Привет, Хабр!
Меня зовут Александр Красных, я тимлид команды ранжирования и рекомендаций в Циан. Мы сделали фичу, которая позволяет найти по фото похожие квартиры. Для этого нужно уметь быстро находить среди миллионов фотографий изображения, визуально похожие по стилю на входную картинку-запрос.
В статье поговорим о том, как мы решили задачу с помощью алгоритмов глубокого обучения, и расскажем, что там под капотом этой функции и как мы подружили EfficientNet с FAISS. В работе над статьей мне помогал Владимир Филипенко (@vovaf709): он изложил самые основы, чтобы текст мог понять и неспециалист.

Искать квартиры по фото мы придумали в мае на внутреннем хакатоне Циан. Идея победила, и мы запустили MVP, чтобы проверить её на наших пользователях.
Итак, вот в чём суть: пользователь загружает картинку → на нашей стороне через EfficientNet генерируется эмбеддинг → понижается размерность вектора → быстро находятся близкие векторы с помощью FAISS → извлекаются изображения.

Ничего сложного, да? А теперь давайте пройдёмся по каждому этапу в отдельности и поговорим о всех тонкостях процесса и некоторых возникших в ходе работы трудностях.
Дескриптор изображений — EfficientNet-B0 + PCA
«А при чём тут нейросети?»
Итак, задача: необходимо найти изображения, визуально похожие по стилю на входную картинку-запрос, причём достаточно быстро. Как будем решать?
Основная проблема — задача сформулирована довольно абстрактно. Непонятно, чем определяется требуемая от нас «похожесть по стилю» с математической точки зрения и как с этим работать.
На помощь приходит такая абстракция, как дескриптор — некий алгоритм, сжимающий изображение в вектор относительно небольшой размерности и при этом сохраняющий как можно больше полезной информации. Но где его взять? Ян Лекун не так давно (в исторической перспективе) придумал свёрточные нейронные сети. Они справляются с задачами компьютерного зрения и последовательно от слоя к слою «сжимают» картинку, превращая в вектор, который на последних слоях выступает своего рода инпутом для алгоритма принятия решения.
Чтобы понять это, рассмотрим некоторую классификационную нейросеть просто как чёрный ящик, о котором известно лишь то, что он последовательно применяет к изображению некоторые преобразования (слои) и на выходе сообщает нам метку (на самом деле вероятность) класса «кухня», «студия» и так далее. Причём важно помнить, что последний слой берёт результат всех предыдущих (обычно это вектор фиксированной размерности), и уже с его помощью пытается как можно более точно предсказать класс объекта. Ключевое, но не тривиальное соображение состоит в том, что для качественной работы такой нейросети ей придётся сложить в рассматриваемый вектор как можно больше полезной для предсказания информации. В связи с этим, взяв предобученную сетку и отрезав ей последний слой (или несколько последних слоёв), мы увидим, как классификационная нейросеть превращается в «умный» дескриптор.
Почему мы выбрали нейросетевой дескриптор?
1. Алгоритм, хорошо решающий задачу классификации, должен обладать инвариантностью относительно изменений входной картинки, которые не меняют сути изображения. Например, фото студии, отражённое относительно вертикальной оси, повёрнутое или же зашумлённое, всё ещё остаётся снимком студии. Это априорное знание закладывается в нейросеть в процессе обучения, когда мы показываем ей картинки, преобразованные (аугментированные) соответствующим образом, а значит, оно в какой-то мере проникает и в дескриптор.

2. В связи с этим архитекторы нейронных сетей стремятся помочь им стать хоть немного инвариантными относительно описанных преобразований, и потому используют при их построении слои, вносящие это свойство на уровне самой модели. Например, max-pooling с соответствующим смещением делает сеть нечувствительной к небольшим сдвигам изображения.

3. Имеются любопытные наблюдения, свидетельствующие о том, что свёрточные нейронные сети фокусируются в большей степени на текстурах объектов, чем на их геометрических формах. А значит, информация о текстуре, или, другими словами, о стиле будет закодирована в векторе предпоследнего слоя, что нам и нужно.

Что ж, стало ясно, что эмбеддинг, построенный с помощью свёрточной модели — то, что нам нужно. Теперь расскажем непосредственно о той сетке, которую мы препарировали.
EfficientNet-B0
EfficientNet — это целое семейство свёрточных нейронных сетей, представленных в 2019 году. Несмотря на то, что сферу обработки изображений стремительно захватывают более продвинутые архитектуры, EfficientNet’ы остаются достойными моделями по соотношению качества работы и требуемого количества вычислительных ресурсов, особенно среди свёрточных сетей.

