
В предыдущей статье я рассказывал, как построить простой кластер Kubernetes с одним мастер-узлом. Прошло время, опали листья... и мне захотелось большего, поэтому решил позариться на высокодоступные кластеры. В интернете много статей о том, как построить подобное решение, и давайте даже опустим тот факт, что многие из них уже устарели. Одно дело — установить кластер, а как же обслуживание: удаление, добавление, замена узлов? Про это и не вспоминают! В итоге оказалось, что не всё так просто, и вот, спустя больше ста установок, удалений и замен, у меня получилось собрать подробнейшее руководство по установке и, главное, обслуживанию highly available кластера с помощью Kubespray.
Оглавление
Введение
Высокодоступный кластер (aka high-availability) - это еще один шажок к production-ready кластеру. Как написано в официальной документации, построить высокодоступный кластер значит:
Отделить плоскость управления (мастер) от рабочих узлов
Реплицировать компоненты плоскости управления на несколько узлов
Добавить балансировщик нагрузки на API Kubernetes
Иметь достаточное количество рабочих узлов, чтобы выдержать нештатные ситуации и высокие нагрузки
Если подходить серьезно к вопросу, то наш будущий кластер будет квази high-available (в основном из-за внешнего балансировщика). Кластер будет состоять из четырёх узлов — двух мастеров и двух рабочих. Машины с характеристиками получше можно использовать как рабочие, а машины послабее — как мастера. На последних не будет запускаться рабочая нагрузка.
Сетап кластера:
Kubenetes version - 1.23.7
Сontainer runtime - Сontainerd 1.6.4
Network plugin - Calico 3.22.3
Доступные виртуалки и их роли я распределил так:
IP 185.186.142.53 - Master #1
IP 185.186.142.5 - Master #2
IP 46.8.19.144 - Worker #1
IP 46.8.19.244 - Worker #2
У всех машин характеристики: 2 CPU 3,0 ГГц, 4 Гб RAM, 100 Гб HDD, ОС Ubuntu 20.04. На рабочих машинах заявлена частота процессора 3,6 ГГц, хотя команда grep MHz /proc/cpuinfo говорит, что фактически 3 ГГц (на мастер-узлах и того чуть меньше). По стоимости четыре машины в месяц обходятся в 2700 руб. (с учётом скидки за оплату на три месяца вперёд). Хочу опять отметить, насколько такой handmade дешевле Kubernetes-as-a-Service решений, аж на 75%!
Важно (но не обязательно) чтобы ваш VPS провайдер поддерживал снимки виртуальных машин, это облегчит обслуживание и тренировку по установке кластера.
Устанавливать кластер будем с домашней машины (далее — Ansible-машина). На ней должны быть Python, Ansible версии 2.4 или выше, и Jinja (это всё мы установим немного позже).
Большая головная боль при установки Kubernetes на "голое" железо - это отсутствие внешнего балансировщика. Для пользователя облачного сервиса GKE или AWS балансировщик прилагается в комплекте.
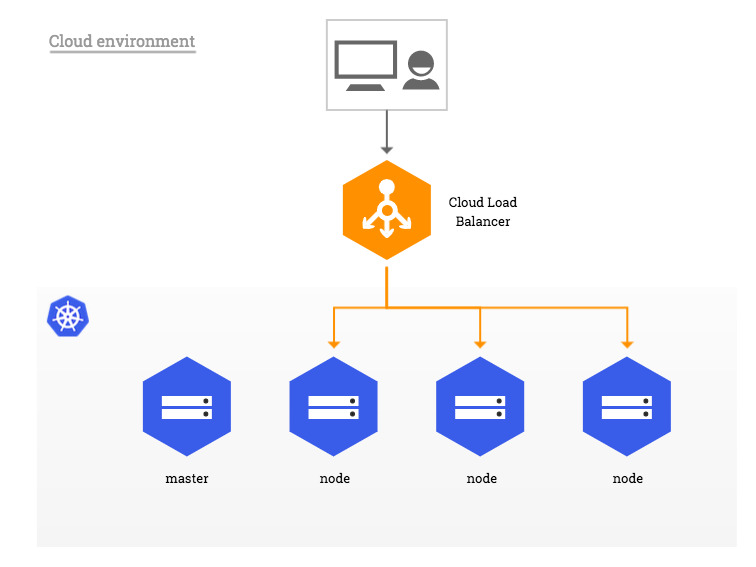
В предыдущей своей статье проблему решал с помощью MetalLb, в этот раз попробую другой подход. Все 4 узла смогут принимать трафик извне, так как поды ingress-nginx будут развернуты на каждом узле (с помощью ресурса Daemonset) и использовать порт 80/443 этой машины.

И конечно нужно привести цитату с предостережением по безопасности данного решения:
Enabling this option exposes every system daemon to the NGINX Ingress controller on any network interface, including the host's loopback. Please evaluate the impact this may have on the security of your system carefully.
Заключительный штрих - я заказал доменное имя awesomeservice.pro на которое будут разрешаться все 4 IP адреса, таким образом задействуем DNS балансировку трафика. Балансировка осуществляется с помощью алгоритма Round Robin — алгоритма кругового обслуживания. Первый запрос передается одному серверу, затем следующий запрос передается другому, и так далее до достижения последнего сервера. Затем направление запросов начинается сначала. Это самое бюджетное и простое решение которое я нашел на данный момент. Именно из-за DNS балансировки будущий кластер выйдет почти высокодоступным. Данное решение имеет ряд неприятных минусов:
Сложно управлять пулом адресов. Хорошо если DNS провайдер предоставляет API для программного изменения адресов. Но это лишний софт, плюс надо учитывать TTL на стороне клиента, его в таком случае советуют ставить на минимальное значение.
И самая большая проблема - нет отслеживания состояния серверов. Если одна машина из пула выйдет из строя, DNS сервер все равно будет отдавать этот адрес. Эту проблему и её последствия я наглядно продемонстрирую после установки кластера.
альтернативное решение
Если ваш VPS провайдер позволяет создавать Virtual IP, то можно его привязать ко всем 4 удаленным машинам и тогда не нужна будет никакая DNS балансировка. Мой провайдер, к сожалению, не предоставляет такой функционал, поэтому протестировать такое решение не могу. А там, где есть данная фича VPS стоят неоправданно дорого.
Приступим к делу.

Установка высокодоступного Kubernetes-кластера
В основе главы лежит эта статья, но на текущий момент она уже устарела, поэтому некоторые разделы будут продублированы и дополнены либо изменены.↑
Настройка виртуальных машин
Этот раздел необходимо выполнить для каждой виртуальной машины будущего кластера. Прежде всего настроим SSH-доступ без пароля. Для этого выполните команду ssh-copy-id на своей локальной машине. Например, у меня она выглядит так:
ssh-copy-id root@185.186.142.53Тут необходимо будет ввести пароль от удалённой машины. После успешного выполнения команды подключаемся к удалённой машине без пароля:
ssh root@185.186.142.53Установим Python:
sudo apt update
sudo apt install pythonВключим переадресацию IPv4:
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.confОтключим подкачку памяти:
swapoff -aПример из жизни №1
Раньше я полагал, что поставщики виртуалок предоставляют чистые образы ОС. Как оказалось, это не совсем так. Я пробовал установить Kubernetes на VPS двух провайдеров. У первого всё работало замечательно, а у второго (который был предпочтителен из-за низкой цены) установка кластера прерывалась на середине из-за внезапного пропадания интернета, а точнее, невозможности скачать определённый файл.
Поиск в интернете упорно ничего не давал, подсказали только в техподдержке: предложили заглянуть в файл resolv.conf и проверить наличие в конфигурации серверов адресов 1.1.1.1 или 8.8.8.8. Как оказалось, у этого провайдера интересная преднастройка ОС, и файл /etc/resolv.conf представляет собой simlink. О чём недвусмысленно сообщал объёмный комментарий в самом файле:
# This file is managed by man:systemd-resolved(8). Do not edit.
#
# This is a dynamic resolv.conf file for connecting local clients to the
# internal DNS stub resolver of systemd-resolved. This file lists all
# configured search domains.
#
# Run "resolvectl status" to see details about the uplink DNS servers
# currently in use.
#
# Third party programs must not access this file directly, but only through the
# symlink at /etc/resolv.conf. To manage man:resolv.conf(5) in a different way,
# replace this symlink by a static file or a different symlink.
#
# See man:systemd-resolved.service(8) for details about the supported modes of
# operation for /etc/resolv.conf.
nameserver 127.0.0.53
options edns0 trust-ad
search template
И в самом файле, конечно, этих резолверов обнаружено не было. Проблему удалось решить только удалением simlink и пересозданием файла с добавлением двух DNS-резолверов (в принципе, будет достаточно одного 1.1.1.1 или 8.8.8.8).
В итоге файл выглядит следующим образом:
nameserver 127.0.0.53
options edns0 trust-ad
search template
nameserver 8.8.8.8
nameserver 1.1.1.1Удаленная машина успешно настроена и готовка к установке Kubernetes. Инструкции из этого подраздела повторите на всех оставшихся машинах будущего кластера.
Также крайне рекомендую на этом этапе сделать снимок системы, чтобы при переустановке кластера можно было откатить систему до текущего состояния. Причём даже не понадобится перенастраивать SSH-доступ без пароля. И тогда в будущем об этом подразделе можно забыть. Функциональность снимков предоставляется провайдером VPS (у меня это vmmanager).
