Задача Datawiz.io: провести кластеризацию клиентов программы лояльности в ритейле.
Кластеризация — это метод поиска закономерностей, предназначенный для разбиения совокупности объектов на однородные группы (кластеры) или поиска существующих структур в данных.
Целью кластеризации является получение новых знаний. Это как “найти клад в собственном подвале”.
Для чего это нужно компаниям? Чтобы лучше узнать своих клиентов. Чтобы найти индивидуальный подход к каждому клиенту, а не работать со всеми одинаково.
Несмотря на то, что многие компании используют программы лояльности и обладают колоссальными данными, их аналитики сначала определяют персону покупателя, а уже потом анализируют ее поведение.
Решение: Machine Learning позволяет пойти от обратного, от личных предпочтений — к персоне. Мы в Datawiz.io используем кластеризацию как метод группирования клиентов по данным о их поведении – покупках, банковских транзакциях, кредитных историях.
Для кластеризации массива данных (чеки, данные по программах лояльности) мы используем алгоритм K-means. Он хорошо масштабируется и оптимизируется под Hadoop.
Также как альтернативу можно использовать алгоритм Affinity Propagation. Конечно, у него есть ряд существенных минусов: он медленный и плохо масштабируется. Но в частных случаях, при желании и наличии свободного времени, можно использовать его для кластеризации на коротких промежутках времени.
Итак, пошагово.
1. Clean Datа.
Прежде, чем формировать матрицу — в обязательном порядке чистим информацию. Убираем то, что не влияет на поведение покупателей и является информационным шумом. Для ритейлеров, например, можно исключить рекламную продукцию, выданные дисконтные карты, скретч-карты, тару и пакеты, покупаемые на кассе. После того как данные очищены приступаем к формированию матрицы.
2. Формируем матрицу с входными данными.
Важно: Результаты кластеризации очень зависят от периода времени, по которому она проводится. Если выберем кроткий период — увидим текущие тренды.
Например, проведя кластеризацию перед Новым годом, увидим кластеры, которые не видны на длительном промежутке времени. (Скажем, кластер “Любители “Оливье” и “Селедки под шубой”). Кластеризация за длительный период позволит увидеть картину в целом, то есть клиентов со стабильным поведением (“лайфстайл”). “Студенты”, “Домохозяйки”, “Пенсионеры” и т.д.
Например, ритейлер хочет провести кластеризацию по программе лояльности за полгода.
У магазина есть чеки Васи, который за полгода купил 1 хлеб, 2 молока и 1 батон; и чеки Оли — она купила 3 хлеба, 5 молока и 2 батона за полгода и т.д.
Значит матрица для этого ритейлера будет выглядеть так:
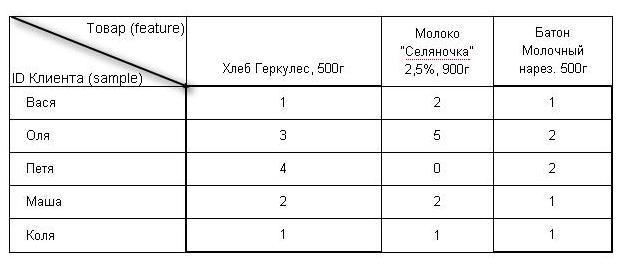
Для ритейлера в среднем, features = 15 тыс. SKU, а samples = 60 тыс. клиентов.
Возьмем каждого отдельно клиента, например Васю со всеми его чеками за полгода. В зависимости от количества вхождений всех товаров по всех его чеках, разместим Васю (и других) на графике, где:
количество осей = количеству товаров (features),
количество точек = количеству клиентов (samples), участвующих в программе лояльности.
Наглядное (и очень схематичное:) изображение:

Но выглядеть результат кластеризации алгоритмом k-means будет так:

Также можно проводить кластеризацию по разных уровнях категоризации товаров (feature reduction), тогда матрица будет выглядеть так:

После того, как матрица сформирована, можно переходить к выбору количества кластеров.
3. Выбираем оптимальное количество кластеров.
Количество кластеров мы выбираем экспериментальным путем, исходя из собственного опыта. Малое количество кластеров будет малоэффективно и не информативно, потому что в таком случае мы получаем один-два “мегакластера”, куда будет входить 98% клиентов и несколько бесполезных маленьких кластеров.
При большом количестве кластеров получится слишком много маленьких групп. К тому же никто не хочет анализировать 5000 отдельных мелких кластеров. Для каждого отдельного случая должен быть свой индивидуальный подход.
Для длительных периодов и большого количества кластеров используем K-means.
4. Проводим кластеризацию.
Выбираем алгоритм K-means (или Affinity Propagation), используем Python библиотеку scikit-learn, на вход даем получившуюся матрицу, запускаем кластеризацию.
5. Анализируем результаты кластеризации.
Результатом работы алгоритма является маркировка всех клиентов программы лояльности, в зависимости от их поведения/покупки. Клиенты с одинаковыми поведенческими характеристиками попадают в один кластер.
Если вы проводите кластеризацию за весь период работы, то в ней участвуют все клиенты программы лояльности. Если за определенный период (год, месяц), то в кластеризации участвуют только те клиенты, которые совершили покупки в заданный период.
Итак, мы провели кластеризацию по программе лояльности для ритейлера за полгода, с количеством кластеров 75. Рассмотрим, как распределились по кластерам покупатели, и какие товары предпочитают в тех или иных кластерах:
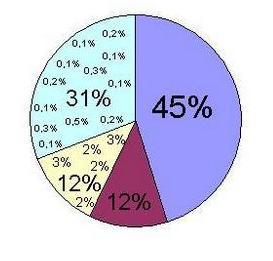
— В “Кластер 1” попало 45% клиентов за этот период. Лидерами продаж по товарам здесь стали: масло, бананы, яйца, молоко, батон, сметана.
— В “Кластере 2” оказалось 12% клиентов. Здесь популярнее остальных уже несколько видов хлеба и сметаны, бананы и непродовольственные товары.
— Пять последующих кластеров уже не такие большие, в каждый из них входят лишь по 2-3% клиентов. (В общей сложности в эти кластеры попали 12% клиентов за выбранный период). Здесь предпочтения клиентов весьма интересны, например: молочные продукты+фрукты, печенье+йогурты\сырки, йогурты\десерты+хлопья, курица+пиво+корм для кошек.
— Оставшиеся 31% покупателей рассеяны по 68 кластерам. в которые входят 0,1-2% клиентов. Также кластер может быть очень маленьким и состоять из 1-2 человек. Чем может быть интересен такой кластер? Читайте в кейсах в конце статьи.
При кластеризации алгоритм выявляет нестандартное поведение клиента. Выявить такое поведение поможет анализ отдельных “фич”(характеристик и особенностей) каждого отдельного кластера.
6. Анализируем характеристики каждого кластера.
- Название кластера. Можно просто пронумеровать кластеры, а можно присвоить им названия, в зависимости от поведенческих особенностей внутри каждого кластера — от “Домохозяек”, “Холостяков”, “Бизнесменов” до “Клуба любителей кошек”:)
- Оборот кластера. Позволяет определить кластеры, приносящие наибольший доход.
- Доля кластера в обороте. В процентном соотношении от общего оборота по кластеризации за выбранный период.
- Количество клиентов в кластере.
- Количество новых клиентов в кластере. (Впервые воспользовались дисконтной картой за выбранный период кластеризации).
- Количество мужчин и женщин в кластере в процентном соотношении. Позволяет выявить типичные мужские и типичные женские покупки, помимо очевидных.
- Общее количество чеков в кластере.
- Количество чеков на одного клиента в кластере. Позволяет отследить сколько раз возвращался клиент за выбранный период кластеризации.
- Среднее количество товаров в чеке.
- Средняя стоимость чека. Позволяет определить, в каком кластере продаются самые дорогие товары.
Проанализировав характеристики каждого кластера и с их помощью определив персону покупателя, можно переходить к персонализированной рассылке.
7. Проводим персонализированную рассылку по каждому кластеру.
Используя кластеризацию клиентов, можно получить четкую систему рекомендаций для персонала — какой товар, какому клиенту и в какое время предлагать.
Зная, что и какой группе людей предлагать, компании смогут избежать метода “ковровой бомбардировки” при sms или e-mail рассылке. Предлагая клиентам только нужные им товары (не забывая про сопутствующие), можно добиться гораздо большего отклика и конверсии в покупку.
Рассмотрим несколько кейсов от Datawiz.io.
Повышение эффективности промо-рассылок с помощью кластеризации.
В результате кластеризации клиентов одной из сети магазинов мы получили 75 кластеров. Для примера рассмотрим три из них: “молодая семья”, “студент” и “пенсионер”.
— Клиенты кластера “молодая семья” были наиболее восприимчивы к предложениям по покупке подгузников, детского питания, фруктов и молока;
— “студентам” предложили скидки на продукты группы фастфуд и пиво;
— а “пенсионерам” на крупы и овощи.
В следствии такой рассылки конверсия в покупку увеличилась на 14,5 %.
Продвижение нового продукта.
Вариант 1. Чтобы узнать кому будет интересен новый продукт, мы сделали рассылку по всех клиентах программы лояльности. По результатах отклика узнали персону покупателя, которой необходимо маркетировать новый продукт. Далее, отследили нужных нам покупателей в кластерах. Провели рассылку уже только по интересующих нас кластерах.
Вариант 2. Компания не захотела проводить рассылку по всех клиентах, так как база весьма обширна. Поэтому мы создали гипотезу, каким кластерам клиентов этот продукт интересен. Из всех интересующих нас кластеров мы взяли рандомно по 1% клиентов и провели по ним тестовую рассылку. С теми кластерами, которые показали наивысшую конверсию в покупку после тестовой рассылки, и работали в дальнейшем, предлагая новый продукт всему кластеру.
Нестандартное поведение клиента.
Мы провели кластеризацию для магазина одной из сети. Алгоритм выдал кластер, в котором было всего 2 клиента. Но внимание привлекла сумма оборота по этому кластеру за небольшой период. Казалось бы, ну покупают люди много разнообразных продуктов и товаров.
Еще одной интересной деталью было то, что много чеков проводились с разницей в несколько минут. Когда же отследили этих клиентов в базе программы лояльности, оказалось, что владельцами двух дисконтных карт были сотрудники магазина.
Вопрос: может сотрудники таким образом склоняли клиентов к покупке? или зарабатывали себе дисконтные баллы? или продавали товар по полной стоимости, а разницу присваивали, то есть, мошенничали?
Вместо вывода.
Использование кластеризации позволит компаниям выстроить с клиентами личные отношения и работать с ними по-новому. Индивидуальный подход к каждому клиенту повысит лояльность потребителей, и несомненно приведет к увеличению прибыли.
