В последнее время все больше говорят про «NoSQL» — прямо «модный» тренд образовался. «Технологию» начинают активно использовать известные авторитетные компании, в т.ч. в высоконагруженных проектах с немалыми объемами данных — и кто-то восхищается, а кто-то обливает себя бензином и факелом выпрыгивает с 35 этажа с криком: "SQL ACID forever!"

Причем о каком бы продукте не говорили, будь то MongoDB или Cassandra — нередко приходится наблюдать прямо таки религиозную восторженность и трепет, как будто речь идет о чем-то новом и священном.
А особенный трепет вызывают мелькающие в сети мозгораздирающие эскизы архитектур, типа кружочка из датацентров, работающих в «мастер-мастер репликации» на нескольких континентах:
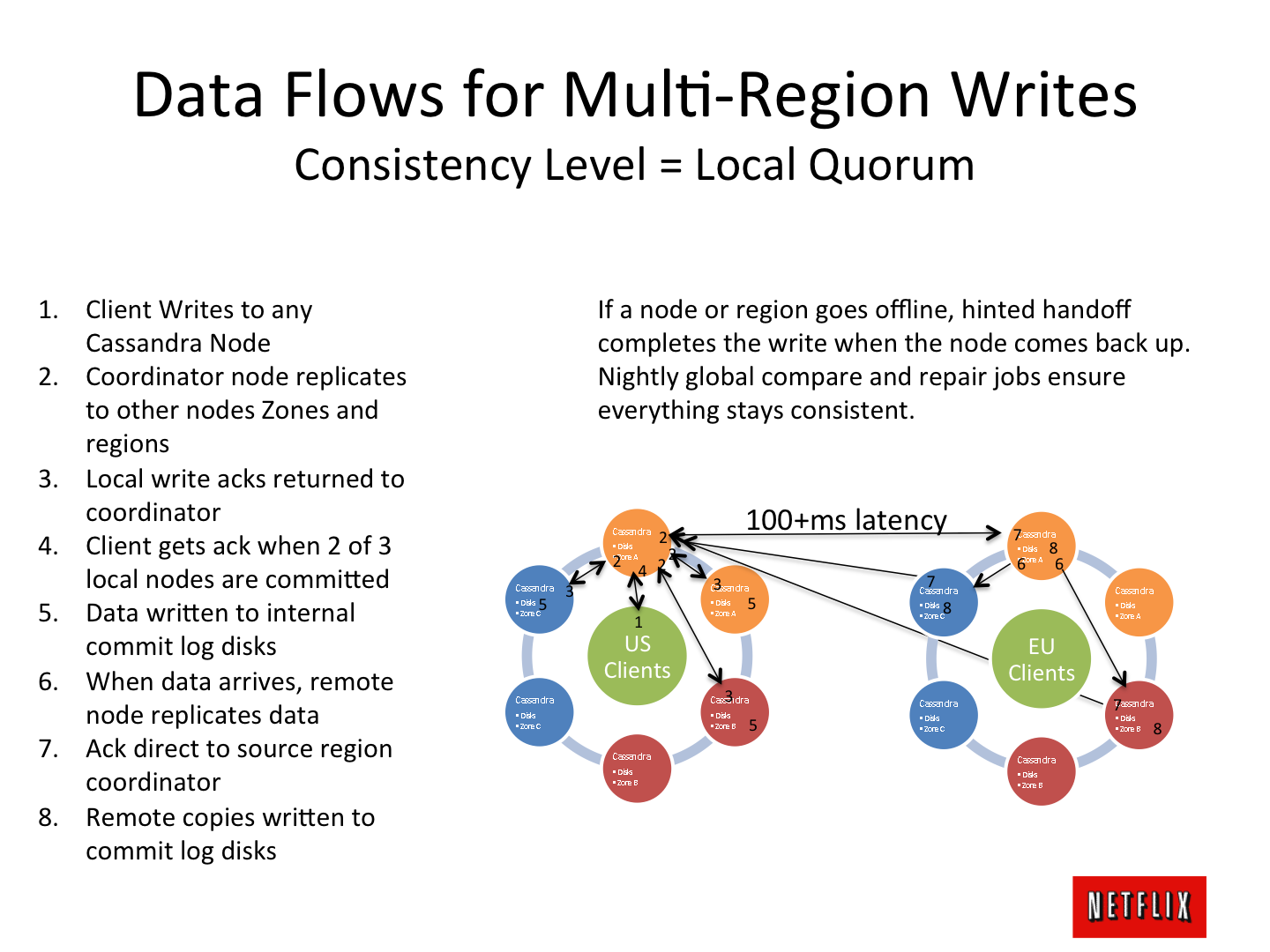
Но… когда начинаешь серьезно использовать «новую» технологию в боевых проектах, понимаешь, откуда это все пошло, в чем причина тех или иных архитектурных решений: колечек датацентров и прочая мистика — формируется практическое и простое, «мурочное» понимание — которым хочется поделиться с коллегами, дабы не наделали архитектурных ошибок и не поплыли на плоту через океан. Об этом, в принципе, статья.