Настройка Ansible-машины
Эти инструкции нужно выполнить только на своей локальной машине, с которой будет устанавливаться Kubernetes. Перейдите в подготовленную директорию и клонируйте репозиторий проекта Kubespray:
git clone git@github.com:kubernetes-sigs/kubespray.git
cd kubesprayПомните, что подобные инструкции по установке любого софта без указания версии могут в будущем привести к проблемам. Либо статья устареет, либо новые версии могут быть обратно несовместимыми. Если вы уверены в себе и готовы решать проблемы и несостыковки, клонируйте мастер-ветку. У меня на данный момент tag v2.19.0. Команда для переключения:
git checkout tags/v2.19.0Перейдём к установке Kubernetes-кластера. Подготовим наш инвентарь, шаблон находится в папке sample, мы его скопируем под новым именем и будем использовать при установке:
cp -rfp inventory/sample inventory/k8sДолжна появиться новая директория k8s. Теперь объявим переменную IPS массивом с перечислением наших виртуальных машин, это нужно для последующего генерирования конфигурации:
declare -a IPS=(185.186.142.5 185.186.142.53 46.8.19.144 46.8.19.244)Сгенерируем конфигурацию в новый инвентарь:
CONFIG_FILE=inventory/k8s/hosts.yaml python3 contrib/inventory_builder/inventory.py ${IPS[@]}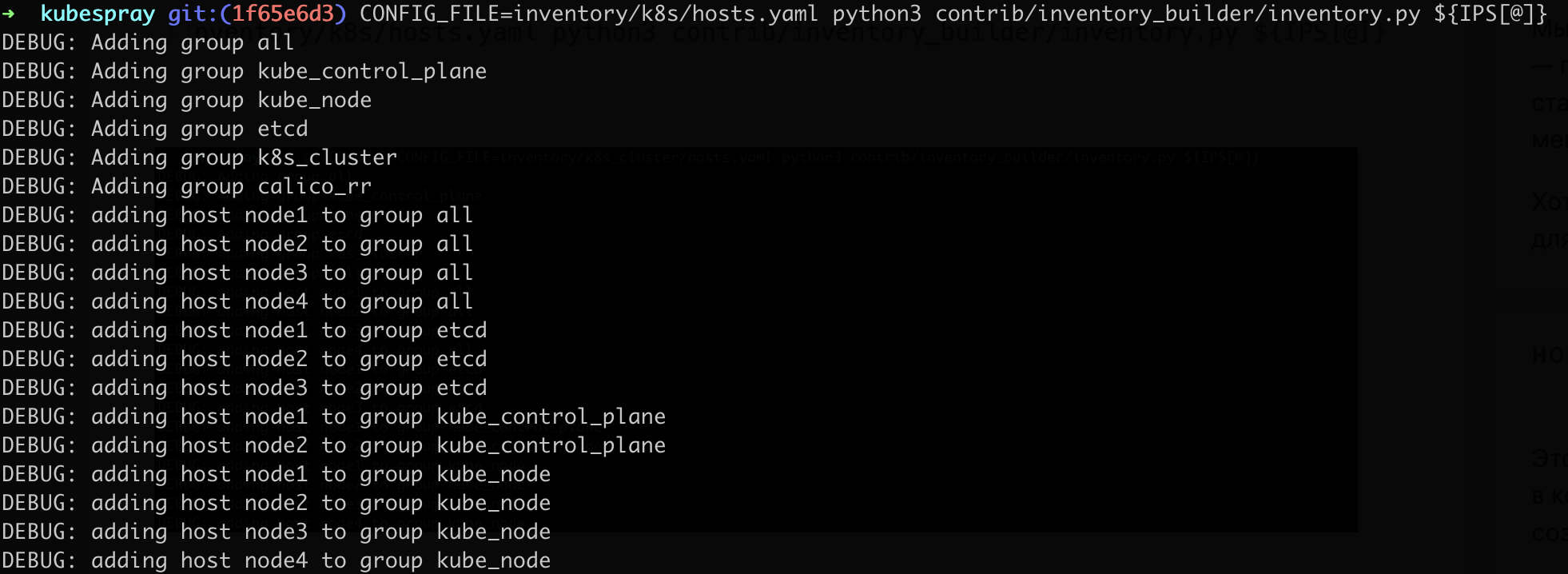
Был создан файл, посмотрим его содержимое:
nano inventory/k8s/hosts.yamlУ меня конфиг выглядит следующих образом
all:
hosts:
node1:
ansible_host: 185.186.142.5
ip: 185.186.142.5
access_ip: 185.186.142.5
node2:
ansible_host: 185.186.142.53
ip: 185.186.142.53
access_ip: 185.186.142.53
node3:
ansible_host: 46.8.19.144
ip: 46.8.19.144
access_ip: 46.8.19.144
node4:
ansible_host: 46.8.19.244
ip: 46.8.19.244
access_ip: 46.8.19.244
children:
kube_control_plane:
hosts:
node1:
node2:
kube_node:
hosts:
node1:
node2:
node3:
node4:
etcd:
hosts:
node1:
node2:
node3:
k8s_cluster:
children:
kube_control_plane:
kube_node:
calico_rr:
hosts: {}Получилась такая конфигурация кластера:
Мастер-узлы перечисляются в разделе
kube_control_plane, в моём случае это node1 и node2.Всего четыре Kubernetes-узла: node1, node2, node3 и node4.
Etcd-кластер будет установлен на три хоста: node1, node2 и node3. Три потому, что для etcd-кластера жизненно необходим кворум большинства, то есть всегда должно быть нечётное количество работающих узлов. Если попробуете удалить один из хостов в
etcd:hosts, то Ansible-роль завершится с ошибкой о необходимости нечётного количества узлов
Установка кластера
Настройки будущего кластера находятся в папке group_vars. Чтобы не устанавливать Helm вручную на каждом мастер-узле, установим в файле addons.yaml параметр helm_enable равным true:
# Helm deployment
helm_enabled: trueВ том же файле addons.yaml раскомментируем и активируем nginx-ingress, а также параметр ingress_nginx_host_network, благодаря которому, к каждому узлу будет привязана пода nginx-ingress:
# Nginx ingress controller deployment
ingress_nginx_enabled: true
ingress_nginx_host_network: trueИтоговый файл выглядит следующим образом
---
# Kubernetes dashboard
# RBAC required. see docs/getting-started.md for access details.
# dashboard_enabled: false
# Helm deployment
helm_enabled: true
# Registry deployment
registry_enabled: false
# registry_namespace: kube-system
# registry_storage_class: ""
# registry_disk_size: "10Gi"
# Metrics Server deployment
metrics_server_enabled: false
# metrics_server_container_port: 4443
# metrics_server_kubelet_insecure_tls: true
# metrics_server_metric_resolution: 15s
# metrics_server_kubelet_preferred_address_types: "InternalIP,ExternalIP,Hostname"
# Rancher Local Path Provisioner
local_path_provisioner_enabled: false
# local_path_provisioner_namespace: "local-path-storage"
# local_path_provisioner_storage_class: "local-path"
# local_path_provisioner_reclaim_policy: Delete
# local_path_provisioner_claim_root: /opt/local-path-provisioner/
# local_path_provisioner_debug: false
# local_path_provisioner_image_repo: "rancher/local-path-provisioner"
# local_path_provisioner_image_tag: "v0.0.21"
# local_path_provisioner_helper_image_repo: "busybox"
# local_path_provisioner_helper_image_tag: "latest"
# Local volume provisioner deployment
local_volume_provisioner_enabled: false
# local_volume_provisioner_namespace: kube-system
# local_volume_provisioner_nodelabels:
# - kubernetes.io/hostname
# - topology.kubernetes.io/region
# - topology.kubernetes.io/zone
# local_volume_provisioner_storage_classes:
# local-storage:
# host_dir: /mnt/disks
# mount_dir: /mnt/disks
# volume_mode: Filesystem
# fs_type: ext4
# fast-disks:
# host_dir: /mnt/fast-disks
# mount_dir: /mnt/fast-disks
# block_cleaner_command:
# - "/scripts/shred.sh"
# - "2"
# volume_mode: Filesystem
# fs_type: ext4
# local_volume_provisioner_tolerations:
# - effect: NoSchedule
# operator: Exists
# CSI Volume Snapshot Controller deployment, set this to true if your CSI is able to manage snapshots
# currently, setting cinder_csi_enabled=true would automatically enable the snapshot controller
# Longhorn is an extenal CSI that would also require setting this to true but it is not included in kubespray
# csi_snapshot_controller_enabled: false
# csi snapshot namespace
# snapshot_controller_namespace: kube-system
# CephFS provisioner deployment
cephfs_provisioner_enabled: false
# cephfs_provisioner_namespace: "cephfs-provisioner"
# cephfs_provisioner_cluster: ceph
# cephfs_provisioner_monitors: "172.24.0.1:6789,172.24.0.2:6789,172.24.0.3:6789"
# cephfs_provisioner_admin_id: admin
# cephfs_provisioner_secret: secret
# cephfs_provisioner_storage_class: cephfs
# cephfs_provisioner_reclaim_policy: Delete
# cephfs_provisioner_claim_root: /volumes
# cephfs_provisioner_deterministic_names: true
# RBD provisioner deployment
rbd_provisioner_enabled: false
# rbd_provisioner_namespace: rbd-provisioner
# rbd_provisioner_replicas: 2
# rbd_provisioner_monitors: "172.24.0.1:6789,172.24.0.2:6789,172.24.0.3:6789"
# rbd_provisioner_pool: kube
# rbd_provisioner_admin_id: admin
# rbd_provisioner_secret_name: ceph-secret-admin
# rbd_provisioner_secret: ceph-key-admin
# rbd_provisioner_user_id: kube
# rbd_provisioner_user_secret_name: ceph-secret-user
# rbd_provisioner_user_secret: ceph-key-user
# rbd_provisioner_user_secret_namespace: rbd-provisioner
# rbd_provisioner_fs_type: ext4
# rbd_provisioner_image_format: "2"
# rbd_provisioner_image_features: layering
# rbd_provisioner_storage_class: rbd
# rbd_provisioner_reclaim_policy: Delete
# Nginx ingress controller deployment
ingress_nginx_enabled: true
ingress_nginx_host_network: true
ingress_publish_status_address: ""
