Что является важным при разработке текстового редактора? Конечно же, «снабдить» его богатым функционалом и обеспечить стабильную работу. Однако многие скажут, что этого недостаточно, чтобы проект действительно был успешным. Нужно его сделать еще и «удобным» для конечного пользователя. А что является важным при разработке такого компонента как текстовый редактор? Да пожалуй, то же самое, вот только удобным он должен быть не только для конечного пользователя, но и для разработчика, который на его основе будет писать приложение.
На первый взгляд удовлетворить и тех, и других будет непросто – одним нужно понятное UI, снабженное набором полезных инструментов, другим – API, позволяющее выполнять широкий спектр задач. Однако зачастую эти задачи связаны друг с другом.
В ходе разработки и поддержки текстового редактора XtraRichEdit мы видели, что некоторые разработчики пишут на его основе редактор языков программирования. Основным требованием таких пользователей была возможность осуществить подсветку синтаксиса. Для этого необходима поддержка поиска по регулярным выражениям, чтобы обеспечить возможность выделения из текста синтаксических блоков и отдельных ключевых слов.
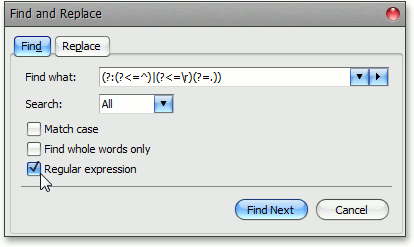
В то же время, сложно себе представить редактор, не обеспечивающий поиск по тексту. Конечно же, далеко не каждый редактор предоставляет возможность искать подстроки по регулярным выражениям, но «плох тот рядовой, который не мечтает стать генералом», поэтому мы ориентировались на более «продвинутые» продукты типа MS Word.
Реализация алгоритма поиска по регулярным выражениям заняла бы большое количество времени, включая отладку и тестирование. Чтобы не изобретать велосипед, мы решили воспользоваться реализацией, имеющейся в .NET Framework.
При этом, основная сложность заключалась в том, что содержимое документа в XtraRichEdit (а также в большинстве текстовых редакторов) представлено не просто строкой, а коллекцией объектов, представляющих фрагменты текста с единым форматированием.
А .NET-овский RegEx принимает на вход строку и только строку (что помешало сделать на входе что-то типа IEnumerable<char> для меня до сих пор загадка. В результате даже поиск по регулярным выражением в Stream становится головной болью).
Но даже получив содержимое документа в виде строки (что не представляет большой сложности), довольно сложно преобразовать полученный результат поиска в позиции модели документа. Это связано с наличием в документе скрытых символов и текста, которые могут не отображаться, но быть представленными в общей структуре документа.
Однако, мы нашли выход. Основная идея заключалась в следующем: фрагмент документа извлекается в буфер и хранится в виде строки (рис. 1). Имея дело с небольшим фрагментом документа и зная смещение буфера относительно начала поиска в абсолютной величине (с учётом скрытого текста), несложно определить положение найденной подстроки.
К тому же это делается без необходимости извлечения всего документа в строку (что достаточно сильно сказывается на производительности приложения), возрастает скорость поиска. Поиск соответствия регулярному выражению производится в пределах этого буфера. Если соответствие не найдено, буфер смещается относительно документа на определенную длину – величину смещения (рис. 2) и снова производится поиск.

Рис. 1.
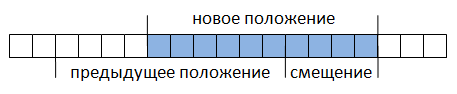
Рис. 2.
Величина буфера и смещения зависят от возможной длины результата поиска, т. е. максимальная длина наибольшего результата не должна превышать длину буфера. Найденное соответствие считается искомым в следующих случаях:
Ненулевое смещение говорит о том, что в предыдущем положении буфера результат найден не был, следовательно, результат, лежащий в начале буфера, был получен урезанием строки поиска при смещении (рис. 3).
