
Всем привет. Меня зовут Нещадин Иван, и я расскажу про оптимизацию одного из микросервисов Авито на Go. История построена вокруг различных инструментов, которые доступны в языке, и пойдёт от простых примеров к более сложным.

Какие были проблемы
В процессе распила монолита у нас появилась необходимость получать публичный номер телефона в различных сервисах. Публичный номер телефона — это номер, который покупатель видит при нажатии кнопки «показать номер» на сайте или «позвонить» в мобильном приложении. Сейчас у нас три вида таких номеров: call tracking, анонимный номер и реальный номер продавца.
Анонимный номер мы выдаём пользователям за деньги в некоторых категориях объявлений. Как правило, это самые дорогие категории: транспорт и недвижимость. Мы делаем это для того, чтобы не показывать настоящий номер человека и переадресовывать вызовы. Call tracking номер тоже переадресовывает вызов, только у него есть дополнительные функции: запись разговоров, статистика звонков и так далее.
У нас было несколько трудностей, в связи с которыми мы решили вынести функциональность публичного номера телефона в отдельный сервис.
Первая проблема — дублирование логики получения номеров из трёх сервисов. Было три сервиса, и нам требовалось сходить в каждый из них, и в каждом месте, где нужно получить публичный номер, написать условия, по которым мы определяем, какой из трёх вариантов номеров показывать в данный момент.
Второй момент — потенциальные проблемы с безопасностью из-за того, что мы не могли контролировать все места выдачи номера телефона. Также для получения номера необходимо было сходить в интеграционное API монолита, потому что базы call tracking жили именно там.
Что решили сделать
Чтобы избавиться от проблем, мы решили создать отдельный сервис phones-gateway. Он принимает на вход ID пользователя, ID объявления, категории и телефон. Phones-gateway сам ходит в сервисы call tracking, реальных телефонов и анонимных номеров. Затем на основании какой-то бизнес-логики он определяет, какой конкретно номер нужно показывать в данной ситуации.
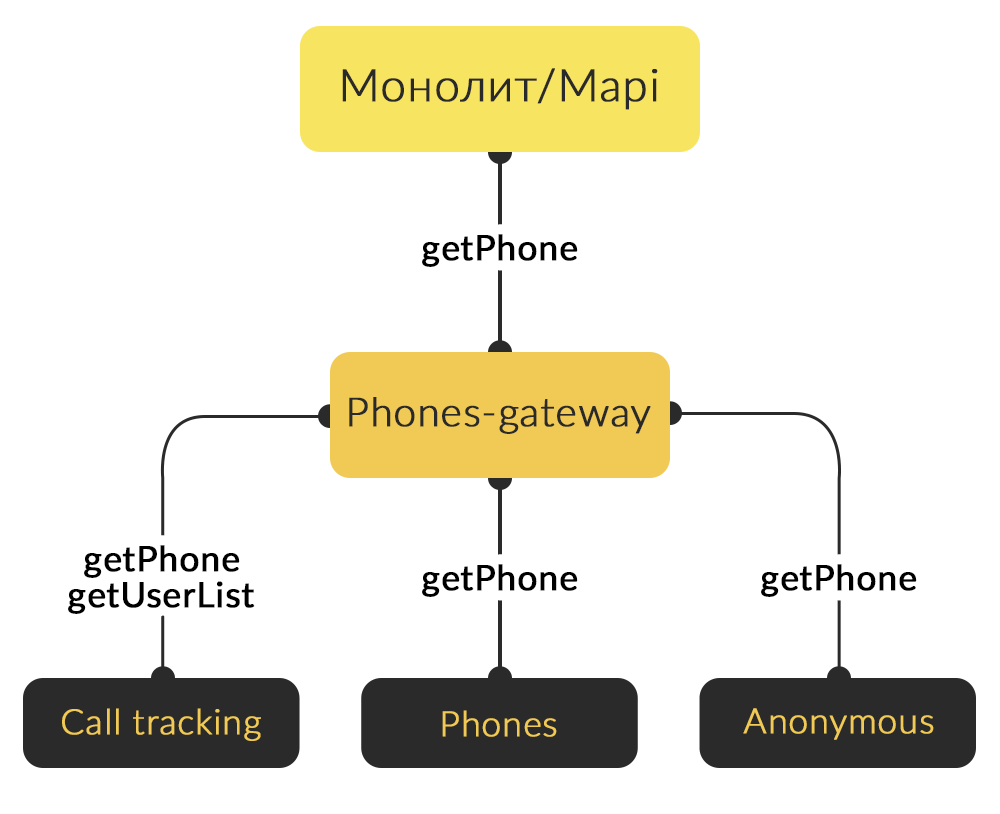
Для анонимных номеров там просто есть проверка на то, подключен анонимный номер или нет, доступна ли категория для анонимного номера. А для call tracking нам нужно знать, у каких пользователей он включен. Поэтому мы решили сохранять в памяти сервиса список людей, у которых включен call tracking, и обновлять этот список при помощи ручки.
И дальше возникает вопрос: что выбрать, чтобы организовать хранение таких статусов в памяти? На тот момент, когда мы делали сервис, на входе задачи было 12 000 статусов и прогноз, что их количество вырастет максимум в десять раз. Нам нужно было посчитать, что будет эффективным для хранения — массив (AKA slice) или map.
Реализация хранения статусов
Для начала накидаем реализации.
Array cache. Первая реализация кэша — через массив, то есть добавление через append и проверка на наличие в цикле. Потом вставка элементов.
type ArrayCache struct {
cache []int64
}
func (c *ArrayCache) Add(userId int64) {
c.cache = append(c.cache, userId)
}
func (c *ArrayCache) Has(userId int64) bool {
for _, innerUserId := range c.cache {
if innerUserId == userId {
return true
}
}
return false
}
ApplyItems необходим для синхронизации: мы дёргаем ручку в сервисе, и он нам возвращает, какие статусы были добавлены, то есть у каких пользователей статус включен, а у каких — выключен. Дальше нам нужно сохранить эти изменения в кэш. И удаление, в котором мы тоже просто перебираем статусы, пока не находим и удаляем.
func (c *ArrayCache) ApplyItems(items map[int64]int64) {
for userId, status := range items {
if c.Has(userId) && status == 6 {
c.Delete(userId)
}
if !c.Has(userId) {
c.Add(userId)
}
}
}
func (c *ArrayCache) Delete(userId int64) bool {
for i, userIdInternal := range c.cache {
if userIdInternal == userId {
c.cache[i] = c.cache[len(c.cache)-1]
c.cache[len(c.cache)-1] = 0
c.cache = c.cache[:len(c.cache)-1]
return true
}
}
return false
}
Map cache. И аналогично реализуем для map. Добавление, проверка на наличие, вставка в результате синхронизации и удаление.
type MapCache struct {
cache map[int64]int64
}
func NewMapCache() *MapCache {
return &MapCache{cache: make(map[int64]int64)}
}
func (c *MapCache) Add(userId, status int64) {
c.cache[userId] = status
}
func (c *MapCache) Has(userId int64) bool {
val, ok := c.cache[userId]
if !ok {
return false
}
if val == 6 {
return true
}
return false
}
func (c *MapCache) ApplyItems(items map[int64]int64) {
for userId, status := range items {
c.cache[userId] = status
}
}
func (c *MapCache) Delete(userId int64) {
delete(c.cache, userId)
}
Бенчмарки
Определить, какая реализация хранения статуса в call tracking эффективнее, нам помогут бенчмарки. В Go бенчмарки — это методы, которые позволяют проверить производительность определённых функций. Что самое приятное, они встроены прямо в язык. Вызвать бенчмарк можно, например, при помощи:
go test -benchОни нужны, чтобы:
- Сравнить производительность различных решений в коде.
- Сравнить между собой производительность библиотек и выбрать лучшую.
- Посчитать, сколько ресурсов и памяти нужно для работы той или иной функциональности или сервиса.
Давайте напишем бенчмарк на наши методы. В Go бенчмарки пишутся, как правило, рядом с тестами. Для того, чтобы Go знал, как их найти и запустить, функции бенчмарков должны иметь имя, которое начинается со слова Benchmark, и они всегда должны принимать *testing.B. Здесь у нас бенчмарк для вставки в массив и бенчмарк для проверки статуса в кэше-массиве:
func BenchmarkArrayInsert(b *testing.B) {
cache := ArrayCache{}
statuses := GenerateStatuses(0, 12000)
cache.ApplyItems(statuses)
b.ResetTimer()
for i := 0; i < b.N; i++ {
statuses := GenerateStatuses(int64(rand.Intn(i + 1) * 6000000), 1)
cache.ApplyItems(statuses)
}
}
func BenchmarkArray_Has(b *testing.B) {
cache := ArrayCache{}
statuses := GenerateStatuses(0, 12000)
cache.ApplyItems(statuses)
b.ResetTimer()
for i := 0; i < b.N; i++ {
cache.Has(int64(i))
}
}
Внутри бенчмарка мы генерируем статусы. Статус выбирается рандомно, соответственно, включен он или выключен — это просто число. Мы генерим 12 000 статусов, как и будет на проде, и записываем их в кэш.
Дальше идёт сам бенчмарк. Перед его запуском обязательно надо вызвать ResetTimer, так как какое-то время мы потратим на то, чтобы заполнить кэш. Бенчмарк выполняется в цикле до b.N, где b.N — это число итераций, которые Go регулирует самостоятельно.
Также напишем бенчмарк для заполнения кэша элементами. Внутри бенчмарка мы случайным образом генерируем десять изменившихся элементов и вставляем их в кэш.
func BenchmarkArray_ApplyItems(b *testing.B) {
cache := ArrayCache{}
statuses := GenerateStatuses(0, 12000)
cache.NewApplyItems(statuses)
b.ResetTimer()
for i := 0; i < b.N; i++ {
st := GenStatuses(10)
cache.NewApplyItems(st)
}
}
И запускаем бенчмарк при помощи команды go test -bench. Для запуска в качестве параметра bench указываем название бенчмарка:
go test -bench=. ./...Здесь мы указали точку, т.е. нужно запустить все имеющиеся в папке бенчмарки.
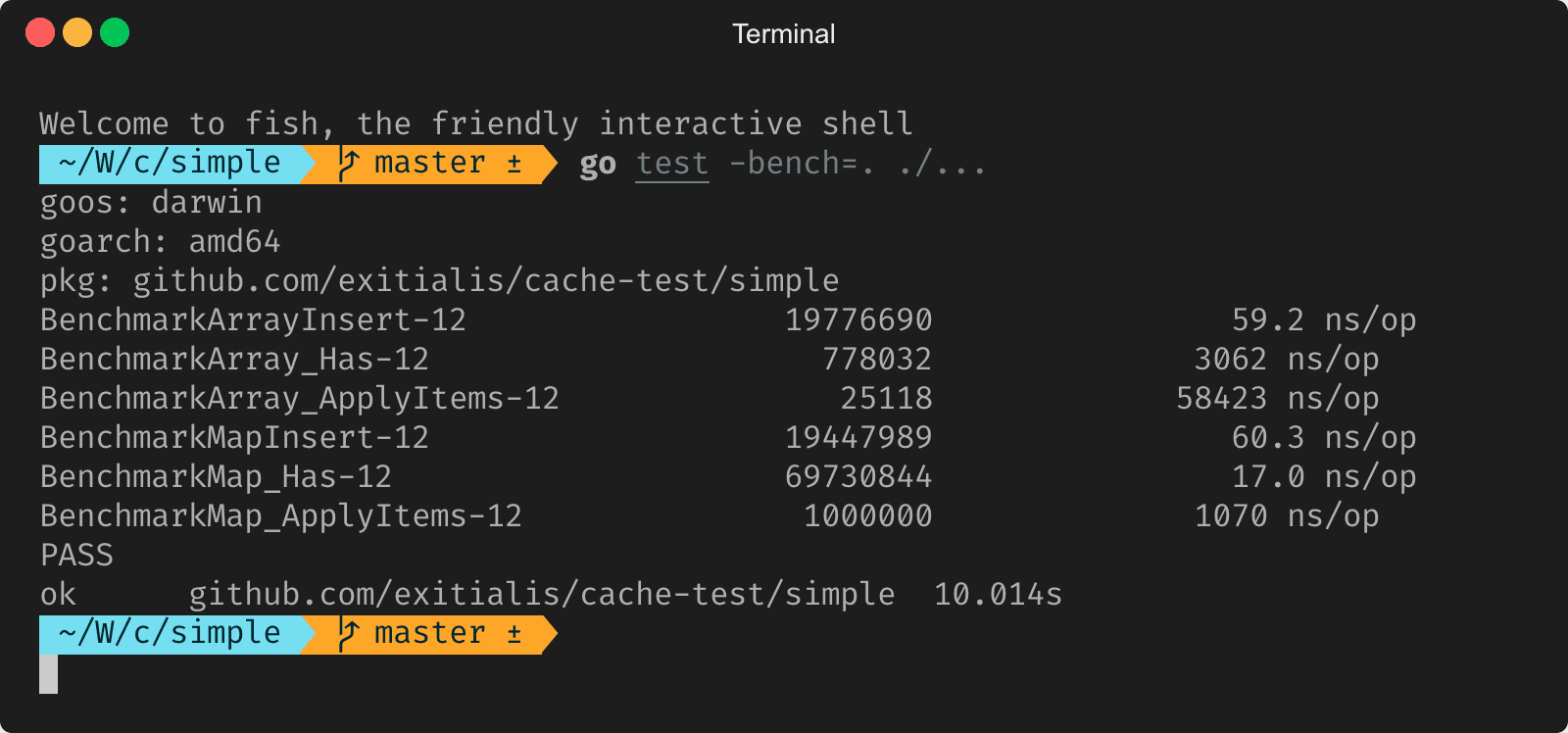
Все бенчмарки прошли, и мы видим, что для массива скорость вставки чуть больше, чем для map. Это и понятно, потому что для вставки map нужно рассчитать хэш, но всё равно, разница совсем мала, буквально наносекунда. Но при этом массив сильно проигрывает в поиске элемента. В общем-то, это тоже понятно, потому что map имеет константное время для поиска. Но массив также очень сильно проигрывает в замене элементов.