# ingress_nginx_nodeselector:
# kubernetes.io/os: "linux"
# ingress_nginx_tolerations:
# - key: "node-role.kubernetes.io/master"
# operator: "Equal"
# value: ""
# effect: "NoSchedule"
# - key: "node-role.kubernetes.io/control-plane"
# operator: "Equal"
# value: ""
# effect: "NoSchedule"
# ingress_nginx_namespace: "ingress-nginx"
# ingress_nginx_insecure_port: 80
# ingress_nginx_secure_port: 443
# ingress_nginx_configmap:
# map-hash-bucket-size: "128"
# ssl-protocols: "TLSv1.2 TLSv1.3"
# ingress_nginx_configmap_tcp_services:
# 9000: "default/example-go:8080"
# ingress_nginx_configmap_udp_services:
# 53: "kube-system/coredns:53"
# ingress_nginx_extra_args:
# - --default-ssl-certificate=default/foo-tls
# ingress_nginx_termination_grace_period_seconds: 300
# ingress_nginx_class: nginx
# ALB ingress controller deployment
ingress_alb_enabled: false
# alb_ingress_aws_region: "us-east-1"
# alb_ingress_restrict_scheme: "false"
# Enables logging on all outbound requests sent to the AWS API.
# If logging is desired, set to true.
# alb_ingress_aws_debug: "false"
# Cert manager deployment
cert_manager_enabled: false
# cert_manager_namespace: "cert-manager"
# cert_manager_tolerations:
# - key: node-role.kubernetes.io/master
# effect: NoSchedule
# - key: node-role.kubernetes.io/control-plane
# effect: NoSchedule
# cert_manager_affinity:
# nodeAffinity:
# preferredDuringSchedulingIgnoredDuringExecution:
# - weight: 100
# preference:
# matchExpressions:
# - key: node-role.kubernetes.io/control-plane
# operator: In
# values:
# - ""
# cert_manager_nodeselector:
# kubernetes.io/os: "linux"
# cert_manager_trusted_internal_ca: |
# -----BEGIN CERTIFICATE-----
# [REPLACE with your CA certificate]
# -----END CERTIFICATE-----
# cert_manager_leader_election_namespace: kube-system
# MetalLB deployment
metallb_enabled: false
metallb_speaker_enabled: true
# metallb_ip_range:
# - "10.5.0.50-10.5.0.99"
# metallb_pool_name: "loadbalanced"
# matallb_auto_assign: true
# metallb_speaker_nodeselector:
# kubernetes.io/os: "linux"
# metallb_controller_nodeselector:
# kubernetes.io/os: "linux"
# metallb_speaker_tolerations:
# - key: "node-role.kubernetes.io/master"
# operator: "Equal"
# value: ""
# effect: "NoSchedule"
# - key: "node-role.kubernetes.io/control-plane"
# operator: "Equal"
# value: ""
# effect: "NoSchedule"
# metallb_controller_tolerations:
# - key: "node-role.kubernetes.io/master"
# operator: "Equal"
# value: ""
# effect: "NoSchedule"
# - key: "node-role.kubernetes.io/control-plane"
# operator: "Equal"
# value: ""
# effect: "NoSchedule"
# metallb_version: v0.12.1
# metallb_protocol: "layer2"
# metallb_port: "7472"
# metallb_memberlist_port: "7946"
# metallb_additional_address_pools:
# kube_service_pool:
# ip_range:
# - "10.5.1.50-10.5.1.99"
# protocol: "layer2"
# auto_assign: false
# metallb_protocol: "bgp"
# metallb_peers:
# - peer_address: 192.0.2.1
# peer_asn: 64512
# my_asn: 4200000000
# - peer_address: 192.0.2.2
# peer_asn: 64513
# my_asn: 4200000000
argocd_enabled: false
