Comments 12
А софтверное решение вида squid + linux vpn, зашейпированный вручную в ширину канала посредством tc, не решает 50-70% приведенных проблем?
Riverbed использует 3 механизма – дедупликация (data streamlining), оптимизация транспорта (transport streamlining), оптимизация приложений (application streamlining). Т.е. максимально хорошо решение работает, когда все 3 механизма работают одновременно. Можно вручную крутить определенные настройки и использовать сторонние решения, но прирост будет незначительным.
Или вы что-то другое имели в виду?
Или вы что-то другое имели в виду?
Слушайте, а можно это как-то в цифрах подтвердить? Ну, взять, к примеру, более-менее стандартный vpn-канал какой-нибудь — pptp там или ipsec, по вкусу. Опять же стандартный линуксовый tc, которым трафик шейпируют, навесить шейпер на vpn-линк с обеих сторон линии, на которой длинная задержка, поставить http прокси, на «серверном» конце, которому объяснить ( http://wiki.squid-cache.org/Features/DelayPools), что не надо клиенту отдавать данные быстрее, чем X mbit — и у вас http/https потоки к клиентам за длинной линией уже пилить перестанут.
Повесить второй прокси на клиентской стороне — получить тем самым дедупликацию (для http/https, ок).
Дальше сравнить такое решение в какой-нибудь метрике с Riverbed-ом и привести ценники, чтоб было понятно, какой выделки требует овчинка.
Просто сейчас, уж простите, но получилась длинная статья с претензией на техничность, но какая-то однобокая, что ли — вы обозначили проблему, сказали, что пробовали разное и пришли к коробочному решению, но не понятно, что именно кроме коробочного вы пробовали и насколько глубоко прокопали в соответствующих направлениях.
Повесить второй прокси на клиентской стороне — получить тем самым дедупликацию (для http/https, ок).
Дальше сравнить такое решение в какой-нибудь метрике с Riverbed-ом и привести ценники, чтоб было понятно, какой выделки требует овчинка.
Просто сейчас, уж простите, но получилась длинная статья с претензией на техничность, но какая-то однобокая, что ли — вы обозначили проблему, сказали, что пробовали разное и пришли к коробочному решению, но не понятно, что именно кроме коробочного вы пробовали и насколько глубоко прокопали в соответствующих направлениях.
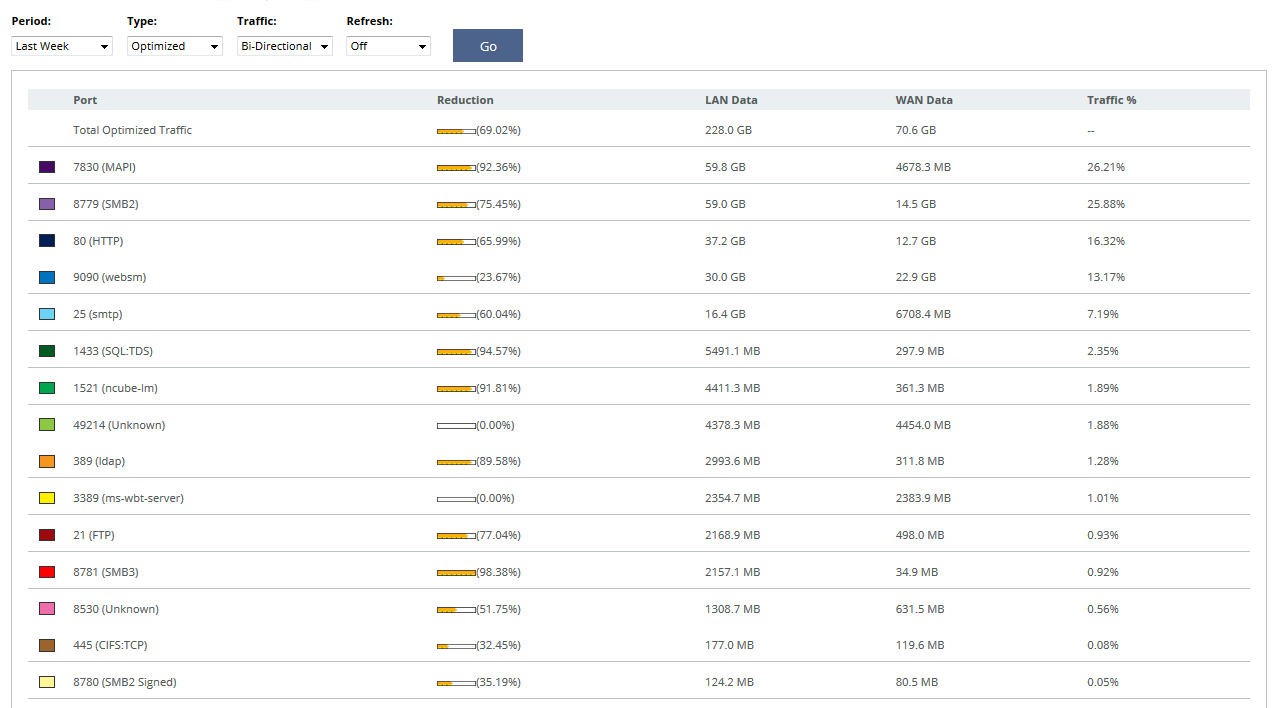
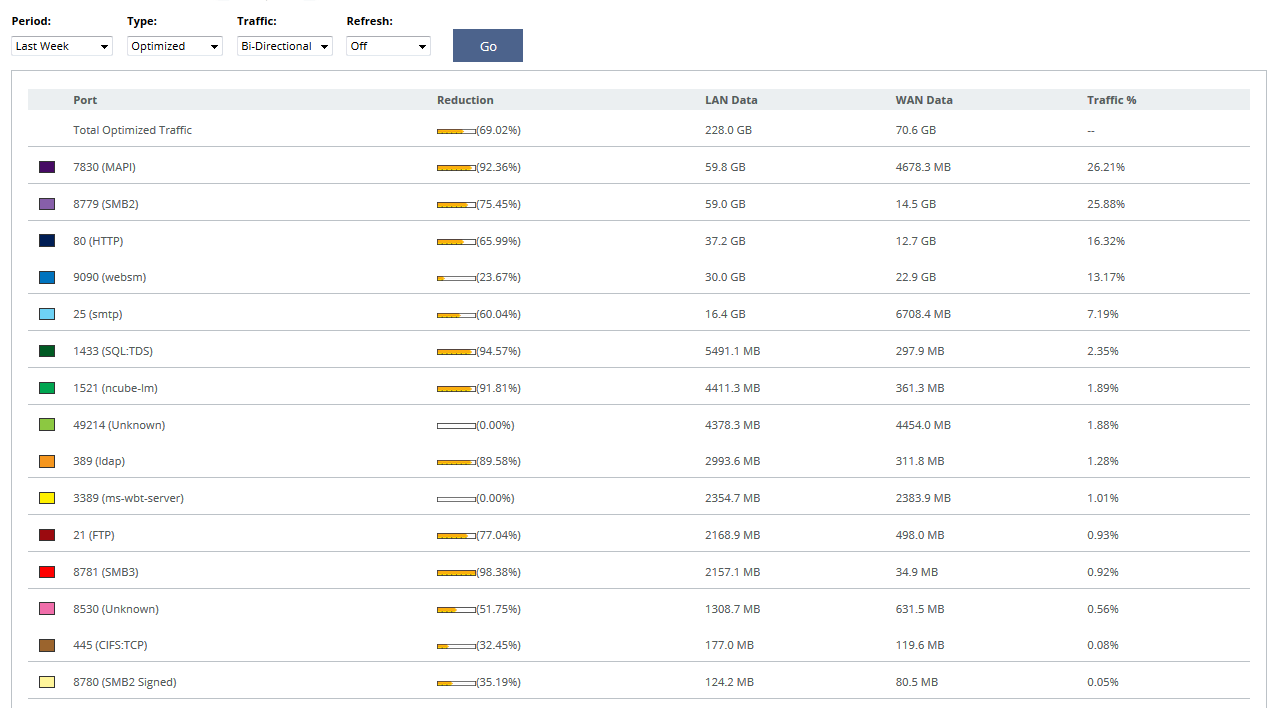
