Петр Лухин
Большинство людей, впервые узнающих об автоматической сборке, вероятно, относятся к ней с осторожностью: избыточные трудозатраты на ее организацию и поддержание работоспособности вполне реальны, взамен же им предлагается лишь призрачное улучшение эффективности разработки в будущем. Кто же не понаслышке с ней знаком – более оптимистичны, поскольку знают: ряда проблем при работе с их системой гораздо проще избежать, пока они еще не сформировались, нежели когда становится уже поздно все менять.
Так чем же таким может быть интересна автоматическая сборка, какие возможности можно реализовать с ее помощью и каких результатов достичь? Попробуем разобраться.

Однако перед тем как ее подробно рассматривать, нужно оговорить следующее: тема автоматизации сборок достаточно обширна и существует большое количество статей, как в ней можно реализовать ту или иную задачу. При этом мало, где можно прочитать, как настроить ее у себя от и до, со всеми тонкостями организации и описанием потенциальных возможностей. Поэтому в данной статье хотелось рассмотреть автоматические сборки именно с этой точки зрения. Если же кого-либо заинтересует, как собственно реализуется тот или иной этап, то по возможности для каждого из них будут перечисляться ссылки на дополнительные материалы или же названия программ, которые можно для этого использовать.
При разработке программного обеспечения часто приходится сталкиваться с тем, что время от внесения исправлений в исходный код и до их попадания к пользователю сильно зависит от множества факторов. Чтобы это сделать, необходимо сначала собрать код в виде библиотек, затем удостовериться в их работоспособности, после чего скомпоновать инсталляторы и протестировать работу продукта после их установки – все эти действия не могут быть выполнены мгновенно, поэтому сроки их реализации определяются тем, как именно они будут проходить.
С одной стороны, все вышеуказанные шаги звучат вполне разумно: действительно, зачем отдавать пользователю продукт, который будет содержать ошибки. Однако на практике ситуацию усугубляет постоянный недостаток времени и ресурсов: исправления ошибок необходимо опубликовать как можно скорее, но в то же время ответственные за качество продукта или его сборку сильно заняты на других работах по нему там, где их присутствие более необходимо.
Поэтому периодически часть шагов для выпуска исправлений пропускается (например, не проверяется соответствие кода стандарту оформления) или же выполняется не в полной мере (например, проверяется лишь факт исправления ошибки, но не его возможное влияние на другую функциональность системы). В результате – пользователь получает либо недостаточно хорошо протестированное или же частично неработоспособное решение, а разработчикам впоследствии придется с этим разбираться и неизвестно, сколько времени им на это потребуется.
Однако подобные проблемные ситуации можно если и не обойти, то, по крайней мере, уменьшить их влияние. Заметим, что большинство шагов являются достаточно однообразными и что важнее – хорошо алгоритмизируемы. А, следовательно – если переложить их выполнение на автоматику, то и времени они будут занимать меньше и шанс допустить при их выполнении ошибку или не сделать что-то нужное также минимизируется.

Для того чтобы программа соблюдала все предъявляемые к ней требования необходимо для начала записать их в виде, который будет понятен компьютеру. Подобным преобразованием занимаются разработчики — в результате их работы и появляется исходный код. В зависимости от используемого подхода, он может быть выполнен либо сразу же, либо после прохождения компиляции. Одним из полезных свойств подобного представления является то, что разные люди имеют возможность модифицировать систему независимо друг от друга без непосредственного общения на протяжении всего времени разработки. В отличие от устной речи с кодом проще работать, он лучше сохраняется, для него можно вести историю изменений. При этом единый стиль оформления и структуризации кода позволяет разработчикам думать схожим образом, что также положительно сказывается на производительности совместной работы.
Для упрощения хранения исходного кода и работы с ним множества людей одновременно полезными оказываются различные системы контроля версий. К примеру, к ним можно отнести TFS, GIT или SVN. Их использование в проектах позволяет уменьшить потери от таких проблем как:
При подобном централизованном хранении исходного кода и своевременном его обновлении можно не только не беспокоиться о том, что какая-либо его часть окажется потерянной (при условии, что гарантируется сохранность самого хранилища), но, что более интересно, появляется возможность выполнения действий над ним в автоматическом порядке.
В зависимости от используемой системы хранения версии способ их запуска может разниться: например, периодический по заданному расписанию, или же при внесении изменений в сами хранимые данные. Обычно подобные автоматизированные последовательности действий применяются для того, чтобы произвести проверку качества кода без участия человека и компоновки инсталляторов для передачи пользователям, поэтому часто их просто называют автоматическими сборками.
В качестве основы для организации их запуска, отслеживания изменений кода и публикации результатов мог бы служить и простенький скрипт, запускающийся планировщиком операционной системы, но лучше, если этим будет заниматься более специализированная программа. Например, при использовании TFS разумным выбором может оказаться TFS Build Server. Или же можно воспользоваться универсальными решениями как, например: TeamCity, Hudson или CriuseControl.
Какие же действия можно автоматизировать? На самом деле их можно перечислить достаточно много:
Это лишь часть из того, что в действительности могло бы пригодиться в вашем проекте – на самом деле подобных пунктов можно придумать множество.
Но что именно можно автоматизировать, когда есть только исходный код программы, пусть и хранящийся централизованно? Немного, поскольку в данном случае можно анализировать лишь его файлы, что накладывает свои ограничения: либо пользоваться лишь самыми простыми проверками, либо искать и использовать сторонние статические анализаторы кода, либо же писать собственные. Однако и в данной ситуации можно извлечь пользу:
Результаты данного этапа сборки можно интерпретировать по-разному: часть проверок носит чисто информационный характер (например, статистика), другая – указывает на возможные проблемы в долгосрочной перспективе (например, оформление кода или же замечания статического анализатора), третья же – на прохождение сборки в целом (например, отсутствие файлов в нужных местах). Также не стоит забывать о том, что проверки все же занимают некоторое время, подчас значительное, поэтому в каждом конкретном случае следует расставлять приоритеты: что для вас важнее – обязательное прохождение всех проверок или же максимально быстрый отклик от более поздних этапов сборки.