Ну вроде все предусмотрено — атомарность, согласованность, изоляция транзакций и надежность фиксации. Пробуй, строй, эксплуатируй. В ISO SQL прописали уровни изоляции транзакций — ну что еще не хватило для полного счастья, когда можно все детерминировать?
Что вызвало причину появления «CAP ереси» в стиле выбери только 2 из трех? :-)

Ответ очевиден — бизнесу нужны новые, «сверхзвуковые» возможности хранилищ данных:
Из популярных:
А электронный бизнес требует и требует:
Понятно, что этот поток требований медленно, но верно вел к суициду… но
… Но если долго просить программистов сделать невозможное — они сделают!

Так вот, прошло не так много времени, как в начале нынешнего столетия появились «NoSQL» продукты и стало возможным:
Причем, судя по всему, кашу заварил Amazon с DynamoDB:
а затем идеи стали клонироваться в виде фейсбуковской Cassandra:
И конечно без Google BigTable тут не обошлось.
Что же это за «серебряная пуля» такая?
При углубленном изучении «NoSQL» продуктов, а последний продукт с которым я плотно работал был Amazon DynamoDB (очень похожий на Apache Cassandra) — стали проявляться «скрытые подводные камни и ограничения», которые никак кроме как «платой за вседозволенность» не назовешь:
А читать, по умолчанию, устаревшуюнеконсистентную информацию :-) А как вы хотели — информация же распространяется с ограниченной скоростью. Ну конечно можно поставить флажок и прочитать только что записанную информацию — но придется подождать-с.
Но опять-таки, нужно знать, что информации нужно время — чтобы она разошлась по континентам и приложение должно уметь это обработать (видим переключение ответственности, блин… снова на программиста :-) ).
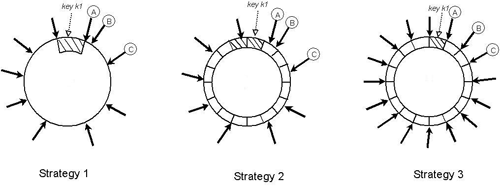
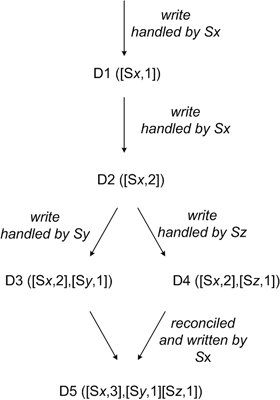
Устойчивость к разделению кластера реализована за счет технологий, похожих на версионность — но периодически нужно будет запускать поиск рассогласований типа «Anti-entropy using Merkle trees».
Можно, но конфигурировать остальные ноды все-таки придется, иногда с ломом и паяльником.
А дальше — интереснее.
В наших проектах мы используем DynamoDB — передовое «NoSQL» решение от Amazon. Давайте рассмотрим его более подробно ниже.