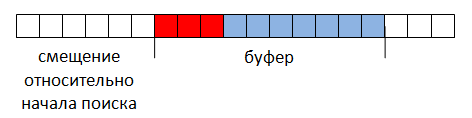
Рис. 3.
Результат, лежащий в конце буфера, отбрасывается по той же самой причине: строка поиска ограничена размерами буфера и реальный результат может пересекать границу буфера.
Приведем пример. Имеется строка — “DevExpress is a great company!”. Содержимое буфера в данный момент – “press is a gre” (рис. 4).

Рис. 4.
Пусть необходимо найти все слова, длина которых больше или равно трем символам. Регулярное выражение в этом случае должно быть таким: “\b\w{3,}\b”. Произведя поиск, получаем первое соответствие – “press”. Оно полностью удовлетворяет искомому выражению, однако не является результатом. Поиск следующего соответствия дает нам “gre”, что также не является результатом. Если величина смещения буфера равна четырём символам, то следующее значение буфера соответствует подстроке “s is a great c”. Результат поиска “great” находится в середине буфера и полностью соответствует регулярному выражению и поэтому может считаться искомым результатом.
Рассмотрим теперь случай, когда найденный результат лежит в начале буфера и смещение буфера равно нулю. В каком случае данный результат может считаться искомым? Очевидно, если начало интервала поиска совпадает с началом документа. Если это не так, то необходима дополнительная проверка, не пересекает ли результат границу интервала поиска. Для этого необходимо перед началом поиска сместить левую границу интервала на один символ влево. Если найденный результат лежит вначале смещенного интервала поиска, то данный результат не является искомым. Такую же проверку необходимо произвести и с результатом, примыкающим к правой границе интервала поиска.
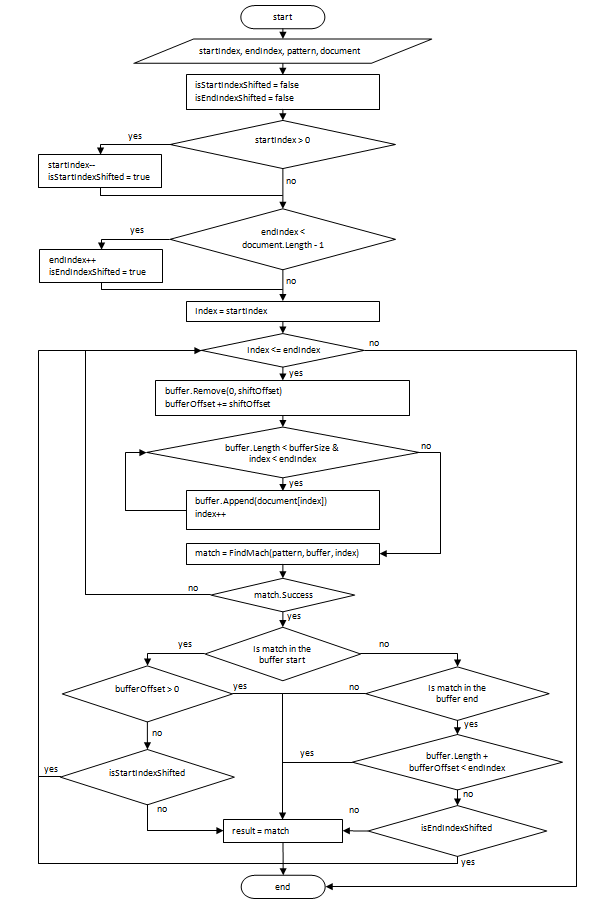
Блок-схема алгоритма поиска представлена ниже.
Входные параметры:
Используя этот алгоритм, вы можете сделать реализацию поиска по регулярным выражениям в документе, представленным не строкой, а набором произвольных объектов. При этом механизм не требует реализации алгоритма «с чистого листа» и использование сторонних библиотек.
