
К чему вы стремитесь в работе? Мной всегда двигало желание быть причастным к чему-то, что действительно помогает людям решать важные задачи. Это стремление привело меня в проект онлайн-системы дистанционного обучения (Learning Management System, сокращённо LMS).
В силу масштаба, разработчикам часто приходится задумываться об аспектах, которые не вызывают трудностей в разработке небольших систем. Недавно мы писали о тонкостях тестирования LMS, а в этой статье я расскажу о том, как мы прошли долгий путь от редких, достаточно рискованных и весьма затратных релизов до частых и более предсказуемых.
Что вы представляете, когда слышите об обучении в школе или университете? О чём бы вы сейчас ни подумали, скорее всего, это реализовано в LMS. Все инструменты, необходимые преподавателям для преподавания, ученикам для обучения, родителям для контроля, а директорам для администрирования учебного процесса, доступны в электронном виде. Платформой ежедневно пользуется более 7 000 000 пользователей из Европы и США, а трудится над ней распределённая команда из нескольких стран.
Особенности релиза
Некоторое время назад заказчик начал агрессивно завоёвывать рынок. Это не только спровоцировало резкий рост команды, но и показало, что в некоторых аспектах мы не были готовы к бо́льшему масштабу. Несмотря на то, что учебные заведения были готовы платить деньги за использование и дополнительную интеграцию, а сам проект располагал достаточным количеством ресурсов для оперативной разработки новой функциональности, процесс экспансии рынка был недостаточно быстрым из-за нечастых релизов. В современном мире никто не готов ждать долго!
В 2013, когда я пришёл в проект, релизы случались 3-4 раза в год; им предшествовало регрессионное тестирование длительностью от 2 до 3 недель, в котором участвовали все разработчики и тестировщики. В период регрессии разработка полностью останавливалась, поскольку важно было пройти каждый тест-кейс вручную, а их, как можно догадаться, было немало. Помимо очевидных издержек, регрессия была весьма утомительной для всех её участников.
Однако просто начать обновляться чаще было невозможно в силу сплетения исторических причин, специфики проекта и предъявляемых к нему требований.
Монолитная архитектура
Проект к тому времени уже имел долгую историю разработки. Начавшись как студенческая курсовая работа, система перетекла в продолжительную фазу разработки на C++ (да, это было давно), затем шёл долгий этап развития на ASP.NET, который используется и по сей день. Многие актуальные сейчас подходы к разработке отсутствовали или только зарождались, .NET 2.0 вовсе не имел такую палитру возможностей, которая есть в современном .NET Core. То, что сейчас может видеться Франкенштейном, некоторое время назад не осознавалось как что-то ужасное. Архитектура системы была монолитна, как титановый шар, но до какого-то момента это всех устраивало.
Негибкая архитектура платформы позволяла релизить только всё и сразу, что увеличивало временные издержки и шанс попасть впросак. Самым логичным шагом в той ситуации стало очень подробное регрессионное тестирование перед релизом.
Жёсткие требования
Если в России подобные системы даже на момент выхода статьи используются нечасто и почти всегда вся информация дублируется на бумаге, то в школах и университетах Европы LMS — это ядро обучения. Все данные о студентах, учителях, родителях, их взаимодействии, посещаемости, успеваемости, учебные материалы, домашние работы и др. хранятся в электронном виде без двойного документооборота. Исходя из этого, к системе предъявляются крайне жёсткие требования безопасности, производительности и, что очень важно, доступности. Представьте, что ваш главный и единственный ресурс, обеспечивающий учебный процесс, вдруг сломался. Недоступность в течение 5 минут вызовет у вас дискомфорт, а часовой простой — крайнюю степень возмущения. Поэтому uptime — время, когда система доступна и полностью выполняет свои функции — одна из ключевых метрик, которая является юридическим обязательством, за неисполнение которого предусмотрены большие штрафы. Uptime 99.9% — это цифра, к которой мы стремимся.
