
Роботы вошли в нашу жизнь. Мы пользуемся ими на повседневной основе, подчас даже не замечая этого. ИИ звонит нам и отвечает на наши звонки. Сейчас даже проезд в метро можно оплатить лицом.
Динамичный рост рынка технологий искусственного интеллекта закономерно породил спрос на инфраструктуру для их разработки. Особенность построения моделей искусственного интеллекта состоит в том, что для их обучения требуются очень мощные и производительные решения. Под катом мы поговорим о том, как начался наш путь в сервисы для ИИ и к чему мы пришли сейчас. Коснемся и исторических моментов, и планов на ближайшее будущее.

У нас в #CloudMTS есть сервис GPU SuperCloud. Это комплексное IaaS-решение, которое главным образом служит для обучения моделей искусственного интеллекта и родственных задач. Разработчики получают готовую инфраструктуру, на которой можно развернуть стек необходимых инструментов и приступить к работе. Кроме того, ближайшее время мы планируем «эволюционировать» и запустить SuperCloud в формате PaaS. Но об этом чуть ниже.
Сегодня я хочу поговорить не о технологиях, лежащих в основе SuperCloud, и даже не о самом продукте. Гораздо интереснее будет рассказ об истории его создания: здесь переплелись философия #CloudMTS, актуальные требования рынка и плавное приближение человечества к технологической сингулярности. Но обо всем по порядку.
Идею построить такой сервис мы начали реализовывать еще 2018 году. Его созданию, как я уже писал выше, способствовали бурный рост и развитие различных систем искусственного интеллекта и машинного обучения. По мере того, как стали появляться удобные фреймворки, а технологии становились всё более зрелыми и доступными, число сервисов, построенных на базе ИИ, неуклонно росло. Это и роботизированные голосовые помощники, и программы распознавания изображений/видео, и системы предиктивного анализа и скоринга данных. Всех не перечесть.
Разработка моделей ИИ носит итерационно-инкрементный характер, то есть подразумевает многократный процесс тренировки и тестирования модели. Это позволяет постепенно повышать результативность модели, пока она не выйдет на требуемый уровень. GPU позволяют тренировать модели гораздо быстрее, нежели на CPU. А самые распространенные фреймворки (например, TensorFlow или PyTorch) глубоко оптимизированы для ускорения работы на GPU. Дома или в офисе качественную и мощную систему не построить: необходимы опыт, колоссальные материальные вложения и специализированное оборудование.
Индустрия ИИ начала интенсивно развиваться в прошлом десятилетии, и вот уже в 2013-15 гг. на рынке стали активно появляться сервисы IaaS и PaaS, предназначенные для решения задач искусственного интеллекта и машинного обучения. Лидером GPU решений и инфраструктуры для обучения моделей является компания NVIDIA. Де-факто NVIDIA на сегодняшний день предоставляет ключевые инфраструктурные технологии для построения систем машинного обучения и искусственного интеллекта.
Главным преимуществом сервисной модели является, как это ни банально, оптимизация затрат. Стоимость видеокарт, стоимость серверов, их обслуживание – весьма существенны, если не сказать больше. Далеко не каждая компания, не говоря уже о независимых разработчиках, может позволить себе покупку сервера с графическими адаптерами. Так, всего одна карта NVIDIA V100 стоит порядка 1 000 000 рублей. Наш сервис GPU SuperCloud построен на базе серверов с 8 такими картами. Расскажем о его строительстве с самого начала.

Зимой 2018 года мы приняли решение закупить узлы DGX-1, это самая первая модель в линейке NVIDIA. В 2019 году мы запустили сервис IaaS. Искушенный читатель может сразу задать вопрос: как на DGX-1, не поддерживающих виртуализацию, удалось разделить ресурсы и организовать полноценный сервис для клиентов. Ответ простой: никак. Нам требовалось всего лишь протестировать гипотезу и приобрести новый опыт, поэтому цель построить продукт «на продажу» мы оставили на более поздний период. Тем более, найти покупателя даже на один узел — задачка не из легких.