В оригинальной статье авторы попытались построить наиболее эффективную одновременно с точки зрения качества и экономии ресурсов свёрточную нейросеть и разработали эмпирические правила по масштабированию её архитектуры. Сначала они использовали neural architecture search, который нашёл оптимальную архитектуру среди указанных для некоторой задачи. По сути, этот алгоритм «умно» перебрал различные конфигурации слоёв нейронки и нашёл такую конфигурацию, которая качественно решает задачу, но при этом требует не очень много ресурсов. Собственно, её назвали EfficientNet-B0. Затем они подобрали поиском по сетке наилучшие коэффициенты для масштабирования ширины, глубины, а также разрешения входного изображения сети. Таким образом, из исходной архитектуры выросли ещё семь, имеющих разный баланс между качеством и количеством параметров.
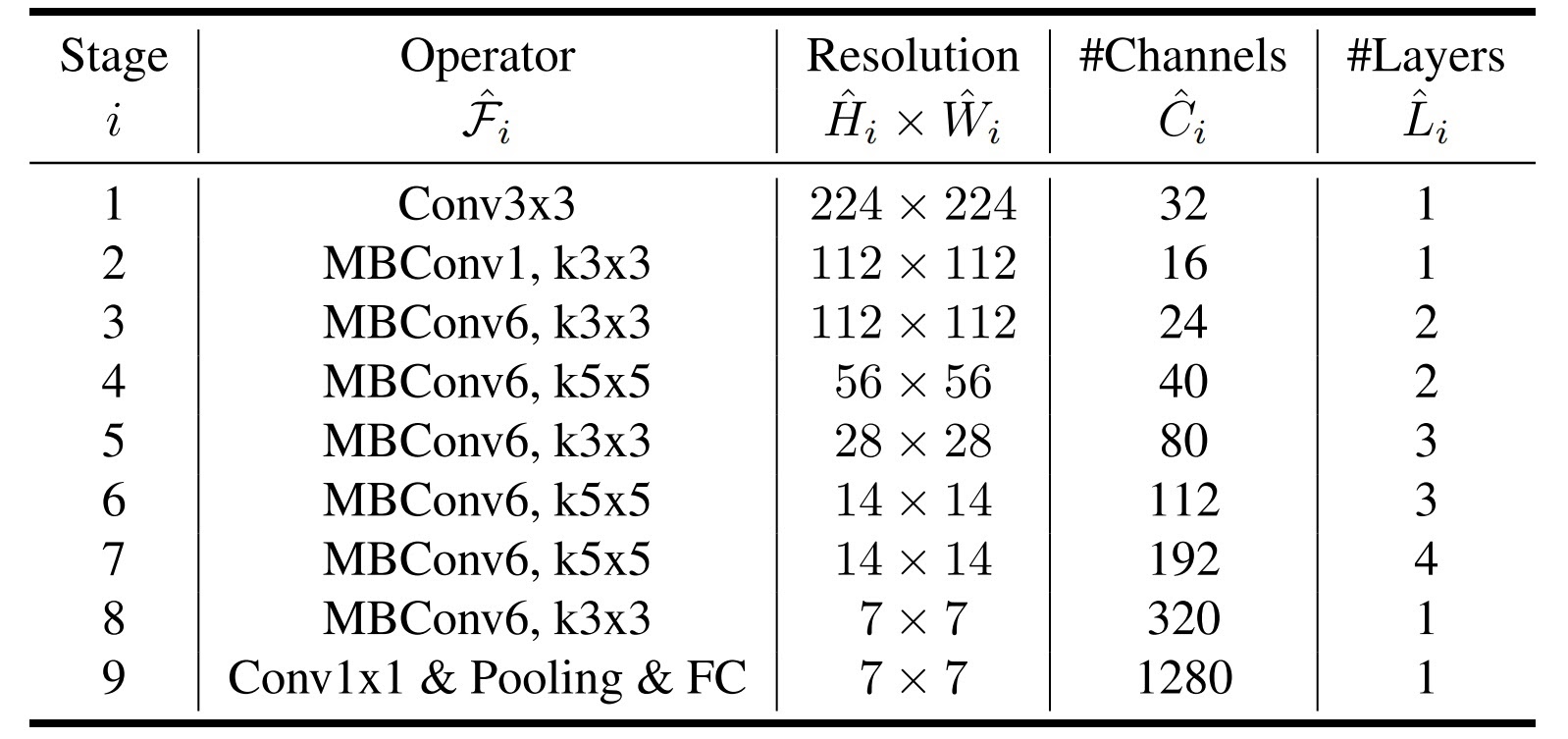
Архитектура EfficientNet-B0 представлена на схеме. Ничего сверхъестественного она из себя не представляет: стандартный вычислительный граф из MobileNet-свёрток с линейным слоем на выходе. Но работает она на ура. За подробностями отсылаю читателя к оригинальной статье, этой и к этому сборнику, а также к полезному видео.
Модель для прода выбиралась из нескольких предобученных на ImageNet EfficientNet’ов и классических ResNet’ов. Мы прогоняли изображения квартир через сетку и с помощью асессоров визуально сравнивали, насколько похожи изображения, эмбеддинги которых близки. Лучше всех себя показал самый компактный EfficientNet-B0, имеющий всего лишь около 5,3 млн параметров. К тому же, EfficientNet-B0 уже применялся в других проектах Циан, что только добавило плюсик ему в карму. По совокупности факторов мы взяли его, а именно — реализацию из библиотеки timm. Во время разработки также пробовали конвертировать сетку в OpenVINO для ускорения инференса. Однако в итоге сошлись на том, что и timm’овских 300 мс на предсказание при использовании CPU вполне достаточно.
PCA
Сложность задачи поиска похожих векторов линейно зависит от длины вектора (нашего эмбеддинга). Главным bottleneck’ом всего пайплайна должен был стать поиск похожих векторов, так как Циан обладает довольно крупной базой изображений квартир, около 20 млн. Поэтому для ускорения этого процесса мы решили понизить размерность эмбеддингов, получаемых из EfficientNet, с 1280 до 128 с помощью PCA (метода главных компонент).
PCA как он есть
Несмотря на свою простоту, этот линейный метод понижения размерности довольно дёшев и эффективен. Его суть заключается в следующем: пусть имеется некоторый набор векторов, размерность которых мы хотим понизить. Делается предположение о том, что вся информация содержится в суммарной вариативности компонент векторов, или, иначе говоря, суммарной дисперсии. Это в общем и целом логично, так как, например, независимый от других константный признак не несёт никакой полезной информации. Тогда остаётся только найти такое линейное отображение в пространстве меньшей размерности, чтобы при действии этого отображения терялось как можно меньше дисперсии.