Релиз же является угрозой стабильности не только по причине потенциальных багов в новой версии. Ещё до изменений релизного процесса в проекте было несколько десятков веб-приложений, различных асинхронных сервисов, API и прочего. Когда система достаточно большая, проблемы при обновлении версии могут возникнуть и в самом процессе развёртывания, что может привести к недопустимому простою.
Неудивительно, что с точки зрения специалистов по информационно-технологическому обслуживанию (Operations, или OPS) идеальный продакшен — это продакшен без релизов, а с точки зрения пользователей — продакшен с максимально частыми обновлениями. Поэтому концепция частых релизов предполагает компромисс между желаниями пользователей, разработчиков и операционистов. Пользователи должны получать обновления в приемлемый срок, OPS должны уметь быстро выкатить новую версию, а разработчики должны убедить операционистов в том, что каждый новый релиз безопасен и они не сядут в лужу.
Неоптимальные процессы
Одной из важных причин редких релизов стали неотлаженные процессы управления релизом и подходы к разработке и тестированию. Подробнее о них я расскажу дальше.
TL;DR
Дано: релизы раз в квартал, амбиции роста, сложный продукт с монолитной архитектурой, неоптимальные процессы, консервативность OPS.
Хотим:денегчастых релизов новых фич.
Не хотим:штрафовдаунтайма.
Трансформация
С осознанием глобальных проблем и чётким пониманием того, что хотелось бы иметь в итоге, компания начала постепенные изменения.
В этой статье я остановлюсь на изменениях в разработке и непосредственном процессе релиза, но стоит отметить, что немало изменений произошло и в работе OPS.
Устранение инфраструктурных проблем
Для начала нужно было устранить некоторые инфраструктурные проблемы.
Во-первых, изолированная работа большого количества команд над отдельными новыми фичами была непростой из-за TFS, который мы использовали. Оказалось, что совместную работу может сильно ускорить новая модель ветвления, которую гораздо проще организовать, используя git. Так проект, собрав
Во-вторых, само развёртывание проекта состояло из неопределённого набора неунифицированных скриптов PowerShell, которые были написаны разными людьми для разных целей, содержали комментарии на разных языках и не всегда были понятны простому смертному. И хотя они худо-бедно выполняли свою функцию, при росте количества компонентов оперировать ими становилось всё тяжелее. Так у нас появилась своя собственная утилита для деплоймента. Она заточена под собственные нужды — автоматизирует последовательность выполнения шагов и развёртывание каждого отдельного компонента системы, ведёт логи процесса. При добавлении нового компонента разработчики и OPS всегда обсуждают, как новое приложение будет разворачиваться на продакшен серверах, включая требования к инфраструктуре и процедуру развёртывания. Сам скрипт развёртывания пишут разработчики, он хранится вместе с исходным кодом компонента. Последовательность развёртывания универсальна для всех серверов, но переменные среды конфигурируются в зависимости от окружения. Новая утилита стала использоваться и на тестовых серверах, и в продакшене, что позволило находить проблемы развёртывания ещё на этапе тестирования.
Несмотря на то, что решения обеих проблем описаны достаточно коротко, они потребовали достаточного количества усилий, координации и времени.
Формализация и сокращение таймлайна
От схемы «ждём, пока все команды закончат разработку, почти месяц регрессим, а потом релизим, когда получится», мы перешли к более предсказуемой концепции «релизных поездов», которые следуют чёткому расписанию. Теперь даты нескольких ближайших релизов известны заранее. Если кто-то не успел в конкретный релиз — семеро одного не ждут. Это изменение позволило планировать доставку фич и быть более точными в своих обещаниях перед клиентами.
Мы начали с робких попыток ежемесячных релизов, затем постепенно дошли до релизов раз в 2 недели. Короткие циклы благотворно сказались на качестве. Меньше кода — меньше рисков, больше вероятность заранее выявить все потенциальные проблемы.