После череды успешных тестов мы развернули сервис для внутреннего заказчика — 2-х компаний внутри МТС. В частности — «Центр Искусственного Интеллекта МТС». А для строительства услуги мы приняли решение использовать стандартные серверы Huawei с видеокартами Nvidia V100: установили на них гипервизор от VMware и раздробили мощности на несколько виртуальных машин.

Huawei G5500
Благодаря технологиям VMware и NDIVIA GPU Manager мы получили возможность делить ресурсы одного сервера в широком диапазоне. К примеру, в одном сервере 8 графических адаптеров. Мы можем поделить его мощности вплоть до ⅛ адаптера. Собственно, так и появился на свет наш сервис GPU SuperCloud в формате IaaS.
Поделимся с вами внутренним наблюдением: наибольшей популярностью у заказчиков пользуются «половинные», «целые» и 1+1 адаптеры. В течение 2020 г. спрос на сервис вырос буквально вдвое. И да, мы вдвое расширили инфраструктуру в начале 2021 г. Сейчас наши серверы утилизированы на 85% полностью, в скором времени мы начнем закупку дополнительных мощностей.
Согласитесь, было бы нечестно рассказать о своем видении услуги, умолчав о тех ее сторонах, которые нам не нравятся, которые мы хотим улучшить и доработать.
Существенный минус для клиентов — сервис предоставляется в виде «голого» IaaS. С одной стороны, разработчик получает полную свободу действий. С другой — даже при самом стандартном сценарии он вынужден разворачивать фреймворки, настраивать CI/CD и осуществлять первичную конфигурацию системы с нуля. При этом услуга активна, и приходится за нее платить еще до начала полноценного использования. Этот момент нивелируется стоимостью: 2-3 недели, в течение которых услуга «простаивает» для бизнеса, отбиваются в течение пары месяцев.
Что касается модели оплаты — на данный момент у нас отсутствует Pay-as-You-Go. В будущем планируем внедрить эту модель. Однако, с другой стороны, нам удалось сбалансировать месячную стоимость аренды и выдать самую низкую цену на рынке.
