Не так давно мы решили сделать проект, который позволял бы искать одежду в различных интернет-магазинах по фотографии (картинке). Идея проста — пользователь загружает изображение (фото), выделяет интересующую его область (футболку, штаны и т.п.), указывает (опционально) уточняющие параметры (пол, размер и т.п.), и система ищет похожую одежду в наших каталогах, сортируя ее по степени схожести с оригиналом.
Сама идея не то что бы новая, но качественно никем не реализованная. На рынке уже несколько лет есть проект www.snapfashion.co.uk, но релевантность его поиска очень низкая, подбор происходит в основном по определению цвета изображения. Например, красное платье он сможет найти, но платье с определенным фасоном или рисунком уже нет. Аудитория этого проекта, к слову, не растет, мы это связываем с тем, что поиск определенно низкой релевантности и, по сути, ничем не отличается, если вы выберете на сайте магазина цвет при поиске по их каталогу.
В 2013 году появился проект www.asap54.com, и здесь поиск чуть лучше. Упор стоит на цвет и некоторые небольшие опции, указываемые вручную из специального каталога (короткое платье, длинное платье, платье средней длинны). Этот проект, столкнувшись с трудностями визуального поиска, слегка завернул в сторону социальных сетей, где модники могут делиться своими «луками» в одежде, из «шазама для одежды» в «инстаграм для модников».
Несмотря на то, что проекты в этой области существуют, определенно остается непокрытой потребность поиска по картинке, очень актуальная сегодня. И решение данной проблемы созданием мобильного приложения, как это сделали SnapFashion и Asap54, наиболее отвечает тенденциям e-commerce рынка: по различным прогнозам доля мобильных продаж в США с 11% в 2013 году может вырасти да 25-50% в 2017. Такой стремительный рост мобильной торговли предвещает и рост популярности самых разных приложений, помогающих совершать покупки. И скорее всего магазины будут сами вкладываться в разработку, продвижение подобных приложений, а также активно сотрудничать с ними.
Проанализировав конкурентов, мы решили, что нужно попробовать самим разобраться с этой темой и запустили проект Sarafan www.getsarafan.com.
Фирменный стиль изначально хотели сделать ярким. Проработали множество вариантов:

В итоге остановились на стиле с яркими красками.
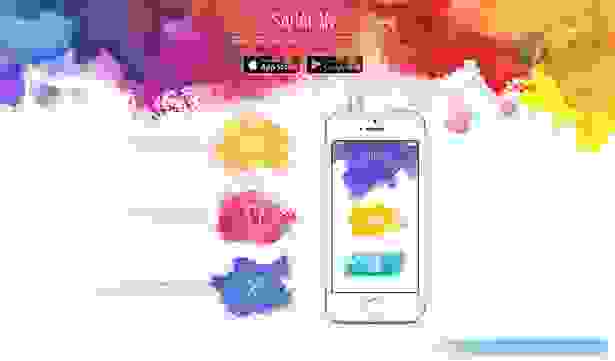
Для старта выбрали клиент под iOS (под iPhone). Дизайн в виде красок, работает через Rest-сервис, на главном экране приложения выбор: сделать фотографию или выбрать из галереи.

Это, пожалуй, было самым простым из всего проекта. А тем временем на передовой backend-разработки все складывалось не так радужно. И вот история наших поисков: что мы делали и к чему пришли.
Визуальный поиск
Нами было опробовано несколько подходов, но ни один из них не дал результатов, которые позволили бы сделать высокорелевантный поиск. В этой статье мы расскажем, что попробовали, и что и как сработало на разных данных. Надеемся, что данный опыт окажется полезным всем читателям.
Итак, главная проблема нашего поиска – это так называемый семантический разрыв (semantic gap). Т.е. разница между тем, какие изображения (в данном случае изображения одежды) считают похожими человек и машина. Например, человек хочет найти черную футболку с коротким рукавом:

Человек без труда скажет, что в списке ниже это второе изображение. Однако машина, скорее всего, выберет изображение 3, на котором женская футболка, но сцена имеет очень похожую конфигурацию и одинаковое цветовое распределение.