Данное отображение, по сути являющееся проектором на новые оси, очень элегантно можно выразить математически с помощью сингулярного (SVD) разложения матрицы, составленной из исходных векторов. Подробно об этом можно почитать здесь, посмотреть там. Ещё есть классная визуализашка с fmin.xyz с поиском главной оси, которая, надеюсь, поможет навести на правильные мысли.
Итак, EfficientNet-B0 (пред)обучен, PCA заряжен, а значит, пора наконец переходить к поиску похожих векторов.
Поиск похожих векторов с помощью FAISS
Задача поиска векторов, ближайших к вектору-запросу, востребована в различных приложениях машинного обучения, в некоторых разделах робототехники, теории кодирования и во многих других сферах. Её решают как подзадачу при рекомендации объявлений в Циан, для распознавания лиц, а классический алгоритм классификации (или его модификация для регрессии) — KNN, по сути, полностью из неё и состоит. Для точного её решения необходимо рассчитать расстояния между вектором-запросом и всеми векторами имеющегося датасета. Это стоит  арифметических операций, где
арифметических операций, где  — размер датасета, а
— размер датасета, а  — размерность вектора, что в случае многомиллионных наборов данных успешно конвертируется в часы ожидания и такие же многомиллионные убытки. Поэтому лучшие умы мира активно трудятся над приближёнными решениям этой задачи в стремлении снизить время работы ценой неточности нахождения ближайших векторов. Как уже было упомянуто, наш набор данных состоит из примерно 20 млн векторов, так что данная проблема актуальна и в нашем случае.
— размерность вектора, что в случае многомиллионных наборов данных успешно конвертируется в часы ожидания и такие же многомиллионные убытки. Поэтому лучшие умы мира активно трудятся над приближёнными решениям этой задачи в стремлении снизить время работы ценой неточности нахождения ближайших векторов. Как уже было упомянуто, наш набор данных состоит из примерно 20 млн векторов, так что данная проблема актуальна и в нашем случае.
Существует множество алгоритмов и трюков, позволяющих найти ближайшие векторы более эффективно, чем это делает наивный подсчёт. Один из них — построить inverted file индекса. Это крайне эффективный и красивый метод, идея которого заключается в следующем: давайте наделим наш набор данных иерархической структурой и сначала будем искать ближайший вектор среди векторов первого уровня, а затем спустимся на второй и продолжим поиск там, среди значительно меньшего количества объектов, отвечающих первому вектору. Геометрически мы разбиваем наш датасет на кластеры с помощью алгоритма k-means, за каждым из которых закрепляем представителя. И сначала ищем ближайшего представителя (центроид кластера), а потом опускаемся в соответствующий кластер и продолжаем поиск в нём. Прекрасное интуитивное объяснение, не скопипастить которое у нас хватило совести, можно найти здесь.