GPU SuperCloud фактически стал опорной точкой для создания суперкомпьютера GROM — третьего по вычислительной мощности на территории Российской федерации.
Он построен на базе NVIDIA DGX A100 и нацелен исключительно на выполнение задач машинного обучения и ИИ. Производительность GROM достигает 2,26 петафлопс. На нем развернут специализированный программный стек, который позволяет реализовать функциональность High Performance Computing (HPC).
Кратко о GROM:
Также мы разрабатываем технологию, которая позволит нам предоставить ресурсы суперкомпьютера внешним заказчикам.
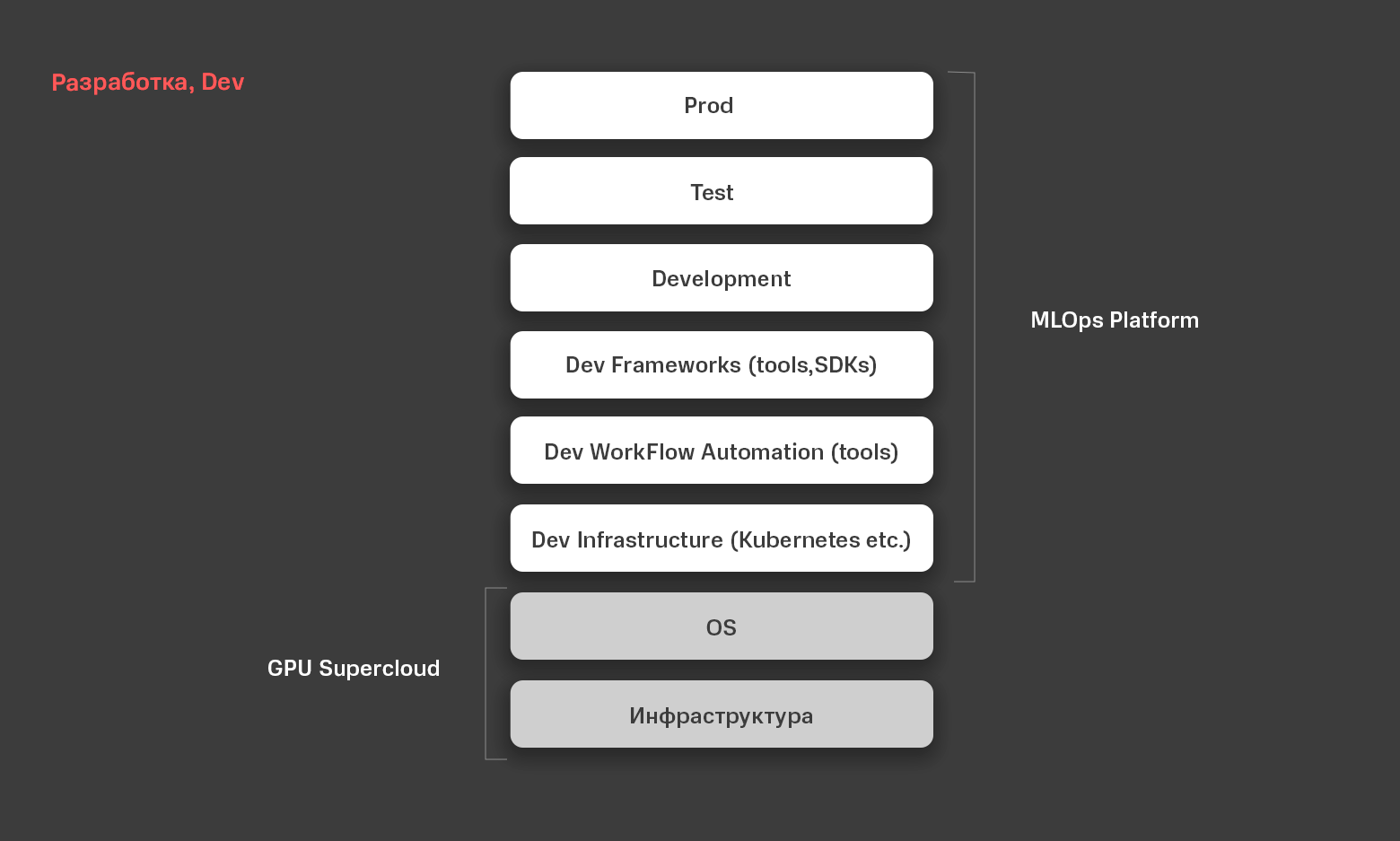
Видя широкий спрос на GPU SuperCloud, мы приняли решение создать и выпустить новый, расширенный продукт. Это высокоуровневый сервис, который позволит заказчикам, работающим с технологиями ИИ, быстрее приступать к проектам, тратить меньше времени на настройку среды и подготовку. Это система класса MLOps.
У наших заказчиков есть спрос на продукт «здесь и сейчас» — чтобы можно было заказать услугу, и сразу же начать пользоваться, не расходуя средства на первоначальную настройку. Мы прикинули, может ли «эволюционировать» наш GPU SuperCloud до чего-то более высокоуровневого, и построили платформу MLOps Platform.
Внутри платформы уже есть все, что нужно разработчику: инфраструктура, набор операционных систем, виртуализация приложений (в нашем случае средствами Kubernetes), инструменты автоматизации процесса разработки. Фреймворки для разработки — Tensorflow, PyTorch, интегрированный Jupyter Notebook & JupyterLab и т.п.
Все инструменты уже преднастроены, все процессы — автоматизированы. Разработчику понадобится только «занести» код, данные и начать работу.
А о том, как устроена наша платформа MLOps Platform изнутри и какие ценности приносит мы расскажем уже в следующей статье. А пока приглашаем вас на бета-тест платформы MLOps Platform — регистрируйтесь по ссылке.