# argocd_version: v2.1.6
# argocd_namespace: argocd
# Default password:
# - https://argoproj.github.io/argo-cd/getting_started/#4-login-using-the-cli
# ---
# The initial password is autogenerated to be the pod name of the Argo CD API server. This can be retrieved with the command:
# kubectl get pods -n argocd -l app.kubernetes.io/name=argocd-server -o name | cut -d'/' -f 2
# ---
# Use the following var to set admin password
# argocd_admin_password: "password"
# The plugin manager for kubectl
krew_enabled: false
krew_root_dir: "/usr/local/krew"Добавим в конфигурацию Ansible пользователя, под которым логинимся по SSH:
nano ansible.cfgВ группе ssh_connection добавьте параметр remote_user, равный root:
remote_user=rootПолностью файл выглядит так:
[ssh_connection]
pipelining=True
ssh_args = -o ControlMaster=auto -o ControlPersist=30m -o ConnectionAttempts=100 -o UserKnownHostsFile=/dev/null
#control_path = ~/.ssh/ansible-%%r@%%h:%%p
[defaults]
# https://github.com/ansible/ansible/issues/56930 (to ignore group names with - and .)
force_valid_group_names = ignore
host_key_checking=False
gathering = smart
fact_caching = jsonfile
fact_caching_connection = /tmp
fact_caching_timeout = 7200
stdout_callback = default
display_skipped_hosts = no
library = ./library
callback_whitelist = profile_tasks,ara_default
roles_path = roles:$VIRTUAL_ENV/usr/local/share/kubespray/roles:$VIRTUAL_ENV/usr/local/share/ansible/roles:/usr/share/kubespray/roles
deprecation_warnings=False
inventory_ignore_extensions = ~, .orig, .bak, .ini, .cfg, .retry, .pyc, .pyo, .creds, .gpg
remote_user=root
[inventory]
ignore_patterns = artifacts, credentialsИ наконец, команда запуска установки кластера. Выполните её в корне директории kubespray:
ansible-playbook -i inventory/k8s/hosts.yaml cluster.ymlУстановка кластера может занять от получаса до полутора часов, в зависимости от скорости интернета. После установки вывод в консоли должен быть примерно таким:
Теперь нужно проверить состояние узлов. Выполните команду:
kubectl get nodes
Затем важно проверить, работают ли системные поды (coredns, kube-controller-manager, kube-scheduler и тд.):
kubectl get pods -n kube-system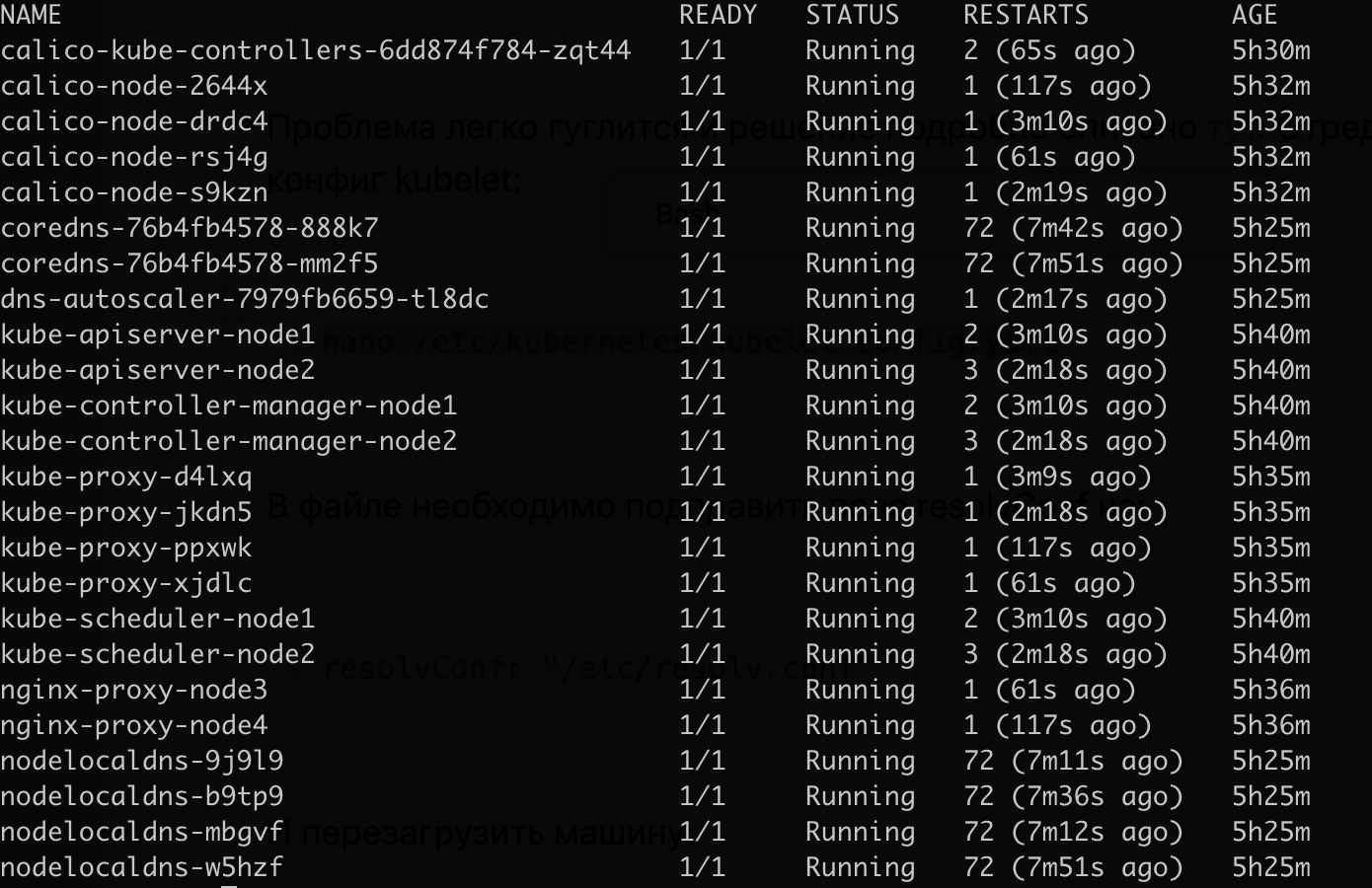
Если появилась ошибка CrashLoopBackOff (пример из жизни №2)
Возможно, после установки возникнет ошибка CrashLoopBackOff у coredns и nodelocaldns:
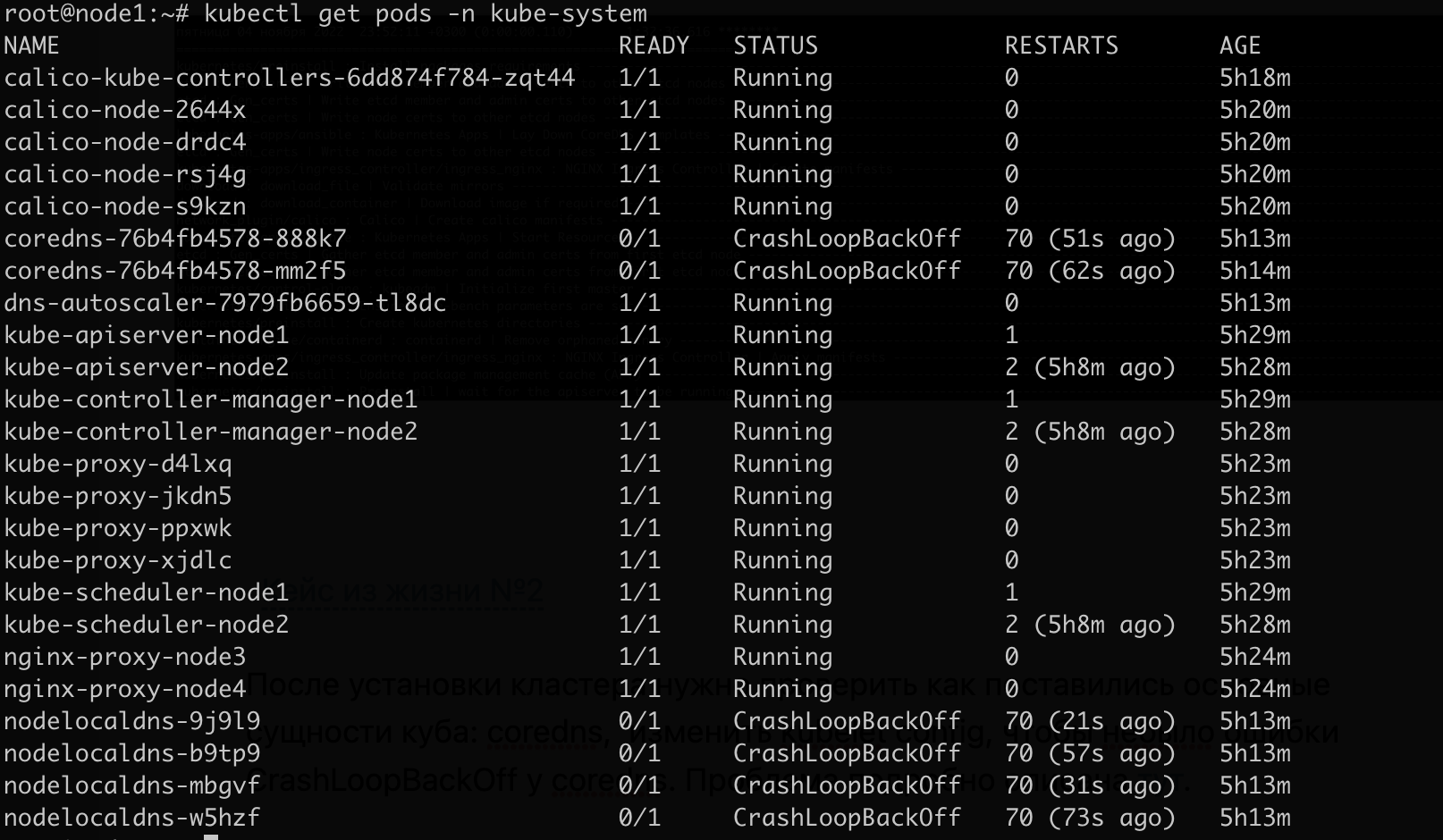
Проблема легко гуглится, и решение подробно описано тут. Отредактируем конфигурацию kubelet:
nano /etc/kubernetes/kubelet-config.yamlВ файле необходимо подправить поле resolvConf на:
resolvConf: "/etc/resolv.conf"И перезагрузить машину:
rebootВыполните это на всех узлах, рабочих и управляющих. После этого поды перезапустятся и ошибка должна исчезнуть:
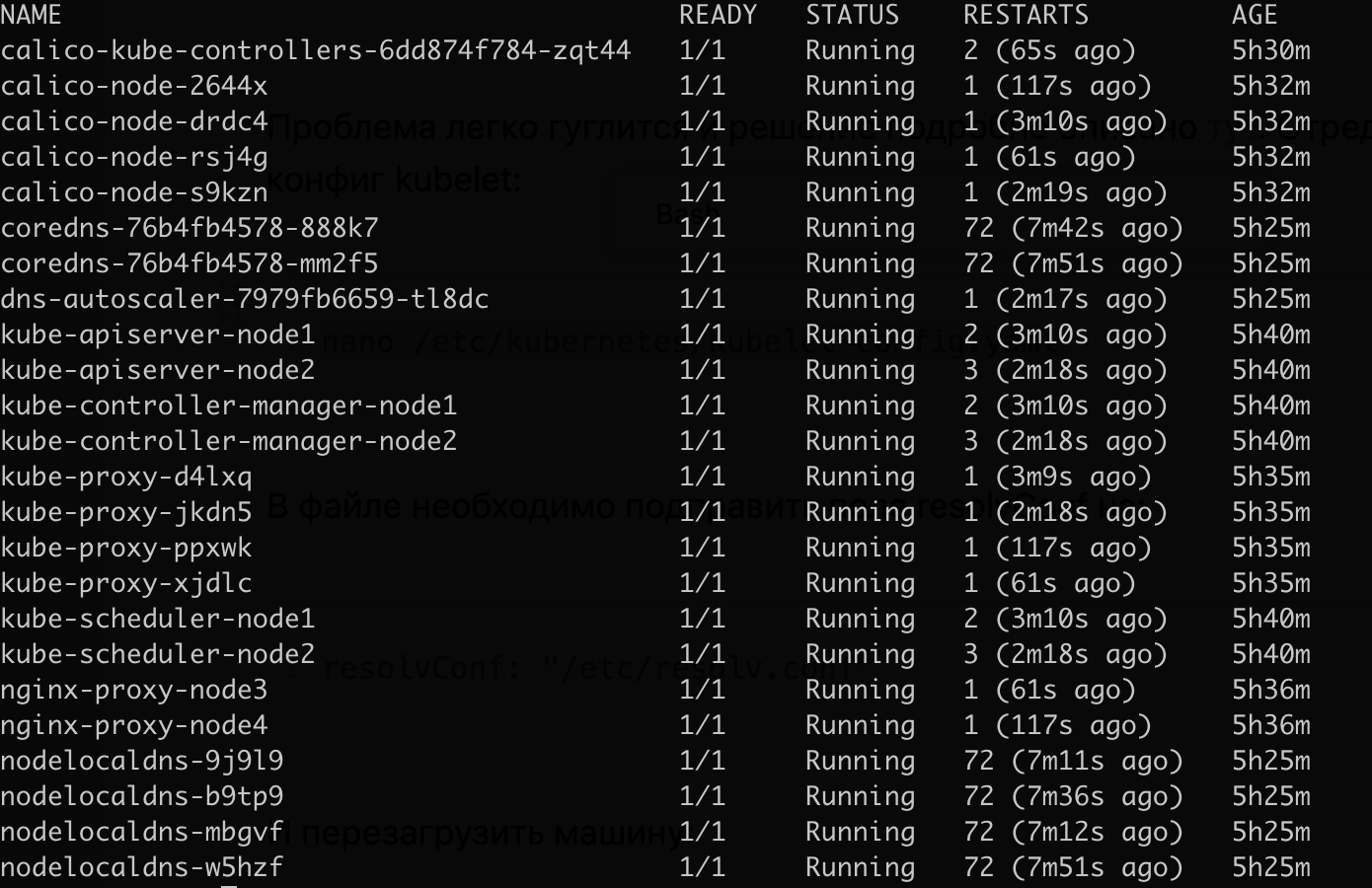
Готово, установка Kubernetes-кластера завершена. Теперь проверим на практике. насколько кластер высокодоступный, то бишь high-availability.