Давайте попробуем узнать, есть ли какая-то разница по выделяемой памяти для работы этих хэшей. Для этого в Go есть встроенная функциональность в бенчмарке — флаг bencmem:
go test -bench=. ./... -benchmem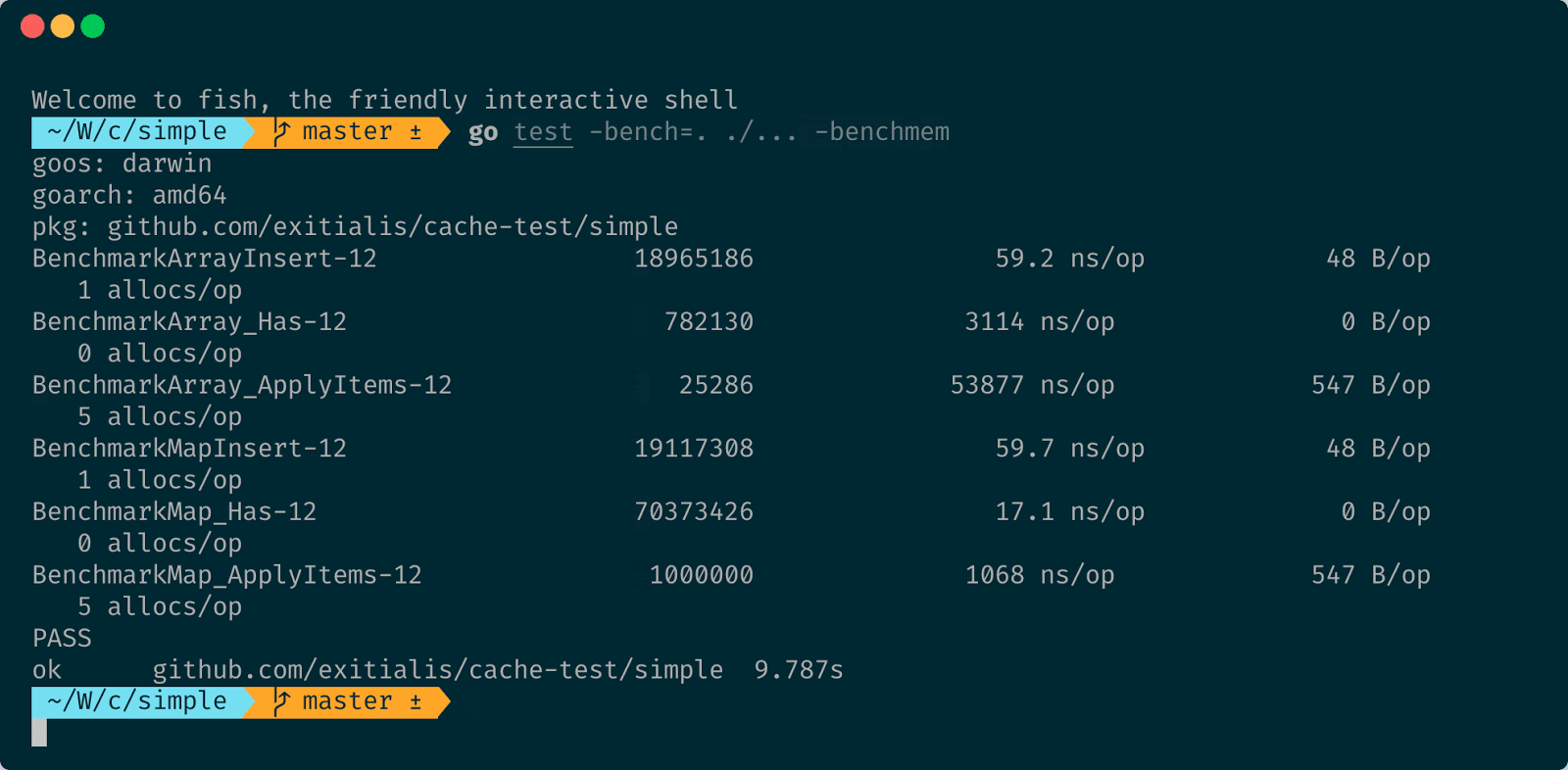
Теперь помимо информации, сколько времени занимает одна операция, мы видим, сколько памяти было выделено в рамках одного цикла бенчмарка, то есть вызова функции, и также видим, сколько аллокаций в этот момент было вызвано. Для вставки у нас выделяется 48 байт памяти на одну операцию и одна аллокация. Для замены выделяется пять аллокаций и 547 байт памяти. Но и для map эти значения в принципе одинаковые. Причём стоит отметить, что здесь учитывается только то, что выделяется в Heap. А то, что выделяется на стеке, никак не учитывается.
Утилиты pprof и benchcmp
Где конкретно происходит выделение памяти, почему операций по её выделению так много для замены элементов и возможно ли это как-то оптимизировать? Ответить на всё эти вопросы поможет утилита pprof.
Pprof — утилита для профилирования программ на Go. Она позволяет узнать, какие функции сколько процессорного времени потратили, где и сколько памяти было выделено, посмотреть, что делала каждая горутина, сколько всего было горутин и так далее. Довольно универсальный инструмент.
Pprof является семплирующим профайлером. Он с какой-то периодичностью прерывает работу программы, берёт стек-трейс, сохраняет его, и в конце на основе того, как часто в стек-трейсах встречается та или иная функция, рассчитывает, сколько времени было потрачено на каждую функцию.
Давайте соберём профиль с наших бенчмарков. Для этого нужно указать флаг cpuprofile и путь до файлов, в которые мы хотим сохранить профиль:
go test -bench=. ./... -cpuprofile=cpu.profileИ важный момент: здесь я указал именно один бенчмарк, чтобы посмотреть профиль для массива и что там вообще происходит.
Но теперь остаётся вопрос, что нам делать с этим файлом профиля и как его просмотреть. Для этого есть команда
go tool pprofВ ней надо указать файл в качестве аргумента. Запустится интерактивный режим, в котором есть несколько полезных команд.
При помощи команды top N можно посмотреть топ-N мест по затратам производительности. И здесь мы видим, что 50% времени было затрачено на проверку наличия элементов в массиве. Это достаточно долго. И почему-то в ApplyItems у нас именно 50% времени занял поиск.
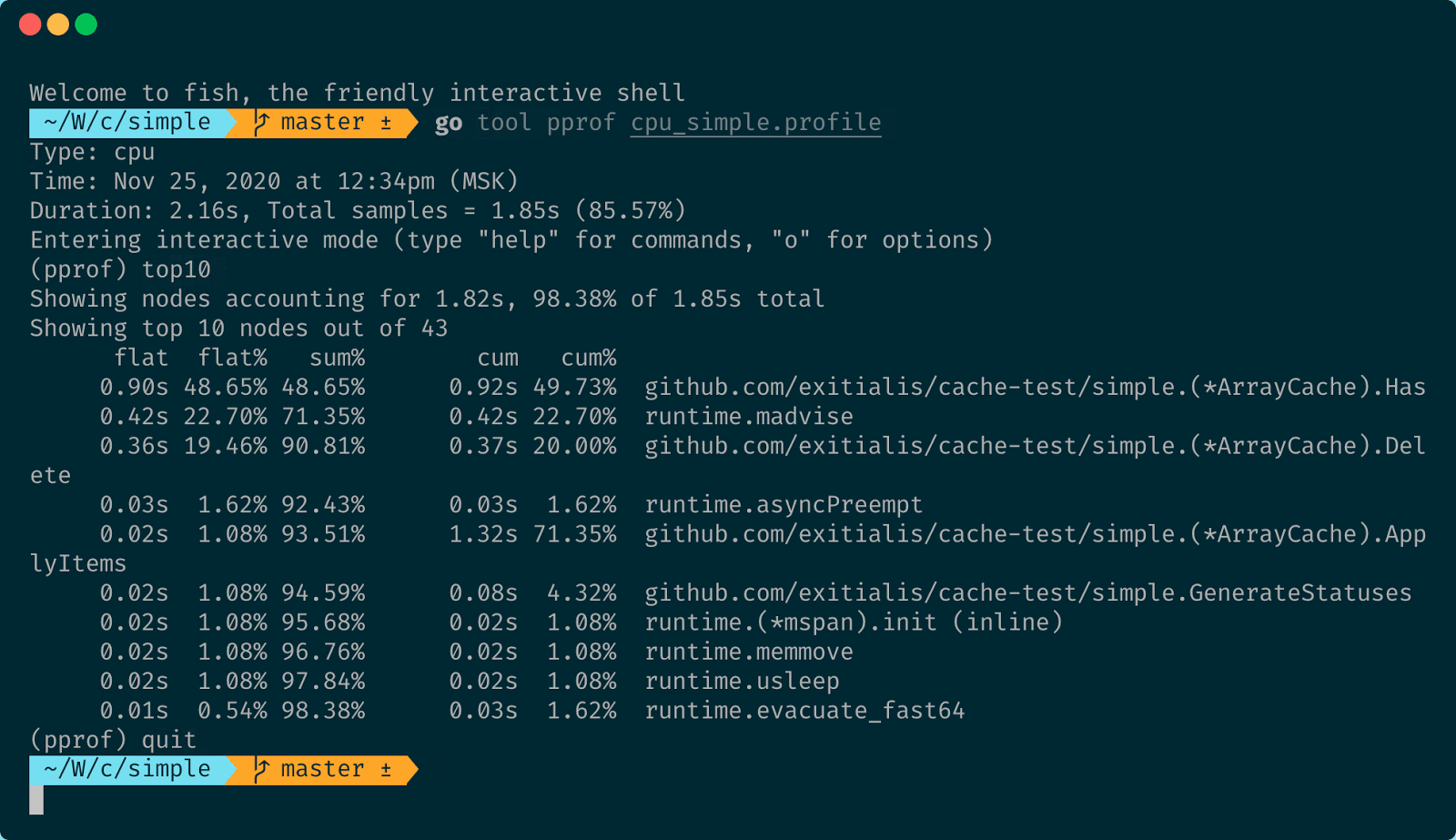
Давайте посмотрим глубже. В этом поможет команда list интерактивного режима pprof. После ввода list мы указываем название метода, который хотели бы просмотреть, и Go прямо показывает в коде, сколько времени было затрачено на какой строке.
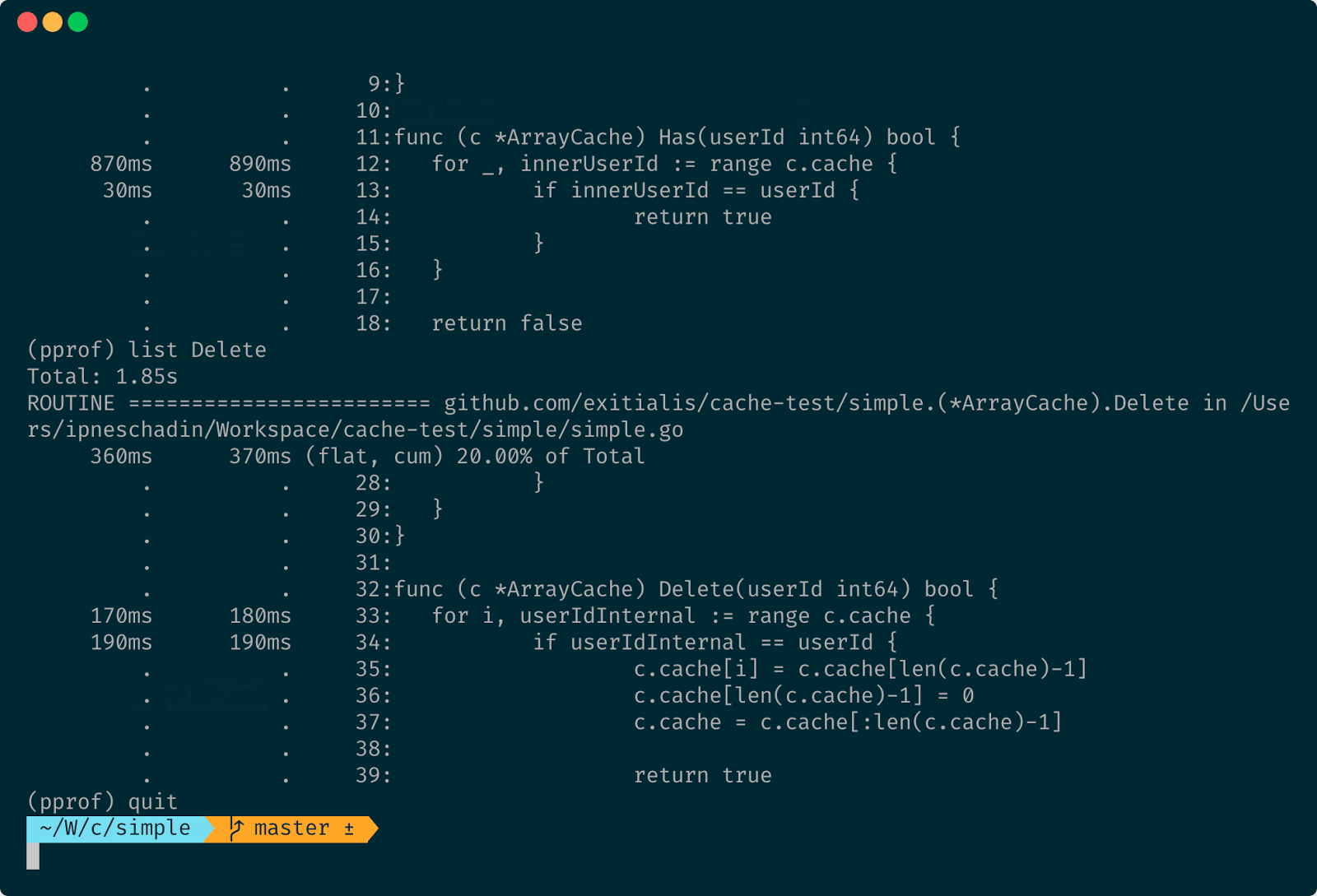
Суммарно за все бенчмарки для функции Has на цикл было потрачено 890 миллисекунд. То есть циклы достаточно быстро работают, и точно не почти секунду для 12 000 элементов. На проверки было потрачено 30 миллисекунд. Тут я ещё проверил Delete. Видно, что 180 миллисекунд затрачено на перебор и 190 миллисекунд на проверки.
Пойдём дальше, потому что пока мы ничего не нашли. Непонятно, в чём конкретно проблема, есть ли она вообще. Попробуем выполнить list для функции ApplyItems, которую проверяем.