С двухнедельными циклами мы прожили несколько лет, но всё же остановились на релизах раз в месяц. Так получилось потому, что процесс всё ещё требовал большого количества ручной работы (тестирование, стейджинг и т.п.). К тому же важным фактором стала усталость тестировщиков: в проекте их не так много, а релизные задачи часто отвлекали их от основной работы в команде. Ежемесячные релизы стали золотой серединой — мы остались достаточно быстрыми в доставке обновлений, релизы всё ещё остались относительно небольшими, но при этом командам разработки стало работать комфортнее.
Как устроен релизный цикл
При обновлениях каждые две недели релизная итерация занимала почти 5 недель. Как же так?
Разберём один двухнедельный релиз методом обратного планирования. Мы знаем дату релиза и сколько занимают стабилизационное тестирование и стейджинг релиз-кандидата (2 недели), тогда к началу стабилизации в релиз должны быть включены все новые фичи (code freeze). Всё, что не было включено вовремя (кроме редких заранее оговорённых случаев), переходит на следующий релиз. Чтобы включить новую разработку в релиз, нужно полностью протестировать её функциональность, включая переводы, и убедиться в отсутствии багов. Локализацию выполняет сторонняя компания, и ей требуется около недели, чтобы перевести новые строки. Поэтому за 2 недели до начала тестирования релиз-кандидата мы отправляем на перевод новые строки. После получения переводов у команд есть примерно неделя, чтобы закончить тестирование и попасть в релиз. Непосредственно после релиза идёт неделя мониторинга новых проблем на продакшене. За это время нужно убедиться, что релиз не привнёс никаких новых проблем, а если проблемы появились — решить, требуется ли их устранить до следующего релиза.
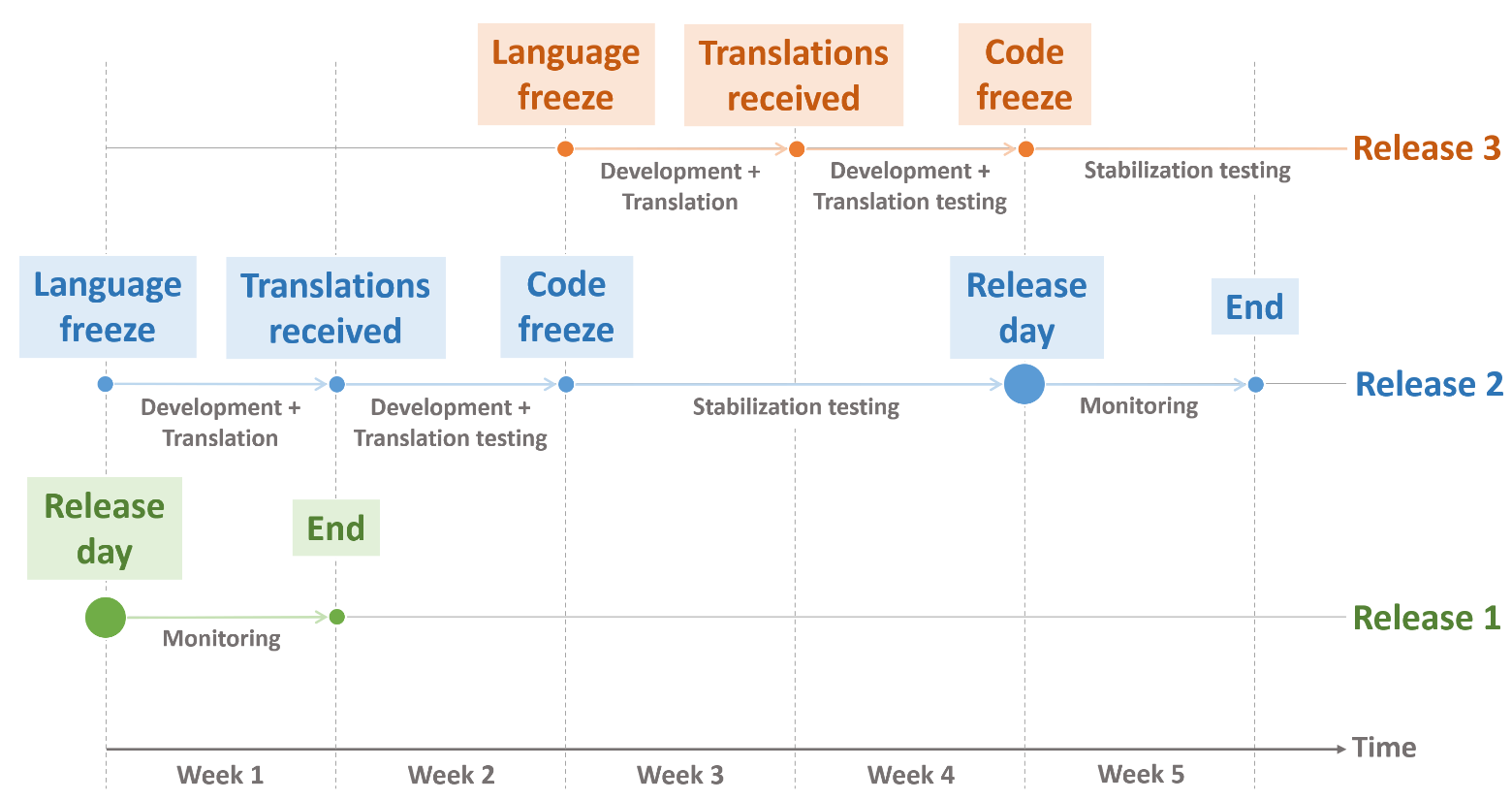
С ежемесячными релизами итерация также длится 5 недель, но после двухнедельного цикла подготовки релиза следуют 2 недели без релизной работы.
Таким образом, в один момент времени может идти мониторинг недавно случившегося релиза, стабилизация нового и подготовка переводов следующего за ним.
