

Вот так выглядела транспортная коробка, которая к нам приехала. Железка стоит по прайсу как 3-4 квартиры в Москве.
В начале марта мы проводили открытый тест-драйв новой flash СХД от EMC — EMC XtremIO. Система считается одной из самых быстрых в мире СХД. Особенность — inline-дедупликация на борту. Железо дорогое, но как сказал один из наших заказчиков: «Нифига себе, я только на лицензиях буду экономить 3 миллиона долларов в год». Потому что массив позволяет сократиться с 128 ядер до 64, а лицензии часто считаются именно по ядрам. И ещё, особенно интересна система будет тем, кто работает с виртуальными средами, кто ищет способ уменьшить время отклика СХД и у кого есть проблемы с производительностью.
В меню были включены следующие тесты: IOPS 100% read, random 4k; IOPS 50% read 50% write, random 4k; IOPS 100% write, random 4k. Проводились с помощью IOmeter. Еще пробовали систему в боевом режиме, смотрели ее реакцию на отказы компонентов (вытаскивали диск «на живую» под высокой нагрузкой, перезагружали контроллер, отключали питание по одному из вводов, выключали UPS) и пиковую нагрузку.
В общем, было на что посмотреть. Подробности ниже.
Flash vs HDD
XtremIO занимает в 10 раз меньше места в дата-центре, чем решения на обычных дисках, чем экономит место в серверной и питание. Тут вообще уместно сравнить flash с аналогичными решениями на дисках. Обычный шкаф c дисками даст порядка 50 тысяч IOPS, если считать, что в шкаф поместится в среднем 250 дисков, и каждый выдаст по 200 IOPS (хотя это с большим запасом). И IOPSы эти будут с уровнем задержки 3-9 миллисекунд. Шкаф XtremIO выдаст до 1 миллиона IOPS, если это потребуется, а главное — задержки будут менее 1 мс, что очень важно для целевых приложений.
Тесты
Тесты на чтение проводились на дисках с созданными разделами и файловой системой, в тестах на запись попробовали тестировать на сырых устройствах без разделов, там результат близок к линии, судя по всему, такую неравномерность результата вносит драйвер ФС. Тестировали на последнем Iometer с шаблоном Full random 4K Read, Full random 4K Write, Full random 4K Write 50%. Вендор заявил соответственно 250к IOPS, 100-150k IOPS в зависимости от уникальности данных, и 150k IOPS при соотношении чтение/запись — 50/50, ниже покажу насколько массив уложился в заявленные параметры.
