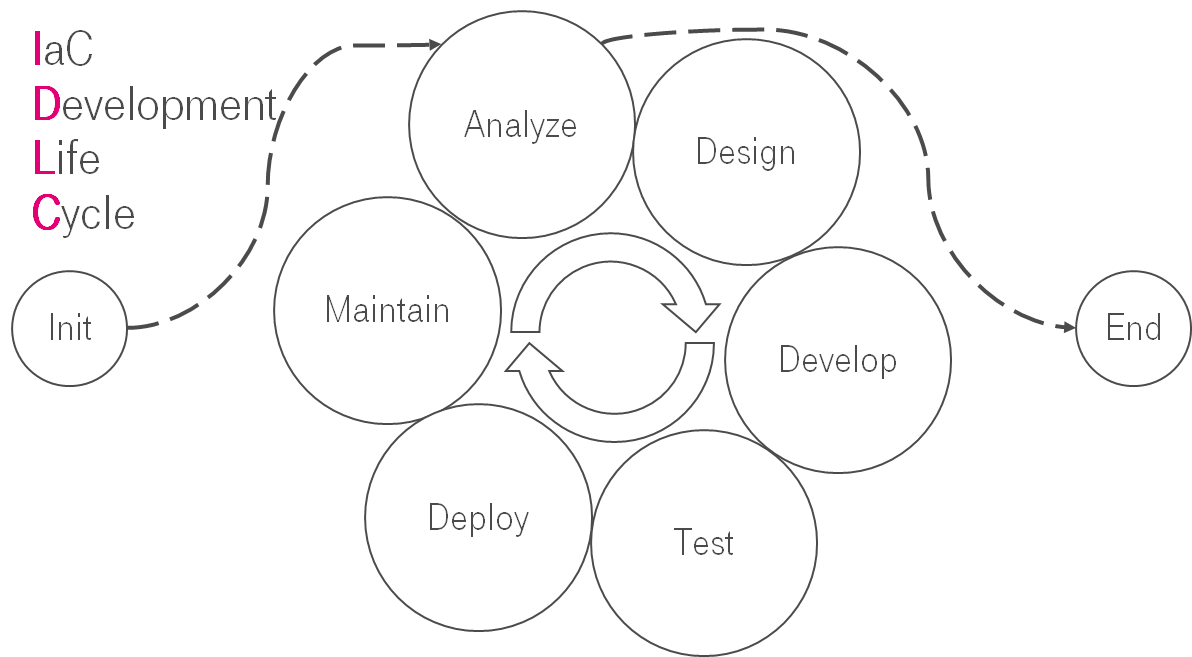
IaC Development Life Cycle
This is the translation of my speech at T-Meetup: DevOps Life Cycle.
I believe that you have heard about SDLC (Systems development life cycle). Is it possible that the same things are applicable for the IaC?
Configuration Management

What is configuration management? CM is a systems engineering process for establishing and maintaining the consistency of a system's configuration with its requirements. Let's think about this together. What does it mean? Originally, it means that you create some kind of guidelines & workflows. It describes how to manage changes; your servers; systems and so on. Also, it should reduce the count of the unique server's configuration. Sometimes, it helps to reduce configuration drift. It helps to make your infrastructure reproducible & predictable. Generally, it boils down to:
- Managing file content.
- Configuration templating.
- System and service state.
- Package management.
- Lifecycle management.
About 10-20 years ago it was quite popular to use Configuration Management. Where were ITIL, ITSM and some other approaches and methodologies for dealing with chaos & unique snowflakes in your infrastructure. Later appeared Configuration Management solutions like CFEngine, Chef, Puppet, Ansible, DSC etc. They helped to automate things and represent agreements about your infrastructure as code. Somebody called that Infrastructure as Code (IaC).
According to Wikipedia
IaC is the process of managing and provisioning computer data centers through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools. The IT infrastructure managed by this process comprises both physical equipment, such as bare-metal servers, as well as virtual machines, and associated configuration resources.