Число, строка, бинарные данные. Забудьте про DATETIME (их можно эмулировать таймстампом, но становится иногда не по себе).
Индексы нужно указать сразу, их должно быть не более — 5 на таблицу. Причем добавлять их в существующую таблицу — нельзя, нужно ее удалять, пересоздавать и перезаливать туда данные. Спокойный сон архитектору — обеспечен.
Можно хранить любой объем данных, но… размер одной «строки таблицы» с именами и значениями «колонок» не должен превышать 64КБ. Правда число «колонок» не ограничивается.
И на одной ноде кластера (c одним значением основного индекса hash key) при наличии дополнительных индексов нельзя хранить больше 10ГБ, так то.
Видимо зря написал «колонок». В «NoSQL» нередко понятия схемы данных просто нет, поэтому в каждой «строке таблицы» могут быть разные «колонки» или «атрибуты».
Можно выбрать данные только по одному индексу (есть еще основной (hash key) индекс, но диапазонные выборки делать по нему нельзя — только константные). Отсортировать — только по одному индексу.
Забудьте про сложные «WHERE, GROUP BY», не говоря о подзапросах — «NoSQL» движки их просто эмулируют и могут выполнять очень медленно.
Можно выполнять более сложные выборки — но методом полного сканирования таблицы (пресловутый table scan) и затем поэлементной фильтрации результатов на серверной стороне, что и долго и дорого.
Транзакции… иногда они нужны :-), а гарантируется лишь атомарное обновление отдельных сущностей (есть правда приятные плюшки с чтениями-инкрементами за одну операцию). Так что транзакции придется эмулировать — а то вы хотели, если данные «размазаны» по 20 серверам/датацентрам всего земного шарика?
Нередко в «NoSQL», в т.ч. DynamoDB начинаю глумиться над основателями реляционной теории и создавать в строках ужасы типа:
user=john blog_post_$ts1=12 blog_post_$ts2=33 blog_post_$ts3=69…
где $ts1-3 — таймстампы публикаций пользователя в блог.
Да, удобно получить список публикаций за один запрос. Но работа программиста — увеличивается.
1) Прежде чем выбирать для проекта «NoSQL» хранилище, вспомните причины появленияфранкенштейна подобного класса продуктов, что часто это не что иное, как набор «memcached» подобных серверов с надстроенной довольно простой логикой и, соответственно — сохранение данных и простые выборки будут, действительно, летать, а что-то посложнее… придется шаманить на стороне приложения.
2) Еще раз перечитайте теорему Брюера и найдите подвохи :-)
3) Внимательно посмотрите документацию по используемому продукту — особенно ограничения. Скорее всего вы встретите множество сюрпризов — и к ним нужно будет аккуратно подготовиться.
4) И посмотрите напоследок в глаза Кодду

Да, вы получите очень надежное, высокодоступное, поддерживающее гибкие схемы репликации современное решение — но платить, увы, придется жесточайшей денормализацией и усложнением логики работы приложения (в т.ч. эмулировать транзакции, жонглирование тяжелыми данными внутри приложения и т.п.). Выбор — за вами!
Всем удачи!

Причем о каком бы продукте не говорили, будь то MongoDB или Cassandra — нередко приходится наблюдать прямо таки религиозную восторженность и трепет, как будто речь идет о чем-то новом и священном.