На любом из мастер-узлов развернём простое приложение из предыдущей статьи, которое по GET-ручке возвращает случайно сгенерированный UUID. Создадим три ресурса, первый — deployment:
kubectl create deployment uuid-server --image=mopckou/sticky-session:0.0.5Далее — Service с типом LoadBalancer:
kubectl expose deployment uuid-server --type=LoadBalancer --port=8080И наконец, создадим манифест ingress с хостом uuid.awesomeservice.pro, который принимает и обрабатывает запросы:
cat <<EOF> ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: uuid-server-ingress
spec:
rules:
- host: uuid.awesomeservice.pro
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: uuid-server
port:
number: 8080
EOFПрименим его:
kubectl apply -f ingress.yamlПроверим созданный ingress:
kubectl get ingress
У ресурса появились выделенные адреса - все 4 узла могут принимать трафик. Но по факту трафик будет поступать только на две машины 185.186.142.53 и 185.186.142.5. Всё потому что только их я завязал на домен uuid.awesomeservice.pro у своего DNS провайдера. Теперь проверим, что сервер отвечает:

В инструментах разработчика можно посмотреть, на какой узел поступил и обработан запрос:
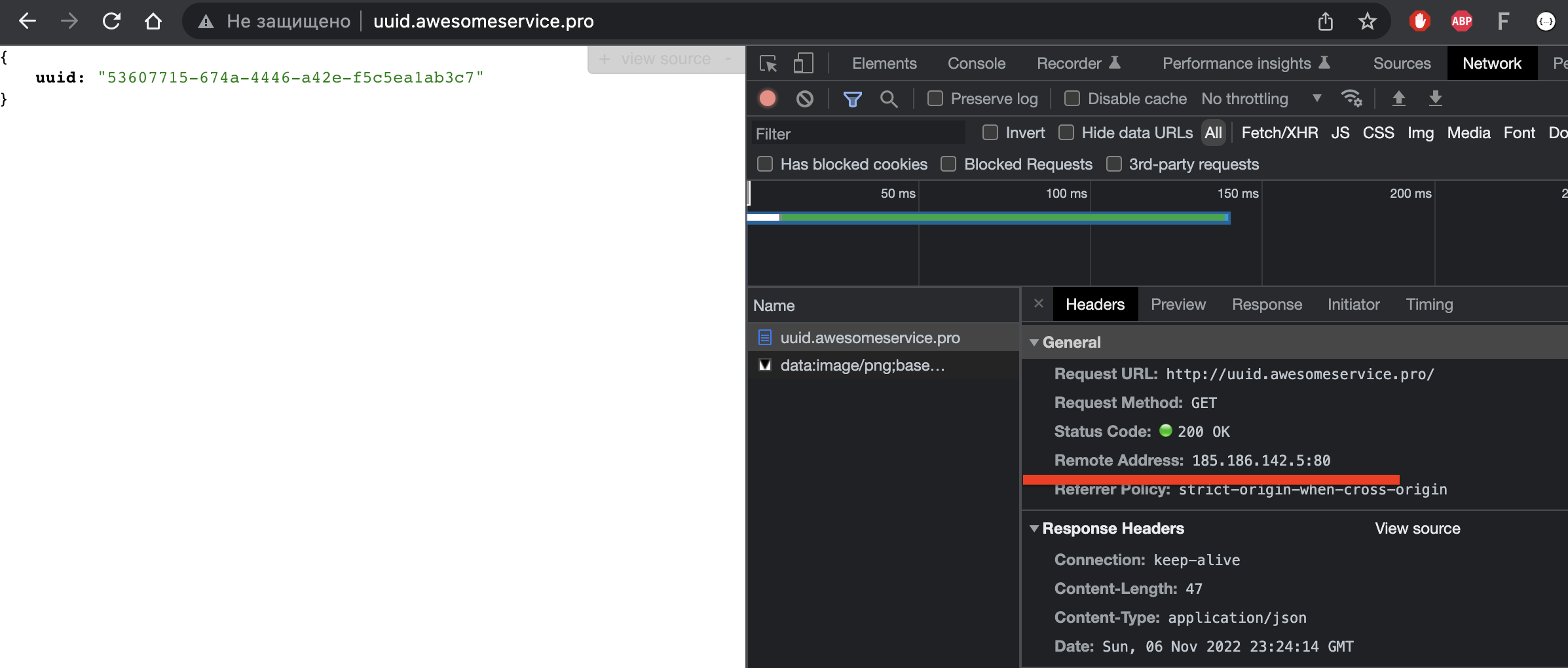
Ответила node1 (185.186.142.5). Ради интереса выполнил запрос в другом браузере (Safari):
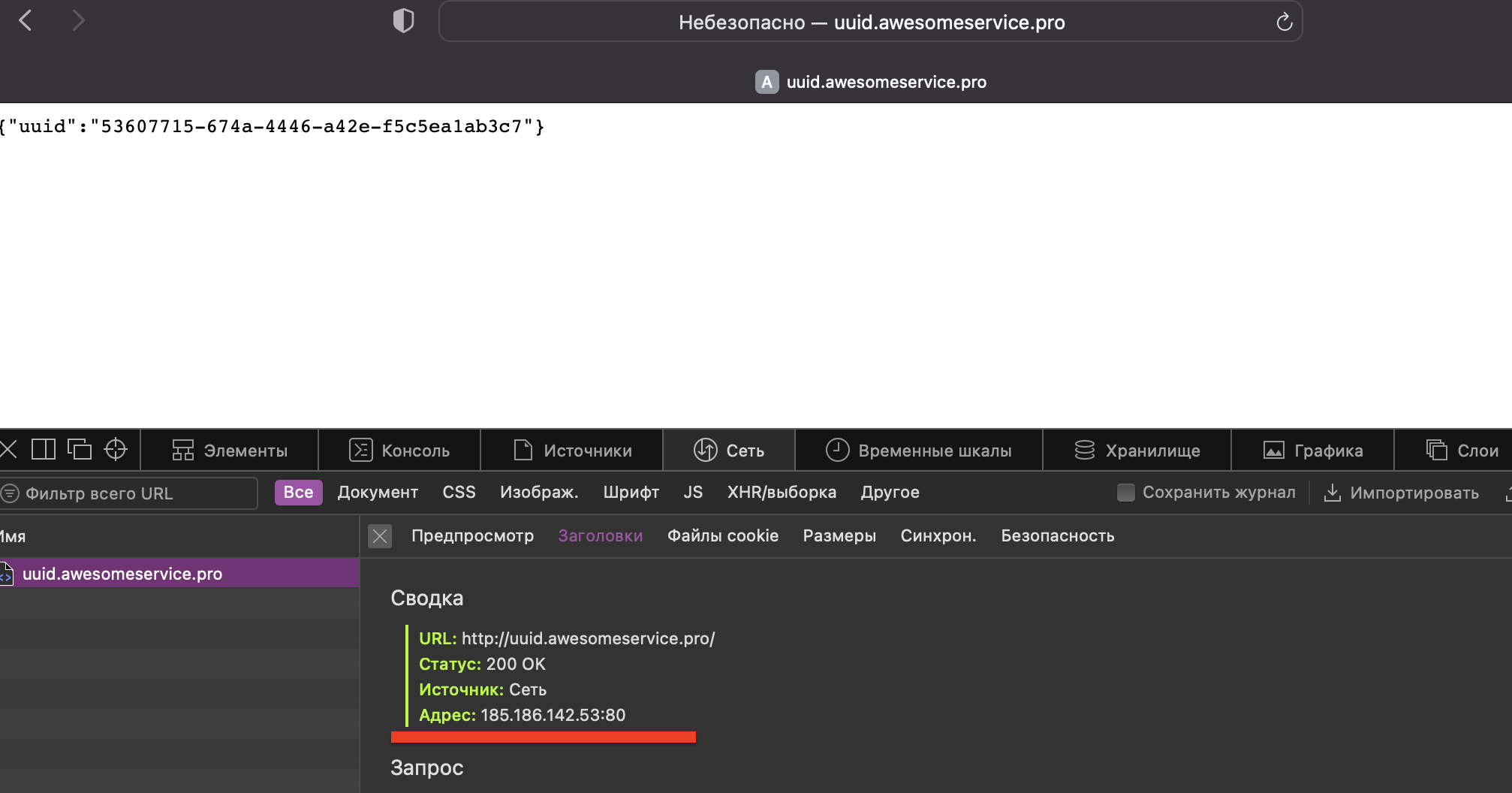
В Safari запрос был обработан узлом node2 (185.186.142.53). Таким образом заодно убедились, что DNS-балансировка работает. Теперь посмотрим, как будет отработана внештатная ситуация и для чего вообще нужен высокодоступный кластер. Допустим, что один из узлов выходит из строя и становится недоступным. Я руками выключаю удалённую машину и через второй узел смотрю состояние кластера:

Теперь проверим, как запрос обработается через браузер:
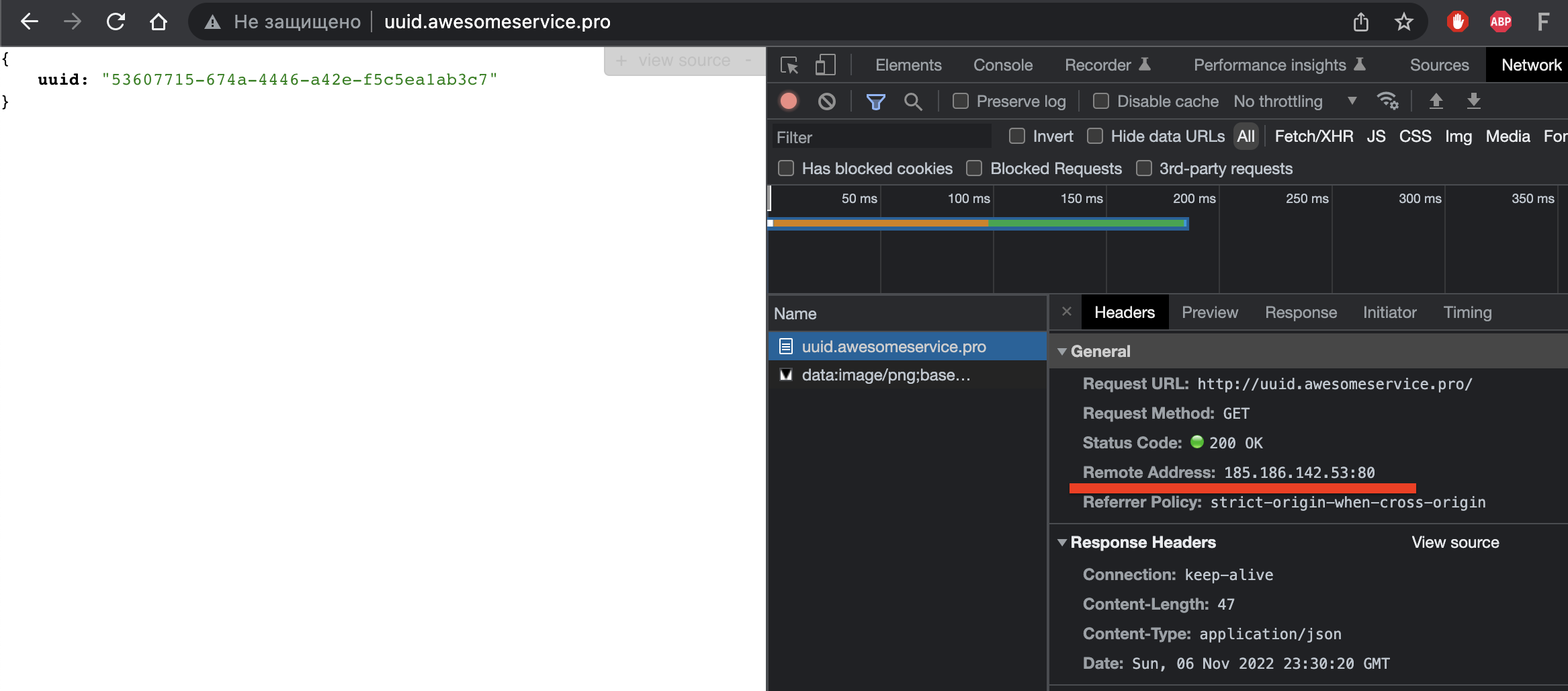
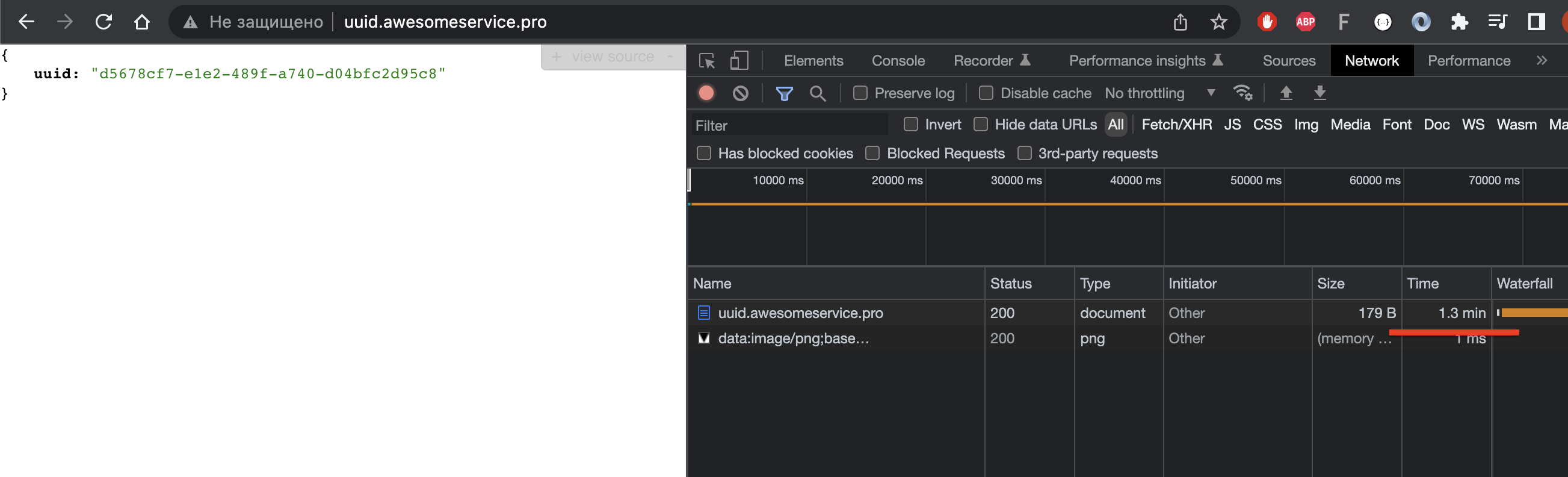
Как видите, раньше запрос в Chrome обрабатывался узлом node1 (185.186.142.5), а после того, как тот стал недоступен, запросы пошли на узел node2 (185.186.142.53). На самом деле мне повезло, видимо TTL истек и локальный кэш выполнил новый запрос к DNS серверу и получил второй адрес. Стоит чуть подольше потыкать запросы, и начинаются проблемы. В какой-то момент браузер всё таки получит адрес недоступного узла (185.186.142.5) и тогда запрос подвисает на 1 минуту, после чего браузер берет второй адрес из пула и наконец запрос успешно выполняется. На картинке видно, что обработка длилась чуть больше минуты.
Но последующие запросы будут сразу поступать на работающий узел:
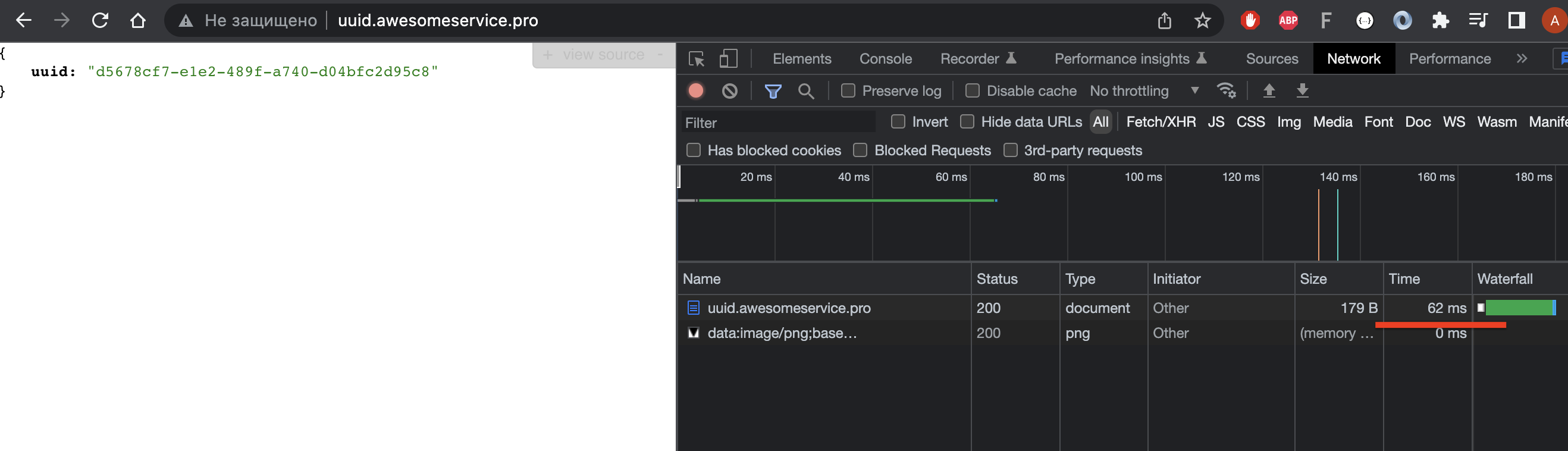
В итоге мы имеем, что кластер не совсем ВЫСОКО доступный. Если в кластере из 4 узлов, один выходит из строя, то мы будем иметь 25% долгих запросов. Но при этом надо отметить, что они всё же будут успешными. Данное поведение я проверил в 2-х браузерах и ради интереса сделал запрос в Python скрипте - там, тоже самое, долгий запрос, но в итоге успешный.