Pushing playbooks into git does not mean that you have IaC. I.e. I migrated a custom configuration management solution. It was 18 months long journey. It took so much time because we were creating new processes & reverse engineering existing ones.
IaC Development Life Cycle
Here we are. From my point of view, processes in IaC are quite similar to software development. The processes are similar to SDLC. IaC changes are looped & constantly follow the same root. Let's put things in order.
Preliminary analysis

On the one hand, what's worth the prize is always worth the fight. But on the other hand, you should rapidly answer three simple questions:
- Do I have a reason for those changes?
- Do I have enough time to do it?
- Do I have enough knowledge about it?
If your answers are negative, then changes might be a problem or a challenge for you. You can do things worse. But remember:
Analyze

Ok, we are ready to analyze. But what is the first step? Let's sidestep. What do you see in the picture below? It's the embankment. It's not far from Deutsche Telekom IT Solutions office in Saint Petersburg. Also, there are 3 people. They make a walk along the embankment. Is it a coincidence? No! You can see that people are analyzing the upcoming changes. Before Covid-19 we used to discuss our infrastructure problems, challenges and search for new ideas during lunch walk. I see the correlation between low-intensity cardio & mental power.

There are formal mechanisms to analyze & plan upcoming activities. I.e. a retrospective is one of them.
- Pin stickers on a wall.
- Discuss bad, good, interesting things in the sprint/release.
- Conclude.
- Prepare action points.

Nowadays, it does not make sense to organize an on-site retrospective each time. There are a lot of tools to do it online. It allows you to use the same techniques.
Design

After the idea has been formalized you need to think through it. You go deeper into details.
In our case we used to:
- Meet with all infrastructure team.
- Get a marker pen.
- Draw on the whiteboard

If the weather was fine we were sitting in the backyard of our office & were drawing there.

In case of world distributed teams, it's not a big deal. There are some approaches like
- SurveyMonkey for collecting ideas.
- Threads in mattermost/slack.
- Emails lists.
- Miro boards.

For online brainstorming, we use hedgedoc. It's kind of google docs but with markdown syntax. These documents can be used as meetings minutes or sent as follow up.
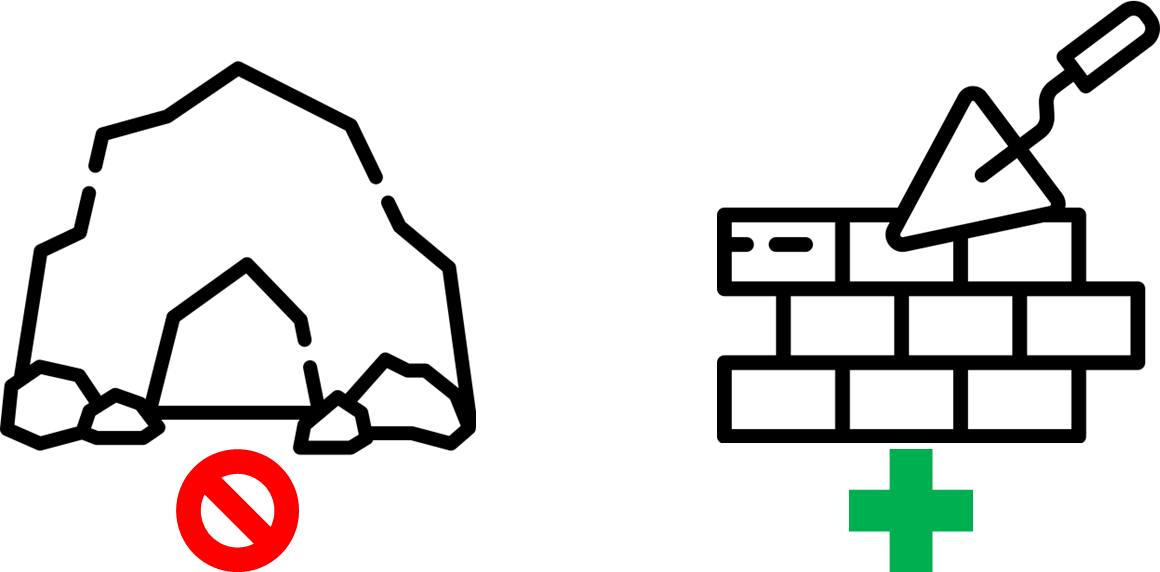
The main concept at this stage is not to build monolith infrastructure. It should be constructed from simple reusable bricks. I.e. If the config file size is bigger than 1000 SLOC then you should reduce complexity somehow: split to multiple well-organized configs.
Development
Here we are. Only after an immense amount of steps we are ready to write code for our IaC.Good try but no. Before that, we should prepare our IaC development environment.
Development environment