А особенный трепет вызывают мелькающие в сети мозгораздирающие эскизы архитектур, типа кружочка из датацентров, работающих в «мастер-мастер репликации» на нескольких континентах:
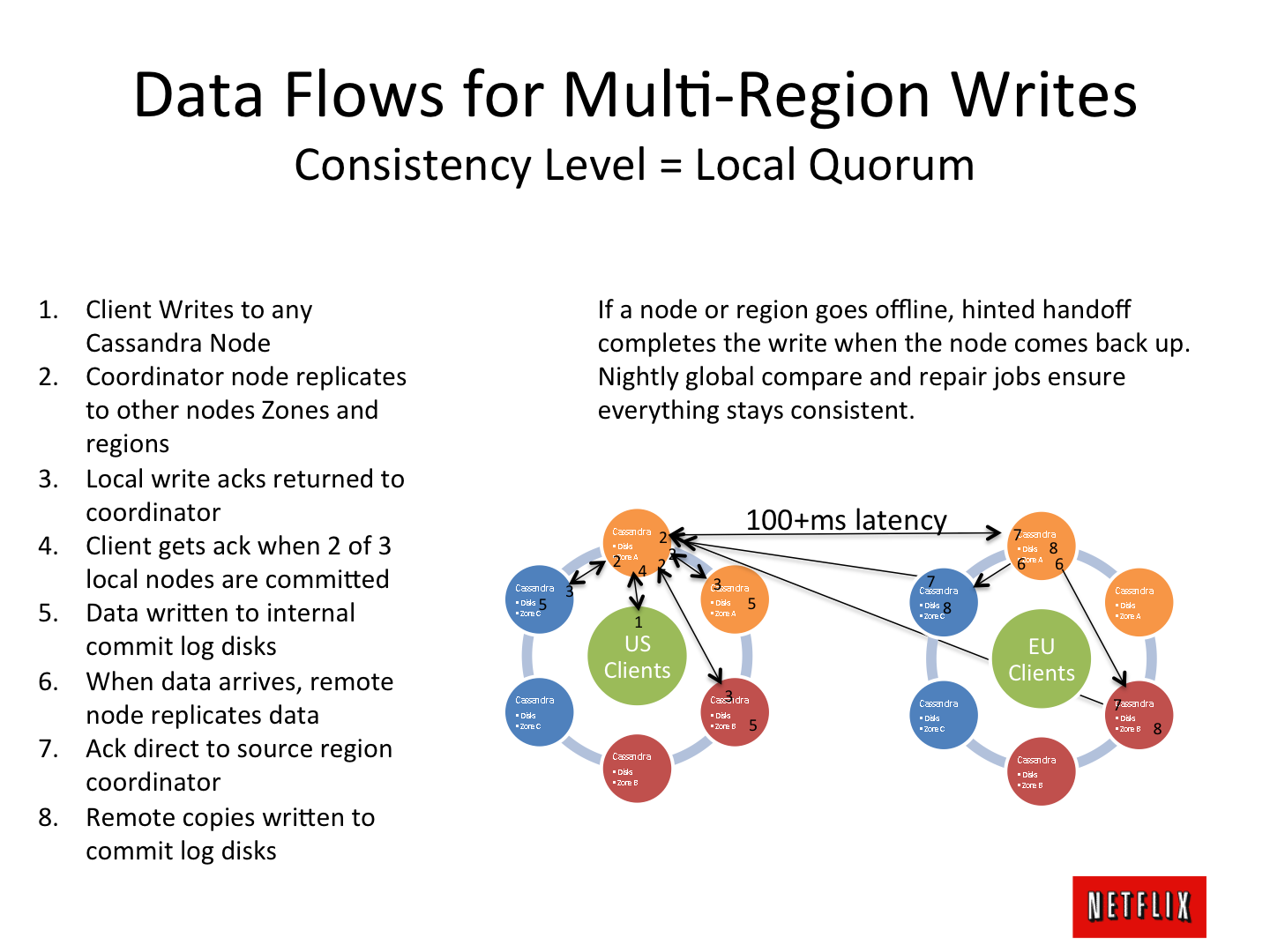
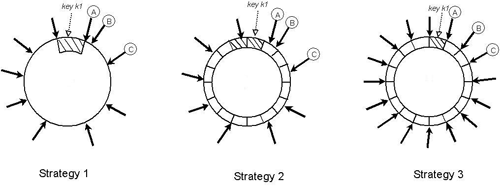
Но… когда начинаешь серьезно использовать «новую» технологию в боевых проектах, понимаешь, откуда это все пошло, в чем причина тех или иных архитектурных решений: колечек датацентров и прочая мистика — формируется практическое и простое, «мурочное» понимание — которым хочется поделиться с коллегами, дабы не наделали архитектурных ошибок и не поплыли на плоту через океан. Об этом, в принципе, статья.