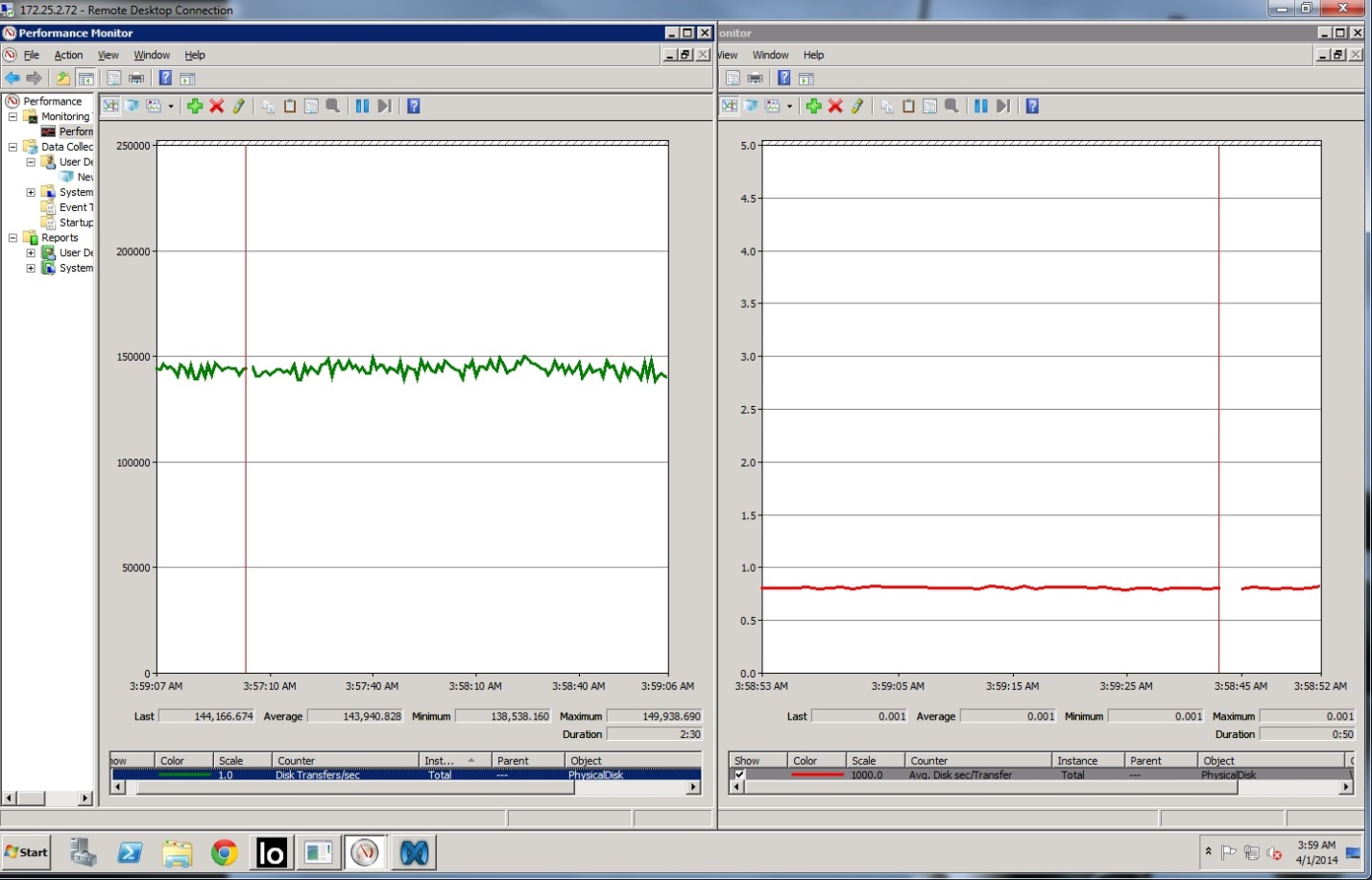
В качестве результатов привожу мгновенное значение на массиве и более подробные измерения на хосте, с которого проводилось тестирование. Для хостовых графиков зелёный – IOPS, красный – задержка.
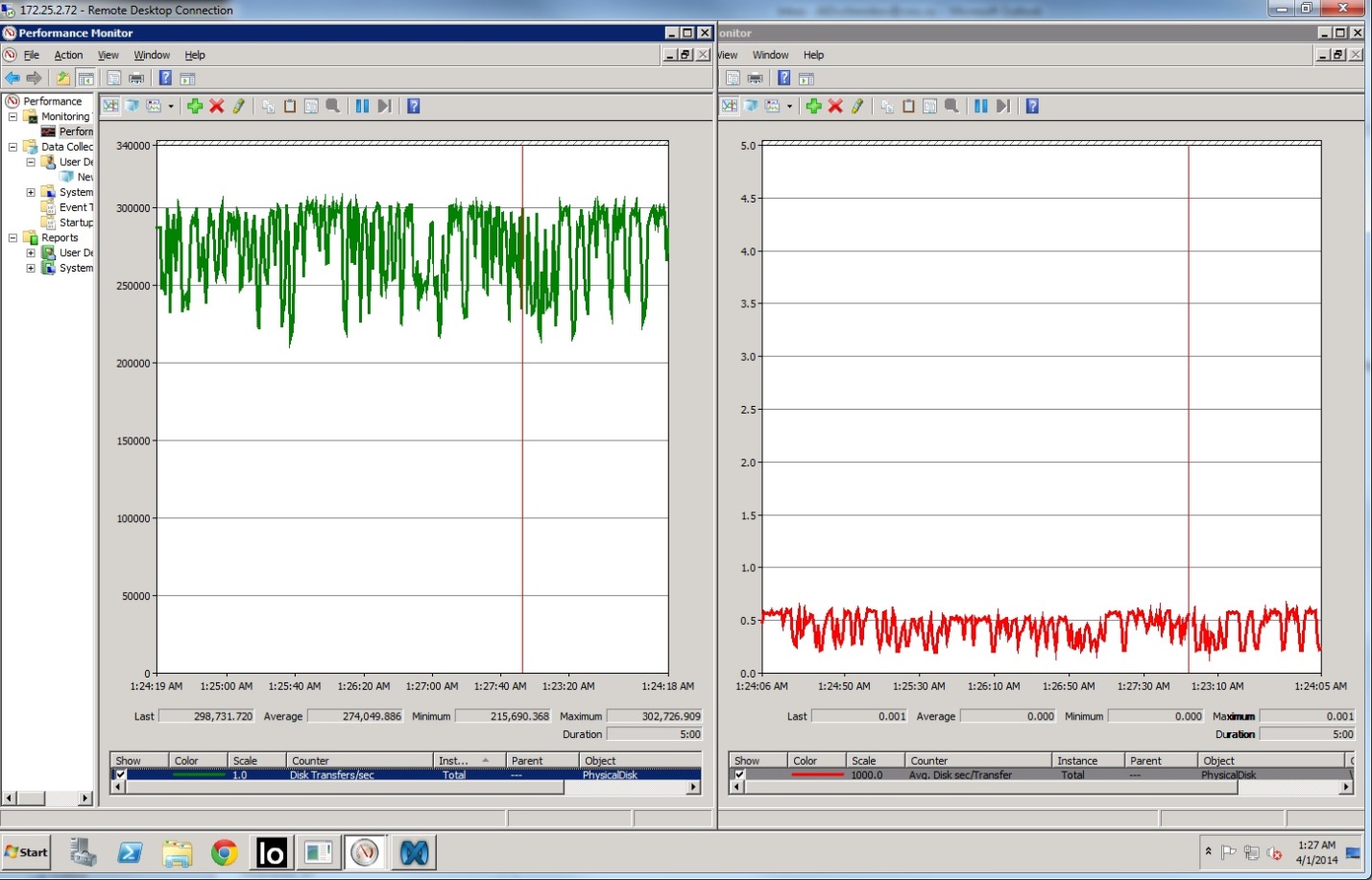
Чтение
С чтением результат был очень обнадёживающий, мы легко достигли заявленных показателей и даже превзошли их.
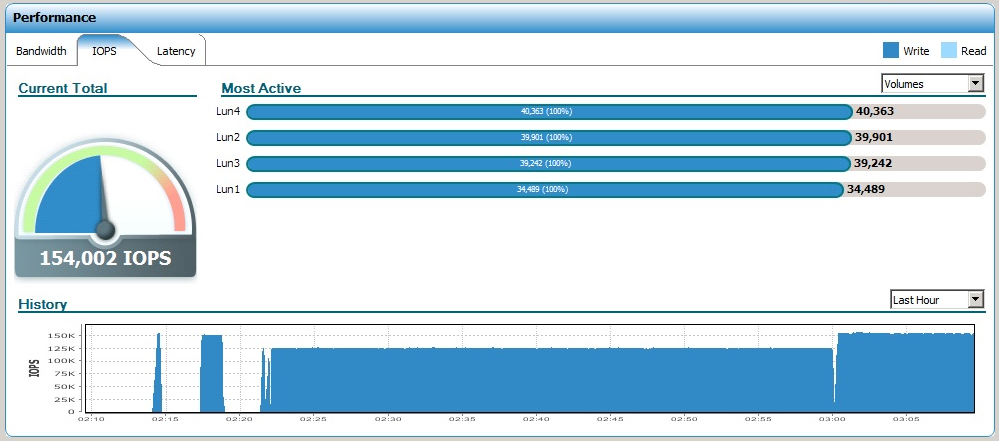
Запись
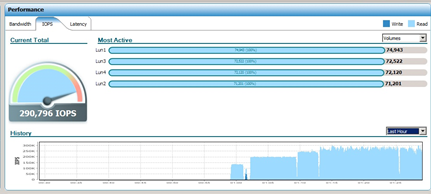
С записью получилось следующим образом:
На суб-милисекундных задержках заявленных характеристик не получили, вот предел которого мы добились:

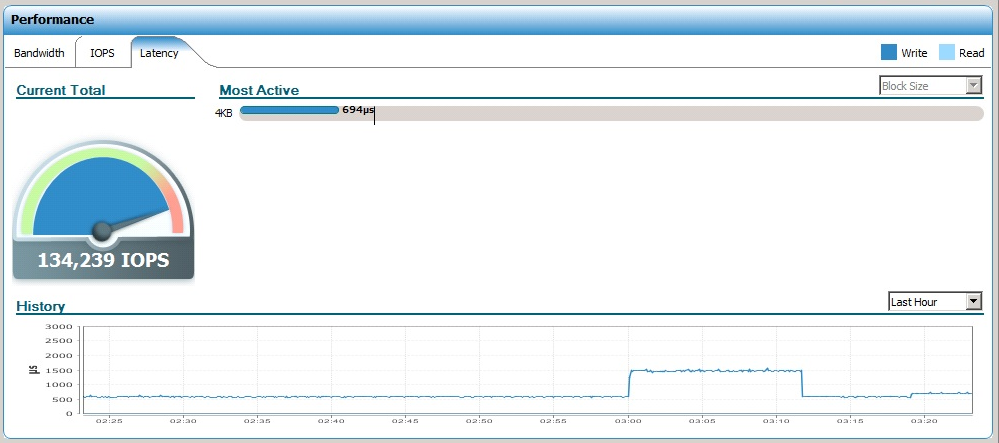
Тем не менее, выжать максимум, если не смотреть на задержку, вышло достаточно легко:
Только задержка на массиве, конечно, выросла выше 1 мс.
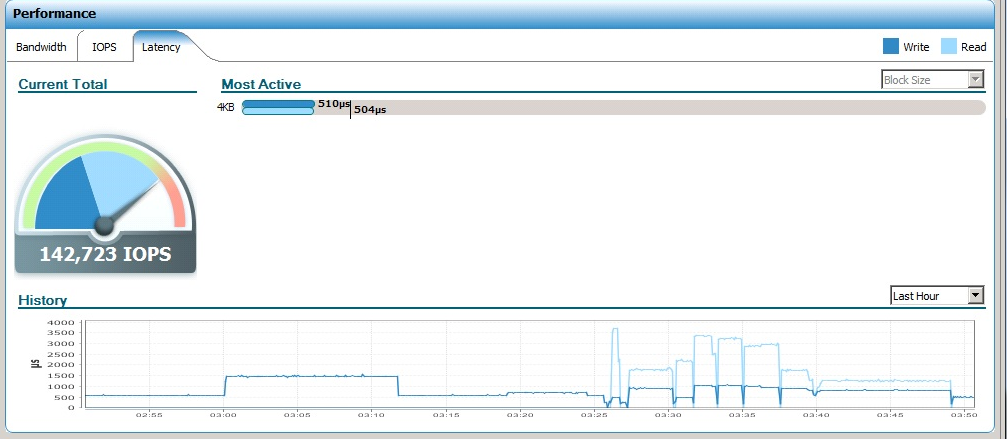
Чтение/запись
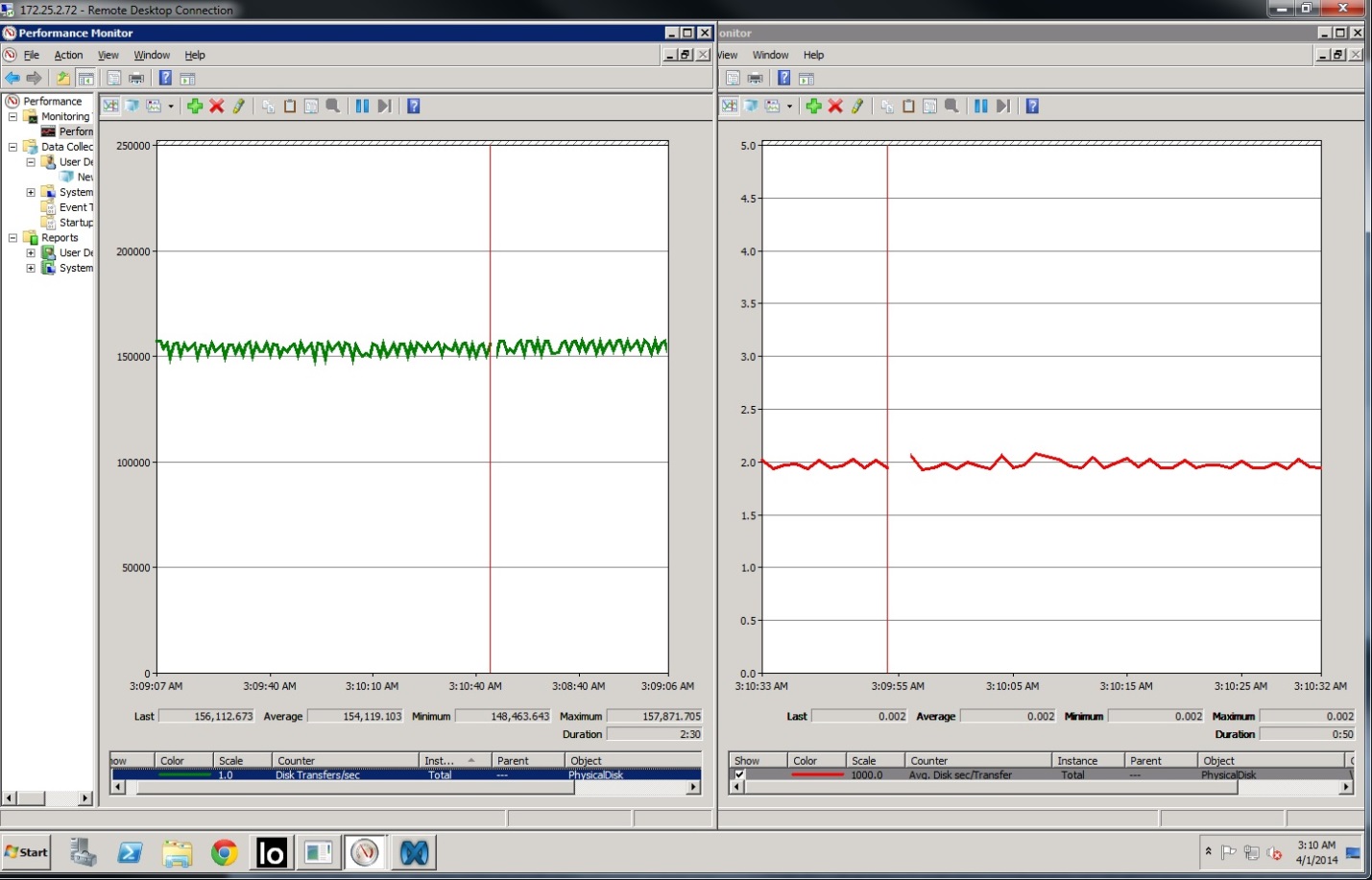
Тут нам не хватило каких-то 5 десятков IOPS чтобы достигнуть заявленных значений:
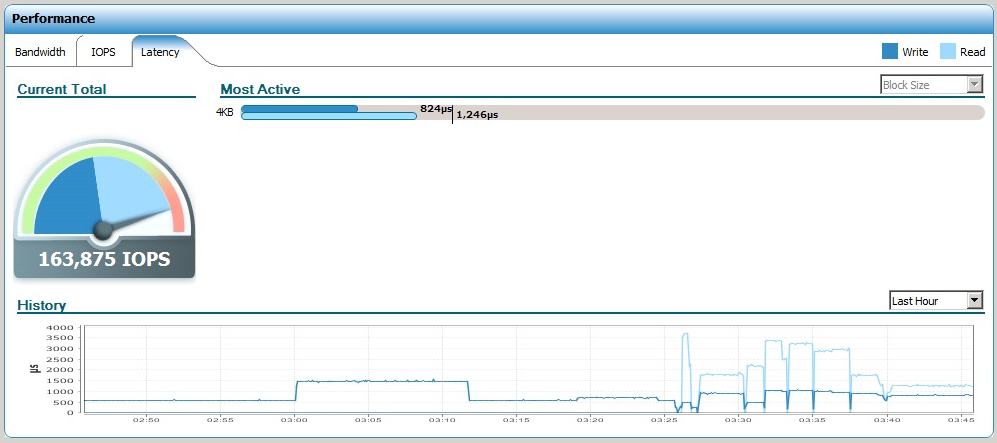