Динамичный рост рынка технологий искусственного интеллекта закономерно породил спрос на инфраструктуру для их разработки. Особенность построения моделей искусственного интеллекта состоит в том, что для их обучения требуются очень мощные и производительные решения. Под катом мы поговорим о том, как начался наш путь в сервисы для ИИ и к чему мы пришли сейчас. Коснемся и исторических моментов, и планов на ближайшее будущее.

Запуск GPU SuperCloud
У нас в #CloudMTS есть сервис GPU SuperCloud. Это комплексное IaaS-решение, которое главным образом служит для обучения моделей искусственного интеллекта и родственных задач. Разработчики получают готовую инфраструктуру, на которой можно развернуть стек необходимых инструментов и приступить к работе. Кроме того, ближайшее время мы планируем «эволюционировать» и запустить SuperCloud в формате PaaS. Но об этом чуть ниже.
Сегодня я хочу поговорить не о технологиях, лежащих в основе SuperCloud, и даже не о самом продукте. Гораздо интереснее будет рассказ об истории его создания: здесь переплелись философия #CloudMTS, актуальные требования рынка и плавное приближение человечества к технологической сингулярности. Но обо всем по порядку.
Идею построить такой сервис мы начали реализовывать еще 2018 году. Его созданию, как я уже писал выше, способствовали бурный рост и развитие различных систем искусственного интеллекта и машинного обучения. По мере того, как стали появляться удобные фреймворки, а технологии становились всё более зрелыми и доступными, число сервисов, построенных на базе ИИ, неуклонно росло. Это и роботизированные голосовые помощники, и программы распознавания изображений/видео, и системы предиктивного анализа и скоринга данных. Всех не перечесть.
Разработка моделей ИИ носит итерационно-инкрементный характер, то есть подразумевает многократный процесс тренировки и тестирования модели. Это позволяет постепенно повышать результативность модели, пока она не выйдет на требуемый уровень. GPU позволяют тренировать модели гораздо быстрее, нежели на CPU. А самые распространенные фреймворки (например, TensorFlow или PyTorch) глубоко оптимизированы для ускорения работы на GPU. Дома или в офисе качественную и мощную систему не построить: необходимы опыт, колоссальные материальные вложения и специализированное оборудование.
Индустрия ИИ начала интенсивно развиваться в прошлом десятилетии, и вот уже в 2013-15 гг. на рынке стали активно появляться сервисы IaaS и PaaS, предназначенные для решения задач искусственного интеллекта и машинного обучения. Лидером GPU решений и инфраструктуры для обучения моделей является компания NVIDIA. Де-факто NVIDIA на сегодняшний день предоставляет ключевые инфраструктурные технологии для построения систем машинного обучения и искусственного интеллекта.
Главным преимуществом сервисной модели является, как это ни банально, оптимизация затрат. Стоимость видеокарт, стоимость серверов, их обслуживание – весьма существенны, если не сказать больше. Далеко не каждая компания, не говоря уже о независимых разработчиках, может позволить себе покупку сервера с графическими адаптерами. Так, всего одна карта NVIDIA V100 стоит порядка 1 000 000 рублей. Наш сервис GPU SuperCloud построен на базе серверов с 8 такими картами. Расскажем о его строительстве с самого начала.

Зимой 2018 года мы приняли решение закупить узлы DGX-1, это самая первая модель в линейке NVIDIA. В 2019 году мы запустили сервис IaaS. Искушенный читатель может сразу задать вопрос: как на DGX-1, не поддерживающих виртуализацию, удалось разделить ресурсы и организовать полноценный сервис для клиентов. Ответ простой: никак. Нам требовалось всего лишь протестировать гипотезу и приобрести новый опыт, поэтому цель построить продукт «на продажу» мы оставили на более поздний период. Тем более, найти покупателя даже на один узел — задачка не из легких.

После череды успешных тестов мы развернули сервис для внутреннего заказчика — 2-х компаний внутри МТС. В частности — «Центр Искусственного Интеллекта МТС». А для строительства услуги мы приняли решение использовать стандартные серверы Huawei с видеокартами Nvidia V100: установили на них гипервизор от VMware и раздробили мощности на несколько виртуальных машин.