Таким образом, разбив датасет размера  на
на  кластеров, мы снизим асимптотическую сложность поиска с
кластеров, мы снизим асимптотическую сложность поиска с  до
до  , что станет весьма и весьма значительным ускорением. С учётом константы, спрятанной за O-нотацией, для нашего датасета с помощью inverted file индекса мы будем искать ближайший вектор примерно в 2000 раз быстрее! Круто! Но, конечно, такое ускорение получается не бесплатно: мы теряем в точности предсказания. Ведь не обязательно ближайший вектор будет лежать в найденном кластере, что прекрасно видно на примере:
, что станет весьма и весьма значительным ускорением. С учётом константы, спрятанной за O-нотацией, для нашего датасета с помощью inverted file индекса мы будем искать ближайший вектор примерно в 2000 раз быстрее! Круто! Но, конечно, такое ускорение получается не бесплатно: мы теряем в точности предсказания. Ведь не обязательно ближайший вектор будет лежать в найденном кластере, что прекрасно видно на примере:

Однако в данной задаче нам и не нужно выдавать математически строгий ответ. Ведь, как мы помним, математическая строгость осталась в главе про дескриптор.
Реализацию этого подхода мы взяли из библиотеки FAISS, разработанной Facebook AI Research. В ней можно найти имплементации и многих других методов быстрого поиска схожих векторов. Неплохие обзоры этого фреймворка можно найти здесь и тут. А если вы хотите подробнее разобраться в зоопарке существующих алгоритмов быстрого поиска, то начать стоит с этой статьи. Стоит отметить, что важное преимущество этой библиотеки — можно запускать её алгоритмы на GPU, однако нам пока эта опция не пригодилась.
К сожалению, в этом алгоритме возникла проблема пустых выдач из-за дополнительных фильтров. Дело в том, что в нашей фиче можно устанавливать фильтры, например, по стоимости квартиры. И в первичной реализации мы сначала искали изображения похожих квартир, а затем применяли настройки к соответствующим объявлениям, что порой приводило к пустому ответу. Чтобы частично решить эту проблему, мы завели не один, а несколько (по 10 бинов для каждой категории) индексов FAISS, отвечающих разным диапазонам значений величин, по которым происходит фильтрация. Это существенно улучшило выдачу, но, разумеется, панацеей не стало, так как при определённом желании установить такую комбинацию фильтров, по которой квартир в принципе может не существовать, всё ещё вполне возможно :)
С учётом поиска в нескольких индексах, обозначаемых в FAISS как IDMap -> IVF2048 -> Flat, набор похожих квартир доставался за  мс на CPU, что нас вполне устроило. Для актуализации индексов мы обновляем их ежедневно, что занимает около двух часов.
мс на CPU, что нас вполне устроило. Для актуализации индексов мы обновляем их ежедневно, что занимает около двух часов.
Внутреннее устройство
Вся фича держится на двух микросервисах. Первый отвечает за получение изображений, поступающих из новых объявлений, их обработку и дальнейшее помещение в индексы FAISS. Второй же реагирует на запросы от пользователя: берёт фото, прогоняет через EfficientNet-B0 + PCA, ищет похожие эмбеддинги с помощью FAISS и отправляет обратно соответствующие объявления, которые также проходят через постфильтрацию. Примеры работы вы можете видеть на скриншотах ниже.