Разберём один двухнедельный релиз методом обратного планирования. Мы знаем дату релиза и сколько занимают стабилизационное тестирование и стейджинг релиз-кандидата (2 недели), тогда к началу стабилизации в релиз должны быть включены все новые фичи (code freeze). Всё, что не было включено вовремя (кроме редких заранее оговорённых случаев), переходит на следующий релиз. Чтобы включить новую разработку в релиз, нужно полностью протестировать её функциональность, включая переводы, и убедиться в отсутствии багов. Локализацию выполняет сторонняя компания, и ей требуется около недели, чтобы перевести новые строки. Поэтому за 2 недели до начала тестирования релиз-кандидата мы отправляем на перевод новые строки. После получения переводов у команд есть примерно неделя, чтобы закончить тестирование и попасть в релиз. Непосредственно после релиза идёт неделя мониторинга новых проблем на продакшене. За это время нужно убедиться, что релиз не привнёс никаких новых проблем, а если проблемы появились — решить, требуется ли их устранить до следующего релиза.

С ежемесячными релизами итерация также длится 5 недель, но после двухнедельного цикла подготовки релиза следуют 2 недели без релизной работы.
Таким образом, в один момент времени может идти мониторинг недавно случившегося релиза, стабилизация нового и подготовка переводов следующего за ним.
Новая стратегия создания веток
Раньше мы не особо переживали о стратегии ветвления, потому что фактически с момента начала регрессии до самого релиза разработка останавливалась.
Схема, к которой мы в итоге пришли, была придумана не нами, но идеально подошла под наши нужды и выглядит так:

Описание
Существуют две главные долгоживущие ветки — develop и master. Код в master в любой момент времени должен совпадать с версией в продакшене. От ветки master создаются ветки для хотфиксов и патчей, и в неё же они включаются сразу после того, как были выпущены. В ветку develop попадают новые, полностью рабочие фичи. Когда настаёт пора начинать стабилизацию нового релиза, релиз-кандидат ответвляется от develop'а, который с этого момента начинает накапливать изменения для следующего релиза. В релизном бранче исправляются баги, найденные в релизе. После завершения стабилизации и непосредственно релиза, релизный бранч оказывается в ветке master.