На этом установка и тестирование кластера завершено. С учетом полученных знаний и подводных камней решайте, подходит ли вам данная сборка кластера.
Обслуживание кластера
Данный раздел был основан на этой статье и issue, а в последствии доработан.
Добавление worker node
Перед тем, как добавлять новый узел, удалённую машину нужно подготовить.
Теперь займемся конфигурациями: добавим в наш инвентарь новый хост. В файле hosts.yaml аналогично добавьте три строчки с новым адресом в раздел all.hosts, и добавьте ссылку на этот хост в раздел с перечислением всех узлов в кластере — all.children.kube_node.hosts. Я добавил пятый узел с адресом 46.8.19.76.
Полный файл hosts.yaml
all:
hosts:
node1:
ansible_host: 185.186.142.5
ip: 185.186.142.5
access_ip: 185.186.142.5
node2:
ansible_host: 185.186.142.53
ip: 185.186.142.53
access_ip: 185.186.142.53
node3:
ansible_host: 46.8.19.144
ip: 46.8.19.144
access_ip: 46.8.19.144
node4:
ansible_host: 46.8.19.244
ip: 46.8.19.244
access_ip: 46.8.19.244
node5:
ansible_host: 46.8.19.76
ip: 46.8.19.76
access_ip: 46.8.19.76
children:
kube_control_plane:
hosts:
node1:
node2:
kube_node:
hosts:
node1:
node2:
node3:
node4:
node5:
etcd:
hosts:
node1:
node2:
node3:
k8s_cluster:
children:
kube_control_plane:
kube_node:
calico_rr:
hosts: {}Перед тем, как запускать плейбук присоединения нового рабочего узла к кластеру, нужно выполнить команду:
ansible-playbook -i inventory/k8s/hosts.yaml facts.yml
Это сбор информации о кластере, он не займёт много времени. Теперь можно пользоваться ключом --limit, который нужен, чтобы во время добавления нового worker-узла не беспокоить уже существующие узлы. После успешного сбора информации запускаем основной плейбук присоединения worker-узла:
ansible-playbook -i inventory/k8s/hosts.yaml --limit=node5 scale.ymlПример из жизни №3
Возможно, будет ошибка при выполнении скрипта. В моём случае надо было посмотреть, что работает resolved service. Запустим резолвер:
systemctl enable systemd-resolved.serviceУдаление worker node
Чтобы удалить рабочий узел, нужно всего лишь воспользоваться следующим плейбуком:
ansible-playbook -i inventory/k8s/hosts.yaml -e node=node5 remove-node.ymlУдаление занимает немного времени, не больше 10 минут. По завершении работы плейбука будет примерно такой вывод:

Плейбук завершится успешно только в том случае, если worker-узел жив. Если он абсолютно нерабочий, то смотрите следующий раздел про замену master-узла, там будет подробно рассказано, как удалить из кластера нерабочий узел.
Замена master node
Удалить мастер-узел, который не отвечает и не на связи, с помощью kubespray не получится. Пробовал разные варианты: запускал плейбук remove-node.yaml, запускал facts.yml, чтобы запросить актуальные данные кластера, запускал upgrade-cluster.yaml — всегда зависает на опросе недоступной ноды. Придётся удалять вручную. Эту инструкцию я долго искал по разным issue github, в итоге после небольших экспериментов получилось успешно удалить как не отвечающий мастер-узел, так и рабочий.