If you use a unified development environment it helps you do not reinvent the wheel. It helps your team to be on the same page & troubleshoot the same bugs. Interesting thing is that you can present development as code and store it in a repository. Usually, I use vscode + remote-ssh / vagrant / ansible.
Development process
For improving IaC development process you can reuse best practices from the software development world. There are a lot of them like the green build master approach, pair DevOpsing, testing, mentoring, code review, etc. If you are really interested in that you can read the article Lessons learned from testing Over 200,000 lines of Infrastructure Code.
Test
Testing pyramid

I suppose that everybody has heard about XP practices or has been involved somehow in that process. There is almost the same for IaC. Those practices are based on a feedback loop. The crucial part of that feedback is testing. It helps you rapidly & cheaply check your changes. The gist of the pyramid is to have a lot of cheap & fast tests as the foundation. Also, there are some expensive & long scenarios on the top.
We can split IaC testing pyramid into some layers:
- Static Analysis — a lot of simple, rapid, primitive tests in your foundation. Linters like shellchek, ansible lint, yamllint.
- Unit — you run something to validate your code molecule / kitchen + testinfra / inspec. So, your IaC should be constructed from simple bricks: roles, modules.
- Integration — They look like unit tests, but they are testing not small blocks, but the whole server configuration.
- E2E — check that group of servers work correctly as an infrastructure.
Tests implementation
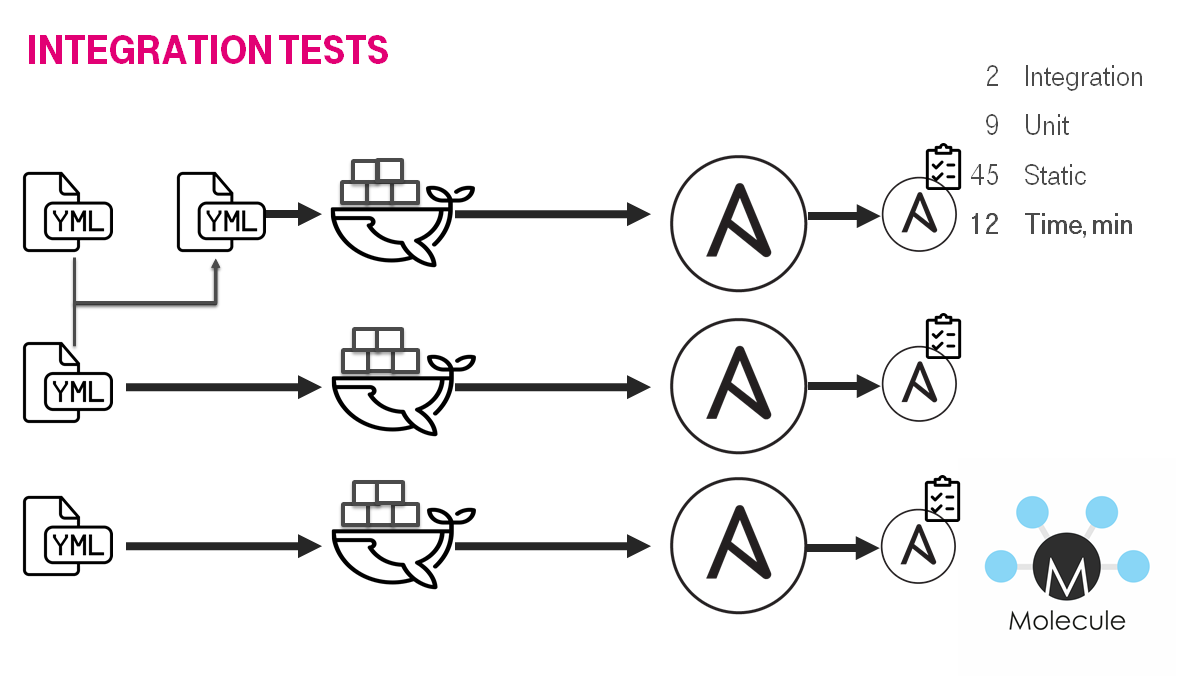
You may ask: How does the testing process work under the hood? Answer is more or less simple. The problem is that those tests are time-consuming mostly. Usually, they work about 5-15 mins. Let's take a look at ansible roles. There is an awesome molecule. It does for each role/playbook:
- Create instance (docker container / virtual machine).
- Converge a role or a playbook.
- Check idempotency.
- Verify the instance configuration.
It might be interesting to read Lessons learned from testing Over 200,000 lines of Infrastructure Code and/or How to test Ansible and don't go nuts for deeper understanding.
When should I start testing my IaC?