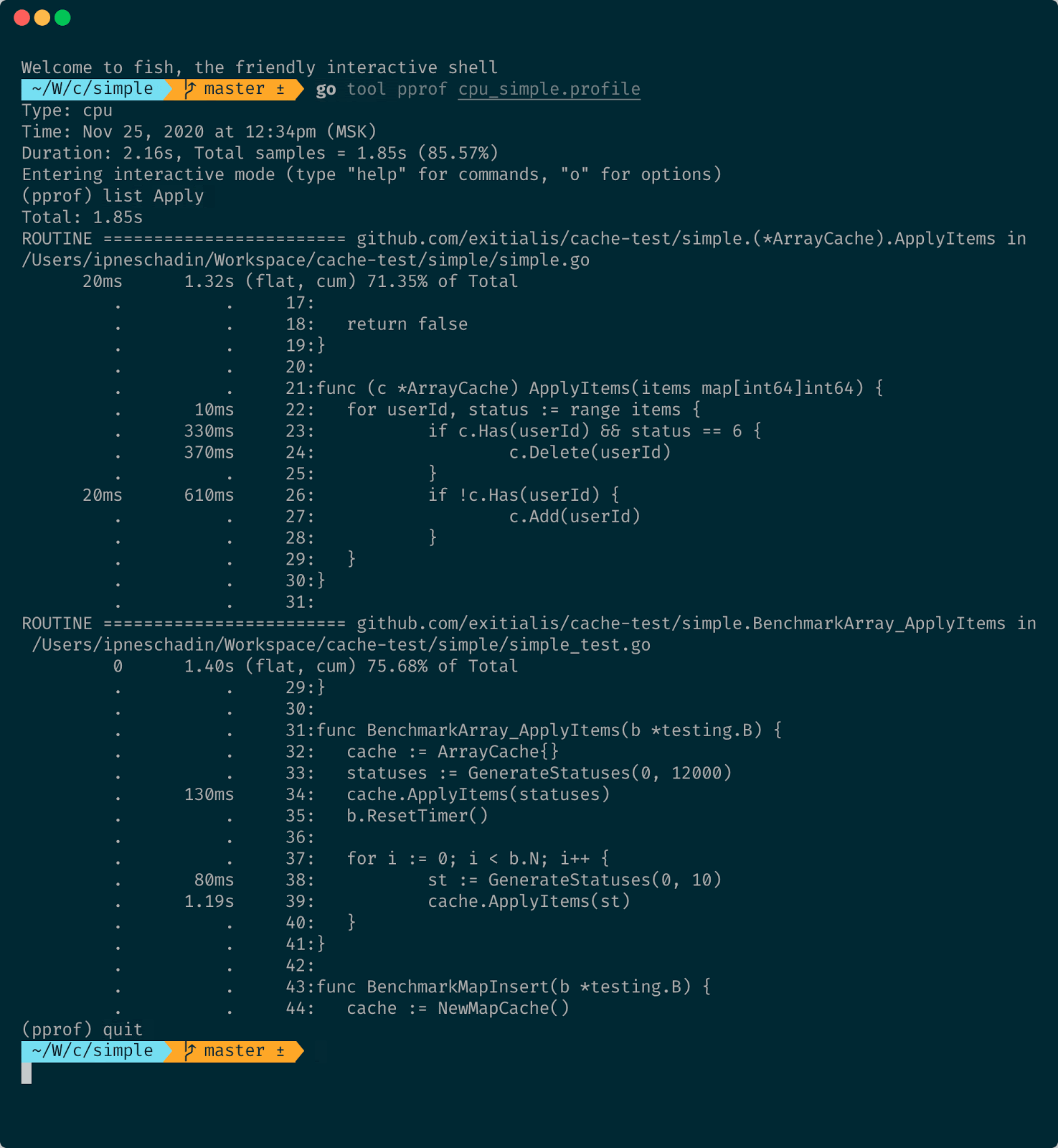
На проверку Has потрачено 330 миллисекунд, потом 370 миллисекунд на удаление, и потом 610 миллисекунд на проверку отсутствия элементов. То есть мы второй раз в цикле пробегаем все элементы, и это не очень хорошо. Попробуем что-нибудь переписать в реализации, чтобы убрать лишний вызов.
Теперь мы будем искать элемент в массиве один раз. Если не нашли, будем добавлять, а если нашли и статус означает, что call tracking выключен, будем удалять.
func (c *ArrayCache) ApplyItems(items map[int64]int64) {
for userId, status := range items {
if c.Has(userId) {
if status == 6 {
c.Delete(userId)
}
} else {
c.Add(userId)
}
}
}
Посмотрим, как изменилась производительность. Для этого есть утилита benchcmp. Мы можем сохранить вывод бенчмарков в файл, и потом при помощи данной утилиты сравнить результаты. Она в удобном виде покажет, что изменилось.
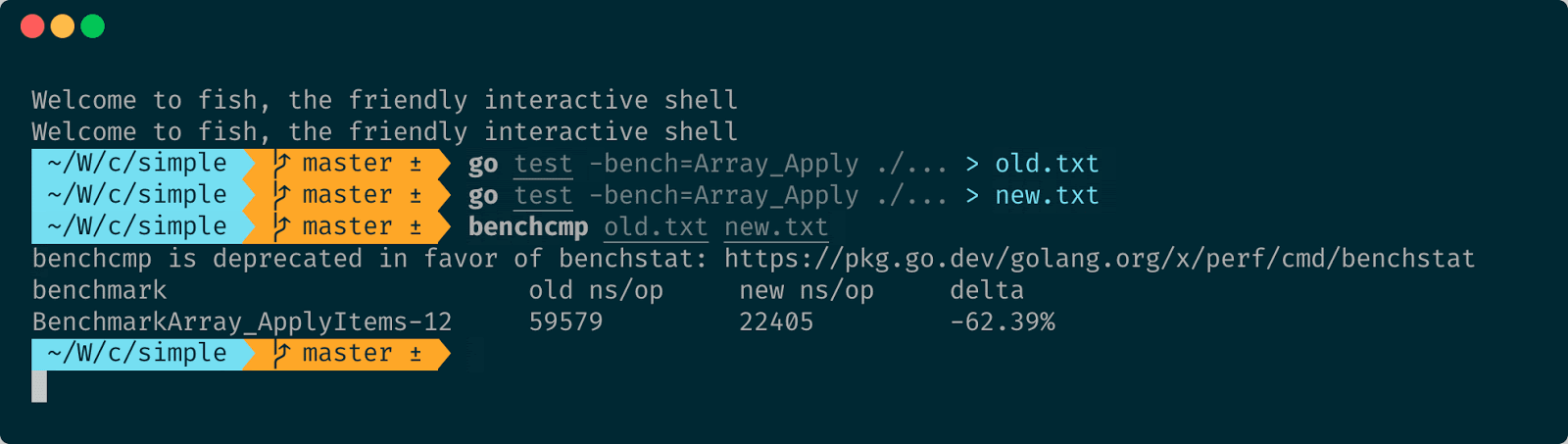
Своим нехитрым изменением мы выиграли примерно 60% производительности, что в принципе очень даже неплохо. То есть pprof помог оптимизировать массив. Запустим бенчмарк ещё раз и посмотрим, изменилось ли что-то, и можем ли мы использовать теперь массив для решения задачи по хранению статусов.
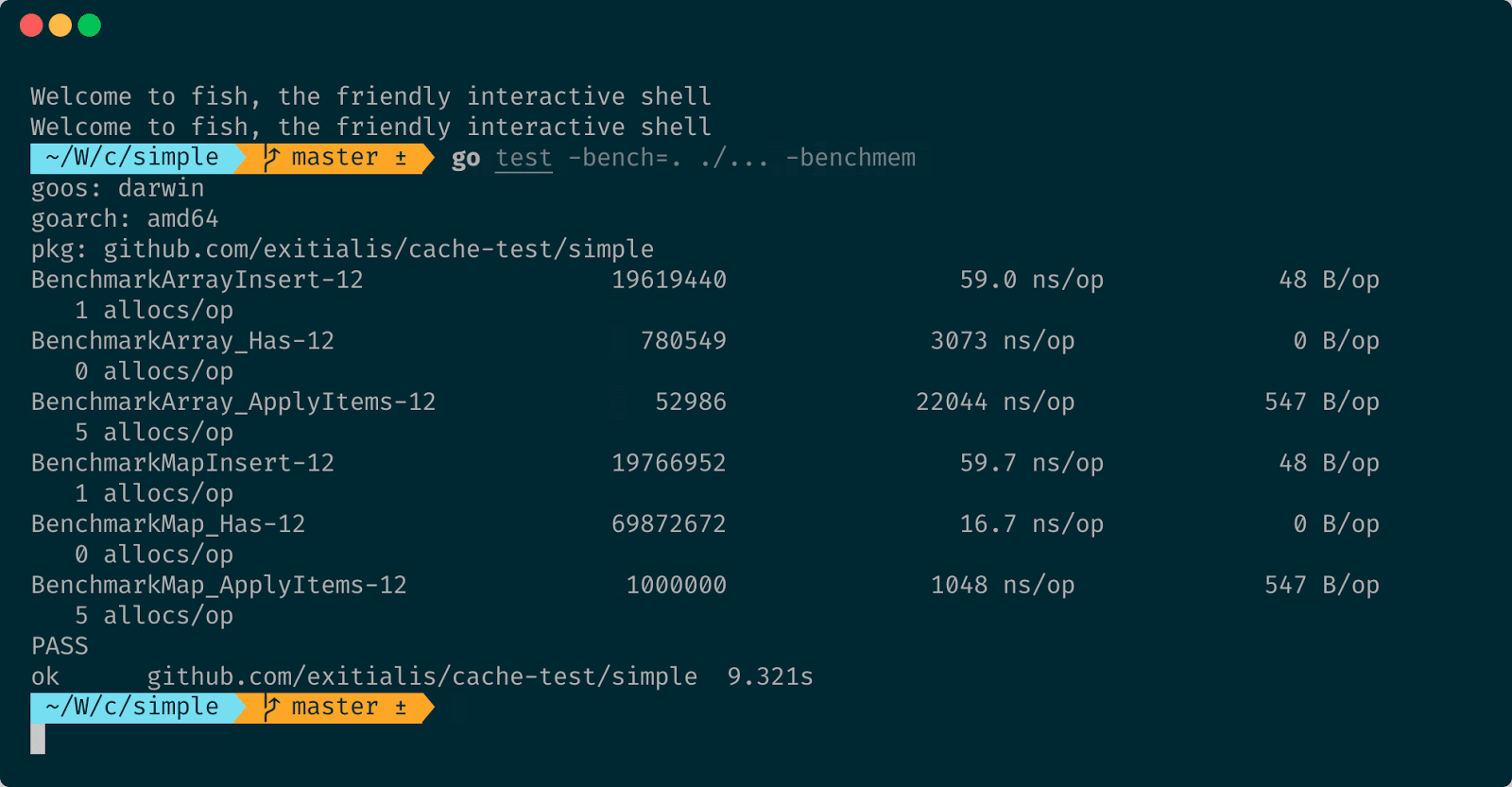
Замена действительно стала значительно быстрее. Но по остальным задачам map всё равно продолжает выигрывать. И вроде как оптимизировать-то особо и нечего. Поэтому по производительности для нашей задачи побеждает кэш написанный с использованием map.
А теперь давайте проверим всё-таки насчёт аллокаций, может быть по памяти map проигрывает. Для этого воспользуемся флагом -benchmem и укажем там путь до профиля памяти. И потом при помощи pprof просмотрим этот профиль, топ-10 по потреблению, и где и сколько памяти было выделено.
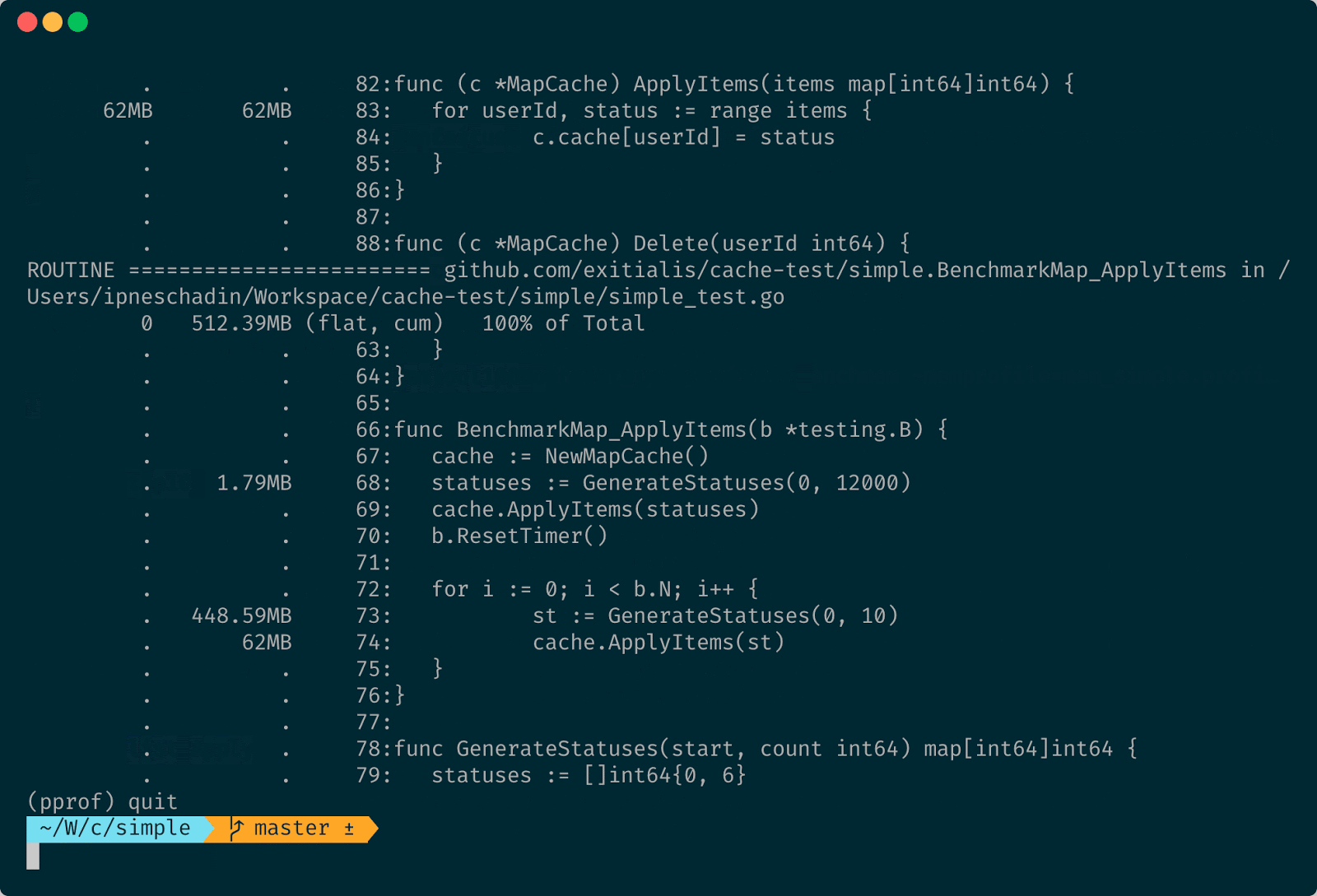
Больше всего памяти выделяется внутри бенчмарка в момент генерации статусов, но это и понятно, потому что мы огромное количество раз генерируем map из десяти элементов. Но сама map потребляет не так много. Для нашей продовой задачи это вполне подходит. Поэтому берём map.
По результатам бенчмарков мы узнали, что:
- Для 12 000 элементов map имеет преимущество на чтение перед массивом примерно в 100 раз.
- Map занимает в Heap менее двух мегабайт памяти для хранения нужных нам данных.
- Благодаря инструментам профилирования и небольшому изменению кода нам удалось выиграть 60% производительности, и всё продолжает работать, как требуется.