Чем же не устраивает старый, добрый ACID?
Ну вроде все предусмотрено — атомарность, согласованность, изоляция транзакций и надежность фиксации. Пробуй, строй, эксплуатируй. В ISO SQL прописали уровни изоляции транзакций — ну что еще не хватило для полного счастья, когда можно все детерминировать?
Что вызвало причину появления «CAP ереси» в стиле выбери только 2 из трех? :-)
- согласованность данных
- доступность
- устойчивость к разделению

Ответ очевиден — бизнесу нужны новые, «сверхзвуковые» возможности хранилищ данных:
- база должна быть всегда доступна для записи и чтения и кейсы типа сервер перезагружается, сеть упала — больно бьют по карману
- интенсивный рост объемов данных и ужесточение требований к их доступности, в т.ч. из-за бурного развития всемирной сети — в одной базе данные ну они просто перестали помещаться
- клиентов становится много в разных точках мира и нужно сохранить заказы как можно быстрее и т.п.
- бурный рост веб-сервисов, появление мобильных устройств
Чем не устраивают «классические» кластера БД?
Из популярных:
- Oracle RAC — видимо, дорого и сложно, тяжеловесно, да и как его раскидывать по разным материкам?
- MySQL cluster — быстрый мастер-мастер, но много подводных камней и ограничений, типа хранения данных только в памяти, но для некоторых кейсов все же неплохо работает
- galera cluster for mysql — да, честный мастер-мастер, пиши куда хочешь (но должен знать куда именно), но нет «устойчивости к разделению», может зависнуть при отсутствии кворума или сойти с ума, со скрипом восстанавливается при падении и тормозит при геораспределенном использовании, т.к. синхронно передает данные на все копии; да и нет шардинга данных между мастерами
А электронный бизнес требует и требует:
- база должна быть доступна всегда, нельзя потерять заказ клиента или его корзину; даже если пропала синхронизация между нодами базы данных
- база должна быть доступна везде (Европе и США), и, конечно, синхронизировать данные между копиями
- база должна неограниченно масштабироваться при увеличении объема данных
- база должна масштабироваться под нагрузку: на запись, на чтение
Понятно, что этот поток требований медленно, но верно вел к суициду… но
Ответ программистов — можно!
… Но если долго просить программистов сделать невозможное — они сделают!

Не все знают, что для полноценного программирования достаточно языка C, а для людей с чувством прекрасного можно излить душу и на C++ — так нет, под давлением бизнеса: «как можно программировать быстрее и чтобы все могли?» — родились технологии, которые на мощном железе сейчас даже уже работают: C#, java, python, ruby ...
Так вот, прошло не так много времени, как в начале нынешнего столетия появились «NoSQL» продукты и стало возможным:
- писать на любой элемент кластера, всегда!
- размещать элементы кластера на разных материках и читать с локальных!
- вырубать любую ноду кластера и система не сойдет с ума!
- добавлять ноды кластера когда душа пожелает, и это позволит масштабировать как запись, так и чтение!
Причем, судя по всему, кашу заварил Amazon с DynamoDB:
DynamoDB is the result of 15 years of learning in the areas of large scale non-relational databases and cloud services.
а затем идеи стали клонироваться в виде фейсбуковской Cassandra:
Apache Cassandra was developed at Facebook to power their Inbox Search feature by Avinash Lakshman (one of the authors of Amazon's Dynamo) and Prashant Malik. It was released as an open source project on Google code in July 2008.
И конечно без Google BigTable тут не обошлось.
Что же это за «серебряная пуля» такая?
А семь шапок сошьешь? И семь сошью...
При углубленном изучении «NoSQL» продуктов, а последний продукт с которым я плотно работал был Amazon DynamoDB (очень похожий на Apache Cassandra) — стали проявляться «скрытые подводные камни и ограничения», которые никак кроме как «платой за вседозволенность» не назовешь:
Писать можно на любую ноду кластера, а читать ...