It's a pretty good question. There is no universal answer for that. Each team/project looks for it. However, I can share some numbers which I use as a lighthouse.
- 200 — linting must be started from the very beginning.
- 2000 — unit tests should be written. You don't run the molecule at this stage you will have problems in the future.
- 4000 — integration tests can be implemented.
- 6000 — E2E tests might be presented.
Deploy
Deploy automation

My strong advice is to avoid applying changes from your laptop or personal PC. You should use a reproducible environment with pinned software versions. It helps to track, observe & control changes. Fortunately, the price for that is not stratospheric. I guess almost everyone has CI/CD. It means you can simply create one more additional worker node & job for automating IaC staff. Let's take a look at simple Jenkins job: provision instance in the cloud:
- Terraform converges infrastructure to the desired state.
- Ansible converges VMs.
You can use awx / ansible tower / GitLab / GitHub actions /… instead of Jenkins. It is just an example of how we do it because we have Jenkins. Please keep in mind that with great power comes great responsibility. If you automate something badly you can make painful changes to your infrastructure. If you do automation you have to care about code review, testing, observability, etc.
Air gap

Sometimes full automation can be an impossible ideal, a pipe dream. I.e. we faced an air-gap to a customer. There was no direct connection to the customer environment. We found a solution for that. The gist was to split deploy into two parts:
- In our network:
- Run Ansible with specific tags, Ansible collects required artefacts.
- Copy packed artefacts to a USB stick.
- Go to customer.
- In customer network:
- Run Ansible with specific tags.
- Wait till installation will be done as usual skipping the downloading artefact stage.
You might want to agree that testing is becoming a crucial part of that scheme. It is important because nobody wants to be in an awkward situation on the customer site. Moreover, sometimes it requires too much time for getting access, travelling, etc.
Maintain

Infrastructure is not static. It is alive like a creature. It is changing every moment. And those changes lead to chaos by default. The interesting thing is that it is fine & expected. If you have agreements about infrastructure & they are presented as code then it is easier to maintain infrastructure and introduce changes.
Let me explain the chart:
- Horizontal axis — timeline.
- Right vertical axis — SLOC for Ansible roles(blue line).
- Left vertical axis — the number of tested/linted roles/playbooks.
- Blue line — Source Lines Of Code in YAML files.
- Red filler — the number of tested roles/playbooks.
- Magenta line — the number of engineers.
After some time, the velocity of changing infrastructure might go down. It is totally ok. From my point of view, there is a correlation between the number of agreements & SLOC of your IaC. I'm not 100% sure that it's the best way to visualize agreements, but it looks like there are some remarks:
- The amount of code is constantly growing.
- The amount of tests is exponentially growing.
- The amount of tests correlates with the amount of code with a time gap.
- The number of engineers is constant.
There is a conclusion from that. We can support IaC growth with a constant amount of engineers because of IaC tests. In other words, IaC testing increases the velocity of changes and makes it cheaper. There is an explanation of that: Agreements as Code: how to refactor IaC and save your sanity?.
Evaluation

I would like to show evolution via a very simple example. Let us imagine that we should install a web application. In the very beginning, it is a simple playbook. The playbook contains all code for installing web-application and a database.

Sooner or later it grows because of new agreements, corner cases, environments, whatever… If it is more than 500 SLOC you might want to split it into two parts: database & web-server. It makes sense because we build infrastructure from simple reusable bricks(Do you remember about tests & code review?).

A bit later you might face a request to support a new OS, web server, etc. The playbook is growing again. The size of the playbook is too big again.

It's an extremely good opportunity to split a complex playbook into simple parts. It's an infinitive process. The complexity of any system is constantly growing and it is ok. The only one thing that can be done: we can slow down exponential complexity growing via review.
End

One does not simply push ansible playbooks to git and say that it is IaC. You should care about creating processes for IaC. Fortunately, you should not reinvent the wheel because you can reuse approaches from the software development world.
Links
- Slides
- Video
- Cross post in personal blog
- A list of awesome IaC testing articles, speeches & links
- How to test Ansible and don't go nuts
- Agreements as Code: how to refactor IaC and save your sanity?
- Lessons learned from testing Over 200,000 lines of Infrastructure Code
- Ansible: CoreOS to CentOS, 18 months long journey