Само собой, интереса ради попробовали добить эти IOPS, но задержка неизбежно поползла вверх и вышла за миллисекунду, причём, что забавно, поползла именно задержка на чтение:

Общие ощущения от массива
В целом, с точки зрения администратора система очень удобна и приятна в управлении, настройка минимальна и не требует серьёзного планирования конфигурации. Фактически единственное, про что не надо забывать – подключать хост к обоим контроллерам (об этом нередко забывают). При этом, несмотря на малое число параметров, интерфейс весьма информативен и нагляден, более-менее опытному администратору хватит пары минут, чтобы со всем разобраться.
С точки зрения сервисного инженера массив достаточно больших размеров по сравнению с аналогами. На мой взгляд, очень чётко просматривается заточка массива под VDI, и хранение «горячих» данных для БД финансового, страхового, научного и энергетического сектора, решению весьма критична возможность дедуплицировать данные максимально сильно.
Из того, что еще понравилось – большинство компонент массива очень удобно менять, у аналогов обычно всё сложнее.
Вообще, о дедупликации на лету для флеш СХД до недавнего времени никто даже не думал из-за возможных вносимых задержек. Компания ЕМС не только подумала, но и смогла представить СХД корпоративного уровня, где эта технология стала ключевой. Такая дедупликация позволяет не записывать данные на диск, если они уже имеются где-то. То есть операция записи, по сути, осуществляется в кэш-памяти, обеспечивая ещё лучшее время отклика. Сейчас EMC единственные, кто делает инлайновую дедупликацию внутри СХД. Другие делают это либо отдельной железкой, либо не «на лету», что, в частности, позволяет избавиться от костылей в виде дедупликации RAM-кэша (он просто не нужен: данные туда попадают уже обработанными). Новый дублирующий блок сразу заменяется на ссылку, где бы внутри системы он не находился – что в кэше, что на SSD. При этом система не старается хранить данные в кэше, а сразу пишет их на SSD – это потребовало от разработчика пересмотра архитектуры, но дало выигрыш в производительности. Всё это в комплексе для решений типа VDI может сокращать количество записей на сами диски до 30 и более раз.
Цена
Каждый раз, когда я показываю такую или похожую коробку, возникает много вопросов по цене. Отвечу на основные. Во-первых, сколько стоит: цена по прайсу – 28 миллионов рублей, но по факту она всегда отличается вниз (и существенно) из-за большого количества программ и специальных условий вендора. Именно поэтому цены на такие решения обычно не объявляются, а указываются в коммерческом предложении на конкретное внедрение. Если вы работаете с высоконагруженными приложениями, то вполне понимаете, что она оправдана: это очень быстрая СХД сама по себе (она убирает «бутылочные горлышки», например, в банках, страховых и у сотовых операторов), плюс «заточенность» под виртуальные среды. Если пересчитывать на многие практические highload-решения, эксплуатация оказывается куда дешевле дисковой (интересна конкретика – пишите, отправлю предложение) И, наконец, эта СХД идёт с поддержкой. Базовая подразумевает кроме софта и консультаций замену любых узлов в течение 1 рабочего дня, а расширенная – выезд в течение 4 часов максимум.
Приглашаю на тест
Система с фото выше сейчас у нас, и используется для тестов и демо. Если вы хотите протестировать её для своих задач (в частности, по своей программе) — пишите мне на vbolotnov@croc.ru.