Человек ожидает, что результатом поиска будут позиции с тем же типом (футболка, майка, джисы …), приблизительно того же фасона и приблизительно с тем же цветовым распределением (цвет, текстура или рисунок). Но на практике обеспечить выполнение всех трех условий оказалось проблематично.
Начнем с самого простого, изображение со схожим цветом. Для сравнения изображений по цвету чаще всего используют метод цветовых гистограмм. Идея метода цветовых гистограмм для сравнения изображений сводится к следующему. Все множество цветов разбивается на набор непересекающихся, полностью покрывающих его подмножеств. Для изображения формируется гистограмма, отражающая долю каждого подмножества цветов в цветовой гамме изображения. Для сравнения гистограмм вводится понятие расстояния между ними. Существует много разных методов формирования цветовых подмножеств. В нашем случае их разумно было бы формировать из нашего каталога изображений. Однако даже для такого простого сравнения требуется выполнения следующих условий:
— Изображения в каталоге должны содержать одну только вещь на легко отделимом фоне;
— Нам нужно эффективно различать фон и интересующую нас область одежды на фотографиях пользователя.
На практике первое условие не выполняется никогда. О попытках решить эту проблему мы расскажем позже. Со вторым условием сравнительно проще, т.к. выделение интересующей области на изображении пользователя происходит с его активным участием. Например, существует довольно эффективный алгоритм удаления фона – GrabCut (http://en.wikipedia.org/wiki/GrabCut). Мы исходили из соображения, что интересующая нас область на изображении находится ближе к центру обведенной пользователем области, чем к ее границе и фон в данной области изображения будет относительно однородным по цвету. С использованием GrabCut и некоторых эвристик, удалось получить алгоритм, работающий корректно в большинстве случаев.
Теперь о выделении интересующей нас области на изображениях каталога. Первое что приходит в голову – сегментировать изображение по цвету. Для этого подойдет например алгоритм watershed (http://en.wikipedia.org/wiki/Watershed_(image_processing)).
Однако изображение красной юбки в каталоге может иметь несколько вариантов:

Если в первом и втором случае сегментировать интересующую область сравнительно легко, то в 3-м случае в мы выделим еще и пиджак. Для более сложных случаев этот метод не сработает, например:

Стоит отметить, что задача сегментации изображений полностью не решена. Т.е. не существует методов, которые позволяют выделить интересующую область одним фрагментом, как это может сделать человек:

Вместо этого изображение разбивается на суперпиксели (superpixel), тут стоит посмотреть в сторону алгоритмов n-cuts и turbopixel.
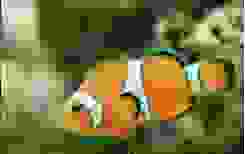
В дальнейшем используют их некоторое сочетание. Например, задача поиска и локализации объекта сводится к поиску сочетания суперпикселей, принадлежащих объекту, вместо поиска ограничивающего прямоугольника.