Как видно из перечисленных выше задач данного этапа, большая часть из них довольно поверхностна (например, сбор статистики или проверка наличия файлов), поэтому для их реализации проще будет написать свои утилиты или скрипты для проверки, нежели искать уже готовые. Другая же — наоборот, позволяет анализировать саму внутреннюю логику кода, что гораздо тяжелее, поэтому предпочтительнее для этого использовать сторонние решения. Например, для статического анализа можно попробовать подключить: PVS-Studio, Cppcheck, RATS, Graudit или же поискать что-либо в других источниках (http://habrahabr.ru/post/75123/, https://ru.wikipedia.org/wiki/Статический_анализ_кода ).
Однако обработка информации об исходных файлах для сборки обычно не является ее непосредственной целью. Поэтому следующим шагом будет компиляция кода программы в набор библиотек, реализующих описанную в нем логику работы. Если его выполнить будет невозможно, то при автоматической сборке этот факт станет ясен вскоре ее запуска, а не через несколько дней, когда потребуется собранная версия. Особенно хорошо эффект наблюдается, когда сборка запускается сразу же после публикации неработоспособного кода, полученного как результата объединения нескольких правок.
Немного забегая вперед, хочется отметить еще один факт. Он заключается в том, что чем больше дополнительной логики вы будете реализовывать в процессе сборки, тем дольше она будет выполняться, что и неудивительно. Поэтому логичным шагом было бы организовать так, чтобы они выполнялись только для кода, который действительно менялся. Как это можно сделать: скорее всего, код вашего продукту не является единой неразделимой сущностью – если это так, значит либо ваш проект еще достаточно мал, либо представляет собой плотно переплетенный клубок взаимосвязей, ухудшающих процесс его понимания не только сторонним людям, но и самим разработчикам.
Для этого проект необходимо разделить на отдельные независимые модули: например, серверное приложение, клиентское приложение, общие библиотеки, внешние собираемые компоненты. Чем больше таких модулей, тем более гибкой будет и разработка и дальнейшее развертывание системы, однако не стоит увлекаться и разбивать чрезмерно сильно – чем мельче будут подобные части, тем больше организационных проблем придется решать при внесении правок сразу в несколько из них одновременно.
Что же это за проблемы: разбиение проекта на независимые модули подразумевает, что для нормальной разработки одного из них совершенно необязательно вносить изменения в остальные. К примеру, если вам необходимо изменить способ получения информации от пользователя в графическом интерфейсе клиентского приложения, то для этого совершенно нет необходимости вносить изменения в серверный код. Значит, разумным решением было бы ограничить тех, кто занимается клиентом, только относящимся к нему исходным кодом, а все относящееся к используемым ими модулям заменить на их уже готовый и протестированный вариант в виде собранных библиотек. Соответственно, какие преимущества мы получим в этом случае:
В результате сборка будет проходить гораздо быстрее, нежели, если бы она последовательно собирала и проверяла все компоненты, а значит, можно будет максимально быстро узнать, были ли внесены ошибки текущими исправлениями или нет. Однако за подобные преимущества придется платить дополнительными накладными расходами на организацию работы с модульной структурой системы:
Реализовывать разбиение системы на модули можно по-разному. Кому-то достаточно разделить код на несколько независимых проектов или решений, кто-то предпочитает использовать подмодули в GIT или что-то аналогичное. Однако какой способ организации вы бы не выбрали: будь то одна последовательная сборка или же оптимизированная для работы с модулями – в результате компиляции кода вы получите набор библиотек, с которыми в принципе уже можно работать, а также, что является более интересным фактом – которые можно протестировать в автоматическом режиме.

Когда появляется необходимость написать какую-либо программу, то сразу же встает вопрос – как проверять, что собранная версия удовлетворяет всем предъявленным требованиям. Хорошо, если их количество невелико – в таком случае можно просмотреть все и основывать свое решение на результате их проверки. Однако обычно это совсем не так – возможных способов использования программы столько, что сложно их даже все описать, не то что бы проверить.
Поэтому за эталон часто принимается другой способ проверки – система считается прошедшей ее в том случае, если она успешно проходит фиксированные сценарии, то есть предопределенные заранее последовательности действий, выбранные как наиболее часто встречающиеся при работе с системой среди пользователей. Способ вполне разумный, поскольку если ошибки все же обнаружатся в выпущенной версии, то более критичными окажутся те из них, которые будут мешать большинству людей, а проявляющиеся лишь иногда в редко используемой функциональности окажутся менее приоритетными.
Как же тогда проводят тестирование в этом случае: готовая для разворачивания система передается тестерам с одной целью – чтобы те попробовали пройти все предопределенные сценарии работы с ней и сообщить разработчикам, столкнулись ли они с какими-либо ошибками, а заодно было ли найдено что-либо непосредственно не относящееся к сценариям. При этом подобное тестирование может затянуться на несколько дней, даже если тестеров будет несколько.
Находимые ошибки и замечания во время тестирования оказывают на время его проведения самое непосредственное влияние: если ошибок найдено не будет, то его потребуется меньше, если же наоборот – то они могут его значительно увеличить за счет долгого определения условий воспроизведения ошибок или способов их обхода, чтобы можно было протестировать остальные сценарии. Поэтому хорошим вариантом оказался бы тот, в котором при тестировании возникало бы как можно меньше замечаний, и оно могло бы закончиться быстрее без потери качества проверки.
Часть ошибок, которые могут быть привнесены в исходный код, выявляет процесс его компиляции. Но он не гарантирует, что программа будет работать стабильно и выполнять все требования к ней. Ошибки же, которые в принципе могут в ней содержаться, можно разделить по сложности их выявления и исправления на следующие категории:
Обычно проверки на данном уровне реализуются с помощью юнит-тестов и интеграционных тестов. В идеале, для каждого метода программы должен быть набор тех или иных проверок, но часто это сделать проблематично: либо из-за зависимости проверяемого кода от окружения, в котором он должен выполняться, либо из-за дополнительных трудозатрат на их создание и сопровождение.