Сейчас кластер состоит из четырёх узлов: двух мастеров и двух рабочих машин:
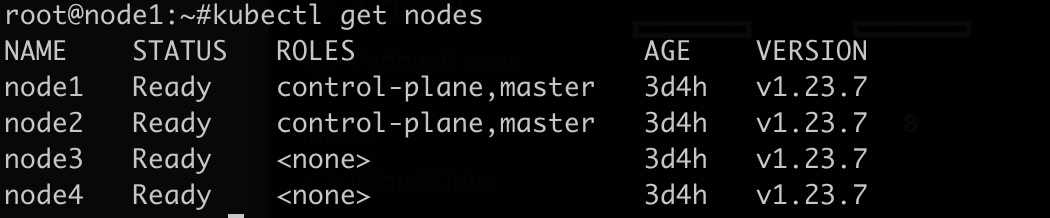
Допустим, первый мастер-узел выходит из строя и не отвечает. Для этого собственноручно выключаю удалённую машину, и примерно через минуту узел помечается как "Not Ready":

Воспроизвели нештатную ситуацию, теперь давайте заменять мастер-узел. Прежде всего объявим его нерабочим:
kubectl cordon node1
kubectl drain node1 --ignore-daemonsetsКлюч --ignore-daemonsets обязателен для недоступных узлов. Возможно, консоль подзависнет на команде drain, поэтому можно прервать ожидание (Ctl+C). После этих команд узел перейдёт в состояние NotReady, SchedulingDisabled.

Удалим узел:
kubectl delete node node1
Теперь нужно обновить cluset-info, а именно, указать в поле server актуальный адрес мастер-узла:
kubectl edit cm -n kube-public cluster-info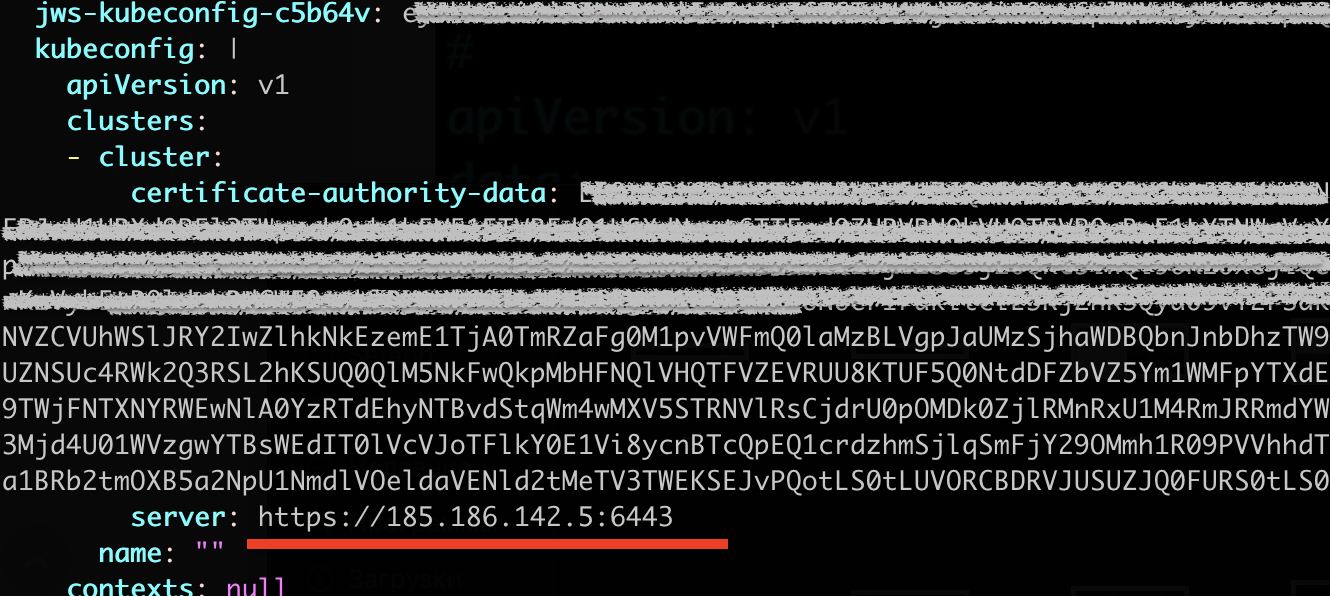
Я заменил на 185.186.142.53 (node2), так как это единственный на данный момент живой мастер. Напомню, что на каждом мастер-узле ещё и развёрнут etcd-кластер, а это значит, что наша нештатная авария задела и etcd-узел вместе с node1 kubernetes. Поэтому нужно подчистить всю информацию, связанную с etcd-1. На каждом рабочем мастер-узле открываем конфигурацию:
nano /etc/kubernetes/manifests/kube-apiserver.yamlИ удалим нерабочий etcd-узел в строке --etcd-servers. В нашем случае IP-адреса будут одинаковы:

Аналогично, на каждом мастер-узле нужно отредактировать etcd-конфигурацию:
nano /etc/etcd.envИ удалить неактивную etcd-ноду в поле ETCD_INITIAL_CLUSTER:
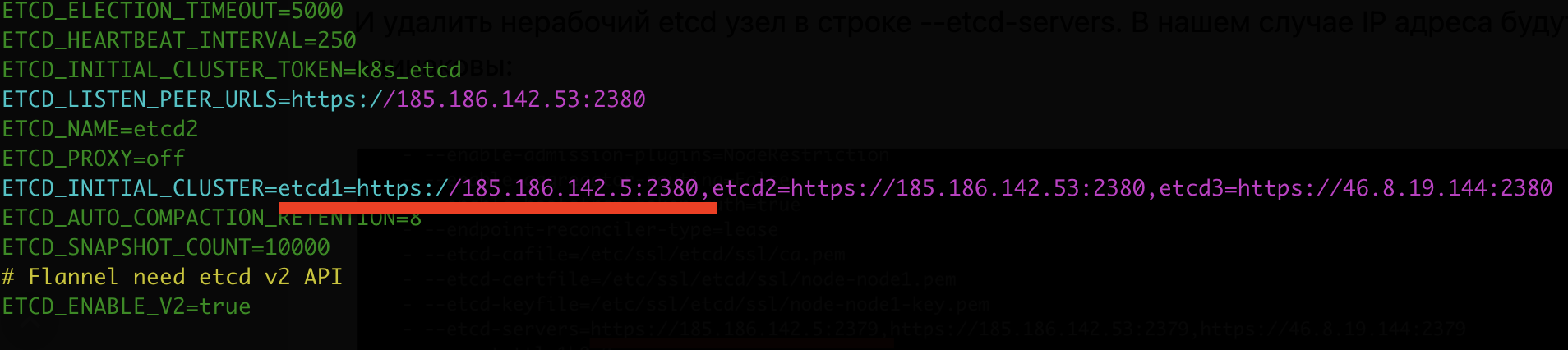
После актуализации конфигураций последний штрих — это удаление ноды непосредственно из etcd-кластера. Воспользуемся консольной утилитой etcdctl для доступа к кластеру etcd. Эта утилита должна быть установлена на мастер-узлах. Прежде всего посмотрим существующие etcd-узлы:
etcdctl member list --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/admin-node2.pem --key=/etc/ssl/etcd/ssl/admin-node2-key.pemВывод будет примерно таким:

Обратите внимание, что ключи --cacert, --cert и --key обязательны, и эти сертификаты уже сгенерированы kubespray и будут лежать в директории /etc/ssl/etcd/ssl/ на каждой машине, где развёрнут etcd-кластер. Теперь удалим из etcd-кластера неактивный узел:
etcdctl member remove 4f211fee4e79e7e7 --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/admin-node2.pem --key=/etc/ssl/etcd/ssl/admin-node2-key.pemВывод будет такой:

Можете после этого проверить предыдущей командой, что etcd-узел удалён. И последнее: возвращаемся на локальную машину и удаляем неактивный host из файла hosts.yaml:
nano inventory/k8s/hosts.yamlДостаточно будет удалить три строчки из children.kube_control_plane.hosts, children.kube_node.hosts и children.etcd.hosts (в all.hosts можно оставить, если потом захотите повторно добавить этот хост в кластер):
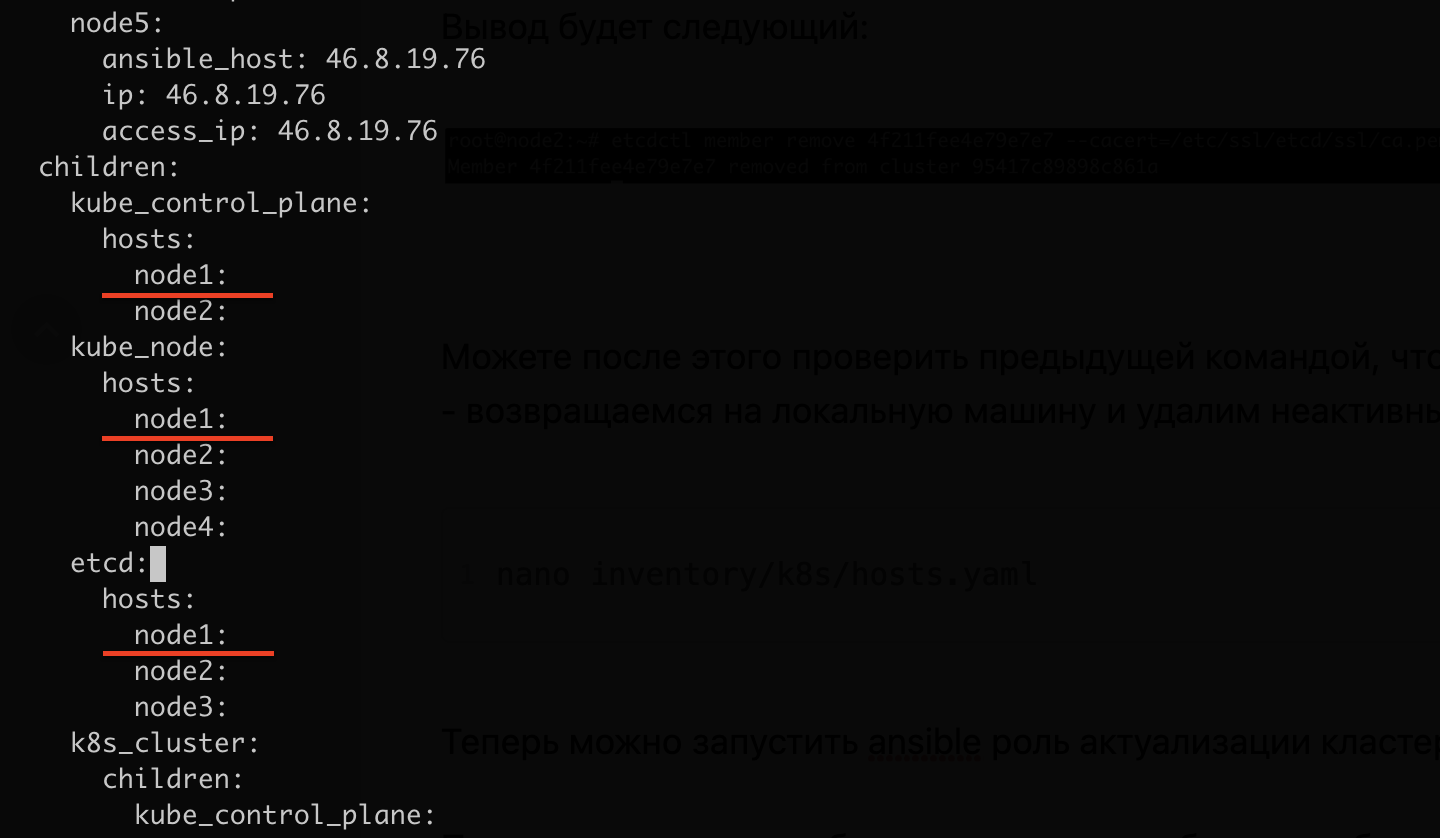
Полный hosts.yaml
all:
hosts:
node1:
ansible_host: 185.186.142.5
ip: 185.186.142.5
access_ip: 185.186.142.5
node2:
ansible_host: 185.186.142.53
ip: 185.186.142.53
access_ip: 185.186.142.53
node3:
ansible_host: 46.8.19.144
ip: 46.8.19.144
access_ip: 46.8.19.144
node4:
ansible_host: 46.8.19.244
ip: 46.8.19.244
access_ip: 46.8.19.244
node5:
ansible_host: 46.8.19.76
ip: 46.8.19.76
access_ip: 46.8.19.76
children:
kube_control_plane:
hosts:
node2:
kube_node:
hosts:
node2:
node3:
node4:
etcd:
hosts:
node2:
node3:
k8s_cluster:
children:
kube_control_plane:
kube_node:
calico_rr:
hosts: {}Теперь нужно запустить Ansible-роль актуализации кластера (upgrade-cluster.yml). При вызове этой команды возникнет ошибка чётного количества etcd-серверов. Чтобы эту ошибку проигнорировать, нужно добавить специальный ключ ignore_assert_errors. Команда для запуска роли:
ansible-playbook -i inventory/k8s/hosts.yaml -e ignore_assert_errors=yes upgrade-cluster.ymlПосле выполнения роли вывод консоли будет такой:
Теперь можно добавлять новый мастер-узел в кластер. Но перед эти подготовить удалённую машину. Я вместо подготовки на node1 (185.186.142.5) накатил снимок ОС с готовым сетапом для установки Kubernetes. Отредактируем hosts.yaml:
nano inventory/k8s/hosts.yamlДобавим новый host (в моем случае это node1) в all.hosts в разделы children.kube_control_plane.hosts, children.kube_node.hosts и children.etcd.hosts. Надо отметить, что советуют всегда добавлять новый хост в конец списка.
Полный файл hosts.yaml
all:
hosts:
node1:
ansible_host: 185.186.142.5
ip: 185.186.142.5
access_ip: 185.186.142.5
node2:
ansible_host: 185.186.142.53
ip: 185.186.142.53
access_ip: 185.186.142.53
node3:
ansible_host: 46.8.19.144
ip: 46.8.19.144
access_ip: 46.8.19.144
node4:
ansible_host: 46.8.19.244
ip: 46.8.19.244
access_ip: 46.8.19.244
node5:
ansible_host: 46.8.19.76
ip: 46.8.19.76
access_ip: 46.8.19.76