На первый взгляд удовлетворить и тех, и других будет непросто – одним нужно понятное UI, снабженное набором полезных инструментов, другим – API, позволяющее выполнять широкий спектр задач. Однако зачастую эти задачи связаны друг с другом.
В ходе разработки и поддержки текстового редактора XtraRichEdit мы видели, что некоторые разработчики пишут на его основе редактор языков программирования. Основным требованием таких пользователей была возможность осуществить подсветку синтаксиса. Для этого необходима поддержка поиска по регулярным выражениям, чтобы обеспечить возможность выделения из текста синтаксических блоков и отдельных ключевых слов.
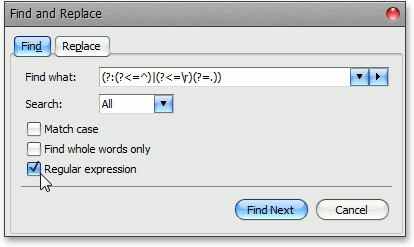
В то же время, сложно себе представить редактор, не обеспечивающий поиск по тексту. Конечно же, далеко не каждый редактор предоставляет возможность искать подстроки по регулярным выражениям, но «плох тот рядовой, который не мечтает стать генералом», поэтому мы ориентировались на более «продвинутые» продукты типа MS Word.
Реализация алгоритма поиска по регулярным выражениям заняла бы большое количество времени, включая отладку и тестирование. Чтобы не изобретать велосипед, мы решили воспользоваться реализацией, имеющейся в .NET Framework.
При этом, основная сложность заключалась в том, что содержимое документа в XtraRichEdit (а также в большинстве текстовых редакторов) представлено не просто строкой, а коллекцией объектов, представляющих фрагменты текста с единым форматированием.
А .NET-овский RegEx принимает на вход строку и только строку (что помешало сделать на входе что-то типа IEnumerable<char> для меня до сих пор загадка. В результате даже поиск по регулярным выражением в Stream становится головной болью).
Но даже получив содержимое документа в виде строки (что не представляет большой сложности), довольно сложно преобразовать полученный результат поиска в позиции модели документа. Это связано с наличием в документе скрытых символов и текста, которые могут не отображаться, но быть представленными в общей структуре документа.
Однако, мы нашли выход. Основная идея заключалась в следующем: фрагмент документа извлекается в буфер и хранится в виде строки (рис. 1). Имея дело с небольшим фрагментом документа и зная смещение буфера относительно начала поиска в абсолютной величине (с учётом скрытого текста), несложно определить положение найденной подстроки.
К тому же это делается без необходимости извлечения всего документа в строку (что достаточно сильно сказывается на производительности приложения), возрастает скорость поиска. Поиск соответствия регулярному выражению производится в пределах этого буфера. Если соответствие не найдено, буфер смещается относительно документа на определенную длину – величину смещения (рис. 2) и снова производится поиск.

Рис. 1.
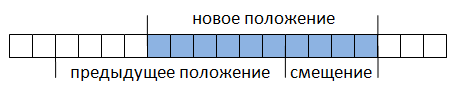
Рис. 2.
Величина буфера и смещения зависят от возможной длины результата поиска, т. е. максимальная длина наибольшего результата не должна превышать длину буфера. Найденное соответствие считается искомым в следующих случаях:
- результат лежит в начале буфера при условии, что смещение положения буфера относительно начала поиска нулевое
- результат лежит в середине буфера.
Ненулевое смещение говорит о том, что в предыдущем положении буфера результат найден не был, следовательно, результат, лежащий в начале буфера, был получен урезанием строки поиска при смещении (рис. 3).
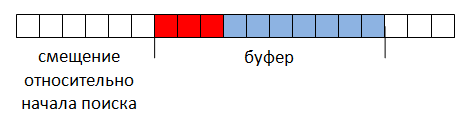
Рис. 3.