Оптимизация сервиса
Перейдём к более сложным примерам. Мы выбрали кэш, дописали код и задеплоили сервис. Всё хорошо, всё работает. Теперь зайдём на страницу с графиками:
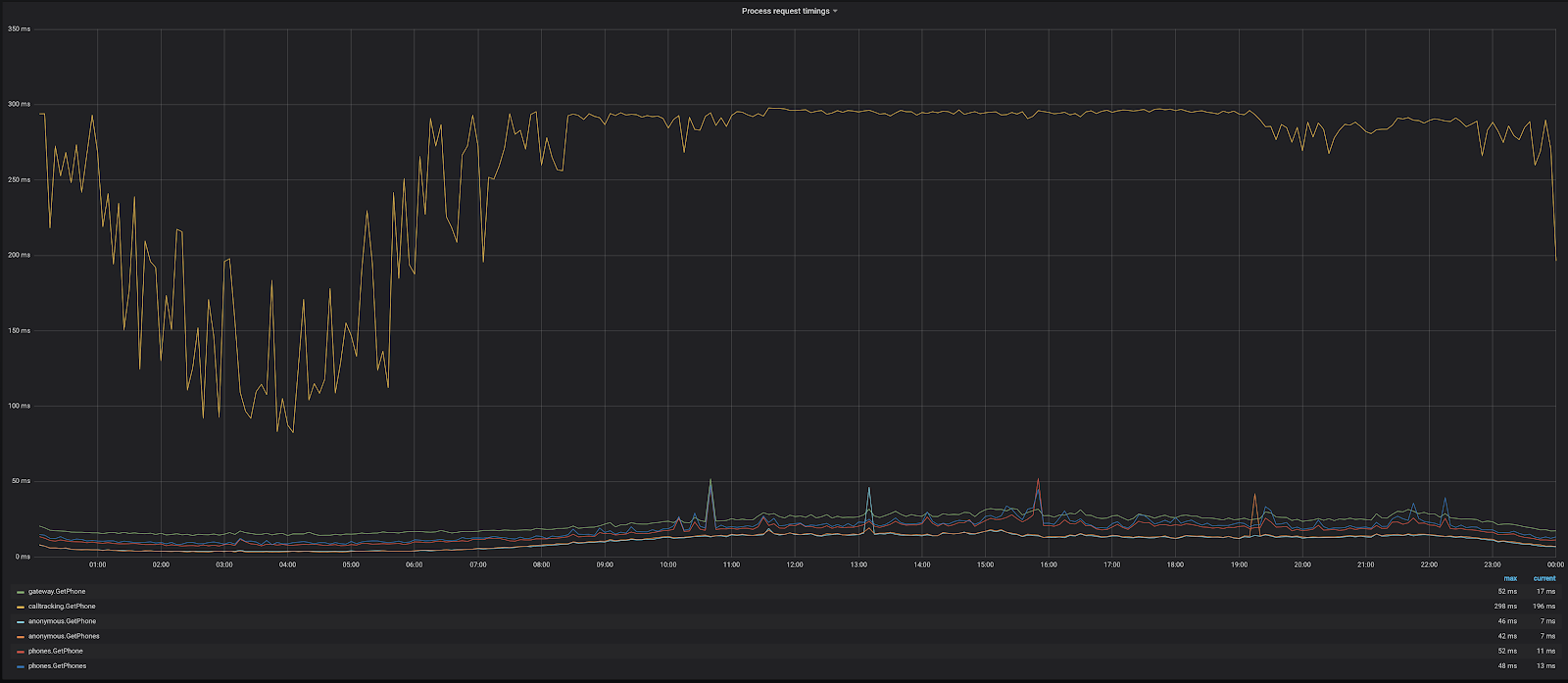
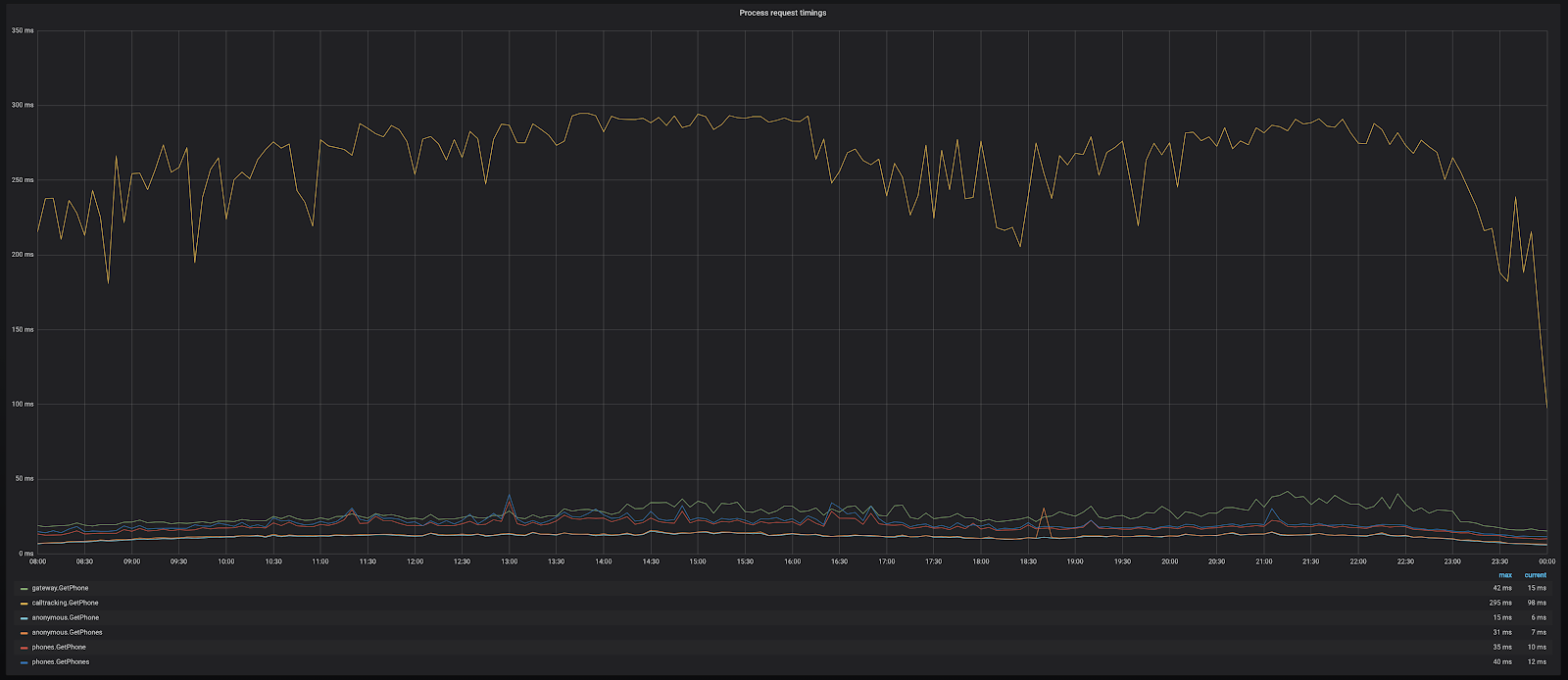
Запросы в один из сервисов очень медленные, особенно по сравнению с остальными. У них практически постоянно время ответа держится в пределах 300 миллисекунд при том, что 300 миллисекунд — предел для тайм-аута. В результате сервис генерирует большое количество ошибок тайм-аутов. Что мы можем здесь оптимизировать?
Первое, что приходит в голову, — добавить кэш для того, чтобы не ходить лишний раз в сервис. То есть мы запросили номер один раз, сохранили его в памяти, и в следующий раз, когда у нас запросят номер, не пойдём в сервис, а отдадим его сразу из памяти.
Для этого отлично подходит LRU-кэш. Это такой вид кэша, когда есть ограниченное количество элементов, и новые значения вытесняют старые. Причём, если мы обращаемся к элементу часто, то он поднимается наверх и не вытесняется из кэша. Таким образом мы закэшируем все часто используемые значения, а все редко используемые не будут храниться в кэше.
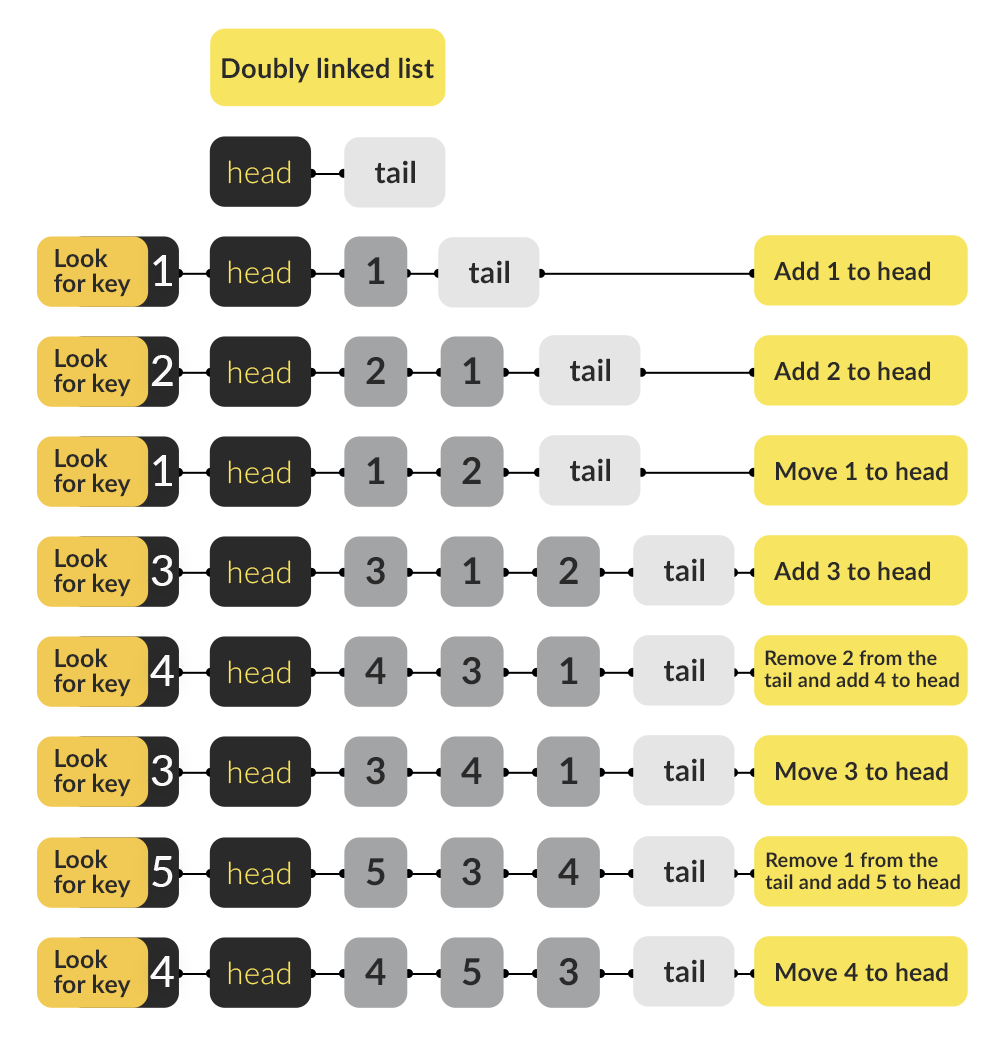
Напишем реализацию такого кэша.
func (c *Cache) GetCalltracking(phones []RealPhone) (phonesInCache map[RealPhone]VirtualPhone, phonesNotFoundInCache []RealPhone) {
phonesInCache = make(map[RealPhone]VirtualPhone, len(phones))
phonesNotFoundInCache = make([]RealPhone, 0, len(phones))
if !config.calltracking.enabled {
phonesNotFoundInCache = phones
return
}
for _, realPhone := range phones {
value, err := c.calltracking.Get(realPhone)
if err == nil {
phonesInCache[realPhone] = value.(VirtualPhone)
continue
}
phonesNotFoundInCache = append(phonesNotFoundInCache, realPhone)
}
return
}
func (c *Cache) SetCalltracking(realPhone RealPhone, virtualPhone VirtualPhone) error {
if config.calltracking.enabled {
return c.calltracking.SetWithExpire(realPhone, virtualPhone, config.calltracking.ttl)
return c.calltracking.Set(realPhone, virtualPhone)
}
return nil
}По умолчанию мы сохраняем номер телефона в кэш на 15 минут, так как номера call tracking могут меняться в течение дня. Для кэширования взяли библиотеку LRU GCache. Тип RealPhone — это обычный string, только с некоторыми проверками, как и VirtualPhone. Этот кэш — что-то вроде map с ключом в виде телефона и значением в виде другого телефона. Мы сохраняем соответствие реального номера телефона пользователя номеру call tracking.
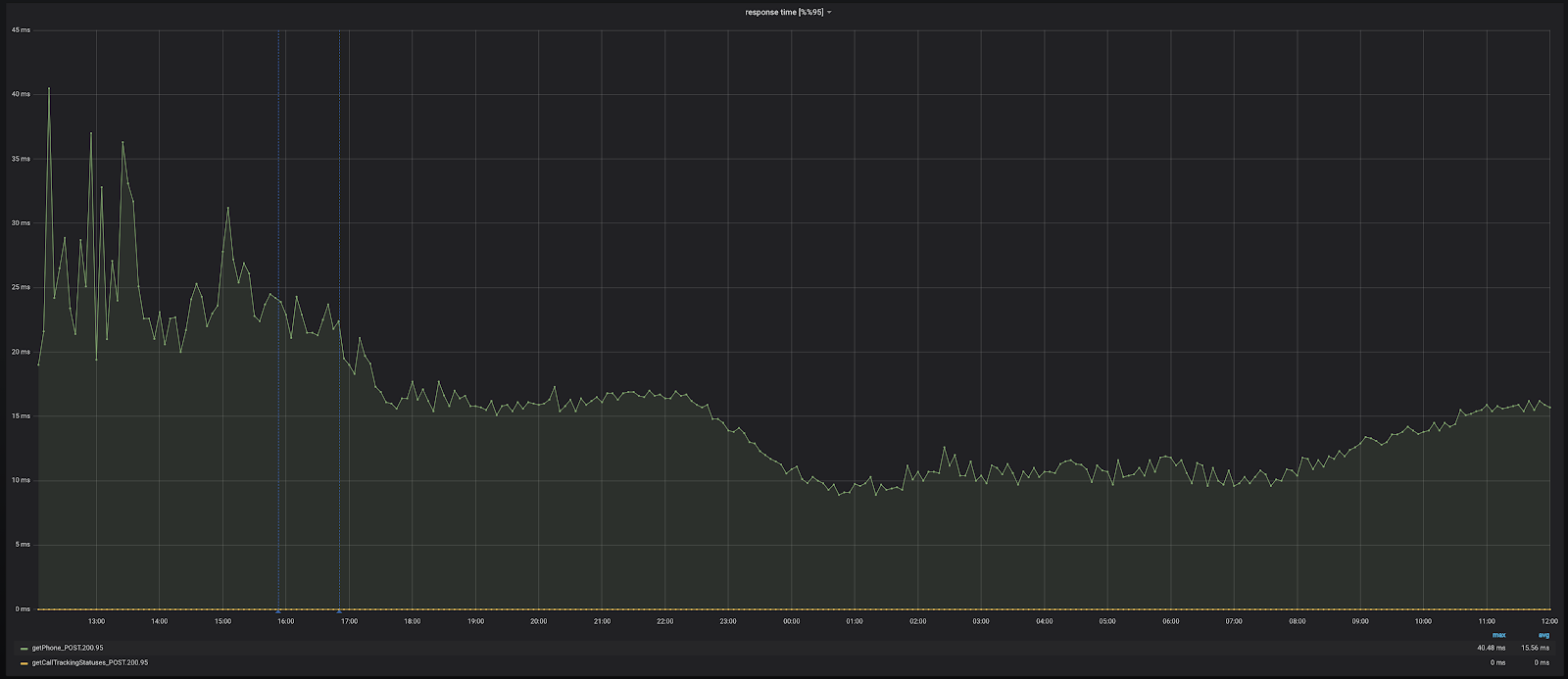
Выкатываем кэш, и видим, что производительность стала получше. Не то чтобы очень сильно, но response time снизился. Число ошибок тоже уменьшилось, больше нет постоянной полочки.