children:
kube_control_plane:
hosts:
node2:
node1:
kube_node:
hosts:
node2:
node3:
node4:
node1:
etcd:
hosts:
node2:
node3:
node1:
k8s_cluster:
children:
kube_control_plane:
kube_node:
calico_rr:
hosts: {}Запускаем плейбук cluster.yaml. В ключе --limit указываем etcd и kube_control_plane, тогда при установке работоспособность worker-узлов затронута не будет.
ansible-playbook -i inventory/k8s/hosts.yaml --limit=etcd,kube_control_plane cluster.yml
Готово, мастер-узел успешно добавлен!
Решение возможных проблем
Если добавляется абсолютно новая виртуалка, то проблем возникнуть не должно. Но если добавляется машина с тем же IP, то даже если система только что переустановлена, возникнут, скорее всего, проблемы. У меня, например, эта ошибка повторяется постоянно:

Каждый раз проблема возникает при присоединении etcd-узла к etcd-кластеру. Посмотрим логи etcd на удалённой машине node1:
journalctl -n 100 --unit=etcdБудет следующая ошибка:
"error":"error validating peerURLs {ClusterID:95417c89898c861a Members:[&{ID:5baef32decc40060 RaftAttributes:{PeerURLs:[https://185.186.142.53:2380] IsLearner:false} Attributes:{Name:etcd1 ClientURLs:[https://185.186.142.53:2379]}} &{ID:80fbe9a8863e9bfe RaftAttributes:{PeerURLs:[https://46.8.19.144:2380] IsLearner:false} Attributes:{Name:etcd2 ClientURLs:[https://46.8.19.144:2379]}}] RemovedMemberIDs:[]}: member count is unequal"Прогуглив ошибку "member count is unequal", можно наткнуться на такое решение. В нём советуют указать машину с другим IP, отличным от прежнего. Это подтверждает тезис, что если добавлять новый хост с новым IP, то Ansible-роль отработает и мастер-узел успешно добавится к Kubernetes-кластеру. Допустим, что у нас нет другой машины. Методом научного тыка я нашёл другое решение: сначала добавим вручную etcd-узел к etcd-кластеру, а после перезапустим Ansible-роль cluster.yaml, и мастер-узел успешно добавится к Kubernetes-кластеру.
Дальнейшие шаги выполняем на мастер-узле (node1). Сначала заглянем в etcd-конфигурацию:
nano /etc/etcd.env
Новый etcd-узел подключается как etcd3, запомним это имя. Вот команда присоединения к etcd-кластеру:
etcdctl member add etcd3 --endpoints=185.186.142.53:2379,46.8.19.144:2379 --peer-urls=https://185.186.142.5:2380 --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/admin-node3.pem --key=/etc/ssl/etcd/ssl/admin-node3-key.pemЗдесь в ключе --endpoints указываются уже существующие узлы etcd-кластера, в --peer-urls — адрес нового etcd-узла (обратите внимание на порты, в первом ключе 2379, во втором — 2380). Остальные ключи — это ссылка на сертификаты, которые уже сгенерированы kubespray, смотрите в соответствующую директорию etc/ssl/etcd/ssl/. Вывод консоли будет такой:

Etcdctl сообщит кластеру о новом участнике и распечатает переменные среды, необходимые для его успешного запуска. Так как служба уже запущена в фоне, то перезапускать ничего не придётся. Убедитесь, что сгенерированные в консоли переменные окружения такие же, как в /etc/etcd.env; если нет, то нужно подправить этот файл на всех удалённых машинах, где развернут etcd, и перезапустить службу.
Смотрим текущее состояние etcd-кластера:
etcdctl member list --endpoints=185.186.142.53:2379,46.8.19.144:2379 --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/admin-node3.pem --key=/etc/ssl/etcd/ssl/admin-node3-key.pem
Etcd-узел успешно добавлен в etcd-кластер. Можно ещё глянуть, как дела со здоровьем кластера:
etcdctl endpoint health --endpoints=https://185.186.142.53:2379,https://46.8.19.144:2379,https://185.186.142.5:2379 --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/admin-node2.pem --key=/etc/ssl/etcd/ssl/admin-node2-key.pem
Etcd-кластер чувствует себя отлично. Наконец, можно перезапустить Ansible-роль и добавить новый мастер-узел к Kubernetes-кластеру.
ansible-playbook -i inventory/k8s/hosts.yaml --limit=etcd,kube_control_plane cluster.yml
Полезные команды
Вот список полезных команд, которые наверняка понадобятся.
Просмотр журнала логов etcd, kubelet:
journalctl --unit=etcd -n 100
journalctl --unit=kubelet -n 100Просмотр статуса и перезагрузка службы:
systemctl status kubelet
systemctl restart kubeletВозможно, понадобится сделать снимок с etcd- узла. Вот рабочий пример:
ETCDCTL_API=3 etcdctl --endpoints https://185.186.142.53:2379 snapshot save snapshot.db --cacert=/etc/ssl/etcd/ssl/ca.pem --cert=/etc/ssl/etcd/ssl/admin-node2.pem --key=/etc/ssl/etcd/ssl/admin-node2-key.pemМониторинг ресурсов виртуалки:
wget -qO- bench.sh | bashК оглавлению ↑
А на этом всё. Пишите, если знаете, как бюджетно (и, желательно, просто и без дергающегося глаза) реализовать внешний балансировщик (отказоустойчивый, конечно!). Хочется, чтобы технология была ближе к обычным работягам 🐝, без сложных Enterprise-решений.
Hidden text
Пятая, юбилейная статья, наконец, закончена.