Изменение подхода к тестированию релиз-кандидата
Мы приняли решение отказаться от ручной регрессии в привычном виде, поскольку новая парадигма не позволяла тратить на тестирование так много времени. Регрессия трансформировалась в тестирование критических областей: были выявлены самые часто используемые и самые важные функции, которые нужно обязательно проверить перед выходом релиза. Мы постепенно покрываем эти области Selenium-тестами, уменьшая объём ручного тестирования.
Раньше в порядке вещей было найти десяток багов в новой функциональности во время регрессии и исправлять их (или откатывать), тем самым сдвигая срок релиза. Согласно новому definition of done, только функциональность, которая полностью выверена и не содержит багов, может быть отправлена в develop. Исходя из этого, мы оставили лишь беглый просмотр новой функциональности в релиз-кандидате на предмет интеграционных проблем.
Отказываться от полноценного регрессионного тестирования было страшно, но, к счастью, заметной деградации качества не произошло.
Изменения в архитектуре
Монолитную систему релизить долго, сложно и рискованно. Переход к частым релизам форсировал декомпозицию на мелкие компоненты, которые можно деплоить отдельно (single deployable). Ввиду размеров проекта этот процесс до сих пор не завершён, но шаг за шагом мы вычленяем новые компоненты, релиз которых может происходить отдельно от релиза главного приложения. Новые компоненты сразу разрабатываются обособленно.
TL;DR
Разработка: перешли с TFS на Git, разработали собственное решение для деплоймента, ввели новую схему создания веток в разработке, пересмотрели и улучшили архитектуру.
Тестирование: убрали ручную регрессию, частично заменив её автоматическими тестами, оставили стабилизацию новой функциональности.
Процессы: описали таймлайн со всеми итерациями релизного процесса, ввели концепцию «релизных поездов» и добавили пилотирование новых фич на небольшом количестве пользователей.
Релиз-менеджмент: из креатива в рутину
Сложно переоценить важность менеджмента релиза в большом проекте, где жизненно необходимо наличие человека, который всегда в курсе текущего положения дел и способен координировать работу большого количества людей.
Роль менеджера релиза в проекте существовала всегда. Исторически это была не просто роль, а некий верховный титул, которого удостаивались лишь 2-3 ключевых человека — самые сеньористые сеньоры. С одной стороны, это привносило некоторую стабильность, но с другой — порождало некоторые издержки.
Во-первых, принимая в расчёт время подготовки релиза и высокий уровень ответственности, эта работа была достаточно тяжёлой, и никто не горел желанием браться за неё часто. Нужно было расширить список потенциальных кандидатов, но это приводило ко второй проблеме: несмотря на то, что за плечами было достаточное количество релизов, каждый новый релиз был не похож на предыдущий. Никто не мог до конца понять, что входит в перечень обязанностей менеджера, а что нет. Самой главной задачей нового релиз-менеджера было выяснить, что вообще делает релиз-менеджер. В самом начале это было совсем непросто, но постепенно мы очертили круг основных задач и ответственности менеджера релиза. Процесс стал хорошо задокументированным: были описаны связи между компонентами, последовательность развёртывания, таймлайн релиза и многое другое. Когда менеджмент из креативной задачи, которую каждый решает по-своему, превращается в подробный алгоритм действий, задачу можно без особого риска поручить любому достаточно опытному человеку. Чем подробнее описан сложный процесс, тем проще найти ответ в случае необходимости. В данном случае бюрократизация процесса оказалась очень оправданной!
Это решение убило сразу несколько зайцев. Из явных: появилось больше взаимозаменяемых релиз-менеджеров без привязки к конкретным личностям, уменьшилась нагрузка на ключевых людей, появилось представление об объёме работы. Из неявных: побывав в шкуре менеджера релиза, разработчик может глубже познакомиться с особенностями проекта и отчётливее понять, как его код может повлиять на производительность.