После такого успешного исправления закономерно возникает мысль: а почему бы не добавить кэш для реальных номеров телефонов? Это поможет ещё быстрее отвечать пользователям. Добавляем такой же кэш с аналогичным кодом и видим, что производительность стала лучше. Нам удалось выиграть порядка 10 миллисекунд, и теперь пользователи в 95% случаев получают номер меньше, чем за 20 миллисекунд.
Выдыхаем. Идём пить чай, отдыхать и спать. На следующее утро просыпаемся, заходим в графики, и что видим?
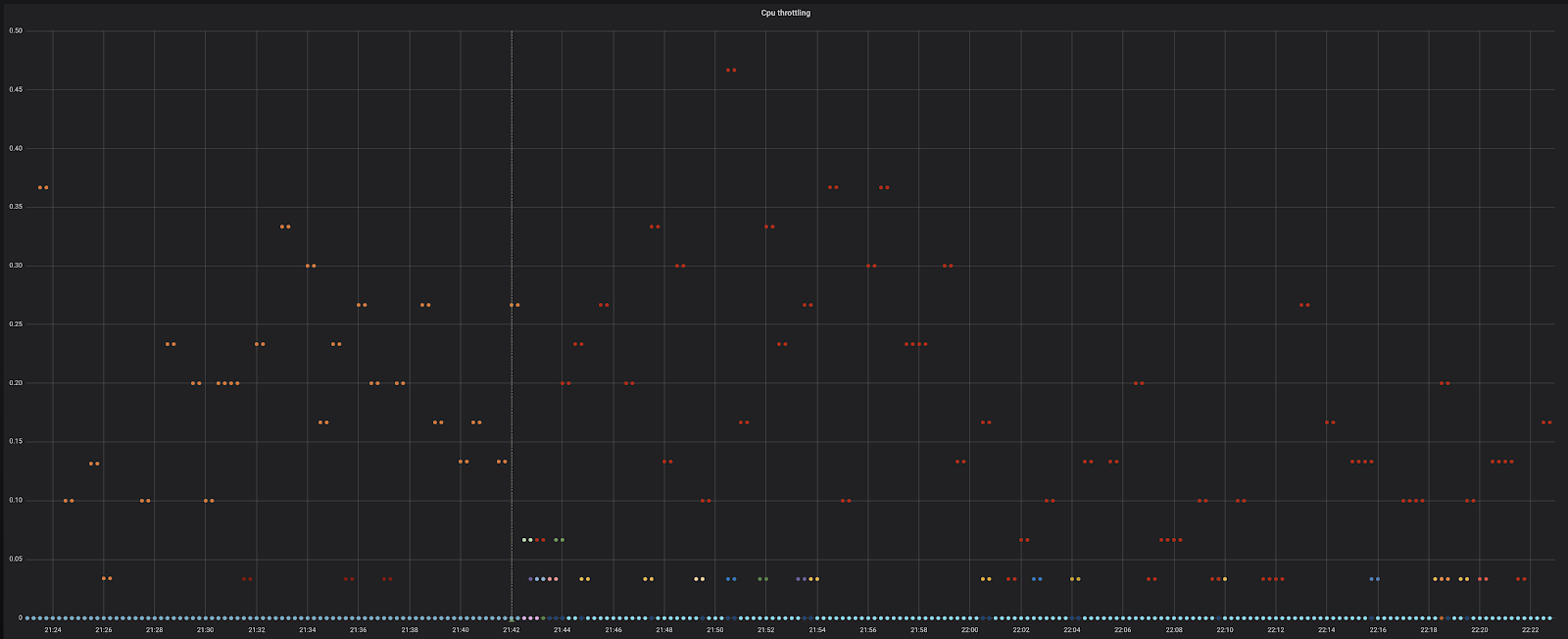
У нас начал дико тротлить CPU. Это нехорошо, надо понять, почему так происходит.
Для начала разберёмся, что такое троттлинг и CPU в терминах Kubernetes. Когда мы запрашиваем один CPU в Kubernetes, это не значит, что нам выделяется конкретно одно ядро процессора из 48, например. Это означает, что нашему контейнеру будет выделено время работы CPU, равное времени одного ядра.
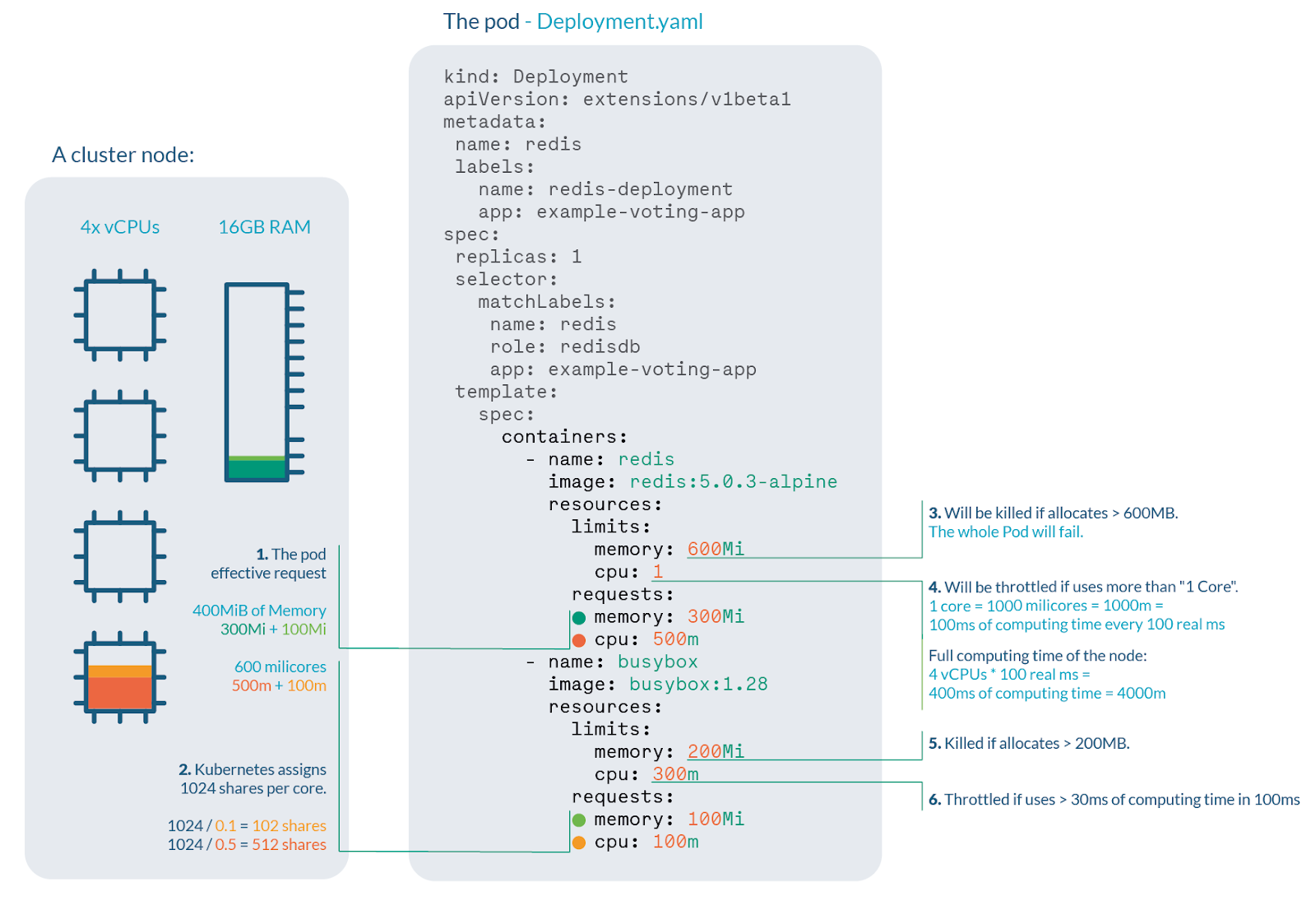
В терминах Kubernetes одно ядро — это тысяча миллиядер. Каждые 100 ms планировщик Kubernetes замеряет, сколько процессорного времени потратил pod. 1000 m — в рамках 100 ms pod’у будет доступно полностью время выполнения на одном ядре процессора.
Когда мы запрашиваем один CPU, мы, грубо говоря, запрашиваем одну секунду работы с процессором. Если контейнер не будет успевать за эту одну секунду выполнять нужные ему задачи, Kubernetes ограничит ему доступ к CPU. То есть планировщик Kubernetes будет переключать задачу на другие pod’ы, и наш pod будет ждать, чтобы доделать нужные ему вычисления.
Для нашего pod было выделено по умолчанию 2 CPU. То есть две секунды времени. И Throttling 0,8 означает, что он в эти две секунды не укладывается, то есть ему нужно около 3 секунд или же почти 3 CPU. Почему это происходит? Давайте разбираться дальше.
Для этого у нас есть та же утилита pprof. В Авито она подключена по умолчанию во всех Go-приложениях, работающих на нашем PaaS. При помощи команды
go tool pprof "http://${POD_IP}:3366/debug/pprof/profile?seconds=10"мы получим профиль нашего сервиса. Pod IP мы можем узнать в Kubernetes дашборде.
У нас запустится интерактивный режим, в которым мы выполняем команду web для этого профиля, и у нас открывается svg-картинка в браузере. И так как я молодец и не сохранил профили, которые собирал ещё летом, мне пришлось всё это воспроизводить. Поэтому в некоторых местах придётся поверить мне на слово. Но я сделал тестовый pod, накатил его в тестовый кластер Kubernetes и буду обстреливать этот pod при помощи утилиты Apache Benchmark, и параллельно снимать профиль.
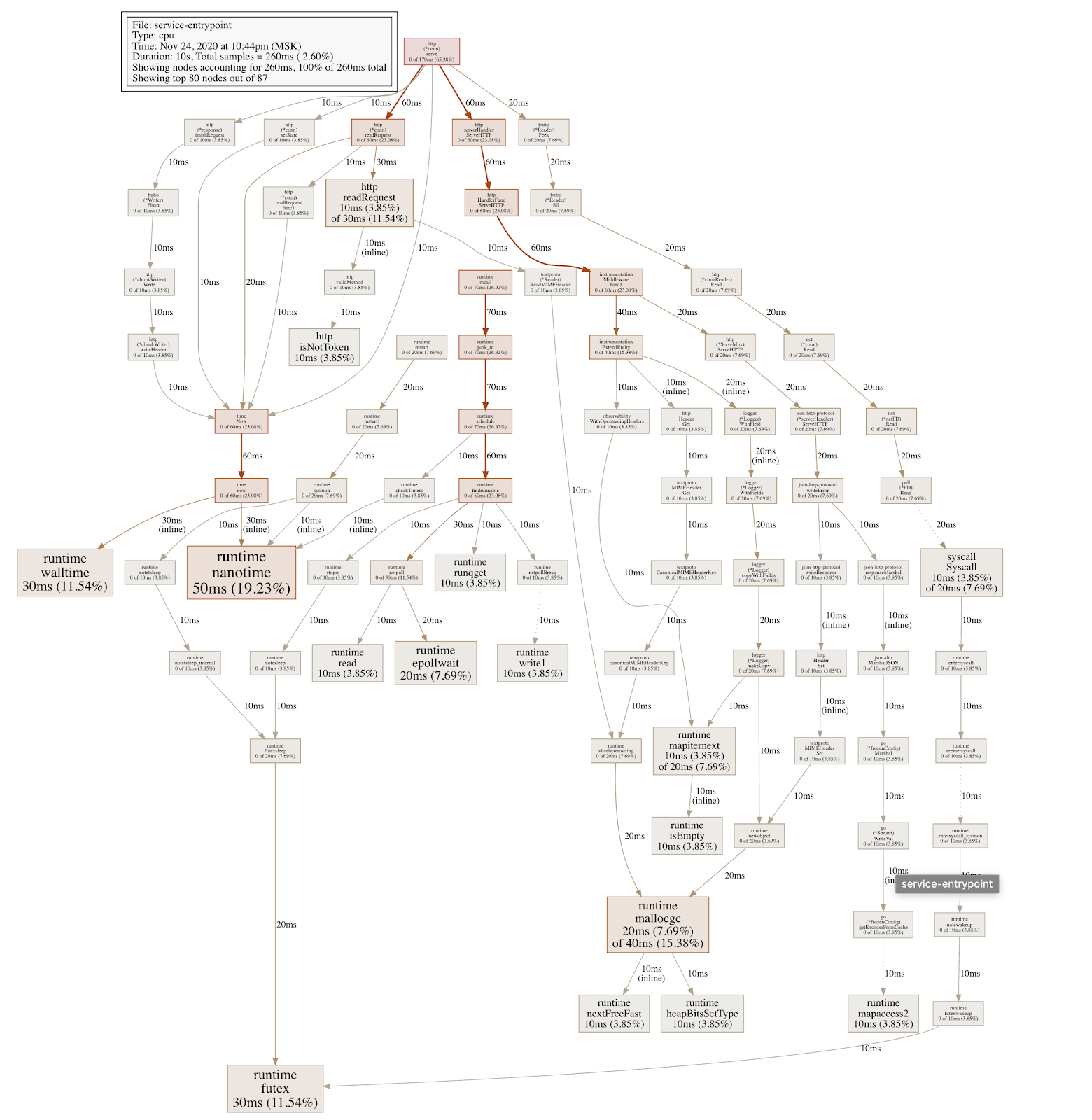
Каждый прямоугольник в снятом профиле — это работа определённой функции. И чем больше прямоугольник по размеру, тем больше времени заняло выполнение функции. Стрелками указывается порядок вызова. Чем толще стрелка, тем больше было времени потрачено на ветку вызова.
Сразу можно заметить, что у нас много вызовов runtime.nanoTime, которые, в свою очередь, вызываются из time.Now. И time.Now тоже вызывается довольно часто. Ещё мы видим вызовы runtime.mallocgc и другие. Если посмотрим внутрь runtime у Go, то увидим, что эти функции вызываются в сборке мусора.
Давайте теперь выполним команду чтобы узнать количество памяти выделенной в heap:
go tool pprof "http://${POD_IP}:3366/debug/pprof/heap?seconds=10"Так мы получим количество памяти, выделенной в куче.