Однако при выделении достаточных ресурсов на формирование и поддержание инфраструктуры автоматического тестирования собираемых библиотек можно обеспечить выявление низкоуровневых ошибок еще до того, как версия попадет к тестерам. А это в свою очередь означает, что они будут реже натыкаться на явные программные ошибки и падения и, следовательно, быстрее проверять систему без потери качества.
После того, как сборка пройдет этап тестирования библиотек, о получаемой системе можно сказать следующее:
Таким образом, получается, что на данном этапе уже отметено в сторону достаточно большое количество ошибок, поэтому следующие действия можно производить с учетом этого факта. Что же можно сделать дальше:
Здесь стоит упомянуть о приоритетах. Что важнее для вашей системы: ее работоспособность или соблюдение принятых правил разработки? Возможны следующие варианты:
Однако стоит понимать, что в любом случае сборку следует понимать успешно выполненной только при прохождении всех ее этапов – приоритизация в данном случае говорит лишь о том, на что нужно сделать упор в первую очередь. Например, сборку документации можно вынести на этап после компоновки инсталляторов, чтобы их можно было бы получить как можно раньше, а также, чтобы в случае невозможности их формирования документация даже и не пыталась собираться.
Для сборки документации в .NET проектах очень удобно использовать программу SandCastle (статья про использование: http://habrahabr.ru/post/102177/). Вполне возможно, что для других языков программирования также можно отыскать что-то аналогичное.

После прохождения этапа тестирования библиотек существует два основных направления дальнейшего выполнения сборки. И если один из них заключается в проверке ее соответствия некоторым техническим требованиям или сборке документации, то другой заключается в подготовке версии для распространения.
Внутренняя организация разработки системы обычно мало интересна конечному пользователю, поскольку для него важно лишь то, сможет ли он установить ее себе на компьютер, будет ли она корректно обновляться, будет ли она предоставлять заявленную функциональность и будут ли возникать при ее использовании какие-либо дополнительные проблемы.
Поэтому для достижения данной цели и необходимо из набора разрозненных библиотек получить то, что можно будет ему передать. Однако успешное их формирование еще не означает, что все в порядке – их можно и нужно еще раз протестировать, но на этот раз, попробовав выполнять действия не как компьютер, а как бы их выполнял сам пользователь.
Способов компоновки инсталляторов существует достаточно большое количество: к примеру, можно воспользоваться стандартным проектом установщика в Visual Studio или же создавать его в InstallShield. Про множество других вариантов можно почитать на IXBT (http://www.ixbt.com/soft/installers-1.shtml, http://www.ixbt.com/soft/installers-2.shtml, http://www.ixbt.com/soft/installers-3.shtml).

Проверять работоспособность системы можно по-разному: сначала во время тестирования библиотек проверяются отдельные узлы, окончательное решение же принимают тестеры. Однако есть возможность еще сильнее упростить им работу – попробовать автоматически пройтись по основным цепочкам работы с системой и выполнить все те действия, которые мог бы выполнять пользователь при реальном использовании.
Подобное автоматическое тестирование часто называют интерфейсным, поскольку во время его выполнения на экране компьютера происходит все то, что было бы у обычных людей: отображение окон, обработка событий наведения или нажатия мыши, набор текста в поля ввода и так далее. С одной стороны это дает высокую степень проверки работоспособности системы – основные сценарии и требования, предъявляемые к ней, описываются на языке пользователей и поэтому могут быть записаны в виде автоматизируемых алгоритмов, однако здесь появляются и дополнительные сложности:
Суммируя все эти замечания можно прийти к следующему выводу: интерфейсное тестирование поможет удостовериться в том, что все проверяемые требования выполняются в точности как они были сформулированы, и все проверки, даже несмотря на затраты по времени, будут выполнены быстрее, нежели если бы их проводили тестеры. Однако за все приходится платить: в данном случае платить придется трудозатратами на поддержание инфраструктуры интерфейсных тестов, и быть готовыми к тому, что они часто будут не проходить.
Если же подобные сложности вас не останавливают, то имеет смысл обратить внимание на следующие инструменты, с помощью которых можно организовать интерфейсное тестирование: например, TestComplete, Selenium, HP QuickTest, IBM Rational Robot или UI Automation.
Какой же результат получается в итоге? При наличии централизованного хранилища исходного кода существует возможность запуска автоматических сборок: по расписанию или же в момент внесения изменений. При этом будет выполнен некоторый набор действий, результатом которых будут:
Таким образом, можно сказать следующее: автоматическая сборка позволяет снять огромный пласт работ с разработчиков и тестеров системы на себя, причем выполняться все это будет без участия пользователя в фоновом режиме. Можно сдать свои исправления в центральное хранилище и знать, что через какое-то время будет готово все для передачи версии пользователю или на окончательное тестирование и не беспокоиться обо всех промежуточных шагах – или же, по крайней мере, узнать о том, что правки были некорректными, как можно скорее.
Напоследок хотелось бы немного коснуться того, что называется непрерывной интеграцией. Основным принципом данного подхода является то, что после внесения исправлений можно как можно раньше узнать, приводят ли правки к ошибкам или нет. При наличии автоматической сборки это сделать достаточно просто, ведь она сама по себе уже почти, что реализует данный принцип – ее узким местом является только время прохождения.
Если рассматривать все этапы, как они были описаны выше, то станет ясно, что некоторые их составные части с одной стороны занимают довольно большое время (например, статический анализ кода или сборка документации), а с другой они проявляют себя лишь в долгосрочной перспективе. Поэтому разумно было бы перераспределить части автоматической сборки так, чтобы то, что гарантированно помешает выпуску версии (невозможность компиляции кода, падения в тестах), проверялось бы как можно раньше. Например, сначала можно собрать библиотеки, прогнать над ними тесты и получить инсталляторы, а статический анализ кода, сборку документации и интерфейсное тестирование отложить на более позднее время.