Итак, задача разметки изображений каталога свелась к поиску сочетания суперпикселей, которые соответствуют вещи данного типа. Это уже задача машинного обучения. Идея была следующая, взять множество размеченных вручную изображений, обучить на ней классификатор и классифицировать различные области сегментированного изображения. Область с максимальным откликом считать интересующей нас областью. Но тут надо снова определиться, как сравнивать изображения, т.к. простое сравнение по цвету гарантированно не сработает. Придется сравнивать форму или некий образ сцены. Как казалось на тот момент, для этих целей подойдет дескриптор gist (http://people.csail.mit.edu/torralba/code/spatialenvelope/). Дескриптор gist – это некая гистограмма распределения краев в изображении. Изображение делится на равные части сеткой какого-либо размера, в каждой ячейке считается и дискретизируется распределение краев разной ориентации и разного размера. Полученные в результате n-мерные вектора мы можем сравнивать.
Была создана обучающая выборка, вручную было размечено множество изображений разных классов (около 10). Но, к сожалению, даже при кросс-валидации не удалось добиться точности классификации выше 50%, меняя параметры алгоритма. Частично виной тому является то, что рубашка с точки зрения распределения краев будет мало чем отличаться от куртки, частично то, что обучающая выборка была недостаточно большая (обычно gist применяется для поиска по очень большим коллекциям изображений), частично то, что для данной задачи он, возможно, вообще не применим.
Еще один метод сравнения изображений – сравнение локальных особенностей. Его идея в следующем – выделить значимые точки на изображениях (локальные особенности), каким-либо образом описать окрестности данных точек и сравнивать количество совпадений особенностей у двух изображений. В качестве дескриптора использовали SIFT. Но сравнение локальных особенностей так же дало плохие результаты, большей частью из-за того, что данный метод предназначен для сравнения изображений одной и той же сцены, снятой с разного ракурса.
Таким образом, не получилось разметить изображения из каталога. Поиск по неразмеченным изображениям с использованием вышеописанных методов иногда давал приблизительно похожие результаты, но в большинстве случаев в результате не было ничего похожего с точки зрения человека.
Когда стало понятно, что разметить каталог у нас не получилось, мы попытались сделать классификатор для изображений пользователя, т.е. автоматически определять тип вещи которую хотел найти пользователь (футболка, джинсы и т.п.). Главная проблема – это отсутствие обучающей выборки. Изображения каталога не подходят, во-первых из-за того что они остались не размечены, а во-вторых они представлены в довольно ограниченном наборе пространственных представлений и нет гарантии что пользователь предоставит изображения в похожем представлении. Чтобы получить большой набор пространственных представлений для вещи мы снимали человека в этой вещи на видео, затем вырезали вещь и строили обучающую выборку по набору кадров. При этом вещь была контрастная и легко отделялась от фона.
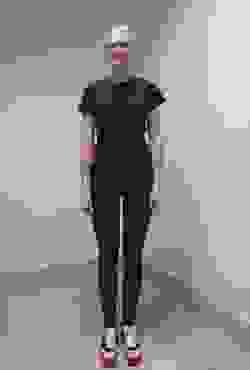
К сожалению, этот подход быстро отклонили, когда стало понятно, сколько видео нужно снять и обработать, чтобы охватить все возможные фасоны одежды.
Компьютерное зрение — это очень обширный сегмент, но нам (пока что) не удалось прийти к желаемому результату с высокорелевантным поиском. Мы не хотим сворачивать в сторону, добавляя дополнительные побочные функции, а будем биться, создавая поисковый инструмент. Мы будем рады услышать любые советы и комментарии.
Сама идея не то что бы новая, но качественно никем не реализованная. На рынке уже несколько лет есть проект www.snapfashion.co.uk, но релевантность его поиска очень низкая, подбор происходит в основном по определению цвета изображения. Например, красное платье он сможет найти, но платье с определенным фасоном или рисунком уже нет. Аудитория этого проекта, к слову, не растет, мы это связываем с тем, что поиск определенно низкой релевантности и, по сути, ничем не отличается, если вы выберете на сайте магазина цвет при поиске по их каталогу.
В 2013 году появился проект www.asap54.com, и здесь поиск чуть лучше. Упор стоит на цвет и некоторые небольшие опции, указываемые вручную из специального каталога (короткое платье, длинное платье, платье средней длинны). Этот проект, столкнувшись с трудностями визуального поиска, слегка завернул в сторону социальных сетей, где модники могут делиться своими «луками» в одежде, из «шазама для одежды» в «инстаграм для модников».
Несмотря на то, что проекты в этой области существуют, определенно остается непокрытой потребность поиска по картинке, очень актуальная сегодня. И решение данной проблемы созданием мобильного приложения, как это сделали SnapFashion и Asap54, наиболее отвечает тенденциям e-commerce рынка: по различным прогнозам доля мобильных продаж в США с 11% в 2013 году может вырасти да 25-50% в 2017. Такой стремительный рост мобильной торговли предвещает и рост популярности самых разных приложений, помогающих совершать покупки. И скорее всего магазины будут сами вкладываться в разработку, продвижение подобных приложений, а также активно сотрудничать с ними.
Проанализировав конкурентов, мы решили, что нужно попробовать самим разобраться с этой темой и запустили проект Sarafan www.getsarafan.com.
Фирменный стиль изначально хотели сделать ярким. Проработали множество вариантов:

В итоге остановились на стиле с яркими красками.

Для старта выбрали клиент под iOS (под iPhone). Дизайн в виде красок, работает через Rest-сервис, на главном экране приложения выбор: сделать фотографию или выбрать из галереи.

Это, пожалуй, было самым простым из всего проекта. А тем временем на передовой backend-разработки все складывалось не так радужно. И вот история наших поисков: что мы делали и к чему пришли.
Визуальный поиск
Нами было опробовано несколько подходов, но ни один из них не дал результатов, которые позволили бы сделать высокорелевантный поиск. В этой статье мы расскажем, что попробовали, и что и как сработало на разных данных. Надеемся, что данный опыт окажется полезным всем читателям.
Итак, главная проблема нашего поиска – это так называемый семантический разрыв (semantic gap). Т.е. разница между тем, какие изображения (в данном случае изображения одежды) считают похожими человек и машина. Например, человек хочет найти черную футболку с коротким рукавом:

Человек без труда скажет, что в списке ниже это второе изображение. Однако машина, скорее всего, выберет изображение 3, на котором женская футболка, но сцена имеет очень похожую конфигурацию и одинаковое цветовое распределение.

Человек ожидает, что результатом поиска будут позиции с тем же типом (футболка, майка, джисы …), приблизительно того же фасона и приблизительно с тем же цветовым распределением (цвет, текстура или рисунок). Но на практике обеспечить выполнение всех трех условий оказалось проблематично.
Начнем с самого простого, изображение со схожим цветом. Для сравнения изображений по цвету чаще всего используют метод цветовых гистограмм. Идея метода цветовых гистограмм для сравнения изображений сводится к следующему. Все множество цветов разбивается на набор непересекающихся, полностью покрывающих его подмножеств. Для изображения формируется гистограмма, отражающая долю каждого подмножества цветов в цветовой гамме изображения. Для сравнения гистограмм вводится понятие расстояния между ними. Существует много разных методов формирования цветовых подмножеств. В нашем случае их разумно было бы формировать из нашего каталога изображений. Однако даже для такого простого сравнения требуется выполнения следующих условий:
— Изображения в каталоге должны содержать одну только вещь на легко отделимом фоне;
— Нам нужно эффективно различать фон и интересующую нас область одежды на фотографиях пользователя.
На практике первое условие не выполняется никогда. О попытках решить эту проблему мы расскажем позже. Со вторым условием сравнительно проще, т.к. выделение интересующей области на изображении пользователя происходит с его активным участием. Например, существует довольно эффективный алгоритм удаления фона – GrabCut (http://en.wikipedia.org/wiki/GrabCut). Мы исходили из соображения, что интересующая нас область на изображении находится ближе к центру обведенной пользователем области, чем к ее границе и фон в данной области изображения будет относительно однородным по цвету. С использованием GrabCut и некоторых эвристик, удалось получить алгоритм, работающий корректно в большинстве случаев.
Теперь о выделении интересующей нас области на изображениях каталога. Первое что приходит в голову – сегментировать изображение по цвету. Для этого подойдет например алгоритм watershed (http://en.wikipedia.org/wiki/Watershed_(image_processing)).
Однако изображение красной юбки в каталоге может иметь несколько вариантов:

Если в первом и втором случае сегментировать интересующую область сравнительно легко, то в 3-м случае в мы выделим еще и пиджак. Для более сложных случаев этот метод не сработает, например:

Стоит отметить, что задача сегментации изображений полностью не решена. Т.е. не существует методов, которые позволяют выделить интересующую область одним фрагментом, как это может сделать человек:

Вместо этого изображение разбивается на суперпиксели (superpixel), тут стоит посмотреть в сторону алгоритмов n-cuts и turbopixel.

