100*(1+2+0)/5 = 60% (т.е. ошибка равна 60%).
Итоги тестового замера
Качество по %WER (чем меньше, тем лучше)
1) 58.6 ЦРТ
2) 64.7 наше решение Amvera Speech- без дообучения
3) 69.1 Tinkoff
4) 69.5 Salutbot (Sber)
5) 79.1 Nanosemantica
«Серебряная медаль» — это конечно хорошо, но WER = 0,64 - это неприемлемый для бизнеса результат.
Без адаптации алгоритм «не видел» часть реплик и допускал большое количество ошибок распознавания.

ШАГ 2 – разметка данных
Чтобы решить задачу, мы стали транскрибировать данные. Это нужно для того, чтобы:
А) Познакомить акустическую модель с шумами, разностью амплитуд и т.д.
Б) Обогатить языковую модель специфическими терминами (марки сигарет, топлива) и учесть статистику употребления. Так, для задачи словосочетание «девяносто пятый» актуальнее, чем словосочетание «шестьдесят третий», так как это наименование топлива, а значит, ему нужно задать более высокую вероятность.
Количество дополнительных данных влияет на результат обучения нелинейно. Эффект заметен начиная от 10 часов аудио. При этом каждые следующие 10 часов дают все меньший прирост. Из опыта: прирост качества почти завершается после разметки и добавления в исходную обучающую выборку данных 50 часов. В связи с этим, транскрибировать больше 40-50 часов аудио почти нецелесообразно.
ШАГ 3 – замеряем прогресс

Качество по %WER (чем меньше, тем лучше)
1) 38.6 Amvera Speech дообучение, 28окт
2) 42.2 Amvera Speech дообучение,19окт
3) 58.6 ЦРТ
4) 64.7 Amvera Speech – без дообучения
5) 69.1 Tinkoff
6) 69.5 Salutbot (Sber)
7) 79.1 Nanosemantica
")
 и детектирует большинство произнесенных реплик вне зависимости от разности в громкости и других факторов.")
Результат
1. Ошибка за месяц снижена в 1,67 раза с 64.7% до 38,6% по WER .
2. Адаптированное решение лучше ближайшего конкурента (бот ЦРТ) в 1,51 раза по WER.
3. Адаптированное решение распознает отраслевые термины (бренды сигарет, марки топлива).
4. Оставшаяся ошибка приходится на сильно искаженную и слабо слышимую речь.
5. Нам повезло - речь на АЗС не очень разнообразна и дообучить алгоритм можно на небольшой выборке.
Конечно, 38,6% по WER - это немаленькая ошибка и нужно смотреть, какие из бизнес-кейсов при такой ошибке решаемы, но это явно лучше изначальных 64.7%.
Бонус для дочитавших: наш телеграм бот для распознавания голосовых сообщений @AmVeraSpeechBot. В боте вы можете проверить качество работы нашего решения (Amvera Speech) по распознаванию речи для общей лексики (это универсальная модель, а не модель для АЗС). Просто отправьте в бот короткую аудиодорожку или голосовое сообщение – и получите текстовую расшифровку.