Что касается ошибок, возникающих при работе сборки, то их можно разделить на две группы: критичные для нее и некритичные. К первым можно отнести те этапы, отрицательный результат которых бы лишал смысла запускать последующие. Например, если не компилируется код, то зачем запускать тесты, а если не прошли они, то не нужно собирать документацию. Подобное досрочное прерывание процессов сборок позволяет завершать их как можно раньше, чтобы не перегружать компьютеры, на которых они выполняются. Если же отрицательный результат этапа – это тоже результат (например, оформление кода не по стандарту не мешает отдавать инсталляторы пользователю), то имеет смысл учитывать это при дальнейшем изучении, но сборку не останавливать.
Как было описано выше, довольно большое количество действий при сборке системы можно переложить на автоматику: чем меньше однообразных задач будет выполняться людьми, тем эффективнее будет их работа. Однако для полноты статьи одной только теоретической части было бы мало – ведь если не знать, реализуемо ли все это на практике, то и неясно, сколько сил потребуется, чтобы настроить автоматическую сборку самим.
Данная статья была написана не с чистого листа. На протяжении нескольких лет в нашей компании не раз приходилось сталкиваться с задачами оптимизации эффективности разработки и тестирования программных продуктов. В итоге самые частые из них были собраны вместе, обобщены, дополнены идеями и соображениями и оформлены в виде статьи. На текущий момент автоматические сборки у нас наиболее активно используются при разработке и тестировании системы электронного документооборота «Е1 ЕВФРАТ». С практической точки зрения то, как именно реализуются описанные в статье принципы при ее создании, могло бы оказаться довольно полезным для ознакомления, однако будет лучше написать на эту тему отдельную статью, чем пытаться дополнить текущую.
Большинство людей, впервые узнающих об автоматической сборке, вероятно, относятся к ней с осторожностью: избыточные трудозатраты на ее организацию и поддержание работоспособности вполне реальны, взамен же им предлагается лишь призрачное улучшение эффективности разработки в будущем. Кто же не понаслышке с ней знаком – более оптимистичны, поскольку знают: ряда проблем при работе с их системой гораздо проще избежать, пока они еще не сформировались, нежели когда становится уже поздно все менять.
Так чем же таким может быть интересна автоматическая сборка, какие возможности можно реализовать с ее помощью и каких результатов достичь? Попробуем разобраться.

Часть 0: Вместо введения
Однако перед тем как ее подробно рассматривать, нужно оговорить следующее: тема автоматизации сборок достаточно обширна и существует большое количество статей, как в ней можно реализовать ту или иную задачу. При этом мало, где можно прочитать, как настроить ее у себя от и до, со всеми тонкостями организации и описанием потенциальных возможностей. Поэтому в данной статье хотелось рассмотреть автоматические сборки именно с этой точки зрения. Если же кого-либо заинтересует, как собственно реализуется тот или иной этап, то по возможности для каждого из них будут перечисляться ссылки на дополнительные материалы или же названия программ, которые можно для этого использовать.
При разработке программного обеспечения часто приходится сталкиваться с тем, что время от внесения исправлений в исходный код и до их попадания к пользователю сильно зависит от множества факторов. Чтобы это сделать, необходимо сначала собрать код в виде библиотек, затем удостовериться в их работоспособности, после чего скомпоновать инсталляторы и протестировать работу продукта после их установки – все эти действия не могут быть выполнены мгновенно, поэтому сроки их реализации определяются тем, как именно они будут проходить.
С одной стороны, все вышеуказанные шаги звучат вполне разумно: действительно, зачем отдавать пользователю продукт, который будет содержать ошибки. Однако на практике ситуацию усугубляет постоянный недостаток времени и ресурсов: исправления ошибок необходимо опубликовать как можно скорее, но в то же время ответственные за качество продукта или его сборку сильно заняты на других работах по нему там, где их присутствие более необходимо.
Поэтому периодически часть шагов для выпуска исправлений пропускается (например, не проверяется соответствие кода стандарту оформления) или же выполняется не в полной мере (например, проверяется лишь факт исправления ошибки, но не его возможное влияние на другую функциональность системы). В результате – пользователь получает либо недостаточно хорошо протестированное или же частично неработоспособное решение, а разработчикам впоследствии придется с этим разбираться и неизвестно, сколько времени им на это потребуется.
Однако подобные проблемные ситуации можно если и не обойти, то, по крайней мере, уменьшить их влияние. Заметим, что большинство шагов являются достаточно однообразными и что важнее – хорошо алгоритмизируемы. А, следовательно – если переложить их выполнение на автоматику, то и времени они будут занимать меньше и шанс допустить при их выполнении ошибку или не сделать что-то нужное также минимизируется.
Часть 1: Код
Для того чтобы программа соблюдала все предъявляемые к ней требования необходимо для начала записать их в виде, который будет понятен компьютеру. Подобным преобразованием занимаются разработчики — в результате их работы и появляется исходный код. В зависимости от используемого подхода, он может быть выполнен либо сразу же, либо после прохождения компиляции. Одним из полезных свойств подобного представления является то, что разные люди имеют возможность модифицировать систему независимо друг от друга без непосредственного общения на протяжении всего времени разработки. В отличие от устной речи с кодом проще работать, он лучше сохраняется, для него можно вести историю изменений. При этом единый стиль оформления и структуризации кода позволяет разработчикам думать схожим образом, что также положительно сказывается на производительности совместной работы.
Для упрощения хранения исходного кода и работы с ним множества людей одновременно полезными оказываются различные системы контроля версий. К примеру, к ним можно отнести TFS, GIT или SVN. Их использование в проектах позволяет уменьшить потери от таких проблем как:
- Получение нескольких вариантов одного и того же кода при редактировании файла несколькими людьми
- Потери исходного кода какого-либо важного компонента во время переезда или по причине забывчивости одного из сотрудников
- Поиска автора функциональности, в которой была обнаружена ошибка или в которую необходимо внести доработки
При подобном централизованном хранении исходного кода и своевременном его обновлении можно не только не беспокоиться о том, что какая-либо его часть окажется потерянной (при условии, что гарантируется сохранность самого хранилища), но, что более интересно, появляется возможность выполнения действий над ним в автоматическом порядке.