То, что Вы описали, будет решением частной задачи ускорения работы и сжатия HTTP/HTTPS. Если требуется сконцентрироваться на одном приложении, тогда коробочное решение вряд ли подойдет, и можно обойтись малыми силами. Обычно задача стоит более комплексно, приложений в канале много, а канал расширить нельзя. Помимо HTTP всегда есть CIFS/SMB (signed), MAPI (чаще всего Encrypted или через HTTPS), FTP, различный трафик БД, терминальные сессии (RDP/Citrix). Даже если будет возможность тюнинговать настройки серверов для лучшей работы, то такое решение будет тяжело масштабируемым, особенно если удаленных точек/филиалов больше 10, к примеру. Прелесть Riverbed SteelHead еще в том, что им без разницы, через какое приложение передаются повторяющиеся/избыточные данные. Пример: скачиваем с файловой шары по SMB презентацию PowerPoint размером 20 МБ, локально на машине удаляем один слайд, сохраняем файл, заливаем обратно, но уже по FTP. В обычном сценарии обратно будет передано все те же 20 МБ, а в случае если на канале стоит Riverbed SteelHead, сжатие будет около 80-90%, в канал уйдет 2-4 МБ. Приведу пример со скриншотами с одного из наших последних пилотов. Первый показывает процент сжатия по приложениям, второй – увеличение пропускной способности канала. Итог тестирования – канал виртуально расширен в 3.2 раза. Таких результатов связкой из прокси и шейпера не добиться.


UFO just landed and posted this here
Отключение компрессии передающего и принимающего узла и сборка пакетов в пачки. Если отключить сжатие каждого отдельного пакета, то можно отлично дедуплицировать множественные повторяющиеся. По факту это будет означать, что для однажды переданного пакета, похожего на следующий передающийся, можно отправлять только номер ближайшего похожего и разницу. Это существенно меньше, чем два сжатых пакета.
— неужели это работает? И профит превышает издержки? Ведь если есть повторения, то и степень сжатия увеличивается. Ну и в некоторых средах передачи имеет значение высокая энтропия сжатых пакетов — там практически нет идущих много раз подряд сигналов одного уровня (0 или 1), что уменьшает вероятность ошибки.
У вас там много где на графиках «обычный TCP», это какой именно congestion control использовался? Можете сравнить чудо-железку с гугловым bbr?
Sign up to leave a comment.
Нельзя так просто взять и расширить каналы связи