

— Знаете, у нас в последнее время тормозят системы, бухгалтерия нервничает, отгрузки продукции задерживаются. Надо это как-то исправить.
— А вы примерно понимаете, что является причиной такой низкой скорости приложений?
— Ну, предполагаем, что проблема с серверами баз данных может скрываться как в программной части, так и аппаратной, но твердой уверенности в этом нет.
Это один из сценариев, когда начинать нужно с технического аудита. По итогам он дает возможность, например, не перекраивать всю инфраструктуру, а вносить тонкие настройки, которые помогут жить эффективно с тем же пластом бизнес- приложений.
Слова «аудит» многие пугаются. Думают, будто это длительный и сложный процесс, который потребует от ИТ-директора полного вовлечения. Поэтому мы все чаще говорим про «обследования» или даже «чекапы» — аудиты минимум на половину автоматизированные. Ниже расскажем, в каких еще случаях такие аудиты могут быть полезны компаниям и какие методики помогают выжать максимум пользы из них при достаточно небольших затратах.
Обычно на рынке используется экспертная модель проведения аудита. В этом случае аудитор на основе неких мировых практик и своего личного практического опыта составляет заключение и дает рекомендации. Однако они бывают весьма субъективными и неполными, а еще и противоречивыми. Для каких-то глобальных внутренних проектов типа цифровизации производства ложные выводы могут быть губительны.
Второй важный момент заключается в том, что каждый аудит — это индивидуальный проект, к которому стоит подходить, ориентируясь на особенности инфраструктуры заказчика. У всех свои задачи, свое оборудование, свои процессы.
Со временем мы пришли к пониманию, что эту индивидуальность можно и нужно формализовать. Причем сделать это так, чтобы удобно было всем сторонам: и тем, кто аудит проводит, и бизнесу, и ИТ.
Наша методика позволяет вне зависимости от особенностей проекта подходить к каждому централизованно. Но обо всем по порядку.
Определяем пул задач
Первое и самое главное — разобраться в причинах, побуждающих компании на проведение аудита.
Ситуации отранжированы по частоте возникновения:
Ситуация | Ранг |
Наличие ограничений в виде требований закона/регулятора | 3,75 |
Смена ИТ-руководства или ощутимое обновление ИТ-команды | 3,38 |
Обязателен процесс обоснования ИТ-решения и бюджета | 3,13 |
Реализуется стратегия снижения затрат | 3,06 |
Снижение доступности и производительности информационных систем | 2,94 |
Планируется/В процессе/Завершен процесс слияния и/или поглощения (M&A) | 2,91 |
Бизнес находится/планируется стадия ощутимого роста | 2,75 |
Осуществляется/Планируется внедрение информационной системы/информационных технологий | 2,75 |
В наличии недоверие бизнеса к ИТ-команде | 2,25 |
Вот основные задачи аудита:
Инвентаризация имеющейся инфраструктуры
Выявление «узких» мест и оптимизация ИТ-инфраструктуры
Определение причин и устранение проблем с производительностью прикладных информационных систем
Передача части процессов по поддержке и обслуживанию инфраструктуры на аутсорсинг
Обоснование ИТ-решения или ИТ-бюджета
Разработка планов миграции инфраструктуры в облако
Разработка планов Disaster Recovery (DRP)
Замена/модернизация парка устаревшего оборудования
Разработка планов (стратегии) развития ИТ
В рамках одного аудита может решаться как одна, так и несколько задач.
Посмотрим, какие реальные ситуации нередко толкают к проведению аудита.
Проблемы с утилизацией ИТ-ресурсов
Часто у заказчиков случаются проблемы либо с производительностью, либо с загруженностью ресурсов. Классическая для on-premise ситуация — есть N серверов, каждый из них используется бизнесом процентов на 30-50. Полную загрузку создавать нельзя, должен быть запас на пики и прочие «из ряда вон» моменты, но и слишком низкая утилизация — тоже проблема.