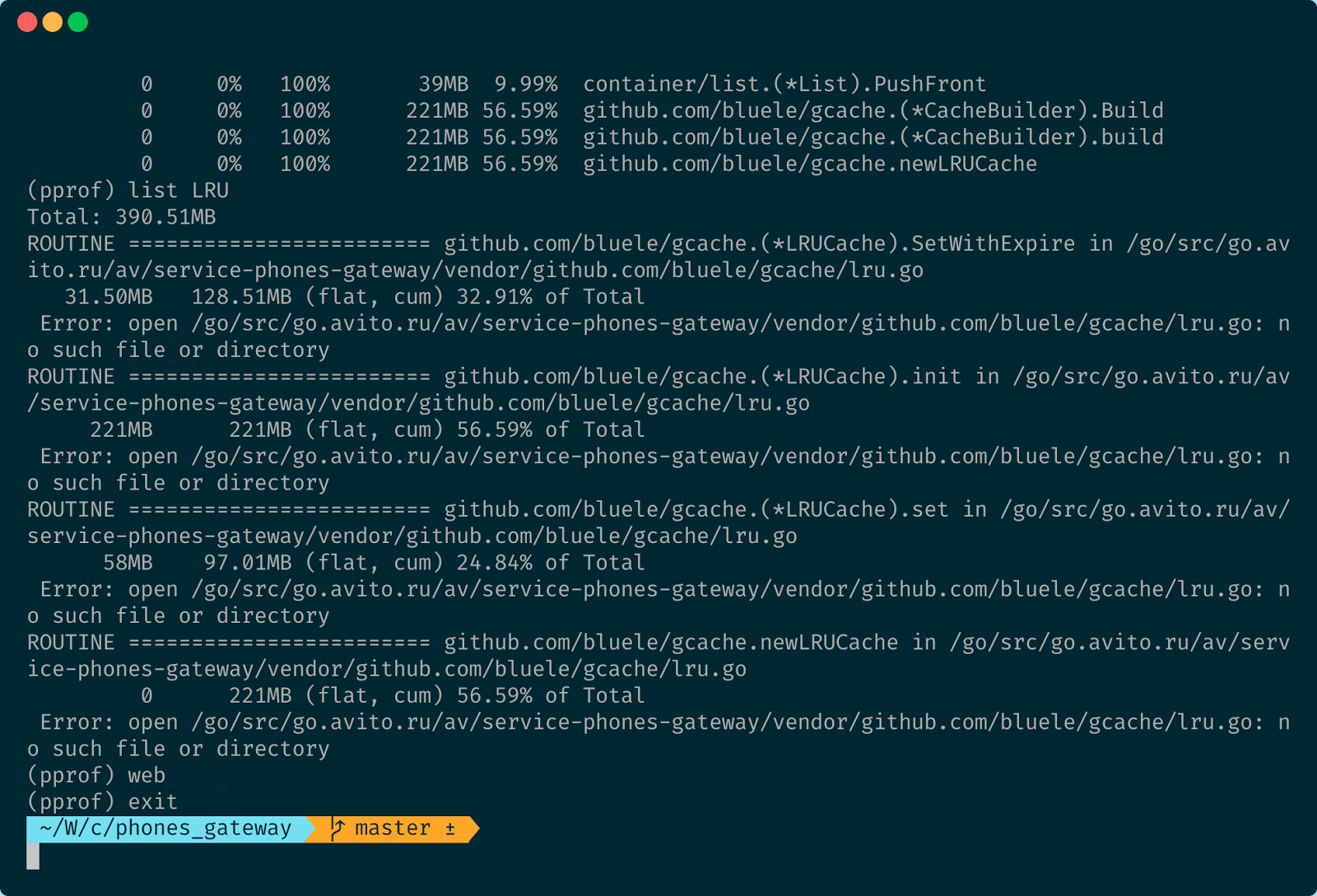
По названиям понятно, что большая часть памяти выделяется где-то внутри SetWithExpire. Функции библиотеки работают с кэшем GCache, который мы выбрали. Теперь выполним команду web, чтобы посмотреть граф выделения памяти.
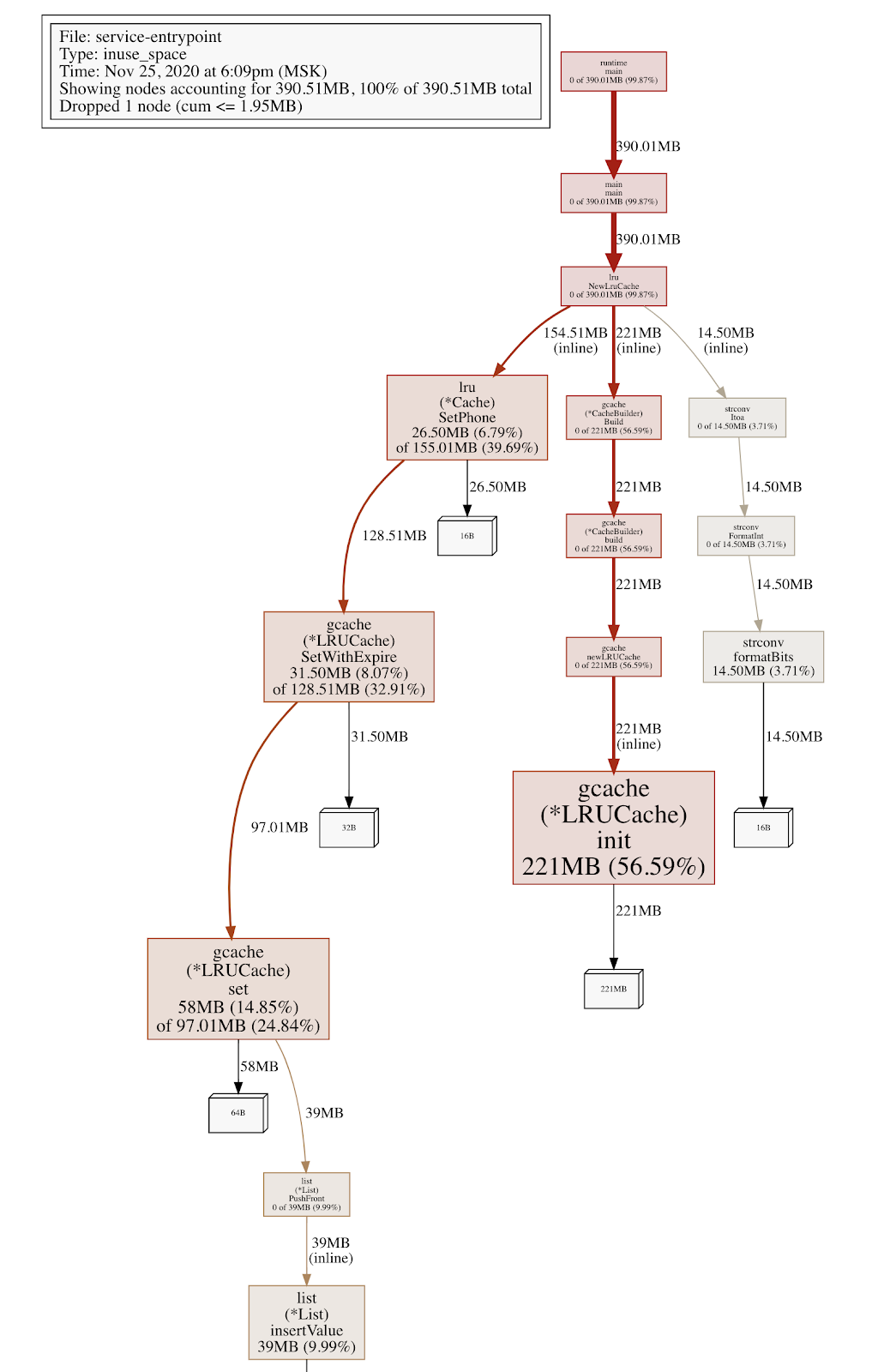
Большая часть выделений памяти действительно происходит внутри библиотеки для кэширования, но пока ничего не понятно. Мы видим, что Heap у нас выделяется. Ну и выделяется и выделяется, чего бухтеть-то.
Дальше выяснить, что происходит, нам поможет инструмент trace. В Авито во всех Go-сервисах на PaaS он включен из коробки. Мы можем дёрнуть url с помощью curl:
curl "httр://${POD_IP}:3366/debug/pprof/trace?seconds=10" > trace.logТеперь при вызове:
go tool trace trace.logу нас откроется страница в браузере.
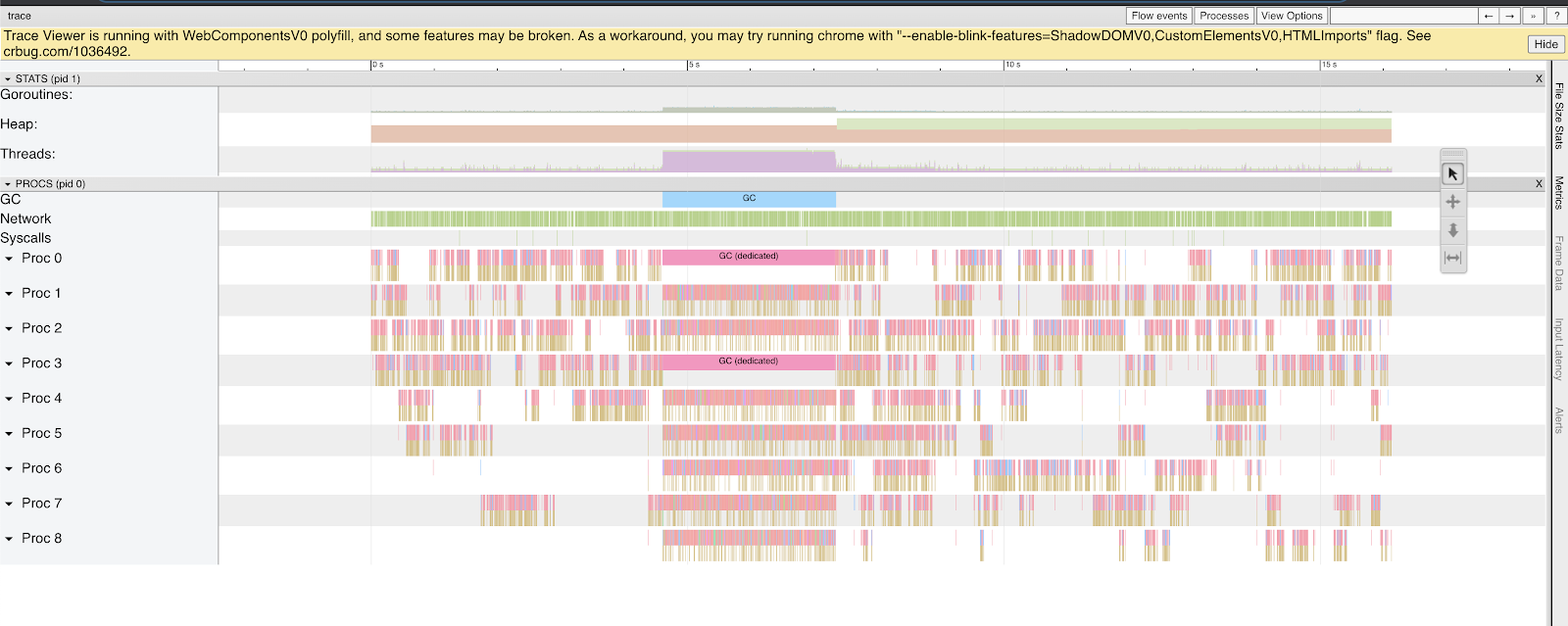
Здесь мы сразу видим, что порядка трёх-четырёх секунд занимает работа garbage collector’a. CPU не нагружен, потом начинается GC, и бум, просто полочка на три-четыре секунды. Чтобы понять, что это значит, нужно немного углубиться в то, как работает garbage collection в Go.
Перед началом работы GC делает stop the world на всех горутинах. То есть на совсем небольшой промежуток времени останавливается выполнение всего кода. Далее GC устанавливает режим write barrier для памяти. Он это делает для того, чтобы указатели в памяти не прыгали, и ему было проще их все посчитать, пометить и найти те, которые нужно удалить.
Дальше идёт этап mark-and-sweep, который может работать параллельно, в разных горутинах. Он ищет те объекты в Heap, на которые нет больше ссылок, то есть до которых мы никак не можем добраться. После того, как он заканчивает этап mark-and-sweep, он удаляет объекты и делает ещё один stop the world, в котором снимает режим write barrier. И после этого всё продолжает работу.
На нашем trace мы видим аж два GC dedicated. GC dedicated — это как раз этап mark-and-sweep. То есть этап, на котором Go проверяет весь Heap и ищет в нём ссылки, до которых мы не можем больше добраться, то есть указатели.
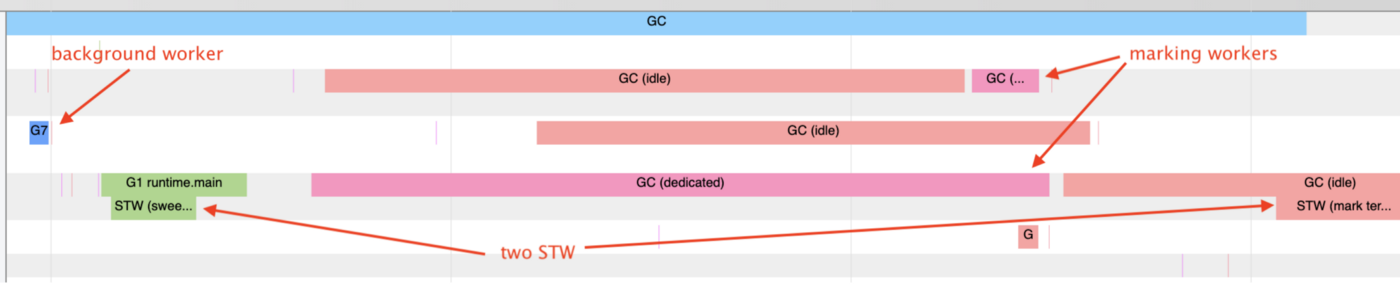
Если GC не хватает одного воркера для пометок, он может на других горутинах запустить дополнительные воркеры. По умолчанию он берёт один воркер, один внутренний процессор в Go. В нашем случае Go явно считает, что не справляется со сборкой мусора, поэтому запустил второй воркер. И проблема с производительностью связана с тем, что у нас очень большое количество указателей в Heap.
Считаем указатели
Строки, по сути, содержат в себе указатель. Если мы посмотрим в src/runtime/string.go, то увидим, что строка — это структура, которая внутри себя хранит указатель и длину. Кэш телефонов у нас 5 млн, и плюс ещё кэш call tracking несколько сотен тысяч. То есть 5 млн телефонов — ключ строка, и значение тоже строка. Это уже 10 млн указателей только со строк.