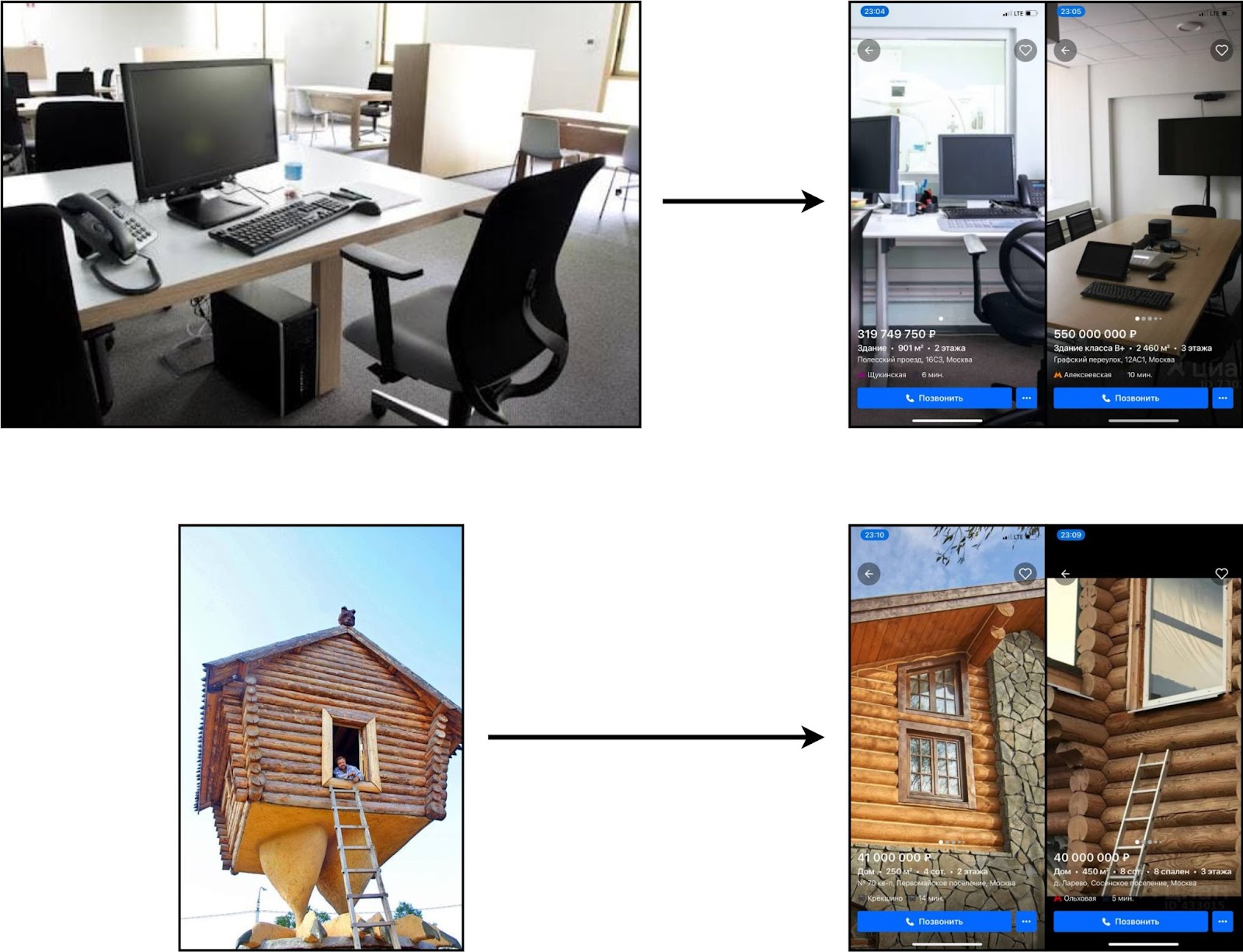
Как видите, вся система неплохо справляется со своей задачей, однако, как говорится, «доверяй, но проверяй», так что рекомендуем вам потестить новую фичу уже самостоятельно в нашем мобильном приложении. К слову: фото удаляется сразу после завершения процессинга. Так что за безопасность личных данных можно не переживать :)
Текущие проблемы + дальнейшие планы
Эта фича уже используется в системе рекомендаций Циан.
Помимо важной проблемы с фильтрацией после поиска в индексе FAISS, которую мы успешно преодолели, сервис всё ещё испытывает трудности при работе с фотографиями плохого качества и низкого разрешения. У человека далеко не всегда имеется возможность сделать хороший, чёткий снимок. Причём зачастую дело не только в качестве вашей камеры, но ещё и в освещении, цветовой гамме квартиры (допустим, у вас всё белое) и других нюансах. Для решения проблемы мы трудимся над проектом по улучшению качества контента, заливаемого на Циан, в том числе с помощью нейросетевого super resolution, про который мы когда-нибудь тоже обязательно расскажем.
Также прямо сейчас мы учим EfficientNet-B0 выдавать похожие представления для изображений квартир со схожими стилями с помощью лосса ArcFace, чтобы адаптировать сетку под нашу задачу.
Так что желаем вам тёплых уютных квартир — пробуйте, ищите, пользуйтесь новой фичей, и будет вам счастье. Кстати, таким способом можно находить офисы и дома (ну а вдруг). Ну а если пока в этом нет необходимости, в случае чего вы знаете, где нас искать. Обнимемся в комментариях!