А читать, по умолчанию, устаревшую
Можно разместить ноды кластера на разных материках, но...
Но опять-таки, нужно знать, что информации нужно время — чтобы она разошлась по континентам и приложение должно уметь это обработать (видим переключение ответственности, блин… снова на программиста :-) ).
Можно выключать любую ноду кластера, рубить топором сетевые кабели, но...
Устойчивость к разделению кластера реализована за счет технологий, похожих на версионность — но периодически нужно будет запускать поиск рассогласований типа «Anti-entropy using Merkle trees».
Добавлять ноды кластера когда душа пожелает
Можно, но конфигурировать остальные ноды все-таки придется, иногда с ломом и паяльником.
А дальше — интереснее.
Ограничения Amazon DynamoDB
В наших проектах мы используем DynamoDB — передовое «NoSQL» решение от Amazon. Давайте рассмотрим его более подробно ниже.
Типов данных — откровенно мало
Число, строка, бинарные данные. Забудьте про DATETIME (их можно эмулировать таймстампом, но становится иногда не по себе).
Индексы добавлять можно, только… сразу
Индексы нужно указать сразу, их должно быть не более — 5 на таблицу. Причем добавлять их в существующую таблицу — нельзя, нужно ее удалять, пересоздавать и перезаливать туда данные. Спокойный сон архитектору — обеспечен.
Размер данных
Можно хранить любой объем данных, но… размер одной «строки таблицы» с именами и значениями «колонок» не должен превышать 64КБ. Правда число «колонок» не ограничивается.
И на одной ноде кластера (c одним значением основного индекса hash key) при наличии дополнительных индексов нельзя хранить больше 10ГБ, так то.
Видимо зря написал «колонок». В «NoSQL» нередко понятия схемы данных просто нет, поэтому в каждой «строке таблицы» могут быть разные «колонки» или «атрибуты».
Запросы...
Можно выбрать данные только по одному индексу (есть еще основной (hash key) индекс, но диапазонные выборки делать по нему нельзя — только константные). Отсортировать — только по одному индексу.
Забудьте про сложные «WHERE, GROUP BY», не говоря о подзапросах — «NoSQL» движки их просто эмулируют и могут выполнять очень медленно.
Можно выполнять более сложные выборки — но методом полного сканирования таблицы (пресловутый table scan) и затем поэлементной фильтрации результатов на серверной стороне, что и долго и дорого.
Транзакции — а что это?
Транзакции… иногда они нужны :-), а гарантируется лишь атомарное обновление отдельных сущностей (есть правда приятные плюшки с чтениями-инкрементами за одну операцию). Так что транзакции придется эмулировать — а то вы хотели, если данные «размазаны» по 20 серверам/датацентрам всего земного шарика?
Пляски с атрибутами
Нередко в «NoSQL», в т.ч. DynamoDB начинаю глумиться над основателями реляционной теории и создавать в строках ужасы типа:
user=john blog_post_$ts1=12 blog_post_$ts2=33 blog_post_$ts3=69…
где $ts1-3 — таймстампы публикаций пользователя в блог.
Да, удобно получить список публикаций за один запрос. Но работа программиста — увеличивается.
Выводы
1) Прежде чем выбирать для проекта «NoSQL» хранилище, вспомните причины появления
2) Еще раз перечитайте теорему Брюера и найдите подвохи :-)
3) Внимательно посмотрите документацию по используемому продукту — особенно ограничения. Скорее всего вы встретите множество сюрпризов — и к ним нужно будет аккуратно подготовиться.
4) И посмотрите напоследок в глаза Кодду

Да, вы получите очень надежное, высокодоступное, поддерживающее гибкие схемы репликации современное решение — но платить, увы, придется жесточайшей денормализацией и усложнением логики работы приложения (в т.ч. эмулировать транзакции, жонглирование тяжелыми данными внутри приложения и т.п.). Выбор — за вами!
Всем удачи!