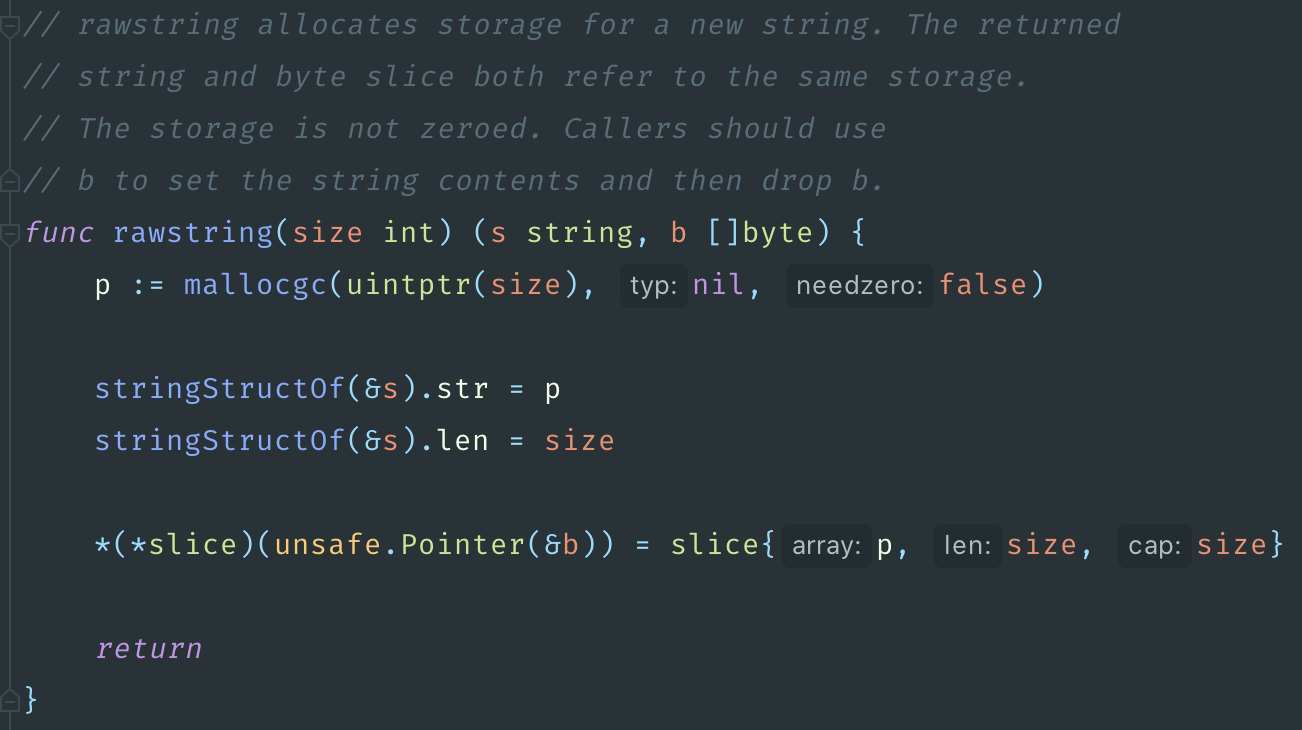
Дальше заглянем в библиотечку кэширования. Под капотом она использует двусвязный список. Каждый элемент двусвязного списка хранит в себе ссылку на следующий и предыдущий элемент, а также ссылку на весь список. То есть в каждом элементе, который лежит в кэше, есть ещё три указателя. Всего получается 10 млн указателей со строк, плюс 5 млн элементов, умноженные на три. Это 25 млн указателей суммарно.

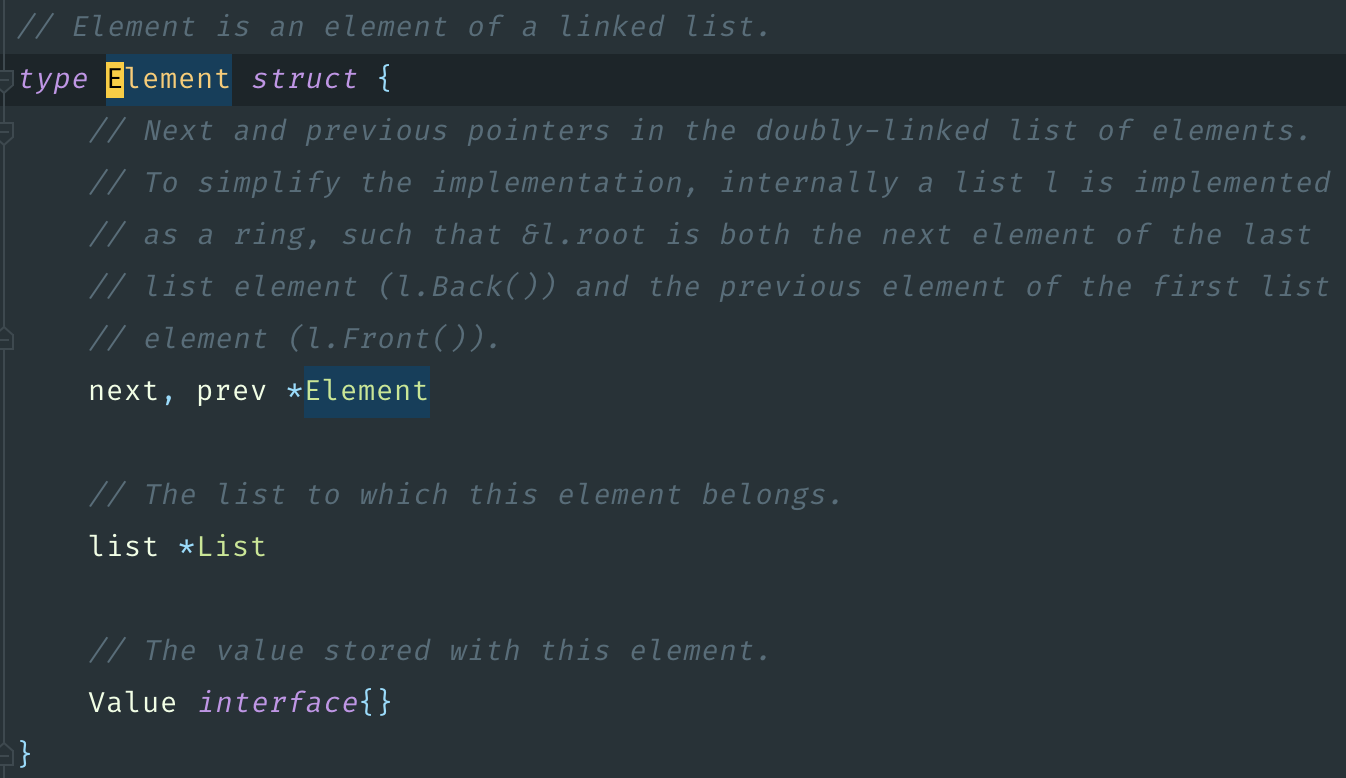
GCache на каждый вызов SetWithExpire делает вызов c.clock.Now, то есть time.Now. Уже немножко проясняется, откуда в Tracing CPU мы видели так много вызовов методов time.Now. Причём он не просто делает этот вызов, но он ещё к каждому элементу сохраняет ссылку на time.Now. Плюс ещё указатель. Их было 25 млн, добавим ещё 5 млн. Итого, 30 млн указателей.
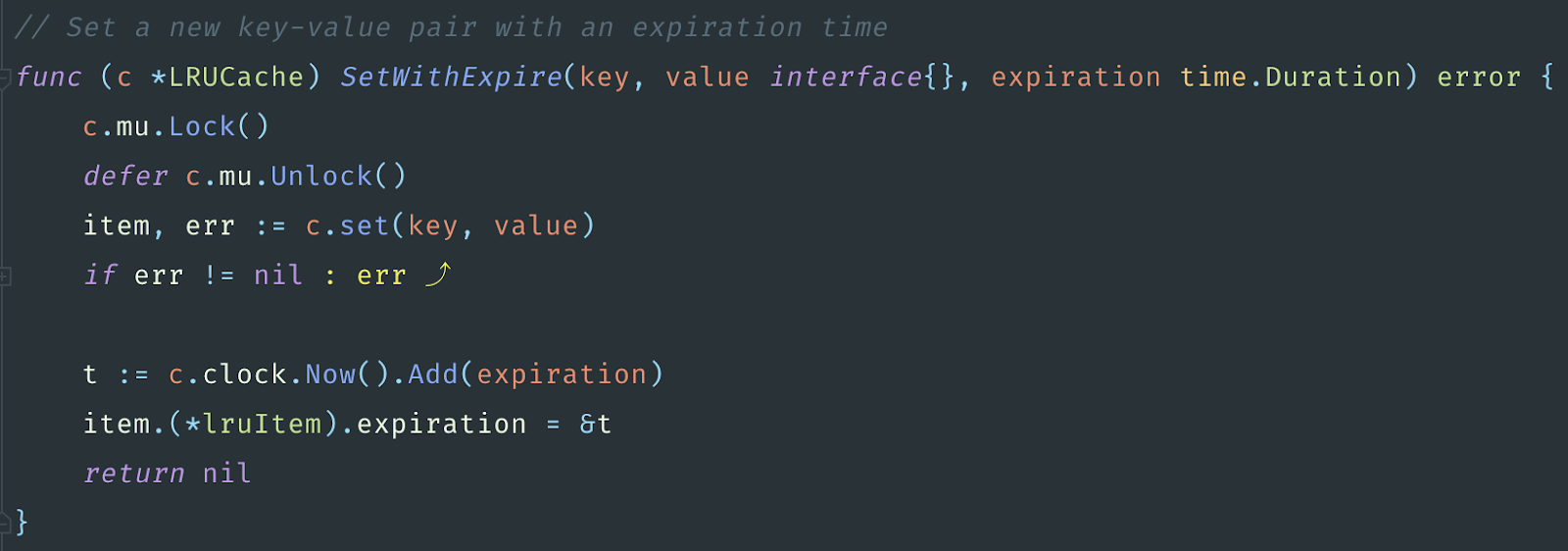
Оптимизация сборщика мусора
Попытаемся сократить количество используемых указателей, чтобы упростить жизнь сборщику мусора.
Для начала попробуем поискать аналоги библиотеки. Нехитрым поиском по GitHub находим такую библиотеку, как CCache. В описании указано, что она создана для того, чтобы быть производительной, хорошо оптимизирована для работы в многопоточном режиме. Сразу же посмотрим, как она работает, чтобы не наступить на те же грабли.
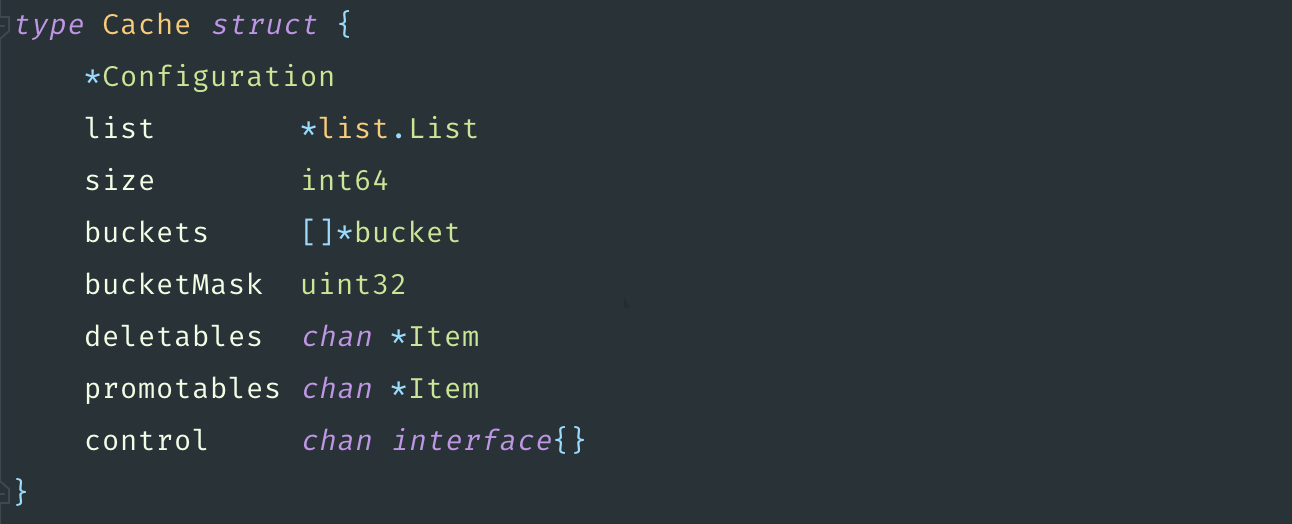
Внутри себя CCache тоже использует двусвязный список. При этом место хранения указателя на время она сохраняет timestamp, а это уже минус 5 млн указателей. Потом она делит элементы на бакеты, то есть мы можем указать количество хранилищ, в которых будут лежать элементы. Делается это для того, чтобы локи не блокировали полностью кэш.
Если у нас, к примеру, параллельно работает восемь горутин и есть восемь бакетов, и каждая горутина попытается записать, то они, с большой вероятностью, спокойно это сделают и не помешают друг другу. А если будет всего один бакет, как в предыдущей реализации с GCache, то первая же горутина заблокирует, а остальные семь будут ждать. И они по очереди будут делать запись. Теперь понятно, почему в CCache сказано, что она написана для работы в многопоточном режиме.
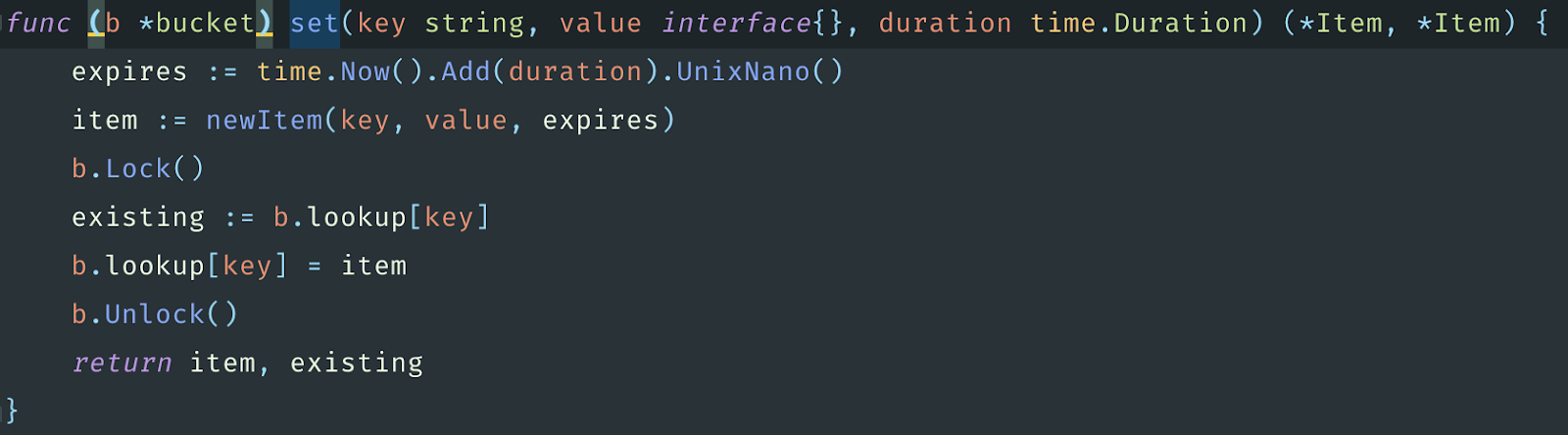
Выбор бакета для сохранения элементов делается при помощи рассчёта хэша. Также есть удаление элементов, время хранения которых уже вышло, и сделано это на каналах, что тоже хорошо.