Результат, лежащий в конце буфера, отбрасывается по той же самой причине: строка поиска ограничена размерами буфера и реальный результат может пересекать границу буфера.
Приведем пример. Имеется строка — “DevExpress is a great company!”. Содержимое буфера в данный момент – “press is a gre” (рис. 4).

Рис. 4.
Пусть необходимо найти все слова, длина которых больше или равно трем символам. Регулярное выражение в этом случае должно быть таким: “\b\w{3,}\b”. Произведя поиск, получаем первое соответствие – “press”. Оно полностью удовлетворяет искомому выражению, однако не является результатом. Поиск следующего соответствия дает нам “gre”, что также не является результатом. Если величина смещения буфера равна четырём символам, то следующее значение буфера соответствует подстроке “s is a great c”. Результат поиска “great” находится в середине буфера и полностью соответствует регулярному выражению и поэтому может считаться искомым результатом.
Рассмотрим теперь случай, когда найденный результат лежит в начале буфера и смещение буфера равно нулю. В каком случае данный результат может считаться искомым? Очевидно, если начало интервала поиска совпадает с началом документа. Если это не так, то необходима дополнительная проверка, не пересекает ли результат границу интервала поиска. Для этого необходимо перед началом поиска сместить левую границу интервала на один символ влево. Если найденный результат лежит вначале смещенного интервала поиска, то данный результат не является искомым. Такую же проверку необходимо произвести и с результатом, примыкающим к правой границе интервала поиска.
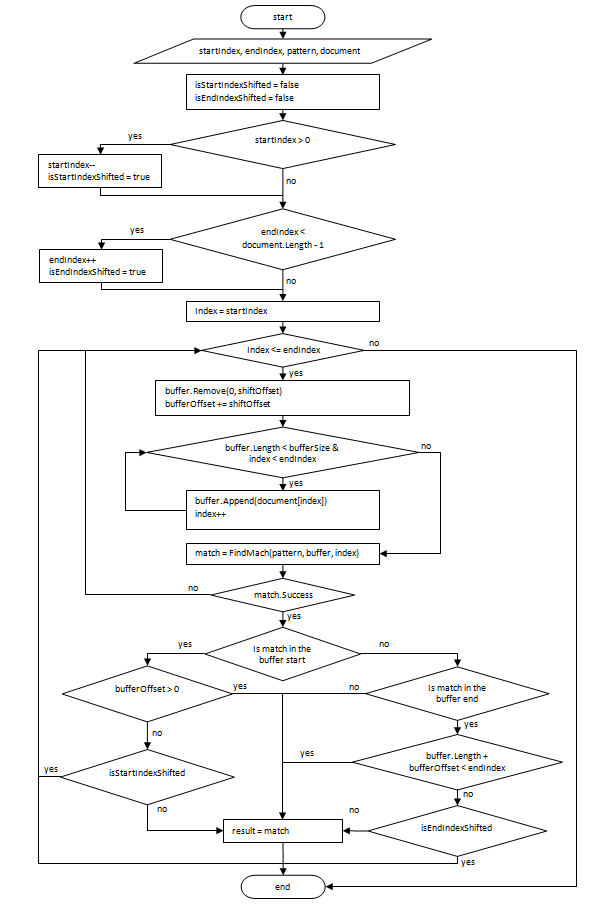
Блок-схема алгоритма поиска представлена ниже.
Входные параметры:
- pattern — регулярное выражение;
- shiftOffset — величина смещения буфера на каждом шаге, костанта;
- bufferOffset — смещение буфера относительно начала поиска;
- document — объект, представляющий документ;
- startIndex, endIndex — границы поиска;
Используя этот алгоритм, вы можете сделать реализацию поиска по регулярным выражениям в документе, представленным не строкой, а набором произвольных объектов. При этом механизм не требует реализации алгоритма «с чистого листа» и использование сторонних библиотек.