В зависимости от используемой системы хранения версии способ их запуска может разниться: например, периодический по заданному расписанию, или же при внесении изменений в сами хранимые данные. Обычно подобные автоматизированные последовательности действий применяются для того, чтобы произвести проверку качества кода без участия человека и компоновки инсталляторов для передачи пользователям, поэтому часто их просто называют автоматическими сборками.
В качестве основы для организации их запуска, отслеживания изменений кода и публикации результатов мог бы служить и простенький скрипт, запускающийся планировщиком операционной системы, но лучше, если этим будет заниматься более специализированная программа. Например, при использовании TFS разумным выбором может оказаться TFS Build Server. Или же можно воспользоваться универсальными решениями как, например: TeamCity, Hudson или CriuseControl.
Часть 2: Тестирование кода
Какие же действия можно автоматизировать? На самом деле их можно перечислить достаточно много:
- Компоновка инсталляторов – пользователям системы обычно интересна именно она сама, а не то, как она была написана или собрана, а значит, они должны получить возможность ее у себя установить
- Формирование обновлений – если ваша система поддерживает технологию обновлений, то хорошим вариантом было бы не только получение полноценных инсталляторов, но и набора инкрементальных патчей для быстрого перехода с одной версии на другую
- Тестирование системы – пользователи должны получать только те версии, которые являются стабильными и реализующими требуемую функциональность, поэтому их необходимо проверять, при этом часть проверок можно переложить на автоматику
- Документирование – данное действие может оказаться полезным, как если вы отдаете внешнее API системы сторонним разработчикам, так и при внутренней разработке, поскольку, чем больше система и чем больше в ней кода, тем становится все меньше людей, знающих ее досконально
- Проверка совместимости версий – если сравнивать различные версии собираемых библиотек, то можно вовремя заметить, когда доступное в каждом модуле внешнее API претерпевает изменения: если что-то в нем перестает быть видимым извне – использующие его модули или программы могут оказаться несовместимы с новой версией; и наоборот – чрезмерное количество непрописанных в документации API функций говорит о том, что либо их необходимо в нее добавить, либо же скрыть от посторонних глаз
- Проверка принятых правил и стандартов – когда код оформлен одинаково, то любой из разработчиков системы сможет в нем свободно ориентироваться. Если же при поиске чего-либо оно не обнаруживается в ожидаемом месте или записано в нестандартной форме, то, даже если искомое и будет найдено или осмыслено, на это будет потрачено дополнительное время, которого можно было бы избежать
- Проверка самой сборки – бывает довольно неприятно, когда после длительного использования автоматической сборки обнаруживается, что она делала не совсем то, для чего предназначалась: например, тесты запускались не все из-за того, что они не были найдены, или же в ней не производилась сборка документации редко используемого модуля, которая внезапно срочно понадобилась
Это лишь часть из того, что в действительности могло бы пригодиться в вашем проекте – на самом деле подобных пунктов можно придумать множество.
Но что именно можно автоматизировать, когда есть только исходный код программы, пусть и хранящийся централизованно? Немного, поскольку в данном случае можно анализировать лишь его файлы, что накладывает свои ограничения: либо пользоваться лишь самыми простыми проверками, либо искать и использовать сторонние статические анализаторы кода, либо же писать собственные. Однако и в данной ситуации можно извлечь пользу:
- Можно проверять наличие файлов или директорий, способы их именования, правила вложенности: вряд ли это пригодится большинству разработчиков, но порой встречаются и подобные ситуации
- Анализировать содержимое файлов исходного кода для проверки соблюдения принятых стандартов: например, какое-то время распространенным было правило в начале каждого файла размещать многострочный комментарий с описание функциональности и указанием автора
- Проверять соблюдение требований, предъявляемых к файлам внешними приложениями: например, если в дальнейшем в сборке предполагается запуск тестов, то нужно удостовериться, что файл, содержащий их описание, настроен корректно и тесты при своем запуске смогут обнаружить проверяемые библиотеки
- Статический анализ кода – когда разработчики совершают ошибки в программе по невнимательности, то бывают случаи, в которых подобные некорректности не выявляются даже тестами и только пристальное изучение исходного кода помогает их найти. Внешние же анализаторы позволяют выявить такие ситуации автоматически, что сильно упрощает разработку
- Сбор разнообразной статистики: количество строк в файлах кода, есть ли полностью совпадающие куски функций, самые редактируемые файлы – не самая важная информация, но иногда она дает возможность взглянуть на проект немного иначе
Результаты данного этапа сборки можно интерпретировать по-разному: часть проверок носит чисто информационный характер (например, статистика), другая – указывает на возможные проблемы в долгосрочной перспективе (например, оформление кода или же замечания статического анализатора), третья же – на прохождение сборки в целом (например, отсутствие файлов в нужных местах). Также не стоит забывать о том, что проверки все же занимают некоторое время, подчас значительное, поэтому в каждом конкретном случае следует расставлять приоритеты: что для вас важнее – обязательное прохождение всех проверок или же максимально быстрый отклик от более поздних этапов сборки.
Как видно из перечисленных выше задач данного этапа, большая часть из них довольно поверхностна (например, сбор статистики или проверка наличия файлов), поэтому для их реализации проще будет написать свои утилиты или скрипты для проверки, нежели искать уже готовые. Другая же — наоборот, позволяет анализировать саму внутреннюю логику кода, что гораздо тяжелее, поэтому предпочтительнее для этого использовать сторонние решения. Например, для статического анализа можно попробовать подключить: PVS-Studio, Cppcheck, RATS, Graudit или же поискать что-либо в других источниках (http://habrahabr.ru/post/75123/, https://ru.wikipedia.org/wiki/Статический_анализ_кода ).
Часть 3: Сборка
Однако обработка информации об исходных файлах для сборки обычно не является ее непосредственной целью. Поэтому следующим шагом будет компиляция кода программы в набор библиотек, реализующих описанную в нем логику работы. Если его выполнить будет невозможно, то при автоматической сборке этот факт станет ясен вскоре ее запуска, а не через несколько дней, когда потребуется собранная версия. Особенно хорошо эффект наблюдается, когда сборка запускается сразу же после публикации неработоспособного кода, полученного как результата объединения нескольких правок.