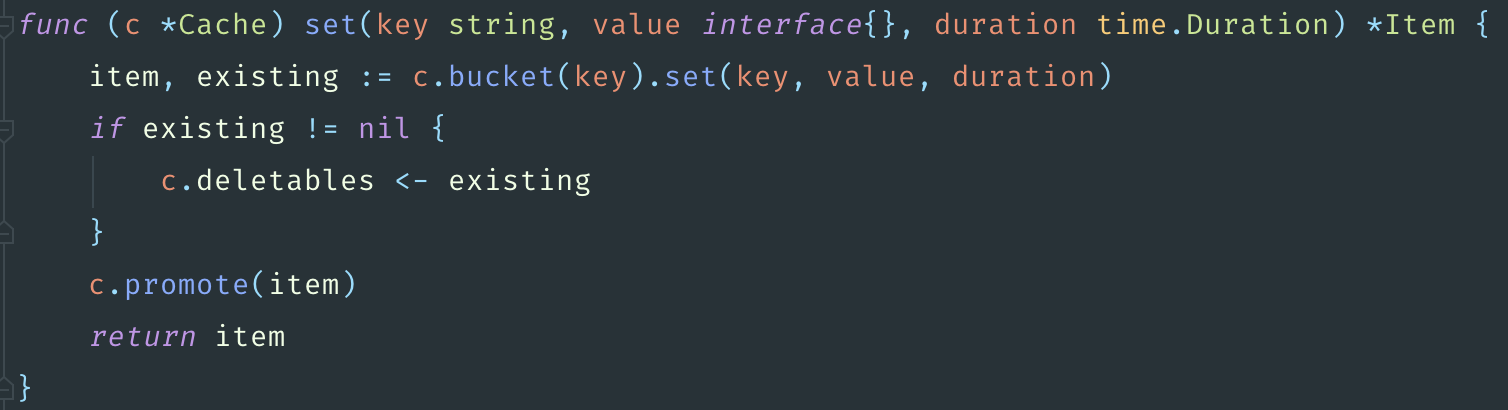
Но есть проблема, что ключ обязательно должен быть строкой в этой библиотеке, что оставляет нам 5 миллионов указателей. Тем не менее, попробуем написать бенчмарки.
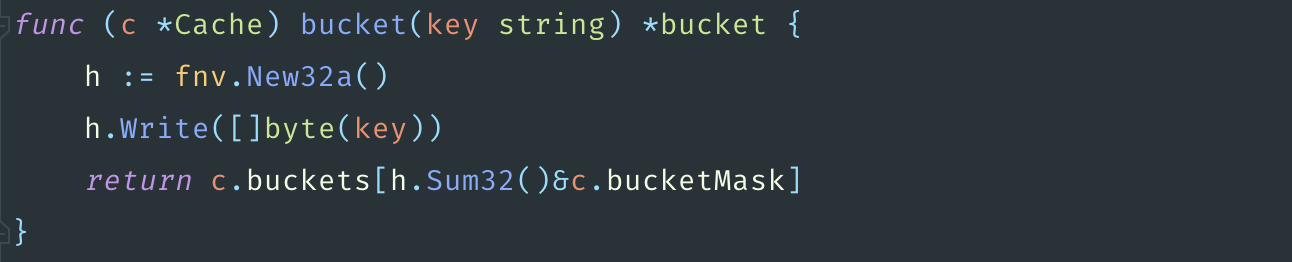
Оказывается, что CCache работает в 69 раз быстрее, чем GCache.
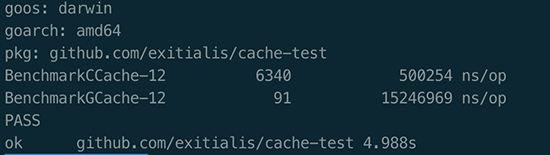
И при этом время работы GC при работе с новой библиотекой сократилась в два раза.
Давайте попробуем заменить библиотечку на проде.
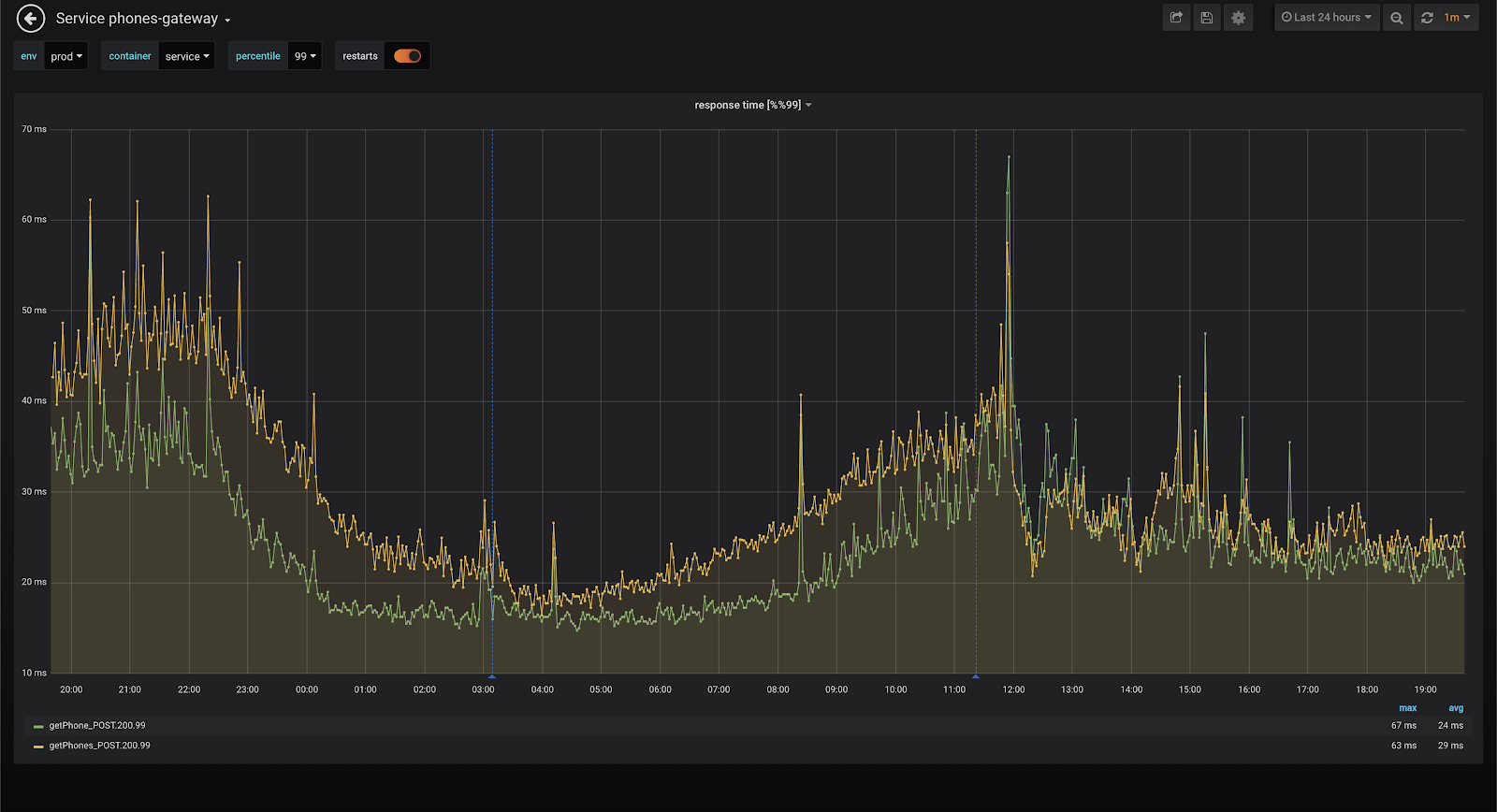
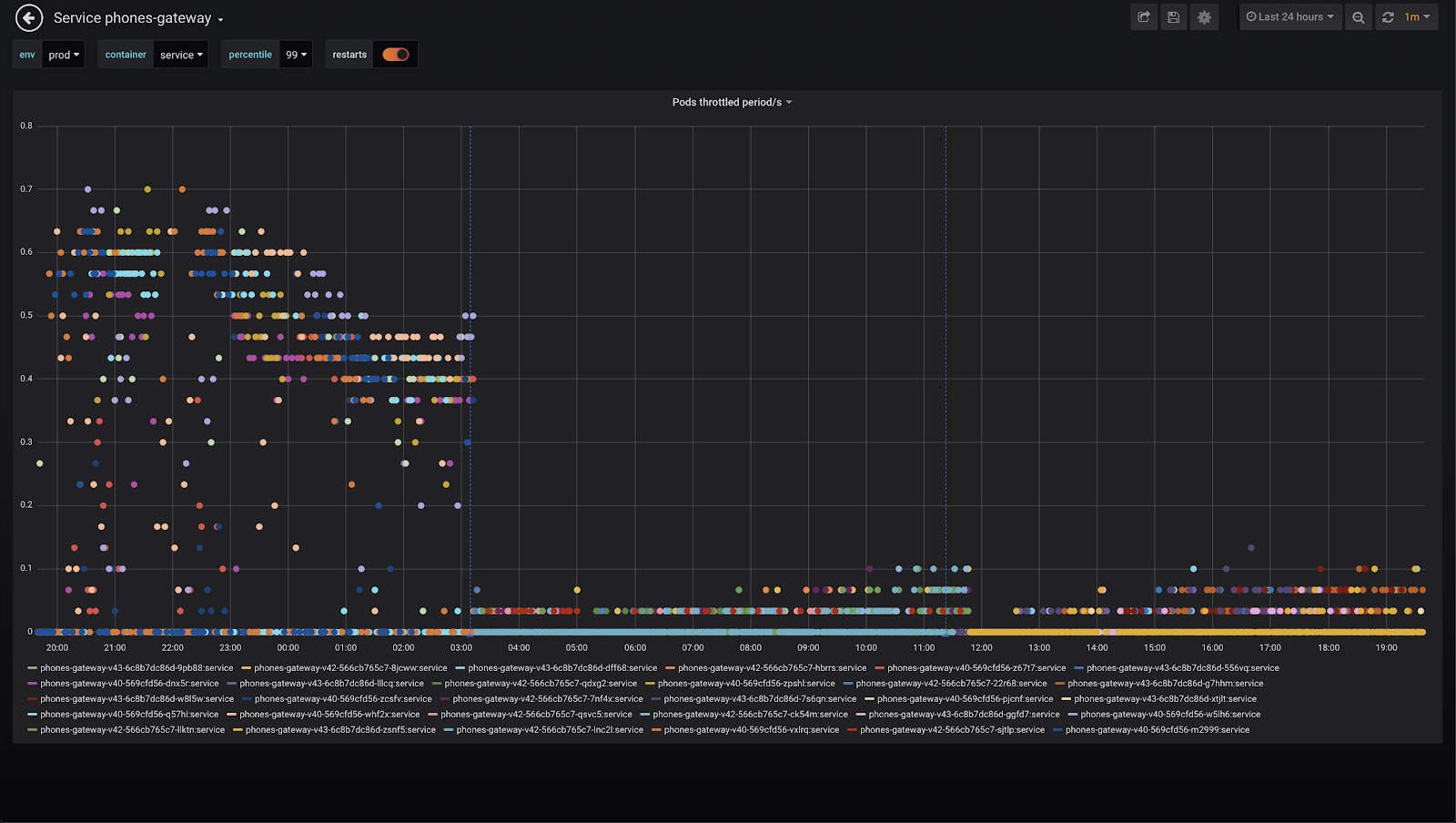
Response time сервиса сразу значительно упал. И самое главное, что Throttling CPU стал намного ниже и выбивается теперь максимум до 0,1. То есть GC стало явно легче работать. После всех оптимизаций и работа с call tracking тоже стала намного лучше, так как я ещё дополнительно расширил размер кэша для него.
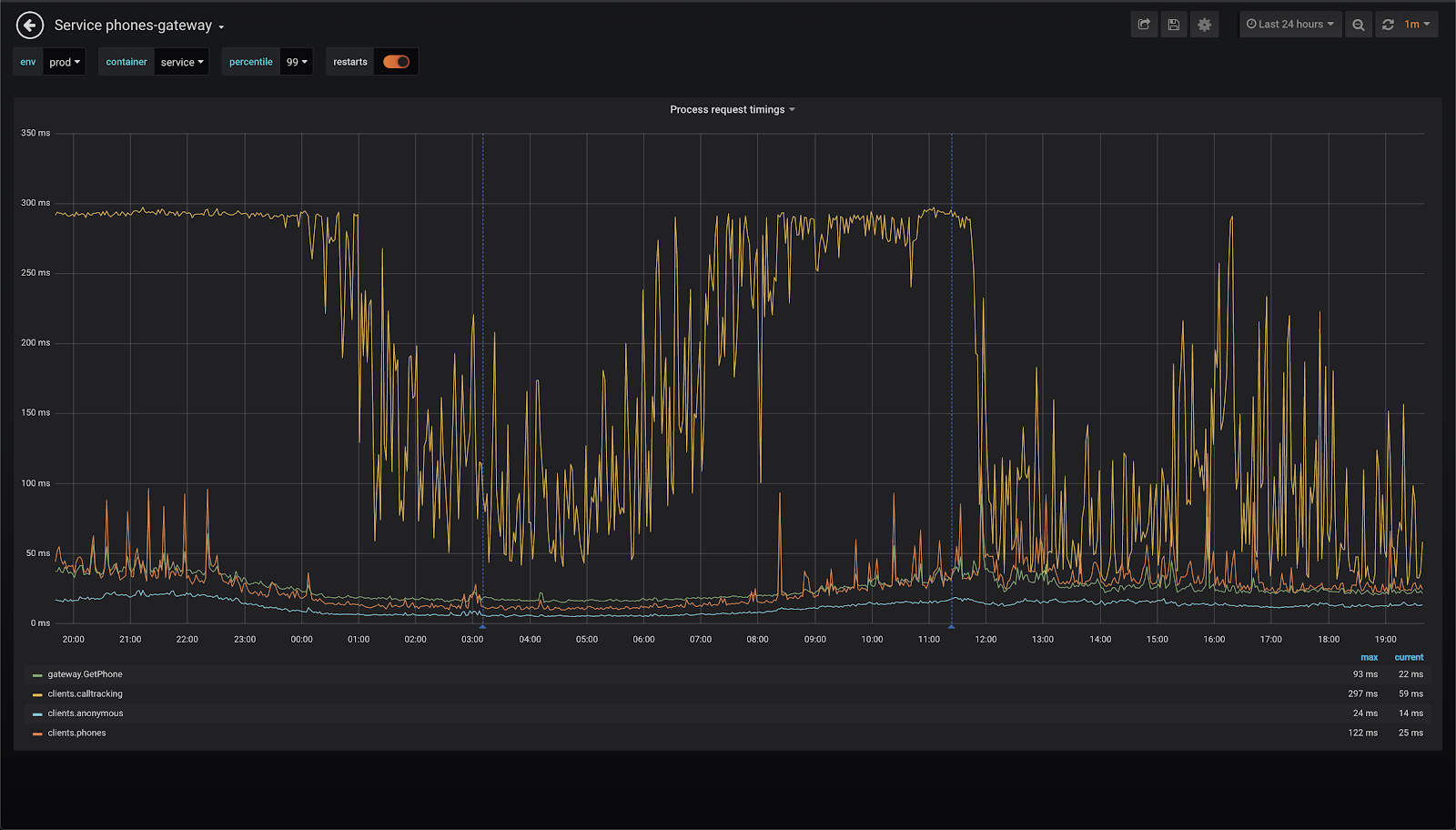
Итог оптимизаций
В итоге проведенных оптимизаций нам удалось:
- Добиться уменьшения response time сервиса в 1,8 раз.
- Снизить Throttling CPU в 8 раз.
- Снизить количество ошибок в два раза, благодаря тому, что тайм-ауты практически пропали.
Несмотря на уже проведенные оптимизации, ещё осталось пространство для улучшений. Как минимум, я находил ещё одну библиотеку, которая вообще не работает с указателями, а работает с массивом байт памяти. Тогда Go не видит указателей и не тратит время на сбор мусора. То есть библиотека сама занимается тем, что очищает мусор. И вообще процесс оптимизации бесконечен. А какие инструменты используете вы для оптимизации своих сервисов?