Нередко бывает и такое, что бизнес неверно оценивает свои задачи, ошибается в расчетах, и часть мощностей простаивает. Причины могут быть разные, здесь это не так важно. Главное — деньги заказчика могут тратиться впустую. У нас были ситуации, когда в ходе аудита инфраструктурных ресурсов мы внимательно изучали все что можно — от ВМ до СХД — и приходили к выводу, что, если перераспределить ресурсы между ВМ, освободится до 30% общих мощностей. Не нужно покупать новое оборудование, можно переиспользовать то, что есть.
Миграция
Практически каждый наш заказчик сталкивался с миграцией. Рано или поздно все переезжают — либо физически, либо в облако, с одной платформы на другую. В рамках подготовки к миграции также необходимо выполнить аудит, но уже с другими вводными. Здесь важны сведения об инфраструктуре и архитектуре, вопросы эксплуатации, HealthCheck.
А если переезд сопряжен с модернизацией и масштабированием — изучаем, как это сделать правильно.
Миграция в облако также осуществляется по этой методологии — отличается только набор галочек в опроснике.
У нас был кейс с одним иностранным банком. Переезд в облако был продиктован решением главного офиса. Соответственно, в рамках аудита важно было понять, насколько облако совместимо с текущей инфраструктурой, весь ли функционал останется доступен. Опять же, возникли вопросы утилизации и порядка переноса систем.
Эксплуатация
Любое оборудование рано или поздно стареет, и его приходится менять. Если у заказчика не выстроен процесс планирования мощностей и возможность следить за состоянием каждой железки отсутствует, стоит произвести аудит имеющегося оборудования: что нужно заменить, что — обновить и т.п. В этом случае мы агрегируем серийные номера и с помощью внутренних или вендорских баз готовим оценку сервисного статуса.
Ох уж это жадное ИТ-подразделение
Часто случается, что бизнес обвиняет ИТ-департамент едва ли не во всех грехах: и жадничают, и обманывают, и работать не умеют. Задача внешнего эксперта — определить, в чем проблема. И, главное, есть ли она на самом деле. Как-то мы работали с одной крупной сетью магазинов, в которой де-факто сосуществовало сразу два ИТ-департамента. Первый — основной. Второй — вырос из другого отдела, размножился и понемногу оброс собственными задачами, собственным оборудованием. Руководителей интересовало, как так вообще вышло насколько это рентабельно: стоимость затрат непрозрачна, деньги уходят, финансовая нагрузка постоянно растет. По итогам аудита выяснилось, что из 200 систем 90% денег «съедали» всего 5. Возник вопрос, почему эти 5 стоят так дорого и зачем тогда нужны еще 195?
В ходе аудита мы составили рекомендации: что сократить, что оптимизировать. Ключевая проблема оказалась в устаревшем ПО, которое год за годом дорожало на IBM-машинах. В итоге заказчик понял, в чем было дело, и фактически «помирился» с ИТ-департаментами.
Новая метла — новый аудит
Иногда могут происходить ситуации, когда в компании сменяется либо ключевой ИТ-штат, либо вообще весь отдел. В этих случаях мы можем помочь новому CIO быстро разобраться в имеющемся ландшафте (и не тратить свое драгоценное время), локализовать проблемы с инфраструктурой и предложить лучшее решение для развития. Важно понимать: аудит не только находит проблемы, но и предлагает решения.
Как бы ни отличались эти ситуации, в каждом случае можно применить нашу методику проведения аудитов. Она позволяет вне зависимости от степени кастомизации проекта к любому из них подойти формально.
В процессе ее разработки мы декомпозировали все проекты аудитов до их операций и выделили кванты обследований. И теперь любой проект — это комбинация типовых квантов, которую можно кастомизировать под любой запрос.
Определяем пул проверяемых систем и компонентов
Наш подход к методологии проведения аудитов чем-то похож на тот, что принят в медицине:
— На что жалуетесь?
— Сетевухи, вроде бы, барахлят.
— Ну-с, молодой человек, держите направление…
*окидывает пациента профессиональным взглядом и дает направление на чекап*
Небольшой интерактивный опросник позволяет отметить «галочками» проблемы и задачи и на лету формирует набор систем, которые надо проверять. Притом сразу с оценкой стоимости.
Такой подход не только упрощает взаимодействие заказчика и проверяющего, но и экономит средства бизнеса: системы, которые не нужно проверять, автоматически отсекаются на этапе заполнения файла.
