Comments 15
Машинное Обучение – более узкое понятие и относится к классу задач, для решения которых компьютер обучают выполнять определенные действия, имея заранее известные правильные ответы, например, классификация объектов по набору признаков или рекомендация музыки и фильмов.
Как рассказал мне однажды один мудрый человек, компьютер ничему не обучают.
Напротив, компьютер обучает модель [данных] по входным данным ( возможно размеченным, тогда это обучение с учителем) при помощи алгоритма обучения.
Иначе бы Вы модель строили руками — брали бы и на глаз по графикам проводили границы разделяющих поверхностей между классами ирисов.
Машинное обучение — это Обучение Машиной, а не Обучение Машины.
Мало, кто это понимает, и это печально, ибо рождает кучу баек и принципиальное непонимание картины.
Вот как-то так.
Не разводите, может быть, демагогию?
А давайте я вам так представлю: машина(алгоритм) таки обучают машину(например, которая выполнят dot product)? И это будет обучение машиной машины.
К чему демагогия? Кому это помогает?
Тут согласен.
А давайте я вам так представлю: машина(алгоритм) таки обучают машину(например, которая выполнят dot product)? И это будет обучение машиной машины.
К чему демагогия? Кому это помогает?
Мало, кто это понимает, и это печально, ибо рождает кучу баек и принципиальное непонимание картины.
Тут согласен.
Да, действительно, изначальный смысл “Машинного Обучения” – это построение моделей, используя специализированные алгоритмы и имеющиеся данные. Но ведь потом эти модели запускаются в эксплуатацию и они начинает выполнять интеллектуальные задачи. И тогда пользователи видят, что обучили именно машину. Поэтому, мне кажется, что такое толкование тоже имеет право на существование.
Сбор и очистка данных. Как показывает практика, этот этап может занимать до 90% времени всего анализа данных
Скажите, нет каких-либо универсальных сервисов, которые выполняли бы эту задачу?
Или для каждых данных свой алгоритм?
Я так понимаю, что приведение данных к пригодному для построения моделей виду — завит от природы самих данных. Соответственно, алгоритмы просто не могут быть универсальными. Конечно есть набор техник, например «заменить пропущенные значения переменной на среднее значение переменной», но понятно это далеко не всегда работает. Вот например, как приводят значения в уже ставшей классической задаче «Титаник» Не смотря на хорошую изученность задачи и небольшое количество данных, это все равно достаточно творческий процесс…
print train_dataЯ думаю, новичкам всё же лучше начинать с Python 3. Все популярные библиотеки его уже поддерживают.
С советом согласен, но если честно, я пока не столкнулся с разницей в синтаксисе и Python 2 и 3. Мне главное было, чтобы хоть что-то заработало ;)
Тот момент, когда interaction effect перепутали с площадью.
Статья написана простым языком и на простых примерах, и это ее достоинство. Однако печальны фактические ошибки:
Не расстояния от линии до точек!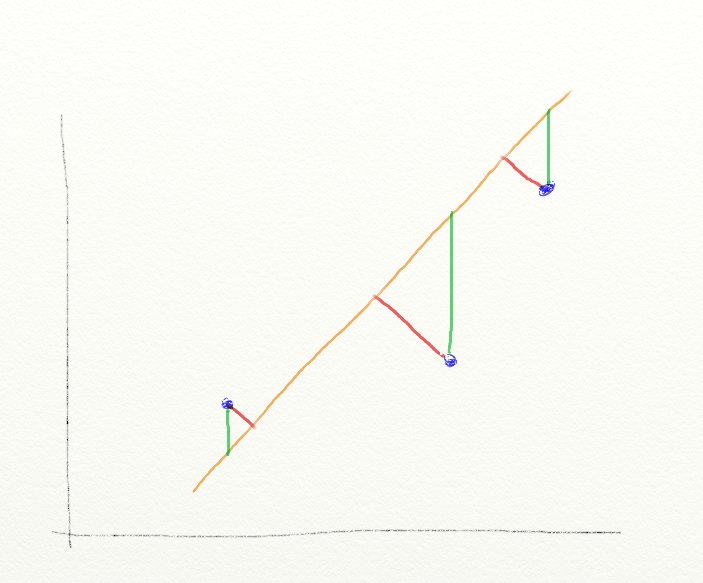
Зачем проводить линию регрессии алгоритмом градиентного спуска? Уравнение этой линии находится простой аналитической формулой.
Такого алгоритма классификации не существует. Существует такой алгоритм обучения классификатора (потенциально произвольного).
Как наглядно представить линейную регрессию? Если смотреть на зависимость между двумя переменными, то это проведение линии так, чтобы расстояния от линии до точек были в сумме минимальные
Не расстояния от линии до точек!

Если смотреть на зависимость между двумя переменными, то это проведение линии так, чтобы расстояния от линии до точек были в сумме минимальные. Самый распространенный способ оптимизации – это минимизация среднеквадратичной ошибки по алгоритму градиентного спуска
Зачем проводить линию регрессии алгоритмом градиентного спуска? Уравнение этой линии находится простой аналитической формулой.
Итак, берем самый известный алгоритм классификации: стохастический градиентный спуск (Stochastic Gradient Descent)
Такого алгоритма классификации не существует. Существует такой алгоритм обучения классификатора (потенциально произвольного).
Спасибо за комментарий! Как вы правильно заметили: целью статьи было максимально упростить материал, чтобы он был понятен на интуитивном уровне. Честно говоря, не понял комментарий, иллюстрированный картинкой. Он о том, что расстояние до линии должно измеряться, по красным линиям, а не зеленым? Если да, то этот момент я не уточнял, т.к. считал, что это интуитивно понятно.
Из вашего текста следует, что измеряется по красным линиям. Метод МНК измеряет по зеленым. И в целом моя претензия к тексту заключается именно в том, что фактические ошибки убивают его полезность. Интуитивно понятный текст по определенной проблеме написать еще сложнее, чем обычный технический. Его может написать только человек, глубоко разбирающийся в проблеме, настолько глубоко, что он способен объяснить проблему на пальцах и при этом не допустить фактических ошибок.
Согласен про сложность написания интуитивно понятной статьи. Уточнил в тексте:
«Если смотреть на зависимость между двумя переменными, то это проведение линии так, чтобы вертикальные расстояния от линии до точек были в сумме минимальные»
«Если смотреть на зависимость между двумя переменными, то это проведение линии так, чтобы вертикальные расстояния от линии до точек были в сумме минимальные»
Уточнил в тексте, что SGD — это алгоритм обучения классификатора. И что метод классификации — SVM
Sign up to leave a comment.
Машинное обучение: от Ирисов до Телекома