Немного забегая вперед, хочется отметить еще один факт. Он заключается в том, что чем больше дополнительной логики вы будете реализовывать в процессе сборки, тем дольше она будет выполняться, что и неудивительно. Поэтому логичным шагом было бы организовать так, чтобы они выполнялись только для кода, который действительно менялся. Как это можно сделать: скорее всего, код вашего продукту не является единой неразделимой сущностью – если это так, значит либо ваш проект еще достаточно мал, либо представляет собой плотно переплетенный клубок взаимосвязей, ухудшающих процесс его понимания не только сторонним людям, но и самим разработчикам.
Для этого проект необходимо разделить на отдельные независимые модули: например, серверное приложение, клиентское приложение, общие библиотеки, внешние собираемые компоненты. Чем больше таких модулей, тем более гибкой будет и разработка и дальнейшее развертывание системы, однако не стоит увлекаться и разбивать чрезмерно сильно – чем мельче будут подобные части, тем больше организационных проблем придется решать при внесении правок сразу в несколько из них одновременно.
Что же это за проблемы: разбиение проекта на независимые модули подразумевает, что для нормальной разработки одного из них совершенно необязательно вносить изменения в остальные. К примеру, если вам необходимо изменить способ получения информации от пользователя в графическом интерфейсе клиентского приложения, то для этого совершенно нет необходимости вносить изменения в серверный код. Значит, разумным решением было бы ограничить тех, кто занимается клиентом, только относящимся к нему исходным кодом, а все относящееся к используемым ими модулям заменить на их уже готовый и протестированный вариант в виде собранных библиотек. Соответственно, какие преимущества мы получим в этом случае:
- Сборка конкретного модуля не будет собирать относящиеся к нему зависимые компоненты, если правки в них не вносились
- Нет необходимости проверять качество внутренней логики работы зависимых модулей, поскольку они считаются уже в достаточной степени протестированными
В результате сборка будет проходить гораздо быстрее, нежели, если бы она последовательно собирала и проверяла все компоненты, а значит, можно будет максимально быстро узнать, были ли внесены ошибки текущими исправлениями или нет. Однако за подобные преимущества придется платить дополнительными накладными расходами на организацию работы с модульной структурой системы:
- Если правки функциональности затрагивают несколько модулей, а не один, то необходимо будет определить, в каком порядке следует их выполнять, и только после этого приступать к компиляции. Было бы неплохо, если бы подобное определение могло происходить в автоматическом режиме
- Сборка каждого отдельного модуля должна гарантировать не только его работоспособность, но также обеспечивать работоспособность зависимых от него модулей. Чтобы решить эту проблему можно предусмотреть фиксированные интерфейсы, которые модуль должен реализовывать и которые будут присутствовать в каждой его версии. Это может оказаться довольно проблематичным, однако в крупных или сильно распределенных проектах подобные работы все же оказываются предпочтительнее исправления ошибок совместимости, которые иначе могут возникнуть
Реализовывать разбиение системы на модули можно по-разному. Кому-то достаточно разделить код на несколько независимых проектов или решений, кто-то предпочитает использовать подмодули в GIT или что-то аналогичное. Однако какой способ организации вы бы не выбрали: будь то одна последовательная сборка или же оптимизированная для работы с модулями – в результате компиляции кода вы получите набор библиотек, с которыми в принципе уже можно работать, а также, что является более интересным фактом – которые можно протестировать в автоматическом режиме.
Часть 4: Тестирование библиотек
Когда появляется необходимость написать какую-либо программу, то сразу же встает вопрос – как проверять, что собранная версия удовлетворяет всем предъявленным требованиям. Хорошо, если их количество невелико – в таком случае можно просмотреть все и основывать свое решение на результате их проверки. Однако обычно это совсем не так – возможных способов использования программы столько, что сложно их даже все описать, не то что бы проверить.
Поэтому за эталон часто принимается другой способ проверки – система считается прошедшей ее в том случае, если она успешно проходит фиксированные сценарии, то есть предопределенные заранее последовательности действий, выбранные как наиболее часто встречающиеся при работе с системой среди пользователей. Способ вполне разумный, поскольку если ошибки все же обнаружатся в выпущенной версии, то более критичными окажутся те из них, которые будут мешать большинству людей, а проявляющиеся лишь иногда в редко используемой функциональности окажутся менее приоритетными.
Как же тогда проводят тестирование в этом случае: готовая для разворачивания система передается тестерам с одной целью – чтобы те попробовали пройти все предопределенные сценарии работы с ней и сообщить разработчикам, столкнулись ли они с какими-либо ошибками, а заодно было ли найдено что-либо непосредственно не относящееся к сценариям. При этом подобное тестирование может затянуться на несколько дней, даже если тестеров будет несколько.
Находимые ошибки и замечания во время тестирования оказывают на время его проведения самое непосредственное влияние: если ошибок найдено не будет, то его потребуется меньше, если же наоборот – то они могут его значительно увеличить за счет долгого определения условий воспроизведения ошибок или способов их обхода, чтобы можно было протестировать остальные сценарии. Поэтому хорошим вариантом оказался бы тот, в котором при тестировании возникало бы как можно меньше замечаний, и оно могло бы закончиться быстрее без потери качества проверки.