Обязанности менеджера релиза
Вот неполный перечень того, что делает менеджер релиза:
Что НЕ входит в задачи менеджера релиза:
- отправляет новые строки на переводы и добавляет готовые переводы;
- организует встречу с представителями команд, участвующих в релизе, где подробно расспрашивает об изменениях, рисках, зависимостях и т. д.;
- создаёт релизную ветку, разворачивает её на тестовых серверах и следит за работоспособностью тестового окружения;
- мониторит логи во время стабилизации, раздаёт найденные баги;
- находится в тесной связи с QA-координатором, который контролирует стабилизационное тестирование, отвечает на его вопросы, помогает найти ответственную команду при нахождении багов;
- контролирует сроки; при невозможности вписаться с таймлайн обсуждает это с владельцами продукта, менеджментом и другими заинтересованными лицами;
- просматривает все изменения в коде после исправления багов;
- отдаёт релиз на стейджинг и отвечает на вопросы OPS;
- в день релиза и последующую неделю мониторит логи;
- при необходимости координирует патчи и хотфиксы, которые являются упрощёнными релизами;
- участвует в ретроспективе релиза.
Что НЕ входит в задачи менеджера релиза:
- развёртывание обновления в продакшене — для этого есть OPS;
- исправление найденных багов — за это ответственны команды.
TL;DR
Сформулировали зону ответственности менеджера релиза, максимально задокументировали процесс, это позволило делегировать роль большему количеству людей.
Так ли всё идеально?
Если у вас сложилось впечатление, что в проекте теперь всё идеально, то спешу вас уверить, что идеала не существует (что не мешает нам к нему стремиться).
Как и в других проектах, мы часто балансируем между созданием новых фич и техническими улучшениями, которые не добавляют прямой ценности с точки зрения конечных пользователей. Поэтому автоматизация регрессии не закончена на 100%, иногда в релиз-кандидате проскакивают баги, и приходится быстро принимать решение о дальнейших действиях. Иногда релизы отменяются или переносятся по разным причинам, начиная с долгих праздничных дней в начале года и мае и заканчивая поздно найденными критическими багами или форс-мажорами. А ещё случаются активности OPS — обновления серверов, миграции данных, установка новой инфраструктуры, — на время которых релизы останавливаются.
У нас случались «неудачные» релизы, после которых нужно было спешно исправлять критические баги.
Когда весь мир в апреле и мае посадили на карантин, нагрузка на платформу дистанционного обучения выросла в несколько раз. Увеличение числа конкурентных сессий, количества операций в целом — всё это обнажило узкие места, которые до этого не выдавали себя. В это время не было релизов новой функциональности, зато были постоянные патчи и хотфиксы. Очень много людей было занято залатыванием дыр. Зато, когда обстановка стабилизировалась, оказалось, что накопилось солидное количество новых фич и новый релизный поезд набит под завязку.

От маленьких, быстро тестируемых и малорискованных релизов произошёл откат в сторону долгой стабилизации (и как следствие, более долгой итерации), а также бо́льшего количества багов в релиз-кандидате, что было очень непривычно.
Стоит отметить, что даже при таком положении дел релизы оказались менее трудозатратны и рискованны, чем раньше.
Дальнейшее развитие
Прогресс необратим — с каждым новым релизом (и его ретроспективой), мы меняемся, выявляем новые слабые стороны и выполняем работу над ошибками.
Вектор дальнейшего улучшения релиза предопределён:
- расширить автоматизацию тестирования;
- стремиться к ещё более коротким релизным циклам, которые будут проходить всё менее заметно как для пользователей, так и для команд;
- вынести как можно больше новых компонентов, которые могут релизиться отдельно.
Выводы
В разработке сложного веб-приложения релиз новой версии занимает особое место. За несколько лет мы сумели перейти с ежеквартальных релизов к релизам раз в 2 недели, но впоследствии остановились на ежемесячных. Это оказалось непросто и увлекательно, трансформация потребовала комплексных изменений, которые коснулись разработчиков, тестировщиков, OPS и менеджмента. Релизы новой версии стали менее объёмными, менее рискованными и более прозрачными с точки зрения сроков — закончилась эпоха, когда релизы были СОБЫТИЕМ. К сожалению, традиция есть мороженое по случаю релиза тоже закончилась.