Клиент сдает анализы соглашается на проверку, по итогам которой мы обнаруживаем, что серверы, к примеру, перегружены, и описываем сценарии решения проблемы.
В целом, в рамках аудита возможно проверить следующие основные инфраструктурные блоки:
Вычислительная инфраструктура:
Серверы
Системы хранения данных и сеть хранения данных
Система резервного копирования
Система архивирования
Система виртуализации
Телекоммуникационная инфраструктура:
Корпоративная сеть передачи данных
Локальная вычислительная сеть
Видео-конференц-связь
Телефония
Беспроводная локальная сеть (WiFi)
Инженерные системы и системы жизнеобеспечения
Базовые инфраструктурные сервисы
Информационная безопасность
Каждый блок можно дополнительно детализировать, например, «Системы хранения данных и сеть хранения данных»:
СХД типа "High-End"
СХД типа "Mid-range entry-level"
Фабрика (SAN)
SAN-коммутатор
NDMP-устройство
Набор обследуемого в каждом блоке оборудования может быть ограничен в зависимости от задачи аудита. Например, при локализации проблем производительности конкретной ИС обследование ограничивается только тем оборудованием, которое задействовано в работе этой ИС.
Если продолжить медицинские аналогии — это позволяет нам не проверять, например, зубы мудрости у каждого клиента. Во-первых, на них жалобы не поступали. Во-вторых, если болят колени, глупо делать стоматологический осмотр. :)
Определяем направление обследования
Опыт проведения аудитов позволил нам проанализировать все параметры, которые необходимо проверять в рамках обследований, и сформировать из них следующие направления. Список ниже применим к каждому инфраструктурному блоку, отобранному на предыдущем этапе.
Общая информация и архитектура
Сводная информация по производителю, модели, конфигурации, базовым характеристикам и архитектуре. На выходе – полная инвентаризационная информация и оценка архитектур на наличие грубых ошибок и соответствие «лучшим практикам».
HealthCheck
Анализ состояния аппаратной части, выявление сбоев и поломок, сообщений встроенных систем мониторинга. Определение мер по локализации и устранению неисправностей.
Отказоустойчивость
Оценка наличия резервирования на уровне компонентов и подсистем, определение риска отказа в обслуживании по причине единичной поломки. Помимо наличия физического резервирования, определяем корректность соответствующих программных настроек, если применимо.
Утилизация и производительность ресурсов
Сбор статистической информации по загрузке системы за отчетный период, выявление пиков, оценка средней утилизации системных ресурсов. На выходе – заключение о степени перегруженности или недостаточной утилизации, о наличии резерва мощностей для дальнейшего роста.
Масштабируемость
Определение возможности наращивать ресурсы в пределах системы за счет модернизации/апгрейда (вертикальное масштабирование), либо путем распределения нагрузки на аналогичные системы (горизонтальное масштабирование). Выполняется как на уровне аппаратных ресурсов, так и на уровне программной прослойки (репликация, шардинг, балансировка).
Актуальность ПО
Определение установленных версий микрокодов, ОС, системного ПО. Оценка необходимости обновления с точки зрения актуальности, поддержки вендорами, наличия критических проблем.
Управление и мониторинг
Проверка покрытия системами мониторинга (при наличии), глубина и степень детализации собираемых метрик. На выходе – оценка достаточности собираемых мониторингом параметров и метрик для полноценного наблюдения за работоспособностью и своевременного реагирования на сбои.
Резервное копирование
Проверка покрытия системой резервного копирования (при наличии). Оценка адекватности частоты резервного копирования, продолжительности хранения копий, достаточности окна резервного копирования. Выявление сбоев создания копий.
Эксплуатация
Оценка условий эксплуатации оборудования, корректности подключения и организации инженерных систем. Оценка сроков эксплуатации, физического и морального износа, наличия действующей гарантии и/или сервисных контрактов.
Оценка возможности замены и миграции на аналоги в рамках стратегии импортозамещения.