Часть ошибок, которые могут быть привнесены в исходный код, выявляет процесс его компиляции. Но он не гарантирует, что программа будет работать стабильно и выполнять все требования к ней. Ошибки же, которые в принципе могут в ней содержаться, можно разделить по сложности их выявления и исправления на следующие категории:
- Тривиальные ошибки – к ним относятся, например, опечатки в сообщениях или мелкие корректировки. Часто больше времени тратится на донесение информации до разработчика, нежели на само исправление. Автоматизация проверок на наличие подобных ошибок возможна, но обычно не стоит того, чтобы ее реализовывать
- Ошибки отдельных частей кода – могут возникать, если разработчик не предусмотрел все возможные варианты использования его методов, в результате чего они оказываются неработоспособными или возвращают неожиданный результат. В отличие от остальных ситуаций подобные ошибки вполне могут быть выявлены в автоматическом режиме – при написании разработчик обычно понимает, как будет использоваться его код, а значит, может описать это в виде проверок
- Ошибки взаимодействия частей кода – если разработкой каждой конкретной части занимается обычно один человек, то когда частей много, то понимание принципов их совместной работы также является некоторым общим знанием. В данном случае несколько сложнее определить все варианты использования кода, однако, при должной проработке подобные ситуации также можно оформить в виде автоматических проверок, правда, уже лишь для некоторых сценариев его работы
- Ошибки логики – они же ошибки несоответствия работы программы предъявленным к ней требованиям. Достаточно сложно описать их в виде автоматизированных проверок, поскольку они и сами проверки формулируются в разной терминологии. Поэтому ошибки подобного рода лучше выявлять при ручном тестировании
Обычно проверки на данном уровне реализуются с помощью юнит-тестов и интеграционных тестов. В идеале, для каждого метода программы должен быть набор тех или иных проверок, но часто это сделать проблематично: либо из-за зависимости проверяемого кода от окружения, в котором он должен выполняться, либо из-за дополнительных трудозатрат на их создание и сопровождение.
Однако при выделении достаточных ресурсов на формирование и поддержание инфраструктуры автоматического тестирования собираемых библиотек можно обеспечить выявление низкоуровневых ошибок еще до того, как версия попадет к тестерам. А это в свою очередь означает, что они будут реже натыкаться на явные программные ошибки и падения и, следовательно, быстрее проверять систему без потери качества.
Часть 5: Анализ библиотек
После того, как сборка пройдет этап тестирования библиотек, о получаемой системе можно сказать следующее:
- В дополнение к исходному коду программы для последующих этапов также доступны скомпилированные библиотеки
- Существует некоторый формальный способ проверки части функциональности, и он был успешно пройден
Таким образом, получается, что на данном этапе уже отметено в сторону достаточно большое количество ошибок, поэтому следующие действия можно производить с учетом этого факта. Что же можно сделать дальше:
- К примеру, сборка документации: операция это небыстрая и нужна только для выпущенных версий, поэтому в случае наличия явных программных ошибок формировать ее было бы довольно бессмысленно
- Поскольку все собираемые библиотеки доступны для анализа, можно произвести проверку совместимости версий: например, удостовериться, что все заявленные методы внешнего API доступны для использования и наоборот – закрыто ли то, что в требованиях не было указано
Здесь стоит упомянуть о приоритетах. Что важнее для вашей системы: ее работоспособность или соблюдение принятых правил разработки? Возможны следующие варианты:
- Если получение пользователем программы более важно, нежели упрощение ее поддержки, то имеет смысл сконцентрироваться на сборке и проверке инсталляторов
- Если же важно, чтобы программа всегда соответствовала заявленным требованиям и не имела недокументированных возможностей API, тогда более приоритетным будет анализ библиотек
Однако стоит понимать, что в любом случае сборку следует понимать успешно выполненной только при прохождении всех ее этапов – приоритизация в данном случае говорит лишь о том, на что нужно сделать упор в первую очередь. Например, сборку документации можно вынести на этап после компоновки инсталляторов, чтобы их можно было бы получить как можно раньше, а также, чтобы в случае невозможности их формирования документация даже и не пыталась собираться.
Для сборки документации в .NET проектах очень удобно использовать программу SandCastle (статья про использование: http://habrahabr.ru/post/102177/). Вполне возможно, что для других языков программирования также можно отыскать что-то аналогичное.
Часть 6: Сборка инсталляторов и обновлений
После прохождения этапа тестирования библиотек существует два основных направления дальнейшего выполнения сборки. И если один из них заключается в проверке ее соответствия некоторым техническим требованиям или сборке документации, то другой заключается в подготовке версии для распространения.
Внутренняя организация разработки системы обычно мало интересна конечному пользователю, поскольку для него важно лишь то, сможет ли он установить ее себе на компьютер, будет ли она корректно обновляться, будет ли она предоставлять заявленную функциональность и будут ли возникать при ее использовании какие-либо дополнительные проблемы.
Поэтому для достижения данной цели и необходимо из набора разрозненных библиотек получить то, что можно будет ему передать. Однако успешное их формирование еще не означает, что все в порядке – их можно и нужно еще раз протестировать, но на этот раз, попробовав выполнять действия не как компьютер, а как бы их выполнял сам пользователь.
Способов компоновки инсталляторов существует достаточно большое количество: к примеру, можно воспользоваться стандартным проектом установщика в Visual Studio или же создавать его в InstallShield. Про множество других вариантов можно почитать на IXBT (http://www.ixbt.com/soft/installers-1.shtml, http://www.ixbt.com/soft/installers-2.shtml, http://www.ixbt.com/soft/installers-3.shtml).
Часть 7: Интерфейсное тестирование
Проверять работоспособность системы можно по-разному: сначала во время тестирования библиотек проверяются отдельные узлы, окончательное решение же принимают тестеры. Однако есть возможность еще сильнее упростить им работу – попробовать автоматически пройтись по основным цепочкам работы с системой и выполнить все те действия, которые мог бы выполнять пользователь при реальном использовании.
Подобное автоматическое тестирование часто называют интерфейсным, поскольку во время его выполнения на экране компьютера происходит все то, что было бы у обычных людей: отображение окон, обработка событий наведения или нажатия мыши, набор текста в поля ввода и так далее. С одной стороны это дает высокую степень проверки работоспособности системы – основные сценарии и требования, предъявляемые к ней, описываются на языке пользователей и поэтому могут быть записаны в виде автоматизируемых алгоритмов, однако здесь появляются и дополнительные сложности:
- Интерфейсное тестирование очень нестабильно: если логика работы небольшой части кода или нескольких взаимодействующих областей довольно редко меняется, то интерфейсное тестирование затрагивает на порядок больше – стоит поменяться отображению, как будет неясно куда щелкать, стоит изменить имя окна и станет неясно, появилось оно или нет
- Тесты выполняются гораздо дольше, чем обычные: нужно не только проверить, что программа работает, нужно удостовериться, что она устанавливается, обновляется, корректно удаляется, что все сценарии проходятся и возможно не единожды. Отображение информации на экране и взаимодействие с программой через интерфейс также сильно замедляет проверку
Суммируя все эти замечания можно прийти к следующему выводу: интерфейсное тестирование поможет удостовериться в том, что все проверяемые требования выполняются в точности как они были сформулированы, и все проверки, даже несмотря на затраты по времени, будут выполнены быстрее, нежели если бы их проводили тестеры. Однако за все приходится платить: в данном случае платить придется трудозатратами на поддержание инфраструктуры интерфейсных тестов, и быть готовыми к тому, что они часто будут не проходить.