Huawei G5500
Благодаря технологиям VMware и NDIVIA GPU Manager мы получили возможность делить ресурсы одного сервера в широком диапазоне. К примеру, в одном сервере 8 графических адаптеров. Мы можем поделить его мощности вплоть до ⅛ адаптера. Собственно, так и появился на свет наш сервис GPU SuperCloud в формате IaaS.
Поделимся с вами внутренним наблюдением: наибольшей популярностью у заказчиков пользуются «половинные», «целые» и 1+1 адаптеры. В течение 2020 г. спрос на сервис вырос буквально вдвое. И да, мы вдвое расширили инфраструктуру в начале 2021 г. Сейчас наши серверы утилизированы на 85% полностью, в скором времени мы начнем закупку дополнительных мощностей.
Плюсы и минусы решения
Согласитесь, было бы нечестно рассказать о своем видении услуги, умолчав о тех ее сторонах, которые нам не нравятся, которые мы хотим улучшить и доработать.
Существенный минус для клиентов — сервис предоставляется в виде «голого» IaaS. С одной стороны, разработчик получает полную свободу действий. С другой — даже при самом стандартном сценарии он вынужден разворачивать фреймворки, настраивать CI/CD и осуществлять первичную конфигурацию системы с нуля. При этом услуга активна, и приходится за нее платить еще до начала полноценного использования. Этот момент нивелируется стоимостью: 2-3 недели, в течение которых услуга «простаивает» для бизнеса, отбиваются в течение пары месяцев.
Что касается модели оплаты — на данный момент у нас отсутствует Pay-as-You-Go. В будущем планируем внедрить эту модель. Однако, с другой стороны, нам удалось сбалансировать месячную стоимость аренды и выдать самую низкую цену на рынке.
Суперкомпьютер GROM
GPU SuperCloud фактически стал опорной точкой для создания суперкомпьютера GROM — третьего по вычислительной мощности на территории Российской федерации.
Он построен на базе NVIDIA DGX A100 и нацелен исключительно на выполнение задач машинного обучения и ИИ. Производительность GROM достигает 2,26 петафлопс. На нем развернут специализированный программный стек, который позволяет реализовать функциональность High Performance Computing (HPC).
Кратко о GROM:
- Суперкомпьютер позволяет массово запускать множество параллельных вычислений сразу на всех узлах (серверах). Решение реализовано на базе программно-аппаратной платформы NVIDIA DGX A100 с графическими процессорами NVIDIA А100 с суммарной GPU RAM 320 Гб в каждом узле.
- Вычислительные узлы объединены высокоскоростной сетью Infiniband. Это коммутируемая компьютерная сеть, которая используется в высокопроизводительных вычислениях и имеет большую пропускную способность и низкие задержки.
- Вычислительный кластер MTS GROM оснащен СХД NetApp на базе технологии NVMe, что обеспечивает сверхбыстрое взаимодействие вычислительных узлов с системой хранения данных для сокращения времени обучения AI-моделей.
- На SuperPOD запускаются массированные задачи обучения: есть возможность выполнять их и на отдельных узлах, и одновременно на всех 20.
- На текущий момент компьютером пользуются внутренние заказчики: одновременно разрабатываются проекты, связанные с распознаванием и синтезом речи, компьютерным зрением и определением графических образов, построением предиктивных моделей и т.п. Над каждой моделью работает отдельная группа разработчиков.
Также мы разрабатываем технологию, которая позволит нам предоставить ресурсы суперкомпьютера внешним заказчикам.
Видя широкий спрос на GPU SuperCloud, мы приняли решение создать и выпустить новый, расширенный продукт. Это высокоуровневый сервис, который позволит заказчикам, работающим с технологиями ИИ, быстрее приступать к проектам, тратить меньше времени на настройку среды и подготовку. Это система класса MLOps.
MLOps Platform
У наших заказчиков есть спрос на продукт «здесь и сейчас» — чтобы можно было заказать услугу, и сразу же начать пользоваться, не расходуя средства на первоначальную настройку. Мы прикинули, может ли «эволюционировать» наш GPU SuperCloud до чего-то более высокоуровневого, и построили платформу MLOps Platform.
Внутри платформы уже есть все, что нужно разработчику: инфраструктура, набор операционных систем, виртуализация приложений (в нашем случае средствами Kubernetes), инструменты автоматизации процесса разработки. Фреймворки для разработки — Tensorflow, PyTorch, интегрированный Jupyter Notebook & JupyterLab и т.п.

Все инструменты уже преднастроены, все процессы — автоматизированы. Разработчику понадобится только «занести» код, данные и начать работу.
А о том, как устроена наша платформа MLOps Platform изнутри и какие ценности приносит мы расскажем уже в следующей статье. А пока приглашаем вас на бета-тест платформы MLOps Platform — регистрируйтесь по ссылке.