Проведение обследования
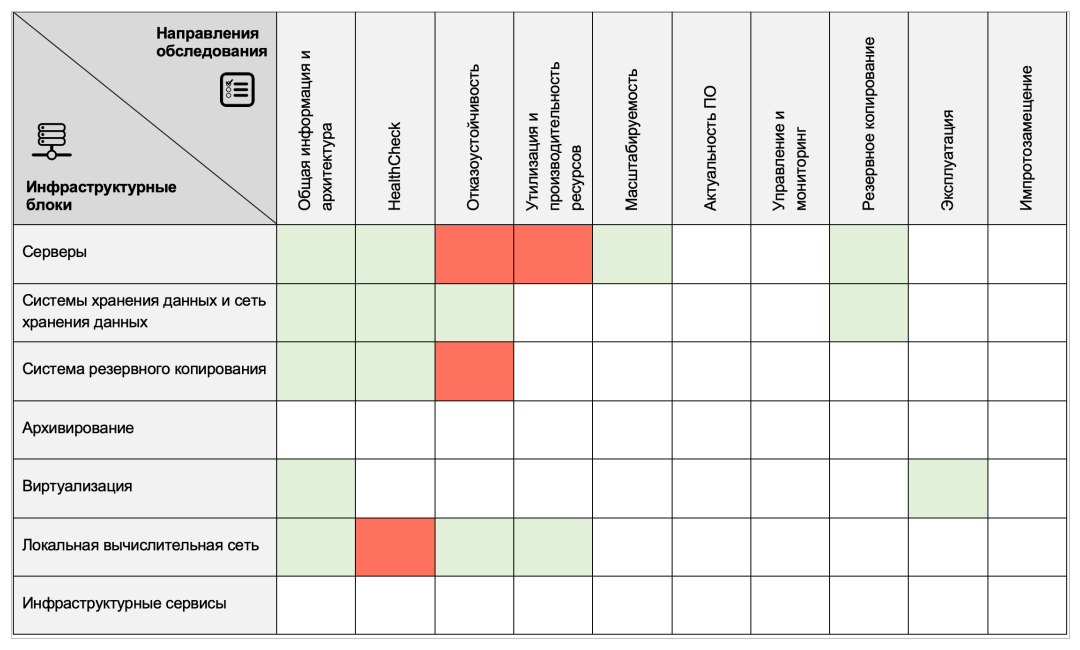
Чек-лист обследования — это набор направлений обследования для выбранных инфраструктурных блоков. Выглядит это, как матрица, где в колонках инфраструктурные элементы, а в строках направления обследования. Каждая ячейка — это типовое обследование, включающее:
Чек-лист показателей, входящих в состав критерия «лучших практик», значения которых требуется определить.
Критерий «лучших практик», определяющий нормальное состояние элемента инфраструктуры по каждому конкретному направлению обследования. Эталонные значения параметров критерия сформированы на основе рекомендаций вендоров и опыта КРОК полученного в более чем 2000 инфраструктурных проектах.
Набор инструментария для определения значений показателей (специальные утилиты, опросники, инструкции по анализу логов и т.д.)
Заключение эксперта о причине выявленного отклонения от «нормы», сформированного путем сравнения полученных значений показателей с критерием.
Ниже представлен пример одного из Критериев «Лучших практик» по направлению «Утилизация и производительность ресурсов» для инфраструктурного блока «Серверы»:

Полученные по всем направлениям и инфраструктурным блокам результаты, сводятся в общую «тепловую» матрицу, и эксперт делает общее заключение по каждому инфраструктурному блоку и по инфраструктуре в целом, а также дает рекомендации по исключению проблемных «зон».
Ретроспектива ноу-хау
Раньше аудит был в некоторой степени творческим, креативным процессом, который отнимал много времени. Соответственно, результат сильно зависел от эксперта, ответственного за аудит.
Сейчас наличие методики снижает влияние человеческого фактора на результаты аудитов: при наличии формальных критериев «нормально/плохо» вероятность ошибки стремится к нулю. Кроме того, такая формализация процесса помогает нам максимально автоматизировать и ускорить обследование — в том числе силами самого заказчика. Используя наши наработки, он его может провести самостоятельно.
Здесь файл целиком с вопросами, которые мы обычно задаем клиентам. Про технические решения, которые используем во время аудитов (например, утилиты, измеряющие производительность), расскажем в следующий раз.