В дальнейшем используют их некоторое сочетание. Например, задача поиска и локализации объекта сводится к поиску сочетания суперпикселей, принадлежащих объекту, вместо поиска ограничивающего прямоугольника.

Итак, задача разметки изображений каталога свелась к поиску сочетания суперпикселей, которые соответствуют вещи данного типа. Это уже задача машинного обучения. Идея была следующая, взять множество размеченных вручную изображений, обучить на ней классификатор и классифицировать различные области сегментированного изображения. Область с максимальным откликом считать интересующей нас областью. Но тут надо снова определиться, как сравнивать изображения, т.к. простое сравнение по цвету гарантированно не сработает. Придется сравнивать форму или некий образ сцены. Как казалось на тот момент, для этих целей подойдет дескриптор gist (http://people.csail.mit.edu/torralba/code/spatialenvelope/). Дескриптор gist – это некая гистограмма распределения краев в изображении. Изображение делится на равные части сеткой какого-либо размера, в каждой ячейке считается и дискретизируется распределение краев разной ориентации и разного размера. Полученные в результате n-мерные вектора мы можем сравнивать.
Была создана обучающая выборка, вручную было размечено множество изображений разных классов (около 10). Но, к сожалению, даже при кросс-валидации не удалось добиться точности классификации выше 50%, меняя параметры алгоритма. Частично виной тому является то, что рубашка с точки зрения распределения краев будет мало чем отличаться от куртки, частично то, что обучающая выборка была недостаточно большая (обычно gist применяется для поиска по очень большим коллекциям изображений), частично то, что для данной задачи он, возможно, вообще не применим.
Еще один метод сравнения изображений – сравнение локальных особенностей. Его идея в следующем – выделить значимые точки на изображениях (локальные особенности), каким-либо образом описать окрестности данных точек и сравнивать количество совпадений особенностей у двух изображений. В качестве дескриптора использовали SIFT. Но сравнение локальных особенностей так же дало плохие результаты, большей частью из-за того, что данный метод предназначен для сравнения изображений одной и той же сцены, снятой с разного ракурса.
Таким образом, не получилось разметить изображения из каталога. Поиск по неразмеченным изображениям с использованием вышеописанных методов иногда давал приблизительно похожие результаты, но в большинстве случаев в результате не было ничего похожего с точки зрения человека.
Когда стало понятно, что разметить каталог у нас не получилось, мы попытались сделать классификатор для изображений пользователя, т.е. автоматически определять тип вещи которую хотел найти пользователь (футболка, джинсы и т.п.). Главная проблема – это отсутствие обучающей выборки. Изображения каталога не подходят, во-первых из-за того что они остались не размечены, а во-вторых они представлены в довольно ограниченном наборе пространственных представлений и нет гарантии что пользователь предоставит изображения в похожем представлении. Чтобы получить большой набор пространственных представлений для вещи мы снимали человека в этой вещи на видео, затем вырезали вещь и строили обучающую выборку по набору кадров. При этом вещь была контрастная и легко отделялась от фона.

К сожалению, этот подход быстро отклонили, когда стало понятно, сколько видео нужно снять и обработать, чтобы охватить все возможные фасоны одежды.
Компьютерное зрение — это очень обширный сегмент, но нам (пока что) не удалось прийти к желаемому результату с высокорелевантным поиском. Мы не хотим сворачивать в сторону, добавляя дополнительные побочные функции, а будем биться, создавая поисковый инструмент. Мы будем рады услышать любые советы и комментарии.