Если же подобные сложности вас не останавливают, то имеет смысл обратить внимание на следующие инструменты, с помощью которых можно организовать интерфейсное тестирование: например, TestComplete, Selenium, HP QuickTest, IBM Rational Robot или UI Automation.
Часть 8: Публикация результатов
Какой же результат получается в итоге? При наличии централизованного хранилища исходного кода существует возможность запуска автоматических сборок: по расписанию или же в момент внесения изменений. При этом будет выполнен некоторый набор действий, результатом которых будут:
- Инсталляторы и обновления системы – обычно являются основной целью сборки, поскольку в итоге именно они будут передаваться пользователю
- Результаты тестирования – автоматизированная сборка позволяет узнать о достаточно крупном пласте ошибок еще до того, как версия будет отдаваться тестерам
- Документация – может оказаться полезной как самим разработчикам системы, так и тем, кто будет с ней интегрироваться
- Результаты проверки совместимости – позволяет удостовериться, что неизвестные вам доработки для системы будут работать с новой ее версией
Таким образом, можно сказать следующее: автоматическая сборка позволяет снять огромный пласт работ с разработчиков и тестеров системы на себя, причем выполняться все это будет без участия пользователя в фоновом режиме. Можно сдать свои исправления в центральное хранилище и знать, что через какое-то время будет готово все для передачи версии пользователю или на окончательное тестирование и не беспокоиться обо всех промежуточных шагах – или же, по крайней мере, узнать о том, что правки были некорректными, как можно скорее.
Часть 9: Оптимизация
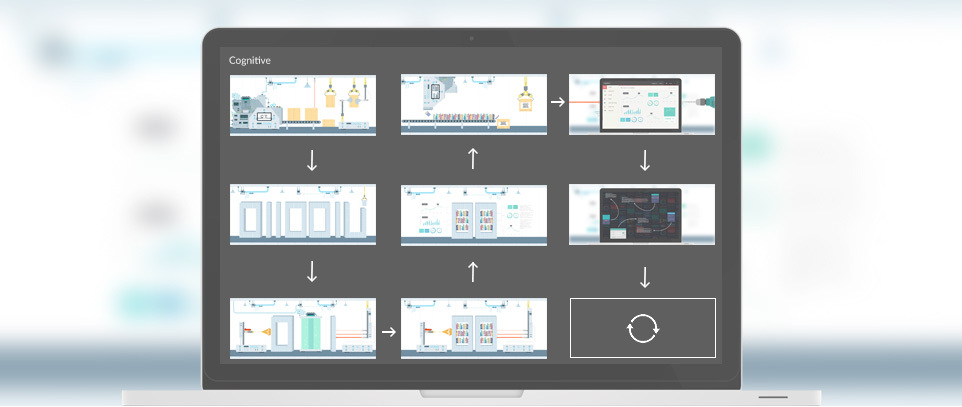
Напоследок хотелось бы немного коснуться того, что называется непрерывной интеграцией. Основным принципом данного подхода является то, что после внесения исправлений можно как можно раньше узнать, приводят ли правки к ошибкам или нет. При наличии автоматической сборки это сделать достаточно просто, ведь она сама по себе уже почти, что реализует данный принцип – ее узким местом является только время прохождения.
Если рассматривать все этапы, как они были описаны выше, то станет ясно, что некоторые их составные части с одной стороны занимают довольно большое время (например, статический анализ кода или сборка документации), а с другой они проявляют себя лишь в долгосрочной перспективе. Поэтому разумно было бы перераспределить части автоматической сборки так, чтобы то, что гарантированно помешает выпуску версии (невозможность компиляции кода, падения в тестах), проверялось бы как можно раньше. Например, сначала можно собрать библиотеки, прогнать над ними тесты и получить инсталляторы, а статический анализ кода, сборку документации и интерфейсное тестирование отложить на более позднее время.
Что касается ошибок, возникающих при работе сборки, то их можно разделить на две группы: критичные для нее и некритичные. К первым можно отнести те этапы, отрицательный результат которых бы лишал смысла запускать последующие. Например, если не компилируется код, то зачем запускать тесты, а если не прошли они, то не нужно собирать документацию. Подобное досрочное прерывание процессов сборок позволяет завершать их как можно раньше, чтобы не перегружать компьютеры, на которых они выполняются. Если же отрицательный результат этапа – это тоже результат (например, оформление кода не по стандарту не мешает отдавать инсталляторы пользователю), то имеет смысл учитывать это при дальнейшем изучении, но сборку не останавливать.
Часть 10: Заключение
Как было описано выше, довольно большое количество действий при сборке системы можно переложить на автоматику: чем меньше однообразных задач будет выполняться людьми, тем эффективнее будет их работа. Однако для полноты статьи одной только теоретической части было бы мало – ведь если не знать, реализуемо ли все это на практике, то и неясно, сколько сил потребуется, чтобы настроить автоматическую сборку самим.
Данная статья была написана не с чистого листа. На протяжении нескольких лет в нашей компании не раз приходилось сталкиваться с задачами оптимизации эффективности разработки и тестирования программных продуктов. В итоге самые частые из них были собраны вместе, обобщены, дополнены идеями и соображениями и оформлены в виде статьи. На текущий момент автоматические сборки у нас наиболее активно используются при разработке и тестировании системы электронного документооборота «Е1 ЕВФРАТ». С практической точки зрения то, как именно реализуются описанные в статье принципы при ее создании, могло бы оказаться довольно полезным для ознакомления, однако будет лучше написать на эту тему отдельную статью, чем пытаться дополнить текущую.
