

Кабель Mellanox MC2609125-005
В нашем случае Infiniband работал бы в пять раз быстрее, чем Ethernet, а стоил бы столько же. Сложность была только одна – всё это нужно было делать без прерывания облачных сервисов в ЦОДе. Ну, это примерно как пересобрать двигатель автомобиля во время движения.
В России таких проектов попросту не было. Все, кто до сих пор пытались переходить с Ethernet на Infiniband, так или иначе останавливали свою инфраструктуру на сутки-двое. У нас же в облачном «плече», которое находится в дата-центре на Волочаевской-1, около 60 крупных заказчиков (включая банки, розницу, страховые и объекты критичной инфраструктуры) на почти 500 виртуальных машинах, размещенных на примерно сотне физических серверов. Мы первые в стране получили опыт перестроения стораджевой и сетевой инфраструктуры без даунтаймов и немного гордимся этим.

Infiniband-кабель на входе в сервер
В итоге пропускная способность каналов связи между серверами «облака» выросла с 10 Гб/сек до 56 Гб/сек.
Что было
В ЦОДе на Волочаевской-1 был Ethernet 10 Гб, который объединял сервера. Всерьёз просчитывать Infiniband для себя мы начали в момент проектирования своего следующего ЦОДа — Компрессора (уровень TIER-3). Сравнив суммарные стоимости владения с учётом карточек, коммутаторов, кабеля, обслуживания, получилось, что Infiniband стоил практически столько же, сколько и Ethernet. Но обеспечивал куда меньшие задержки в сети и был банально быстрее минимум в 5 раз.
Ну и плюс стоит упомянуть тот отличный факт, что Infiniband на таких объектах на порядок проще в настройке и поддержке. Сеть один раз проектируется и дальше спокойно расширяется просто втыканием новых железок. Никаких танцев с бубном как в случае сложных Ethernet-архитектур, никакого обхода коммутаторов и настроек под ситуацию. Если где-то на коммутаторе проблемы, падает только он, а не весь сегмент. Внутри инфраструктуры настоящий Plug-and-Play.
Так вот, построив облачное плечо в дата-центре Компрессор на Infiniband и почувствовав, насколько замечательна эта технология, мы задумались о перестроении облачного плеча ЦОДа на Волочаевской-1 с использованием FDR InfiniBand.
Поставщик
Крупных поставщиков Infiniband четыре, но практика такова, что стоит строить всю сеть на гомогенном оборудовании от одного вендора, а именно Mellanox. К тому же, на момент проектирование это был единственный вендор, который поддерживал самый современный Infinband стандарт — FDR. Собственно, у нас был прекрасный опыт уменьшения задержек сети для нескольких заказчиков (в том числе крупной финансовой компании) именно с использованием Mellanox – их технология отлично себя зарекомендовала.
Латентность Infiniband FDR порядка 1-1,5 микросекунд, а на Ethernet порядка 30-100 микросекунд. То есть разница в два порядка, на практике в данном конкретном случае тоже примерно так.
Относительно топологии и архитектуры мы решили сильно упростить себе жизнь. Выяснилось, что не очень сложно и затратно сделать точно такую же схему, как во втором облачном плече (наше облако базируется в двух ЦОДах) – в ЦОДе Компрессор – это позволило получить две одинаковые площадки. Зачем? Проще резервировать оборудование замены, проще обслуживать, нет зоопарка оборудования, к каждому из которого нужен свой подход. Плюс у нас как раз оставалось совсем немного до выхода некоторого оборудования из поддержки – мы заодно заменили старые сервера. Уточню: этот факт не влиял на принятие решения, но оказался приятным бонусом.
Cамой важной причиной было снижение задержек в сети. Многие наши заказчики в «облаке» используют синхронную репликацию, и поэтому уменьшение сетевых задержек позволяет косвенно ускорить работу, например, СХД. Кроме того, использование Infiniband позволяет выполнять миграцию виртуальных машин намного быстрее. Если говорить не о текущем моменте, а о будущем, то раз Infinband поддерживает RDMA, то в будущем мы сможем добавить возможность мигрировать виртуальные машины на порядки быстрее, заменив TCP на RDMA.
Безусловно, сейчас в мире Ethernet появляются технологии RDMA, TRILL, ECMP, которые вкупе дают те же самые возможности, что и Infiniband — но в Infinband возможности построения Leaf-Spine топологии, RDMA, автонастройки уже существуют давно и проектировались на уровне протоколов, а не добавлялись как AD-HOC решения, как в Ethernet-е.
Перенос
В облачном плече на Волочаеской у нас был сетевой и стораджевый сегмент на 10-гигабитной сети. К нему мы подключили сегмент инфраструктуры, построенный на Mellanox, так, что получился один L2-сегмент, и все что было на первом стенде в онлайн-режиме мигрировали на новый. Заказчики ничего кроме повышения скорости работы сервисов не почувствовали, никакие машины не отключались, никаких критичных проблем в процессе переезда не произошло.
Вот схема переноса в упрощенном варианте:

Вот более сложный:
По сути мы создали одну среду передачи данных между этими двумя стендами, хотя технологии в принципе не очень совместимы. Перенесли виртуальные инфраструктуры заказчиков, а потом разъединили стенды.
Для объединения двух сред мы использовали управляемые коммутаторы Mellanox SX6036. Перед проектированием тестового стенда для миграции облака, к нам приезжал инженер из Mellanox для консультаций и технической помощи. После согласования с ним наших планов и возможностей оборудования Mellanox, он прислал нам GW лицензии, позволяющие использовать коммутатор в качестве Proxy-ARP шлюза, который может транслировать трафик из сети Ethernet в Infiniband сегмент. В общей сложности переезд делали около месяца (не считая работы над проектом). Он был разделен на несколько этапов, первые – мы собрали тестовый стенд — мини-модель «облака» — для того чтобы проверить жизнеспособность идеи (мигрировать нужно было не только обычную, но и стораджевую сеть). Отработали несколько раз переносы на тестовом стенде и стали писать план боевой миграции.

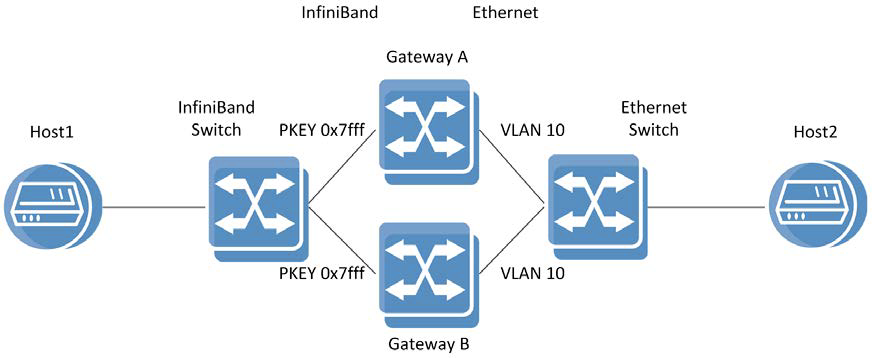
Схема тестового стенда
Дальше – служба эксплуатации перешла на ночной график и стала потихоньку монтировать всё необходимое. История про жену, у которой муж ходил по ночам непонятно куда и утверждал, что на работу – это как раз про такие переезды.

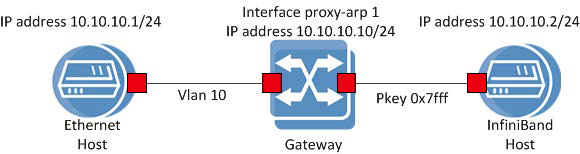
Конкретная схема (ip addresses, vlans, pkey необходимые дня настройки оборудования) для реализации перехода с 10G сети на Infiniband.

В процессе монтажа

Кабель QSFP-4xSFP+ Hybrid, подключенный в Mellanox SX6036

Тот же кабель, подключенный в 10G модуль Ethernet коммутатора

Оптика на входе в 10G-Ethernet часть
Старое оборудование сейчас стоит в сторонке, и его мы уже начали разбирать. Медленно и спокойно вынимаем его из стоек и демонтируем. Скорее всего, оно уедет в тестовые среды, чтобы помогать нам прорабатывать еще более сложные технические кейсы, которыми мы вас обязательно еще порадуем.
Всё, хоть формально мы ещё не закончили переезд (нужно убрать старые стойки), результат уже очень греет. С удовольствием отвечу на ваши вопросы про переезд в комментариях или по почте mberezin@croc.ru.
